









目录
一、知识图谱的表示方式
知识图谱就是知识的结构化表示,不同的行业有不同的知识,以及不同的知识体系
我们这里定义只针对一个特定知识体系的知识图谱为特定领域的知识图谱,可以兼容不同知识体系的图谱为通用知识图谱,下面我来分别简单介绍下我理解的他们各自的特点以及建模方式
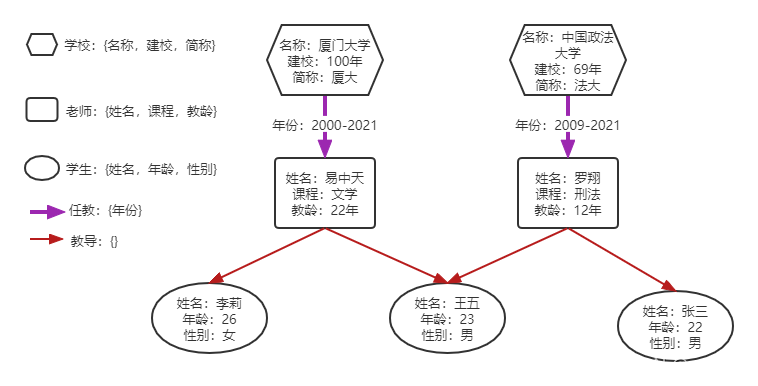
1.1 特定领域的知识图谱
如下图所示,这种图谱在单一领域内非常常用。
通过指定不同的类型,类型包含的属性,类型间存在的关系,以及关系包含的属性进行创建。
特点
- 对单一领域建模,操作可以非常精细
- 可以直接跑各种图算法,非常方便
- 和关系型数据库的思路较为相似,很容易理解
- 泛用性不足,同一套数据结构很难跨领域使用
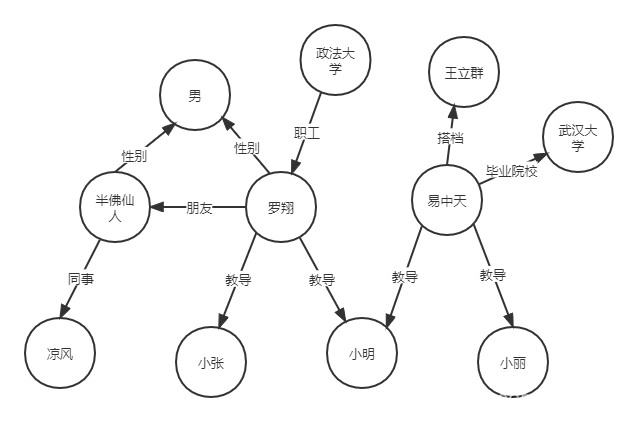
1.2 简单的通用知识图谱
如下图所示,是我们常见的基于词以及词与词之间的关系的三元组图谱。
这种图谱以词作为实体来进行图谱的构建。
特点
- 制作简单,没有什么复杂的逻辑规则
- 查询简单,只需要根据词进行查询即可
- 无法用于展示同名实体(还有明星叫罗翔怎么办)
- 没有对关系进行归类,构建过程中很有可能出现 “教授”,“教导” 两种关系名称,但表示的是同一种关系
- 没有对实体进行归类,比如用户想知道图谱中有哪些人的时候会较为困难
补充
其实这种保持词唯一的结构,更适合用于构建语义网。可以内置一些语义上的上下位词、近义词、反义词、属性、实例等关系。如生物和动物是上位词关系,年龄和人类是属性关系,姚明和篮球运动员是实例关系等等。通过构建的语义网,可以让机器更精准的理解句子所要表达的含义,赋能各种语义理解类业务。
1.3 可自定义本体的通用知识图谱
先介绍下本体的概念
本体定义了组成「主题领域」的词汇表的「基本术语」及其「关系」,以及结合这些术语和关系来定义词汇表外延的「规则」
其实简单来说本体就是下层实体创建要遵循的规则,知识图谱构建所用的骨架。
在下图中,可以看到上半部分其实就是本体部分,下半部分就是基于所定义的本体构建的实体部分。

特点
- 可以让用户定义属于自己领域的本体,非常通用
- 加入了近义词概念,可以在标准化领域术语的的基础上增加语义理解能力
- 这个图谱中实体的名称是属性之一,可以通过指定本体的展示属性进行变更,降低了图谱维护人员修改本体名称属性的成本
- 可以支持各种维度的查询
- 实现整套逻辑较为复杂
- 查询复杂,需要多处数据的组合,因为需要整合多处数据查询速度相对来说会慢一点,可以考虑适量加入缓存进行性能优化
补充
在这个结构的基础上其实还可以有很多的扩展,这里简单说下供大家思考(实现起来较为复杂,自行取舍)
- 将类的上下位关系融入本体中,加入下位的类继承上位类的属性的功能
- 多个近义词表示的其实是一个“意思”,这个“意思”也可以像实体那样作为中间节点,而不放上具体的词
- 在工业上实际构建上其实比较难以区分实例关系和属性关系,是否可以将其进行一层抽象,做成统一的表示,降低实际构建者的试错成本
二、图数据库选型
需求:
- 支持高可用
- 开源软件
- 性能较高
- 社区活跃
- 支持多schema(可选)
背景:
- 小团队
- toB业务
国内相对主流的图数据库:
Neo4j,Tiger Graph,Janus Graph,Nebula Graph,Dgraph,Huge Graph等
- Neo4j:我们团队第一个考虑的就是Neo4j,因为网上资料比较多,而且也发展了多年,技术相对比较成熟,生态也较为完备,但是社区版不支持高可用,并且不是分布式数据存储对于大数据量存储存在一些问题
- Tiger Graph:性能非常不错,可惜是非开源软件
- Janus Graph:开源软件,使用组件较多,运维比较麻烦,查询性能相对较差
- Huge Graph:开源软件,查询性能相对较差
- Nebula Graph:开源软件,社区很活跃,提出问题很快就能收到答复,支持多schema,支持高可用,分布式数据存储可扩展,性能也非常不错
- Dgraph:开源软件,采用graphQl进行查询比较新颖,分布式数据存储可扩展,以国外社区为主,国内获取资料相对困难一些,企业版支持多schema,开源版不支持
根据我们自身的情况以及综上所述的对比下,我们团队选择了Nebula Graph
三、基于Nebula Graph的数据库交互层的实现
团队主要采用java作为后台开发语言,所以下面会以java技术栈进行分析
这里我只是抛砖引玉拼拼凑凑写出我的一些想法,以及实践过程中使用过的方法,大家可以各取所需,并提出自己的想法
- 语句生成:拆解MyBatis仅使用其语句生成部分
- 简单语句生成:封装出对应表结构的实体,作为元数据,并根据增删改查业务封装出增删改查的语句生成类
- 数据库驱动:nebula-java
- 语句执行:自行进行封装,将是用到的框架进行整合,加入执行流程。需要留意的是目前Nebula Graph不支持事务,执行失败无法自动回退,一定要校验好业务方面没有问题,一定可以执行,然后最后统一进行执行,否则只成功执行了一部分语句会导致数据错误
- 整合解决方案:借鉴neo4j-ogm,mybatis-plus,nebula-jdbc整合做出适合nebula-graph的数据库操作框架(正在探索)















 3382
3382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









