









我们要爬取的网站是https://tieba.baidu.com/p/3797994694
首先爬取第一页的图片,使用python3自带库urllib,详细的代码如下:
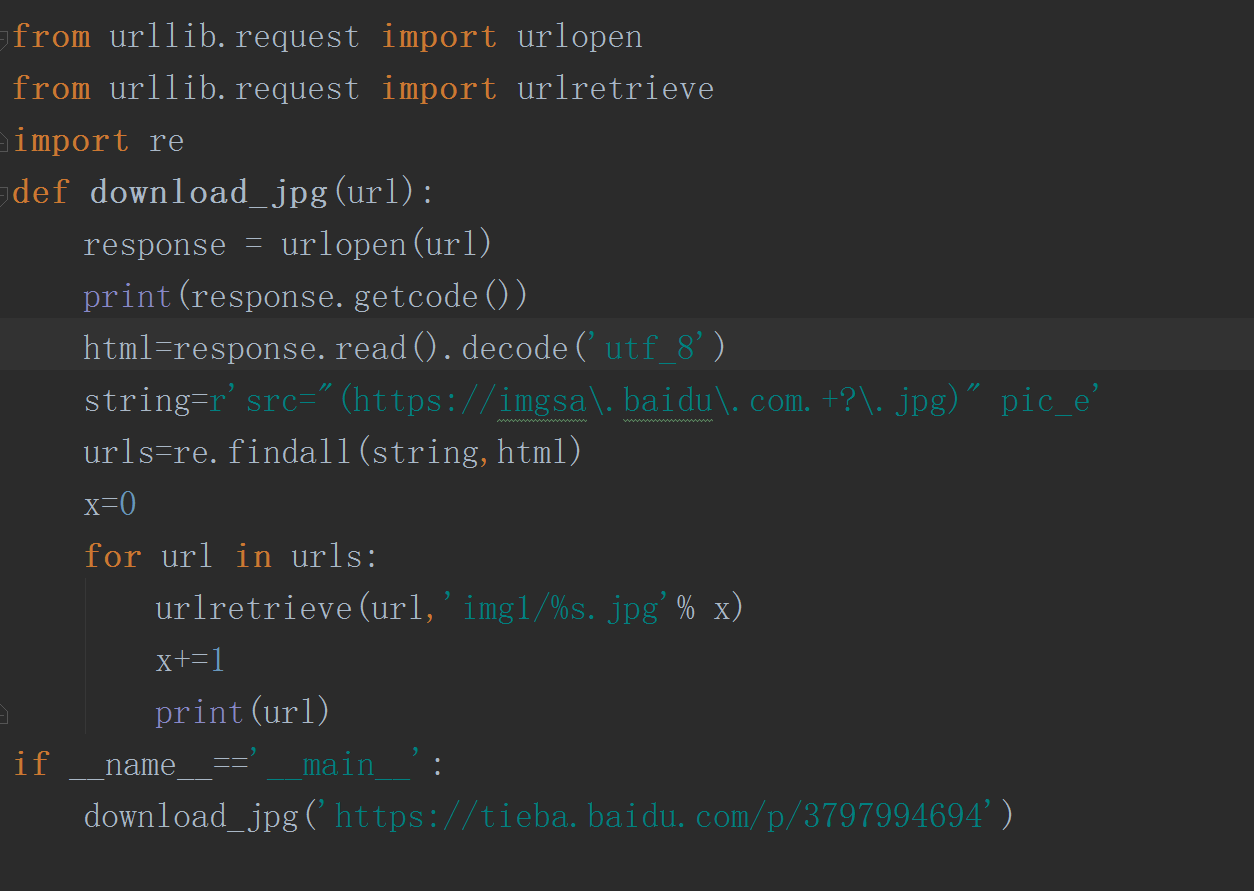
接下来爬去多页的图片,这里我们选取五页的图片,这里我们采用requests,beautifulsoup第三方库和自带库urllib,详细的代码如下:


我们要爬取的网站是https://tieba.baidu.com/p/3797994694
首先爬取第一页的图片,使用python3自带库urllib,详细的代码如下:
 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























