






目录
L2-001紧急救援:涉及最短路dij和vector,邻接表,堆)
day1:
about:并查集
举例1:此题为2020的河北省赛第五题,标准的并查集,我学废了
#include<iostream>
using namespace std;
int father[1000005];
void init(int n)//初始化,让每个人的父亲都是自己
{
for (int i = 0; i <= n; i++)
{
father[i] = i;
}
}
int find(int x)//一直往后找父亲,直到找到自己是父亲的点,返回的是自己的祖先
{
return x == father[x] ? x : father[x] = find(father[x]);
}
void union2(int x, int y)//这是存父亲的操作,这个操作会让每个人的父亲等于后一个
{
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY)
{
father[rootX]=rootY;
}
}
bool same(int x, int y)//这个用来判断两个的祖先是不是一样的,来判断在不在一个集合里面
{
return find(x) == find(y);
}
long long getNums(int n)//在该题中,这个res是为了统计每个集合有多少个数字,我们能知道find(father[i])这个东西是找这个点i的祖先,好像find(i)也没差?
{
int* res = new int[n + 1];
for (int i = 1; i <= n; ++i) res[i] = 0;
long long ans = 1;
for (int i = 1; i <= n; i++)
{
res[find(father[i])]++;
}
for (int i = 1; i <= n; i++)
{
if (res[i]>1)
{
long long anss = 1;
for (int j = 1; j <= res[i]; j++)
{
anss *= 2;
anss %= 998244353;
}
ans=ans*(anss-1);
ans %=998244353;
}
}
return ans;
}
int main()
{
int n,m;
cin >>n>> m;
init(n);
for (int i=1;i<=m;i++)
{
int l,r;
cin >> l>>r;
union2(l,r);
}
cout << getNums(n);
}由上,我们可以学会——并查集就是开一个一维数组存父亲,然后通过递归调用找祖先,同一个祖先的就是在同一个集合之中,好,结束。
about:优先队列
举例1:合并果子
这个题就是每次都把最小的两个挑出来合并,这样可以得到最优解,那么怎么样更快捷的找到两个最小值呢,这里我们使用了优先队列,小根堆,把最小的放在堆顶
#include<bits/stdc++.h>
using namespace std;
priority_queue< int , vector<int> , greater<int> > a;//建立一个优先队列,int类型,以vector存储,用greater排序的队列,具体对象是a
long long t1,t2,ans,n,x;
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>x;
a.push(x);//放入队列
}
while(a.size()>1)
{
t1=a.top();//取出栈顶
a.pop();//删除栈顶
t2=a.top();
a.pop();
ans+=t1+t2;
a.push(t1+t2);
}
cout<<ans;
return 0;
}一些关于优先队列的知识来咯:
//优先队列创建大小跟堆,默认大根堆
#include<queue>
priority_queue<int> q;
priority_queue<int, vector<int>, less<int> > q;
//less表示按照递减(从大到小)的顺序插入元素
priority_queue<int, vector<int>, greater<int> > q;
//greater表示按照递增(从小到大)的顺序插入元素
q.empty();//队列空为真
q.pop();//删除对顶元素
q.push();//加入一个元素
q.size();//返回拥有元素个数
q.top();//返回对顶元素(默认int型最大的优先级高,先出队)
struct cmp
{
operator bool()(int x,int y)
{
return p[x]>p[y];//自定义优先级高的为p[i]小的
}
}
对于优先队列,很方便的就是他是一个有序的队列,在不需要记录序号的排序和取放的时候很方便。
举例2:Running Median这是一道找中位数的题目,而数集是动态的,这时候考虑优先队列,并时刻取出来一半,这个主意不怎么好,没有发挥优先队列的优势,还有一个想法是在增加数组的时候,统计三个数字,以此来标记中位数,这个可以把他优化一下,变成我们的最优解,开两个堆,大根堆和小根堆,拿新增的数字和这两个堆的堆顶作比较。
不知道为啥下面这个代码选c++11还爆了内存
#include <bits/stdc++.h>
using namespace std;
int x, num, n, a[10001];
int main()
{
scanf("%d", &x);
while(x--)
{
scanf("%d %d", &num, &n);
for(int i = 1;i <= n; i++)
{
scanf("%d", &a[i]);
}
printf("%d %d\n", num, n/2+1);
priority_queue <int, vector<int>, greater<int> > q;//小根堆放较大的数字
priority_queue <int, vector<int> > p;//大顶堆放较小的数字
for(int i = 1;i <= n; i++)
{
if((q.empty() && p.empty()) || a[i] >= q.top()) q.push(a[i]);//如果是第一个或者是比小根堆中最小的还大的数字,就放在小根堆里
else p.push(a[i]);//否则放在大顶堆里
while((int)q.size()-(int)p.size() > 1) //如果小根堆里的数字比大顶堆还多1,就移动一个最小的到大顶堆里面去
{
int t = q.top();
q.pop();
p.push(t);
}
while((int)p.size()-(int)q.size() > 1) //同理
{
int t = p.top();
p.pop();
q.push(t);
}
if(i&1)//如果此时的i是奇数,说明要输出了
{
if(q.size() > p.size()) printf("%d ", q.top());//通过判断哪个堆长度更长的方式找到需要的中位数
else printf("%d ", p.top());
}
if(i%20 == 0) puts("");//这个应该是换行把?
}
if(x) puts("");
}
}
以上,我们又学废了一个优先队列的好用处,就是动态存储,用两个堆的方式巧妙排序,取出中间的数字。
举例3:第K小,一开始用了两个优先队列,后来发现有点多余,就改成一个了,这一题非常简单,就是开一个大跟堆,里面是从小到大排序的,top是最大的,如果这个堆一直只有k的长度,堆顶不就是第k小的那个数字了吗,这里要注意的是维护这个优先队列保持k的长度。
#include<bits/stdc++.h>
using namespace std;
priority_queue <int, vector<int>, less<int> > q;
int main()
{
int n,m,k,t,a;
cin>>n>>m>>k;
for(int i=1;i<=n;i++)
{
cin>>a;
q.push(a);
}
while((int)q.size()>k)
{
int l=q.top();
q.pop();
}
for(int i=1;i<=m;i++)
{
cin>>t;
if(t==1)
{
cin>>a;
if((int)q.size()<k) q.push(a);
else if(a<=q.top())
{
q.push(a);
q.pop();
}
}
else
{
if((int)q.size()==k)cout<<q.top()<<endl;
else cout<<"-1"<<endl;
}
}
}举例4:这是一题贪心思想的选择士兵题,我有点想不明白的就是,如果为了满足新加入士兵而移出去的人如果战斗力比新加入士兵多的话,是不是得移动回来,题解的是不用,直接判断移动前后选最优解,那我就有点纳闷了,你都移动出来了,没有移动回去的操作,你后面不就不知道你的实际人数是几个了,那你选择的这个最优解在后面和优先队列的长度不匹配了怎么办??
这个是我的只对了一个样例的超时代码,还用到了向量vector
#include<iostream>
#include<queue>
#include<algorithm>
using namespace std;
priority_queue <int ,vector<int>,greater<int> >q;
vector<int> g;
struct dd
{
int v;
int s;
}a[100005];
bool cmp(dd x,dd y)
{
return x.s>y.s;
}
int main()
{
int n,ans=0;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i].v>>a[i].s;
}
sort(a+1,a+n+1,cmp);
for(int i=1;i<=n;i++)
{
if((int)q.size()<a[i].s)
{
q.push(a[i].v);
ans+=a[i].v;
}
else
{
int sum=0;
while((int)q.size()>=a[i].s)
{
sum+=q.top();
g.push_back(q.top());
q.pop();
}
if(sum<=a[i].v)
{
q.push(a[i].v);
ans+=a[i].v-sum;
}
else
{
auto it=g.begin();//vector<int>::iterator
while(it!=g.end())
{
q.push(*it);
it=g.erase(it);
}
}
}
}
cout<<ans<<endl;
}这是参考题解改正的代码,过于贪心,我实属不理解
#include<iostream>
#include<queue>
#include<algorithm>
using namespace std;
priority_queue <int ,vector<int>,greater<int> >q;
vector<int> g;
struct dd
{
long long v;
int s;
}a[100005];
bool cmp(dd x,dd y)
{
return x.s>y.s;
}
int main()
{
int n;
long long ans=0,sum=0;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i].v>>a[i].s;
}
sort(a+1,a+n+1,cmp);
for(int i=1;i<=n;i++)
{
sum+=a[i].v;
q.push(a[i].v);
while((int)q.size()>a[i].s)
{
sum-=q.top();
q.pop();
}
ans=max(ans,sum);
}
cout<<ans<<endl;
}day2:
我在学二分,但是我的笔记不知道为啥不见了
例1:找某个范围的完全平方数
第一种方法:巧妙用数学小知识:1-9有9个数字,那么1-81就有9个完全平方数。
#include<iostream>
#include<math.h>
using namespace std;
int main()
{
int n,l,r,m;
cin>>n;
for(int i=1;i<=n;i++)
{
int ans=0;
cin>>l>>r;
m=sqrt(l);
ans=(int)(sqrt(r))-m;
if(m*m==l) ans++;
cout<<ans<<endl;
}
}第二种方法:把范围内的完全平方数都按顺序存在数组里,然后通过stl中的二分函数来进行二分查找, upper_bound(v.begin(),v.end(),r)-lower_bound(v.begin(),v.end(),l);//就是把范围内的找出来。
返回第一个大于r的下标减去第一个小于l的下标就是
#include<iostream>
#include<algorithm>
#include<vector>
using namespace std;
long long n,m,l,r;
vector<long long>v;
void init()
{
v.push_back(0);
for(int i=1;i<=31623;i++)
{
v.push_back(i*i);
}
}
int main()
{
scanf("%lld",&n);
init();
while(n--)
{
scanf("%lld%lld",&l,&r);
long long res=upper_bound(v.begin(),v.end(),r)-lower_bound(v.begin(),v.end(),l);
printf("%lld\n",res);
}
return 0;
}第三种方法:我原本还有个想法,就是每个都二分查一下是不是在范围里,不过,我感觉有点多余。
例2:跳石头
这一个题经常做,但是想不起来怎么写,以下是copy的
#include<iostream>
using namespace std;
int n,m,L;
int a[50005];
bool check(int x)
{ //check函数判断这个最短跳跃距离x是否合法
int last=0; //last表示的是上一块石头的位置
int cnt=0; //cnt用来计数
for(int i=1;i<=n+1;i++)
{ //枚举每一块石头
if(a[i]-last<x) cnt++; //如果这一块石头和上一块石头的距离比x小,计数+1。而且如果石头移走,last还是上一块石头的位置。
else last=a[i]; //否则这块石头就不必移走,last=这块石头的位置。
}
if(cnt>m) return 0; //cnt如果超过m个,就不合法。
else return 1; //cnt如果小于等于m,就合法。
}
int main()
{
cin>>L>>n>>m;
for(int i=1;i<=n;i++) cin>>a[i];
a[n+1]=L; //注意这个一共有n+2块石头(起点和终点)
int l=1,r=L; //注意l和r都是最短跳跃距离的边界,而不是石头的边界。
while(l<r){
int mid=(l+r+1)>>1; //取中点,用的是第二种形式。 右移是除2,左移是乘2
if(check(mid)) l=mid; //分别处理
else r=mid-1;
}
cout<<l; //退出循环后一定是l==r,所以输出什么都可以。
return 0;
}day3
(2023年3月本废物又隆重登场)
今天是水题+总结
打的第一个,搞笑的是把pd2移到pd1前面直接对了九个
//一个简单的模拟打法,过了六个点,超时
#include<iostream>
#include<math.h>
int pd1(int x)
{
if(x==1) return 0;
if(x==2) return 1;
int k=sqrt(x);
for(int i=2;i<=k;i++)
{
if(x%i==0) return 0;
}
return 1;
}
int pd2(int x)
{
int y=0,z=x;
while(z)
{
y=y*10+z%10;
z/=10;
}
if(y==x) return 1;
else return 0;
}
using namespace std;
int main()
{
int a,b;
cin>>a>>b;
for(int i=a;i<=b;i++)
{
if(pd1(i)&&pd2(i)) cout<<i<<endl;
}
return 0;
}这个题方法就是一个一个数字判断,还可以列举回文判断质数,或者列举质数判断回文,然后函数可以剪枝
//改成埃氏筛法把到b的质数列举,对了九个点,牛逼!
#include<iostream>
#include<math.h>
#include<string.h>
using namespace std;
bool prime[100000010];
void pd11(int x)
{
for(int i=2;i<=x;i++)
{
if(prime[i])//如果是质数
{
for(int j=2*i;j<=x;j+=i)
{
prime[j]=false;//倍数不是质数
}
}
}
}
int pd2(int x)
{
int y=0,z=x;
while(z)
{
y=y*10+z%10;
z/=10;
}
if(y==x) return 1;
else return 0;
}
int main()
{
int a,b;
cin>>a>>b;
memset(prime,true,sizeof(prime));
pd11(b);
for(int i=a;i<=b;i++)
{
if(prime[i]&&pd2(i)) cout<<i<<endl;
}
return 0;
}//其他不变,改了个欧拉筛法,还是九个
#include<iostream>
#include<math.h>
#include<string.h>
using namespace std;
int p[100000010];
bool v[100000010];
void pd12(int x)
{
int cnt=0;
for(int i=2;i<=x;i++)
{
if(v[i]) p[cnt++]=i;
for(int j=0;j<cnt&&i*p[j]<=x;j++)
{
v[i*p[j]]=false;
if(i%p[j]==0) break;
}
}
}
int pd2(int x)
{
int y=0,z=x;
while(z)
{
y=y*10+z%10;
z/=10;
}
if(y==x) return 1;
else return 0;
}
int main()
{
int a,b;
cin>>a>>b;
memset(v,true,sizeof(v));
pd12(b);
for(int i=a;i<=b;i++)
{
if(v[i]&&pd2(i)) cout<<i<<endl;
}
return 0;
}知识点1:求质数和筛质数
单个的就判断到sqrt有没有被整除,筛一群的就把每个数的倍数筛出,再优化一下就是不重复筛一个倍数,就是让每个数只被最小质因数筛去(咋判断暂时没仔细看,可背下来)
知识点2:求回文和列举回文
我不想写了,求回文,1搞逆序数,2搞成字符串头尾比较,3什么栈还是什么的
int pd2(int x)//求逆序数,全部反转
{
int y=0,z=x;
while(z)
{
y=y*10+z%10;
z/=10;
}
return y==x;
}
int pd21(int x)//反转一半
{
if(x>0&&x%10==0) return 0;
int c=0;
while(x>c)
{
c=c*10+x%10;
x/=10;
}
return c==x || x==c/10;
}列举回文我去抄一个看看
(我去看了一些乱七八糟的题解,有打表的,有判断+剪枝的,比如说什么偶数位回文除了11都不是质数且是11的倍数,比如说什么符合要求的数字不超过9个九,还有制造回文数的,说是深搜,好不想看了下次一定)
搬了一个洛谷的代码过来
#include<iostream>
using namespace std;
bool isprime(int x){ //判断质数的函数,应该不用我多解释
if(x<2)return false;
if(x==2)return true;
for(int i=2;i*i<=x;i++){
if(x%i==0)return false;
}
return true;
}
int l,r,x,y; //l,r是题目范围,x,y是他们的长度
int a[10]; //储存创造出来的数
bool b=true; //用来作为是否跳出的判断
void go(int x,int k){ //k是总位数,x是目前枚举到的位置
if(x==(k+1)/2){ //(k+1)/2是k位的中间数,可以自己算一下
for(int i=k;i>x;i--){ //把剩下的位数完善
a[i]=a[k-i+1];
}
int shu=0; //将数组转化成数
for(int i=1;i<=k;i++){
shu=shu*10+a[i];
}
if(shu<l)return; //小于l就跳过
if(shu>r){ //大于r就跳出
b=false;
return;
}
if(isprime(shu))cout<<shu<<endl; //是质数就输出
return; //这个一定不能漏,要不然会一直搜下去(本人是亲身体验过的受害者)
}
int i;
if(x)i=0;
else i=1; //最高位不能是0
for(i=i;i<=9;i++){ //dfs(深度优先搜索)下一位,没学过可以去看下P1706
if(b==false)return; //如果已经出现大于r的数,就跳出函数
a[x+1]=i;
go(x+1,k);
}
return;
}
int weishu(int j){ //计算一个数的长度
int b=j,count=0;
while(b>0){
b/=10;
count++;
}
return count;
}
int main(){
cin>>l>>r;
x=weishu(l);
y=weishu(r);
for(int i=x;i<=y;i++){
if(i==1){ //一位数特判
if(l<=5&&r>=5)cout<<5<<endl;
if(l<=7&&r>=7)cout<<7<<endl;
continue;
}
if(i==2){ //两位数特判
if(l<=11&&r>=11)cout<<11<<endl;
continue;
}
if(i%2==0)continue; //偶数位就跳过
if(i==9)break; //九位直接跳出
b=true; //每次搜索要先重置这个变量
go(0,i); //从第0位开始搜
}
return 0;
}day4
四级都没过,来刷个小水题
//四重循环大枚举,30分
int n,m,ans=0,anss=0;
cin>>n>>m;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
for(int k=i;k<=n;k++)
{
for(int l=j;l<=m;l++)
{
if(i==j) anss++;
else ans++;
}
}
}
}
cout<<anss<<" "<<ans<<endl;整理一下,修改代码
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
if(i==j) anss+=(n-i+1)*(m-j+1);
else ans+=(n-i+1)*(m-j+1);
}
}40分,WA了6个,这说明啥,这说明我的思路错了,错得还不清。(数学剪枝哈哈哈( ╯□╰ )
好吧,下载了一个数据,发现是超过int范围了,开longlong直接过,水题诚不欺我。
我又去看了题解的一个,人家for循环里头是这样的
sum+=min(i,j);//是正方形
sum1+=i*j;//是全部day5
每天只打一个题目的懒鬼呜呜呜
使用暴力搜索枚举or背包
//暴力搜索,参考了洛谷的一个题解
#include<bits/stdc++.h>
int le,minn,ri;
int s[30][30],ans=0;
using namespace std;
void dp(int x,int y)
{
if(x>s[0][y])
{
minn=min(minn,max(le,ri));
return;
}
le+=s[x][y];
dp(x+1,y);
le-=s[x][y];
ri+=s[x][y];
dp(x+1,y);
ri-=s[x][y];
}
int main()
{
cin>>s[0][1]>>s[0][2]>>s[0][3]>>s[0][4];
for(int i=1;i<=4;i++)
{
for(int j=1;j<=s[0][i];j++)
{
cin>>s[j][i];
}
minn=99999999;
le=0;
ri=0;
dp(1,i);
ans+=minn;
}
cout<<ans<<endl;
}//借一个01背包代码来用
#include<bits/stdc++.h>
using namespace std;
int s[5],a[21],f[1210],ans=0;
int main()
{
for(int i=1;i<=4;i++)
cin>>s[i];//四个背包
for(int k=1;k<=4;k++)//依次进行枚举
{
int sum=0;
for(int j=1;j<=s[k];j++)
{
cin>>a[j];
sum+=a[j];//记录背包大小
}
memset(f,0,sizeof(f));//清空背包
f[0]=1;//初始化
for(int i=1;i<=s[k];i++)
for(int j=sum;j>=0;j--)
if(f[j])//如果上一个大小可以取
f[j+a[i]]=1;//那么加上物品后的容量也可以取
int tmp=sum,res;
for(int i=0;i<=sum;i++)//枚举答案
if(f[i]&&tmp>=abs(i-(sum-i)))
{
tmp=abs(i-(sum-i));
res=max(i,sum-i);
}
ans+=res;//将答案记录下来
}
cout<<ans<<endl;
}
day6
本水狗又来了。最近好多人生病,今天还在看水题
总结暴力水题秘诀:
1.认真看题目!!!
2.可以有更好的思路,但没必要搞得很麻烦,对于笨蛋来说。逻辑很重要。
3.如果时间复杂度允许,就按最简单的写法来
4.记得开longlong傻瓜!!!!算出来能大于八位数就开吧!!!!
呜呜呜我写的东西没保存呜呜呜
关于gcd最大公约数:
long long gcd(long long x,long long y)
{
return y?gcd(y,x%y):x;
}最小公倍数等于两数相乘/最大公约数
关于sort排序运用:
从大到小输出:
int cmp(int x,int y) { return x>y; }
sort(a+n,a+n+1,cmp); 从a[1]到a[n]按cmp规则排序
运用上STL的sort以及相关简单操作
#include<bits/stdc++.h>
using namespace std;
bool cmp(pair<int,int>a,pair<int,int>b)//为了让sort排序时候按pair中的first进行排序
{
return a.first<b.first;
}
int main()
{
int n,m,ans=0;
vector<pair<int,int>> p;//生成了一个对数组p
cin>>n>>m;
for(int i=1;i<=m;i++)
{
int x,y;
cin>>x>>y;
p.push_back({x,y});//这是将pair放入vector的方式
}
sort(p.begin(), p.end(), cmp);//对p按cmp的规律从开头到结尾进行排序
for(auto it=p.begin();it!=p.end();it++)//这是通过auto it进行循环,从开头到结尾
{
if(n!=0)
{
if(n>=it->second)//对于在数组中的指向不能直接用点,要用->不然会报错
{
ans+=it->first*it->second;
n-=it->second;
}
else
{
ans+=n*it->first;
n=0;
break;
}
}
}
cout<<ans<<endl;
}
前一个是pair后一个是vector,好像差别不大呀 vector受到数据影响大点
举例子:一个pair的定义输入排序输出
pair<int,int>pa[100];
int a,b;
for(int i=0;i<5;i++)scanf("%d%d",&a,&b),pa[i]=make_pair(a,b);
sort(pa,pa+5);
for(int i=0;i<5;i++)printf("%d %d\n",pa[i].first,pa[i].second);
return 0;
下回把stl搞清楚一下(未做)
day7
今天是考了个二级的一天,pta做的很烂,把算法的东西写在这里。
题目一:用了栈,因为先进后出,还用了一个multiset,排序比较方便可以了解一下
https://www.luogu.com.cn/problem/P1165?contestId=104480
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;
cin>>n;
stack<int>a;
multiset<int>q;
for(int i=1;i<=n;i++)
{
int x;
cin>>x;
if(x==0)
{
int y;
cin>>y;
a.push(y);
q.insert(y);
}else if(x==1)
{
if(!a.empty()) q.erase(a.top());
a.pop();
}else
{
if(a.empty()) cout<<"0"<<endl;
else cout<<*q.rbegin()<<endl;
}
}
}题目二:找共同亲戚的,并查集一直不老实记下来
https://www.luogu.com.cn/problem/P1551?contestId=104480
#include<bits/stdc++.h>
using namespace std;
int father[5005];
void init(int n)
{
for (int i = 0; i <= n; i++)
{
father[i] = i;
}
}
int find(int x)
{
return x == father[x] ? x : father[x] = find(father[x]);
}
void union2(int x, int y){
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY)
{
father[rootX]=rootY;
}
}
bool same(int x, int y){
return find(x) == find(y);
}
int main()
{
int n,m,p,a[5001],b[5001],x[5001],y[5001];
cin>>n>>m>>p;
init(n);
for(int i=1;i<=m;i++)
{
cin>>a[i]>>b[i];
if(a[i]<b[i]) union2(a[i],b[i]);
else union2(b[i],a[i]);
}
for(int i=1;i<=p;i++)
{
cin>>x[i]>>y[i];
if(find(x[i])==find(y[i])) cout<<"Yes"<<endl;
else cout<<"No"<<endl;
}
}题目三:关于cmp和结构体,略
题目四:重头戏来啦,最短路先上!
https://www.luogu.com.cn/problem/P1396
第一次floyd:得了十分(是无向图,没有双向赋值
第二次floyd:70分,一个点超时,两个点超边界
#include<bits/stdc++.h>
using namespace std;
int e[1005][1005];
const int INF=0xffff;
int main()
{
int n,m,s,t;
cin>>n>>m>>s>>t;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
{
if(i!=j) e[i][j]=INF;
}
for(int i=1;i<=m;i++)
{
int u,v,w;
cin>>u>>v>>w;
if(e[u][v]>w)
{
e[u][v]=w;
e[v][u]=w;
}
}
for(int k=1;k<=n;k++)
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
{
e[i][j]=min(e[i][j],max(e[i][k],e[k][j]));
}
}
cout<<e[s][t]<<endl;
}第一次dij:30分,我又没有搞好无向图的存法,把每条线都存进去就对了
第二次dij: 100分
#include<bits/stdc++.h>
using namespace std;
const int INF=0xfffff;
int main()
{
int n,m,s,t;
cin>>n>>m>>s>>t;
vector<int>head(n*2+1,-1),e(m*2+1,0),nex(m*2+1,0),w(m*2+1,0),dist(m*2+1,INF);
vector<bool>vis(n*2+1,false);
for(int i=1;i<=m;i++)
{
int u,v,t;
cin>>u>>v>>t;
e[i]=v;
nex[i]=head[u];
head[u]=i;
w[i]=t;
e[i+m]=u;
nex[i+m]=head[v];
head[v]=i+m;
w[i+m]=t;
}
dist[s]=0;
priority_queue<int,vector<pair<int,int>>,greater<> >q;
q.push({0,s});
while(!q.empty())
{
int id=q.top().second;
q.pop();
if(vis[id]) continue;
vis[id]=true;
for(int i=head[id];i!=-1;i=nex[i])
{
int j=e[i];
if(dist[j]>max(dist[id],w[i]))
{
dist[j]=max(dist[id],w[i]);
}
q.push({dist[j],j});
}
}
cout<<dist[t]<<endl;
}大佬的二分(有空再看
#include <cstdio>
#include <algorithm>
#define min(x,y)(x<y?x:y)
#define max(x,y)(x>y?x:y)
using namespace std;
const int M = 10001;
const int INF = 999999;
int n,m,u[M<<1],go[M<<1],val[M<<1],ans;
int fa[M],a,b;
int l = INF,r,mid;
inline int read() {
register int ans=0;register char c=getchar();register bool neg=0;
while((c<'0')|(c>'9')) neg^=!(c^'-'),c=getchar();
while((c>='0')&(c<='9')) ans=(ans<<3)+(ans<<1)+(c^'0'),c=getchar();
return neg?-ans:ans;
}
//快读
inline int getfa(int x)
{
if(fa[x] == x) return x;
return fa[x] = getfa(fa[x]);
}
//并查集
inline bool judge(int x,int y) {
if(getfa(x) != getfa(y)) return 0;
return 1;
}
//并查集判断
inline void H_(int x,int y)
{
if(getfa(x) != getfa(y)) fa[getfa(x)] = fa[getfa(y)];
}
//合并
inline bool check(int x)
{
for(register int i = 1;i <= n; i++) fa[i] = i;
for(int i = 1;i <= m; i++) if(val[i] <= x) H_(u[i],go[i]);
//将权值小于等于mid的边的量个点合并
return judge(a,b);
}
int main(void)
{
n=read();m=read();a=read();b=read();
for(register int i = 1;i <= m; i++)
{
u[i] = read();go[i] = read();val[i] = read();
l = min(val[i],l); r = max(val[i],r);
}
//二分
while(l <= r)
{
mid = (l + r) >> 1;
if(check(mid)) ans = mid,r = mid - 1;
else l = mid + 1;
}
printf("%d",ans);
return 0;
}
大佬的spfa(这玩意我也不会,有空再看
最后再附上SPFA的代码
#include <cstdio>
#include <algorithm>
#include <cstring>
#include <queue>
//char xB[1<<15],*xS=xB,*xT=xB;
//#define getchar() (xS==xT&&(xT=(xS=xB)+fread(xB,1,1<<15,stdin),xS==xT)?0:*xS++)
using namespace std;
const int M = 30001;
inline int read() {
int ret;bool flag=0;char c;
while((c=getchar())<'0'||c>'9')flag^=!(c^'-');ret=c^48;
while((c=getchar())>='0'&&c<='9') ret=(ret<<3)+(ret<<1)+(c^48);
return flag?-ret:ret;
}
//快读
queue <int> Q;
int fir[M>>1],nex[M],go[M],val[M];
int dis[M>>1],vis[M>>1];
int n,m,a,b,tot;
inline void add_edge(int x,int y,int z)
{
nex[++tot] = fir[x],fir[x] = tot,go[tot] = y,val[tot] = z;
}
//前向星
int main(void)
{
n = read();m = read();a = read();b = read();
for(int i = 1;i <= m; i++)
{
int x,y,z;
x = read();y = read();z = read();
add_edge(x,y,z);
add_edge(y,x,z);
}
for(int i = 1;i <= n; i++) dis[i] = 1e9 + 7;
dis[a] = 0;
Q.push(a);
vis[a] = 1;
while(!Q.empty())
{
int Now = Q.front();
Q.pop();
int Go;
vis[Now] = 0;
for(int i = fir[Now];i,Go = go[i];i=nex[i])
{
if(dis[Go] > max(dis[Now],val[i]))
{
dis[Go] = max(dis[Now],val[i]);
if(!vis[Go]) Q.push(Go),vis[Go]=1;
}
}
}
if(dis[b] == 1e9+7) dis[b] = -1;
printf("%d",dis[b]);
return 0;
}这题的正解是最小生成树(但是我数据结构课没有认真听呜呜呜)
开始最小生成树学习ing
去看树的那篇博客,学好了哈哈哈
day8 :开始打ptaL2的题目
L2-001紧急救援:涉及最短路dij和vector,邻接表,堆)
如果表较为稀疏就用邻接表存图。(M约等于N)
dij通常需要开设1个存边的,1个更新路径的和一个判断点存没存的
(后两个与点的数量有关,前一个如果是邻接表就和边的数量有关,如果且是无向图就是边数量的双倍)
贪心思想不可以求负权边。(具体见最短路博客)
先打了一个模板dij,我打算之后都用这个模板
#include<bits/stdc++.h>
using namespace std;
#define F(i,m,n) for(int i=m;i<=n;i++)
const int INF=0x3f3f,M=1000,N=505;
vector<int>head(N,-1),e(M,0),nex(M,0),w(M,0);//邻接表
vector<int>dis(N,INF);//路径
vector<bool>vis(N,false);//判断是否已经过
int idx=0;
void add(int a,int b,int c)//idx是边的编号
{
e[idx]=b;//用来访问这条边指向的节点
nex[idx]=head[a];//用来找下一个边
head[a]=idx;//存储头结点为a的第一个边
w[idx]=c;//记录边的权重
idx++;
}
int main()
{
int n,m,s,d,a[N];//s,d是始终点
cin>>n>>m>>s>>d;
F(i,0,n-1)
{
cin>>a[i];
}
F(i,0,m-1)
{
int x,y,z;
cin>>x>>y>>z;
add(x,y,z);
add(y,x,z);
}
dis[s]=0;
priority_queue<int,vector<pair<int ,int>>,greater<>>q;
//存的是到起点的目前的最大距离和点,按距离从小到大排序
q.push({0,s});//加入
while(!q.empty())//判断是否为空队列
{
int id=q.top().second;//返回堆顶的第二个元素
q.pop();//删除堆顶
if(vis[id]) continue;
//重复执行几次一直到每个点的邻接表都被查过了,说明每条边我们都走过了,很快堆就会变成空的
vis[id]=true;
for(int i=head[id];i!=-1;i=nex[i])//这里查的是以id为起点的每条边
{
int j=e[i];
if(dis[j]>dis[id]+w[i])
{
dis[j]=dis[id]+w[i];
}//对于已经有的s-j的路线,如果能覆盖就覆盖
q.push({dis[j],j});
//无论如何都放进去,如果大了,也不会影响什么,但是j是新走过的路,如果不加,可能堆里会没有j点
}
}
cout<<dis[d]<<endl;
}之前打过,如果要输出路径或者增加别的什么东西就直接改模板就好了,代码如下
#include<bits/stdc++.h>
#define F(i,n,m) for(int i=n;i<=m;i++)
using namespace std;
const int inf=0x3f3f3f;
int t1,t2,t3;
int n,m,s,d;
int main()
{
cin>>n>>m>>s>>d;
vector<int>h(n*2+1,-1),e(m*2+1,0),ne(m*2+1,0),w(m*2+1,0),dist(m*2+1,inf),num(n*2+1,1);//head存第一条边的序号,head的下标是点的序号
vector<bool>vis(n*2+1,false);
int a[n*2+1];//每个城市的救援队
vector<int>c(n*2+1,0);//到每个城市集结的最多救援队
F(i,0,n-1)
{
cin>>a[i];
}
F(i,0,m-1)
{
scanf("%d %d %d",&t1,&t2,&t3);
e[i]=t2;
ne[i]=h[t1];
h[t1]=i;
w[i]=t3;
e[i+m]=t1;
ne[i+m]=h[t2];
h[t2]=i+m;
w[i+m]=t3;
}
dist[s]=0;
priority_queue<int,vector<pair<int,int>>,greater<>>q;//第一个数代表距离,第二个数代表点
vector<vector<int>>citys(n*2+1);
q.push({0,s});
c[s]=a[s];
citys[s].push_back(s);
while(!q.empty())
{
int id=q.top().second;
q.pop();
if(vis[id]) continue;
vis[id]=true;
for(int i=h[id];i!=-1;i=ne[i])//i是边的序号,id是点的序号,j是id连接的点的序号
{
int j=e[i];
if(dist[j]>dist[id]+w[i])
{
dist[j]=dist[id]+w[i];
num[j]=num[id];
c[j]=c[id]+a[j];
citys[j]=citys[id];
citys[j].push_back(j);
}
else if(dist[j]==dist[id]+w[i])
{
num[j]+=num[id];
if(c[j]<c[id]+a[j])
{
c[j]=c[id]+a[j];
citys[j]=citys[id];
citys[j].push_back(j);
}
}
q.push({dist[j],j});
}
}
cout<<num[d]<<" "<<c[d]<<endl;
int l=citys[d].size();
F(i,0,l-2)cout<<citys[d][i]<<" ";
cout<<citys[d][l-1]<<endl;
}002链表查重
大概意思就是给出一串数据的前后结点地址,对于一整串链表来进行删除操作,使得绝对值一样的被删除,感觉是模拟题,代码比较抽象,各种标记法,主要用到结构体和两个函数存两种链表
003月饼
也是模拟,结构体排序
004这是二叉搜索树吗
没啥思路
去看了一圈题解,首先,前序遍历可以直接建立二叉搜索树。其次,该题是找后序,可以根据左右子树来直接判断是不是二叉树,然后输出后序。好像判断后序的长度是不是n也可以判断出这题是不是二叉树。
csdn找了一个比较好理解的代码如下,原L2-004 这是二叉搜索树吗?(二叉树)_l2-004 这是二叉搜索树吗?_MangataTS的博客-CSDN博客
#include<bits/stdc++.h>
using namespace std;
int a[1005],n;
vector<int> ans;
void dfs1(int root,int tail)
{
if(root > tail) return;
int l = root + 1,r = tail;
while(a[l] < a[root] && l <= tail) l++;
while(a[r] >= a[root] && r > root) r--;
if(l - r != 1) return;//因为要刚好越过分界线
dfs1(root+1,r);//向左子树递归
dfs1(l,tail);//向右子树递归
ans.push_back(a[root]);//将当前的父节点放入答案
//如果我们发现是一个二叉搜索树那么ans存的就是后根遍历的结果,
//因为是递归左右子树后才放入ans中的,下面同理
}
void dfs2(int root,int tail){
if(root > tail) return;
int l = root + 1,r = tail;
while(a[l] >= a[root] && l <= tail) l++;
while(a[r] < a[root] && r > root) r--;
if(l - r != 1) return;
dfs2(root+1,r);
dfs2(l,tail);
ans.push_back(a[root]);
}
int main()
{
cin>>n;
for(int i = 0;i < n; ++i) cin>>a[i];
dfs1(0,n-1);
if((int)ans.size() != n)//没找到,再找一次镜像
{
ans.clear();
dfs2(0,n-1);
}
if((int)ans.size() == n)
{
cout<<"YES"<<endl;
for(int i = 0;i < n; ++i) cout<<ans[i]<<" \n"[i == n-1];
}
else
{
cout<<"NO"<<endl;
}
return 0;
}
L2-005集合相似度-STLSET
题目的意思很好理解,就是统计多对集合不相似不重复数。用stl的集合set来解决
源代码如下
#include<bits/stdc++.h>
using namespace std;
int n;
#define F(i,n,m) for(int i=n;i<=m;i++)
int main()
{
cin>>n;
set<int> q[55];
F(i,1,n)
{
int a;cin>>a;
F(j,1,a)
{
int b;scanf("%d",&b);
q[i].insert(b);
}
}
int k;
cin>>k;
F(i,1,k)
{
int x, y;
int sum=0;
scanf("%d %d",&x,&y);
for(auto j:q[x])if(q[y].count(j))++sum;
int ans=q[x].size()+q[y].size()-sum;
double d=(double)sum/(double)ans;
printf("%.2f%%\n",d*100/1.0);
}
}复习一下set的用法
//set作为一个容器也是用来存储同一数据类型的数据类型,并且能从一个数据集合中取出数据,在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。应该注意的是set中数元素的值不能直接被改变。
set<int> s;
set<int>::const_iterator iter;
set<int>::iterator first;
set<int>::iterator second;
F(i,1,10)
{
s.insert(i);//添加i在集合中
}
erase(iterator)//删除定位器iterator指向的值
erase(first,second)//删除定位器first和second之间的值
erase(key_value)//删除键值key_value的值
if(!a.count(x))//集合中没找到x以下函数:
(1) insert(x)可将x插入set容器中,并且自动递增排序和去重,时间复杂度O(logN),其中N是set中元素的数量。
(2) find(x)返回set中对应值为x的迭代器,时间复杂度O(logN),N为set内元素的个数。
(3) erase()erase有两种用法:删除单个元素,删除一个区间内的所有元素。
删除单个元素有两种方式:erase(it)
删除该迭代器对应的元素,时间复杂度O(1)
erase(x):
删除该元素,时间复杂度O(logN)
删除一个区间的元素erase(st,ed)
删除区间[st,ed)内的元素,时间复杂度O(ed-st)
(4) size()用来获得set内元素的个数,时间复杂度O(1)
(5) clear()用来清空set中所有元素,复杂度O(N),其中N为set内元素的个数。
(6) count(x)返回set中x的数量
006-树的遍历queue
该死的树,我真的搞不懂,,,
首先,我们需要知道层序遍历是什么,其实就是一层一层往下 遍历,,,
那么后序和中序怎么建树捏
我试图自己写一个,写的跟狗屎一样,不过我觉得递归是个可行的方法。
下面是一个知道中后求前序的,不过这题求的是层序。
#include<cstdio>
#include<iostream>
#include<cstring>
using namespace std;
void beford(string in,string after)
{
if (in.size()>0)
{
char ch=after[after.size()-1];
cout<<ch;//找根输出
int k=in.find(ch);
beford(in.substr(0,k),after.substr(0,k));
beford(in.substr(k+1),after.substr(k,in.size()-k-1));//递归左右子树;
}
}
int main()
{
string inord,aftord;
cin>>inord;
cin>>aftord;//读入
beford(inord,aftord);
cout<<endl;
return 0;
}
/*BADC
BDCA
ABCD
*/我去查题解,人家太聪明啦,加了个变量用来存层序,这不是很好吗?
已知后序与中序输出前序(先序):
后序:3, 4, 2, 6, 5, 1(左右根)
中序:3, 2, 4, 1, 6, 5(左根右)
分析:因为后序的最后一个总是根结点,令i在中序中找到该根结点,则i把中序分为两部分,左边是左子树,右边是右子树。因为是输出先序(根左右),所以先打印出当前根结点,然后打印左子树,再打印右子树。左子树在后序中的根结点为root – (end – i + 1),即为当前根结点-(右子树的个数+1)。左子树在中序中的起始点start为start,末尾end点为i – 1.右子树的根结点为当前根结点的前一个结点root – 1,右子树的起始点start为i+1,末尾end点为end。
输出的前序应该为:1, 2, 3, 4, 5, 6(根左右)
#include <cstdio>
using namespace std;
int post[] = {3, 4, 2, 6, 5, 1};
int in[] = {3, 2, 4, 1, 6, 5};
void pre(int root, int start, int end) {
if(start > end) return ;
int i = start;
while(i < end && in[i] != post[root]) i++;
printf("%d ", post[root]);
pre(root - 1 - end + i, start, i - 1);
pre(root - 1, i + 1, end);
}
int main() {
pre(5, 0, 5);
return 0;
}另外还有个建树的,让我copy来研究一波
天梯赛刷题笔记-L2-006 树的遍历_月色美兮的博客-CSDN博客
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#include<unordered_map>
#include<queue>
using namespace std;
typedef long long ll;
const int N = 45;
int n;
int postorder[N], inorder[N]; //后序遍历,中序遍历
unordered_map<int, int>l, r, pos; //每个点左右儿子,pos代表在中序遍历中每个值对应的下标
int build(int il, int ir, int pl, int pr) { //中序遍历和后序遍历左右端点
int root = postorder[pr]; //根节点是后序遍历的右端点
int k = pos[root]; //根节点在中序遍历中的下标
if (il < k) l[root] = build(il, k - 1, pl, pl + k - 1 - il); //左子树存在
//左子树中序遍历和后序遍历的长度一样所以 x-pl=k-1-il
if (ir > k) r[root] = build(k + 1, ir, pl + k - 1 - il + 1, pr - 1);//右子树存在
return root;
}
void bfs(int root, int n) {
queue<int>q;
q.push(root);
while (q.size()) {
auto t = q.front();
q.pop();
n--;
if (n != 0) cout << t << " ";
else cout << t;
if (l.count(t)) q.push(l[t]); //左子树存在,插入队列
if (r.count(t)) q.push(r[t]); //右子树存在,插入队列
}
}
int main() {
cin >> n;
for (int i = 0; i < n; i++) cin >> postorder[i];
for (int i = 0; i < n; i++) {
cin >> inorder[i];
pos[inorder[i]] = i; //中序遍历每个值对应的下标
}
int root = build(0, n - 1, 0, n - 1); //中序遍历,后序遍历区间
bfs(root, n);
return 0;
}关于stl中的queue就是先进先出的普通队列啦
int x;
Queue_Name.push(x);//将元素放入队尾
Queue_Name.pop();//弹出队头元素
int f=Queue_Name.front();//返回队头元素
int b=Queue_Name.back();//返回队尾元素
bool Emp=Queue_Name.empty();//判断队列是否为空
int l=Queue_Name.size();//返回队列的大小
我感觉数据结构尤其是树真的好难理解啊┭┮﹏┭┮,我先不研究,继续打题
!!!!!我打了一个堪称模板的!
#include<bits/stdc++.h>
using namespace std;
int n,a[50],b[50];
#define f(i,n,m) for(int i=n;i<=m;i++)
struct TREE
{
int data;
TREE *left,*right;
};
TREE* create(int l1,int r1,int l2,int r2)
{
if(l1>r1||l2>r2) return NULL;
TREE* root=new(TREE);
root->data=a[r2];
int index=-1;
f(i,l1,r1)
{
if(a[r2]==b[i])
{
index=i;break;
}
}
root->left=create(l1,index-1,l2,r2-r1+index-1);
root->right=create(index+1,r1,r2-r1+index,r2-1);
return root;
}
int r=0;
//层次遍历
void Inorder(TREE* T)
{
queue<TREE*>q;
q.push(T);
while(!q.empty()){
int n=q.size();
while(n--){
TREE* root=q.front();
if(!r)cout<<root->data;
else cout<<" "<<root->data;
q.pop();
if(root->left)q.push(root->left);
if(root->right)q.push(root->right);
}
r++;
}
}
int main()
{
int n;
cin>>n;
f(i,1,n) cin>>a[i];
f(i,1,n) cin>>b[i];
TREE* tree;
tree=create(1,n,1,n);
Inorder(tree);
}L2-007 家庭房产并查集+map
我的猜测是并查集,打打看。
可以改union2中的if符号改变祖先,然后排序的话可以写个结构体啊map啥的,俺不想写了。。。随便找一个看看
#include<bits/stdc++.h>
using namespace std;
struct node{
int id;
int flag;
// fu,mu;
// int child[5];
int set;
int area;
}people[1010];
struct Ans{
int flag;
int id;int ren;
double set,area;
}ans[10000];
bool cmp(Ans a,Ans b){
if(a.area!=b.area) return a.area>b.area;
else return a.id<b.id;
}
int father[10000];
int have[10000];
int getFather(int x){
int a=x;
while(x!=father[x]) x=father[x];
while(a!=x){
int z=father[a];
father[a]=x;
a=z;
}
return x;
}
void unoin(int a,int b){
int fa=getFather(a);int fb=getFather(b);
if(fa>fb) father[fa]=fb;
else father[fb]=fa;
}
void init(){
for(int i=0;i<10000;i++) father[i]=i;
return;
}
int main(){
init();
int n;
cin>>n;
for(int i=0;i<n;i++){
int id,fu,mu,k,child,set,area;
scanf("%d %d %d %d",&id,&fu,&mu,&k);
have[id]=1;
if(fu!=-1){
unoin(id,fu);have[fu]=1;
}
if(mu!=-1){
unoin(id,mu);have[mu]=1;
}
for(int j=0;j<k;j++){
scanf("%d",&child);have[child]=1;
unoin(child,id);
}
scanf("%d %d",&set,&area);
people[i].id=id;people[i].set=set;people[i].area=area;
}
//家族房产套数、面积统计 找people[1010]
for(int i=0;i<n;i++){
int father=getFather(people[i].id);
ans[father].id=father;
ans[father].flag=1;
ans[father].ren=0;
ans[father].set+=people[i].set;
ans[father].area+=people[i].area;
}
//家族数 人数 找所有人
int cnt=0;
for(int i=0;i<10000;i++){
if(have[i]==1){
int father=getFather(i);
ans[father].ren++;
}
if(ans[i].flag==1) cnt++;
}
printf("%d\n",cnt);
for(int i=0;i<10000;i++){
if(ans[i].flag==1){
ans[i].set=ans[i].set*1.0/ans[i].ren;
ans[i].area=ans[i].area*1.0/ans[i].ren;
}
}
sort(ans,ans+10000,cmp);
for(int i=0;i<cnt;i++){
printf("%04d %d %.3f %.3f\n",ans[i].id,ans[i].ren,ans[i].set,ans[i].area);
}
return 0;
}关于map
关于map
#include<map>
map<int,int> a;//建立一个STL容器
f(i,1,n)
{
cin>>x;
a.insert(pair<int,int>(x,i));//用对存储 key是x 如果有同样的x 不录入
}
map<int,int>::iterator k;//定义变量k, 可赋值a的key和second
f(i,1,m)
{
cin>>x;
k=a.find(x);//令k等于x的对应数值
if(k!=a.end())//如果k存在,即找到了key为x的对应数值,一定是输出第一个
{
cout<<k->second;//意思为输出k的second
}
else cout<<"-1";//没找到
}
}
录入
1.使用insert//关键词重复不录入
m.insert(pair<int,string>(1,"333"));
2.使用数组方式//关键词重复会覆盖
m[1]="333";
遍历
m_t::iterator i;//初始化变量
for(i=m.begin();i!=m.end();i++)//从开始到结尾遍历
{
cout<<i->first<<" "<<i->second<<endl;//输出key和对应值
}map<int,pair<int,int> >a;//建立三个数值的map (加个pair
for(auto i:a)
{
if(i.second.first) cout<<i.fisrt<<" "<<i.second.second;//查找非键值
}
if(a.count(d))//查找key为d的
{
ans++;
anss+=s-a[d].first;
anss+=a[d].second;
a.erase(d);//删除
}
008- 最长对称子串
字符串回文?打打看吧
我高估了这个题,直接模拟就行了
#include<bits/stdc++.h>
#define f(i,n,m) for(int i=n;i<=m;i++)
int maxx=-1;
using namespace std;
int main()
{
string a;
getline(cin,a);
int n=a.size();
f(i,0,n)
{
int r=i-1;
int l=i+1;
int ans=1;
while(r>=0&&l<n)
{
if(a[r]==a[l])
{
ans+=2;
r--;
l++;
}else
{
break;
}
}
if(ans>maxx) maxx=ans;
r=i;
l=i+1;
ans=0;
while(r>=0&&l<n)
{
if(a[r]==a[l])
{
ans+=2;
r--;
l++;
}else
{
break;
}
}
if(ans>maxx) maxx=ans;
}
cout<<maxx<<endl;
}009-抢红包
这题我猜也能模拟
也很简单,结构体排序
#include<bits/stdc++.h>
#define f(i,n,m) for(int i=n;i<=m;i++)
using namespace std;
struct dd
{
double q=0.0;
int bh=0;
int gs=0;
}a[10005];
bool cmp(dd x,dd y)
{
if(x.q!=y.q) return x.q>y.q;
else if(x.gs!=y.gs) return x.gs>y.gs;
else return x.bh<y.bh;
}
int main()
{
int n;
cin>>n;
f(i,1,n)
{
a[i].bh=i;
int k,t,p;
cin>>k;
f(j,1,k)
{
cin>>t>>p;
a[i].q-=p;
a[t].q+=p;
a[t].gs++;
}
}
sort(a+1,a+n+1,cmp);
f(i,1,n)
{
a[i].q/=100.0;
printf("%d %.2lf\n",a[i].bh,a[i].q);
}
}010排座位
我直接猜是并查集,敌人开个二维数组判断好了
判断的非常准确,不过
1二位判断注意要把无向的双重赋值
2并查集三目循环第一个条件语句要两个等于号
3union2的打法是先找祖先再赋值为祖先
4循环的边界要注意是哪个变量
#include<bits/stdc++.h>
#define f(i,n,m) for(int i=n;i<=m;i++)
using namespace std;
int dr[105][105];
int father[105];
void init(int n)
{
f(i,1,n) father[i]=i;
}
int find(int x)
{
return father[x]==x?x:find(father[x]);
}
void union2(int x,int y)
{
int rx=find(x);
int ry=find(y);
if(rx!=ry) father[rx]=ry;
}
int same(int x,int y)
{
return find(x)==find(y);
}
int main()
{
int n,m,k;
cin>>n>>m>>k;
init(n);
f(i,1,m)
{
int x,y,z;
cin>>x>>y>>z;
if(z==1)
{
union2(x,y);
}
else
{
dr[x][y]=z;
dr[y][x]=z;
}
}
f(i,1,k)
{
int x,y;
cin>>x>>y;
if(dr[x][y]==-1)
{
if(same(x,y)) cout<<"OK but..."<<endl;
else cout<<"No way"<<endl;
}
else if(same(x,y)) cout<<"No problem"<<endl;
else cout<<"OK"<<endl;
}
}011玩转二叉树
我看我是玩不转这玩意了,呜呜呜我真的会哭
这个是别人的代码
#include <bits/stdc++.h>
using namespace std;
const int N = 1100;
int a[N], b[N]; // a 中序遍历序列, b 前序遍历序列
int tree[N], sum[N]; // tree 暂时存放树中的结点, sum 层序遍历序列
void build(int n, int la, int ra, int lb, int rb)
{
if(ra < la || rb < lb)
return ;
if(ra == la)
{
tree[n] = a[la];
return ;
}
for(int i = la; i <= ra; ++ i)// 记得是遍历数组a, 一定注意!!!
{
if(a[i] == b[lb])
{
tree[n] = b[lb];
build(2 * n, la, i - 1, lb + 1, lb + i - la);
build(2 * n + 1, i + 1, ra, lb + i - la + 1 , rb);
}
}
}
void bfs(int s)
{
queue<int>q;
int cnt = 1;
q.push(s);
while(q.size() != 0)
{
int p = q.front();
q.pop();
if(tree[p] != 0)
{
sum[cnt++] = tree[p];
q.push(2 * p + 1);
q.push(2 * p);
}
}
}
int main()
{
int n;
memset(tree, 0, sizeof(tree));// 记得初始化
cin >> n;
for(int i = 1; i <= n; ++ i)cin >> a[i];
for(int i = 1; i <= n; ++ i)cin >> b[i];
build(1, 1, n, 1, n);
bfs(1);
for(int i = 1; i <= n; ++ i)
{
if(i == n)cout << sum[i];
else cout << sum[i] <<" ";
}
} 再来一个代码
#include <bits/stdc++.h>
#define LL long long
using namespace std;
const int maxn = 1e5 + 10;
const double PI = acos(-1.0);
int zhong[50], qian[50];
struct node {
int data;
node *l, *r;
};
int now = 0;
int n;
node *creat(int l, int r) {
if (l > r) return NULL;
int mid;
node *root = new node;
root->data = qian[now];
for (int i = l; i <= r; i++) {
if (qian[now] == zhong[i]) {
mid = i;
break;
}
}
now++;
root->l = creat(l, mid - 1);
root->r = creat(mid + 1, r);
return root;
}
vector<int> ans;
void ceng(node *root) {
queue<node *> q;
q.push(root);
while (q.size()) {
auto now = q.front();
q.pop();
if (now == NULL) continue;
ans.push_back(now->data);
q.push(now->r);
q.push(now->l);
}
}
int main(int argc, char const *argv[]) {
cin >> n;
for (int i = 0; i < n; i++) cin >> zhong[i];
for (int i = 0; i < n; i++) cin >> qian[i];
node *root = creat(0, n - 1);
ceng(root);
for (int i = 0; i < ans.size(); i++) {
if (i == ans.size() - 1)
cout << ans[i] << endl;
else
cout << ans[i] << ' ';
}
return 0;
}012堆的判断,不知道是什么鸟,先跳过
一开始还以为是特么按顺序的二叉树,写了半天的判断
#include<bits/stdc++.h>
using namespace std;
const int N = 1010;
int h[N];
int n,m;
map<int,int> mp;
void heap_swap(int a,int b)
{
swap(h[a],h[b]);
}
void up(int x)
{
while(x/2 && h[x/2]>h[x])
{
heap_swap(x/2,x);
x/=2;
}
}//建立一个小根堆,需要用到up()进行建堆,同时为了后序对两个结点间的关系进行判断,我们需要将建好的堆的值与其下标形成一种映射关系,所以需要用到map
//在比较阶段我们只需用到一个string s用来抵消字符串和判断是哪一种情况,之后根据之前建好的map,对映射间的关系进行判断即可
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)
{
cin>>h[i];
up(i);
}
for(int i=1; i<=n; i++) mp[h[i]]=i;
string s;
int x,y;
while(m--)
{
cin>>x;
cin>>s;
if(s[0]=='a') //x and y are siblings
{
cin>>y;
getline(cin,s);
if(mp[x]/2==mp[y]/2) puts("T");
else puts("F");
}
else
{
cin>>s;
cin>>s;
if(s[0]=='r') //x is the root
{
if(mp[x]==1) puts("T");
else puts("F");
}
else if(s[0]=='p') //x is the parent of y
{
cin>>s;
cin>>y;
if(mp[x]==mp[y]/2) puts("T");
else puts("F");
}
else //x is a child of y
{
cin>>s;
cin>>y;
if(mp[x]/2==mp[y]) puts("T");
else puts("F");
}
}
}
return 0;
}
L013 红色警报并查集
我猜是并查集,但是我不知道怎么写
我写了一个并查集,然后我发现需要删除点位再判断联通关系是否改变,emmm
我去看了一下别人的,方法就是统计集合数量,然后一个个删除点,再一次次并查集统计集合数量,然后通过这个判断条件就能得出城市删除是否影响的结论了,这一题需要把边都保存下来。
using namespace std;
int n,m;
int fa[505];
int K;
struct DATA
{
int x,y;
}p[5005];
int vis[1000];
int Find(int x)
{
if(fa[x]==x) return x;
return fa[x]=Find(fa[x]);
}
void Union(int x,int y)
{
int a=Find(x);
int b=Find(y);
if(a==b) return;
fa[a]=b;
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=0;i<n;i++)
{
fa[i]=i;
}
for(int i=0;i<m;i++)
{
scanf("%d%d",&p[i].x,&p[i].y);
Union(p[i].x,p[i].y);
}
int num=0;
for(int i=0;i<n;i++)
{
if(fa[i]==i) num++;
}
scanf("%d",&K);
int cnt=K;
while(K--)
{
int x;
scanf("%d",&x);
vis[x]=1;
int num1=0;
for(int i=0;i<n;i++) fa[i]=i;
for(int i=0;i<m;i++)
{
if(vis[p[i].x]==1 || vis[p[i].y]==1)
{
continue;
}
Union(p[i].x,p[i].y);
}
for(int i=0;i<n;i++)
{
if(fa[i]==i)
{
num1++;
}
}
if(num1==num || num1==num+1)
{
printf("City %d is lost.\n",x);
}
else
{
printf("Red Alert: City %d is lost!\n",x);
}
num=num1;
}
if(cnt==n)
{
printf("Game Over.\n");
}
return 0;
}L014-列车调度
大概需要用到队列把,但是很多队列?我不太懂
看了一下题解,根据题意,是要分成n个有序的队列,在前面的就得先出去,随意可以利用集合来判断当前点是不是能进去,如果能进去就不算,进去了就是多了一个序列?最终看集合的长度
先将输入的第一个序号放到set中
注意set中保存的是每个铁轨中序号最小的列车号
这样的意义在于,如果接下来输入的列车序号有比它还小的,那么他们就可以在同一铁轨中排着队
对应的操作是:更新 对应铁轨中最小的列车序号
接着输入数据,如果在set中找不到比输入列车序号小的,那就要新建铁轨,即向set中添加一个新的记录
最后,set中数据的个数,对应着所需铁轨的条数
stl里的函数多又难以记住呜呜呜
#include<bits/stdc++.h>
using namespace std;
#define f(i,n,m) for(int i=n;i<=m;i++)
int main()
{
set<int>s;
int n;cin>>n;
f(i,0,n-1)
{
int a;cin>>a;
auto it=s.lower_bound(a);//是在s中找一个比a大的数字
if(it!=s.end())//找到了,说明a可以排在这个地方了
{
s.erase(it);//在集合中的这个it没用了,删掉
}
s.insert(a);
//执行了if,找到比a大的,把这个大的删了,a排上
//如果没执行过if,没找到比a大的,说明要开一个新的队伍,添加这个元素
}
cout<<s.size();
}015-互评成绩,模拟结构体
016-有情人终成姐妹
集合比较好使?或者搜索。
不想写
这题比较有趣的一点是,爸妈的性别也要记录下俩,还有五服的限制需要注意一些关系限制
听说测试点有误,有人变性了(
#include<iostream>
#include<cstring>
#include<algorithm>
#include<vector>
#include<cmath>
using namespace std;
const int N = 100010;
bool vis[N],sex[N];
vector<vector<int>> g(N);
bool dfs(int x,int d){
vis[x] = true;
if(d == 4) return true;
for(int num: g[x]){
if(vis[num] || !dfs(num,d+1)) return false;
}
return true;
}
int main(){
cin.tie(0)->sync_with_stdio(false);
cout.tie(0);
int n; cin>>n;
for(int i = 0; i < n; i++){
int b,f,m; char c;
cin>>b>>c>>f>>m;
if(c == 'M') sex[b] = 1;
else sex[b] = 0;
if(f != -1) {
sex[f] = 1;
g[b].push_back(f);
}
if(m != -1){
sex[m] = 0;
g[b].push_back(m);
}
}
int k; cin>>k;
while(k--){
int a,b;
cin>>a>>b;
if(sex[a] == sex[b]) {
puts("Never Mind");
continue;
}
memset(vis,0,sizeof vis);
dfs(a,0);
if(dfs(b,0)) puts("Yes");
else puts("No");
}
return 0;
} 017简单到不配拥有姓名
018明天再说
day9 PTA比赛总结
蓝桥杯省一开心的!!!
pta被卡之狗屎字符串呜呜呜,去总结
还有优先队列被我给忘记了
看见题目长的就不想打L2系列,还有暴搜对这种数据已经够够,就是给的时间真的太短啦
day10 记录学不会的数论之欧拉函数
我们其实画一下图就可以发现,我们能看见的人关于点( 0 , 0 ) (n−1,n−1)这条线对称,我们只需要处理一半就可以了(除了(1,1),(0,1),(1,0)这三个点)。则可以发现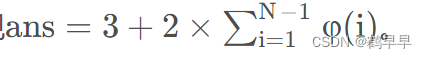
我们使用Eratosthenes筛法可以使用欧拉函数的计算公式在O ( N log N ) 的时间内处理出欧拉函数:
#include <bits/stdc++.h>
using namespace std;
int n,ans,phi[40005];void euler() {
for(int i=2;i<n;i++) phi[i]=i;
for(int i=2;i<n;i++) {
if(phi[i]==i) {
for(int j=i;j<=n;j+=i)
phi[j]=phi[j]/i*(i-1);
}
}
return ;
}int main() {
scanf("%d",&n);
if(n==1) {
printf("0");
return 0;
}
euler();
for(int i=2;i<n;i++) ans+=2*phi[i];
printf("%d",ans+3);
return 0;
}
P2158 [SDOI2008]仪仗队_凌曦月的博客-CSDN博客
day11贪心的复习
1.选择不相交区间问题
题目是活动安排
对于这种有重合区间找最优组合的,需要想到用结构体进行排序,然后贪心选择。一般把区间的末尾进行排序,这样前面已做出的选择不会影响后序的选择,这样才能从局部最优推到全局最优。
#include<bits/stdc++.h>
using namespace std;
struct dd
{
int s,t;
}a[1005];
bool cmp(dd x,dd y)
{
return x.t<y.t;
}
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i].s>>a[i].t;
}
sort(a+1,a+n+1,cmp);
int ans=1,tt=a[1].t;
for(int i=2;i<=n;i++)
{
if(a[i].s>=tt)
{
ans++;
tt=a[i].t;
}
}
cout<<ans<<endl;
}2.区间选点问题
题目种树
题目一般提供数轴和各个区间,对此进行选点找最优方案,对于这种题目我们要对区间进行排序,然后对数轴一个区间一个区间的处理
在中树这道题中,要想种树中的少,贪心的方法就是数轴上的一个点尽量能满足更多区间的需要。需要注意的是,一开始出现一些错误,例如对区间末尾的边界处理不到位,以及边界中需要重新统计点位,因为点位和区间可能没有那么高的重合率,中间可能会有空点或者被选中的点(结合区间处理只按区间末尾排序,这样会导致其终点会出现各种各样的情况,会有少部分数据前面的影响后面,在范围不大的情况下我们可以通过遍历相关信息来及时更新数据)
#include<bits/stdc++.h>
using namespace std;
struct dd
{
int b,e,t;
}a[5005];
bool s[30005];
bool cmp(dd x,dd y)
{
return x.e<y.e;
}
int main()
{
int n,h;
cin>>n>>h;
for(int i=1;i<=h;i++)
{
cin>>a[i].b>>a[i].e>>a[i].t;
}
sort(a+1,a+h+1,cmp);
int ans=0;
for(int i=1;i<=h;i++)
{
int p=0;
for(int j=a[i].b;j<=a[i].e;j++)
{
if(s[j]) p++;
}
if(p>=a[i].t) continue;
else
{
ans+=a[i].t-p;
for(int j=a[i].e;j>=a[i].b;j--)
{
if(!s[j])
{
s[j]=true;
p++;
}
if(p==a[i].t) break;
}
}
}
cout<<ans<<endl;
}3.区间覆盖问题
题目喷水装置
题目一般提供N个闭区间,然后我们要选择尽量少的区间,使得这些区间能覆盖一段线段。解法是把区间按左端点小到大排序,依次处理。选择可以覆盖起点s的区间中右端点最大的,直到区间包含终点
在喷水装置这题中,最大的障碍是喷头是圆形的,其范围比较不规律,一开始写的时候按初始的最远的起点排序,其实是不正确的,我们在排序的时候就要处理好每个喷头的边界,需要通过计算,把用不上的圆弧都削掉,然后代码就变得简单起来。
网上找的一个代码,用的是stl,可能我平时更习惯用结构体
using namespace std;
int t,n,l;//组数,喷头数,长度
int s;//喷头位置
double w,r;//草坪宽度,喷头半径
double maxn;//临时变量
int main()
{
vector< pair<double,double> >vec;
pair<double,double> p;
cin>>t;//输入总组数
while(t--)//t--不等于0时
{
cin>>n>>l>>w;//输入喷头数,草坪长、宽
vec.clear();//确保容器vec为空
for(int i=0;i<n;i++)
{
cin>>s>>r;//输入喷头位置、半径
if(r<w/2)
continue;//如果半径小于宽度的一半,则一定不会覆盖草坪,获取下一个喷头数据
r=sqrt(r*r-(w/2*w/2));//勾股定理逆用,
p=make_pair(s-r,s+r);//求区间
vec.push_back(p);//尾部插入区间
}
sort(vec.begin(),vec.end());//升序
int k=0;//记录已遍历到的喷头数
double now=0;//记录覆盖到的位置
int ans=0;//记录选用的的喷头数
int flag=1;//标记是否还能覆盖
int len=vec.size();//容器大小
while(k<len)
{
if(now<vec[k].first)
{flag=0;
break;}//前面覆盖到的位置与当前可覆盖区间不相交,即存在不覆盖的情况
if(now>=l)break;//覆盖已完成
maxn=-1;
while(now>=vec[k].first&&k<len)//当下一个区间可覆盖,尽可能选覆盖区间最大的
{
maxn=max(maxn,vec[k].second);
k++;//记录已遍历的喷头数
}
now=maxn;
ans++;//每换一个区间,选用的喷头数加一
}
if(flag==1)
cout<<ans<<endl;
else
cout<<"-1"<<endl;
}
return 0;
}4.流水作业调度
题目加工生产调度
原创代码,呜呜呜逻辑太优美啦。
这个题目的意思就是两条生产线,n个产品要按生产线顺序生产,生产时间不一致,来安排最优的生产顺序。把它贪心化,需要思考怎么样最大程度利用两条生产线,使空闲时间最短。得出结论,在第一条生产线上加工时间短优先,第二条加工时间长优先。
据书上说,这个叫johnson算法,第一个集合a<b,a从小到大排序,第二个集合a>=b,b从大到小排序,按照这个排序写一个结构体和cmp,然后我们就按照他的生产顺序来安排,起始的安排如何注意一下就可以算了。比如说这一题,先把第一个集合的a加起来,然后第二个集合一个个判断b是否可以叠加还是中间有等待时间。注意第一个产品的b等待时间也要算上。
#include<bits/stdc++.h>
using namespace std;
struct dd
{
long long a,b,c=1,d;
}s[1005];
bool cmp(dd x,dd y)
{
if(x.c==y.c&&x.c==1)
{
return x.a<y.a;
}
if(x.c==y.c&&x.c==0)
{
return x.b>y.b;
}
return x.c>y.c;
}
int main()
{
int n;
cin>>n;
int t=n;
for(int i=1;i<=n;i++)
{
cin>>s[i].a;
s[i].d=i;
}
for(int i=1;i<=n;i++)
{
cin>>s[i].b;
if(s[i].a>=s[i].b)
{
s[i].c=0;
t--;
}
}
sort(s+1,s+n+1,cmp);
long long ans1=0,ans2=s[1].a;
for(int i=1;i<=t;i++)
{
ans1+=s[i].a;
ans2+=s[i].b;
}
for(int i=t+1;i<=n;i++)
{
ans1+=s[i].a;
if(ans2>=ans1) ans2+=s[i].b;
else ans2=ans1+s[i].b;
}
cout<<ans2<<endl;
for(int i=1;i<=n;i++)
{
cout<<s[i].d;
if(i!=n) cout<<" ";
else cout<<endl;
}
}5.带限期和罚款的单位时间任务调度
题目智力大冲浪
就是任务有截止时间,没完成有惩罚,怎么安排惩罚少
这题思路很简单,但是一开始没想到。首先我们要贪心,为了让扣的的钱越少,所以我们应该优先做扣钱多的项目(毕竟大家付出的时间代价是一样的),然后,为了让别的项目更有可能完成,我们要把这个项目拖到最后一刻才做(不是说截止时间那一天,而是说在前面更优先的任务做完之后剩下的空闲安排时间中的最后一刻),这里只需要开一个数组来模拟一下被占用的时间安排就可以了。
#include<bits/stdc++.h>
using namespace std;
struct dd
{
int a,b;
}s[1005];
int l[1005];
bool cmp(dd x,dd y)
{
return x.b>y.b;
}
int main()
{
int n,m;
cin>>m>>n;
for(int i=1;i<=n;i++)
{
cin>>s[i].a;
}
for(int i=1;i<=n;i++)
{
cin>>s[i].b;
}
sort(s+1,s+n+1,cmp);
int t=0;
for(int i=1;i<=n;i++)
{
for(int j=s[i].a;j>=0;j--)
{
if(j==0)
{
m-=s[i].b;
}
if(l[j]==0)
{
l[j]=1;
break;
}
}
}
cout<<m<<endl;
}我想说个高兴事,就是传智杯拿了国二,哈哈哈有点子小水哈哈哈~希望蓝桥杯国赛和ccpc能拿到好成绩呜呜
贪心的五种类型说完了,感兴趣的可以继续打题练习。
















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









