







1.RDD设计背景
在实际应用中,存在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。虽然,类似Pregel等图计算框架也是将结果保存在内存当中,但是,这些框架只能支持一些特定的计算模式,并没有提供一种通用的数据抽象。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
2.RDD概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为RDD的功能很受限、不够强大。但是,实际上RDD已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(比如MapReduce、SQL、Pregel等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
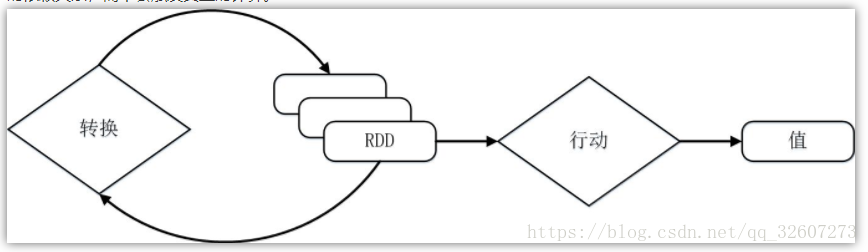
需要说明的是,RDD采用了惰性机制,即在RDD的执行过程中(如图1所示),真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
图1: Spark的转换和行动操作
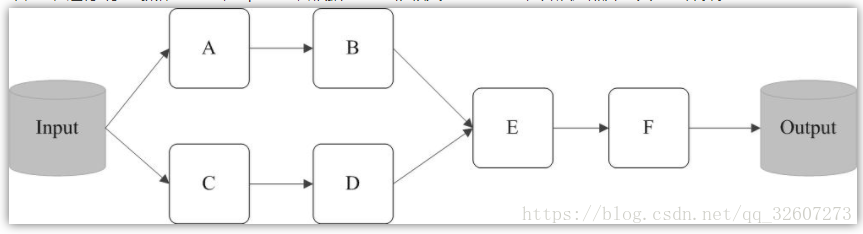
例如,在图2中,从输入中逻辑上生成A和C两个RDD,经过一系列“转换”操作,逻辑上生成了F(也是一个RDD),之所以说是逻辑上,是因为这时候计算并没有发生,Spark只是记录了RDD之间的生成和依赖关系。当F要进行输出时,也就是当F进行“行动”操作的时候,Spark才会根据RDD的依赖关系生成DAG,并从起点开始真正的计算。
图2: RDD执行过程的一个实例
上述这一系列处理称为一个“血缘关系(Lineage)”,即DAG拓扑排序的结果。采用惰性调用,通过血缘关系连接起来的一系列RDD操作就可以实现管道化(pipeline),避免了多次转换操作之间数据同步的等待,而且不用担心有过多的中间数据,因为这些具有血缘关系的操作都管道化了,一个操作得到的结果不需要保存为中间数据,而是直接管道式地流入到下一个操作进行处理。同时,这种通过血缘关系把一系列操作进行管道化连接的设计方式,也使得管道中每次操作的计算变得相对简单,保证了每个操作在处理逻辑上的单一性;相反,在MapReduce的设计中,为了尽可能地减少MapReduce过程,在单个MapReduce中会写入过多复杂的逻辑。例1:一个Spark的“Hello World”程序
这里以一个“Hello World”入门级Spark程序来解释RDD执行过程,这个程序的功能是读取一个HDFS文件,计算出包含字符串“Hello World”的行数。启动pyspark
PYSPARK_PYTHON=python3 ./bin/pysparkSpark 2.1.0仅支持Python 2.7+/3.4+的版本。本人使用的是Python 3.6版本。在Ubuntu 16.04中已经自带了Python 3.5,就不用再安装Python.如果你的系统中仍未安装好Python 3.4以上的版本,请安装Python 3.4以上的版本
在pyspark的交互环境下,输入如下代码
fileRDD = sc.textFile('hdfs://localhost:9000/test.txt') def contains(line): ... return 'hello world' in line filterRDD = fileRDD.filter(contains) filterRDD.cache() filterRDD.count()可以看出,一个Spark应用程序,基本是基于RDD的一系列计算操作。第1行代码从HDFS文件中读取数据创建一个RDD;第2、3行定义一个过滤函数;第4行代码对fileRDD进行转换操作得到一个新的RDD,即filterRDD;第5行代码表示对filterRDD进行持久化,把它保存在内存或磁盘中(这里采用cache接口把数据集保存在内存中),方便后续重复使用。当数据被反复访问时(比如查询一些热点数据,或者运行迭代算法),这是非常有用的,而且通过cache()可以缓存非常大的数据集,支持跨越几十甚至上百个节点;第6行代码中的count()是一个行动操作,用于计算一个RDD集合中包含的元素个数。这个程序的执行过程如下:
- 创建这个Spark程序的执行上下文,即创建SparkContext对象;
- 从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
- 构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
- 执行到第6行代码时,count()是一个行动类型的操作,触发真正的计算,开始实际执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
3.RDD特性
总体而言,Spark采用RDD以后能够实现高效计算的主要原因如下:
(1)高效的容错性。现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。在RDD的设计中,数据只读,不可修改,如果需要修改数据,必须从父RDD转换到子RDD,由此在不同RDD之间建立了血缘关系。所以,RDD是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需通过RDD父子依赖(血缘)关系重新计算得到丢失的分区来实现容错,无需回滚整个系统,这样就避免了数据复制的高开销,而且重算过程可以在不同节点之间并行进行,实现了高效的容错。此外,RDD提供的转换操作都是一些粗粒度的操作(比如map、filter和join),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据项进行了修改),这就大大降低了数据密集型应用中的容错开销;
(2)中间结果持久化到内存。数据在内存中的多个RDD操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销;
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化开销。
4. RDD之间的依赖关系
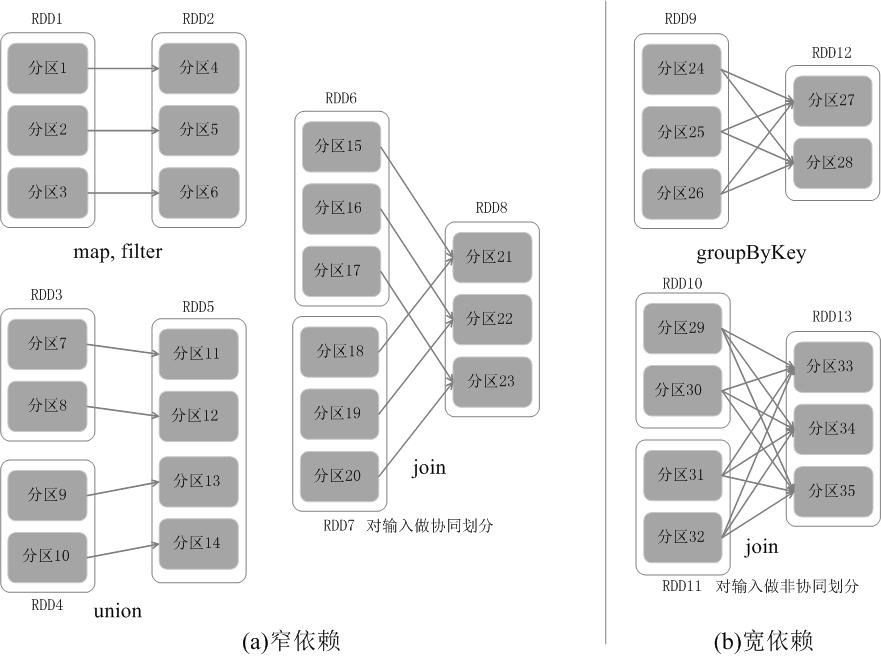
RDD中不同的操作会使得不同RDD中的分区会产生不同的依赖。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),图3展示了两种依赖之间的区别。
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;比如图3(a)中,RDD1是RDD2的父RDD,RDD2是子RDD,RDD1的分区1,对应于RDD2的一个分区(即分区4);再比如,RDD6和RDD7都是RDD8的父RDD,RDD6中的分区(分区15)和RDD7中的分区(分区18),两者都对应于RDD8中的一个分区(分区21)。
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。比如图3(b)中,RDD9是RDD12的父RDD,RDD9中的分区24对应了RDD12中的两个分区(即分区27和分区28)。
总体而言,如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。窄依赖典型的操作包括map、filter、union等,宽依赖典型的操作包括groupByKey、sortByKey等。对于连接(join)操作,可以分为两种情况。
(1)对输入进行协同划分,属于窄依赖(如图(a)所示)。所谓协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖,如图(b)所示。
对于窄依赖的RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的RDD,则通常伴随着Shuffle操作,即首先需要计算好所有父分区数据,然后在节点之间进行Shuffle。
图3 窄依赖与宽依赖的区别
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其它RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
5.RDD运行过程
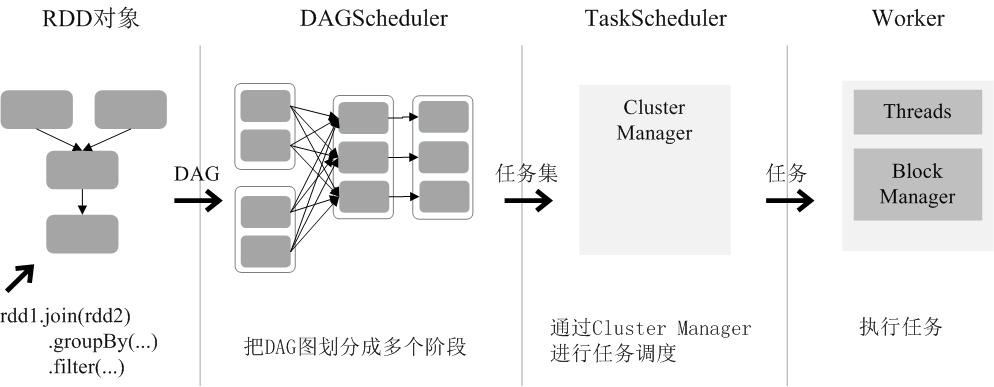
通过上述对RDD概念、依赖关系和阶段划分的介绍,结合之前介绍的Spark运行基本流程,这里再总结一下RDD在Spark架构中的运行过程(如图9-12所示):
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
6.RDD创建
RDD可以通过两种方式创建:
* 第一种:读取一个外部数据集。比如,从本地文件加载数据集,或者从HDFS文件系统、HBase、Cassandra、Amazon S3等外部数据源中加载数据集。Spark可以支持文本文件、SequenceFile文件(Hadoop提供的 SequenceFile是一个由二进制序列化过的key/value的字节流组成的文本存储文件)和其他符合Hadoop InputFormat格式的文件。
* 第二种:调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。从文件系统中加载数据创建RDD
Spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URI作为参数,这个URI可以是本地文件系统的地址,或者是分布式文件系统HDFS的地址,或者是Amazon S3的地址等等。
下面请切换回pyspark窗口,看一下如何从本地文件系统中加载数据:>>> lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")下面看一下如何从HDFS文件系统中加载数据,把刚才在本地文件系统中的“/usr/local/spark/mycode/rdd/word.txt”上传到HDFS文件系统的hadoop用户目录下。然后,在pyspark窗口中,就可以使用下面任意一条命令完成从HDFS文件系统中加载数据:
>>> lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt") >>> lines = sc.textFile("/user/hadoop/word.txt") >>> lines = sc.textFile("word.txt")注意,上面三条命令是完全等价的命令,只不过使用了不同的目录形式,你可以使用其中任意一条命令完成数据加载操作。
在使用Spark读取文件时,需要说明以下几点:
(1)如果使用了本地文件系统的路径,那么,必须要保证在所有的worker节点上,也都能够采用相同的路径访问到该文件,比如,可以把该文件拷贝到每个worker节点上,或者也可以使用网络挂载共享文件系统。
(2)textFile()方法的输入参数,可以是文件名,也可以是目录,也可以是压缩文件等。比如,textFile(“/my/directory”), textFile(“/my/directory/.txt”), and textFile(“/my/directory/.gz”).
(3)textFile()方法也可以接受第2个输入参数(可选),用来指定分区的数目。默认情况下,Spark会为HDFS的每个block创建一个分区(HDFS中每个block默认是128MB)。你也可以提供一个比block数量更大的值作为分区数目,但是,你不能提供一个小于block数量的值作为分区数目。通过并行集合(数组)创建RDD
可以调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。
下面请在pyspark中操作:>>> nums = [1,2,3,4,5] >>> rdd = sc.parallelize(nums)上面使用列表来创建。在Python中并没有数组这个基本数据类型,为了便于理解,你可以把列表当成其他语言的数组。
7.RDD操作
RDD被创建好以后,在后续使用过程中一般会发生两种操作:
* 转换(Transformation): 基于现有的数据集创建一个新的数据集。
* 行动(Action):在数据集上进行运算,返回计算值。转换操作
对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用。转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。
下面列出一些常见的转换操作(Transformation API):
* filter(func):筛选出满足函数func的元素,并返回一个新的数据集
* map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集
* flatMap(func):与map()相似,但每个输入元素都可以映射到0或多个输出结果
* groupByKey():应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集
* reduceByKey(func):应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合行动操作
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
下面列出一些常见的行动操作(Action API):
* count() 返回数据集中的元素个数
* collect() 以数组的形式返回数据集中的所有元素
* first() 返回数据集中的第一个元素
* take(n) 以数组的形式返回数据集中的前n个元素
* reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
* foreach(func) 将数据集中的每个元素传递到函数func中运行*下面是RDD的基础操作API介绍:
操作类型
函数名
作用
转化操作
map()
参数是函数,函数应用于RDD每一个元素,返回值是新的RDD
flatMap()
参数是函数,函数应用于RDD每一个元素,将元素数据进行拆分,变成迭代器,返回值是新的RDD
filter()
参数是函数,函数会过滤掉不符合条件的元素,返回值是新的RDD
distinct()
没有参数,将RDD里的元素进行去重操作
union()
参数是RDD,生成包含两个RDD所有元素的新RDD
intersection()
参数是RDD,求出两个RDD的共同元素
subtract()
参数是RDD,将原RDD里和参数RDD里相同的元素去掉
cartesian()
参数是RDD,求两个RDD的笛卡儿积
行动操作
collect()
返回RDD所有元素
count()
RDD里元素个数
countByValue()
各元素在RDD中出现次数
reduce()
并行整合所有RDD数据,例如求和操作
fold(0)(func)
和reduce功能一样,不过fold带有初始值
aggregate(0)(seqOp,combop)
和reduce功能一样,但是返回的RDD数据类型和原RDD不一样
foreach(func)
对RDD每个元素都是使用特定函数














 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









