









引言
博主尝试用Python语言去写其他语言组别的试题,按逆序刷的话,今天先做一套十一届Java研究生组的试题。
试题A:约数个数

本题考察的是质因数的知识,由于是填空题,所以直接从1开始遍历到根号78120,判断每一个数是否能整除78120即可。比较基础。
res = 0
for i in range(1, 78120+1):
res += 1 if 78120 % i == 0 else 0
print(res)
# 输出 96
注意Python遵循左闭右开的原则,所以右边是78120 + 1。
试题B:跑步锻炼

本题考察的是日期处理。同届大赛Python组也有一道一样的题,这里算是博主自己复习一遍吧。
通过Python内置的datetime模块来做本题。
import datetime
start = datetime.date(year=2000, month=1, day=1)
stop = datetime.date(year=2020, month=10, day=1)
res = 0
for dif in range((stop - start).days + 1):
cur = start + datetime.timedelta(days=dif)
res += 2 if cur.isoweekday() == 1 or cur.day == 1 else 1
print(res)
# 输出 8879
注意date类的天数属性是day,而timedelta类的天数属性是days。
1)通过timedelta遍历起止日期间的每一天
2)通过isoweekday()函数判断某个日期是否为周一
3)通过time类的day属性判断某个日期是否为月初
试题C:平面切割

本题考察的是数学知识吧?
博主有心无力,百度的时候看到知乎上有人提问了,然后下面的解答写得挺不错,这里就不班门弄斧了。
直接上链接:20个圆和20条直线最多能把平面分成几个部分?
试题D:蛇形填数

本题同样出现在同届大赛Python组上。这里再次复习下。
以第 3 行第 3 列为例,我们将头向左转 45 度看图,会发现 13所在的斜线上方是一个等腰三角形。
我暂且把目标数所在的这条斜线称作“目标线”,目标线上方的这个等腰三角形称作“目标三角形”。
目标线

目标三角形

目标三角形每一层的元素个数分别是 1,2,3。。。而我们目标线本身位于目标三角形之外。
若是将目标线作为三角形的一部分,则目标线应该是三角形的第 2 * i -1 行,故目标线之上的目标三角形有 2 * i - 2 层,元素总数为 (求一个等差数列的和嘛。)

知道了目标三角形的元素总数 s,那么目标线上的元素就是从 s + 1 一直到 s + (2 * i - 1),又由于题目问的都是对角线元素的值,所以目标值,应该是 目标线上起止元素的中间数!
也就是 s + i 。
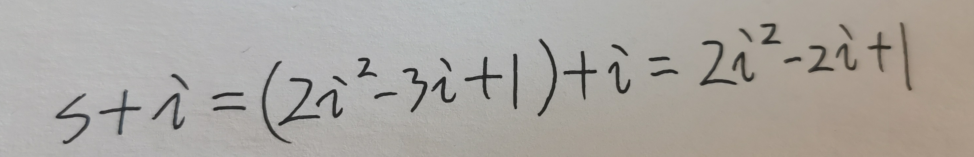
最后得出的 2 * i^2 - 2 * i + 1就是本题的通式,i 为目标所在行所在列。
i = 20
res = 2 * pow(i,2) - 2 * i + 1
print(res)
# 输出 761
博主写这道题解的感觉和之前第一次写完全不一样,描述起来思路更清晰,最后总结的通式也更简洁,看来同一题还是要多复习,每次都会有进步的。
试题E:排序

本题同样出现在同届大赛Python组上。解本题需要对冒泡排序有一定的了解,要对冒泡的轮数、每一轮的比较数做到熟稔于心,不然可能会无从下手。
首先,我们要知道对于一个长度为 n 的序列,对它做冒泡排序会发生些什么:
1)进行 n-1 轮的冒泡,每一轮将最大(或最小)元素上升到应该所在的位置。
2)第一轮冒泡,从第1个元素遍历到第n-1个元素,共进行 n-1 次比较。
3)第二轮冒泡,从第1个元素遍历到第n-2个元素,共进行 n-12次比较。
4)第 i 轮冒泡,从第1个元素遍历到第 n-i 个元素,共进行 n-i 次比较。
每进行一次比较操作,就有可能会发生相应的交换操作,如果每一次比较都发生交换,则该序列会发生这么多次交换,n是序列长度。

该种情况下的交换数,是长度为 n 的序列所能发生的最多交换次数,此时序列为全逆序状态(如321,DCBA这样子的序列)。
知道了这一点,我们就可以确定目标序列的最短长度。
因为拿 n = 7为例吧,长度为 7 的序列,最多就只能发生 21 次交换,根本达不到题目要求的 100次。
所以,先通过代码求出可能达到100交换的最短序列长度:
for n in range(1, 100):
if n * (n - 1) // 2 >= 100:
print(n)
break
# 输出 15 105
求得可能达到100次交换的最短序列长度为15,且若是全逆序情况下,最多可以有105次交换。
现在要做的就是从全逆序序列中进行改造,改造到只剩100次交换。
# 全逆序
['O', 'N', 'M', 'L', 'K', 'J', 'I', 'H', 'G', 'F', 'E', 'D', 'C', 'B', 'A']
还是回到冒泡排序本身的特点上,我们先看字母A,字母A如果要到它应该在的位置(第一个位置),应该进行 14次交换,为什么是14次呢?因为A前面有14个比他大的元素,假设A前面只有12个比他大的元素,那他只需要交换12次即可到达正确的位置。
也就是说,我们可以让某个元素前面比他大的元素比原来少5个,这样该元素所要进行的交换数就少5次了,而其他元素的交换数不变,可以达到总交换数 -5 的效果。
首先,那些原本交换数就不足5次的元素肯定不考虑,因为他们怎么减也减不了5次。这样我们就把目光锁定在 J 以及 J 以后的字母。
还是拿 字母A 为例,如果我将A向前移动5个位置,那么此时
['O', 'N', 'M', 'L', 'K', 'J', 'I', 'H', 'G', 'A', 'F', 'E', 'D', 'C', 'B']
A 前面只有 9 个比他大的元素,实现了交换数 -5
同理,我们还可以将 B 向前移动5个位置,C向前移动 5 个位置。。。J向前移动5个位置。我们得到了多个解。
再看题目给的条件,当最短序列长度有多个解时,取字典序最小的作为答案,考虑前面的解,只有将 J 向前移动 5 个位置时,J会变成新的首元素,字典序最小;其他方案都会让 O 一直是首元素。
至此,我们应该选择的方案是将 J 向前移动 5 个位置
['J', 'O', 'N', 'M', 'L', 'K', 'I', 'H', 'G', 'F', 'E', 'D', 'C', 'B', 'A']
保险期间,我们验算一下,手写一个冒泡排序,记录交换数。
def bubblesort(lst):
res = 0
for b in range(len(lst)-2, -1, -1):
for i in range(b+1):
if lst[i] > lst[i+1]:
lst[i], lst[i+1] = lst[i+1], lst[i]
res += 1
print(res)
bubblesort(lst)
# 输出 100
试题F:成绩统计
本题同样出现在同届大赛Python组上。
需要注意的点:
1)85分以及上的分数既要加到优秀人数中,也要同时加到合格人数中。
2)输出顺序是先输出合格再输出优秀。
3)Python如何四舍五入和百分比输出。
前两个点都是比较“反人类”的,估计就是故意挖的坑。
n = int(input())
scores = [int(input()) for _ in range(n)]
a = b = 0
for score in scores:
if score >= 60:
b += 1
if score >= 85:
a += 1
print('{:.0%}'.format(round(b / n, 2)))
print('{:.0%}'.format(round(a / n, 2)))
试题G:回文日期

本题考查的是Python日期处理和回文判断的知识。
利用Python中datetime模块,可以很方便地处理日期,同时datetime模块下还有strptime() 和 strftime()函数可以方便地进行日期类型和字符串类型之间的转换。
下面是博主写的第一版代码:
import datetime
n = input()
start = datetime.datetime.strptime(n, '%Y%m%d')
dif = 1
while True:
cur = start + datetime.timedelta(days=dif)
cur_str = cur.strftime('%Y%m%d')
if cur_str == cur_str[::-1]:
res1 = cur_str
break
else:
dif += 1
dif = 1
while True:
cur = start + datetime.timedelta(days=dif)
cur_str = cur.strftime('%Y%m%d')
if cur_str[0] == cur_str[2] == cur_str[5] == cur_str[7] and cur_str[1] == cur_str[3] == cur_str[4] == cur_str[6]:
res2 = cur_str
break
else:
dif += 1
print(res1)
print(res2)
可以发现代码从框架上看还是比较简单的,就是从输入日期开始不断遍历日期,每一次遍历都把日期转换成字符串去判断回文,判断回文就直接用Python切片 [::-1]去完成。
问题就是这段代码在蓝桥杯练习系统上只能跑到80分,有两个用例会超时:

因此博主仔细观察了一下代码,发现有地方可以优化一下下,下面是博主的第二版代码,只改了一个小地方:
import datetime
n = input()
start = datetime.datetime.strptime(n, '%Y%m%d')
dif = 1
while True:
cur = start + datetime.timedelta(days=dif)
cur_str = cur.strftime('%Y%m%d')
if cur_str == cur_str[::-1]:
res1 = cur_str
break
else:
dif += 1
while True:
cur = start + datetime.timedelta(days=dif)
cur_str = cur.strftime('%Y%m%d')
if cur_str[0] == cur_str[2] == cur_str[5] == cur_str[7] and cur_str[1] == cur_str[3] == cur_str[4] == cur_str[6]:
res2 = cur_str
break
else:
dif += 1
print(res1)
print(res2)
我把两个while之间的 dif = 1删去了,为什么呢?
因为 ABABBABA的回文日期一定是普通的回文日期,所以ABABBABA回文日期一定是从第一个普通回文日期开始才可能出现的,我们没有必要在找到第一个普通回文日期后,重新从输入日期开始遍历,直接从找到的第一个普通回文日期开始遍历即可。
但是,这样的小修改也不能完美解决超时问题,依然还有1个用例超时:

所以到这里,博主就想,应该是我用的这个方法本身复杂度就太高了。
另外,我也将代码提交到了 AcWing上,超时的第四个用例应该是:11111110
这个用例找第一个普通回文日期非常快,就是下一个日期11111111,但是找ABABBABA回文日期却非常慢,因为我们要找到20200202才可以,复杂度太高,一天一天地去遍历判断不可取!
这时就要转换思路了,对于同一年,比如2020年,最多就只能有一个回文日期存在,我们没有必要从2020年的第一天和判断到2020年的最后一天,我们只要判断以2020为年份的回文字符串是否满足日期格式即可。
什么意思呢?以2020年为例,它的回文日期就是20200202,作为一个日期字符串,他是合法的,所以我们就找到了这样一个回文字符串。
但是,假设年份是 2030,那么他的回文日期就是 20033002,
这是一个不合法的日期字符串(月份不能是30呀)。所以我们就可以按年份进行判断,只要该年份不能构成一个合法的回文字符串,那么我们就直接跳到下一年。这样效率就快了非常多。
import datetime
n = input()
year = n[:4]
while True:
try:
x = datetime.datetime.strptime(year+year[::-1], '%Y%m%d')
# 合法日期
if x > datetime.datetime.strptime(n, '%Y%m%d'):
res1 = year + year[::-1]
break
else:
year = str(int(year) + 1)
except:
year = str(int(year) + 1)
while True:
if year[0] == year[2] and year[1] == year[3]:
try:
x = datetime.datetime.strptime(year + year[::-1], '%Y%m%d')
res2 = year + year[::-1]
break
except:
year = str(int(year) + 1)
else:
year = str(int(year) + 1)
print(res1)
print(res2)
我们通过datetime中的strptime()函数将根据年份构造出的回文字符串进行转换,若是一个合法的日期字符串,则可以顺利通过;若不合法,则会触发一个异常,我们用try except语句去捕获这个异常,避免程序出错。
其实这里博主对Python异常捕获的使用非常外行,写出来的代码很丑陋,但好在最终还是解决了问题,蓝桥杯练习系统上也能AC了。

试题I:子串分值

本题考察的点可以用Python自带的计数器类Counter来应对。Counter类可以快速统计出一个字符串中每个字符出现的次数。
from collections import Counter
s = input()
res = 0
for i in range(len(s)):
for j in range(i, len(s)):
p = Counter(s[i:j+1])
for item in p:
if p[item] == 1:
res += 1
print(res)
这段代码从正确性上可以解决所有用例,但是其本质还是属于暴力破解,即枚举全部子串,然后再逐个遍历子串中的字符,判断出现的次数,所以时间复杂度特别高。
将这段代码放到蓝桥杯练习系统上,只能得到40分,只能通过40%的用例。其余用例均超时。
因此,还是要找到一个不那么直接的解决方法。其实,之前蓝桥杯办过一场备考直播,其实有老师讲到了这道题,博主正好也是看了那场直播,所以对该题的解法有印象。
在B站上可以看到备考直播的录播:B站的录播
具体从47分半左右开始看,就是本题的讲解。视频中老师讲得肯定比我在这里文字描述的好,而且我的代码也就是根据他的思路来写的,所以这里就不赘述了,建议大家看原视频。
下面是Python代码的实现:
s = input()
res = 0
for i in range(len(s)):
left, right = i-1, i+1
while left >= 0 and s[left] != s[i]:
left -= 1
while right <= len(s)-1 and s[right] != s[i]:
right += 1
res += (i-left) * (right-i)
print(res)
需要注意的是,左右边界本身是否包含在子串内,这一点我觉得视频讲得不是很清楚,需要自己想明白才能做对,想明白左右边界代表的到底是什么。
另外,博主写的这个第二段代码,时间复杂度是O(N^2)。
因为我们不仅遍历了字符串s中的每一个点,还从该点向左右出发去遍历了一遍,所以用例还不能全部通过。事实上,在蓝桥杯练习系统上只得了90分,还有一个用例是超时的。

这就要求我们去想一个时间复杂度O(N)的算法,我们只要遍历一次字符串就能解题,这里同样还是备考直播中老师提到的,可以用哈希表去存储每个字符最后一次出现的位置,这样一遍从左到右的扫描就可以获取每个字符的左边界信息;再来一遍从右到左的扫描就可以获取每个字符的有边界信息;最后直接通过左右边界信息计算结果即可。
以下就是本题的最终版:
s = input()
hash_map = {}
left_i, right_i = [0 for _ in range(len(s))], [0 for _ in range(len(s))]
res = 0
# 找每个字符的左边界
for i in range(len(s)):
if s[i] not in hash_map:
hash_map[s[i]] = i
left_i[i] = -1
else:
left_i[i] = hash_map[s[i]]
hash_map[s[i]] = i
hash_map = {}
# 找每个字符的右边界
for i in range(len(s)-1, -1, -1):
if s[i] not in hash_map:
right_i[i] = len(s)
hash_map[s[i]] = i
else:
right_i[i] = hash_map[s[i]]
hash_map[s[i]] = i
# 遍历字符左右边界,计算结果
res = [(right_i[i] - i) * (i - left_i[i]) for i in range(len(s))]
print(sum(res))
时间复杂度O(N)的代码,也终于在蓝桥杯练习系统上跑到了AC

另外,博主好奇,尝试了一下只使用“一半”的哈希会有什么结果,就是我只用哈希去找左边界,有边界还是用指针去遍历,我想看一下会有什么效果,下面是代码:
s = input()
hash = {}
res = 0
for i in range(len(s)):
# 找左边界
left = -1 if s[i] not in hash else hash[s[i]]
hash[s[i]] = i
# 找右边界
right = i+1
while right <= len(s) - 1 and s[right] != s[i]:
right += 1
res += (i-left) * (right-i)
print(res)
仅从代码长度上看,应该是最简短的版本了,而且关键是这段代码同样可以AC!!!只是总体耗时上比其全部哈希的代码要长上不少:


试题H:作物杂交


本题考察的点是递归,我们需要通过杂交方案去搜索最短的杂交方案,编写一个递归函数即可。
n, m, k, t = list(map(int, input().split()))
time = list(map(int, input().split()))
seeds = list(map(int, input().split()))
ways = [list(map(int, input().split())) for _ in range(k)]
def gettime(plant):
if plant in seeds:
return 0
else:
res = float('inf')
for way in ways:
if way[2] == plant:
p1, p2 = way[0], way[1]
temp = max(gettime(p1), gettime(p2)) + max(time[p1-1], time[p2-1])
res = min(res, temp)
return res
print(gettime(t))
这段代码通过了蓝桥云课的全部用例,但在蓝桥杯练习系统上全部运行超时,得分为0,说明这种方法虽然正确,但时间开销极大,甚至得不了一点分数。

从优化的角度去考虑,我们在搜索过程中进行了很多次重复搜索,如果能将每次搜索的中间结果保存下来,那么就可以减少很多重复搜索。下面是优化后的递归代码:
n, m, k, t = list(map(int, input().split()))
time = list(map(int, input().split()))
seeds = list(map(int, input().split()))
ways = [list(map(int, input().split())) for _ in range(k)]
gettime = [float('inf') for _ in range(n)]
for seed in seeds:
gettime[seed-1] = 0
# 获取种子target的时长
def dfs(target):
res = float('inf')
if gettime[target-1] != float('inf'):
return gettime[target-1]
for way in ways:
if way[2] == target:
p1, p2 = way[0], way[1]
res = min(res, max(dfs(p1), dfs(p2)) + max(time[p1-1], time[p2-1]))
gettime[target-1] = res
return res
print(dfs(t))
这段代码在蓝桥杯练习系统上获得了60分,其他4个用例还是超时,说明我们优化得还不够。
到了这一步,博主就在站内找题解了。寻找后发现一件事,包括本题在内的蓝桥杯压轴题,写出题解放在站内的非常之少,而博主会逐个将他们的代码提交到蓝桥杯练习系统上测试,发现其中又有绝大多数得分为0,说明有很多甚至都不是一份有效的题解。
就拿问题为例,博主找了站内所有的题解,只有这一份是可以AC的,其他题解甚至都会运行错误。
下面先贴出博主“翻译”后的代码:
n, m, k, t = list(map(int, input().split()))
time = list(map(int, input().split()))
seeds = list(map(int, input().split()))
ways = [list(map(int, input().split())) for _ in range(k)]
time.insert(0, 0)
gettime = [float('inf') for _ in range(n+1)]
mix = [[] for _ in range(n+1)]
for way in ways:
p1, p2, p3 = way[0], way[1], way[2]
temp = [p1, p2, max(time[p1], time[p2])]
mix[p3].append(temp)
for seed in seeds:
gettime[seed] = 0
def dfs(target):
if gettime[target] != float('inf'):
return gettime[target]
for i in range(len(mix[target])):
gettime[target] = min(gettime[target], max(dfs(mix[target][i][0]), dfs(mix[target][i][1])) + mix[target][i][2])
return gettime[target]
print(dfs(t))
由于我也是借鉴别人的,所以分析什么的看看就好,具体还是要翻阅原帖
这段代码将培育那些需要杂交才能得到的作物(起初我们没有的作物)所需的时间记录了下来;而在此基础上,还记录了每种杂交方案所需的两种植物和种植时间。
mix[target][i]保存了这些信息
这样一来,我们就不需要重复判断当前方案是否是时间最短的方案。
另外,本题还有一个理解的重点,就是求时间,时间包括两部分(以 A + B = C为例):
1)获取作物A 和 作物B 的时间
2)种植作物A 和 作物B 的时间
这两部分要好好零五,至少博主当时领悟了很久。
试题I:装饰珠
本题出现在了同届大赛Python组上,题解在另一份博客上写过了,直接点链接就可以访问。















 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









