









ElasticSearch 结构化搜索 - shaomine - 博客园
https://www.cnblogs.com/shaosks/p/7566985.html
ElasticSearch 结构化搜索全文 - shaomine - 博客园
https://www.cnblogs.com/shaosks/p/7568722.html
Elasticsearch的CURD、复杂查询、聚合函数、映射mappings - MC_Hotdog - 博客园
https://www.cnblogs.com/Alexephor/p/11390966.html
GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
https://github.com/medcl/elasticsearch-analysis-pinyin
ElasticSearch安装拼音插件 elasticsearch-analysis-pinyin_十有八⑨的博客-CSDN博客_elasticsearch 拼音插件
https://blog.csdn.net/qq_32331997/article/details/86639527
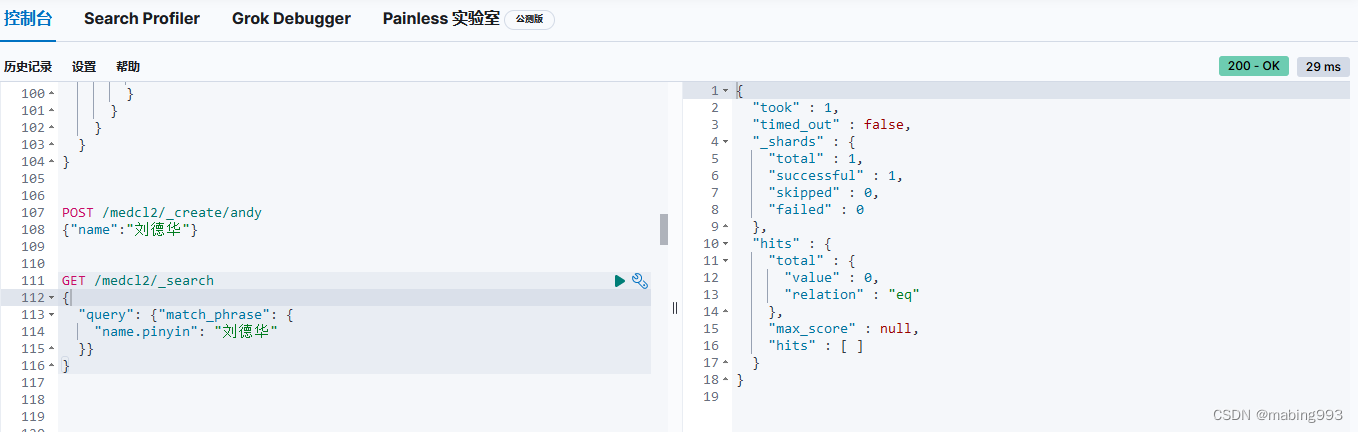
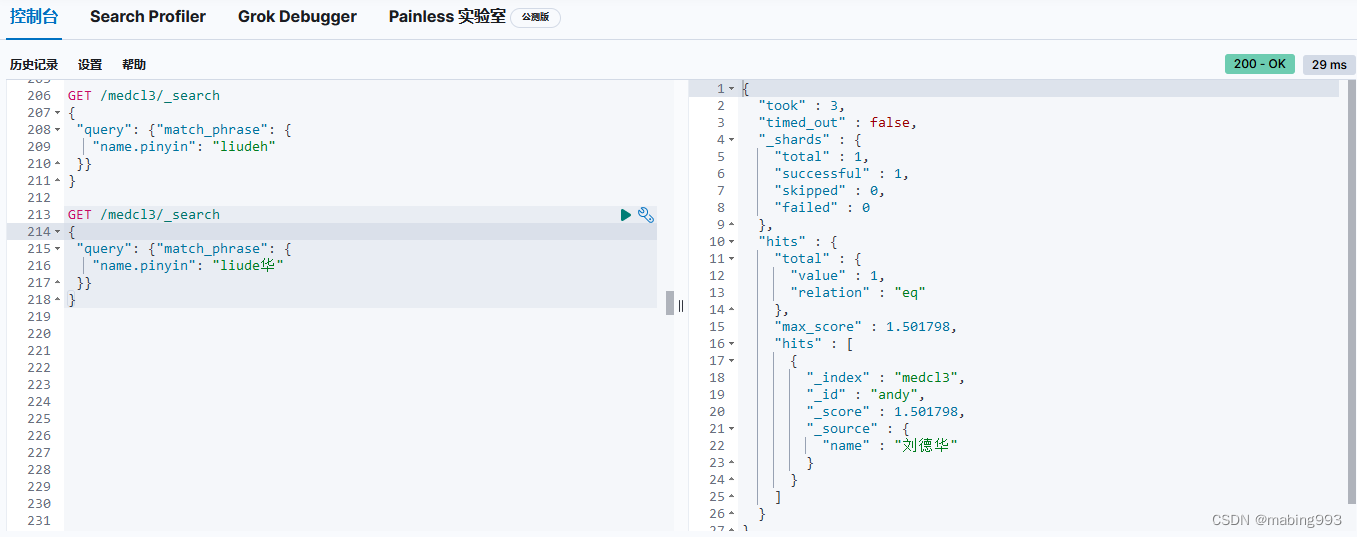
github选择v8.2.0,支持Elasticsearch8.2.2
修改plugin-descriptor.properties版本为8.2.2,重启ES,ES重启完成后,Kibana也重启。
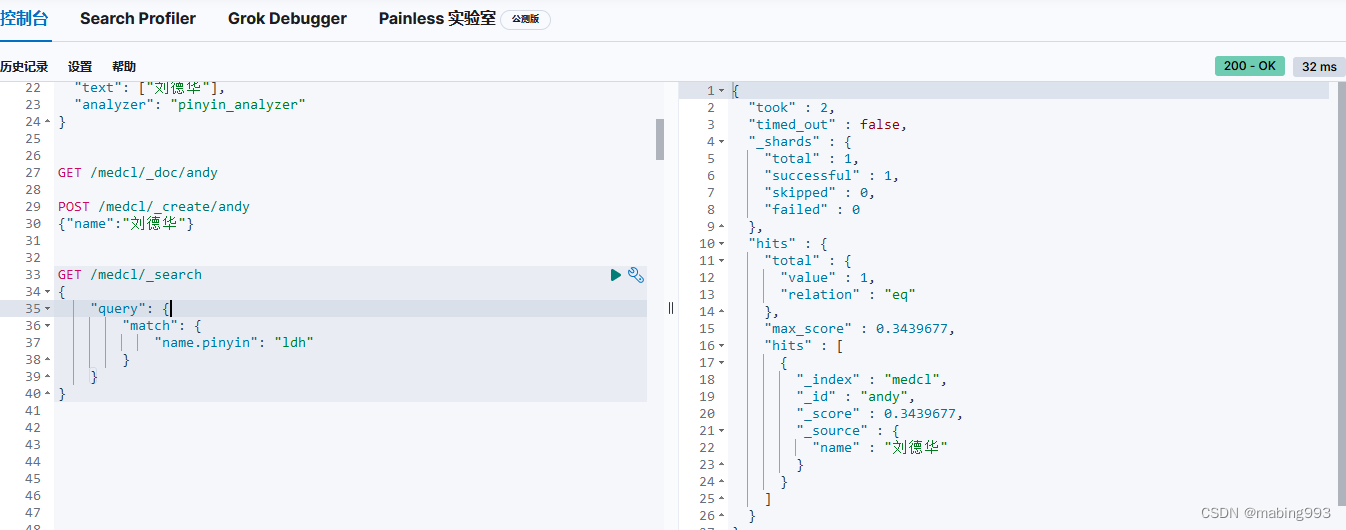
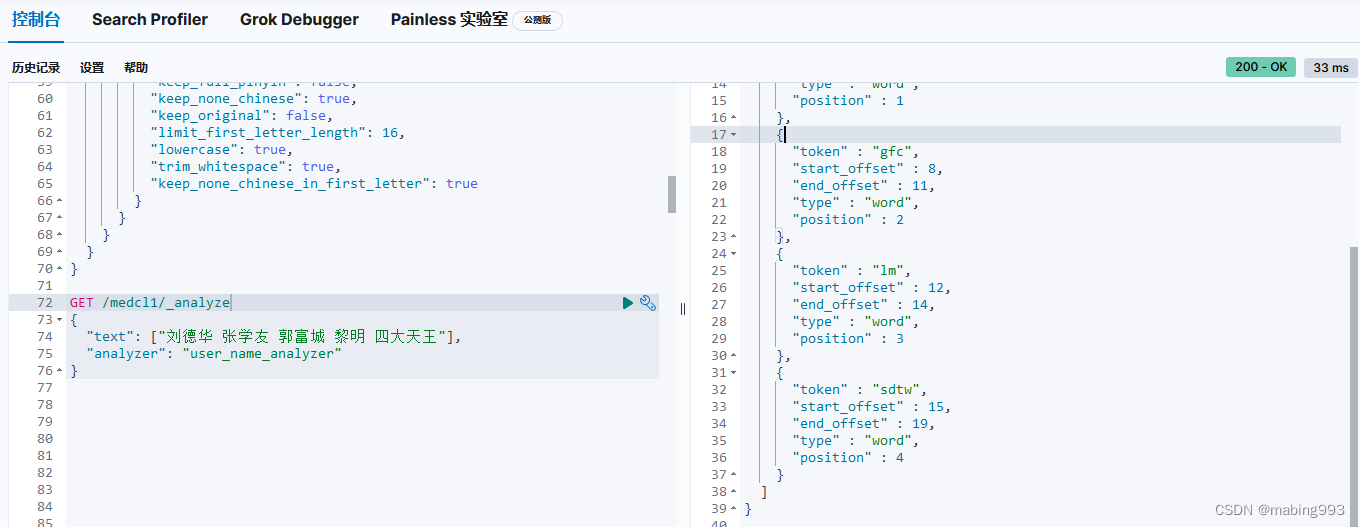
Kibana测试一下pinyin,使用下面的example
GitHub - medcl/elasticsearch-analysis-pinyin at v8.2.0
https://github.com/medcl/elasticsearch-analysis-pinyin/tree/v8.2.0 
python-elasticsearch基本用法 - 做个笔记 - 博客园
https://www.cnblogs.com/mrzhao520/p/14120991.html
在Python中操作Elasticsearch - 王大拿 - 博客园
https://www.cnblogs.com/wangkun122/articles/10736507.html
Python 操作 ElasticSearch - shaomine - 博客园
https://www.cnblogs.com/shaosks/p/7592229.html
Python Elasticsearch Client — Python Elasticsearch client 8.2.2 documentation
https://elasticsearch-py.readthedocs.io/en/v8.2.2/index.html
Deprecation warnings in 7.15.0 pre-releases · Issue #1698 · elastic/elasticsearch-py · GitHub
https://github.com/elastic/elasticsearch-py/issues/1698
elasticsearch-py自7.15.0后,接口参数名有所改变,同时建议全部使用关键字参数
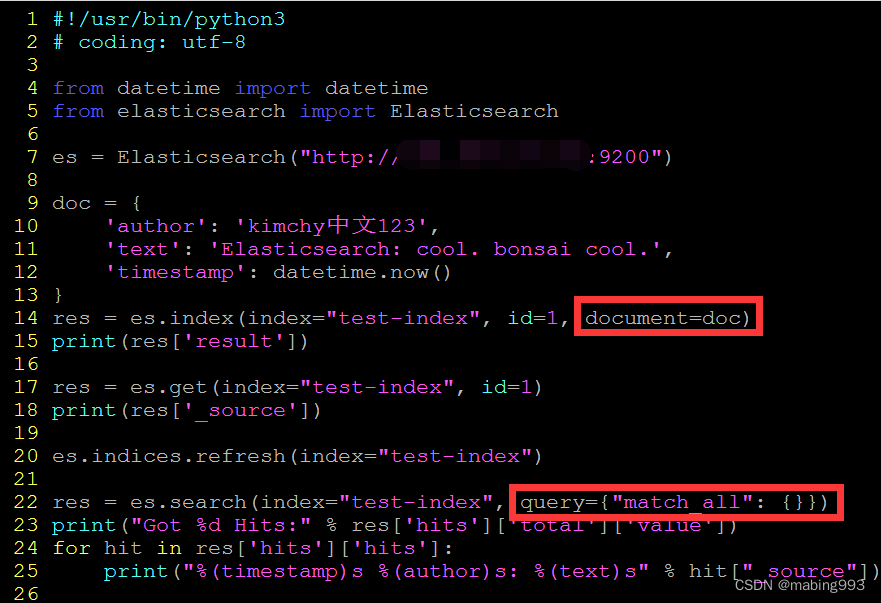

一个完整Demo,使用以下数据
适应新环境 | Elasticsearch: 权威指南 | Elastic
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_finding_your_feet.html

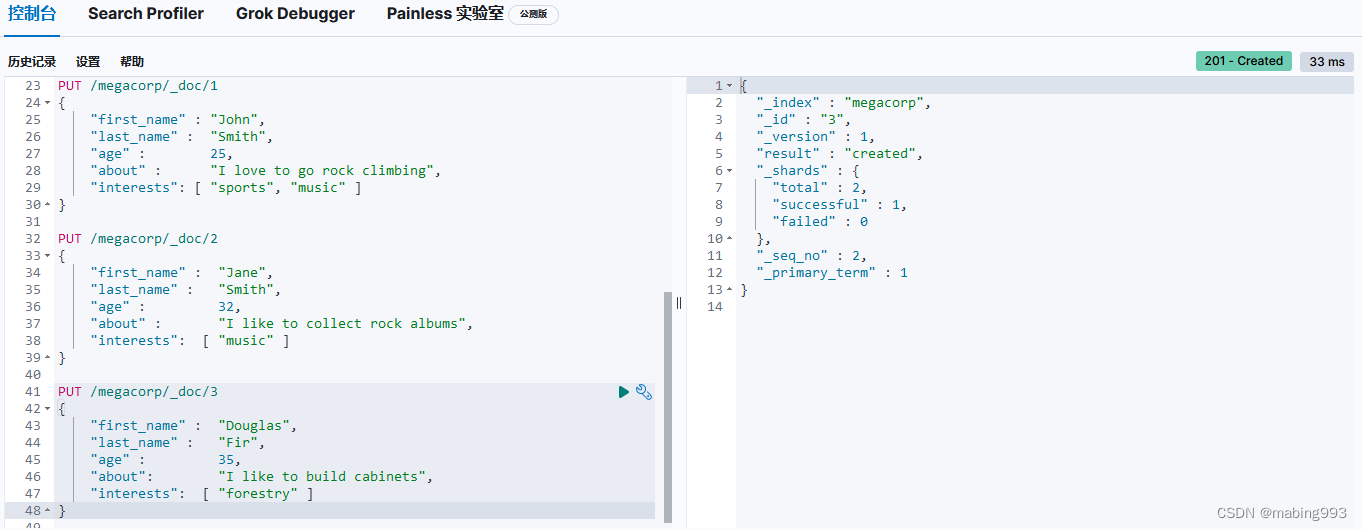
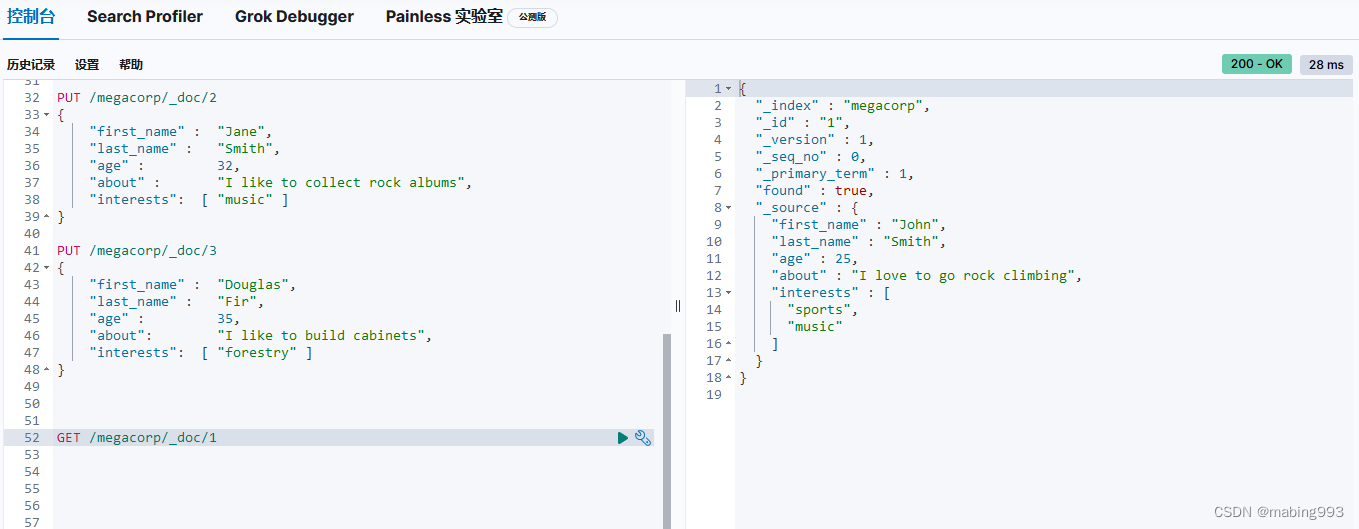
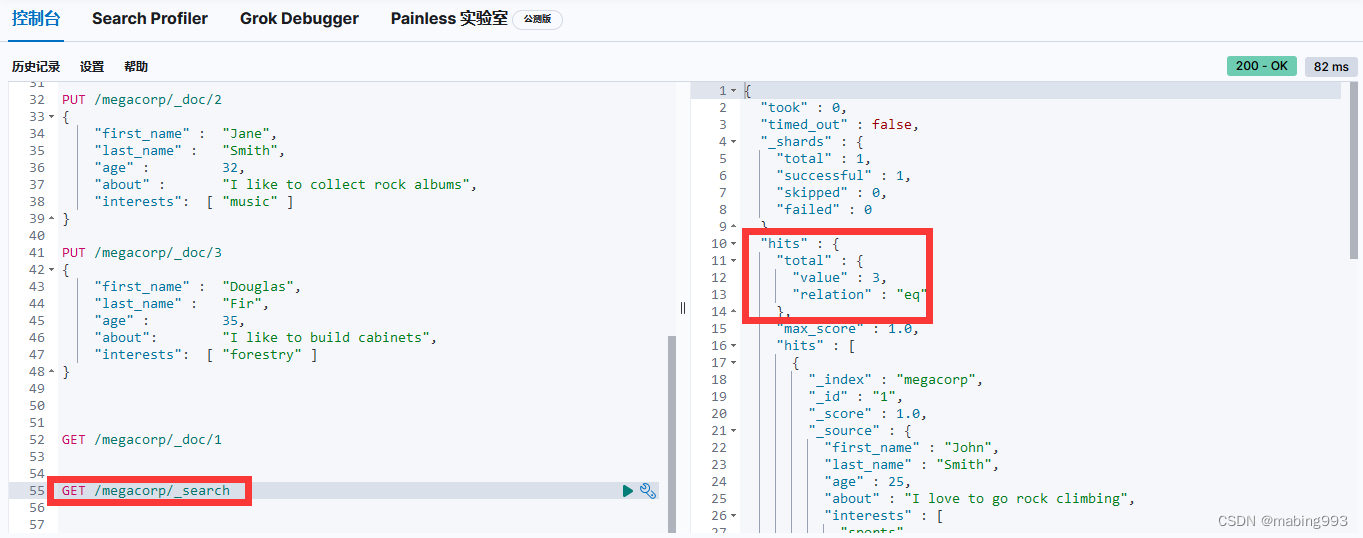
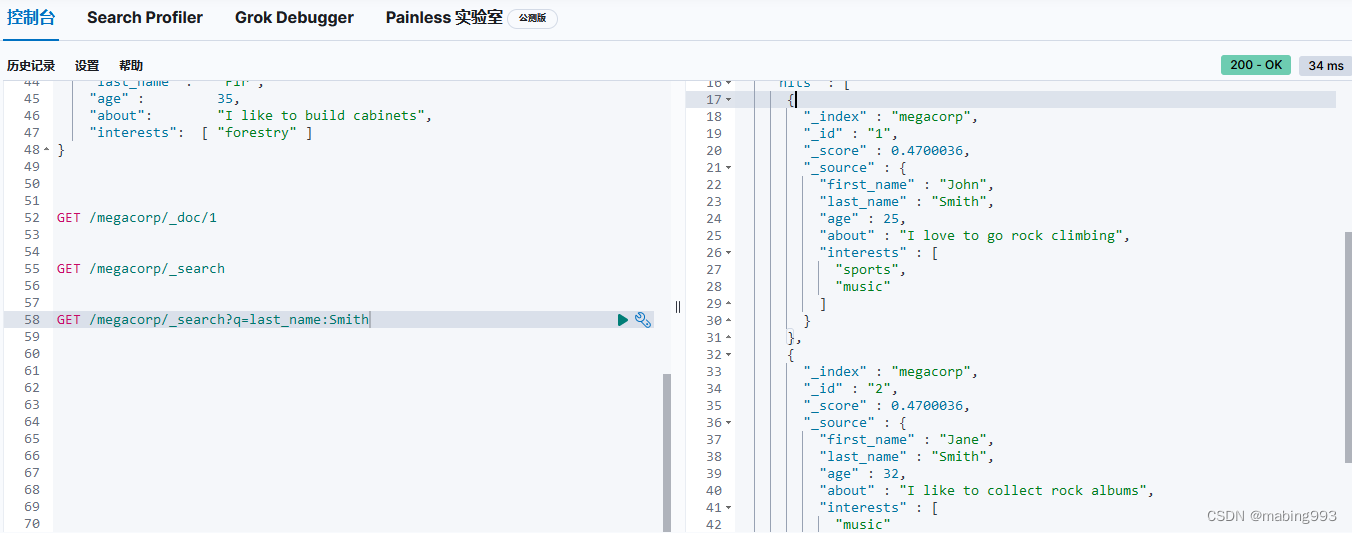
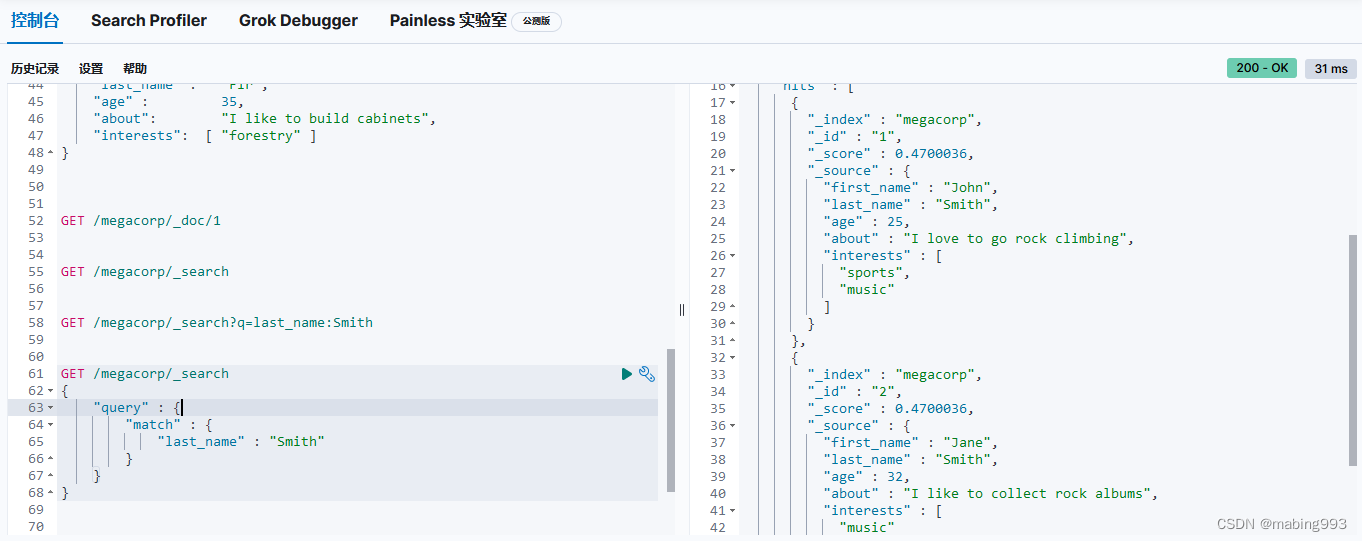
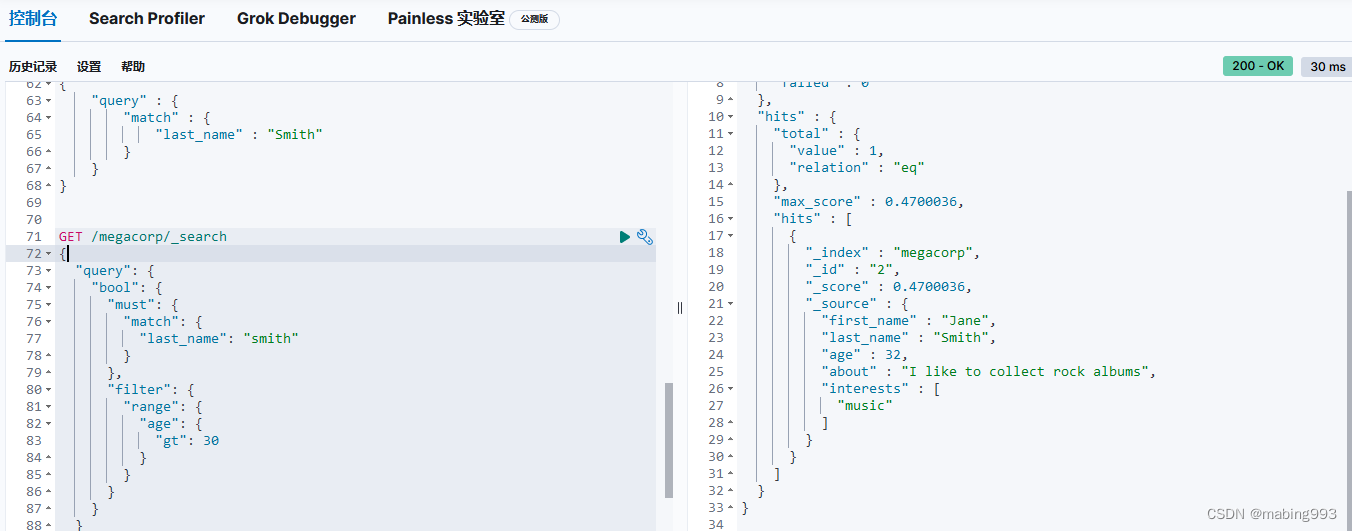
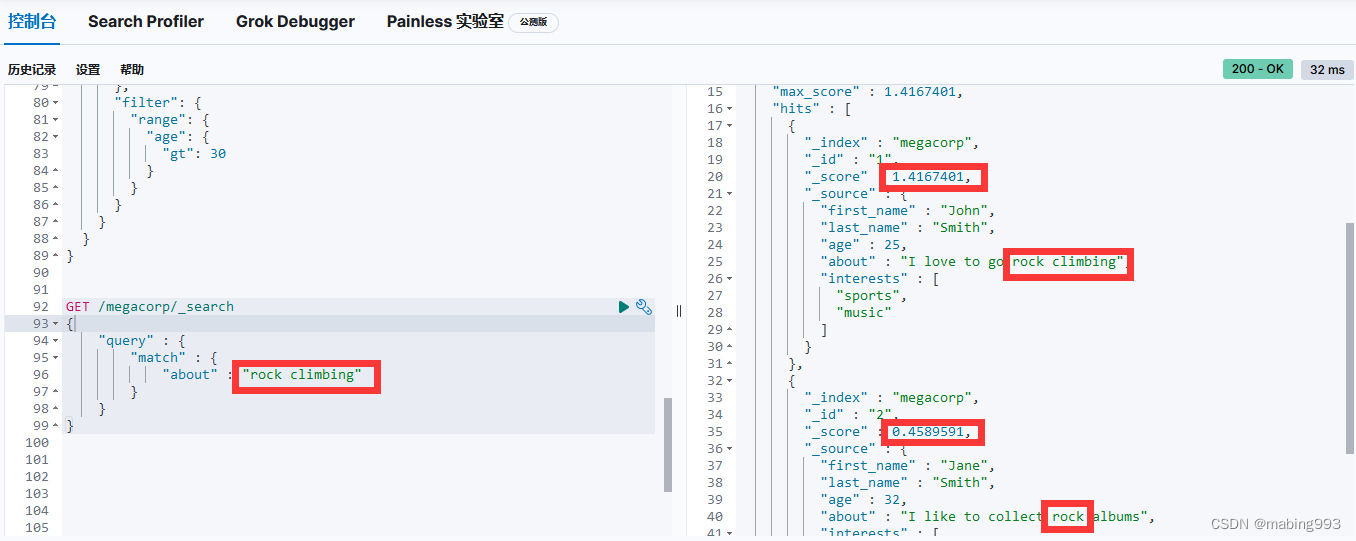
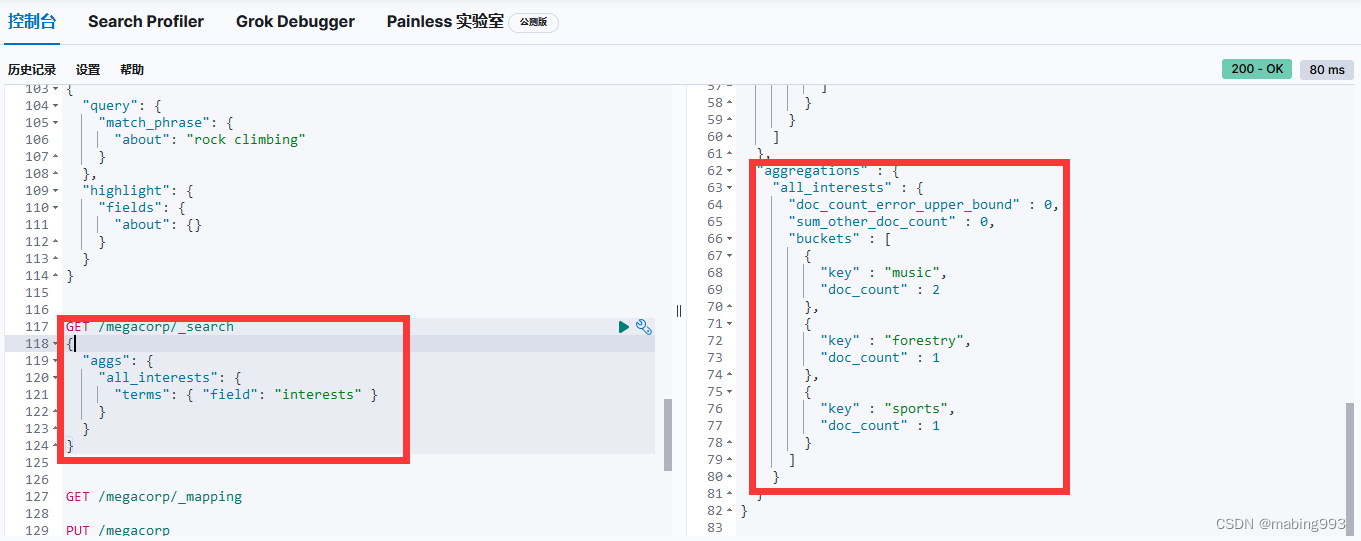
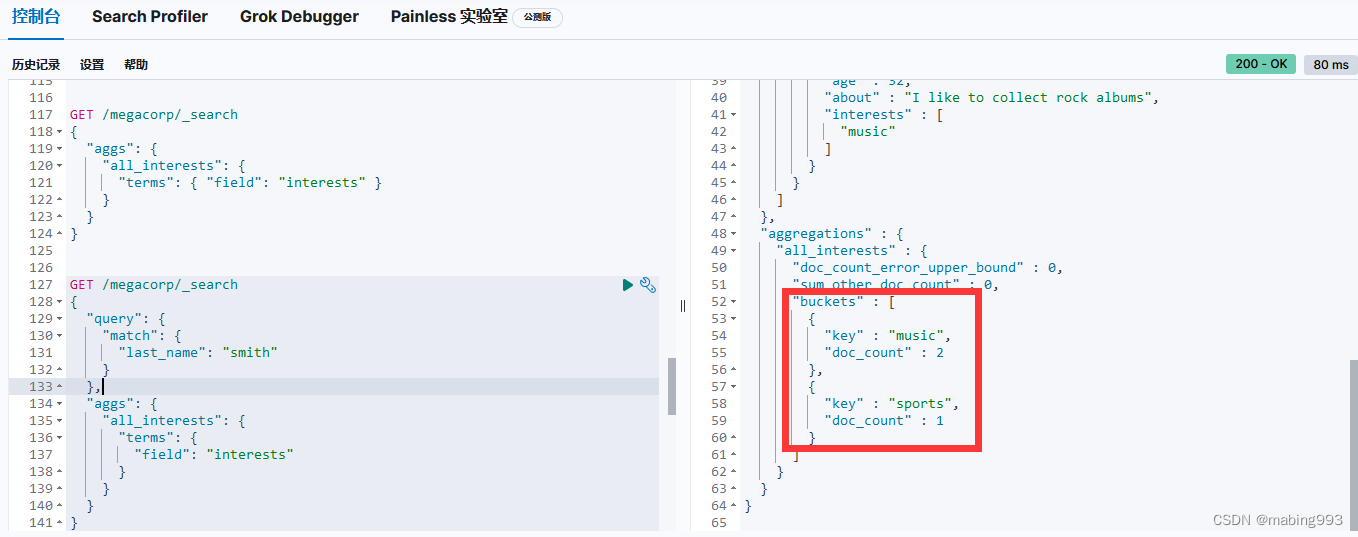
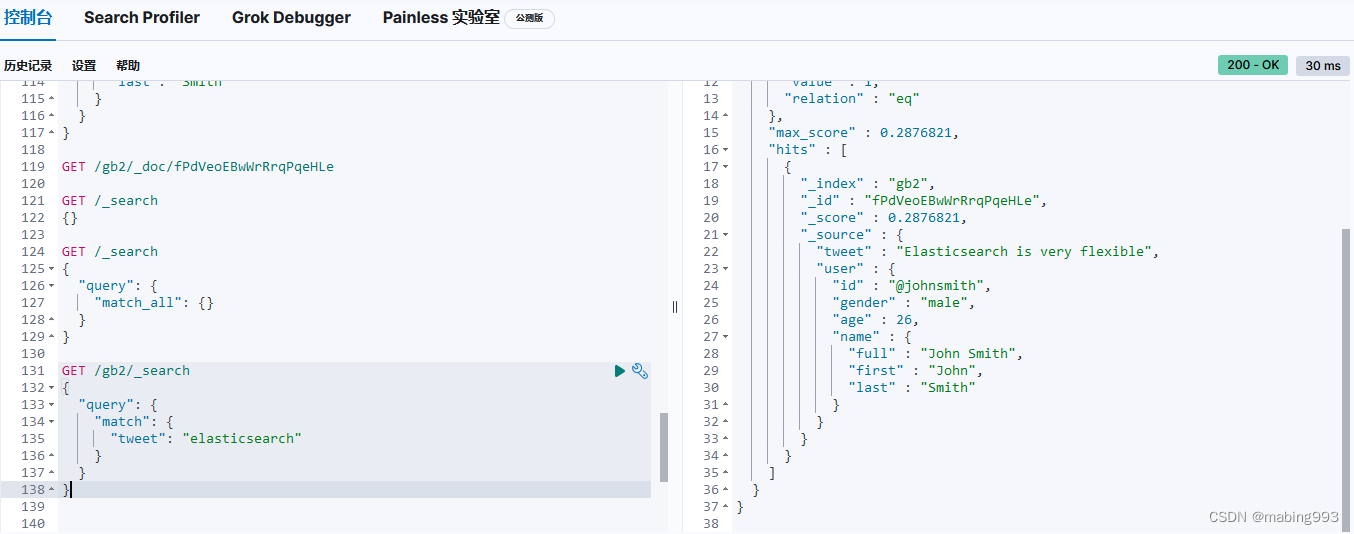
Elasticsearch默认按照“相关性”得分排序,即每个文档跟查询的匹配程度。第一个最高得分的结果很明显:John Smith的about属性清楚地写着“rock climbing”。
但为什么Jane Smith也作为结果返回了呢?原因是她的about属性里提到了“rock”。因为只有“rock”而没有“climbing”,所以她的相关性得分低于John的。
这是一个很好的案例,阐明了Elasticsearch如何在全文属性上搜索并返回相关性最强的结果。Elasticsearch中的“相关性”概念非常重要,也是完全区别于传统关系型数据库的一个概念,数据库中的一条记录要么匹配要么不匹配。
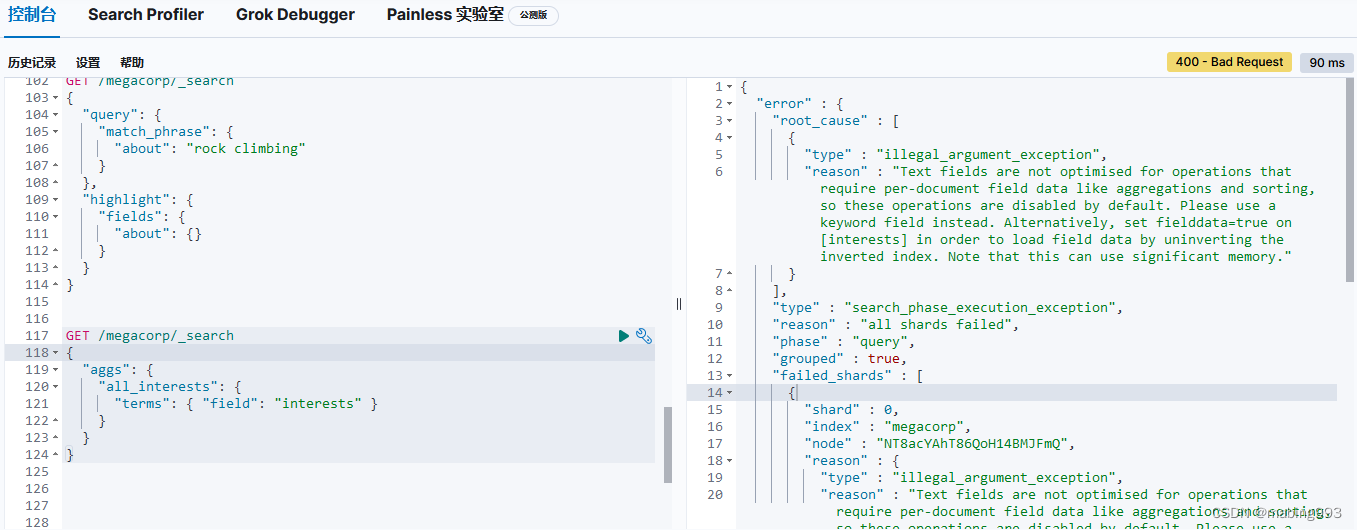
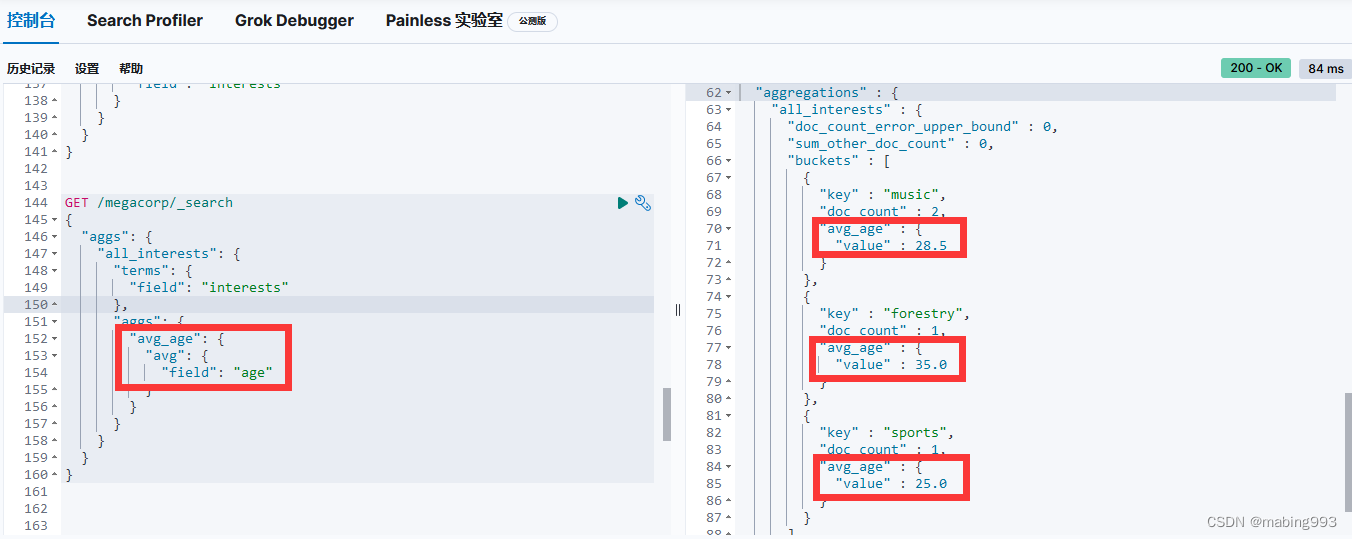
聚合出错,原因在于interests的type为text,不支持聚合。
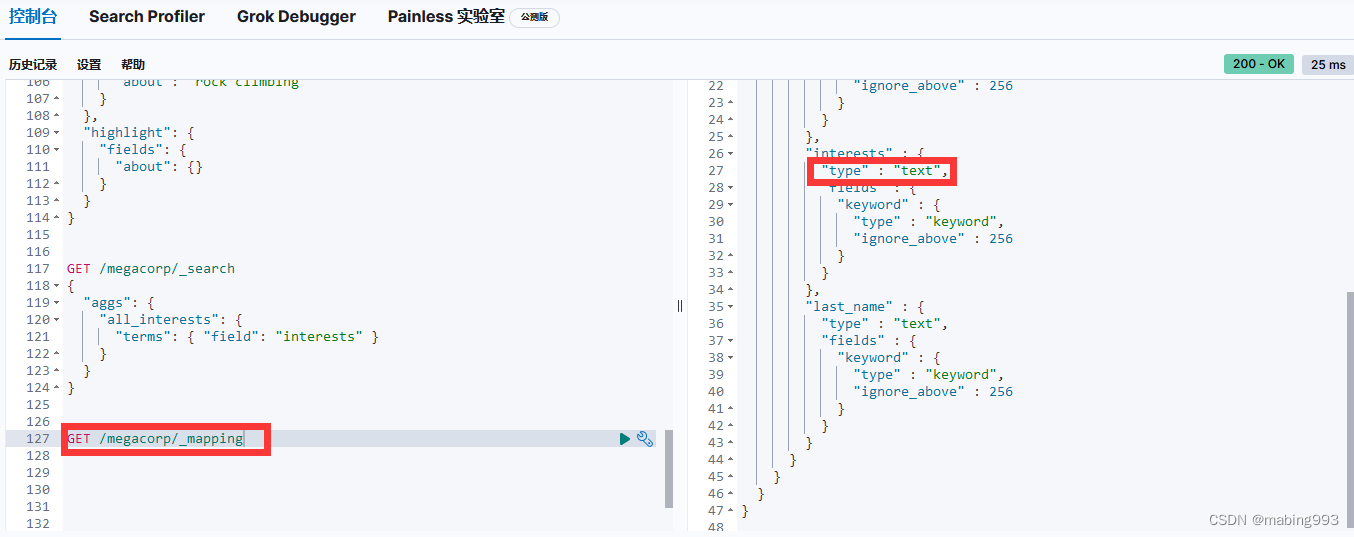
修改方法一:添加fielddata为true,这种方法改动小。fielddata在text字段中默认未启用,但fielddata会消耗大量的堆内存,特别是当加载大量的text字段时;fielddata一旦加载到堆中,在segment的生命周期之内都将一致保持在堆中,所以谨慎使用。
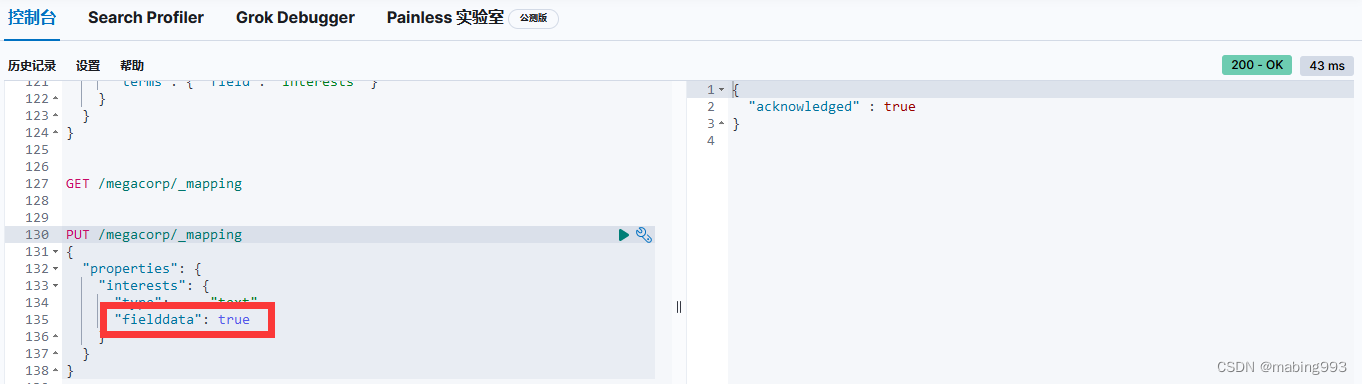
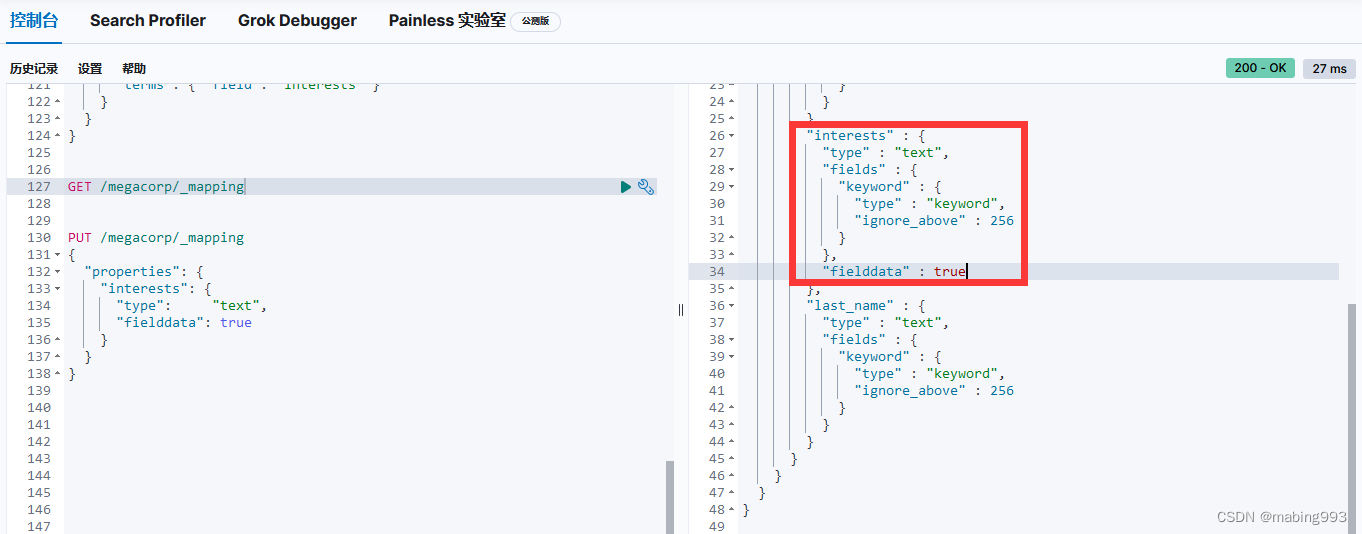
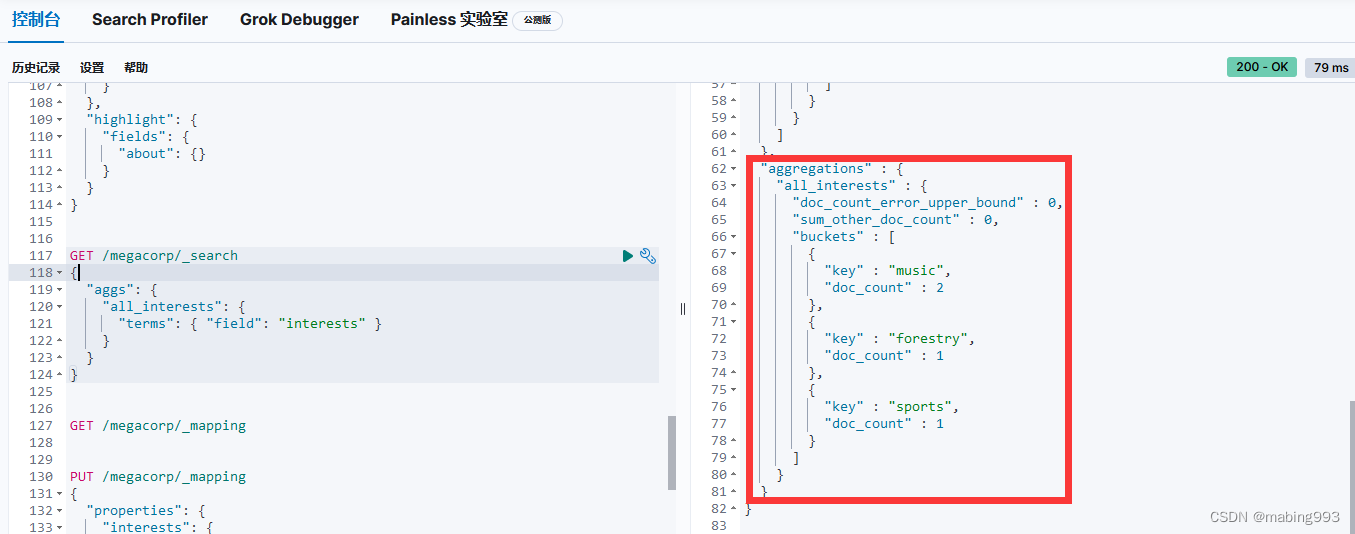
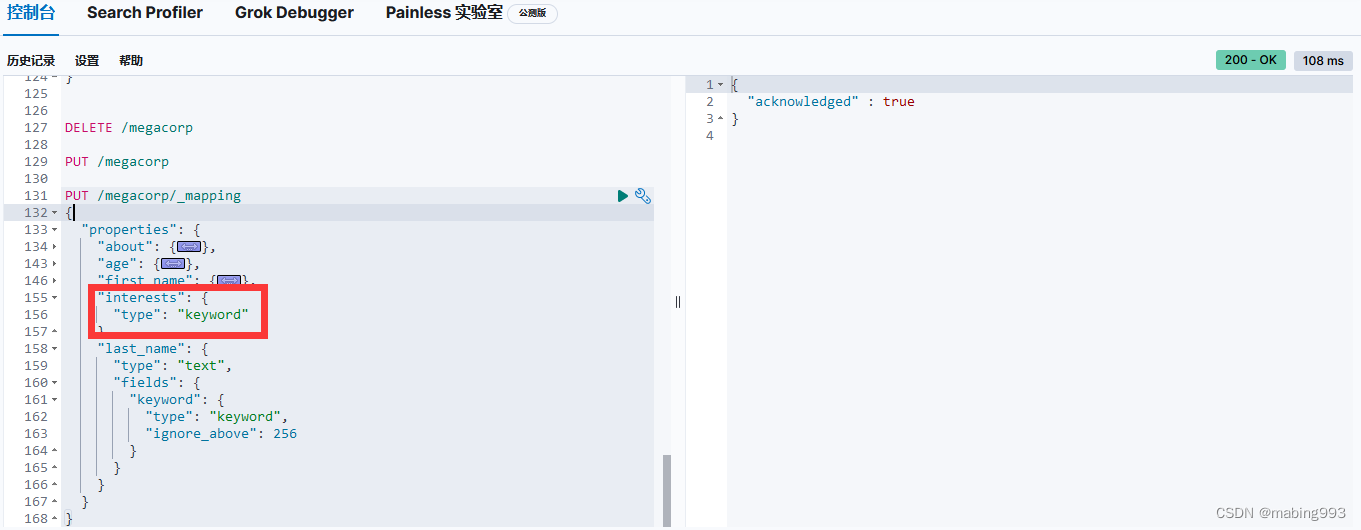
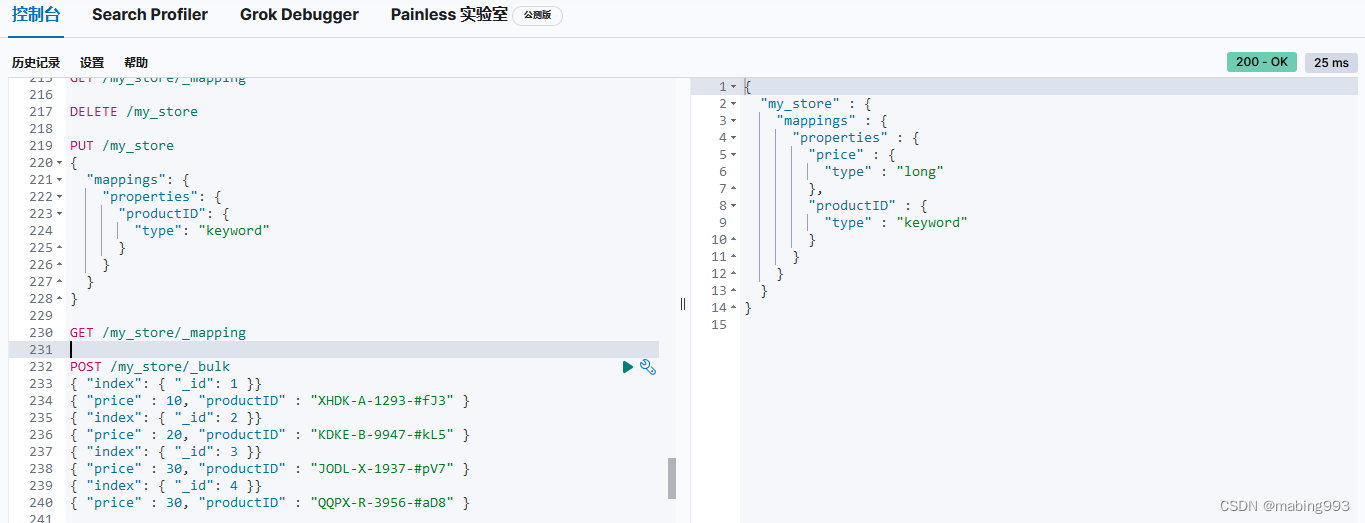
修改方法二:新建index时指定interests的type为keyword

空查询返回所有索引的所有文档
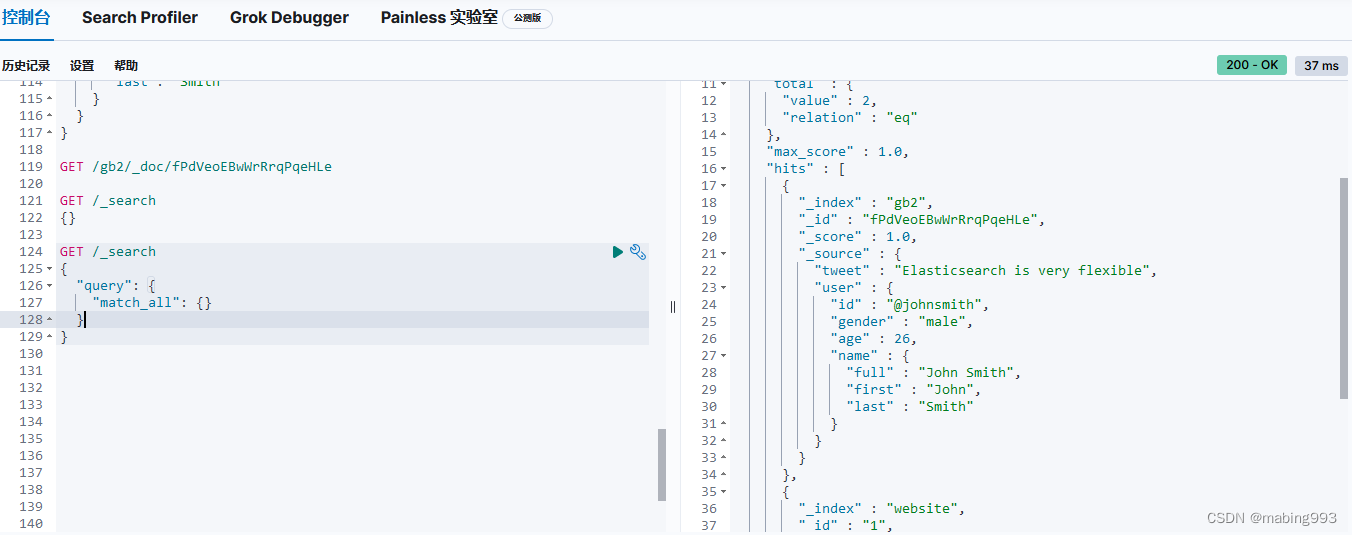
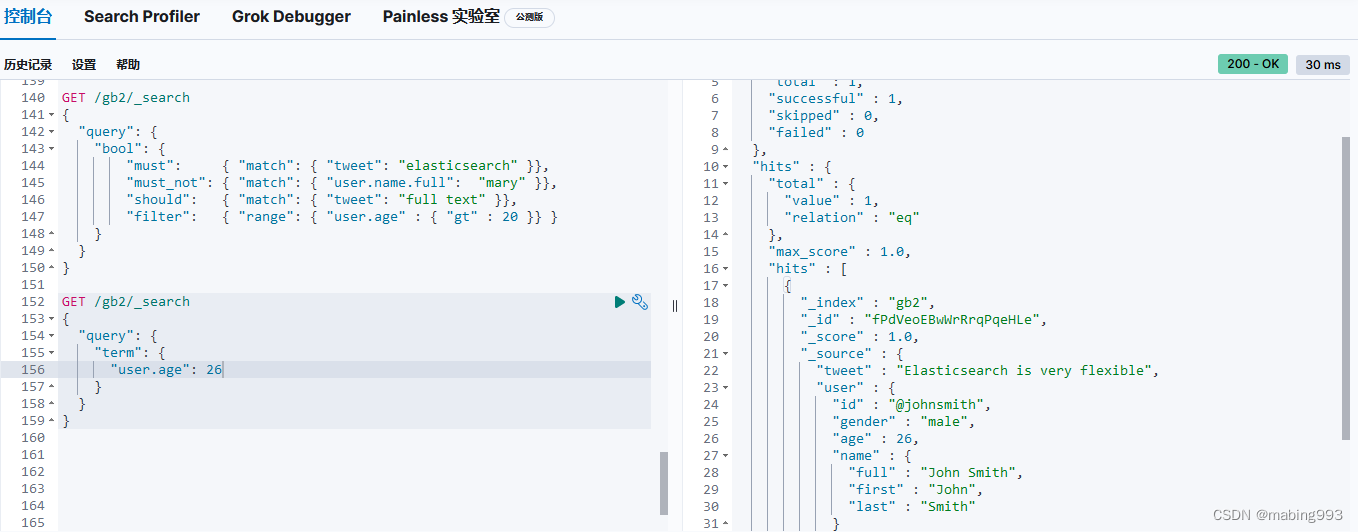
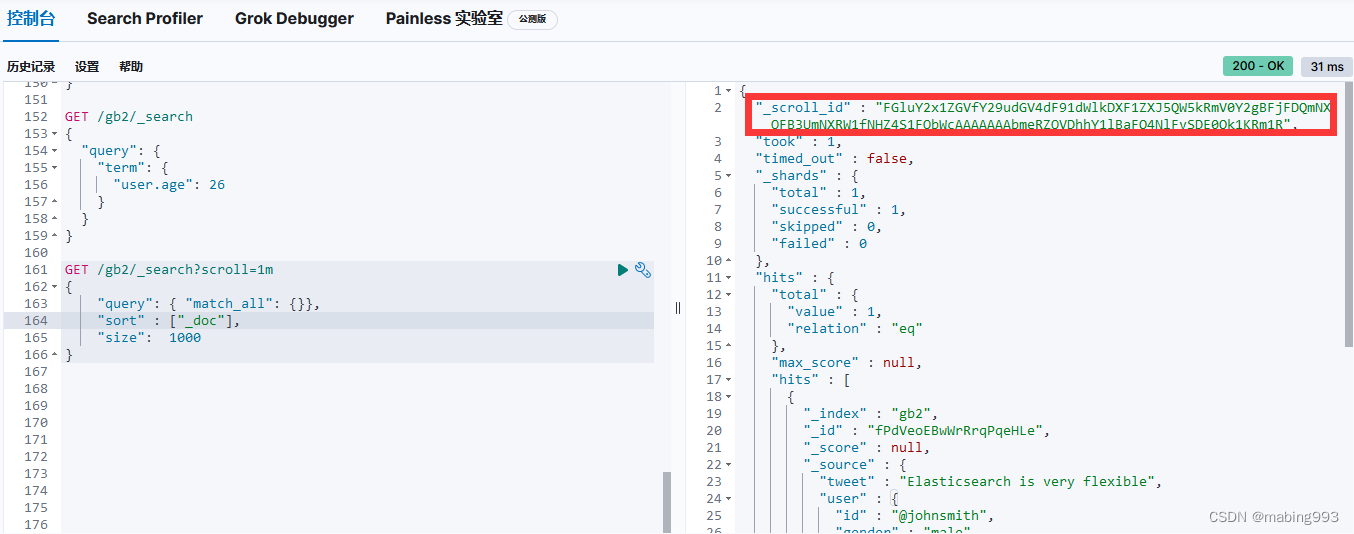
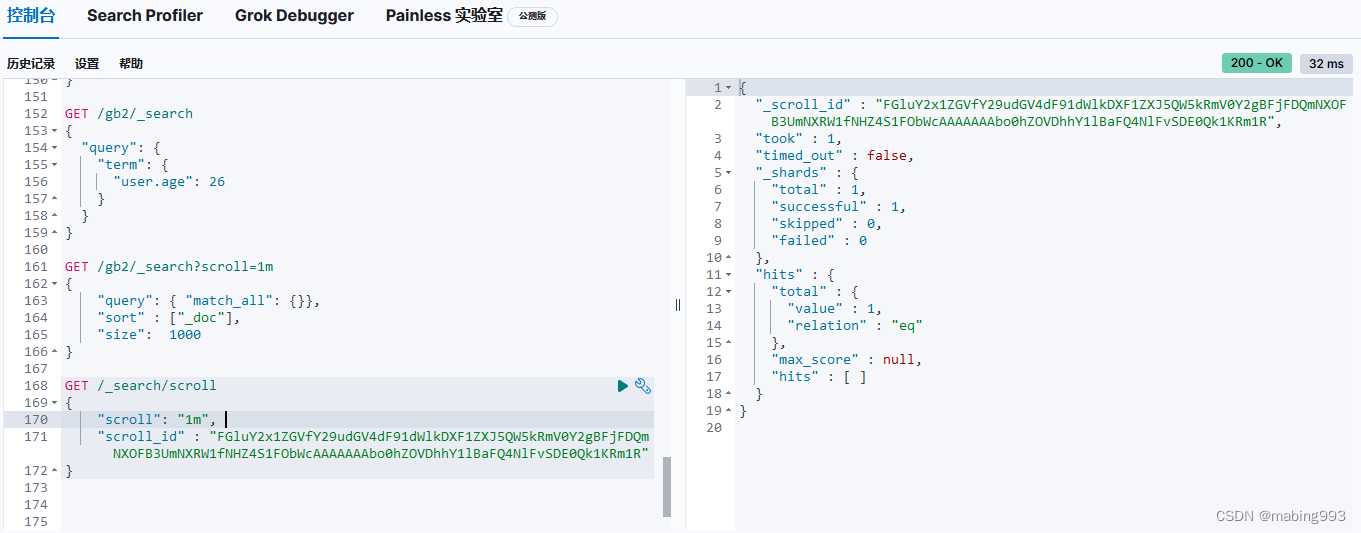
scroll=1m表示设置scroll_id保留1分钟可用,使用scroll必须要将from设置为0,size决定后面每次调用_search搜索返回的数量。
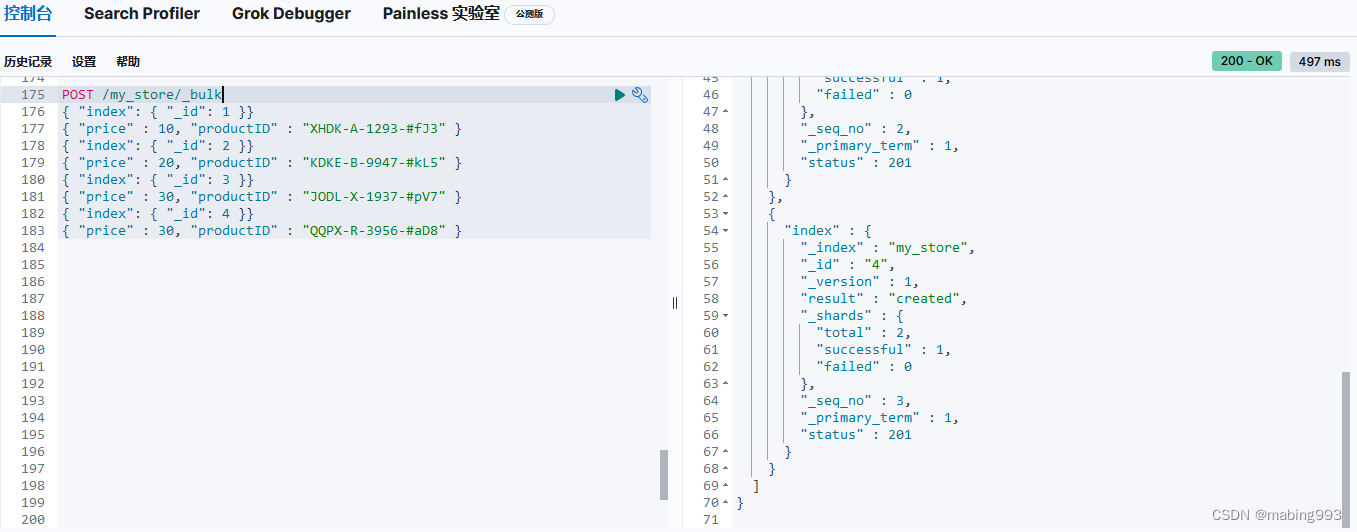
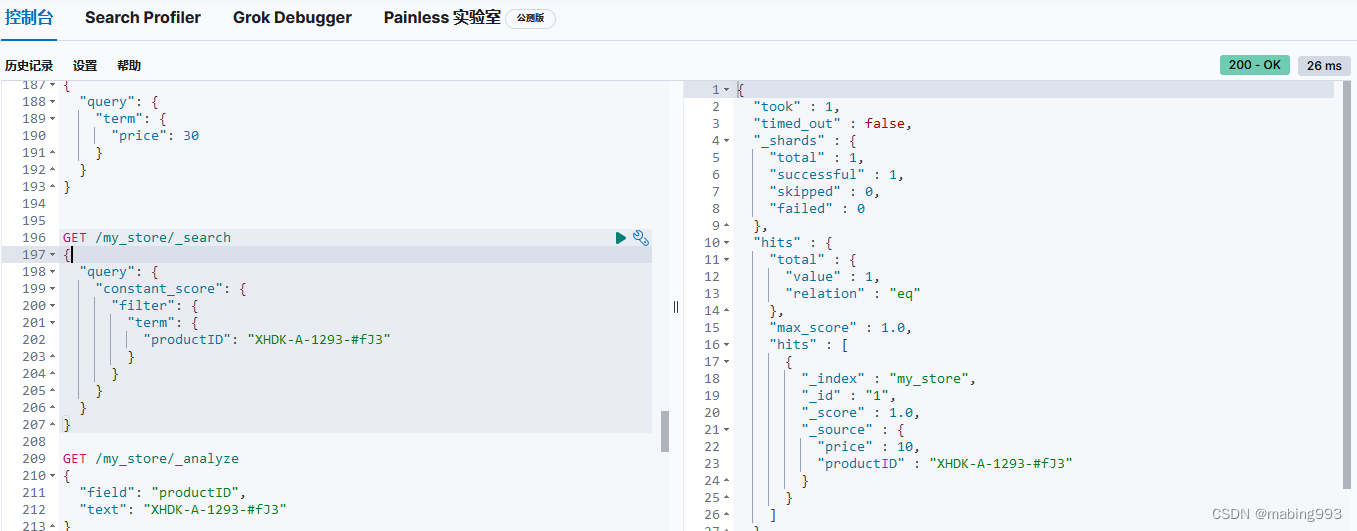
通常当查找一个精确值的时候,我们不希望对查询进行评分计算。只希望对文档进行包括或排除的计算,所以我们会使用 constant_score 查询以非评分模式来执行 term 查询并以 1 作为统一评分。
最终组合的结果是一个 constant_score 查询,它包含一个 term 查询。查询置于 filter 语句内不进行评分或相关度的计算,所以所有结果都会返回一个默认评分 1 。
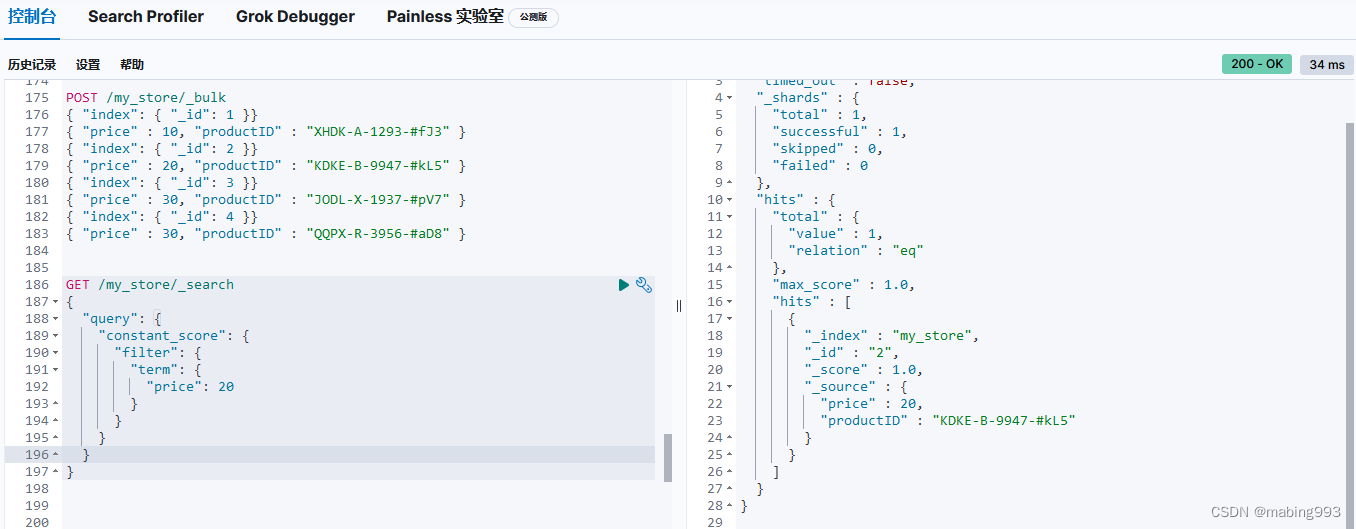
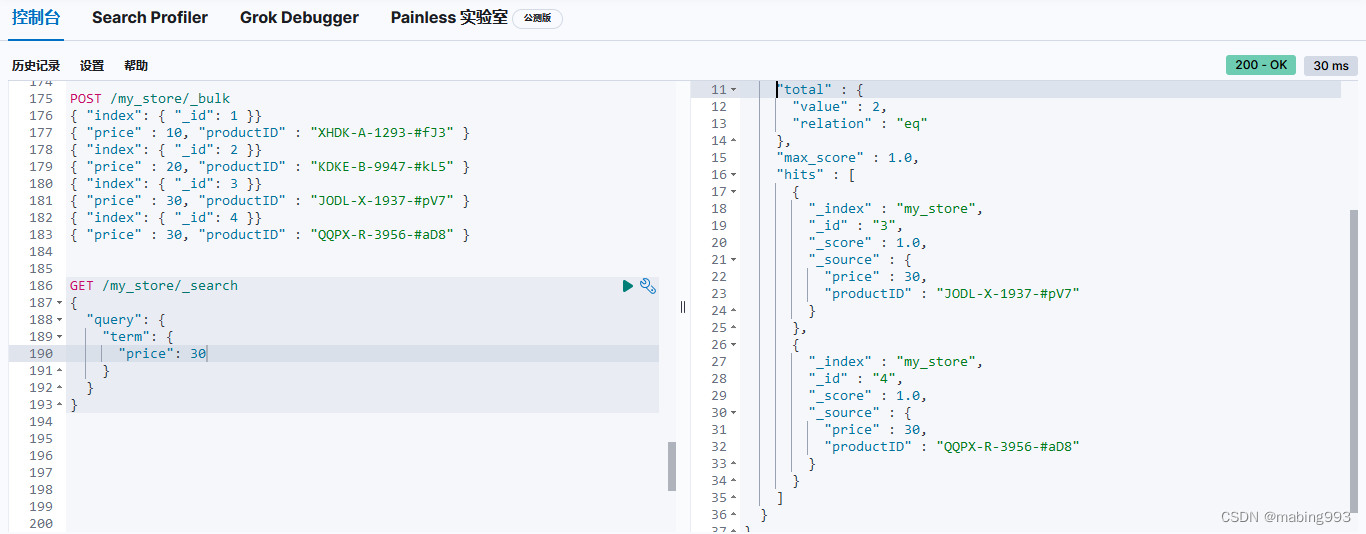
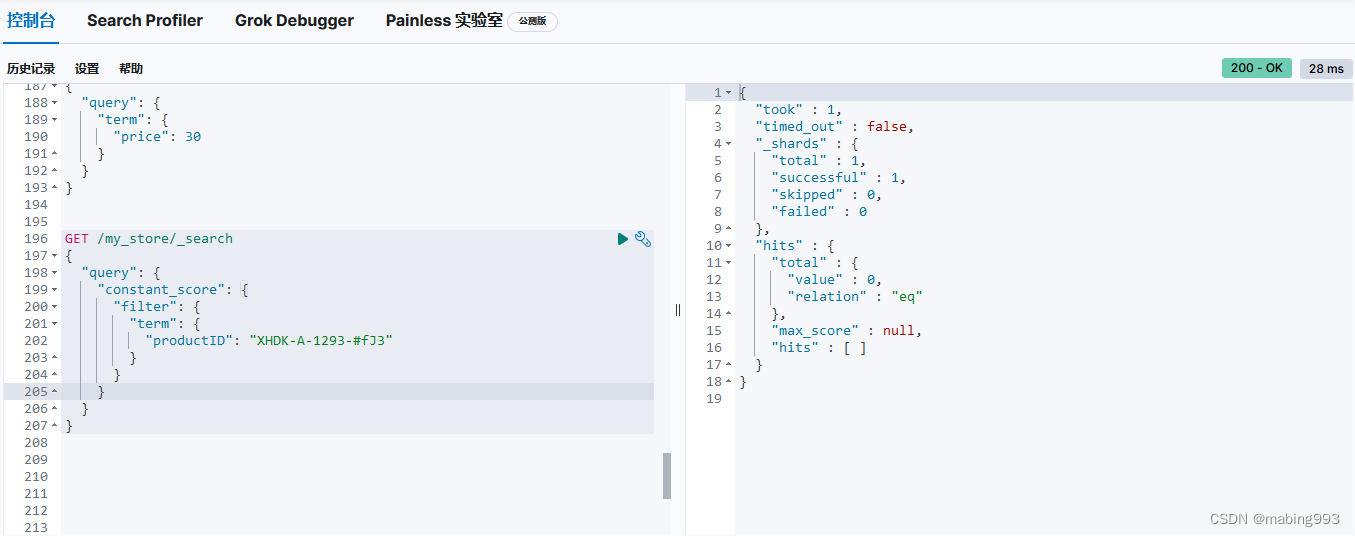
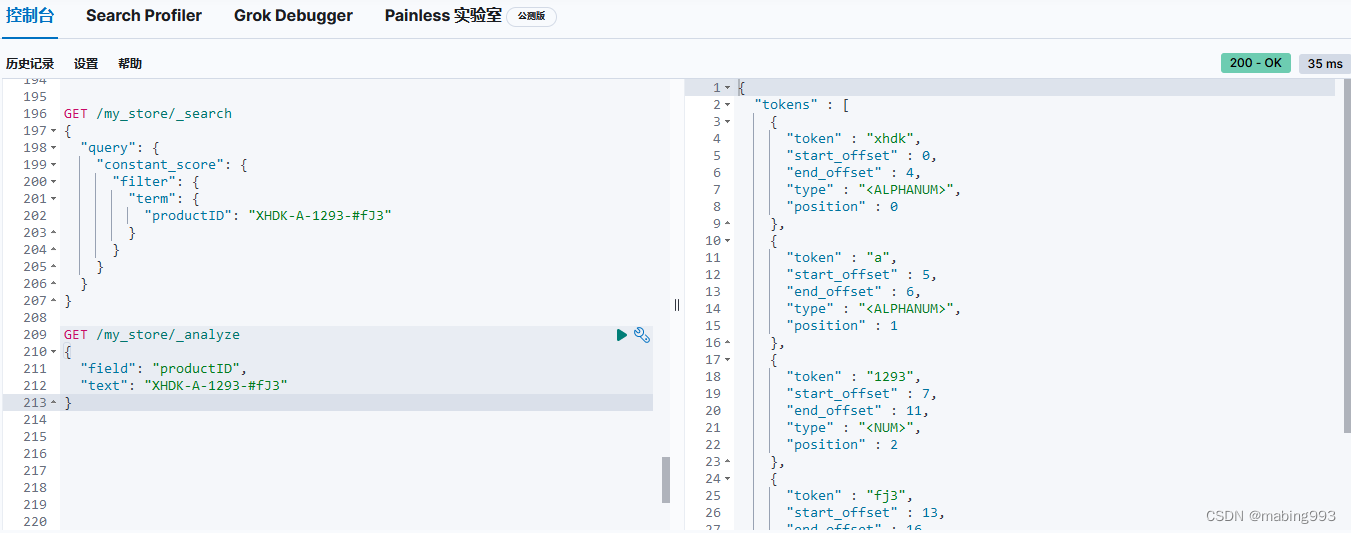
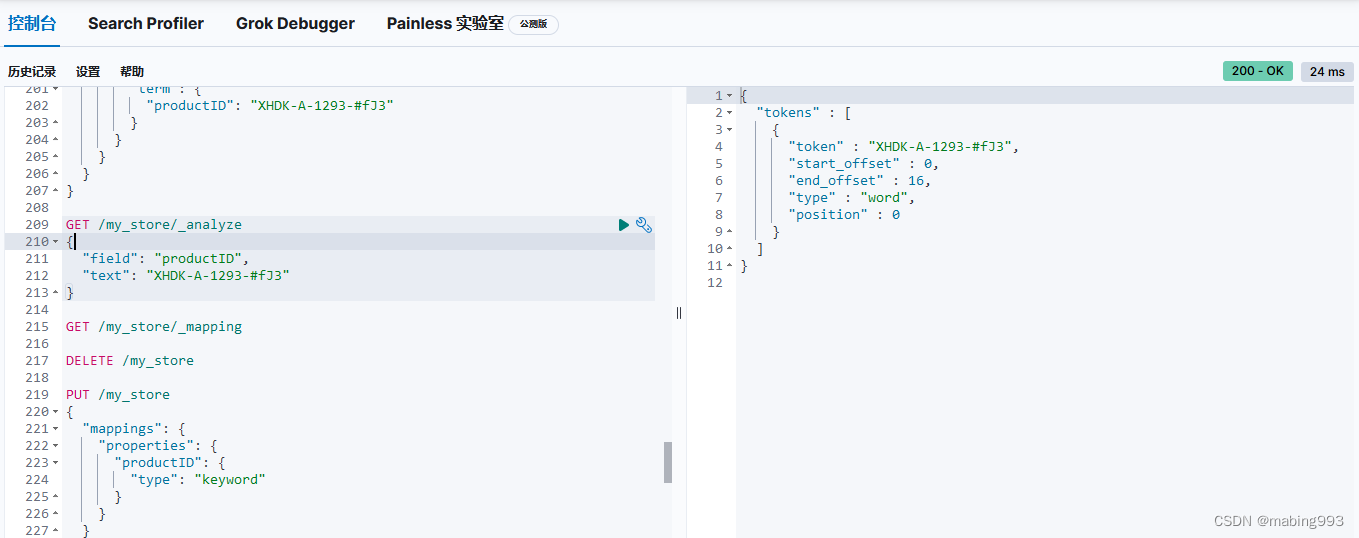
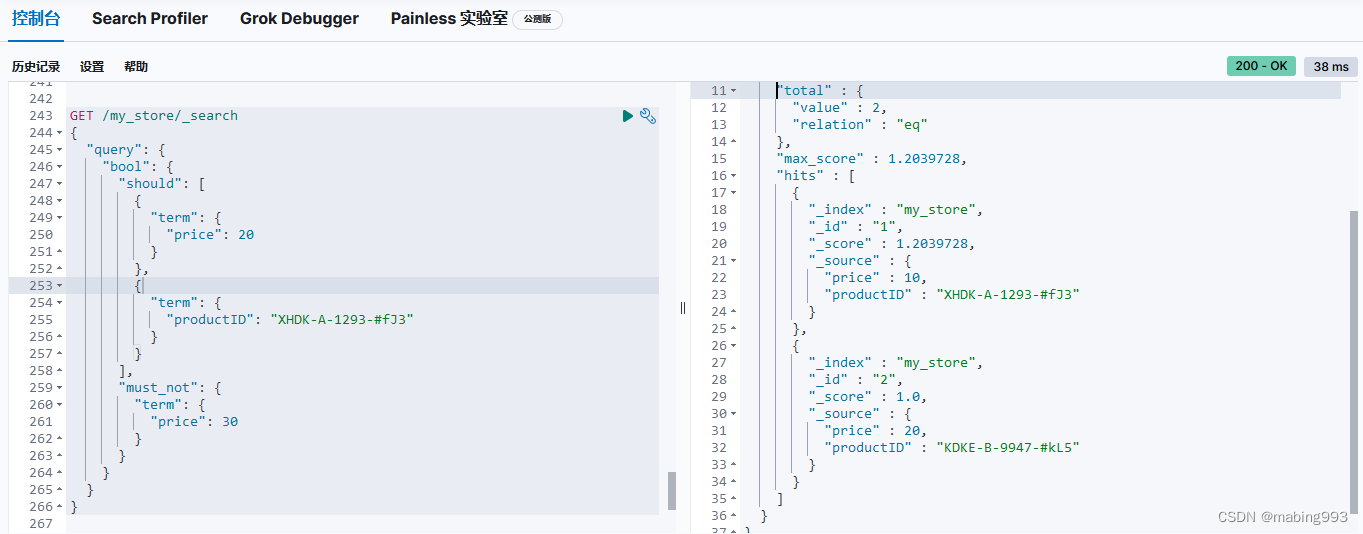
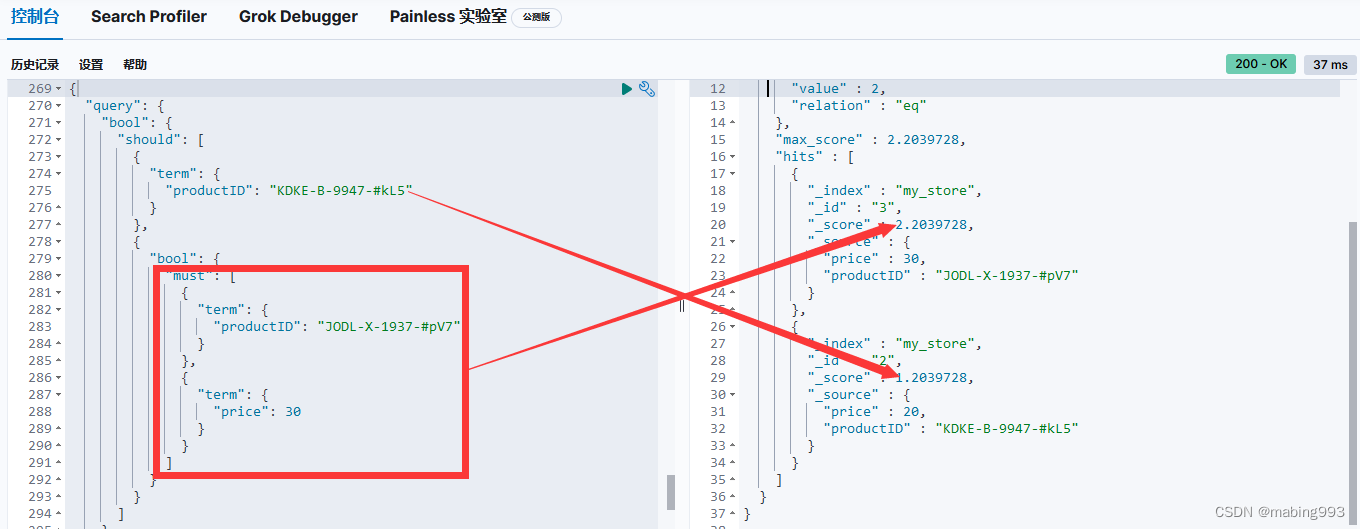

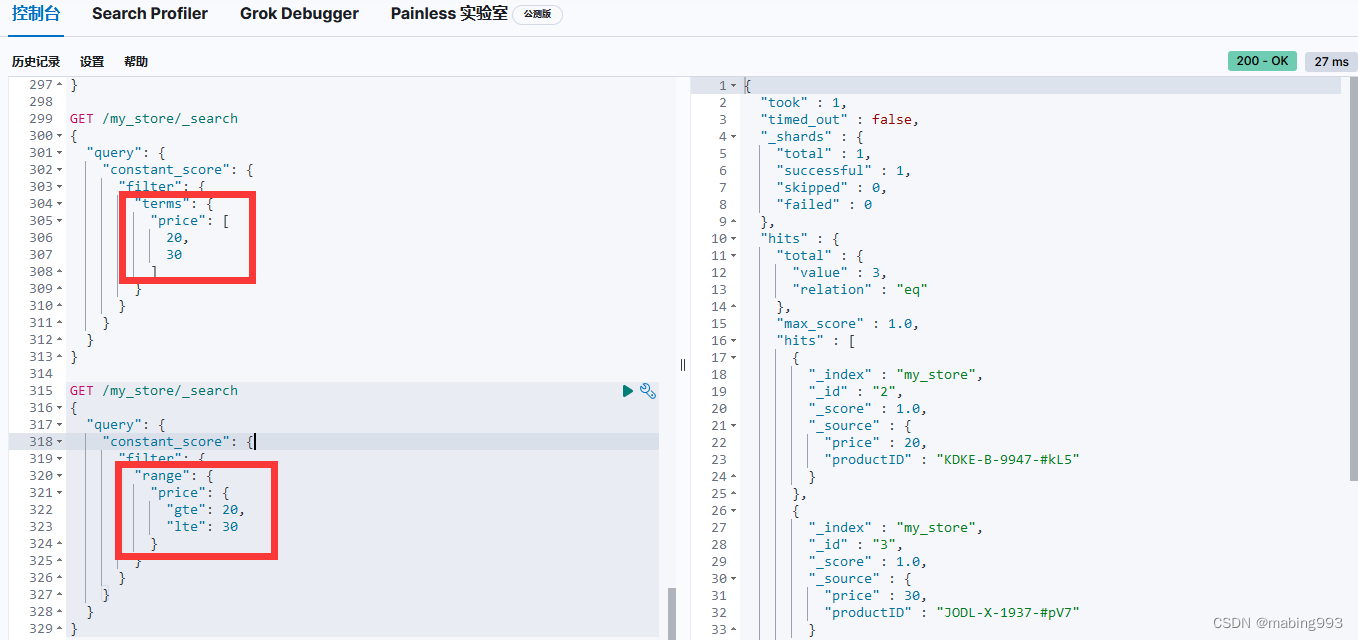
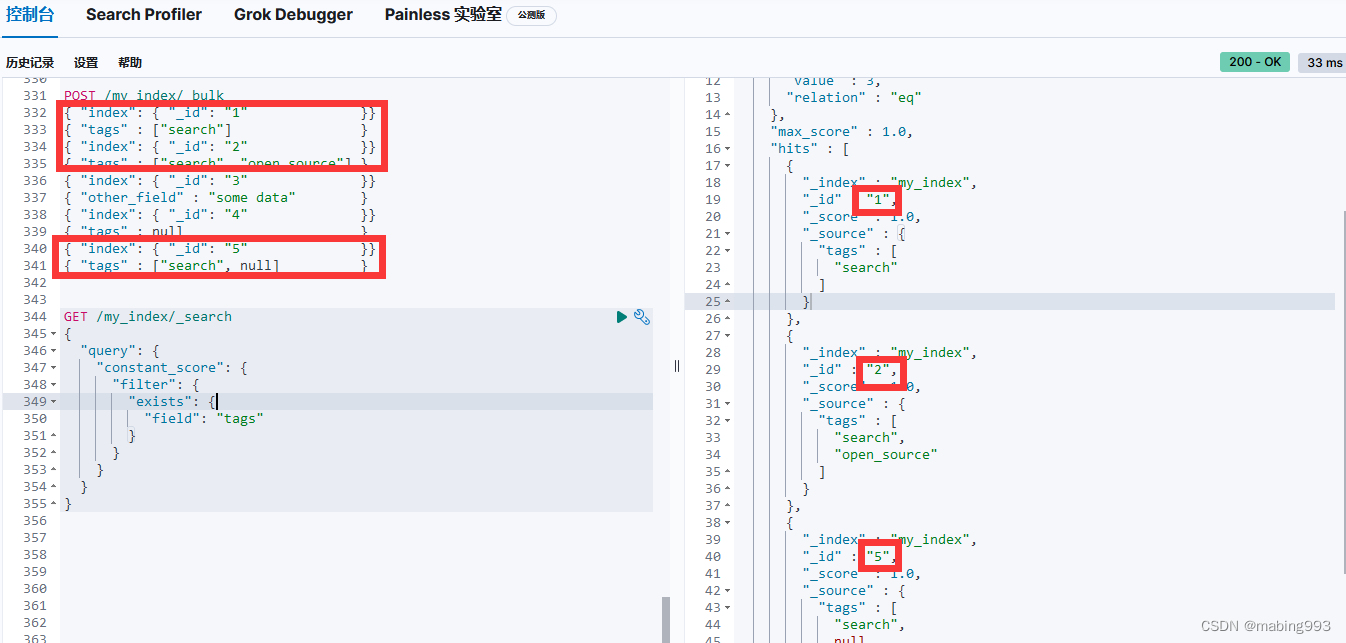
Filter Query Missing 已经从 ES 5 版本移除
Refer to:
https://www.elastic.co/guide/en/elasticsearch/reference/6.1/query-dsl-exists-query.html#_literal_missing_literal_query
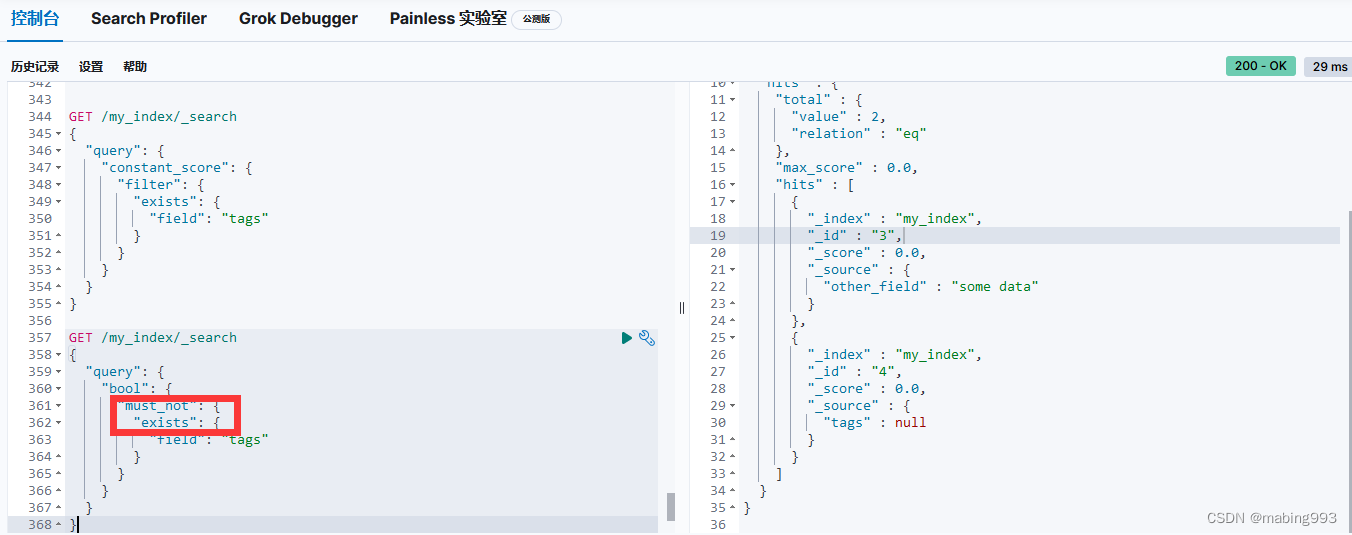
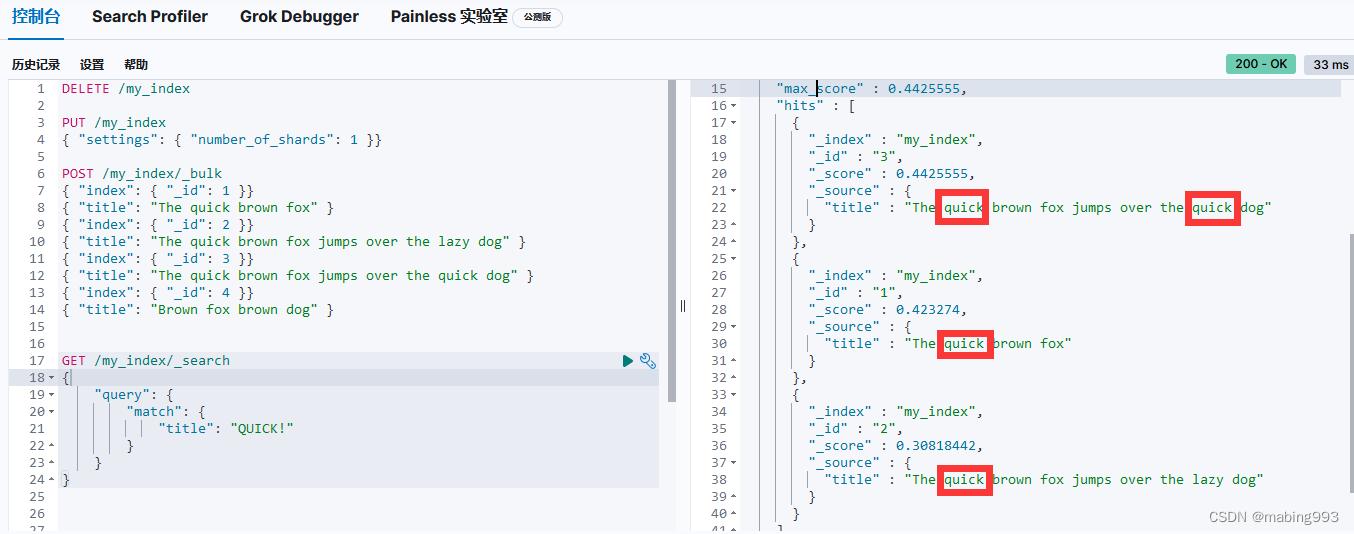
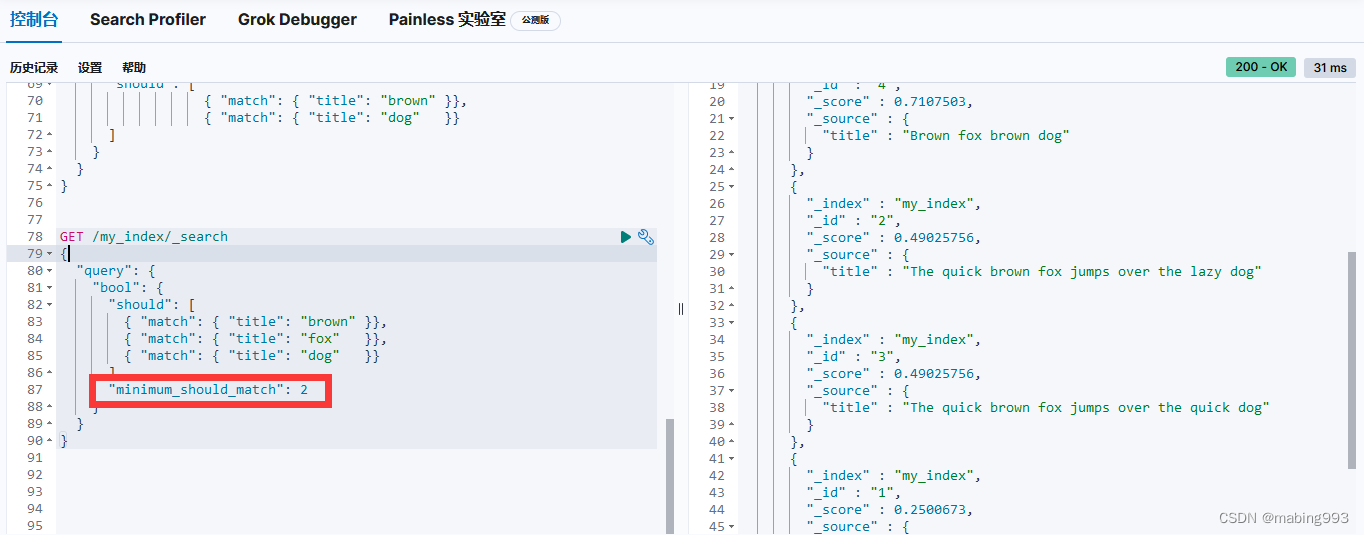
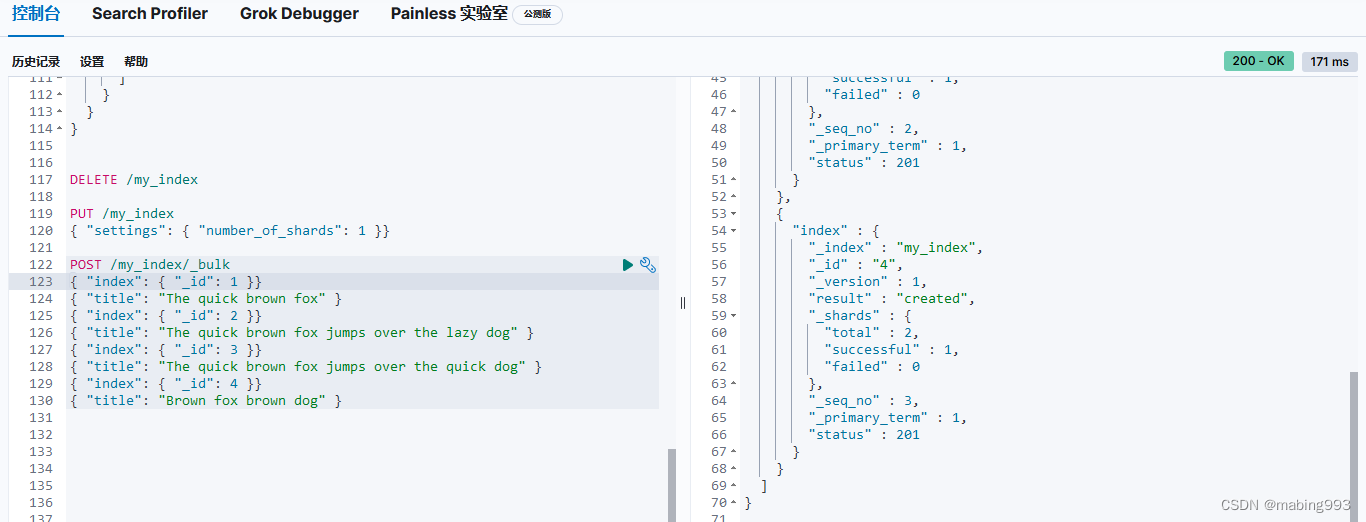
评分采用词 quick 在相关文档的 title 字段中出现的频率,以及字段的长度(即字段越短相关度越高)相结合的计算方式。
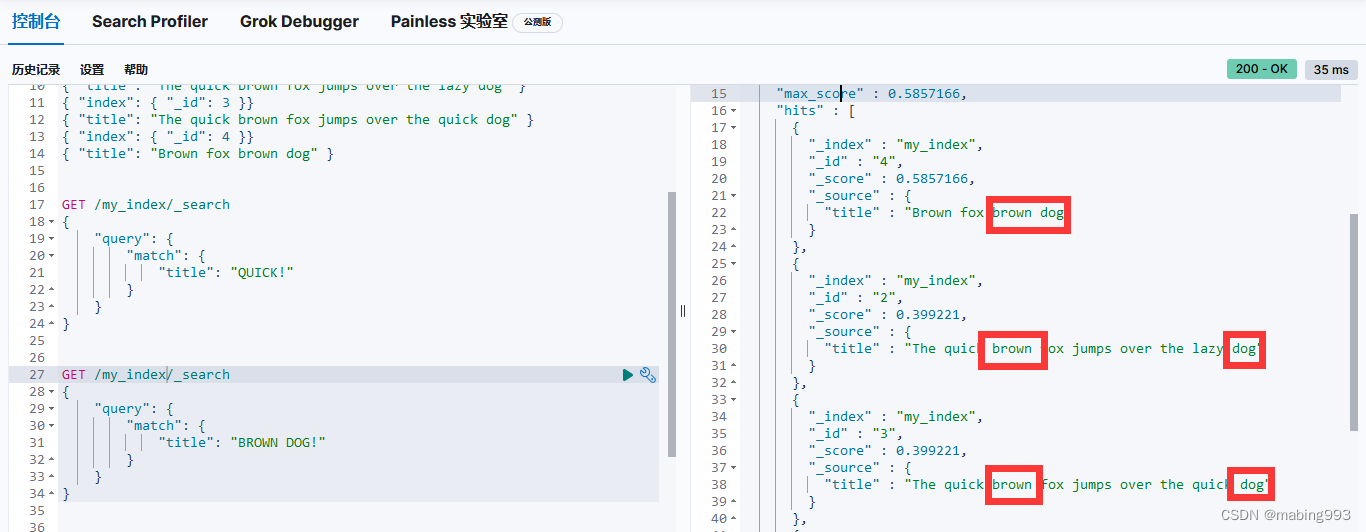
文档 4 最相关,因为它包含词 "brown" 两次以及 "dog" 一次。
文档 2、3 同时包含 brown 和 dog 各一次,而且它们 title 字段的长度相同,所以具有相同的评分。
文档 1 也能匹配,尽管它只有 brown 没有 dog 。
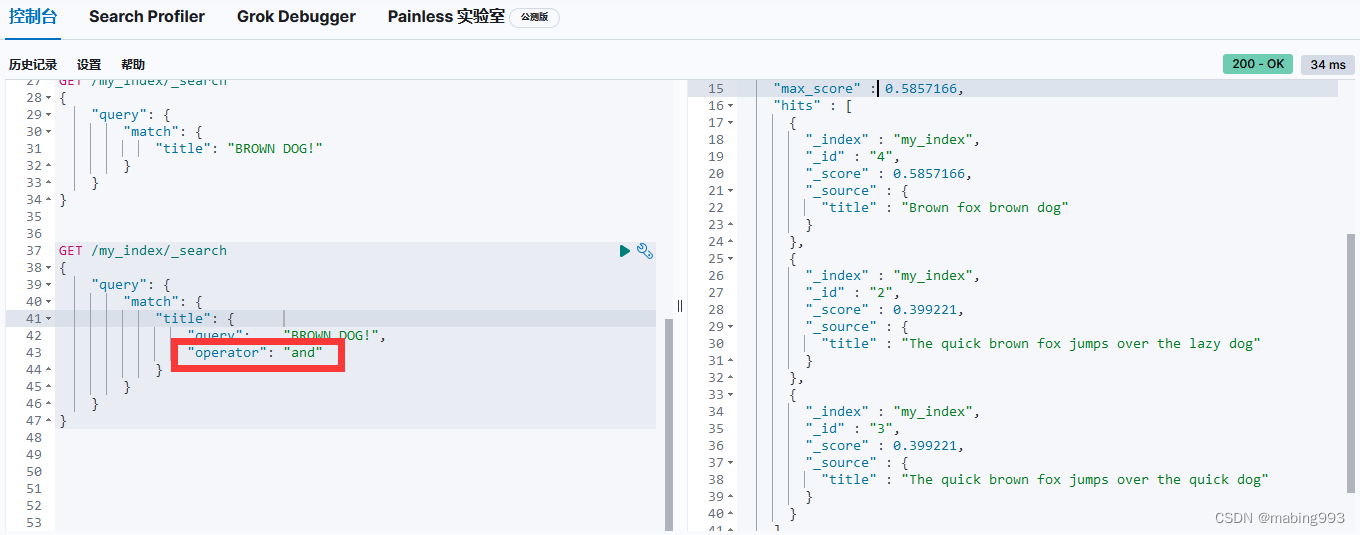
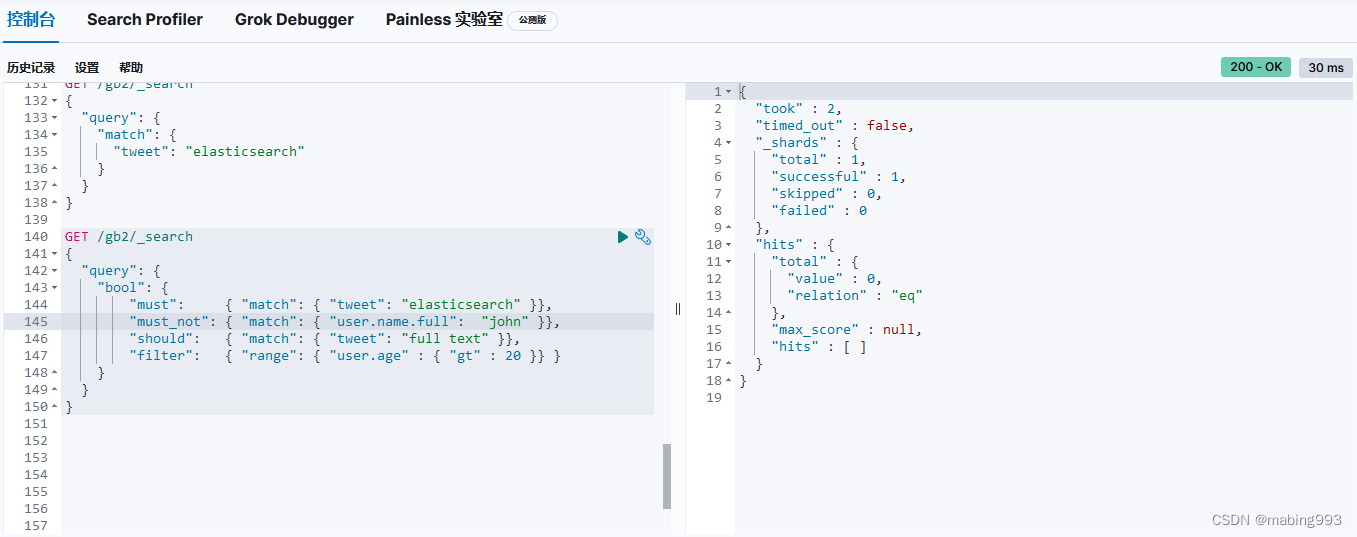
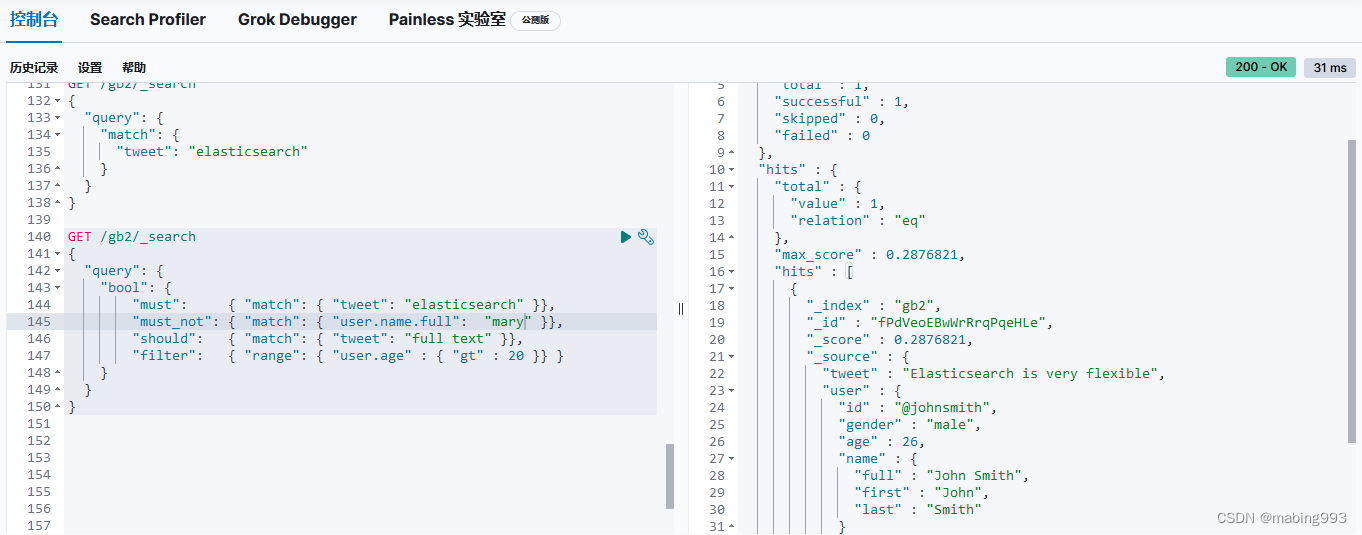
bool 查询会为每个文档计算相关度评分 _score ,再将所有匹配的 must 和 should 语句的分数 _score 求和,最后除以 must 和 should 语句的总数。
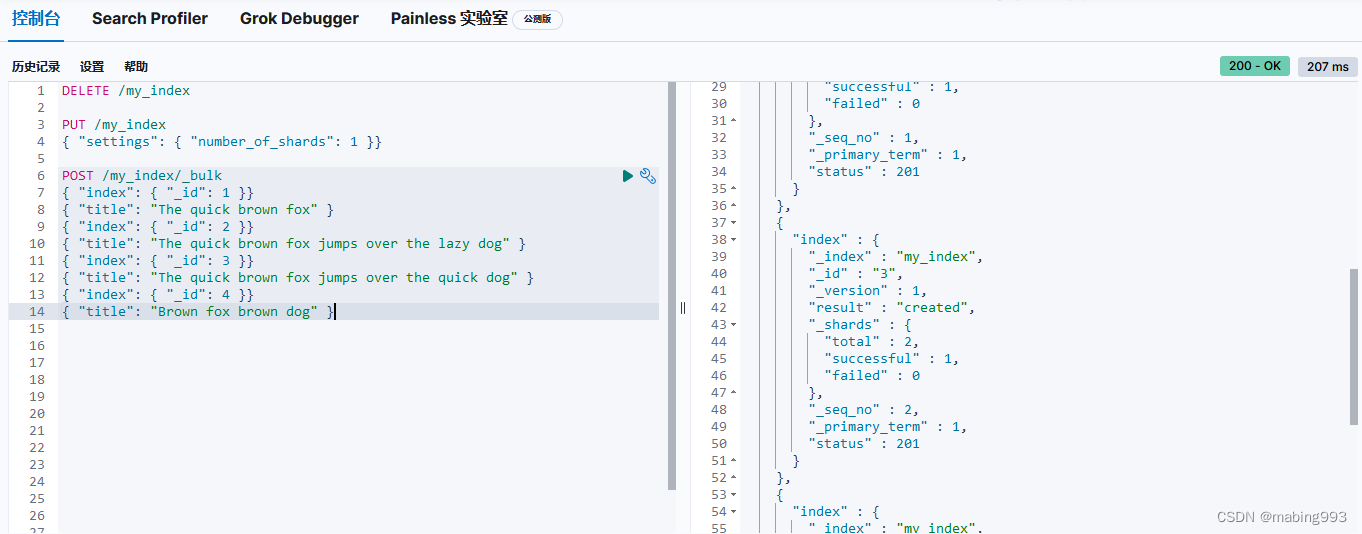
must_not 语句不会影响评分,它的作用只是将不相关的文档排除。
所有 must 语句必须匹配,所有 must_not 语句都必须不匹配,但有多少 should 语句应该匹配呢?默认情况下,没有 should 语句是必须匹配的,只有一个例外:那就是当没有 must 语句的时候,至少有一个 should 语句必须匹配。
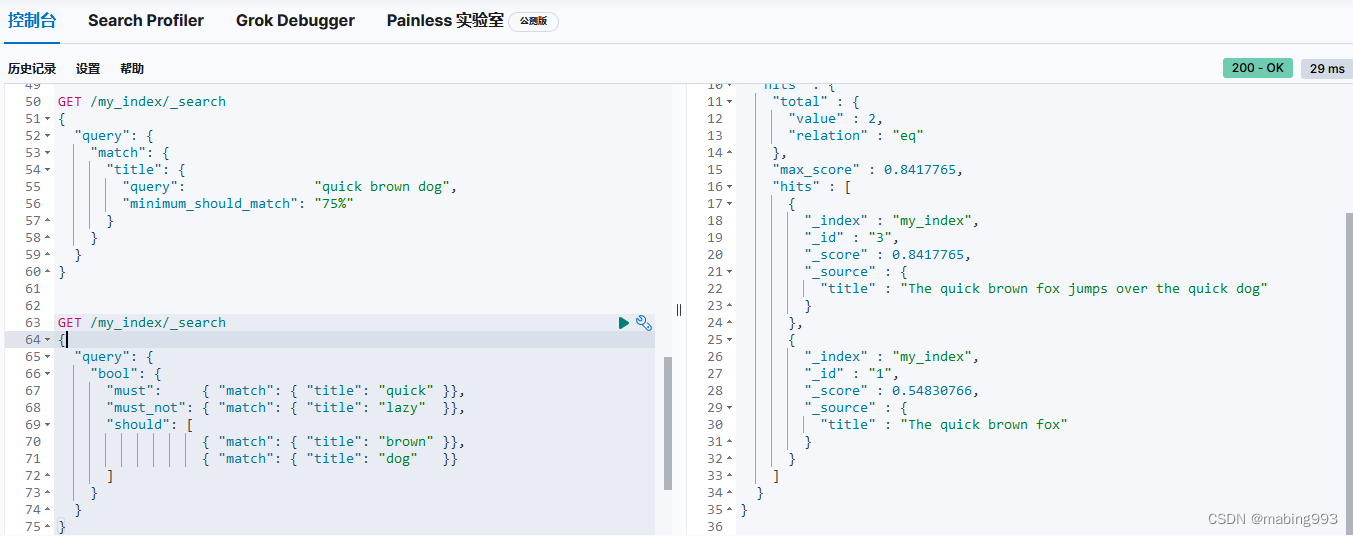
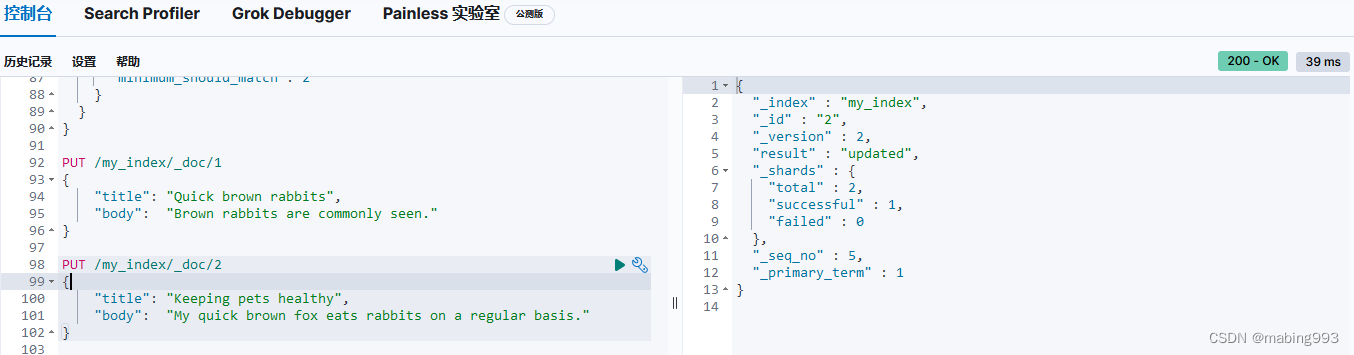
这个查询结果会将所有满足以下条件的文档返回: title 字段包含 "brown" AND "fox" 、"brown" AND "dog" 或 "fox" AND "dog" 。如果有文档包含所有三个条件,它会比只包含两个的文档更相关。
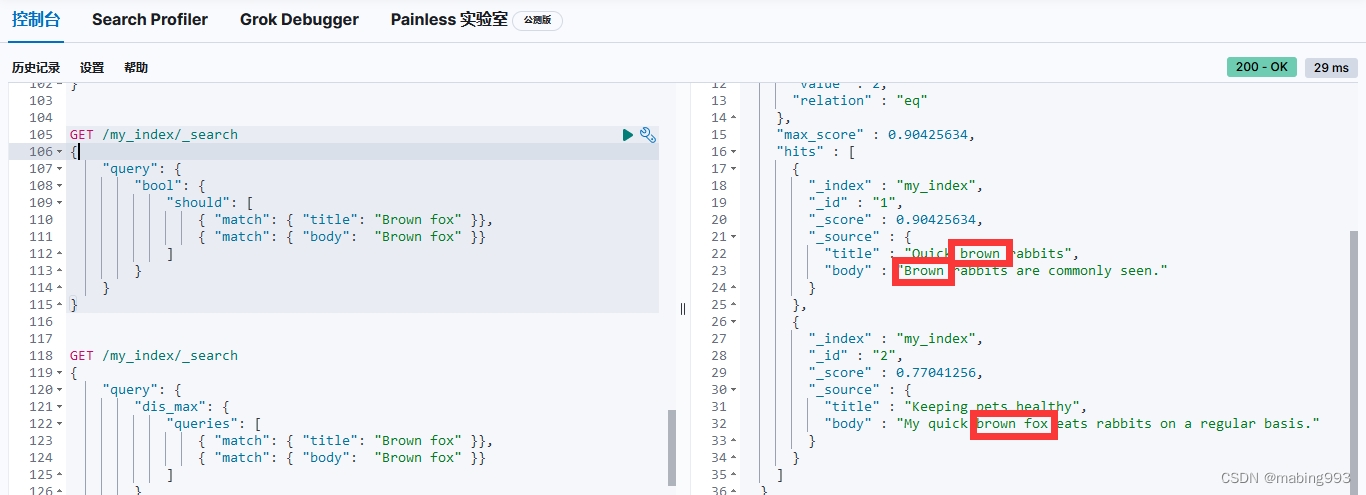

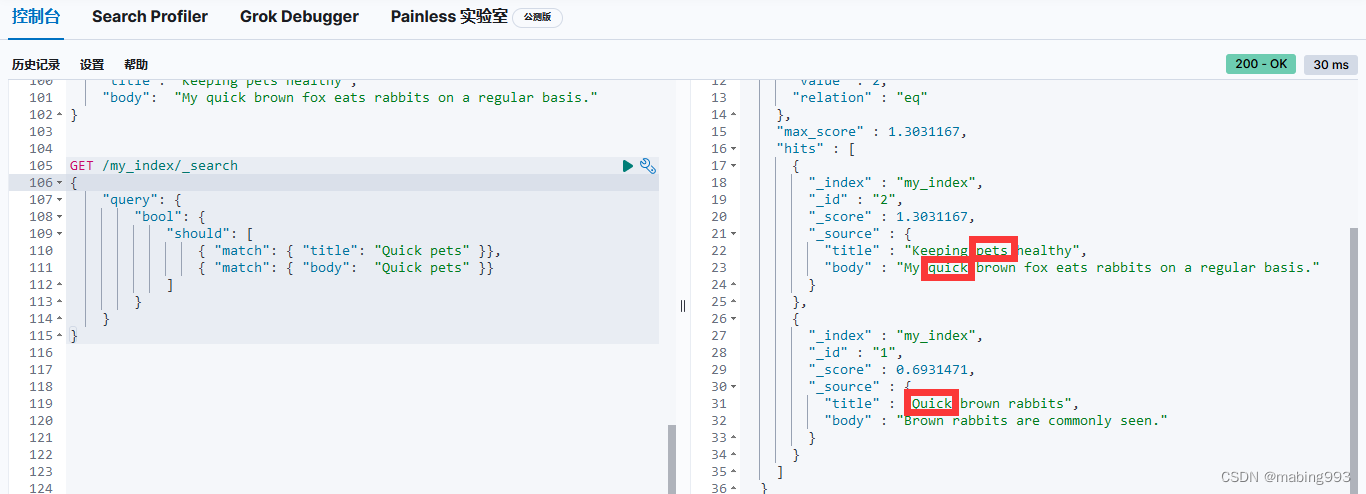
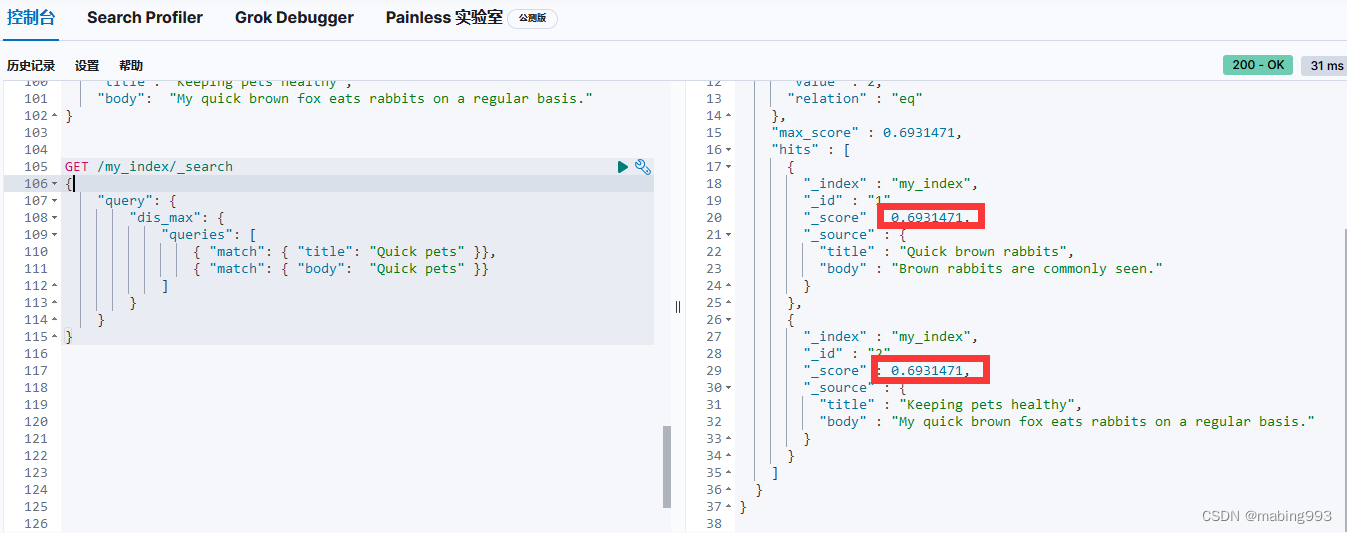

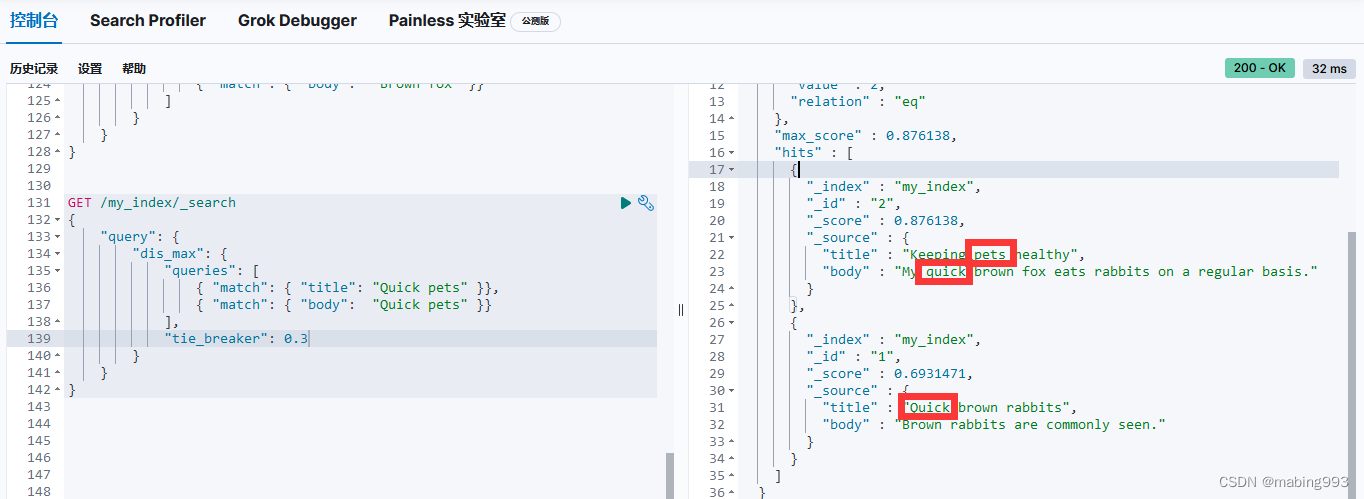


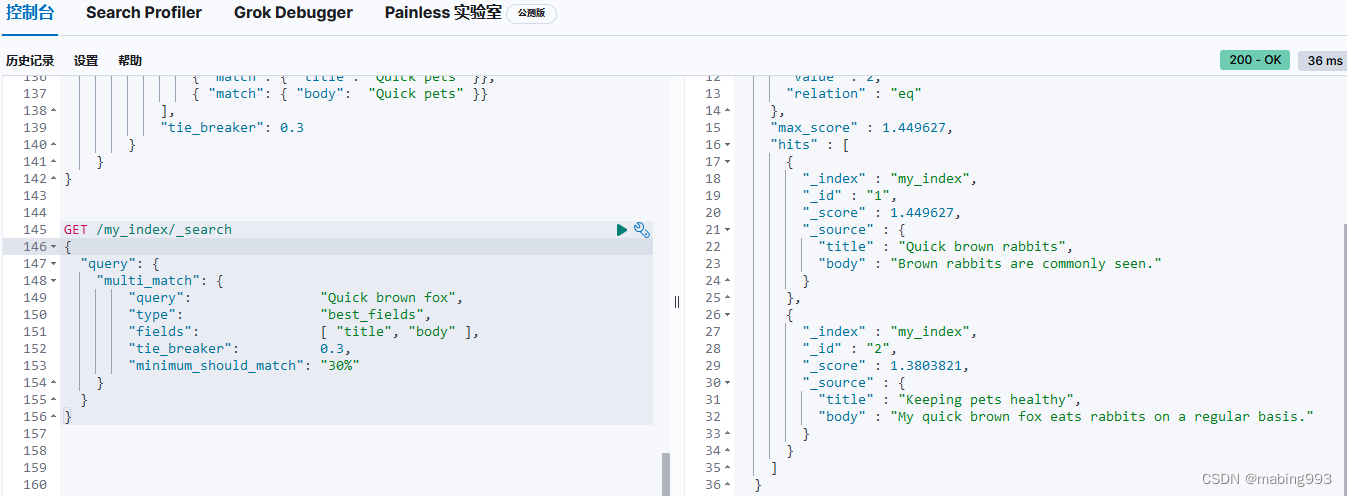


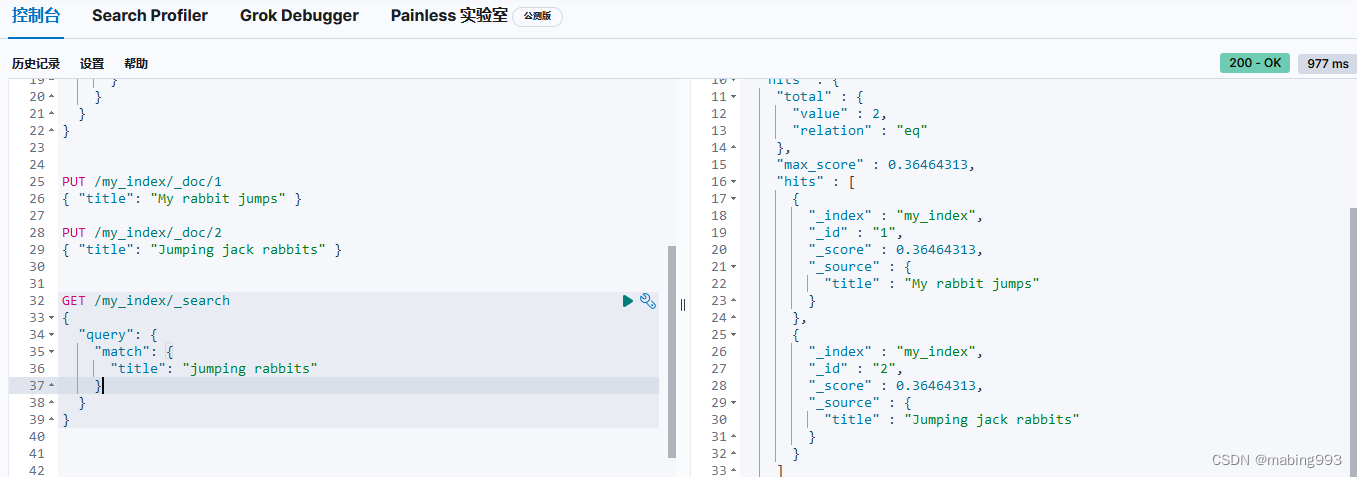
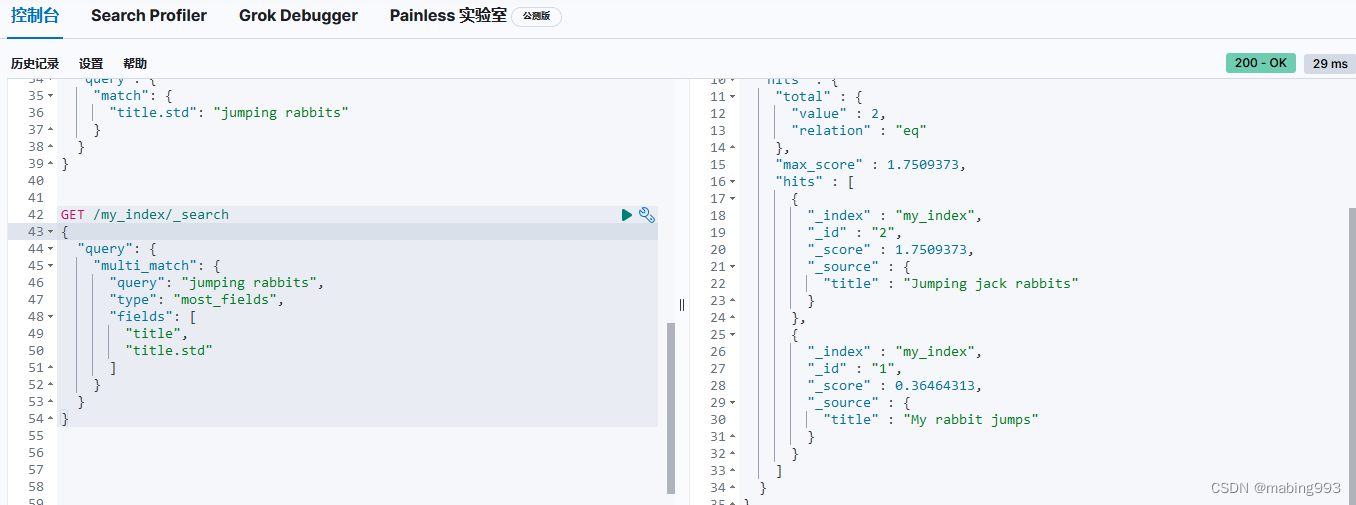
因为有了 english 分析器,这个查询是在查找以 jump 和 rabbit 这两个被提取词的文档。两个文档的 title 字段都同时包括这两个词,所以两个文档得到的评分也相同。
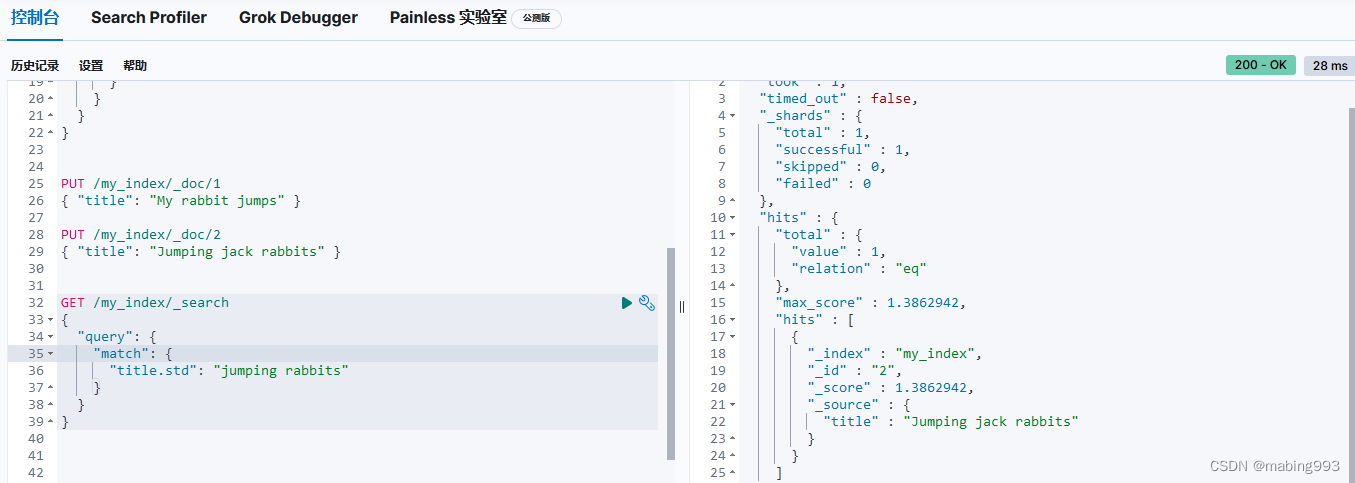
如果只是查询 title.std 字段,那么只有文档 2 是匹配的。尽管如此,如果同时查询两个字段,然后使用 bool 查询将评分结果 合并 ,那么两个文档都是匹配的( title 字段的作用),而且文档 2 的相关度评分更高( title.std 字段的作用)。
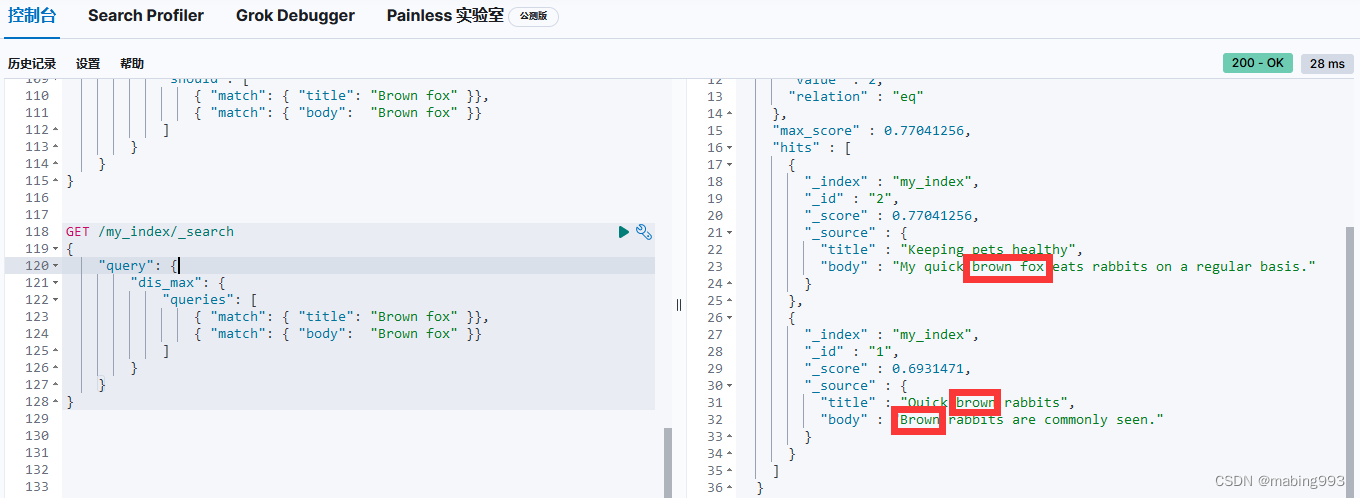
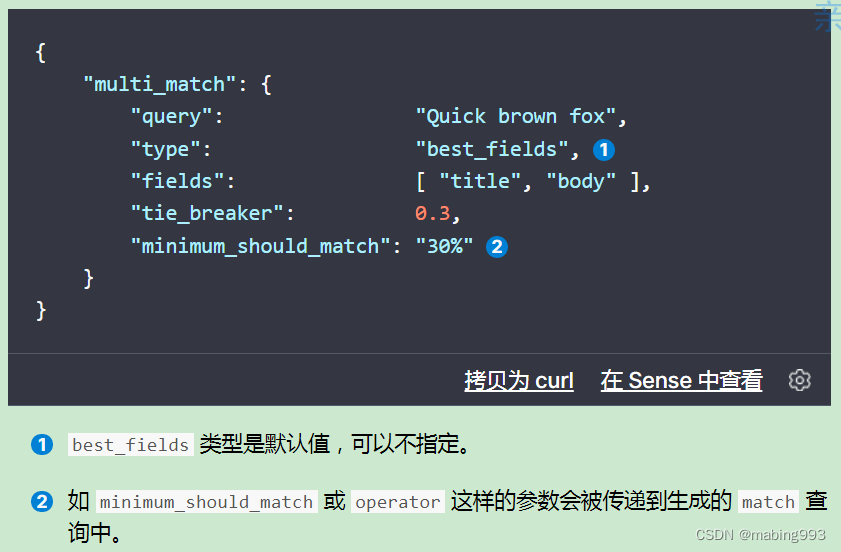
我们希望将所有匹配字段的评分合并起来,所以使用 most_fields 类型。这让 multi_match 查询用 bool 查询将两个字段语句包在里面,而不是使用 dis_max 查询。
自定义 _all 字段
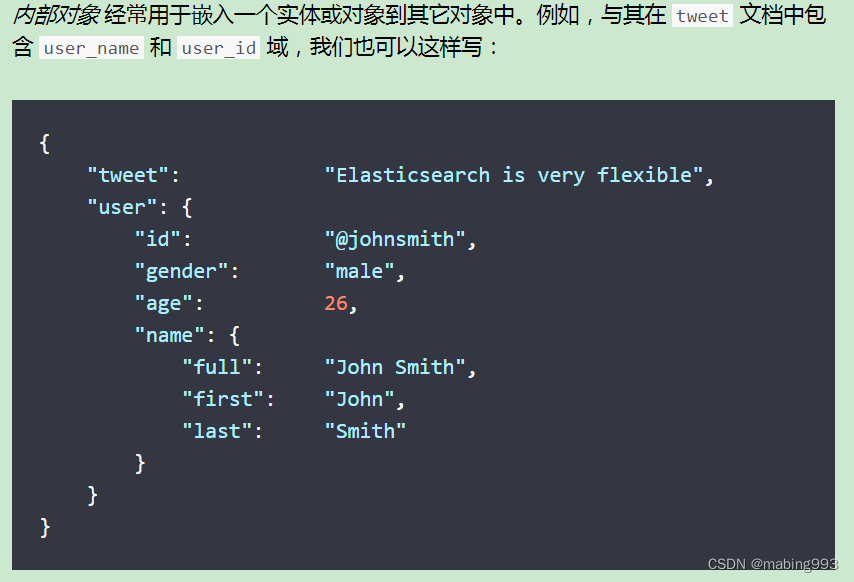
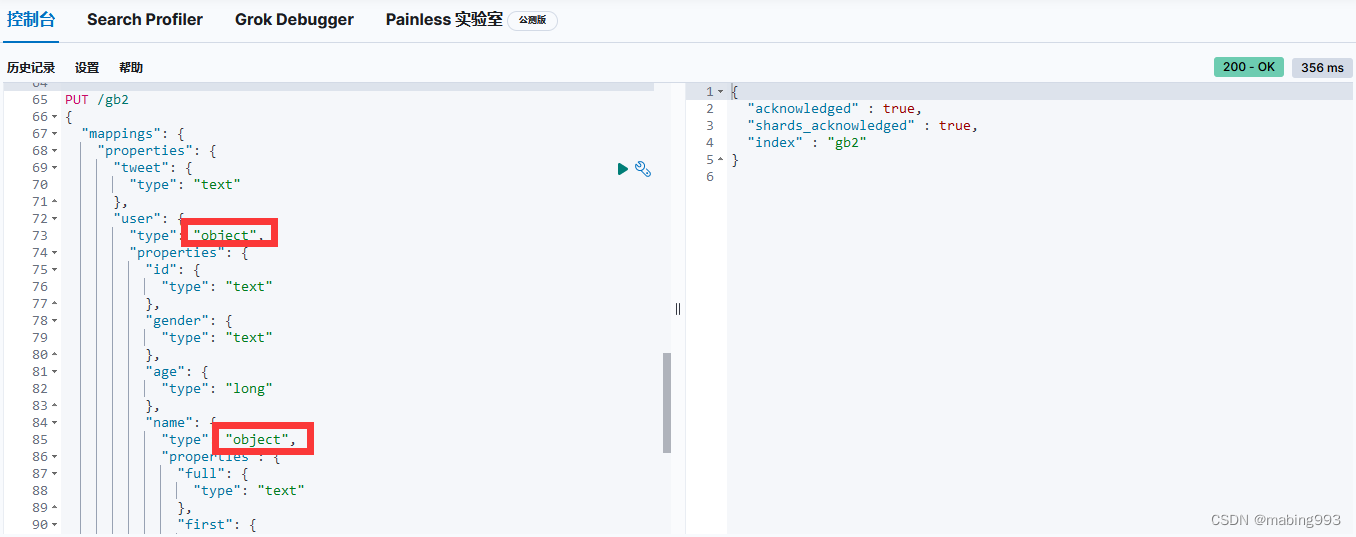
在 all-field 字段中,我们解释过 _all 字段的索引方式是将所有其他字段的值作为一个大字符串索引的。然而这么做并不十分灵活,为了灵活我们可以给人名添加一个自定义 _all 字段,再为地址添加另一个 _all 字段。
Elasticsearch 在字段映射中为我们提供 copy_to 参数来实现这个功能:
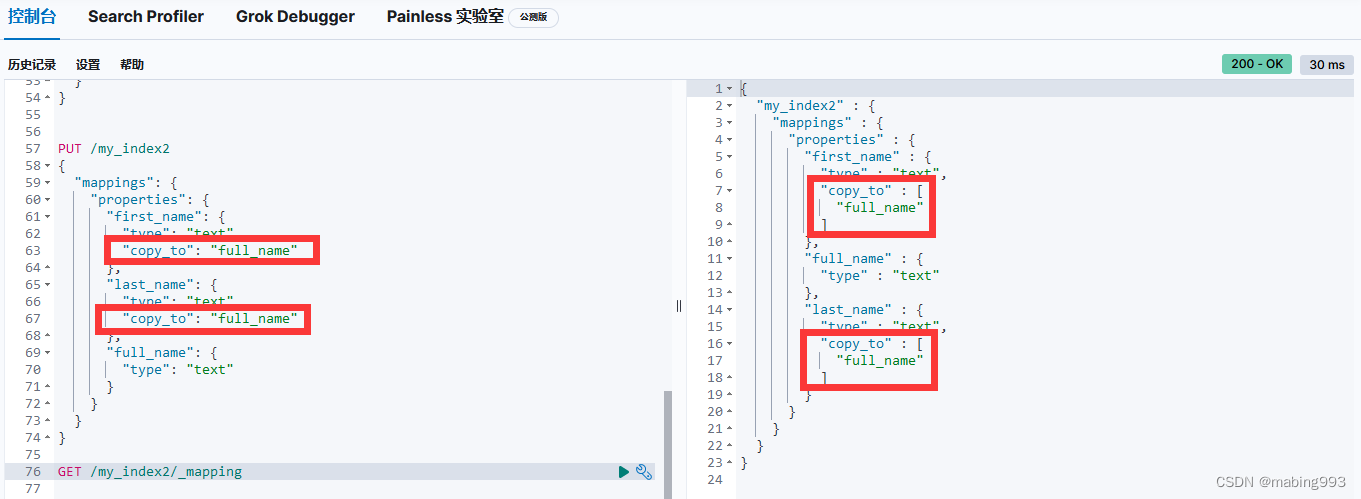
有了这个映射,我们可以用 first_name 来查询名,用 last_name 来查询姓,或者直接使用 full_name 查询整个姓名。
first_name 和 last_name 的映射并不影响 full_name 如何被索引, full_name 将两个字段的内容复制到本地,然后根据 full_name 的映射自行索引。
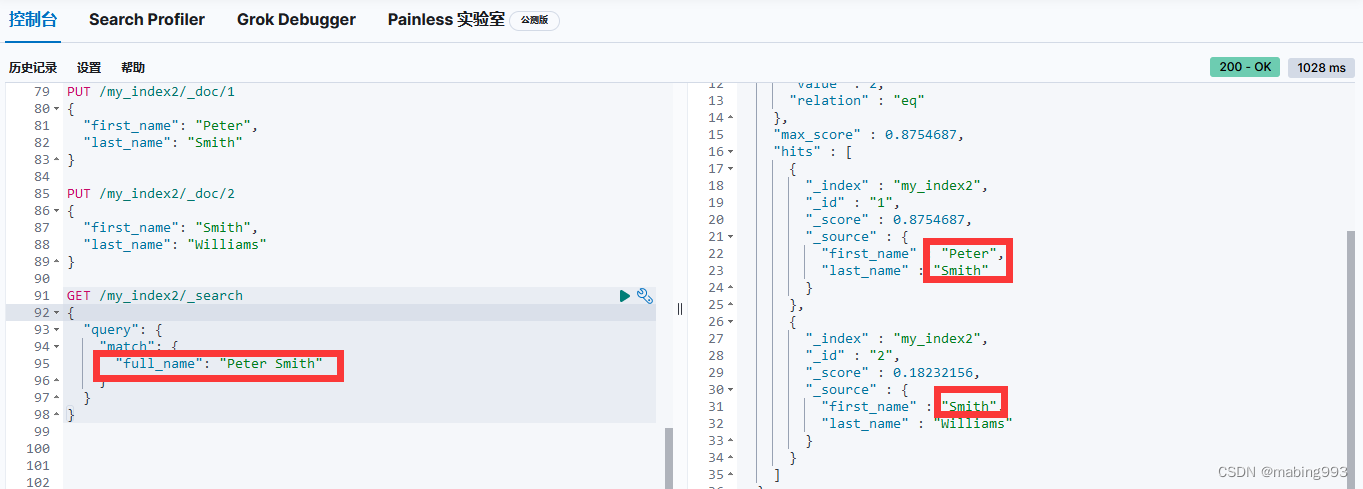
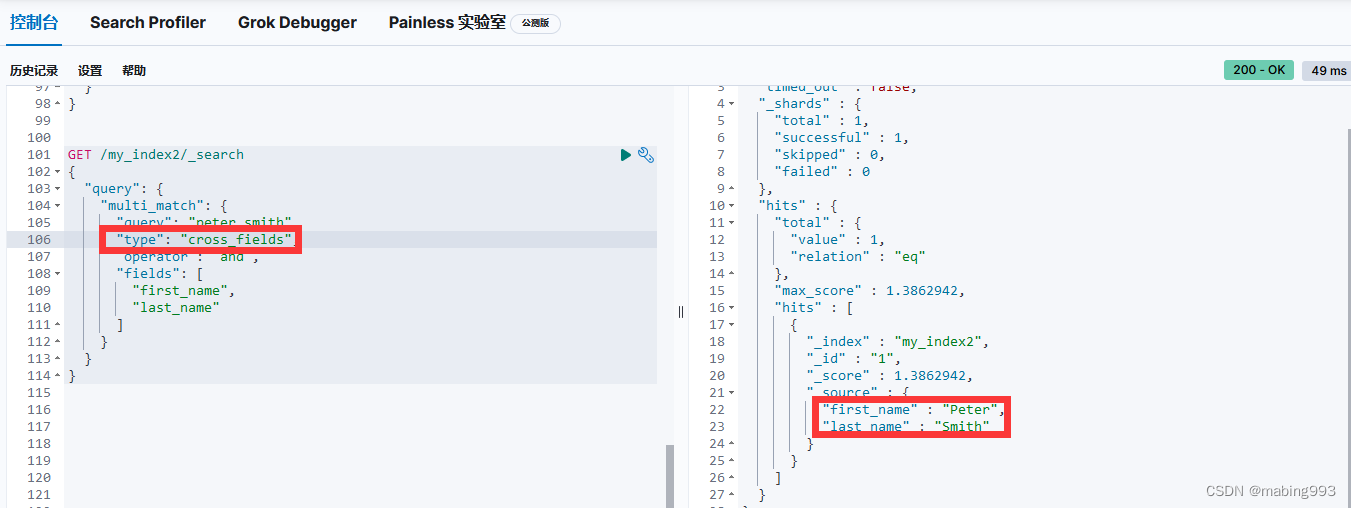
字段中心式对于匹配的文档, peter 和 smith 都必须同时出现在相同字段中,要么是 first_name 字段,要么 last_name 字段:
(+first_name:peter +first_name:smith)
(+last_name:peter +last_name:smith)
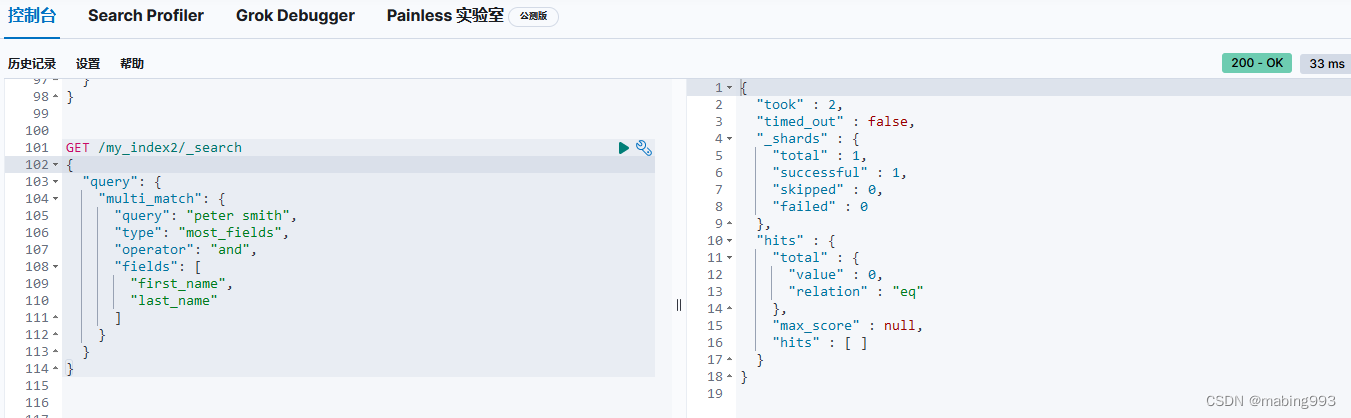
词中心式 会使用以下逻辑:
+(first_name:peter last_name:peter)
+(first_name:smith last_name:smith)
换句话说,词 peter 和 smith 都必须出现,但是可以出现在任意字段中。
cross_fields 类型首先分析查询字符串并生成一个词列表,然后它从所有字段中依次搜索每个词。这种不同的搜索方式很自然的解决了 字段中心式 查询三个问题中的二个。剩下的问题是逆向文档频率不同。
幸运的是 cross_fields 类型也能解决这个问题,通过 validate-query 可以看到它通过 混合 不同字段逆向索引文档频率的方式解决了词频的问题:
+blended("peter", fields: [first_name, last_name])
+blended("smith", fields: [first_name, last_name])
换句话说,它会同时在 first_name 和 last_name 两个字段中查找 smith 的 IDF ,然后用两者的最小值作为两个字段的 IDF 。结果实际上就是 smith 会被认为既是个平常的姓,也是平常的名。
为了让 cross_fields 查询以最优方式工作,所有的字段都须使用相同的分析器,具有相同分析器的字段会被分组在一起作为混合字段使用。
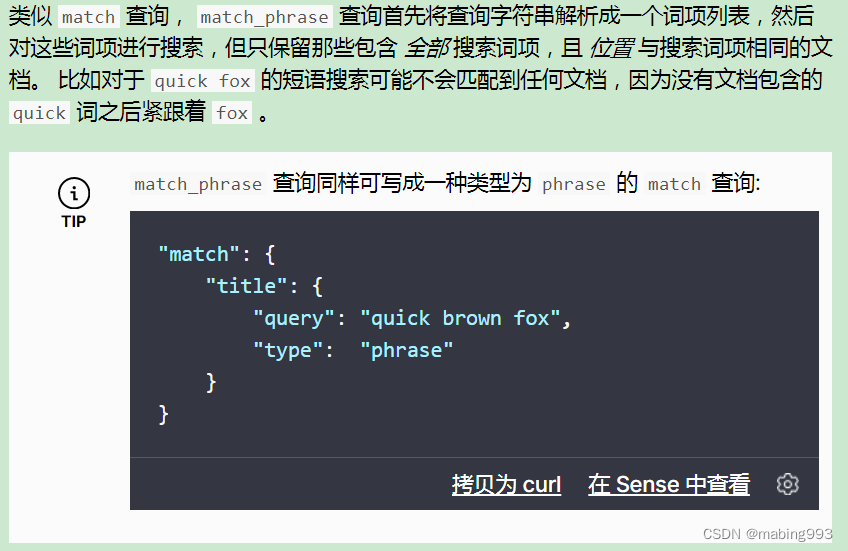
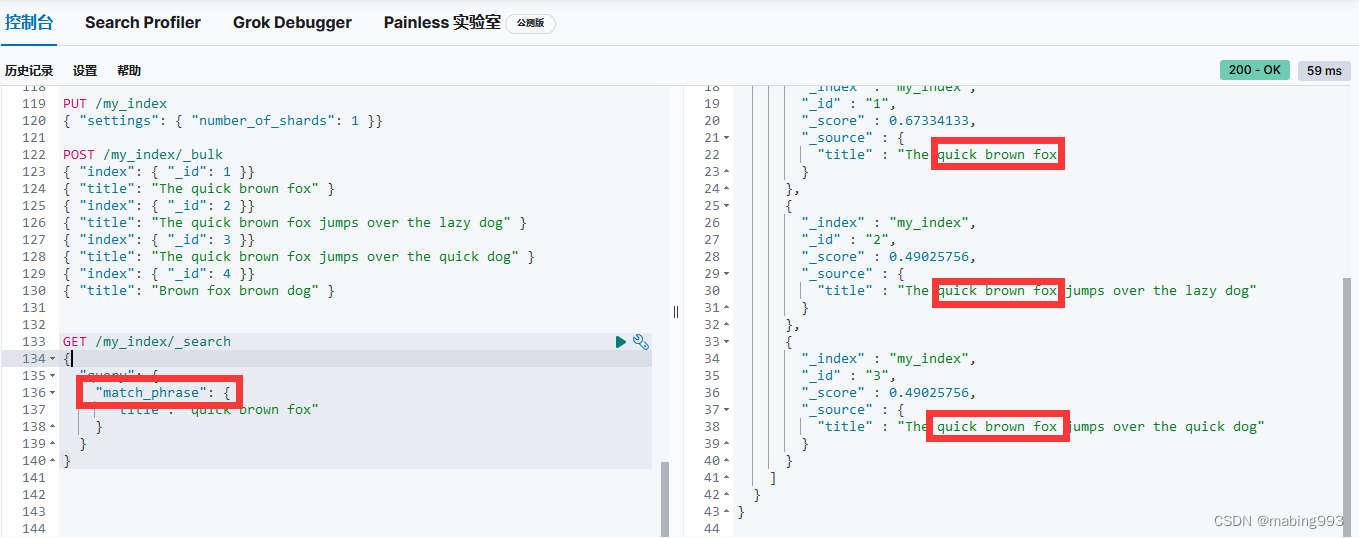

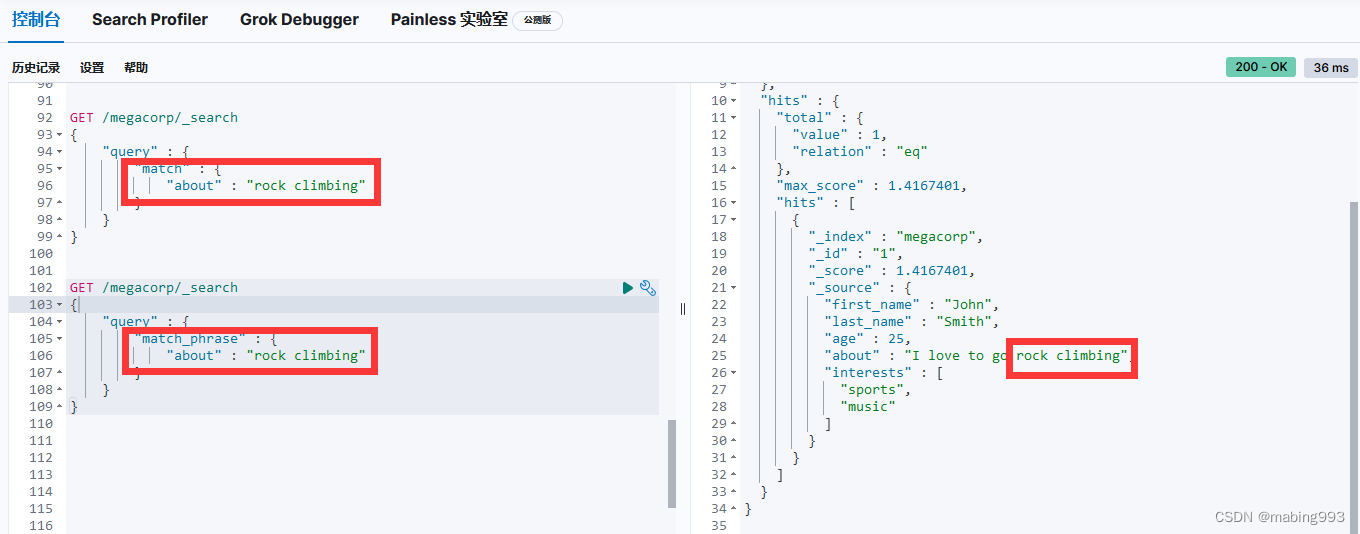
精确短语匹配 或许是过于严格了。也许我们想要包含 “quick brown fox” 的文档也能够匹配 “quick fox,” , 尽管情形不完全相同。
我们能够通过使用 slop 参数将灵活度引入短语匹配中,slop 参数告诉 match_phrase 查询词条相隔多远时仍然能将文档视为匹配。相隔多远的意思是为了让查询和文档匹配需要移动词条多少次?
为了让查询 The brown fox 能匹配一个包含 The quick brown fox 的文档, 我们需要 slop 的值为 1 。
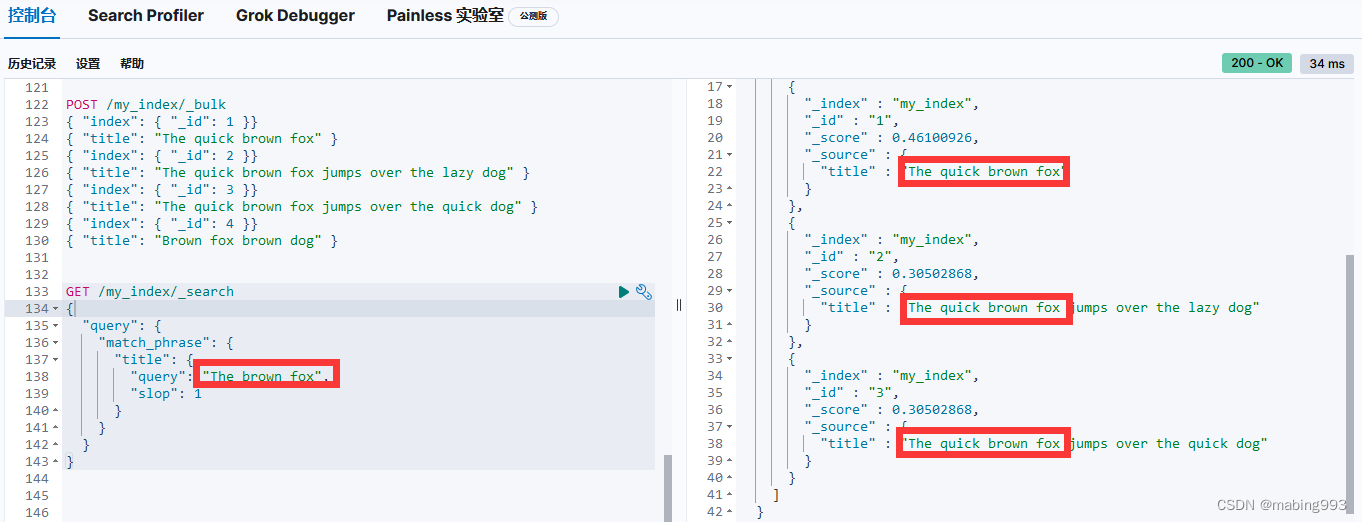

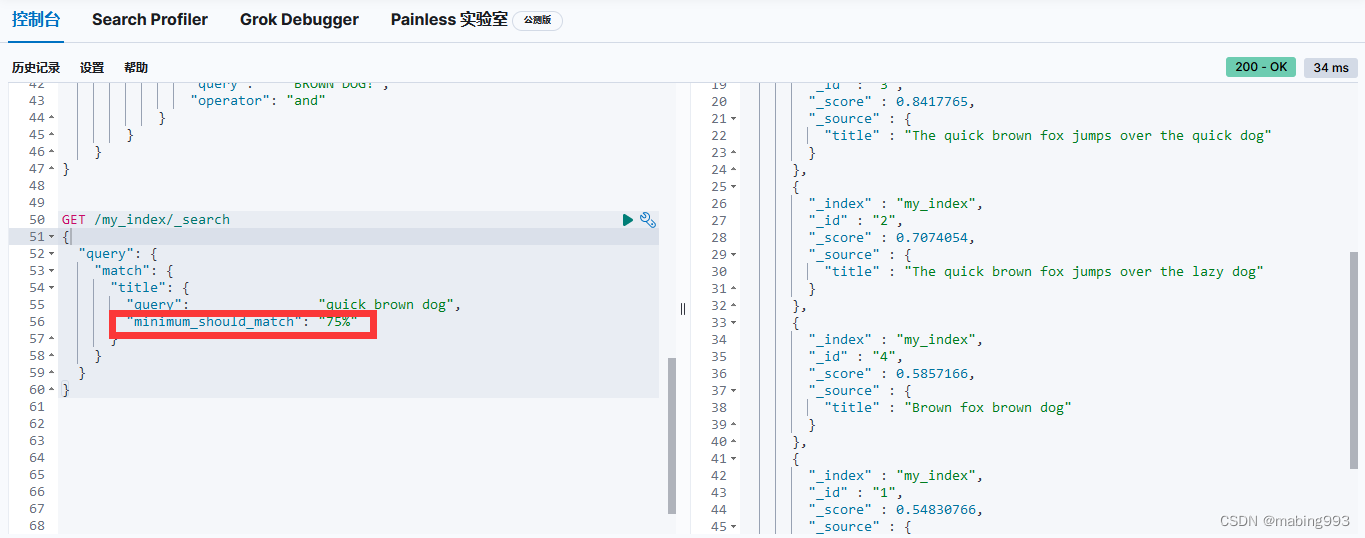
我们可以将一个简单的 match 查询作为一个 must 子句。 这个查询将决定哪些文档需要被包含到结果集中。 我们可以用 minimum_should_match 参数去除长尾。 然后我们可以以 should 子句的形式添加更多特定查询。 每一个匹配成功的都会增加匹配文档的相关度。
must 子句从结果集中包含或者排除文档。
should 子句增加了匹配到文档的相关度评分。
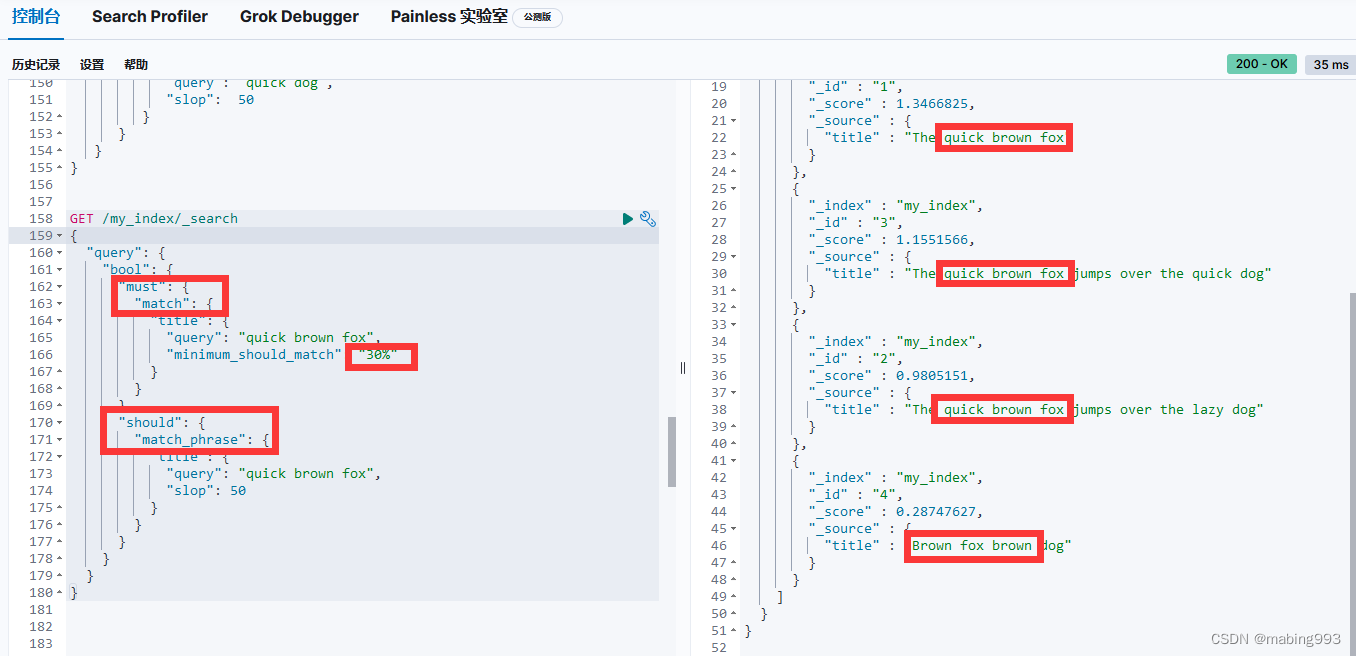

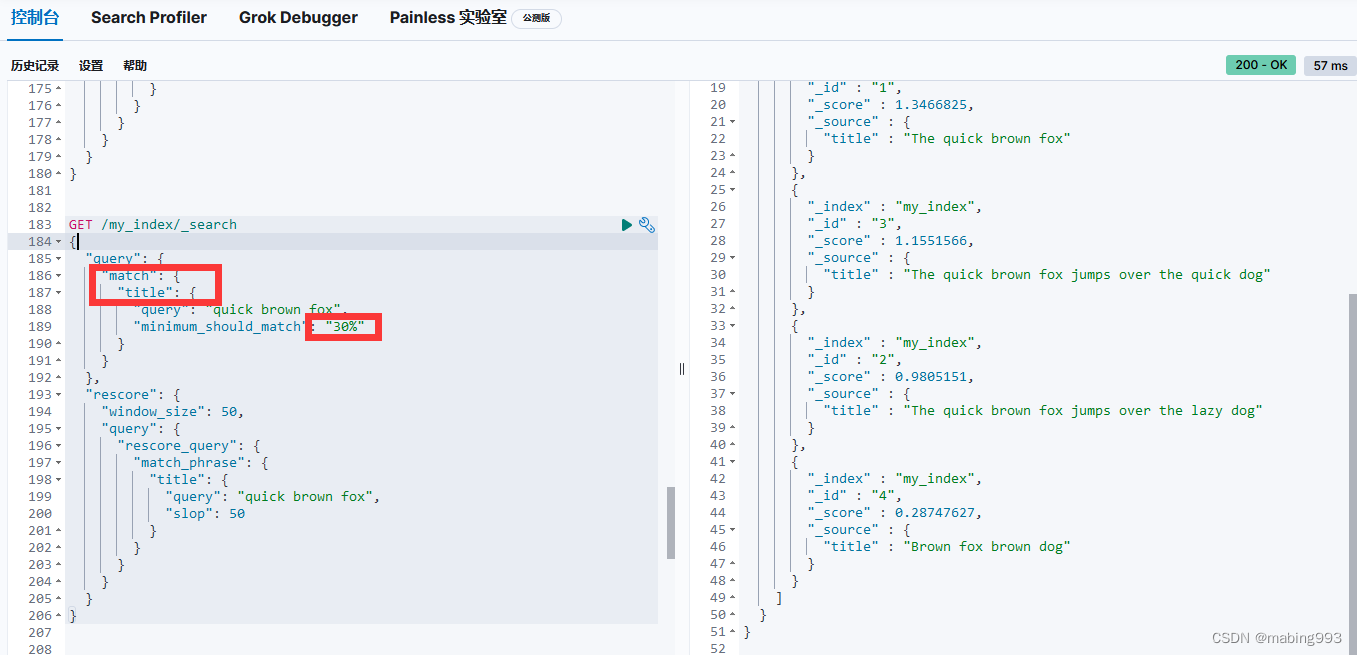

为了获得两方面的优势,我们可以使用multifields(多字段)对 title 字段建立两次索引: 一次使用 english(英语)分析器,另一次使用 standard(标准)分析器。
主 title 字段使用 standard(标准)分析器。
title.english 子字段使用 english(英语)分析器。
使用most_fields query type(多字段搜索语法)让我们可以用多个字段来匹配同一段文本。
由于 title.english 字段的切词,无论我们的文档中是否含有单词 foxes 都会被搜索到,第二份文档的相关性排行要比第一份高, 因为在 title 字段中匹配到了单词 not 。
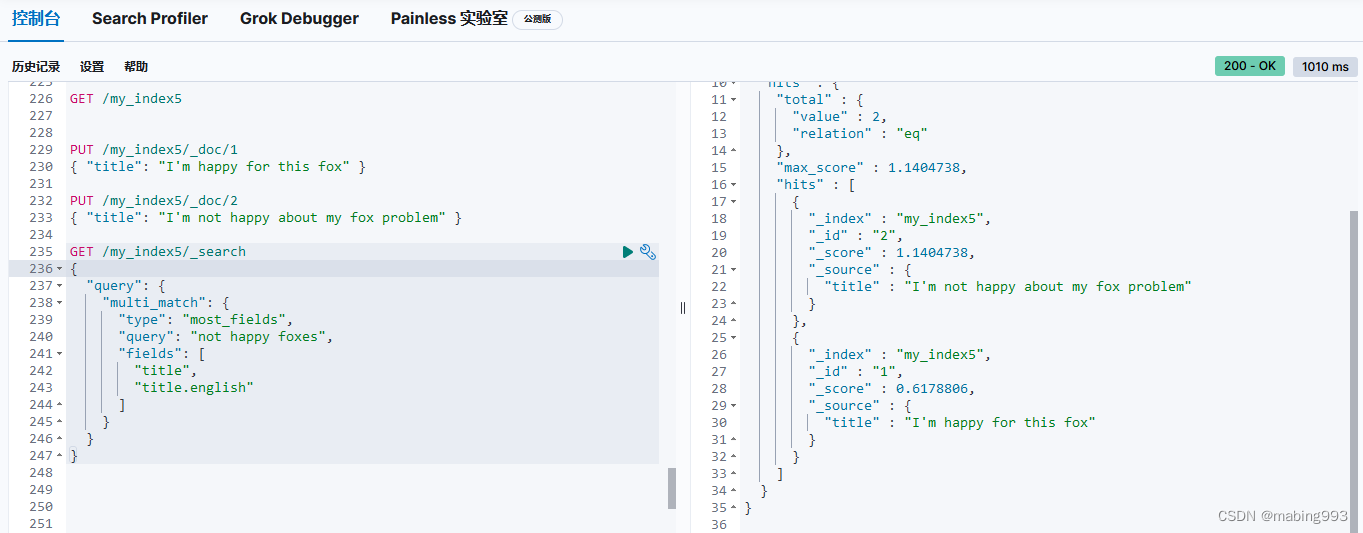
fuzzy 查询是 term 查询的模糊等价。 也许你很少直接使用它,但是理解它是如何工作的,可以帮助你在更高级别的 match 查询中使用模糊性。
fuzzy 查询是一个词项级别的查询,所以它不做任何分析。它通过某个词项以及指定的 fuzziness 查找到词典中所有的词项。 fuzziness 默认设置为 AUTO 。
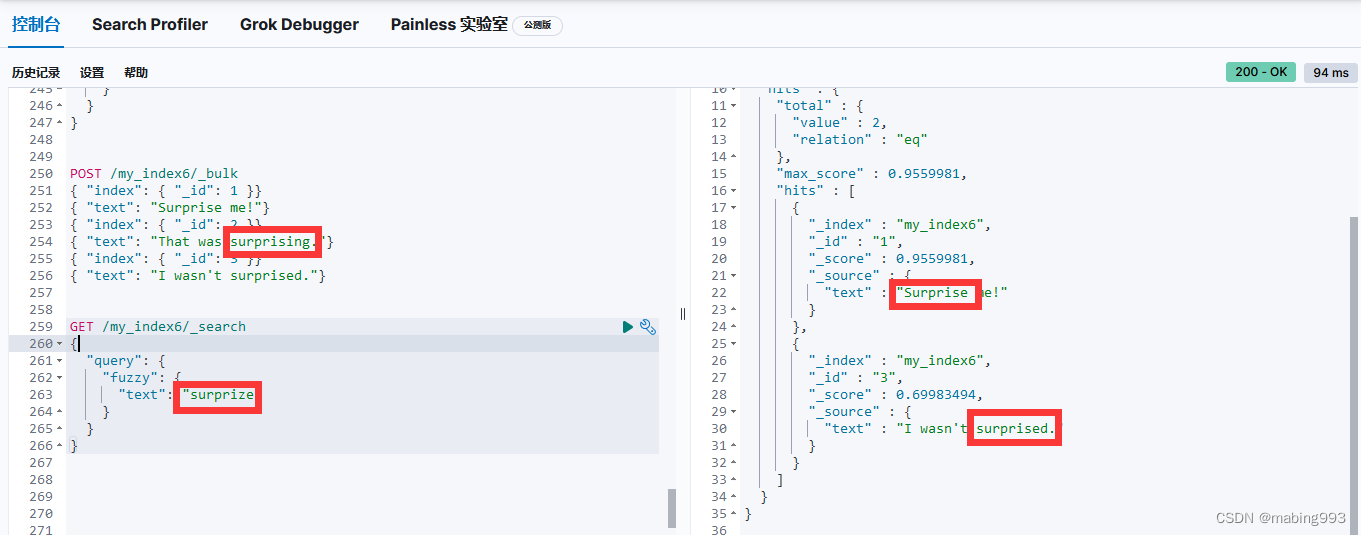
模糊性(Fuzziness)只能在 match 和 multi_match 查询中使用。不能使用在短语匹配、常用词项或 cross_fields 匹配。
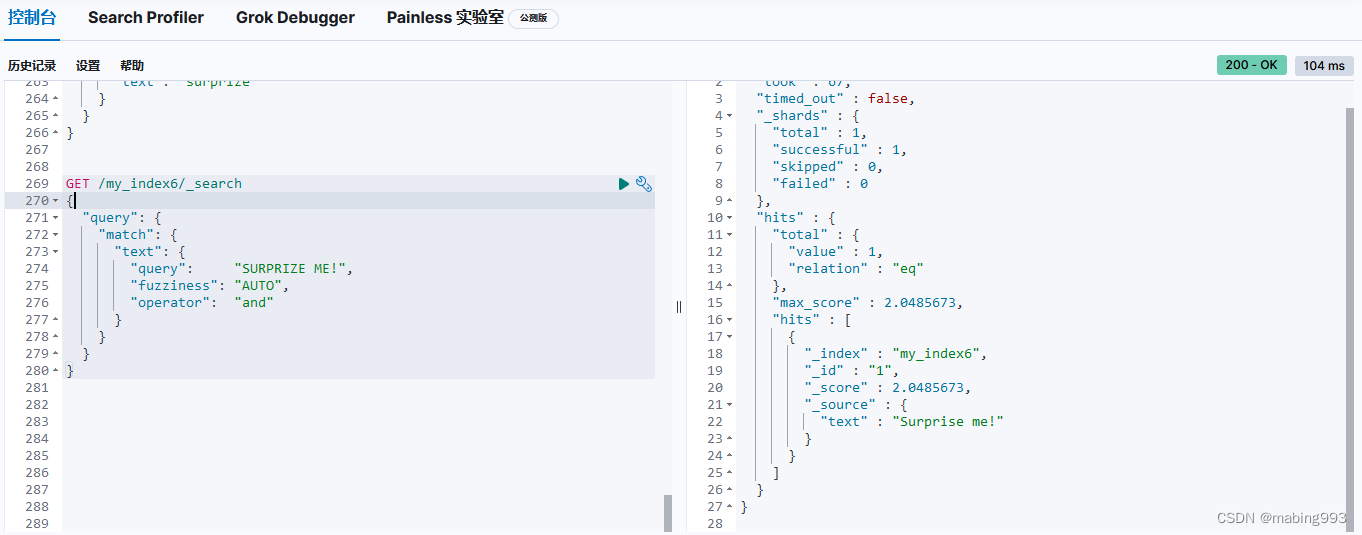

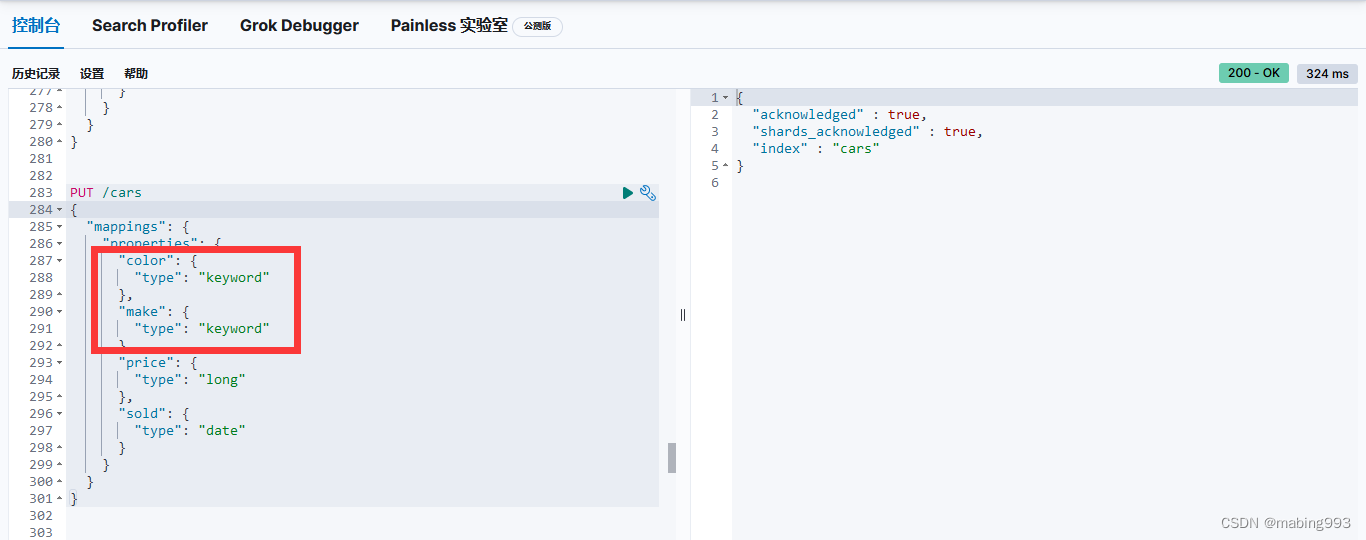
因为我们设置了 size 为 0 ,所以不会有 hits 搜索结果返回。
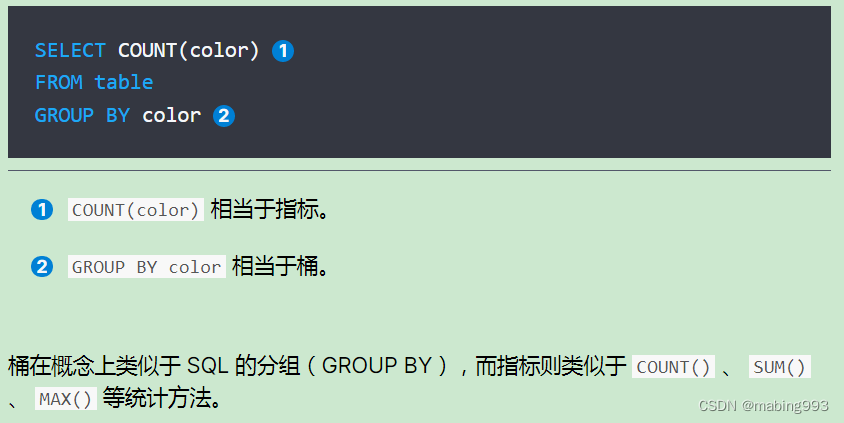
popular_colors 聚合是作为 aggregations 字段的一部分被返回的。
每个桶的 key 都与 color 字段里找到的唯一词对应。它总会包含 doc_count 字段,告诉我们包含该词项的文档数量。
每个桶的数量代表该颜色的文档数量。
响应包含多个桶,每个对应一个唯一颜色(例如:红 或 绿)。每个桶也包括 聚合进 该桶的所有文档的数量。例如,有四辆红色的车。
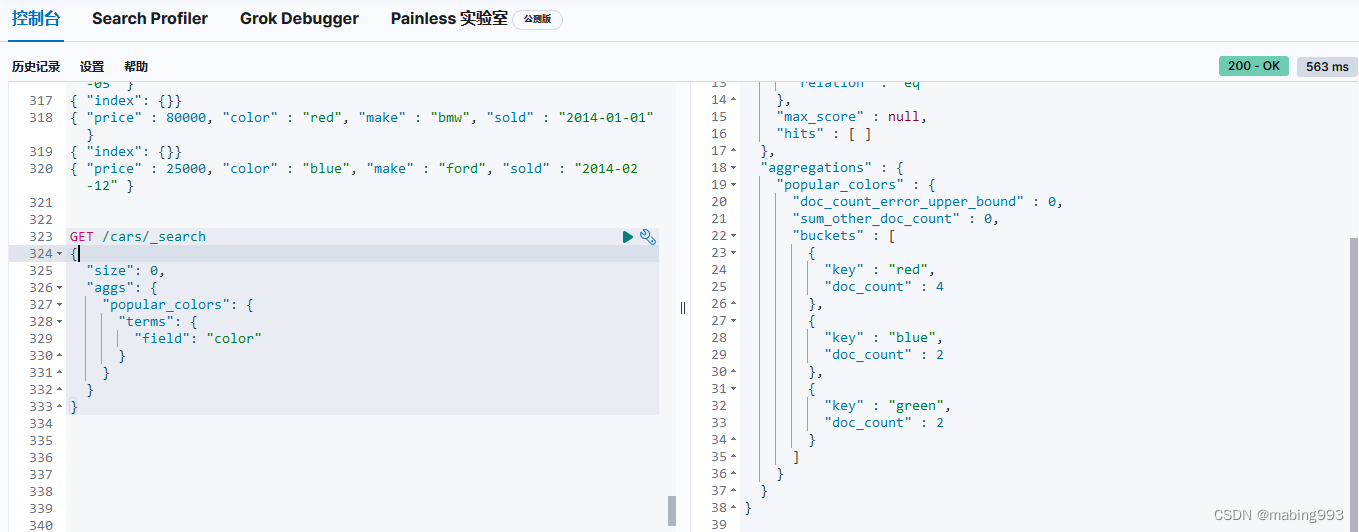
正如所见,我们用前面的例子加入了新的 aggs 层。这个新的聚合层让我们可以将 avg 度量嵌套置于 terms 桶内。实际上,这就为每个颜色生成了平均价格。
正如 颜色 的例子,我们需要给度量起一个名字( avg_price )这样可以稍后根据名字获取它的值。最后,我们指定度量本身( avg )以及我们想要计算平均值的字段( price )
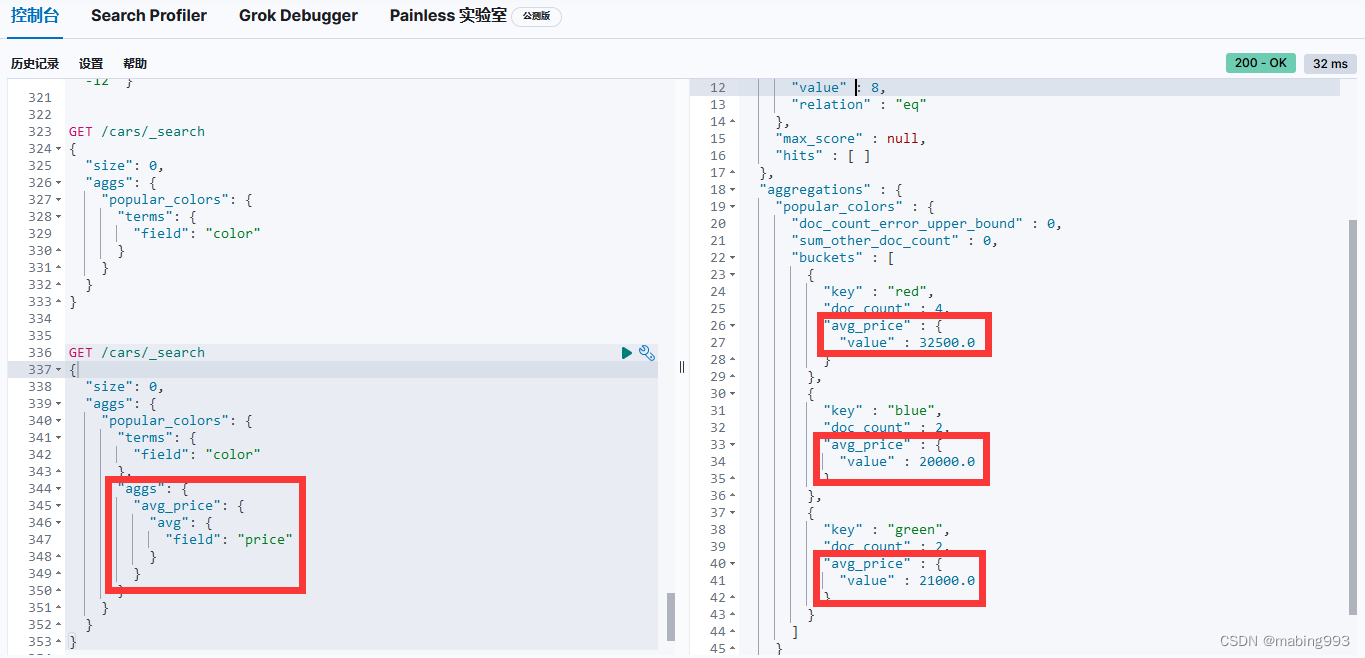
注意前例中的 avg_price 度量仍然保持原位。
另一个聚合 make 被加入到了 color 颜色桶中。
这个聚合是 terms 桶,它会为每个汽车制造商生成唯一的桶。
正如期望的那样,新的聚合嵌入在每个颜色桶中。
现在我们看见按不同制造商分解的每种颜色下车辆信息。
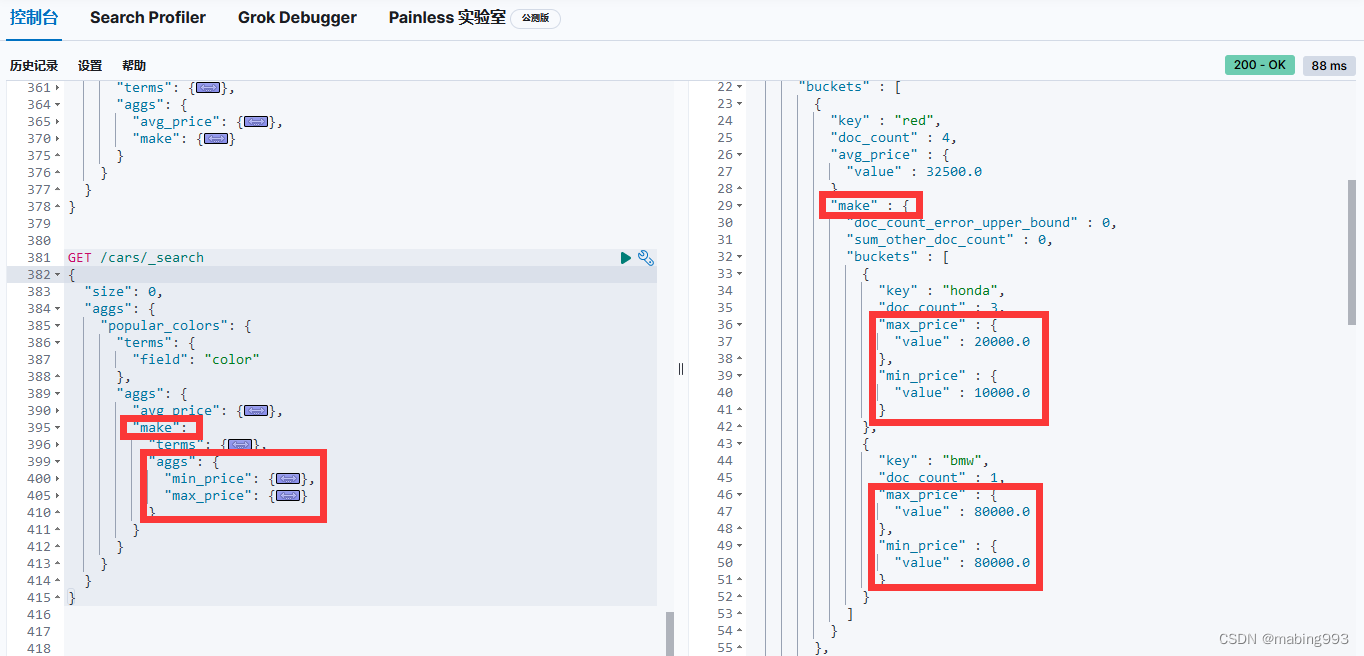
最终,我们看到前例中的 avg_price 度量仍然维持不变。
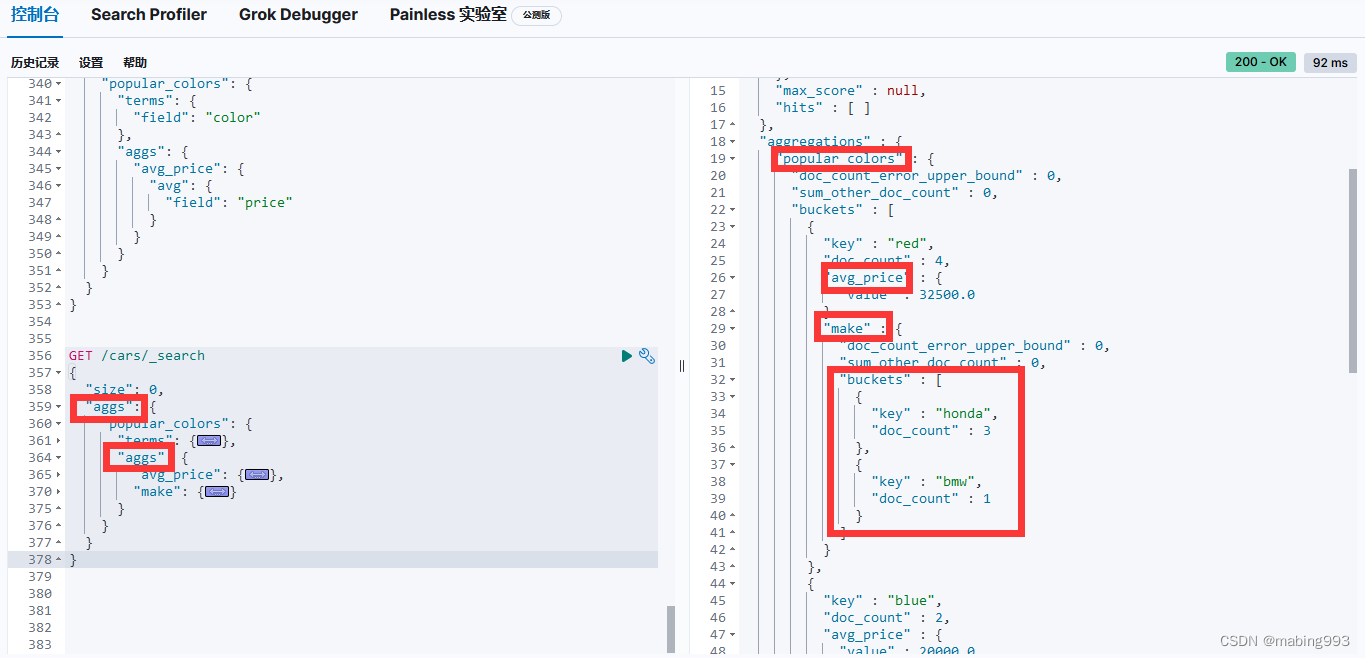
我们需要增加另外一个嵌套的 aggs 层级,然后包括 min 最小度量以及 max 最大度量。min 和 max 度量现在出现在每个汽车制造商( make )下面。
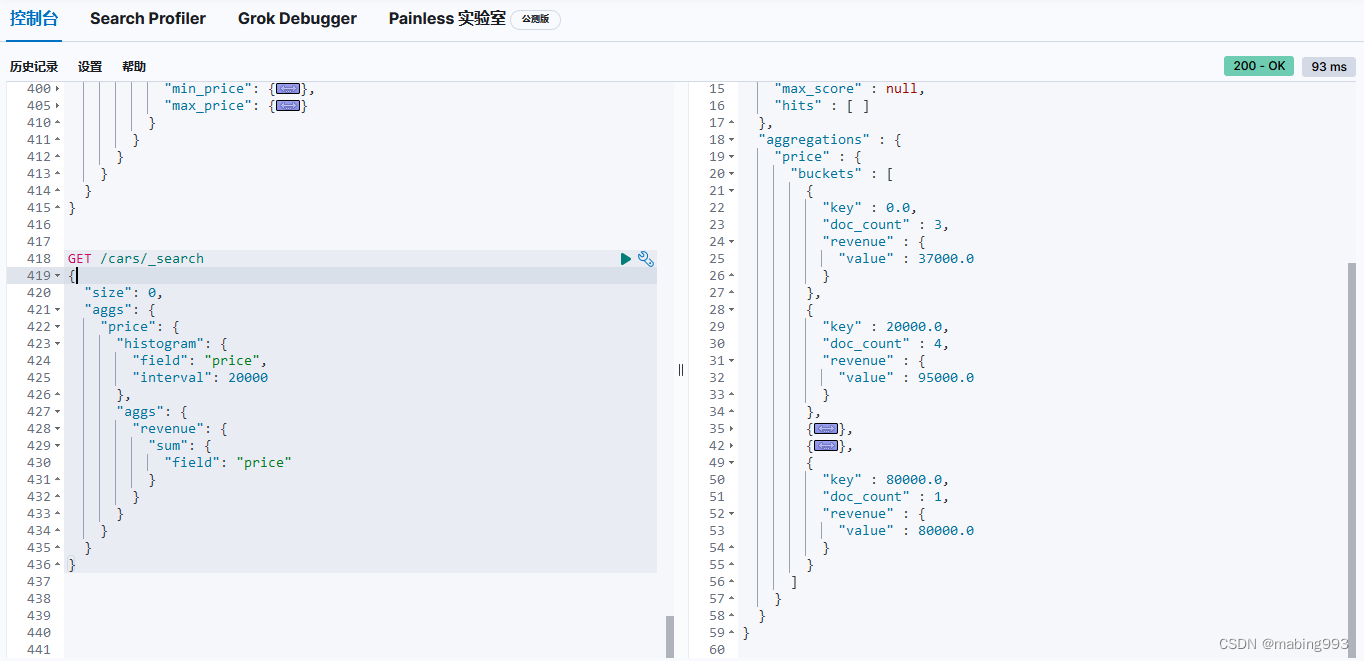
histogram 桶要求两个参数:一个数值字段以及一个定义桶大小间隔。
sum 度量嵌套在每个售价区间内,用来显示每个区间内的总收入。
date_histogram出错,暂时找不到原因
所有聚合的例子到目前为止,你可能已经注意到,我们的搜索请求省略了一个 query 。 整个请求只不过是一个聚合。
聚合可以与搜索请求同时执行,但是我们需要理解一个新概念: 范围 。 默认情况下,聚合与查询是对同一范围进行操作的,也就是说,聚合是基于我们查询匹配的文档集合进行计算的。查询(包括了一个过滤器)返回一组文档的子集,聚合正是操作这些文档。
因为聚合总是对查询范围内的结果进行操作的,所以一个隔离的聚合实际上是在对 match_all 的结果范围操作,即所有的文档。
一旦有了范围的概念,我们就能更进一步对聚合进行自定义。我们前面所有的示例都是对 所有 数据计算统计信息的:销量最高的汽车,所有汽车的平均售价,最佳销售月份等等。
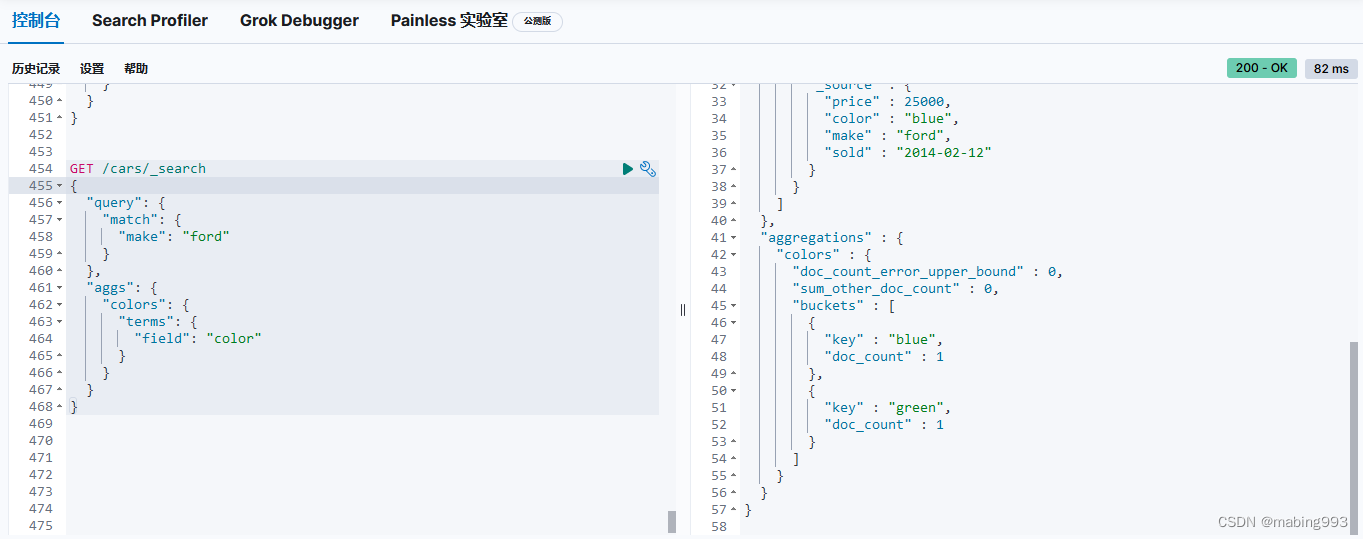
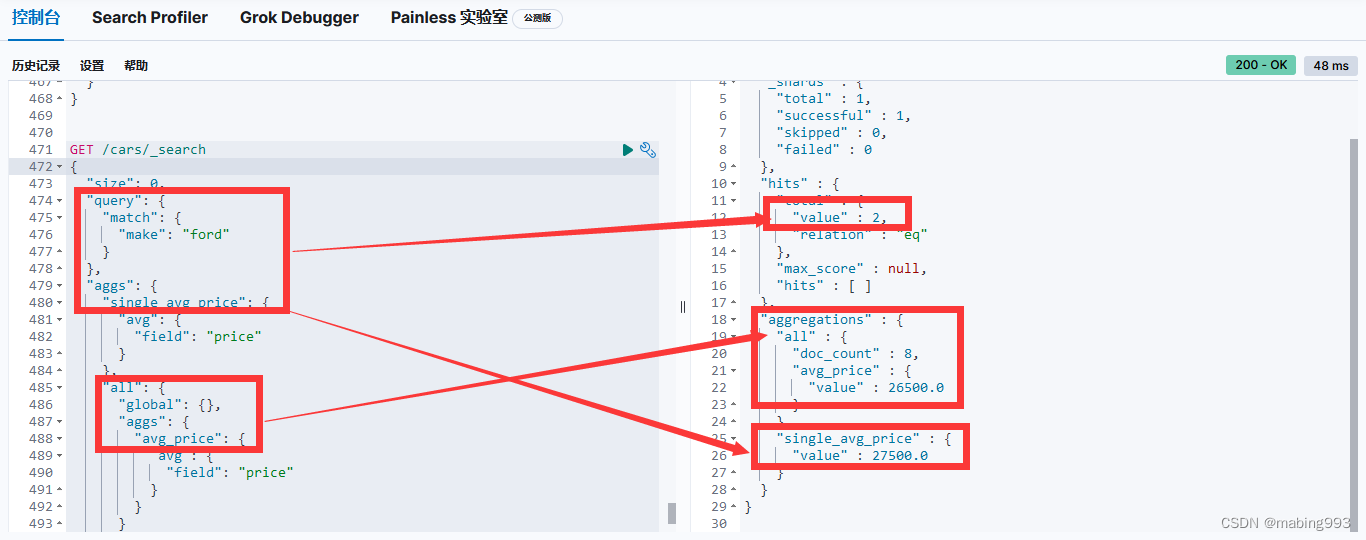
利用范围,我们可以问“福特在售车有多少种颜色?”诸如此类的问题。可以简单的在请求中加上一个查询(本例中为 match 查询):
通常我们希望聚合是在查询范围内的,但有时我们也想要搜索它的子集,而聚合的对象却是 所有 数据。
例如,比方说我们想知道福特汽车与 所有 汽车平均售价的比较。我们可以用普通的聚合(查询范围内的)得到第一个信息,然后用 全局 桶获得第二个信息。
全局 桶包含 所有 的文档,它无视查询的范围。因为它还是一个桶,我们可以像平常一样将聚合嵌套在内。
single_avg_price 度量计算是基于查询范围内所有文档,即所有 福特 汽车。avg_price 度量是嵌套在 全局 桶下的,这意味着它完全忽略了范围并对所有文档进行计算。聚合返回的平均值是所有汽车的平均售价。
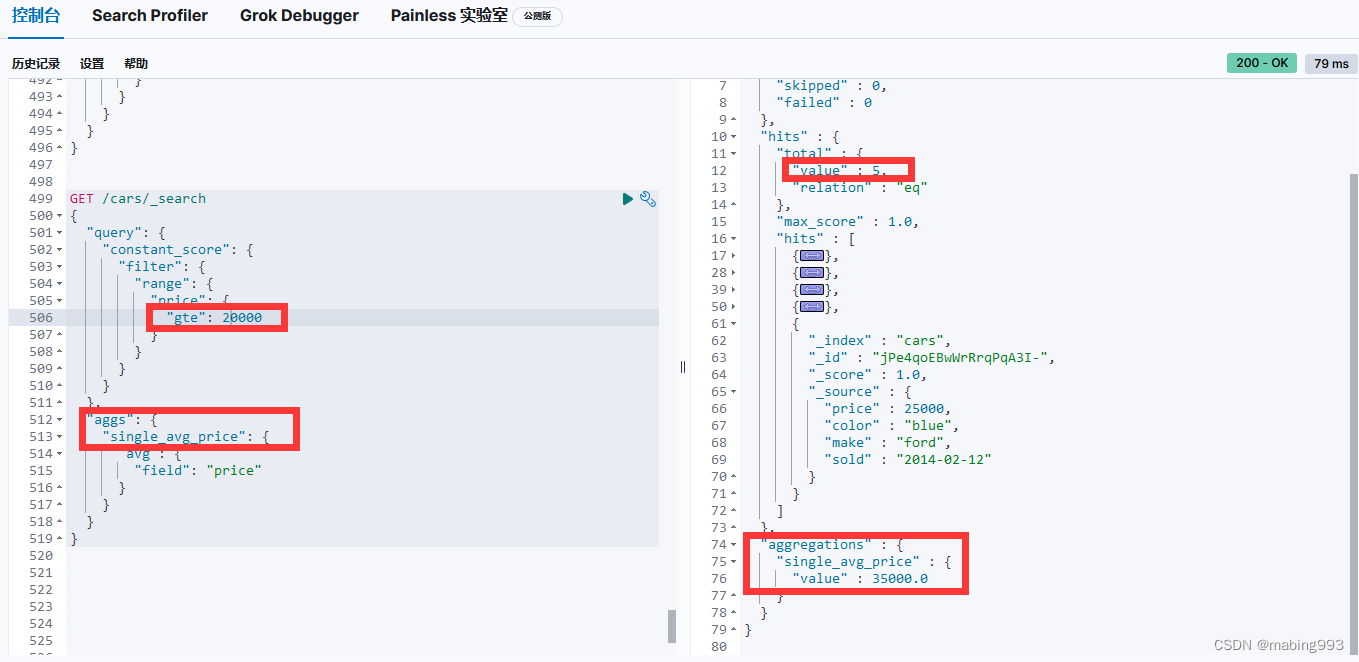
聚合范围限定还有一个原生的扩展就是过滤。因为聚合是在查询结果范围内操作的,任何可以适用于查询的过滤器也可以应用在聚合上,可以对聚合结果进行过滤而不是仅对查询范围做限定。
我们可以用一种特殊的桶,叫做 filter (注:过滤桶) 。 我们可以指定一个过滤桶,当文档满足过滤桶的条件时,我们将其加入到桶内。
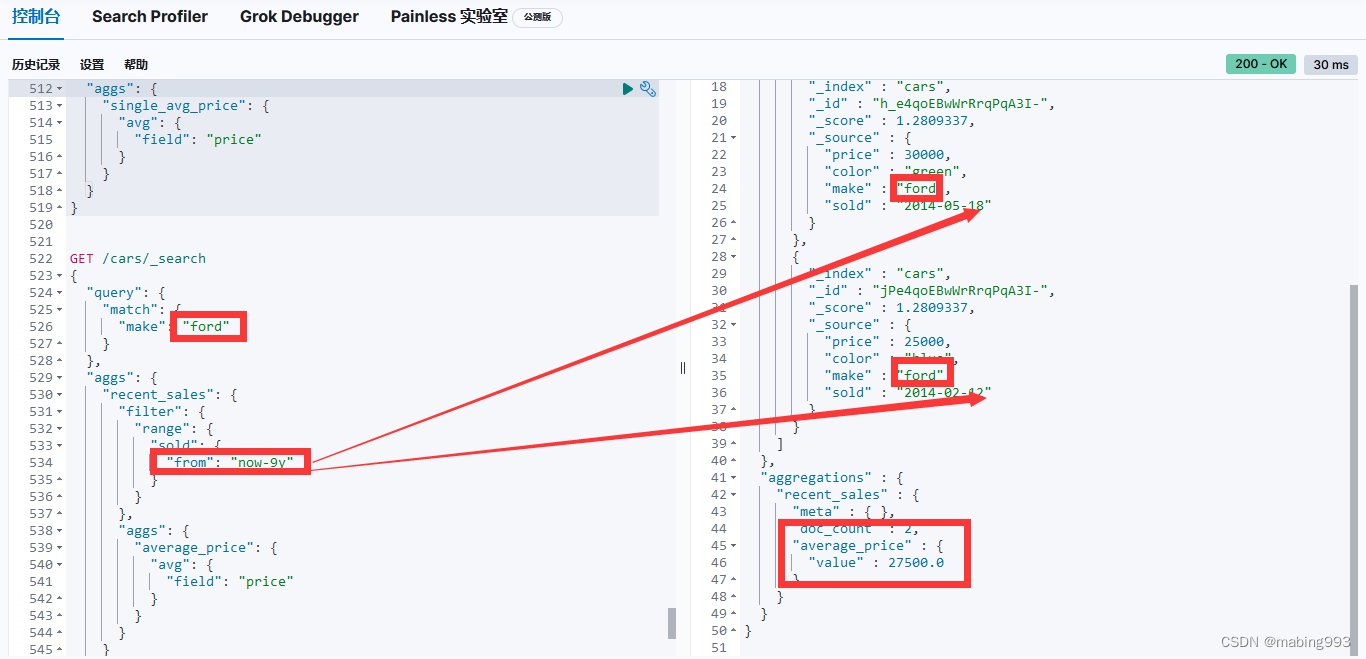
目前为止,我们可以同时对搜索结果和聚合结果进行过滤(不计算得分的 filter 查询),以及针对聚合结果的一部分进行过滤( filter 桶)。
我们可能会想,"只过滤搜索结果,不过滤聚合结果呢?" 答案是使用 post_filter 。
它是接收一个过滤器的顶层搜索请求元素。这个过滤器在查询 之后 执行(这正是该过滤器的名字的由来:它在查询之后 post 执行)。正因为它在查询之后执行,它对查询范围没有任何影响,所以对聚合也不会有任何影响。
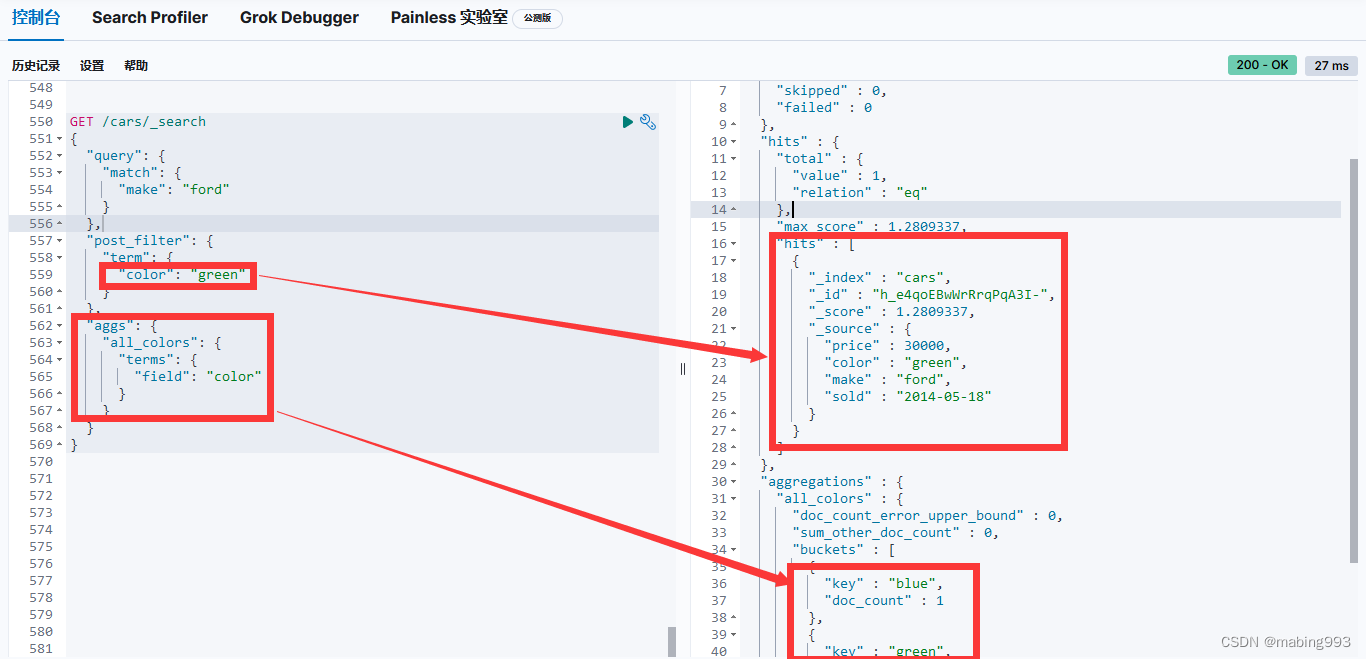
我们可以利用这个行为对查询条件应用更多的过滤器,而不会影响其他的操作,就如 UI 上的各个分类面。让我们为汽车经销商设计另外一个搜索页面,这个页面允许用户搜索汽车同时可以根据颜色来过滤。颜色的选项是通过聚合获得的:
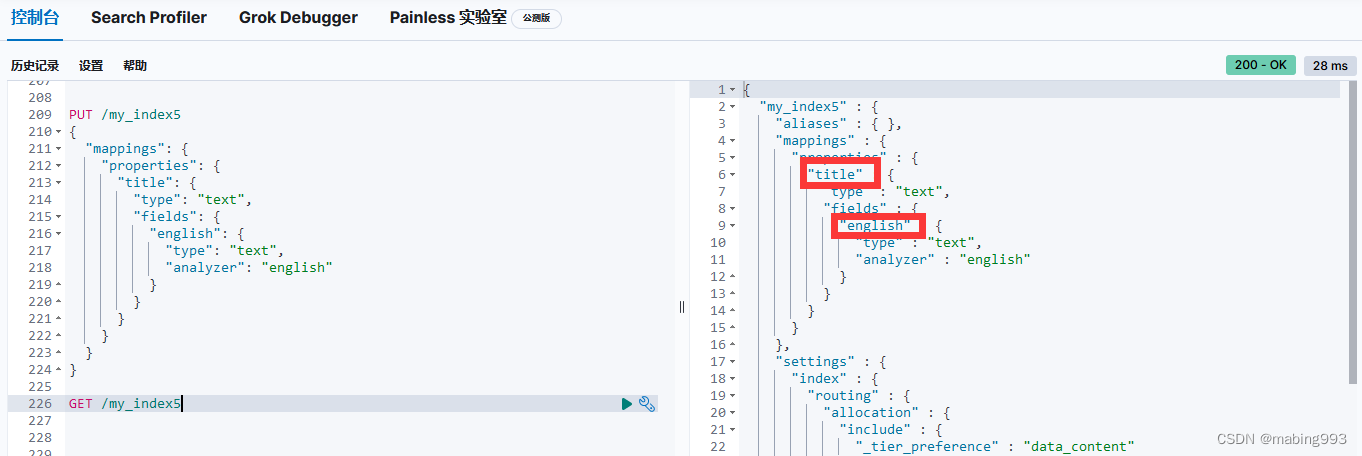
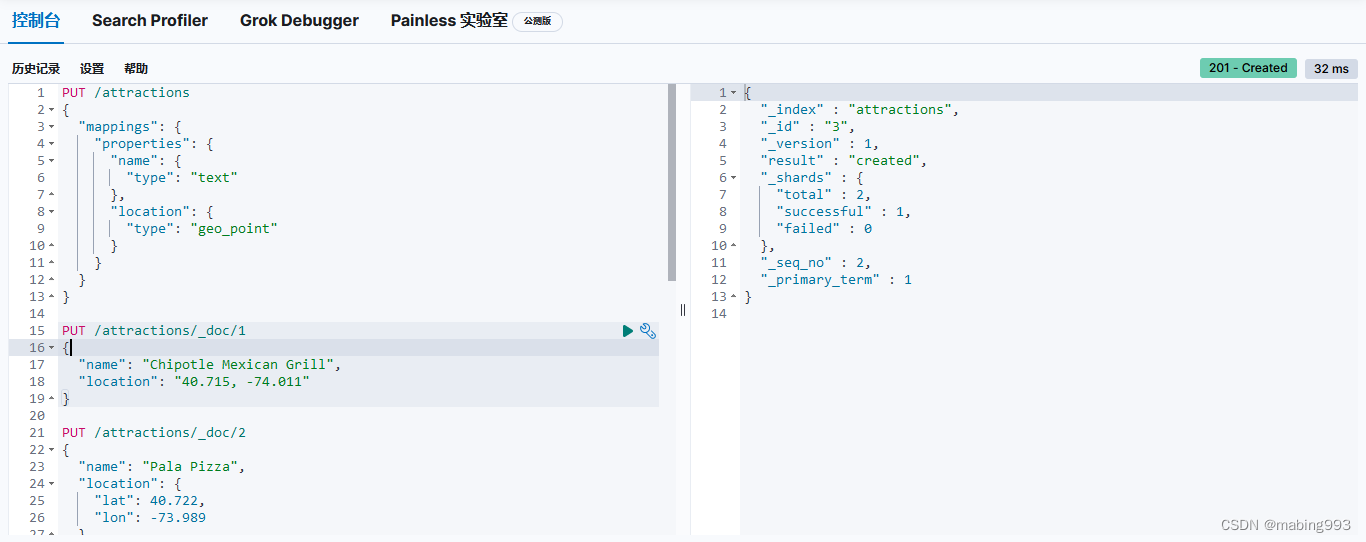
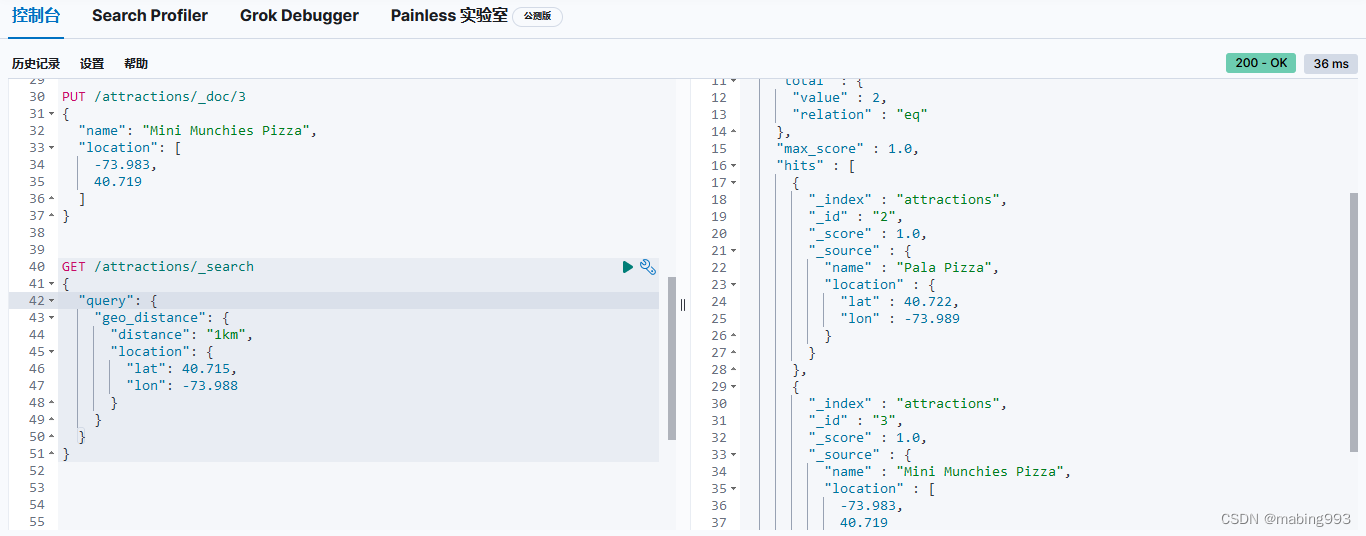
Elasticsearch 提供了 两种表示地理位置的方式:用纬度-经度表示的坐标点使用 geo_point 字段类型, 以 GeoJSON 格式定义的复杂地理形状使用 geo_shape 字段类型。
Geo-points 允许你找到距离另一个坐标点一定范围内的坐标点、计算出两点之间的距离来排序或进行相关性打分、或者聚合到显示在地图上的一个网格。另一方面,Geo-shapes 纯粹是用来过滤的,它们可以用来判断两个地理形状是否有重合或者某个地理形状是否完全包含了其他地理形状。
location 字段被声明为 geo_point 后,我们就可以索引包含了经纬度信息的文档了。经纬度信息的形式可以是字符串、数组或者对象:
字符串形式以半角逗号分割,如 "lat,lon" 。
对象形式显式命名为 lat 和 lon 。
数组形式表示为 [lon,lat] 。
可能所有人都至少一次踩过这个坑:地理坐标点用字符串形式表示时是纬度在前,经度在后"latitude,longitude",而数组形式表示时是经度在前,纬度在后 [longitude,latitude],顺序刚好相反。
其实,在 Elasticesearch 内部,不管字符串形式还是数组形式,都是经度在前,纬度在后。不过早期为了适配 GeoJSON 的格式规范,调整了数组形式的表示方式。
我们可以将一篇博客文章的评论以一个 comments 数组的形式和博客文章放在一起,comments被当作一个整体。
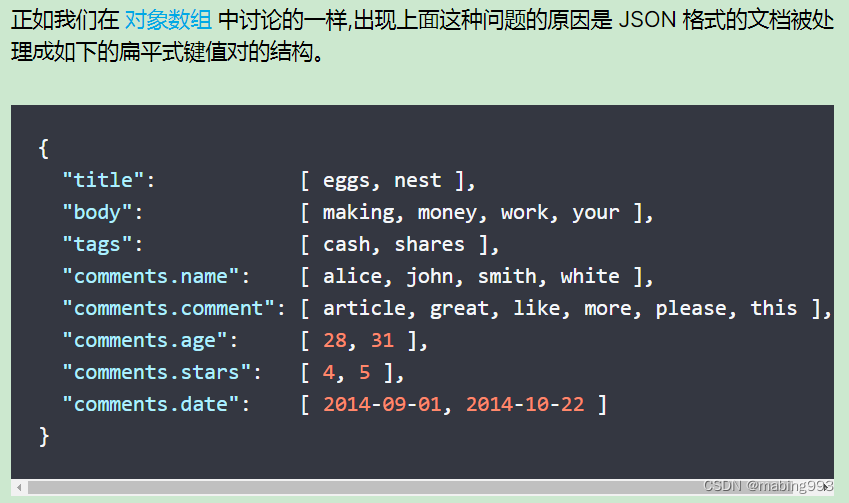
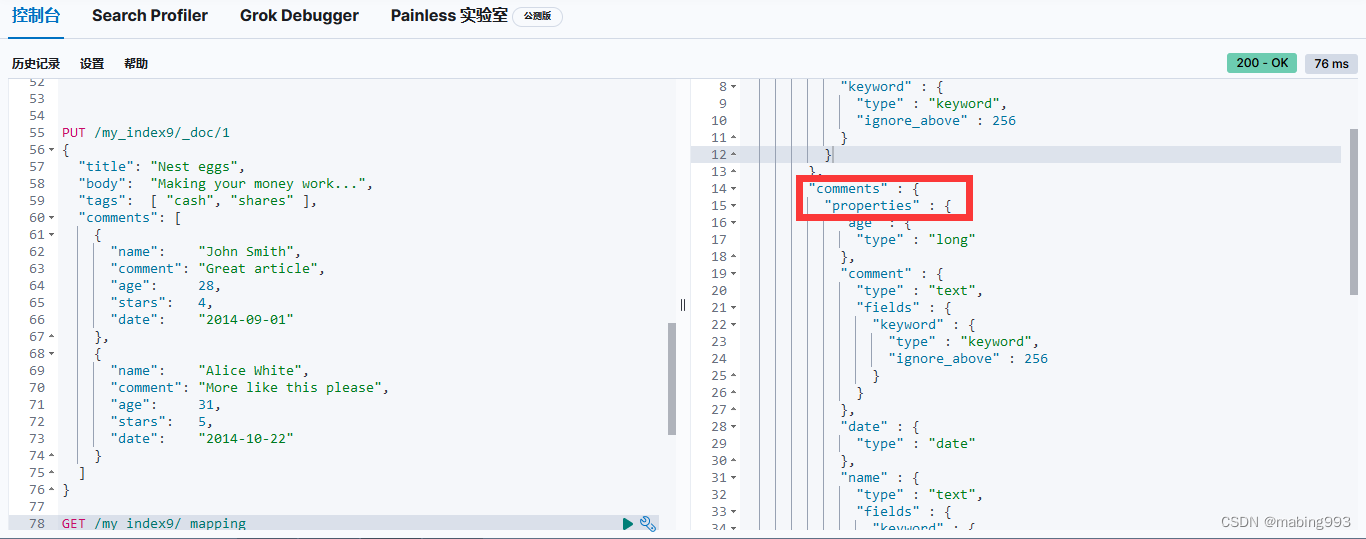
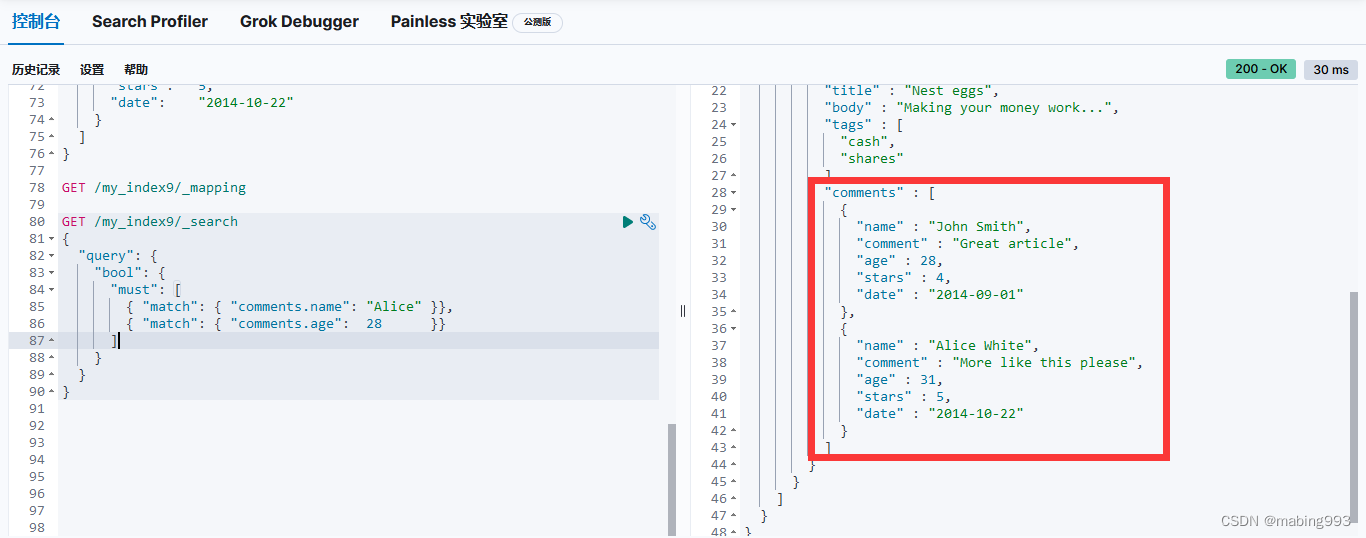
嵌套对象 就是来解决这个问题的。将 comments 字段类型设置为 nested 而不是 object 后,每一个嵌套对象都会被索引为一个 隐藏的独立文档。
在独立索引每一个嵌套对象后,对象中每个字段的相关性得以保留。我们查询时,也仅仅返回那些真正符合条件的文档。
不仅如此,由于嵌套文档直接存储在文档内部,查询时嵌套文档和根文档联合成本很低,速度和单独存储几乎一样。
嵌套文档是隐藏存储的,我们不能直接获取。如果要增删改一个嵌套对象,我们必须把整个文档重新索引才可以。值得注意的是,查询的时候返回的是整个文档,而不是嵌套文档本身。
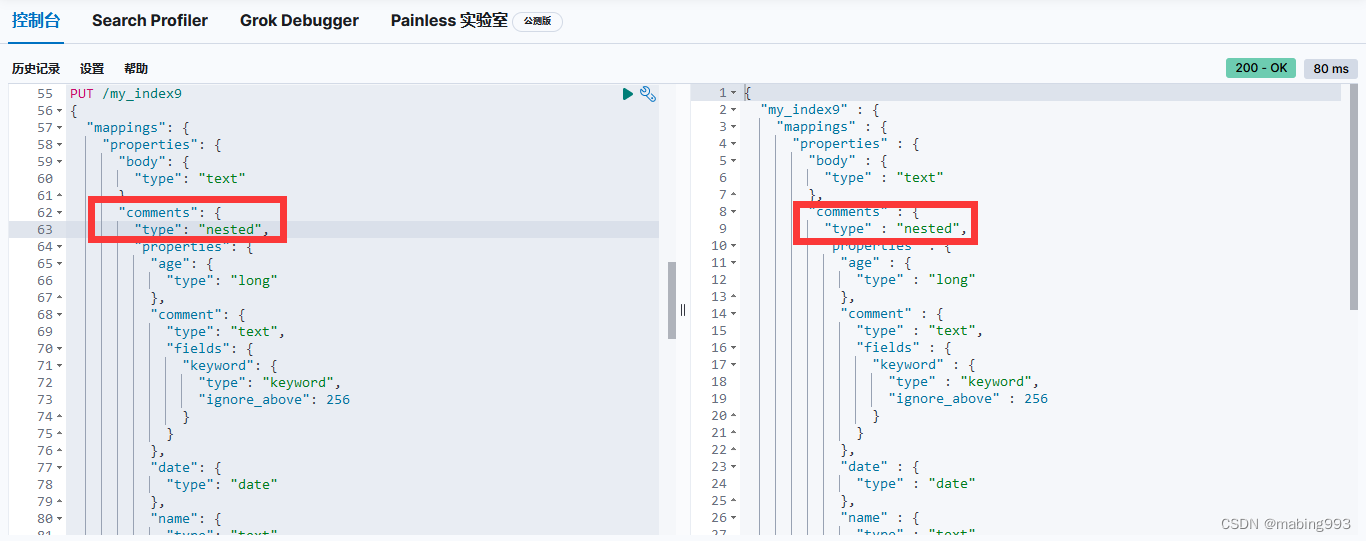
由于嵌套对象被索引在独立隐藏的文档中,我们无法直接查询它们。
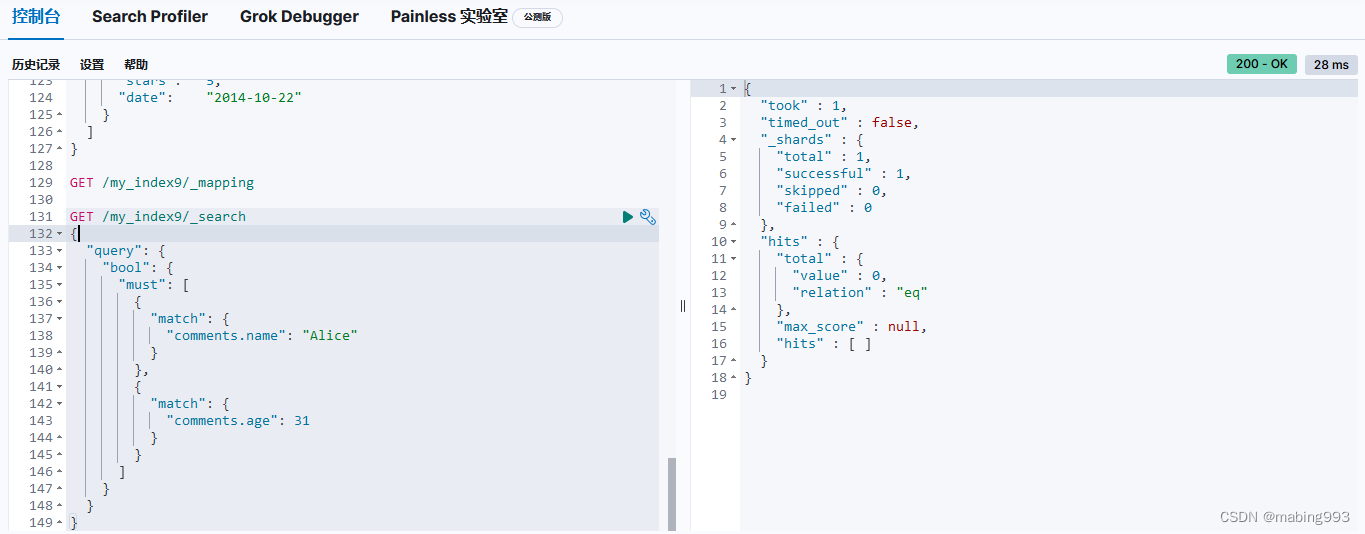
相应地,我们必须使用 nested 查询 去获取它们,nested 子句作用于嵌套字段 comments 。在 nested 查询中,既不能查询根文档字段,也不能查询其他嵌套文档。comments.name 和 comments.age 子句操作在同一个嵌套文档中。
nested 字段可以包含其他的 nested 字段。同样地,nested 查询也可以包含其他的 nested 查询。而嵌套的层次会按照你所期待的被应用。
nested 查询肯定可以匹配到多个嵌套的文档。每一个匹配的嵌套文档都有自己的相关度得分,但是这众多的分数最终需要汇聚为可供根文档使用的一个分数。
默认情况下,根文档的分数是这些嵌套文档分数的平均值。可以通过设置 score_mode 参数来控制这个得分策略,相关策略有 avg (平均值), max (最大值), sum (加和) 和 none (直接返回 1.0 常数值分数)。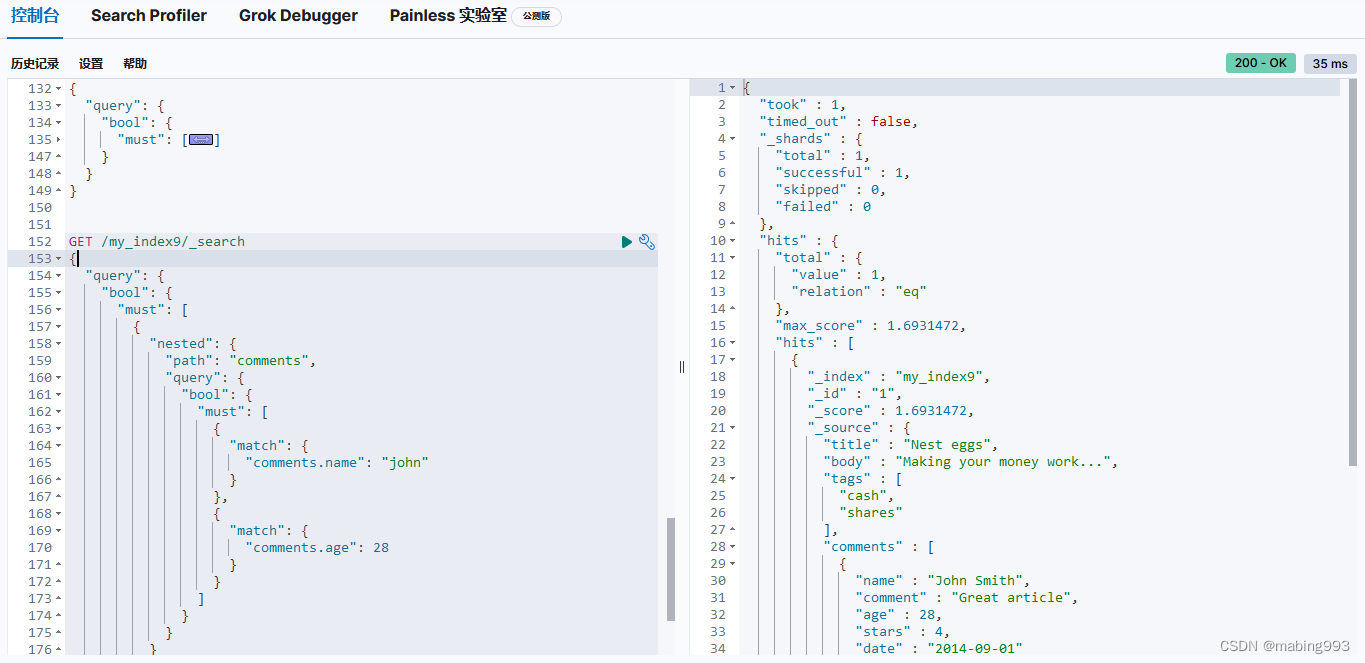
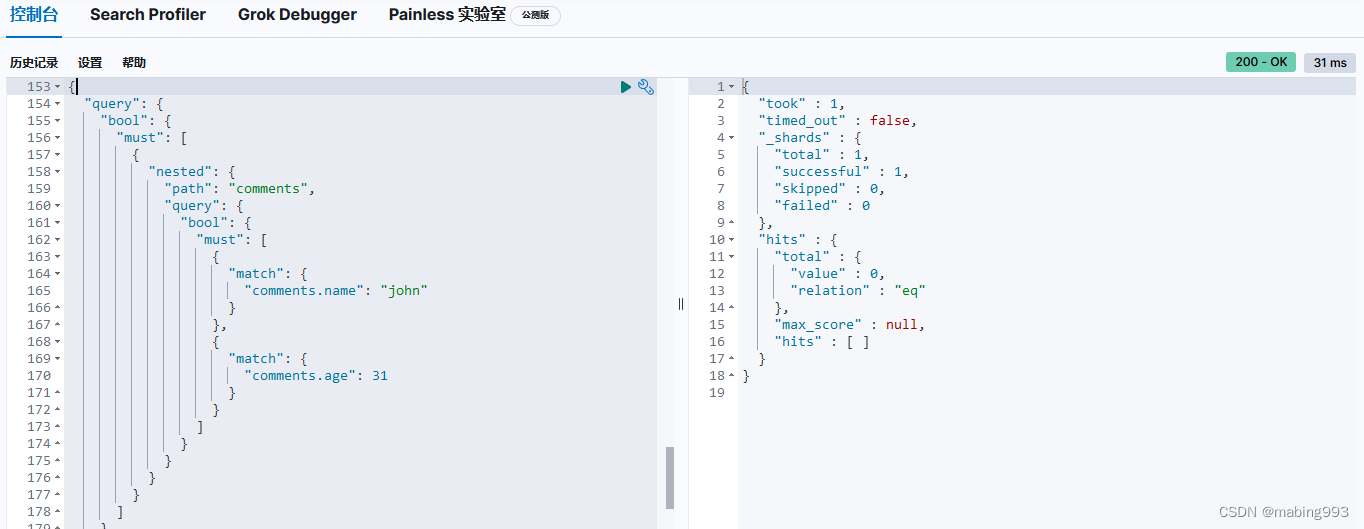
尽管嵌套字段的值存储于独立的嵌套文档中,但依然有方法按照嵌套字段的值排序。假如我们想要查询在10月份收到评论的博客文章,并且按照 stars 数的最小值来由小到大排序,那么查询语句如下:
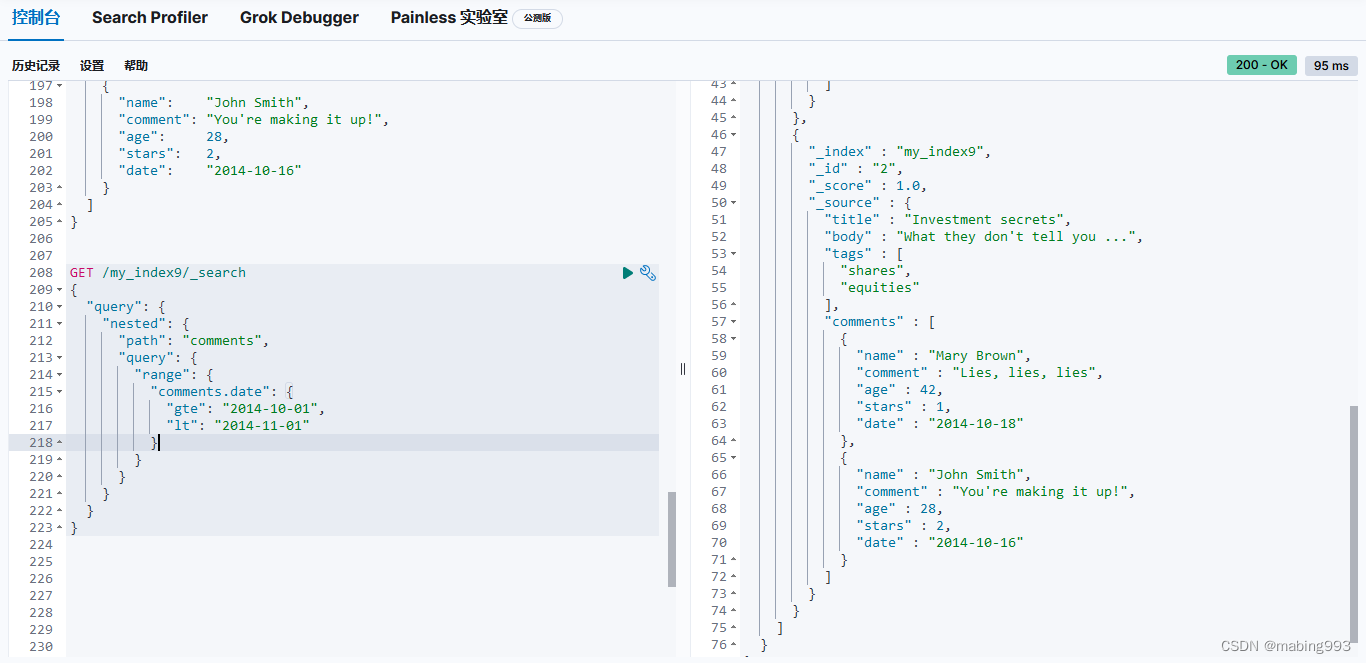
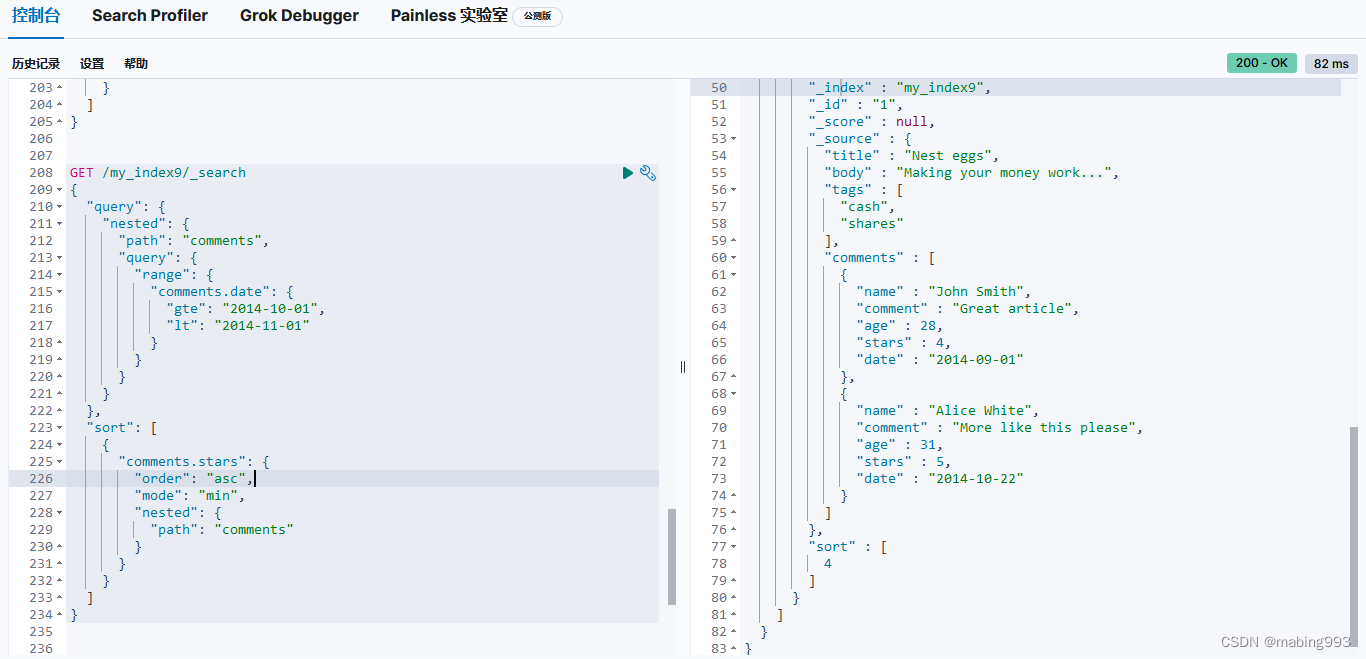
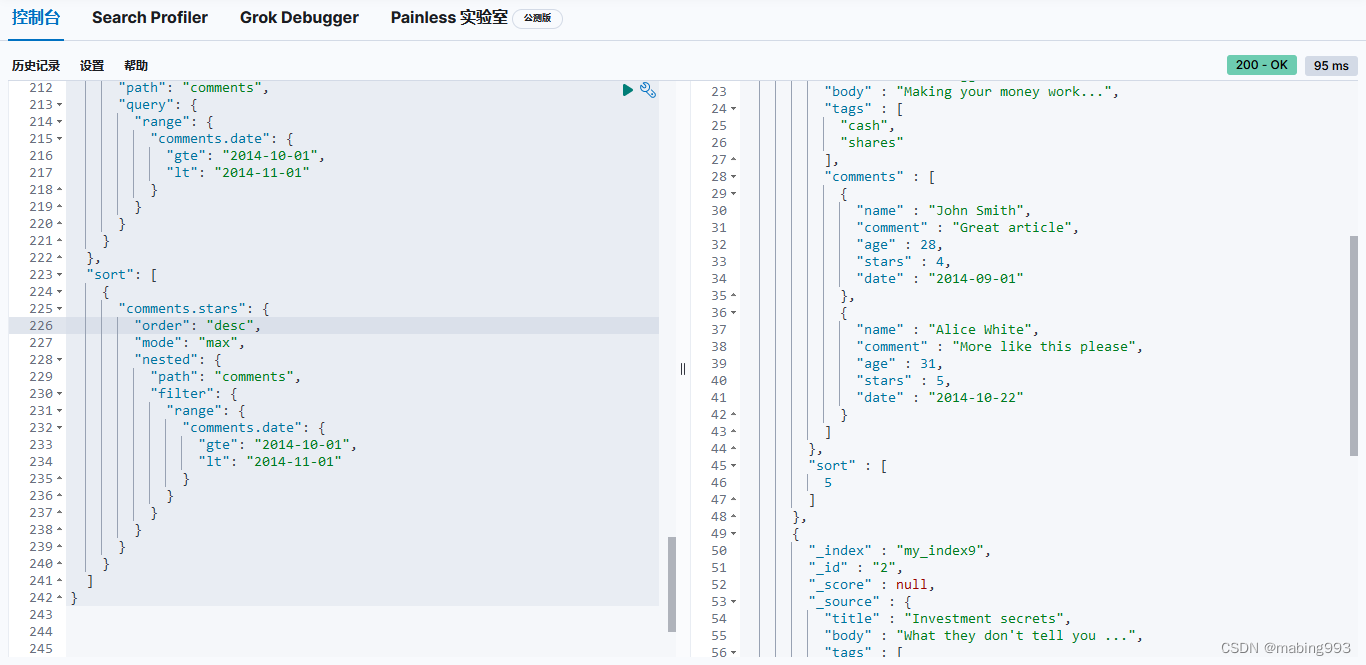
更多更新使用语法可参考
What is Elasticsearch? | Elasticsearch Guide [8.2] | Elastic
https://www.elastic.co/guide/en/elasticsearch/reference/8.2/elasticsearch-intro.html















 2978
2978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









