







参考:https://zhuanlan.zhihu.com/p/25759682
原文:https://cs.stanford.edu/~pliang/papers/freebase-emnlp2013.pdf
一 、摘要
作者训练了一个可扩展到Freebase的语义解析器,由于大规模获取数据代价昂贵,作者从问答对中学习,而不是依赖于标注的逻辑形式。这种方法的主要挑战是如何缩小给定问题的大量可能的逻辑谓词。作者从以下两个方面解决:第一,作者使用知识库和大型的文本语料构建从短语到谓词的粗略映射;第二,作者使用桥接操作来生成基于相邻谓词的附加谓词。
二、介绍
作者将用户提问的自然语言问题转变为逻辑形式。传统的语义解析器有两个缺点:需要大量标注的逻辑形式作为监督,在限定领域并且极少数量的逻辑谓词。本文的目标是在不用标注的逻辑形式下,学习一个语义解析器,扩展到有大量谓词的Freebase知识库中。
第一个难点是在于如何将自然语言短语映射为逻辑谓词。之前的工作是手工规则、远程监督、模式匹配相结合的方法。本文的做法是使用大量的文本语料和知识库来构建短语和谓词的粗略对齐。由于一词多义,轻动词和介词难以对齐,为了解决这个问题,作者提出了桥接的操作,基于相邻的谓词来生成谓词。
对齐谓词之后就要将谓词组合成逻辑形式,之前的做法基于大量的规则,作者改为定义一些简单的组合规则,这些规则过度生成然后使用模型特征来模拟软规则和类别。 特别是,作者在预测的逻辑形式的表示上使用POS标签特征和其它特征。
三、建立过程
为了查询知识库,作者使用逻辑语言----λ-DCS。逻辑形式有以下形式和操作:

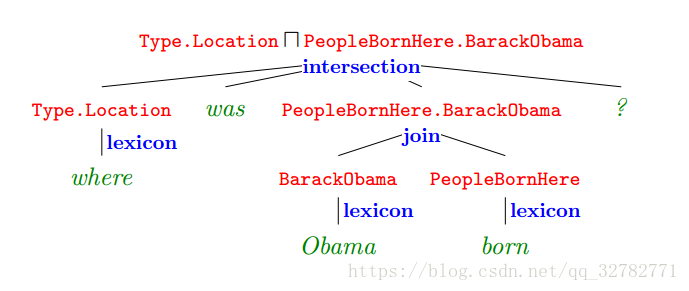
给与一段话,语义解析器可能会构造很多可能的推导。构造过程根据词库映射和组合规则。例子若下图:
训练分类器:作者提出 discriminative log-linear model求得每一段话 x 的一个推导 d ∈ D(x) 的概率:

其中x代表自然语言问题,Φ(x, di)是由问题 x 和推导 di 提取出来的b维特征向量,θ 是需要学习的参数向量。对于训练集的答案对 (xi, yi) 最大化 log-likelihood损失函数, 训练目标为:
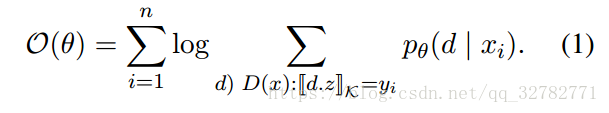
四、方法
1.对齐
自然语言短语映射到逻辑谓词,大量文本语料映射到知识库,这一操作也被称为对齐(Alignment)。我们知道自然语言实体到知识库实体映射相对比较简单,比如将“Obama was also born in Honolulu.”中的实体Obama映射为知识库中的实体BarackObama,可以使用一些简单的字符串匹配方式进行映射。
但是要将自然语言短语如“was also born in”映射到相应的知识库实体关系,如PlaceOfBirth, 则较难通过字符串匹配的方式建立映射。怎么办呢?没错,我们可以进行统计。直觉上来说,在文档中,如果有较多的实体对(entity1,entity2)作为主语和宾语出现在was also born in的两侧,并且,在知识库中,这些实体对也同时出现在包含PlaceOfBirth的三元组中,那么我们可以认为“was also born in”这个短语可以和PlaceOfBirth建立映射。
比如(“Barack Obama”,“Honolulu”),(“MichelleObama”,“Chicago”)等实体对在文档中经常作为“was also born in”这个短语的主语和宾语,并且它们也都和实体关系PlaceOfBirth组成三元组出现在知识库中。
2.桥接
完成词汇表的构建后,仍然存在一些问题。比如,对于go,have,do这样的轻动词(light verb)难以直接映射到一个知识库实体关系上,其次,有些知识库实体关系极少出现,不容易通过统计的方式找到映射方式,还有一些词比如actress实际上是两个知识库实体关系进行组合操作后的结果
(作者最后提到这个问题有希望通过在知识库上进行随机游走Random walk或者使用马尔科夫逻辑Markov logic解决),因此我们需要一个补丁,需要找到一个额外的二元关系来将当前的逻辑形式连接起来,那就是桥接。
3.组成
作者提出了三种操作:join、aggression、intersection,同时也提出了多种特征用于训练:rule feature、POS feature、donation feature。
五、实验
作者实现了自底向上的集束分析器,使用AdaGrad进行优化。
作者在FREE917数据集中进行实验,30%作为测试集,70%作为训练集,训练集中80%用来训练,20%用来验证,最终准确率为62%,高于别人工作的59%。
作者还做了一些特征实验,详细可以看原文。
六、总结
首先,词汇映射是整个算法有效(work)的基点,然而这里采用的词汇映射(尤其是关系映射)是基于比较简单的统计方式,对数据有较大依赖性。最重要的是,这种方式无法完成自然语言短语到复杂知识库关系组合的映射(如actress 映射为
其次,在答案获取的过程中,通过远程监督学习训练分类器对语义树进行评分,注意,这里的语义树实际的组合方式是很多的,要训练这样一个强大的语义解析分类器,需要大量的训练数据。我们可以注意到,无论是Free917还是WebQuestion,这两个数据集的问题-答案对都比较少。














 3400
3400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









