







1.安装IK中文分词器
IK中文分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载与ES相同的版本,然后解压到es目录 /plugins 文件夹下,然后重命名analysis-ik
然后重新启动ES即可 。
2.kibana操作es rest命令
1.进入菜单页,选择management - devTools 开发工具
2. elasticsearch 几个核心的概念,
| elasticsearch | 对比 | 数据库 |
| INDEX | 相当于 | 数据库 |
| TYPE | 相当于 | 表 |
| ID | 相当于 | 主键 |
一般不使用多个TYPE类型,而是直接新创建一个INDEX。一般TYPE设置为_doc名字。
官方解答:文档元数据 | Elasticsearch: 权威指南 | Elastic
3.操作CURD
操作方式请求
DELETE 删除索引、删除TYPE、删除单条数据
GET 查询索引、查询TYPE、查询单条数据
POST | PUT 更新或创建
格式 : 请求/{index}/{type}/{id}
在kibana 开发工具 输入创建数据命令:
#创建员工1
PUT /employee/_doc/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
#创建员工2
PUT /employee/_doc/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
#创建员工2
PUT /employee/_doc/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
#查询所有员工
GET employee/_search
#查询所有员工,匹配某个字段
GET employee/_search
{
"query": {
"match": {
"first_name": "John"
}
}
}
#查询所有员工,匹配某个字段,值看某个字段_source
GET employee/_search
{
"query": {
"match": {
"first_name": "John"
}
}
, "_source": ["first_name","last_name"]
}
#GET 求情获取 ID = 1 的数据
GET employee/_doc/1
#DELETE 删除ID =1 的数据
DELETE employee/_doc/1
#修改 覆盖形式 但是会直接替换掉其他字段,可以看到interests 字段已经不存在了
POST /employee/_doc/5
{
"first_name" : "test",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets"
}
#修改 只修改某个字段
POST /employee/_doc/5/_update
{
"doc": {
"first_name": "Jane Doe"
}
}
#bool 过滤器命令 match 匹配多个字段 (match标准匹配)
GET employee/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"first_name": "Jane"
}
},
{
"match": {
"age": "35"
}
}
]
}
}
}
#minimum_should_match 标识 should 至少匹配几项
#must 必须匹配
#must_not 必须不匹配
#should 默认情况下,should语句一个都不要求匹配,只有一个特例:如果查询中没有must语句,那么至少要#匹配一个should语句
GET /employee/_search
{
"query": {
"bool": {
"must": {
"match": {
"first_name": "Jane"
}
},
"must_not": {
"match": {
"first_name": "John"
}
},
"should": [
{
"match": {
"first_name": "Jane"
}
},
{
"match": {
"first_name": "Douglas"
}
}
],
"minimum_should_match" : 1
}
}
}
#minimum_should_match 标识 should 至少匹配
GET /employee/_search
{
"query": {
"bool": {
"must": {
"match": {
"first_name": "Jane"
}
},
"must_not": {
"match": {
"first_name": "John"
}
},
"should": [
{
"match": {
"first_name": "Jane"
}
},
{
"match": {
"first_name": "Douglas"
}
}
],
"minimum_should_match" : 1
}
}
}
#term 命令 精准匹配
GET employee/_search
{
"query": {
"term": {
"first_name":"Jane"
}
}
}
# term 和 terms 是 包含(contains) 操作,而非 等值(equals) (判断)
GET employee/_search
{
"query": {
"terms": {
"first_name":["Douglas","Jane"]
}
}
}
#constant_score 查询
#尽管没有 bool 查询使用这么频繁,constant_score 查询也是你工具箱里有用的查询工具。
#它将一个不变的常量评分应用于所有匹配的文档。它被经常用于你只需要执行一个 filter 而没有其它查询。
#term 命令 精准匹配 不评分操作constant_score + filter
GET employee/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"first_name" : "Jane"
}
}
}
}
}
#查询测试
GET employee/_search
{
"query" : {
"bool": {
"should" : [
{ "term" : {"first_name" : "Jane"}},
{ "term" : {"age" : "35"}}
],
"must_not" : {
"term" : {"age" : 2}
}
}
}
}
#创建指定索引类型 1.默认_doc类型
PUT employee
{
"mappings": {
"properties": {
"user": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
或
#2.创建myType类型
PUT employee
{
"mappings": {
"myType": {
"properties": {
"user": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}
中文分词器测试:
#fielddata在text字段中默认未启用
#因为fielddata会消耗大量的堆内存,特别是当加载大量的text字段时;fielddata一旦加载到堆中,在segment的#生命周期之内都将一致保持在堆中,所以谨慎使用
#分词查询
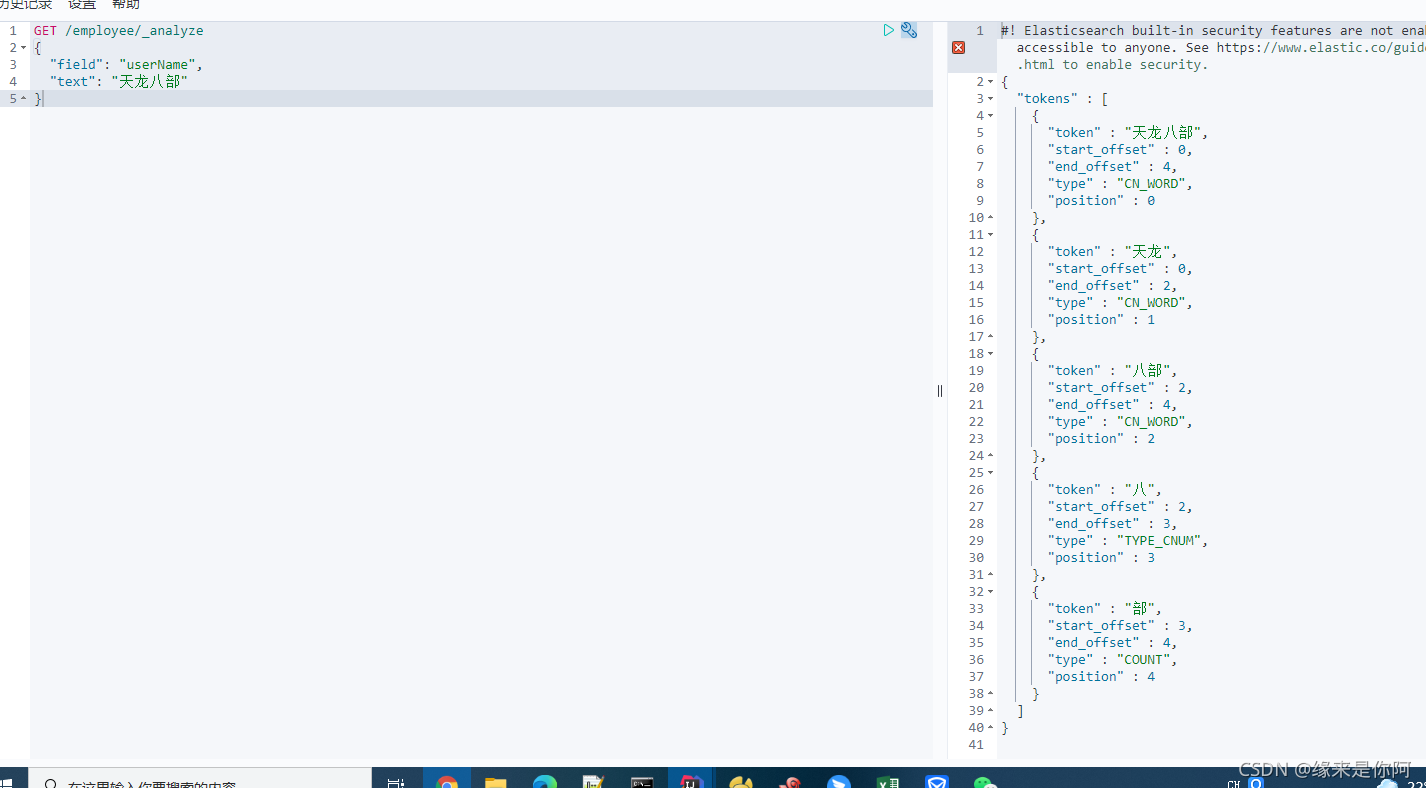
GET /employee/_analyze
{
"field": "last_name",
"text": "天龙八部"
}
Tips:
term 查询比match 更精准 ,但是适用于精确值匹配,这些精确值可能是数字、时间、布尔或者那些 not_analyzed 的字符串。
should进行评分操作
filter 不进行评分操作。
constant_score 查询
尽管没有 bool 查询使用这么频繁,constant_score 查询也是你工具箱里有用的查询工具。
它将一个不变的常量评分应用于所有匹配的文档。它被经常用于你只需要执行一个 filter 而没有其它查询。
更多操作与优化请查询官网文档














 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









