







作者:翁松秀
Windows系统下搭建Spark开发环境三步曲,简单粗暴,走你┏ (゜ω゜)=☞
[TOC]
Step1:安装Spark
到官网http://spark.apache.org/downloads.html选择相应版本,下载安装包。我这里下的是2.1.3版本,后面安装的Hadoop版本需要跟Spark版本对应。下载后找个合适的文件夹解压即可。我是新建了一个home文件夹,底下放了三个文件夹,分别是spark, hadoop, scala。
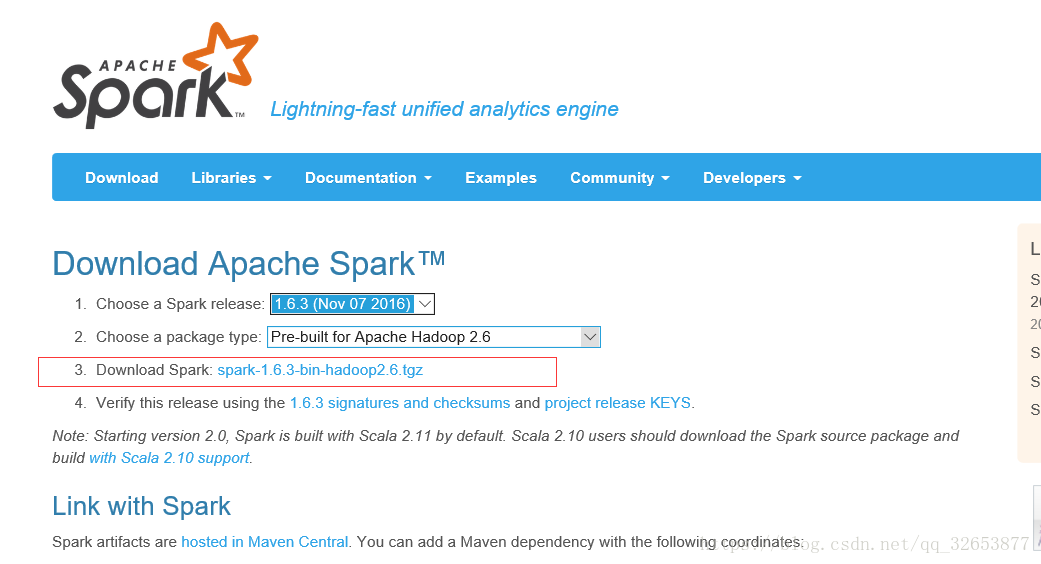
解压之后配置环境变量,将Spark底下的bin文件所在的目录添加到环境变量的Path变量中,后面Hadoop也一样。

然后打开cmd进行测试,输入spark-shell,如果出现如下的”Spark”说明安装成功。
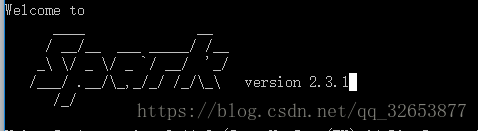
OK, Welcome to Spark!
Step2: 安装Hadoop
到http://mirrors.hust.edu.cn/apache/hadoop/common/下载相应版本的Hadoop安装包,我下的是2.7.7。具体的Spark和Hadoop版本对应可以到网上查,Spark和Hadoop版本不一致可能会导致出问题。
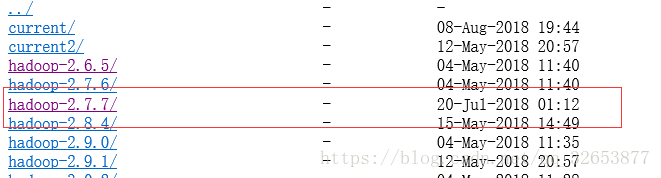
将下载好的安装好进行解压,然后将Hadoop底下的bin目录配置到Path变量中。
为了防止运行程序的时候出现nullpoint异常,到github下载hadoop.dll和winutils.exe 下载地址:https://github.com/steveloughran/winutils
找到对应的hadoop版本,然后进入bin目录下,下载hadoop.dll和winutils.exe, 然后复制到所安装hadoop目录下。
到官网https://www.scala-lang.org/download/下载镜像,然后安装即可。一般默认会自动配置好环境变量。安装好之后打开cmd测试,输入scala,如果出现以下内容则安装成功。

如果没有成功,检查一下Path环境变量,如果安装之后没有自动配置,则手动配置,参照Spark的环境配置。
Step3: 安装IDEA
Spark开发有两种方式,一种是用内置的spark-shell,另一种是独立应用开发,独立应用开发支持的语言有Java、Scala、Python和R语言。如果采用Java语言进行Spark开发,需要配置Maven,最新版的Eclipse和IntelliJ都内置Maven,所以采用Eclipse和IntelliJ来开发Spark是比较方便的。
IntelliJ安装参考教程
https://blog.csdn.net/qq_35246620/article/details/61200815
Eclipse安装参考教程
https://jingyan.baidu.com/article/d7130635194f1513fcf47557.html


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











