









GEE从入门到实战的10个系列单元:
- GEE系列:第1单元 Google地球引擎简介
- GEE系列:第2单元 探索数据集
- GEE系列:第3单元 栅格遥感影像波段特征及渲染可视化
- GEE系列:第4单元 Google 地球引擎中的数据导入和导出
- GEE系列:第5单元 遥感影像预处理【GEE栅格预处理】
- GEE系列:第6单元 在 Google 地球引擎中构建各种遥感指数
- GEE系列:第7单元 利用GEE进行遥感影像分类【随机森林分类】
- GEE系列:第8单元 Google 地球引擎中的时间序列分析【时间序列】
- GEE系列:第9单元 在GEE中生成采样数据【随机采样】
- GEE系列:第10单元 使用 Google 地球引擎创建图形用户界面【GUI开发】
第 6 单元:在 Google 地球引擎中构建各种指数
1简介
在本模块中,我们将讨论以下概念:
- 如何在 GEE 中重命名图像的波段。
- 如何使用已有的遥感指数。
- 如何使用波段数学生成自己的遥感指数。
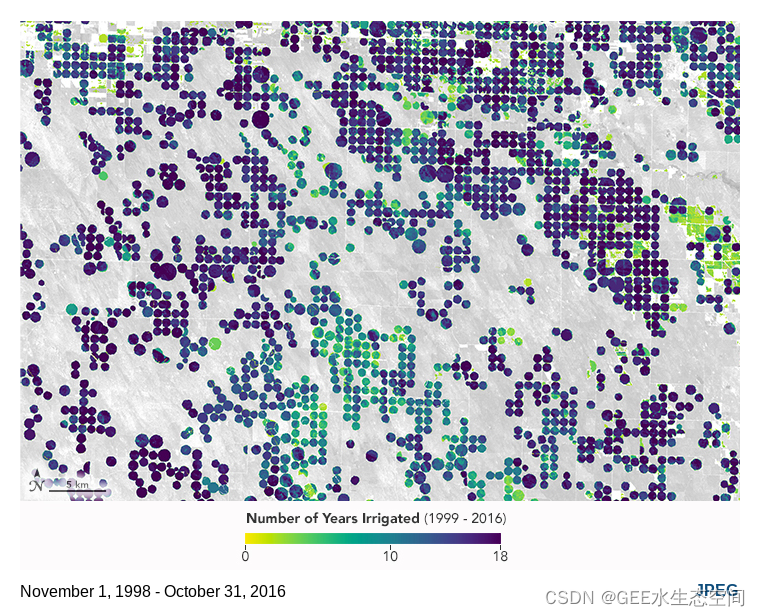
一个田地已经灌溉的年数的卫星图像。灌溉水最可能的来源是奥加拉拉含水层。图片来自科罗拉多州霍利奥克附近。资料来源:美国国家航空航天局
2背景
世界上大部分生产力最高的农业用地都被广泛开发用于耕作。增加整体农业生产的努力通常依赖于通过引水项目进口水或从称为含水层的地下水库中提取地下水来提高边缘土地的生存能力。奥加拉拉含水层位于美国西部 10 个州以下,为该国约 30% 的灌溉农业提供水源。含水层的广泛使用加上缓慢的补给率意味着含水层的许多地区水位显着下降。从这些含水层中提取水的过程非常引人注目,以至于 NASA GRACE 卫星已经能够探测到地球对这些含水层的引力随时间的变化。与世界各地的其他主要含水层相比,奥加拉拉的减少幅度很小。然而,有大量可用数据显示奥加拉拉的农业土地产量。在本模块中,我们将了解哪些遥感数据非常适合识别奥加拉拉内的灌溉农田。我们的目标是将这些相同的方法应用于世界上其他公开可用的农业数据较少但依靠地下水开采来促进边缘土地农业的地区。
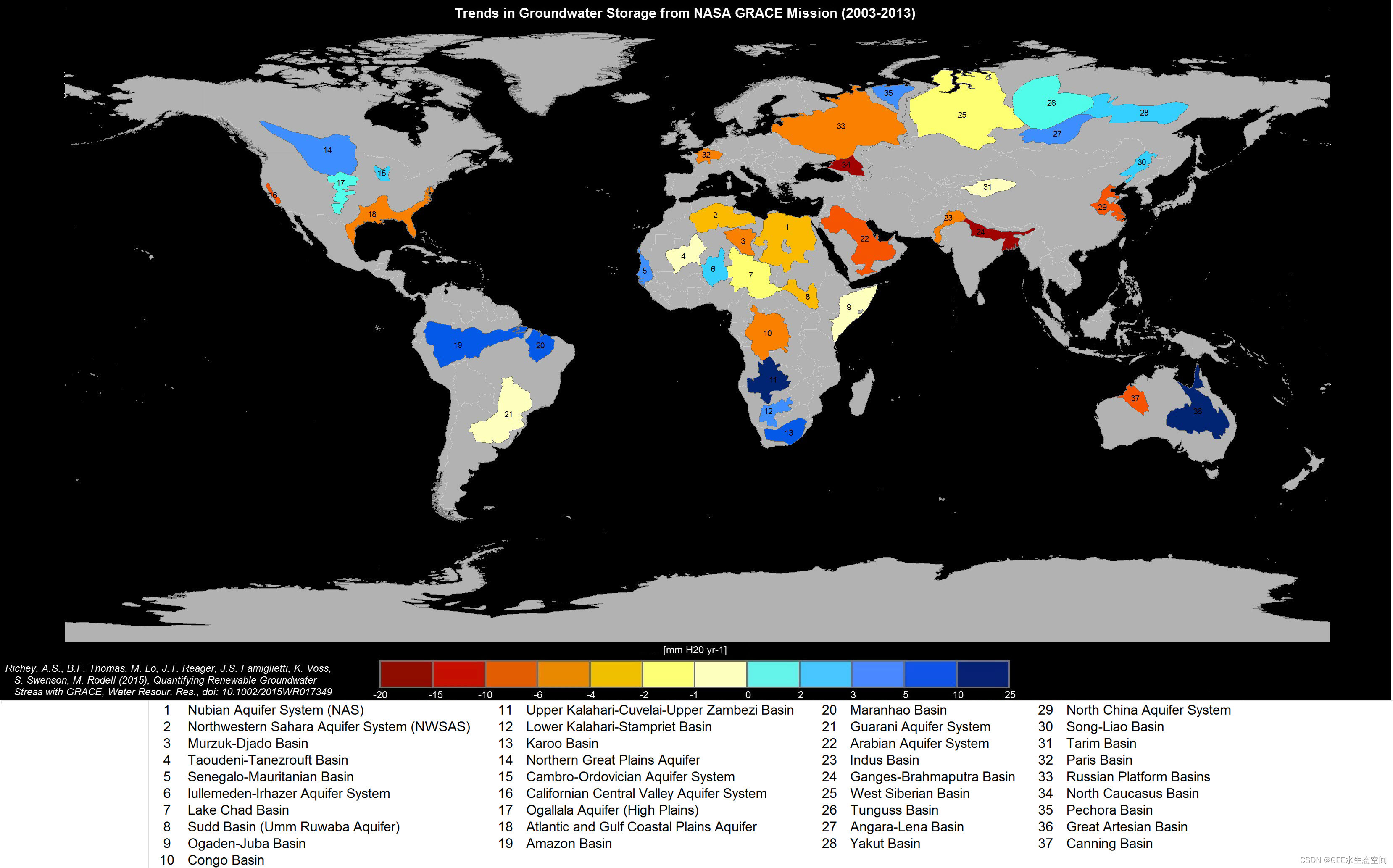
地球 37 个最大含水层地下水储量变化趋势。在此处阅读有关此图像的更多信息。图片来源:加州大学欧文分校/NASA/JPL-Caltech。
2.1关于数据
平均降水量
我们知道,在农作物无法从降雨中获得足够水分的地方,灌溉更有可能发生。因此,应该存在年总降水量与区域内灌溉农业概率之间的关系。为了在 Ogallala 中查看这种关系,我们将从WorldClim数据集(气候数据的全球资源)中引入年降水量栅格。WorldClim 版本 1 中有 19 个气候变量,但目前我们只关心一个, bio12:年降水量。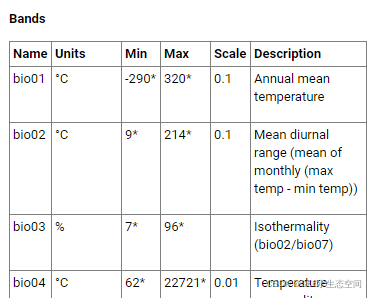
GEE 的 WorldClim 版本 1 元数据示例。
农田数据层
我们有兴趣确定哪些遥感数据可用于将灌溉农田与某个位置的自然景观区分开来。为了访问不同遥感数据的适当性,我们需要一个验证数据集来比较我们的值。为此,我们将依赖USDA NASS Cropland 数据层。该数据集每年开发一次,空间分辨率为 30 m,适用于美国 48 州。它包含 255 个独特的作物类别。
注意:我们在模块 3中为土地覆盖使用了不同的分类数据集。
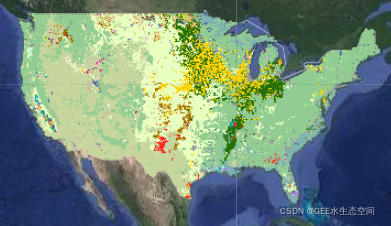
美国农业部全球农田数据层横跨美国本土。黄色代表玉米,绿色代表大豆,红色代表棉花。观察加利福尼亚中央山谷的多样性也很有趣。
3用遥感影像识别灌溉土地
您需要为此模块打开一个新的 Google 地球引擎脚本。在code.earthengine.google.com/上执行此操作
3.1定义一个感兴趣的区域
我们的第一步是定义感兴趣的区域。
使用下面的 Ogallala 含水层图像,使用地图左上角的绘制矩形工具在 GEE 脚本中绘制边界框。
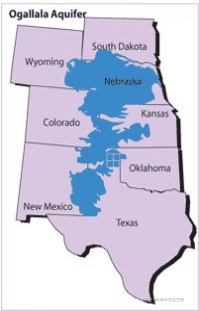
显示奥加拉拉含水层范围的图像。
这张地图和含水层的简短描述可以在这里找到。
边界框不需要是完美的。我们只是想将我们的关注点缩小到可能来自这个水源的一般区域。那就是含水层之上的所有土地。
3.2表征降水
首先,我们将通过使用唯一 ID 调用 BioClim 数据集来引入年降水量层。这些数据存储为多波段图像,因此我们将使用ee.Image()函数调用它。
// Call in image by unique ID.
var bioClim = ee.Image("WORLDCLIM/V1/BIO");
print(bioClim, "bioClim");从 print 语句中我们可以看到每个变量都存储为一个带区。ee.Image.select()我们可以使用该函数拉取我们感兴趣的特定波段。选择后,我们会将结果剪辑到我们感兴趣的区域并重命名,以便我们记住“bio12”代表什么。
// Select specific band, clip to region of interest, and rename.
var precip = bioClim
.select("bio12")
.clip(geometry)
.rename("precip");
Map.addLayer(precip, {min:240 , max:1300}, "precip", false);我们可以从生成的图像中看出,当您从东向西穿越大平原时,降水量会出现可预测的减少。我们将在该地区的西部看到更多的灌溉农业是有道理的。我们将添加 Cropland 数据层来测试这个假设。
3.3表征农业
在这种情况下,农田数据层存储为图像集合。我们仍在使用唯一 ID 调用它,但我们正在使用该ee.ImageCollection()函数。
// Call in collection base on unique ID and print.
var crops = ee.ImageCollection("USDA/NASS/CDL");
print(crops, "crops");图像集合包含多个具有相同属性的图像。因此,处理图像集合在很大程度上依赖于过滤功能。过滤很有用,但应用过滤器不会更改影像的数据类型。过滤器总是返回一个图像集合对象。这很好,但是不同的 GEE 对象有不同的功能。通常您需要将图像集合转换为图像。最常见的方法之一是应用reducer。与其他遥感软件相比,减速器是使 GEE 脱颖而出的元素之一。虽然它们非常强大,但我们不会在本模块中详细介绍它们的功能。
// Filter collection by a date range and pull a specific image from the collection.
var crop2016 = crops
.filterDate("2016-01-01","2016-12-30")
.select(['cropland']);
print(crop2016, "crop2016");正如我们所料,该crop2016对象仍然是一个图像集合对象,即使它只包含一个图像。

2016 年农田数据集的打印声明。
我们可以简单地通过它包含的唯一 ID 调用此图像,然后使用该Image.select()函数拉取我们感兴趣的特定波段,而不是应用 reducer。我们可以通过打印对象和读取元数据来查看图像 ID。
// Call the specific image by the unique ID, select band of interest, and clip to region of interest.
var cropType2016 = ee.Image("USDA/NASS/CDL/2016")
.select("cropland")
.clip(geometry);
print(cropType2016, "cropType2016");
Map.addLayer(cropType2016, {}, "cropType2016", false);在这里,我们调用图像,选择感兴趣的波段,并将图像剪辑到我们的输出区域。
我们可以使用这两个数据集来查看土地耕地和该地区平均降水量的大图模式。如果你真的想深入研究这些数据,你可以看看种植的作物类型。您需要通过搜索数据集从 USDA 层提取元数据。如上所述,数据集中有 255 种不同的土地覆被类型,因此它很快就会变得不堪重负。下面是我们感兴趣的地区常见作物的表格。
| 价值 | 颜色 | 庄稼 |
|---|---|---|
| 1 | 黄色的 | 玉米 |
| 2 | 红色的 | 棉 |
| 24 | 棕色的 | 冬小麦 |
作物的圆形区域表示使用中心枢轴灌溉的田地。考虑到该地区的干旱程度以及流经该地区的主要河流数量,中心支点使用的水很可能来自地表以下,即奥加拉拉含水层。不圆的田地仍然可以灌溉。虽然效率可能较低,但许多地区使用漫灌来浇灌作物。如果没有对作物和该地的生长条件的广泛了解,则很难根据这两层来确定田地是否进行了洪水灌溉。我们希望农田和非农田之间光谱反射率值的差异有助于我们做出区分。
您可以打开这两个图层并调整透明度以查看降水量和农田之间的重叠。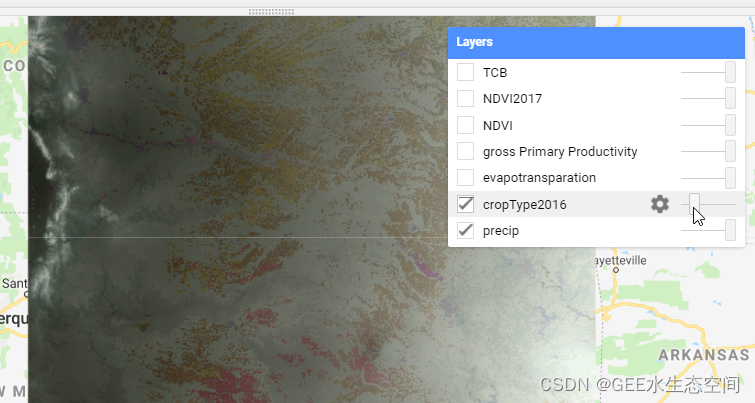
通过增加降水图像的透明度,我们可以直观地评估大面积地理区域作物类型与年降水量之间的关系。
3.4可视化现有指数
GEE 的主要优点之一是它是一个数据存储库。在本节中,我们将访问一些已经生成的预先存在的数据集,看看我们是否可以依靠它们来回答我们的问题,而不必担心花时间生成我们自己的数据集。无需重新发明轮子。我们将研究三个选项:
蒸发蒸腾作用:通过土壤和其他表面的蒸发作用以及植物的蒸腾作用,水从陆地转移到大气中的过程。
初级生产力:光合作用或化学合成发生的速率。
归一化差异植被指数:描述植被覆盖可见光和近红外反射率之间差异的无量纲指数,可用于估计土地区域内植被的密度和健康状况。
这些指数为我们提供了有关给定位置存在多少植物生命的信息。由于灌溉通过提供比其他方式更多的水来支持植物生长,我们可能怀疑灌溉土地会在指数图像中脱颖而出。您可以使用以下名称在 GEE 中搜索所有这些数据集的详细信息。
蒸发量:Terra Net 蒸发量 8 天全球 500m
初级生产力总值:Landsat 初级生产力总值 CONUS
NDVI : Landsat 8 32 天 NDVI 综合
// Evapotranspiration: call in image collection by unique ID and print to understand data structure.
var et = ee.ImageCollection("MODIS/006/MOD16A2")
.filterBounds(geometry);
print(et, "modisET");调用新数据集并打印它是一种很好的做法,这样您就可以在尝试过滤之前查看数据结构和图像可用性。即使请求与数据集中存在的信息不匹配,GEE 也会对数据集应用过滤器,因此您需要了解您的要求是否可行。
从元数据中,我们建立了一个有意义的日期范围,并且我们知道我们对哪些波段感兴趣。现在我们将过滤集合。
// Filter by data, select band, apply reducer to get single image and clip image.
var et2 = et
.filterDate("2016-07-01","2016-09-30")
.select(['ET'])
.median()
.clip(geometry);
Map.addLayer(et2, {max: 357.18 , min: 29.82}, "evapotransparation", false);蒸发蒸腾层作为图像集提供。我们在这里应用一个中值缩减器,因为我们想要代表该地区生长季节的广义值。中值缩减器将获取一堆图像,计算每个单元格的中值,并将所有这些单元格编译回单个图像。应用中值缩减器后,您的图像不再代表单个时间点,而是一段时间内的信息集合。
我们也将对“初级生产力总产值”层重复此过程。
// Gross Primary Productivity.
var GPP = ee.ImageCollection("UMT/NTSG/v2/MODIS/GPP");
print(GPP, "modisGPP");
var GPP2 = GPP
.filterDate("2016-07-01","2016-09-30")
.select(['GPP'])
.median()
.clip(geometry);
Map.addLayer(GPP2, {max: 1038.5 , min: 174.5}, "gross Primary Productivity", false);之前的两个数据集来自 MODIS 图像。我们使用的 NDVI 层来自不同的传感器 Landsat。虽然两种传感器之间存在许多差异,但主要因素是空间分辨率(像素区域)和时间分辨率(图像重新捕获周期)。Landsat 的空间分辨率要好得多(30 m,而 MODIS 为 500 m),但时间分辨率要低得多(返回时间为 16 天,而 MODIS 为 1 天)。始终建议比较多个传感器,因为每个传感器都有优点和缺陷。您需要了解哪种工具最适合您的应用程序。
// Pulling in NDVI data.
var LS8NDVI = ee.ImageCollection("LANDSAT/LC8_L1T_32DAY_NDVI")
print(LS8NDVI, "ls8NDVI");
// Filter, reduce, then clip.
var LS8NDVI2 = LS8NDVI
.filterDate("2016-07-01","2016-09-30")
.median()
.clip(geometry);
Map.addLayer(LS8NDVI2, {max: 0.66 , min: -0.23}, "NDVI", false);加载地图上的三幅图像需要一些时间来探索在整个景观中识别的视觉模式。观察图像之间反射率差异的好地方是在科罗拉多州的乔斯附近。您可以像在 Google 地图中一样在搜索栏中搜索“Joes, Colorado”来找到它。在乔斯方圆几英里内有一些明显的中心枢纽灌溉区、代表自然景观的未开发土地和河岸带。
min我们使用定义的可视化参数和 将所有图像添加到地图中max。这些值是通过应用拉伸和记录脚本中的最小值和最大值来创建的。这是一种使数据中的差异更容易看到的方法,并且不会改变数据中的基础值。

科罗拉多州乔斯周围地区的 NDVI 图像。明亮区域代表具有高 NDVI 值的位置,并与灌溉土地和河岸地区相关。
3.5想法和局限
您决定使用什么索引完全取决于您。这里使用的三个似乎捕捉到了灌溉和非灌溉土地的差异,但所有图像都有一些独特的考虑。
-
蒸散:单元格大小对于区分中心枢轴位置来说有点大。
-
初级生产力总量:与蒸发量数据类似的单元大小问题。此外,此数据集仅适用于毗邻的美国,因此无法帮助我们解决全球性问题。
-
NDVI:看起来像是赢家,但数据只能在 2017 年之前获得,所以在那之后它对我们没有任何帮助。
基于这些观察到的限制,我们将使用 Landsat 8 数据生成我们自己的一组指数,这些数据可以在图像收集的任何时间点应用于任何位置。
4建立自己的指数
我们将在 Landsat 8 图像上创建 NDVI 指数,因为它确实很好地突出了植被区域。
第一步是引入 Landsat 图像。因为我们正在大面积工作并编译来自多个时间段的图像,我们将使用预处理的 USGS Landsat 8 Surface Reflectance Tier 1 数据集。这是可用于 Landsat 影像的最高级别预处理,可有效地让您通过减轻大气影响直接比较来自不同影像的值。您可以在模块 5中找到各种预处理级别的详细说明。
// Call in Landsat 8 surface reflectance Image Collection, filter by region and cloud cover, and reduce to single image.
var LS8_SR2 = ee.ImageCollection("LANDSAT/LC08/C01/T1_SR")
.filterDate("2017-07-01","2017-09-30")
.filterBounds(geometry)
.filterMetadata('CLOUD_COVER', 'less_than', 20)
.median();
print(LS8_SR2,'LS8_SR2');按元数据过滤是一个新命令。您可以通过检查图像的文档和函数本身来了解它是如何工作的。
有多种方法可以定义索引。我们将在本节中介绍三个。其中两种方法需要定义单独的波段,一种需要从图像中选择波段。我们的第一步是从波段中定义单个图像。
// Pull bands from the LS8 image and save them as images.
var red = LS8_SR2.select('B4').rename("red");
var nir = LS8_SR2.select('B5').rename("nir");
print(red);归一化差异植被指数 (NDVI) 是一种非常常见的植被测量方法。使用以下等式计算:
NDVI = (nir - red)/(nir + red)
生成指数的第一种方法是使用数学函数来重现 NDVI 方程。您不能在 GEE 中单独使用符号 (+,-,/,*) 作为数学表达式。相反,您需要写出操作。
// Generate NDVI based on predefined bands.
var ndvi1 = nir.subtract(red).divide(nir.add(red)).rename('ndvi');
Map.addLayer(ndvi1, {max: 0.66 , min: -0.23},'NDVI1',false);直接调用数学函数很快就会变得很麻烦。另一种选择是依赖内置函数。在我们的例子中,有一个特征normalizedDifference()函数ee.Image。我们在 Landsat 8 图像集合中应用了缩减器,因此我们得到了可以使用的图像。因此,调用此函数就像将其指向正确的波段一样简单。
// Define LS8 NDVI using built in normalized difference function.
var ndvi2 = LS8_SR2.normalizedDifference(['B5', 'B4']);
Map.addLayer(ndvi2, {max: 0.66 , min: -0.23},'NDVI2',false);可用于生成索引的最后一种方法是构建表达式。鉴于 GEE 中内置了归一化差分函数,因此将这种方法用于 NDVI 是没有意义的。我们在这里以它为例。对于更复杂的指数,例如流苏帽转换或增强植被指数 (EVI),该过程是必要的。
// Use the expression function to generate NDVI.
var ndvi3 = LS8_SR2.expression("(nir - red) / (nir+red)", {
"nir" : nir,
"red" : red }
)
Map.addLayer(ndvi3, {max: 0.66 , min: -0.23},'NDVI3',false);
生成索引的三种不同方法的相同 NDVI 值 该图像以内布拉斯加州奥加拉拉镇为中心。中心的黑暗特征是麦康纳湖。
如果你比较三个 NDVI 图像,你会发现它们都是一样的;到同一终点的不同路线。您使用什么方法取决于您拥有的数据集以及您尝试创建的索引。那里有数百种选择。索引数据库是一个很好的参考,可以了解每个特定传感器索引数据库的可能性。
4.1改变位置
回顾使用 GRACE 传感器创建的地下水地图的变化(见下图),让我们快速将我们的指数应用于地下水资源严重枯竭的新区域,看看我们是否可以发现一些灌溉农业。
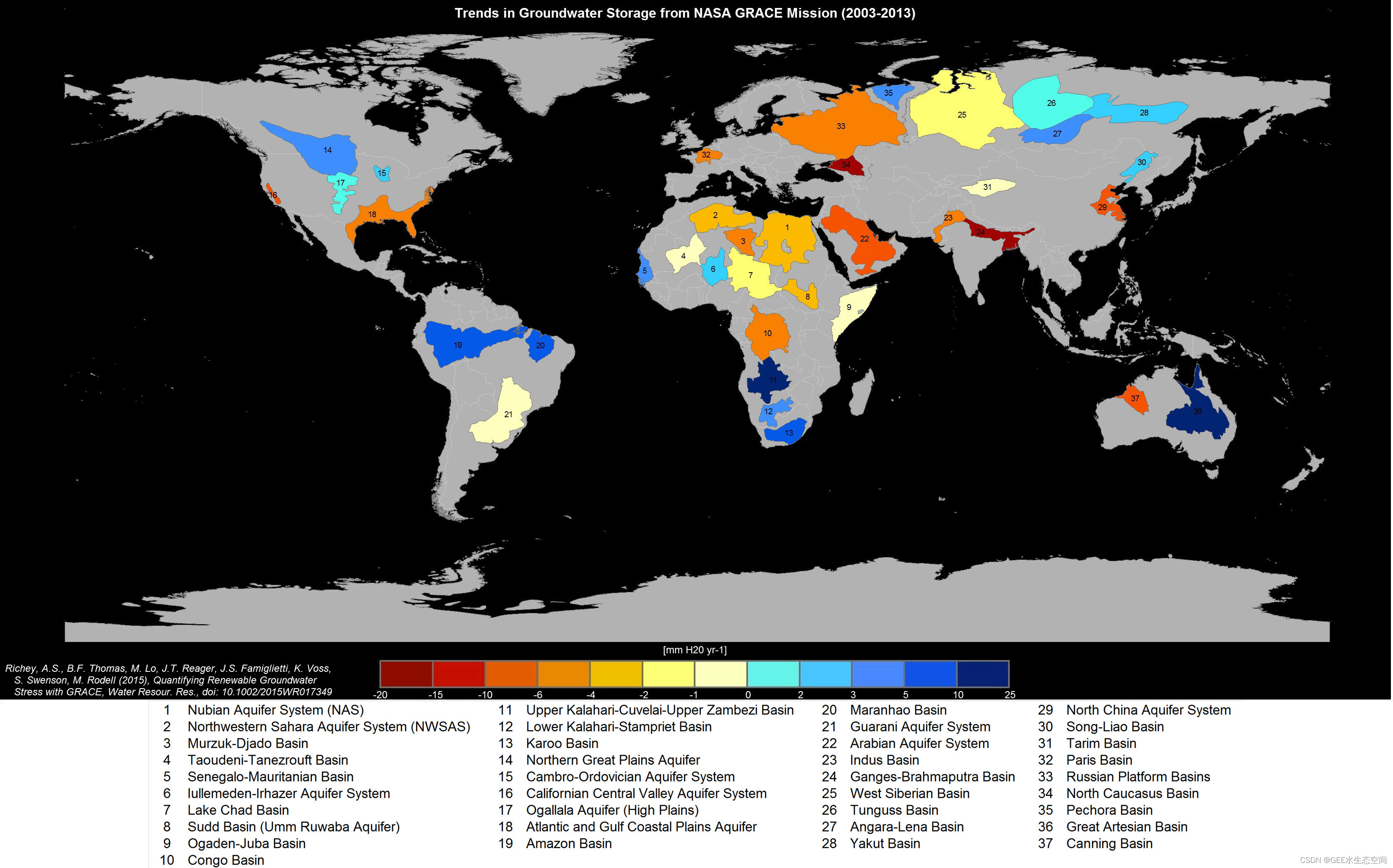
红色区域代表过去 20 年含水层的测量减少。
要更改感兴趣的区域,您也可以。
- 删除当前几何特征并绘制一个新的。
或者
- 向现有几何图层添加第二个特征。
我们会选择第二个。
在几何导入下拉框中选择几何图层。选择后,功能名称应显示为粗体。然后,您可以在阿拉伯半岛上绘制一个新框并单击运行。
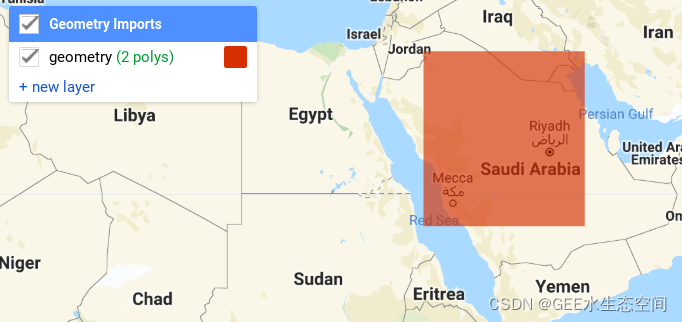
在阿拉伯半岛上增加了新的几何特征,该地区的地下水供应量正在大幅下降。
结果很明显。大部分景观已转变为中心枢纽灌溉农业。在沙漠生态系统中,毫无疑问,这种农业用水来自地下水。不幸的是,在这种情况下,地下水没有得到补充。与所有不可再生资源一样,这种丰富的时期不会持续。

确定的大面积灌溉农业使用了遥感数据。这张图片位于沙特阿拉伯的 Al Huwayd 市附近。
5结论
通过这个模块,我们对与灌溉土地相关的多个数据集进行了比较。涉及各种图像和图像集合的过滤和操作的概念可以应用于广泛的过程。利用或生成自己的指数的过程是在 GEE 内进行更多定量分析的第一步。
5.1模块最终代码
// Call in image by unique ID.
var bioClim = ee.Image("WORLDCLIM/V1/BIO");
print(bioClim, "bioClim");
// Select specific band, clip to region of interest, and rename.
var precip = bioClim
.select("bio12")
.clip(geometry)
.rename("precip");
Map.addLayer(precip, {min:240 , max:1300}, "precip", false);
// Call in collection base on unique ID and print.
var crops = ee.ImageCollection("USDA/NASS/CDL");
print(crops, "crops");
// Filter collection by a date range and pull a specific image from the collection.
var crop2016 = crops
.filterDate("2016-01-01","2016-12-30")
.select(['cropland']);
print(crop2016, "crop2016");
// Call the specific image by the unique ID, select band of interest, and clip to region of interest.
var cropType2016 = ee.Image("USDA/NASS/CDL/2016")
.select("cropland")
.clip(geometry);
print(cropType2016, "cropType2016");
Map.addLayer(cropType2016, {}, "cropType2016", false);
// Evapotranspiration: call in image collection by unique ID and print to understand data structure.
var et = ee.ImageCollection("MODIS/006/MOD16A2")
.filterBounds(geometry);
print(et, "modisET");
// Filter by data, select band, apply reducer to get single image and clip image.
var et2 = et
.filterDate("2016-07-01","2016-09-30")
.select(['ET'])
.median()
.clip(geometry);
Map.addLayer(et2, {max: 357.18 , min: 29.82}, "evapotransparation", false);
// Gross Primary Productivity.
var GPP = ee.ImageCollection("UMT/NTSG/v2/MODIS/GPP");
print(GPP, "modisGPP");
var GPP2 = GPP
.filterDate("2016-07-01","2016-09-30")
.select(['GPP'])
.median()
.clip(geometry);
Map.addLayer(GPP2, {max: 1038.5 , min: 174.5}, "gross Primary Productivity", false);
// Pulling in NDVI data.
var LS8NDVI = ee.ImageCollection("LANDSAT/LC8_L1T_32DAY_NDVI");
print(LS8NDVI, "ls8NDVI");
// Filter, reduce, then clip.
var LS8NDVI2 = LS8NDVI
.filterDate("2016-07-01","2016-09-30")
.median()
.clip(geometry);
Map.addLayer(LS8NDVI2, {max: 0.66 , min: -0.23}, "NDVI", false);
// Call in Landsat 8 surface reflectance Image Collection, filter by region and cloud cover, and reduce to single image.
var LS8_SR2 = ee.ImageCollection("LANDSAT/LC08/C01/T1_SR")
.filterDate("2017-07-01","2017-09-30")
.filterBounds(geometry)
.filterMetadata('CLOUD_COVER', 'less_than', 20)
.median();
print(LS8_SR2,'LS8_SR2');
// Pull bands from the LS8 image and save them as images.
var red = LS8_SR2.select('B4').rename("red");
var nir = LS8_SR2.select('B5').rename("nir");
print(red);
// Generate NDVI based on predefined bands.
var ndvi1 = nir.subtract(red).divide(nir.add(red)).rename('ndvi');
Map.addLayer(ndvi1, {max: 0.66 , min: -0.23},'NDVI1',false);
// Define LS8 NDVI using built in normalized difference function.
var ndvi2 = LS8_SR2.normalizedDifference(['B5', 'B4']);
Map.addLayer(ndvi2, {max: 0.66 , min: -0.23},'NDVI2',false);
// Use the expression function to generate NDVI.
var ndvi3 = LS8_SR2.expression("(nir - red) / (nir+red)", {
"nir" : nir,
"red" : red }
)
Map.addLayer(ndvi3, {max: 0.66 , min: -0.23},'NDVI3',false);















 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









