







 RANSAC算法是一种处理包含噪声数据的有效方法,尤其在数据集中有效数据占多数时。它通过随机抽样和最小二乘法去除异常点,提高模型的准确性。在比较中,RANSAC算法的拟合效果优于传统的最小二乘法,能得出更优的数学模型。算法通过迭代找到最大共识集,并以此构建最佳模型。在模拟实验中,RANSAC算法在MATLAB中得到了实现。
RANSAC算法是一种处理包含噪声数据的有效方法,尤其在数据集中有效数据占多数时。它通过随机抽样和最小二乘法去除异常点,提高模型的准确性。在比较中,RANSAC算法的拟合效果优于传统的最小二乘法,能得出更优的数学模型。算法通过迭代找到最大共识集,并以此构建最佳模型。在模拟实验中,RANSAC算法在MATLAB中得到了实现。
RANSAC算法全称是随机抽样一致算法(random sample consensus,RANSAC),RANSAC算法的基本假设是样本中包含正确数据(inliers,可以被模型描述的数据),也包含异常数据(outliers,偏离正常范围很远、无法适应数学模型的数据),即数据集中含有噪声。这些异常数据可能是由于错误的测量、错误的假设、错误的计算等产生的。同时RANSAC也假设,给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。数据分两种:有效数据(inliers)和无效数据(outliers)。偏差不大的数据称为有效数据,偏差大的数据是无效数据。如果有效数据占大多数,无效数据只是少量时,我们可以通过最小二乘法或类似的方法来确定模型的参数和误差;如果无效数据很多(比如超过了50%的数据都是无效数据),最小二乘法就失效了,我们需要新的算法。
如果一组二位的数据点含有许多噪声点,直接采用最小二乘法求出的数学模型不够准确。而比较好的方法就是用RANSAC算法剔除那些噪声点,获得最大的支持数据集合,再用最大支持数据通过最小二乘求出最佳数学模型。
首先如果没有使用RANSAC算法,通过最小二乘法模拟出的数学模型如下图所示,其中的二位数据是我们随机生成的包含噪声点的数据集合。
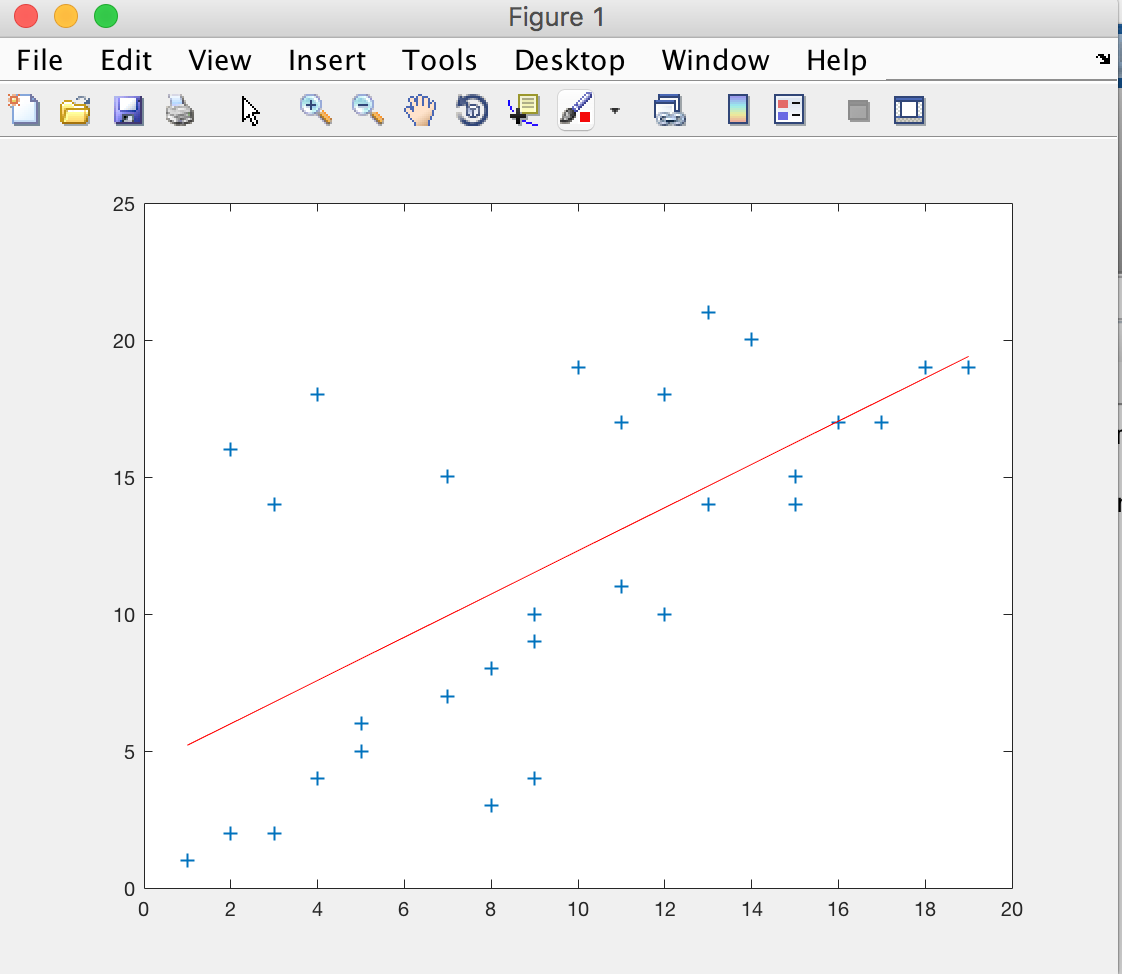
可以看出,上半部分是误差较大的点,而通过最小二乘拟合的直线将噪声点也考虑进去,得到的不是最佳数学模
型。
现在我们采用RANSAC算法剔除一些噪声点后,在进行最小二乘拟合得到的图如下所示。
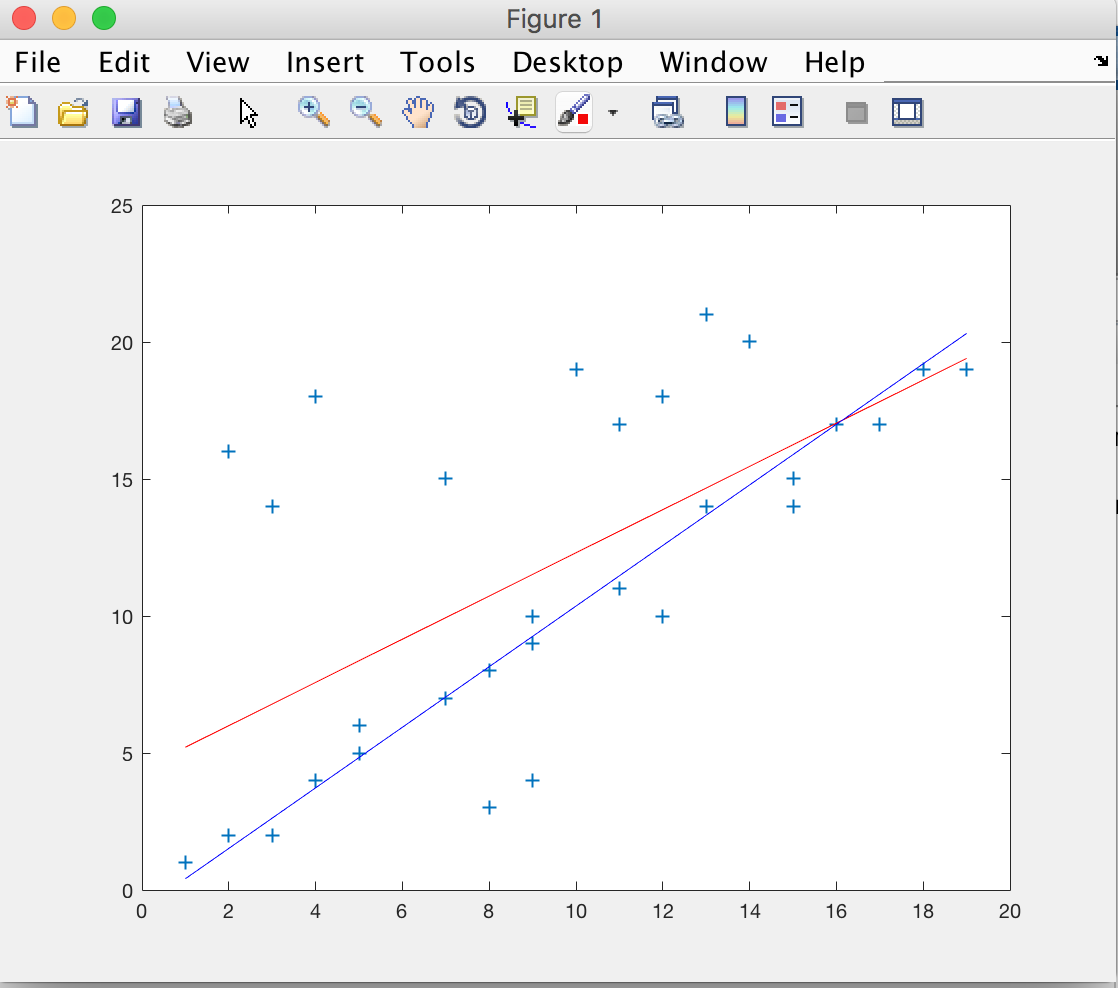
其中红色的直线是未使用RANSAC算法拟合的直线,蓝色的直线是使用RANSAC算法拟合的直线。从中可以看出使用RANSAC算法之后的数学模型更佳。
算法:
伪代码的算法如下所示:
输入:
Data
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









