









课程内容
阿里巴巴Arthas介绍
你是否遇到过如下生产问题?
- 怎么貌似我的代码没有更新成功呢?这跑的真是我的代码吗?
- 奇怪了,为什么接口会返回这个内容?应该是返回那个的才对的呀
- 这个调用从哪里出去了,一点日志都没有
- 这个类的成员变量的值是什么
- … …
告诉大家一个好消息,上面这些个问题,arthas都能解决,而且入门不难(精通难)
- 介绍:Arthas 是 Alibaba 在 2018 年 9 月开源的 Java 诊断工具。支持 JDK6+, 采用命令行交互模式,可以方便的定位和诊断线上程序运行问题。Arthas 官方文档十分详细,详见:Arthas
- 使用:下载,启动,挂载,即可。(建议直接看上面的Arthas官方链接,然后看【快速开始】,就是这么快 [狗头][狗头])
接下来是卖家秀时间(别误会,Arthas目前是不收费的)
- jad:jad + 类全名,反编译源码。解决第1个“代码没有更新”问题
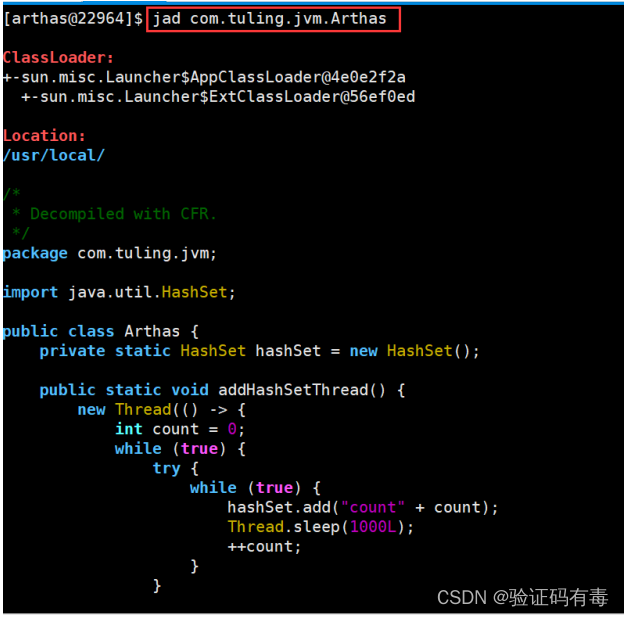
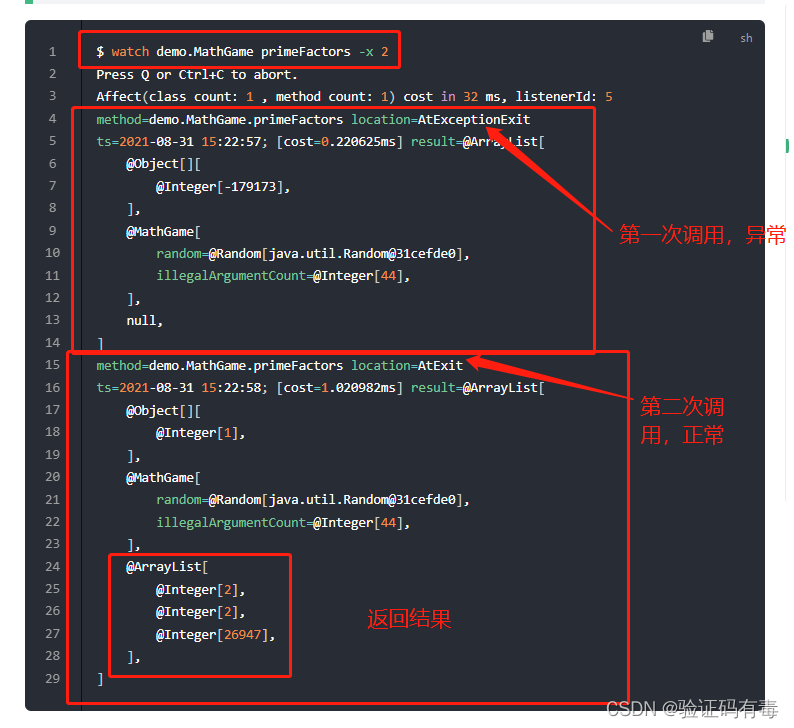
- 使用watch命令,查看当前方法的请求、返回情况。解决第2个“接口返回内容不对”问题
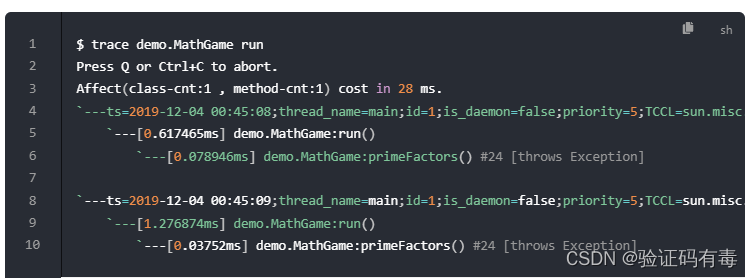
- trace:方法内部调用路径,并输出方法路径上的每个节点上耗时。解决第3个“调用不知道从哪里走了”的问题
- ognl表达式:查看某个类的成员变量。解决第4个“类的成员变量的值是什么”的问题(由于只能看静态变量,所以在Spring下想要查看非静态变量,只能绕绕圈子基于SpringUtil工具来看了)
[arthas@71175]$ ognl '@com.jvm.tuling.arthas.ApplicationUtil@getBean("user").id'
@Integer[58]
[arthas@71175]$ ognl '@com.jvm.tuling.arthas.ApplicationUtil@getBean("user").name'
@String[zhangshen]
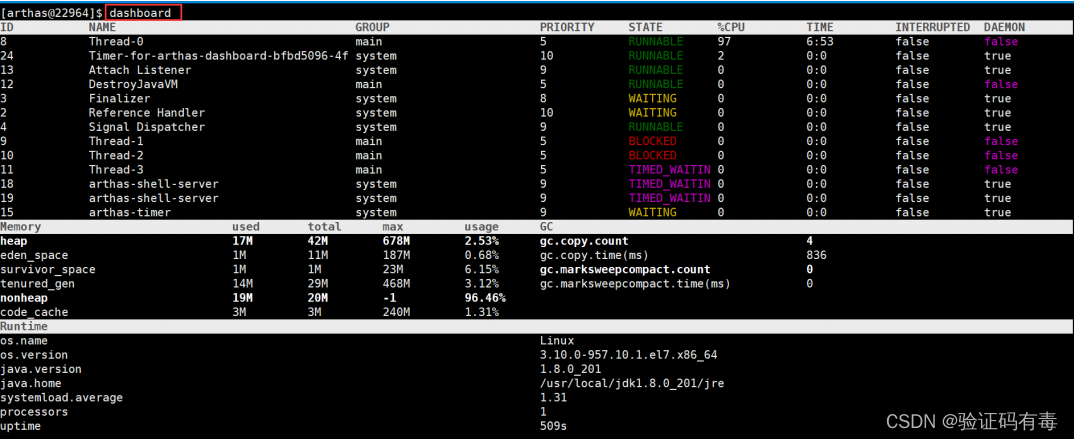
- dashboard:该命令可以查看整个进程的运行情况,线程、内存、GC、运行环境信息(集top -p转H、jstat -gc)
- thread:该命令有点像是jstack命令,输入thread [线程id]可以查看线程堆栈

或者thread -n 3 -i [取样时间],相当于top -H -p ,列出 1000ms 内最忙的 3 个线程栈
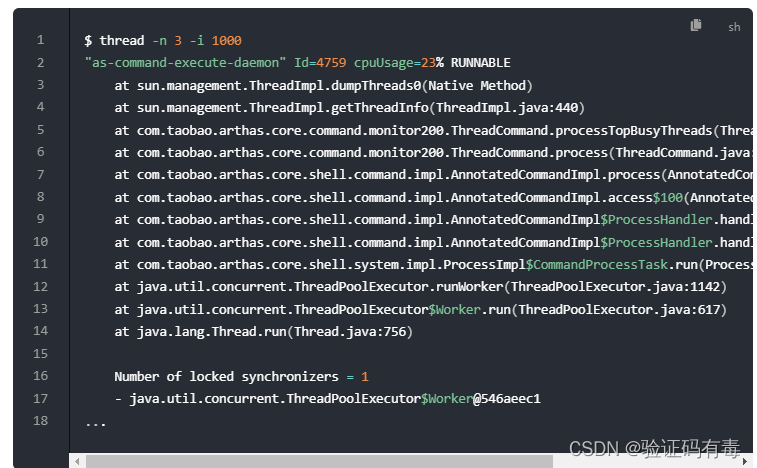
或者通过thread -b查看当前进程的死锁情况

GC日志详解
对于java应用我们可以通过一些配置把程序运行过程中的gc日志全部打印出来,然后分析gc日志得到关键性指标,分析GC原因,调优JVM参数。打印GC日志方法,在JVM参数里增加参数,%t 代表时间。下面是一个打印gc日志的简单JVM参数配置:
‐Xloggc:./gc‐%t.log ‐XX:+PrintGCDetails ‐XX:+PrintGCDateStamps ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCCause ‐XX:+UseGCLogFileRotation ‐XX:NumberOfGCLogFiles=10 ‐XX:GCLogFileSize=100M
下图是一段JVM刚启动时截取的一些日志,大家看个热闹,起码对jdk8默认的ParallelGC有一个简单的认识:
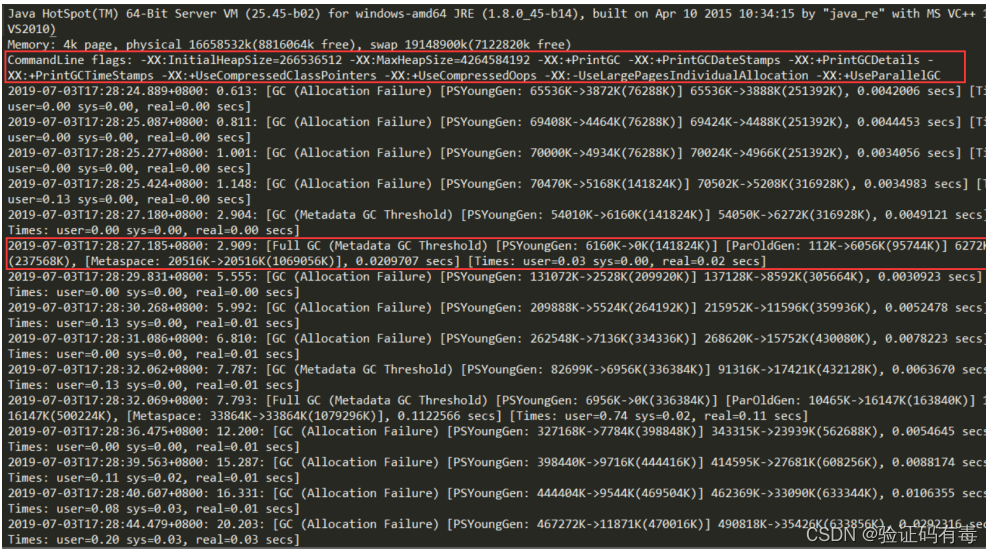
图中第一个红框,是项目的配置参数,即我们在启动时显式设置的JVM参数
图中的第二个红框,是一个GC时间点发生的GC相关情况
- 2019-07-03T17:28:27.185:日志记录时间
- 2.909:这是JVM从启动开始到本次GC经过的时间
- Full GC(Metadata GC Threshold):表明了本次GC类型为Full GC,括号里的则是GC原因。是年轻代的GC,ParOldGen是老年代的GC,Metaspace是元空间的GC
- [PSYoungGen:6160K->0K(141824K)]:分别表示GC之前占用年轻代的大小,GC之后年轻代占用,以及整个年轻代的大小
- [ParOldGen:112K->6056K(95744K)]:分别表示GC之前占用老年代的大小,GC之后老年代占用,以及整个老年代的大小
- 6272K->6056K(237568K),这三个数字分别对应GC之前占用堆内存的大小,GC之后堆内存占用,以及整个堆内存的大小
- [Metaspace:20516K->20516K(1069056K)],这三个数字分别对应GC之前占用元空间内存的大小,GC之后元空间内存占用,以及整个元空间内存的大小
- 0.0209707是该时间点GC总耗费时间
比如从上面这张图片,我们可以观察到,几次FullGC都是因为元空间内存不足导致的,所以我们可以适当调整一下: ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M(正常我们可以这么设置)
PS:事实上,线上的GC环境会更恶劣,GC日志成千上百万行,你不可能肉眼去看,所以一般推荐找一些诸如gceasy的GC可视化分析工具。
Class常量池与运行时常量池
Class常量池,可以简单的理解为是class文件中的资源仓库。我们知道,class文件除了包含类的版本、字段、方法、接口等描述信息(元信息)以外,还有一项信息就是常量池(Constant Pool Table),用与存放编译期间生成的各种字面量和符号引用。
话都说到这里了,那什么是字面量跟符号引用呢?
- 字面量:字面量就是指由字母、数字等构成的字符串或者数值常量。注意:字面量只能是等号的右值,如下(1,zhangshen,就是右值)
int a = 1;
String b = "zhangshen";
- 符号引用:符号引用是编译原理中的概念,是相对于直接引用来说的。主要包括了以下【类和接口的全限定名】、【字段的名称和描述符】、【方法的名称和描述符】等常量。基本可以这么认为:Xxx.java文件内的,所有我们编写的内容皆符号。
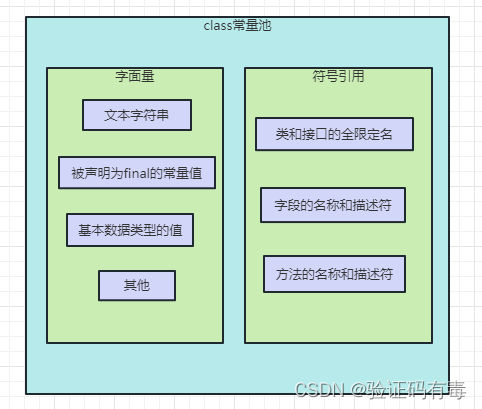
这些常量池现在是静态的信息,只有运行时加载到内存后,这些符号才会有对应的内存地址信息,也随之变成了运行时常量池,对应的符号引用在程序加载或者运行时,会被转变为被加载到内存区域的代码的直接引用,这个过程就是所谓的动态链接了。例如:compute()这个符号引用在运行时就会被转变为compute()方法具体代码在内存中的地址。主要是通过对象头里的类型指针去转换直接引用
字符串常量池
字符串常量池,顾名思义就是用来存储字符串常量的池子。凡是“XXX池”,几乎都可以认为是用来做缓存提升性能的。这里也不例外,设计思想如下:
- 由于字符串的分配,和普通对象一样,会耗费高昂的时间和空间代价(相对)。然而,在我们的日常开发中,String类型又是一种最为频繁使用到的数据类型,而大量频繁地创建字符串,势必会影响性能
- 于是JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。大概的思路是:开辟一个字符串常量池做缓存;创建字符串常量时,先查询字符串常量池中有没有;存在,则直接返回引用,反之,则是实例化一个新的字符串,并且将这个新的字符串放入到池子中,以便于下次使用时,直接拿来用,这就是缓存嘛(后续我将这一系列操作叫做:维护字符串常量池)
下面我们用一些例子给大家展示一下(JDK1.7以上)
- 直接赋值字符串
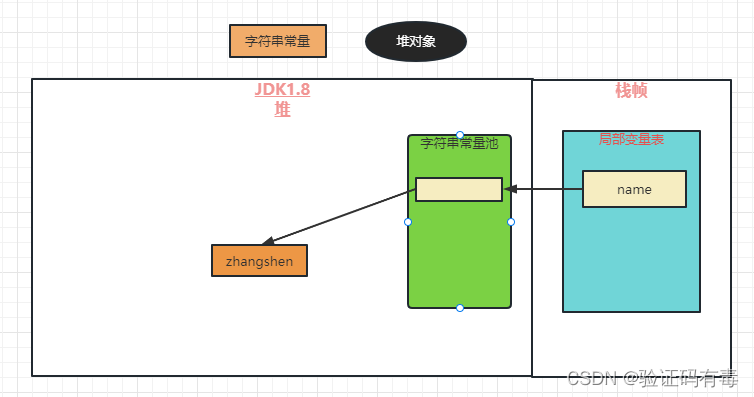
String name = "zhangshen";
上面这种方式创建字符串对象,只会在常量池中。 name指向的是常量池中“zhangshen”的引用
它的创建流程是:先在池中,通过字符串的equals方法,找是否有相同的字符串,有则返回,无则创建新的实例,并放入到池子中,然后返回这个新的实例的引用
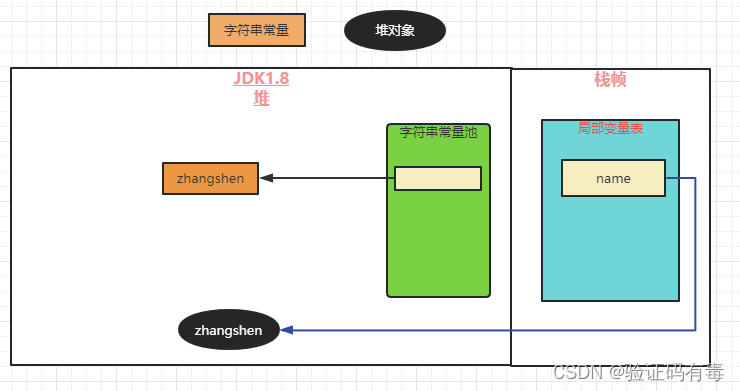
- new String()的方式创建字符串
String name = new String("zhangshen");
还记得吧,我们说过凡是new出来的,都会在堆里面创建一个对象(不考虑栈上分配的机制)。然后上面咱又说了,JVM对字符串做了点优化,即:维护字符串常量池。所以,上面这个方式,会在字符串常量池中和堆内存中都创建对象,最后返回的是堆对象的引用。它的大致流程化如下:
1.因为显式存在"zhangshen"这个字面量,所以会先检查字符串常量池中是否存在字符串常量"zhangshen"
2.如果不存在,就要先在字符串常量池中创建这么一个字符串常量,再然后才会去堆中创建一个字符串对象“zhangshen”
3.如果存在,则只需要去堆中创建一个字符串对象“zhangshen”
4.最后返回堆中对象的引用
总结一下,为什么要有这么一个流程呢?缓存啊亲们 [狗头][狗头]
- intern方法创建字符串
String name = new String("zhangshen");
String son = name.intern();
System.out.println(name == son); // 输出false
String的intern方法是一个native方法。当调用intern方法时,如果池中已经包含一个等于此String对象字符串的内容(即:equals==true时),则返回池中字符串的引用。否则,将intern返回的引用指向当前字符串name(JDK1.6之前还需要将name复制到字符串常量池)
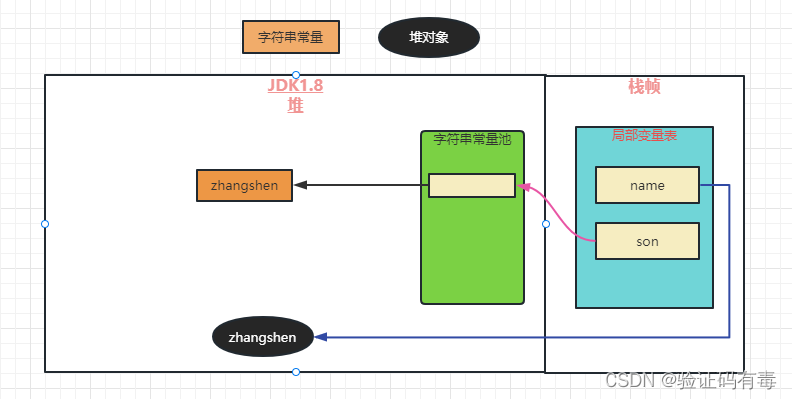
我们做个小总结吧,根据上面的结果,我们可以总结出以下规律:
1.显式出现的字面量,会在字符串常量池中生成对应的字符串
2.显示出现的new,则会在堆中生成对应的对象实例
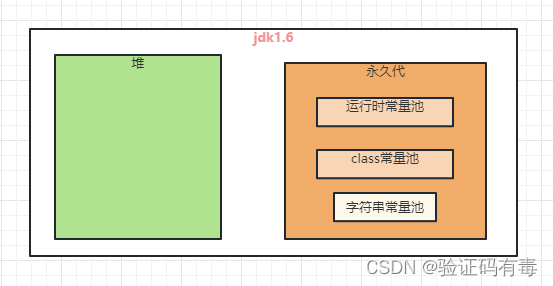
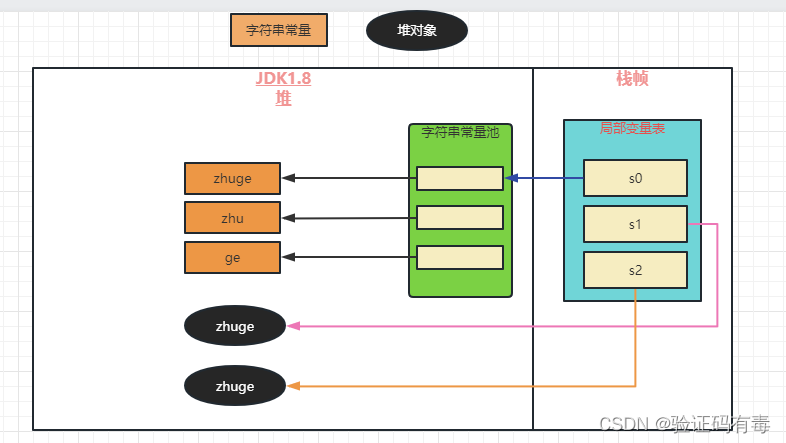
值得注意的是,上面的例子,是建立在jdk1.8上的。在此之前,字符串常量池的位置,是不一样的。主要区别如下图:
jdk1.6时代:常量池存在于永久代中
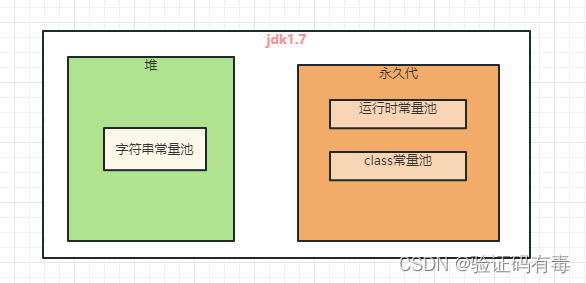
jdk1.7时代:主间去永久代,字符串常量池从运行时常量池中分离到堆中
jdk1.8时代:去掉了永久代的概念,转而新增了“方法区/元空间”,字符串常量池还是在堆中

另外,也有一种说法是,元空间其实是在直接内存中,不再存在于JVM中了
字符串常量池设计原理
字符串常量池底层是hotspot的C++实现的,底层类似一个 HashTable, 保存的本质上是字符串对象的引用。看一道比较常见的面试题,下面的代码创建了多少个 String 对象?
String s1 = new String("he") + new String("llo");
// 上述代码本质上是:new StringBuilder().append(new String("he")).append(new String("llo"))
String s2 = s1.intern();
System.out.println(s1 == s2);
// 在jdk1.6中,这里输出false,总共会创建6个对象
// 在jdk1.7及以上,这里输出true,总共会创建5个对象
上面的输出为什么会有差异?这主要跟jdk版本的不同,字符串常量池的变化有关,最重要的,还是因为String的intern()方法也改变了。
- intern方法改变前:首先会在字符串常量池中通过equals方法查找相等的字符串,如果有,则返回该字符串在常量池中的引用;如果没有,则需要先在永久代上创建该字符串实例,再然后才返回该新的实例在字符串常量池中的引用。
- intern方法改变后:首先会在字符串常量池中通过equals方法查找相等的字符串,如果有,则返回该字符串在常量池中的引用;如果没有,则可以直接新建一个,字符串常量池指向堆上实例的引用
上述区别的图示如下:
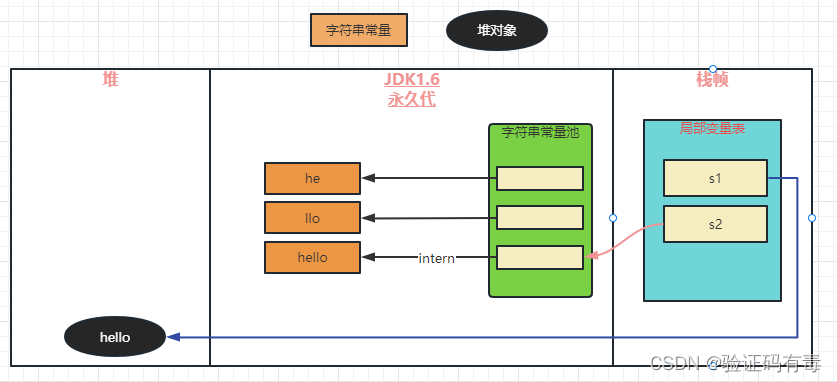

由上面两个图,也不难理解为什么 JDK 1.6 字符串池溢出会抛出 OutOfMemoryError: PermGen space ,而在
JDK 1.7 及以上版本抛出 OutOfMemoryError: Java heap space
String常量池问题的几个例子
- 例1:
String s0 = "zhuge";
String s1 = "zhuge";
String s2 = "zhu" + "ge"; // 这个代码在编译期就会被优化为 "zhuge"
System.out.println( s0==s1 ); //true
System.out.println( s0==s2 ); //true
分析一下:s0/s1都是"zhuge"这个字面量在字符常量池中的引用,所以第一个打印为true没什么疑问。主要是第二行"zhu" + “ge”,由于他们都是字面量,字面量+字面量=另一个字面量,也会在编译期确定,所以s2也是"zhuge"这个字面量在字符常量池中的引用。s0=s1=s2
- 例2:
String s0="zhuge";
String s1=new String("zhuge");
String s2="zhu" + new String("ge");
System.out.println( s0==s1 ); // false
System.out.println( s0==s2 ); // false
System.out.println( s1==s2 ); // false
- 例3:
String a = "a1";
String b = "a" + 1; // 编译期优化:a1
System.out.println(a == b); // true
String a = "atrue";
String b = "a" + "true"; // 编译期优化:atrue
System.out.println(a == b); // true
String a = "a3.4";
String b = "a" + 3.4; // 编译期优化:a3.4
System.out.println(a == b); // true
上面这个没太大疑问,都会通过编译期优化合在一起,所以输出内容都是true
- 例4:
String a = "ab";
String bb = "b";
String b = "a" + bb;
System.out.println(a == b); // false
分析:由于在字符串的"+“连接中,有字符串引用存在bb,而引用的值在程序编译期是无法确定的,即"a” + bb无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给b。所以上面程序的结果也就为false
- 例5:
String a = "ab";
final String bb = "b";
String b = "a" + bb;
System.out.println(a == b); // true
分析:上面这个就有意思多了,看上去跟例4一样,但是由于bb字段+了final修饰,所以会在编译期被当作常量处理。所以"a" + bb相当于"a" + “b”,最后结果为true
- 例6:
String a = "ab";
final String bb = getBB();
String b = "a" + bb;
System.out.println(a == b); // false
private static String getBB()
{
return "b";
}
分析:JVM对于字符串引用bb,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和"a"来动态连接并分配地址为b,故上面 程序的结果为false
- 例7:终极例子
// 字符串常量池:"计算机"和"技术" 堆内存:str1引用的对象"计算机技术"
// 堆内存中还有个StringBuilder的对象,但是会被gc回收,StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用
String str2 = new StringBuilder("计算机").append("技术").toString(); // 没有出现"计算机技术"字面量,所以不会在常量池里生成"计算机技术"对象
System.out.println(str2 == str2.intern()); // true
// "计算机技术" 在池中没有,但是在heap中存在,则intern时,会直接返回该heap中的引用
// 字符串常量池:"ja"和"va" 堆内存:str1引用的对象"java"
// 堆内存中还有个StringBuilder的对象,但是会被gc回收,StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用
String str1 = new StringBuilder("ja").append("va").toString(); // 没有出现"java"字面量,所以不会在常量池里生成"java"对象
System.out.println(str1 == str1.intern()); //false
// java是关键字,在JVM初始化的相关类里肯定早就放进字符串常量池了
String s1=new String("test");
System.out.println(s1==s1.intern()); //false
// "test"作为字面量,放入了池中,而new时s1指向的是heap中新生成的string对象,s1.intern()指向的是"test"字面量之前在池中生成的字符串对象
String s2=new StringBuilder("abc").toString();
System.out.println(s2==s2.intern()); //false
// 同上
八种基本类型的包装类和对象池
Java中基本类型的包装类的大部分都实现了常量池技术(严格来说应该叫对象池,在堆上),这些类是Byte,Short,Integer,Long,Character,Boolean,另外两种浮点数类型的包装类则没有实现。另外Byte,Short,Integer,Long,Character这5种整型的包装类也只是在对应值小于等于127时才可使用对象池,也即对象不负责创建和管理大于127的这些类的对象。因为一般这种比较小的数用到的概率相对较大
public class Test {
public static void main(String[] args) {
//5种整形的包装类Byte,Short,Integer,Long,Character的对象,
//在值小于127时可以使用对象池
Integer i1 = 127; //这种调用底层实际是执行的Integer.valueOf(127),里面用到了IntegerCache对象池
Integer i2 = 127;
System.out.println(i1 == i2);//输出true
//值大于127时,不会从对象池中取对象
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4);//输出false
//用new关键词新生成对象不会使用对象池
Integer i5 = new Integer(127);
Integer i6 = new Integer(127);
System.out.println(i5 == i6);//输出false
//Boolean类也实现了对象池技术
Boolean bool1 = true;
Boolean bool2 = true;
System.out.println(bool1 == bool2);//输出true
//浮点类型的包装类没有实现对象池技术
Double d1 = 1.0;
Double d2 = 1.0;
System.out.println(d1 == d2);//输出false
}
}
学习总结
- 温习了Arthas的基本操作,学会了ongl命令的简单应用
- 学习了jdk8默认的ParallelGC的GC日志详情
- 学习了字符串常量池的设计原理
- 认识了八种基本类型的包装类型和对象池
















 36
36











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











