







Bitmap索引
时序数据库从抽象语义上来说总体可以概括为两个方面的基本需求,一个方面是存储层面的基本需求:包括LSM写入模型保证写入性能、数据分级存储(最近2小时的数据存储在内存中,最近一天的数据存储在SSD中,一天以后的数据存储在HDD中)保证查询性能以及存储成本、数据按时间分区保证时间线查询性能。另一方面是查询层面的基本需求:包括基本的按时间线进行多个维度的原始数据查询、按时间线在多个维度进行聚合后的数据统计查询需求以及TopN需求等。
可见,多维条件查询通常是时序数据库的一个硬需求,其性能好坏也是评价一个时序数据库是否优秀的一个重要指标。调研了市场上大多时序数据库(InfluxDB、Druid、OpenTSDB、HiTSDB等),基本上都支持多维查询,只有极个别的暂时支持的并不完美。通常来说,支持多维查询的手段无非两种:Bitmap Index以及Inverted Index,也称为位图索引和倒排索引。
接下来笔者会重点介绍使用Bitmap索引来加快多维条件查询的基本原理以及工程实践,最后也会对倒排索引进行一个简单的介绍。其实这两种索引无论在原理上还是在工程实践上都极其相似,只是在几个小的细节问题上有所不同,在文章最后笔者也会进行详细的说明。
Bitmap索引到底是个神马
Bitmap称为位图,对此不了解的童鞋可以自行Google。在此我们举个简单的例子来演示如何使用Bitmap Index来加速数据库的多维查询性能。下图是一张典型的时序数据表:

图中Timestamp列是时序列,Page、Username、Gender和City这几个列是维度列,Added以及Removed两列是数值列。基于这样的原始表,可以构造一个典型的多维查询如下:
select Added from datasource where Gender = ‘Female’ and City = ‘Taiyuan’
查询中使用两个维度条件进行过滤,分别是Gender以及City列。很显然,如果不使用任何技术手段的话,在原始表上根据如上两个维度的过滤条件进行查询需要遍历整个原始表,并对相应维度列进行过滤,这个代价很显然是非常可观的。那能不能有一种方法可以直接根据维度的过滤条件得到待查找目标行,比如上述示例中能不能根据Gender = ‘Female’ and City = ‘Taiyuan’这两个过滤条件直接定位到待查找目标行就是第二行,其他行都不满足条件,这样的话只需要查找第二行的Added列返回给用户即可,不再需要野蛮的全表扫描并一条一条数据进行对比。这就是Bitmap索引(位图索引)的使命!
使用Bitmap索引的基本原理是将这两列上的数值映射到bitmap上,再采用intersection表示来实现and、or等这种查询谓词。在上述示例中,将Gender以及City两列映射成bitmap如下图所示:



剩下的描述Druid中怎么使用位图索引的,以及在什么地方使用的,详细请点击链接
http://hbasefly.com/2018/06/19/timeseries-database-8/?cmjqby=ogk4w&bensne=betaq
倒排索引
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
先来回忆一下我们是怎么插入一条索引记录的:

其实就是直接PUT一个JSON的对象,这个对象有多个字段,在插入这些数据到索引的同时,Elasticsearch还为这些字段建立索引——倒排索引,因为Elasticsearch最核心功能是搜索。
那么,倒排索引是个什么样子呢?

首先,来搞清楚几个概念,为此,举个例子:
假设有个user索引,它有四个字段:分别是name,gender,age,address。画出来的话,大概是下面这个样子,跟关系型数据库一样
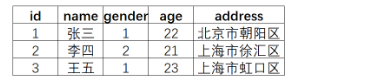
Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term(直译为:单词)
Term Dictionary(单词字典):顾名思义,它里面维护的是Term,可以理解为Term的集合
Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引
Posting List(倒排列表):倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。(PS:实际的倒排列表中并不只是存了文档ID这么简单,还有一些其它的信息,比如:词频(Term出现的次数)、偏移量(offset)等,可以想象成是Python中的元组,或者Java中的对象)
(PS:如果类比现代汉语词典的话,那么Term就相当于词语,Term Dictionary相当于汉语词典本身,Term Index相当于词典的目录索引)
我们知道,每个文档都有一个ID,如果插入的时候没有指定的话,Elasticsearch会自动生成一个,因此ID字段就不多说了
上面的例子,Elasticsearch建立的索引大致如下:

Elasticsearch分别为每个字段都建立了一个倒排索引。比如,在上面“张三”、“北京市”、22 这些都是Term,而[1,3]就是Posting List。Posting list就是一个数组,存储了所有符合某个Term的文档ID。
只要知道文档ID,就能快速找到文档。可是,要怎样通过我们给定的关键词快速找到这个Term呢?
当然是建索引了,为Terms建立索引,最好的就是B-Tree索引(PS:MySQL就是B树索引最好的例子)。
首先,让我们来回忆一下MyISAM存储引擎中的索引是什么样的:

我们查找Term的过程跟在MyISAM中记录ID的过程大致是一样的
MyISAM中,索引和数据是分开,通过索引可以找到记录的地址,进而可以找到这条记录
在倒排索引中,通过Term索引可以找到Term在Term Dictionary中的位置,进而找到Posting List,有了倒排列表就可以根据ID找到文档了
(PS:可以这样理解,类比MyISAM的话,Term Index相当于索引文件,Term Dictionary相当于数据文件)
(PS:其实,前面我们分了三步,我们可以把Term Index和Term Dictionary看成一步,就是找Term。因此,可以这样理解倒排索引:通过单词找到对应的倒排列表,根据倒排列表中的倒排项进而可以找到文档记录)
为了更进一步理解,下面从网上摘了两张图来具现化这一过程:

根据单一职责原则,一篇只讲一件事情,关于倒排索引结构就讲到这里,至于更多细节,比如:压缩,存储那些以后再説
B-Tree树















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









