







Distillation as a defense to adversarial perturbations against DNNs
Distillation as a defense to adversarial perturbations against DNNs
1. Introduction
Distillation is a training procedure initially designed to train a DNN using knowledge transferred from a different DNN. The intuition was suggested in [18] while distillation itself was formally introduced in [19]. The motivation behind the knowledge transfer operated by distillation is to reduce the computational complexity of DNN architectures by transferring knowledge from larger architectures to smaller ones.
蒸馏的概念,首先指的是一个训练过程,最初设计是用一个不同的DNN中使用知识迁移来训练另一个DNN。
使用蒸馏操作的在知识迁移背后的动机是通过大架构(结构复杂)到小架构之间的知识迁移,可实现降低DNN的计算复杂度。
这样操作的一个好处是促进了深度学习在一些资源受限,不能使用GPUs计算设备中的部署(例如智能手机)。
本文的工作从蒸馏角度出发,并不是利用两个模型之间的知识迁移,而是提出了一种新的变种用来对对抗样本进行防御。
本文工作的思路:通过使用在蒸馏中提取到的知识来训练网络,可以达到减小网络的梯度辐值的效果。这样在基于梯度信息的对抗攻击方法中可使得该类方法失效。如果对抗梯度较高,此种情况下生成对抗样本是比较简单的,因为此时在输入端较小的扰动就能引起输出较大的变化。为了防御此类扰动,防御者必须减小输入的变化,也即对抗梯度的辐值。换句话说,本文使用防御蒸馏来对学习到的模型进行平滑处理,以提高模型在训练数据集外的泛化性。
最后(因此),在测试的时候,使用防御蒸馏训练得到的模型会对对抗样本不再那么敏感。
Contributions:
- 我们明确了
DNN防御对抗样本设计的需求。这些准则明确了对抗鲁棒、输出准确性和DNNs性能之间内在的tension; - 提出了防御蒸馏方法,可用于训练对抗鲁棒模型。蒸馏提取了训练得到的概率向量信息,并将其用于再用于训练网络。这与原始的蒸馏不一样,原始的蒸馏是减小
DNN的架构来提高计算的性能,而不是将获得/提取的知识反馈到原始模型中去; ⋆ ⋆ ⋆ \star\star\star ⋆⋆⋆ - 从理论上研究了防御蒸馏可作为一种安全策略。我们表明了蒸馏策略可通过减小对输入扰动的敏感性来生成一个更加光滑的模型,这些光滑的
DNN classifiers对对抗样本有更强的防御能力,同时可以i提高模型的泛化性; ⋆ ⋆ ⋆ \star\star\star ⋆⋆⋆ - 从经验上表明,防御蒸馏方法在
MNIST数据集上可将对抗样本的攻击成功率从95.89%降到0.45%;在CIFAR10数据集上从87.89%降到5.11%; - 进一步的对蒸馏参数空间的经验实验表明,正确的蒸馏参数化可以降低模型对输入的敏感性可达
1
0
30
10^{30}
1030。相继的,若要生成对抗样本,此时需要扰动的最小输入特征量更大,例如对第一个
DNN模型需要原来的790%;第二个模型则也需要556%。
2. Adversarial Deep Learning
A. Deep Neural Networks in Adversarial Settings
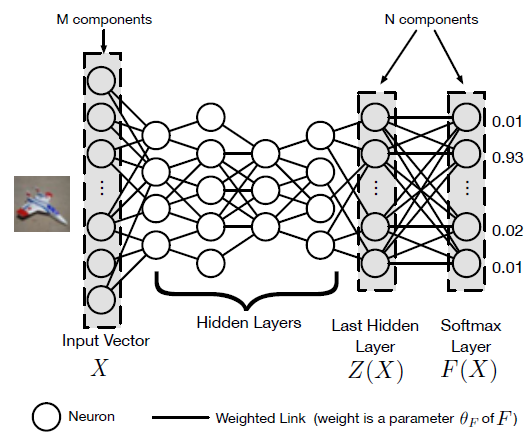
对抗样本的作用/目的:
- 对于分类器,一种是降低分类结果的置信度,通过降低
DNN's对某个类别的置信度,从而使得分类结果模棱两可;另一种是直接使得DNN模型误分类(本文关注的类型)。
应用场景:
- 对恶意软件可执行文件进行略微修改,使得可以躲避基于
DNN构建的检测系统; - 对支票上的手写字添加扰动,使得
DNN系统误识别。例如一般是将数字识别为较大的数字; - 对非法金融操作的模型进行更改,使得它能躲开欺诈检测系统的检测。
同时,对本文的攻击类型进行限定,白盒攻击,即要能获得目标模型的架构。
B. Adversarial Sample Crafting
总的将对抗样本的生成通过下图描述:
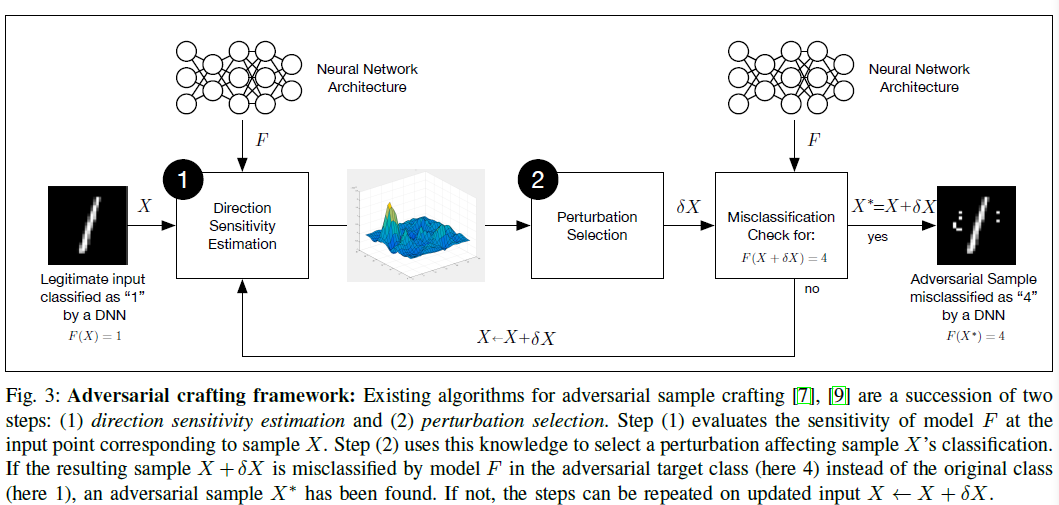
本文将生成对抗样本的过程分类两大步:
- Direction Sensitivity Estimation:即评估输出类别变化对输入的敏感程度(可以人为是梯度信息);
- Perturbation Selection:基于输入维度,使用敏感度/灵敏度信息选择一个扰动 δ X \delta X δX;
- 如果误分类了,则结束,否则继续…
即第一步是找到DNN学习到的,在输入空间上变化,最容易引起输出变化的方向;第二步则基于第一步的信息来找到有效的扰动大小
可以就理解为寻优过程,第一步是找到方向,第二步是确定大小。
(1)Direction Sensitivity Estimation
如何确定灵敏度方向:找到使得在输入上添加最小扰动的维度方向。
FGSM,对输入的所有维度求梯度,根据目标/无目标攻击类型确定灵敏度方向;- 另一种方法是通过前向导数的方法,引入雅可比行列式,即可得到每个输出分量对输入分类的梯度;
- 前两种都是对输入的所有维度求灵敏度(梯度),另一种方法是基于
K-L散度的Local Distribution Smoothness,用来评价两个不同概率分布之间的相似度,使用的是网络的近似海瑟矩阵(Hessian Matrix)。但是这种方法的目的并不是用来生成对抗样本,而是通过local distribution smoothness作为训练正则化项来提高训练的准确性。
(2)Perturbation Selection
即如何在第一步确定的方向上找到最小的扰动(向量)。
FGSM是在所有的方向上使用的梯度的符号乘上扰动量;- 上面的雅可比相关的方法则没有在输入的所有维度上进行操作,而是引入显著图(
saliency maps)来确定需要扰动的最少维度。这种方法可以显著的减少需要扰动的输入特征数。 - 以上两类方法的扰动值大小都是一个固定的参数。对于其它的方法,如何确定扰动值大小一般是通过
L
p
L_p
Lp
norm确定。
C. About Neural Network Distillation
蒸馏最开始的motivation是通过减小DNN的架构或集成不同的DNN架构实现计算模型的轻量化,以实现可将模型部署在一些计算资源有限的(移动)设备上。
直观来讲:就是首先训练一个(大的)DNN模型,然后通过提取它的概率密度向量(软标签)来训练第二个(小)模型,以实现轻量化的效果。
这种方法的思想是:训练一个网络得到的信息(knowledge)不仅编码在了网络模型的权重参数中,同时也编码在了训练学习得到的概率向量中。(This intuition is based on the fact that knowledge acquired by DNNs during training is not only encoded in weight parameters learned by the DNN but is also encoded in the probability vectors produced by the network.)
防御(防御)的softmax输出:
F
(
X
)
=
[
e
z
i
(
X
)
/
T
∑
l
=
0
N
−
1
e
z
l
(
X
)
/
T
]
i
∈
0..
N
−
1
F(X)=\left[\frac{e^{z_{i}(X) / T}}{\sum_{l=0}^{N-1} e^{z_{l}(X) / T}}\right]_{i \in 0 . . N-1}
F(X)=[∑l=0N−1ezl(X)/Tezi(X)/T]i∈0..N−1
其中,
- Z ( X ) = z 0 ( X ) , . . . , z N − 1 ( X ) Z(X)=z_0(X),...,z_{N-1}(X) Z(X)=z0(X),...,zN−1(X)是图一中的逻辑输出。
-
T
T
T是蒸馏温度,逻辑层共有,大于1(等于1就是原始的
softmax层),是一个关键参数。
**简而言之,**蒸馏(防御)需要训练两个网络,第一个网络正常训练,但是引入了蒸馏温度。在训练第二个网络的时候,使用第一个训练网络的一些信息实现知识迁移。具体来说就是将第二个网络训练的labels使用第一个网络的输出替代(特殊的softmax层),即将硬标签替换成软标签训练第二个网络。

关于蒸馏温度 T T T:
- 蒸馏温度
T
T
T要较大,较大的温度
T
T
T使得
DNN给出的输出概率概率较大较平均; - 因为 x < 0 x<0 x<0,即 e x ∈ [ 0 , 1 ] . e^{x} \in [0,1]. ex∈[0,1].又因为 T → ∞ , T \rightarrow \infty , T→∞,所以$ e^{(\cdot/T)}\rightarrow 1 , 所 以 ,所以 ,所以F(X) \rightarrow 1/N, $,
inputs = (-0.1192, -1.8580, 1.2193, 14.3442, -4.9071, 0.4101, 3.7067, -4.6348,
-4.5286, -1.6535)
softmax_1 = ([5.2313e-07, 9.1931e-08, 1.9949e-06, 9.9997e-01, 4.3577e-09, 8.8815e-07,
2.3998e-05, 5.7215e-09, 6.3626e-09, 1.1279e-07])
softmax_100 = ([0.0995, 0.0978, 0.1009, 0.1150, 0.0949, 0.1001, 0.1034, 0.0951, 0.0952,0.0980])
softmax_10000 = ([0.1000, 0.1000, 0.1000, 0.1001, 0.0999, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000])
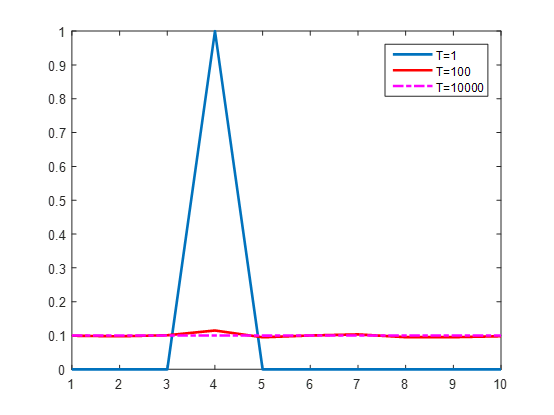
在经过第一个训练网络对labels数据进行重label后,再用于训练第二个DNN。经过操作后,标签由最开始的“硬标签”变成了“软标签”。这样在训练第二个网络时,就可以使用更轻量化的架构。**同时,**第二次训练的时候还可以同时使用“硬标签”和“软标签”。第二次训练的时候仍然要使用第一次用到的蒸馏温度,这样训练得到的模型精度和第一个模型精度相当,但是计算复杂度减轻了很多。在预测的时候设置为
T
=
1
T=1
T=1。
3. Defending DNNs using Distillation
将蒸馏引入DNN中进行对抗样本防御。
A. Defending against Adversarial Perturbations
本文的约束/框架:攻击方法基于网络对输入的灵敏度方向,即梯度方向。因此,如果网络得到的梯度较大,则攻击过程会较为简单,因为此时较小的扰动就能引起结果较大的变化。 因此,为了防御住此类方法的攻击,一个思路就是减小这样的“对抗梯度”信息。换句话说,可以通过对模型进行平滑处理,从而使得训练得到的网络能对训练数据集分布外的数据泛化性更好。
DNN Robustness:引入了一个新的概念,即DNN模型的鲁棒性(robustness)只是模型对扰动的抵抗能力。一个“鲁棒”模型应包含:
- 对服从/不服从训练数据集分布的数据都有较好的精度;
- 模型较为平滑,使得模型对输入,即一定范围内的数据分类具有稳定性。如下所示, X X X为原始样本,阴影部分为该良好样本的领域,领域越大,表示模型越鲁棒。
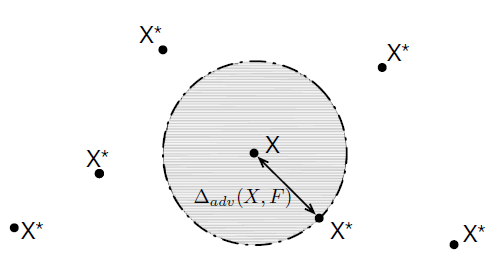
为了评估鲁棒性,引入了一个metric:
ρ
a
d
v
(
F
)
=
E
μ
[
Δ
a
d
v
(
X
,
F
)
]
\rho_{a d v}(F)=E_{\mu}\left[\Delta_{a d v}(X, F)\right]
ρadv(F)=Eμ[Δadv(X,F)]
其中:
- μ \mu μ为数据分布;
- Δ a d v ( X , F ) \Delta_{a d v}(X, F) Δadv(X,F)
Δ a d v ( X , F ) = arg min δ X { ∥ δ X ∥ : F ( X + δ X ) ≠ F ( X ) } \Delta_{a d v}(X, F)=\arg \min _{\delta X}\{\|\delta X\|: F(X+\delta X) \neq F(X)\} Δadv(X,F)=argδXmin{∥δX∥:F(X+δX)=F(X)}
定义为使得模型误分类的最小扰动(期望)。
Defence Requirements:对如何防御给出了几点要求/限制
low impact on the architecture:对模型的架构修改不能太大;maintain accucary:防御的方法不能降低模型的精度; ⋆ \star ⋆ ⋆ \star ⋆ ⋆ \star ⋆maintain speed of network:防御方法不能影响模型在测试阶段的速度。相对测试阶段,在训练阶段增加了模型的计算量(降低运算速度相对影响不大,因为训练模型的成本是一次性的),只要不能巨大的差别就影响不大;defenses should work for adversarial samples relatively close to points in the training dataset:防御针对的对象是相对训练集较近的数据,一方面,如果离原始训练集较远,则很容易被检测出来(即使人眼);但是如果扰动很小,无穷小,则有不能形成对抗样本。
对于本文提出的防御蒸馏方法:首先不需要对网络的加过进行任何更改;其次,在模型训练阶段会增大训练时间,但很小,在测试阶段则完全没影响。对于模型的性能,即上面的第二点,通过对比有无部署本文提出的方法可对模型的性能进行比较(在实验阶段)。
B. Distillation as a defense
介绍防御蒸馏。
本文的防御蒸馏和之前的蒸馏(知识蒸馏)不一样的地方在于:本文训练的两个模型架构是一样的,即目的不是了压缩,而是为了能防御住对抗攻击。
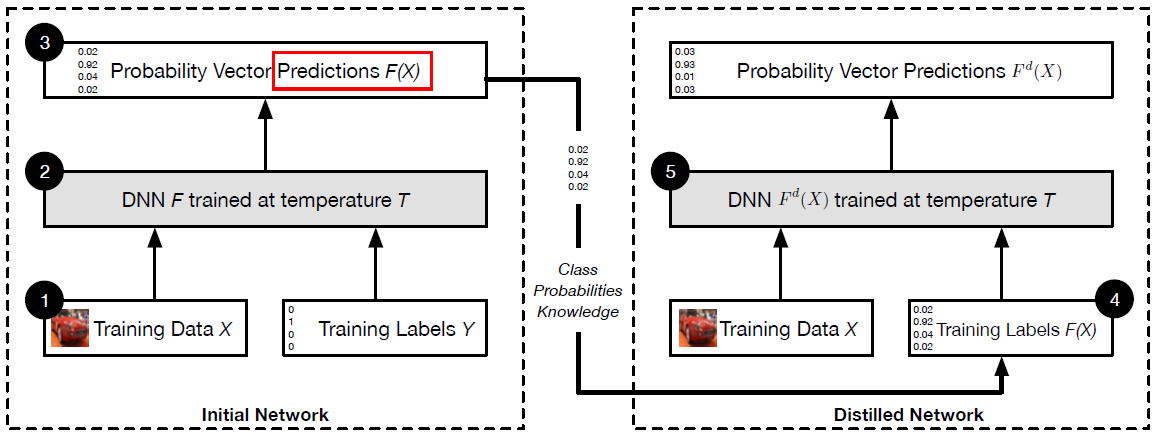
- 原始网络
- 原始训练数据集 X X X和原始的标签数据 Y Y Y;其中数据 Y Y Y为硬标签;
- 基于原始数据集、标签训练和引入蒸馏过程训练网络;
- 此时训练得到的网络输出是
F
(
X
)
F(X)
F(X),是一个经过
softmax输出后的概率分布;
- 蒸馏网络
- 基于第一个网络的预测结果 F ( X ) F(X) F(X)和原始输入数据重新得到训练数据;
- 使用新的训练数据和原始网络架构、蒸馏温度 T T T进行训练,得到蒸馏模型。
这么处理的一个好处是可以避免模型过于依赖某些数据。例如对于数字识别问题,假设硬标签是“7”,而软标签是“7”的概率是0.6,“1”的概率是0.4,则应该可以说明“7”和“1”之间应该有某些相似的特征可以提取。使用软标签进行训练的时候可以利用这些特征并区分这些差异,这样也能提高模型的泛化性。
4. Analysis of Defensive Distillation
分析三个方面:(1)网络训练;(2)模型的灵敏性;(3)模型的泛化性能。
问题的背景:只要数据量足够,我们最终总能找到一个网络架构,使得训练得到的模型可以满足精度要求,同时能对对抗样本鲁棒。
A. Impact of Distillation on Network Training
首先,对于传统的神经网络训练过程,最终是要满足:
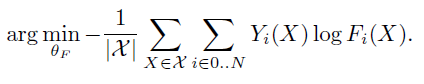
确定网络参数的过程。
其中, Y ( X ) Y(X) Y(X)为硬标签, F i ( X ) F_i(X) Fi(X)为模型的预测输出。简单来讲训练过程就是使得 Y ( X ) Y(X) Y(X)和 F i ( X ) F_i(X) Fi(X)不断接近的过程。
但是因为是硬标签,因此上式可以简化为:
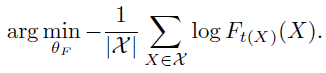
其中
t
(
X
)
t(X)
t(X)为向量中的非零index.
而对于防御蒸馏,需要求解的问题是:
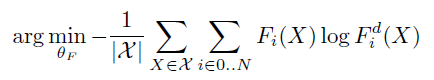
因为不是[0, 1]二值问题,因此此时不能简化,而需直接求解计算。
这样转换后训练的模型可以避免对结果过于自信,某种程度上提高了泛化性(3和8,1和7之间有相似的地方)。
关于神经网络训练,神经网络最终是要使得训练得到的模型
F
d
(
X
)
F^d(X)
Fd(X)尽可能接近真实模型
F
(
X
)
F(X)
F(X),
H
(
F
d
(
X
)
,
F
(
X
)
)
=
H
(
F
(
X
)
)
+
K
L
(
F
(
X
)
∥
F
d
(
X
)
)
\mathrm{H}\left(F^{d}(X), F(X)\right)=\mathrm{H}(F(X))+\mathrm{KL}\left(F(X) \| F^{d}(X)\right)
H(Fd(X),F(X))=H(F(X))+KL(F(X)∥Fd(X))
其中
H
(
F
(
X
)
)
H(F(X))
H(F(X))是香农熵(与
F
d
(
X
)
F^d(X)
Fd(X)无关)因此关键是后面的交叉熵。
B. Impact of Distillation on Model Sensitivity
上面分析的是防御蒸馏对训练过程,优化求解的影响。本节分析为什么蒸馏防御在较高蒸馏温度 T T T下能防御住对抗攻击。
模型/输出对输出的梯度可以写成雅可比形式,首先有:
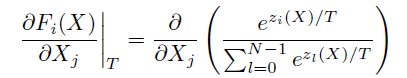
令 g ( X ) = ∑ l = 0 N − 1 e z l ( X ) / T g(X) = \sum^{N-1}_{l=0}e^{z_l(X)/T} g(X)=∑l=0N−1ezl(X)/T,则由下式:
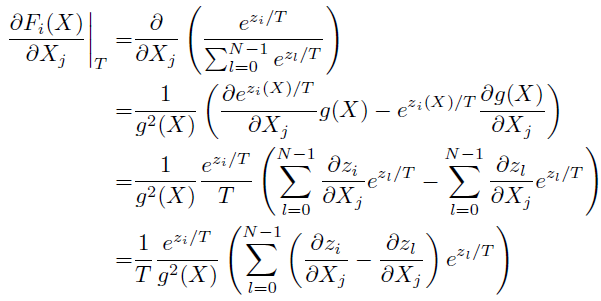
可以看出:
- 首先,雅可比值与 T T T 称反比;
- 其次, e e e指数中的值都除以了 T T T。
因此,随着蒸馏温度 T T T的增大,该矩阵值是减小的。
- 这也就解释了使用较大的蒸馏温度 T T T确实可以降低模型对输入变化的敏感性,即对输入扰动不那么敏感;
- 蒸馏温度只在训练阶段设置,而在测试阶段蒸馏温度
T
=
1
T=1
T=1,因为这种对输入不敏感的特性已经通过训练过程
encoding到了模型的参数中,并不会随着测试温度 T T T的改变而有不同影响,影响的只是输出的概率值大小,让结果更加离散,但是相对大小影响不了,也就不会影响分类结果。
C. Distillation and the Generalization Capabilities of DNNs
**motivations:**模型训练得到的预测概率 F ( X ) F(X) F(X)不仅将输入 X X X的正确分类信息编码到了网络中,同时将类别之间的相似信息也编码到了模型中。
以数字分类为例,假设对于输入数字“7”,硬标签是“7”,使用硬标签训练的时候则会强调是“7”。而不会认为是其它的,但是如果预测出来的输出是 F 7 ( X ) = 0.6 F_7(X)=0.6 F7(X)=0.6, F 1 ( X ) = 0.4 F_1(X)=0.4 F1(X)=0.4,则也从侧面说明了“7”和“1”之间从模型角度来看也是有相似性的。过分强调是“7”一定程度上降低了模型的泛化性。

从两个可学习理论进行研究:
stability,learnability。
基于两个定义:
Asymptotic Empirical Risk Minimizer:
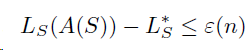
A
A
A表示学习规则(learning rule),
L
S
L_S
LS表示不同的经验损失,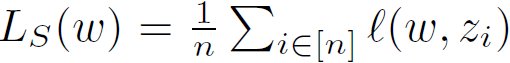 ,其中
ℓ
\ell
ℓ为
,其中
ℓ
\ell
ℓ为loss function。即对于一个可学习任务,使用不同的训练方法最终都是可以收敛的;
Stability:
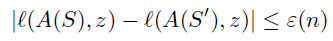
满足这个条件则说明学习规则
A
A
A是stability的。
Theorem 1:

即如果一个学习规则 A A A满足“渐进经验风险最小化器”和“稳定性”,则说明学习规则 A A A是泛化性。且其泛化误差 L D L_{\mathcal D} LD收敛到 L D ∗ L_{\mathcal D^*} LD∗,且与任意的数据生成分布 D \mathcal D D无关。
下一步则说明了本文的蒸馏防御是满足这两个条件的,因此泛化性很好。
- 首先。
5. Evaluation
回答了几个问题:
- 问题-1:
问:蒸馏防御有提高模型的对抗鲁棒性吗?(对对抗攻击的防御)且对分类精度有没有影响?
答:对于本文研究的两个模型,模型1的攻击成功率从
98.89%降到了0.45%;模型2的攻击成功率从87.89%降到了5.11%。对于模型的预测精度有一定的影响,但 ≤ 1.37 \le1.37% ≤1.37。
- 问题-2:
问:防御整理有降低
DNN模型对输入的灵敏度吗?答:防御蒸馏确实降低模型对输入扰动的灵敏度。实验表明,量级最大可差 1 0 30 10^{30} 1030。
- 问题-3:
问:防御蒸馏能提高模型的鲁棒性吗?
答:防御蒸馏能影响被对抗攻击的输入特征数。对于模型1模型的鲁棒性提升了
790%,模型2提升了556%;对于metric,模型1从1.55%增加到了14.08%,模型2从0.39%增加到了2.57%。
A. Overview of the Experimental Setup
数据集:MNIST和CIFAR10。

对CIFAR10数据集的说明,其中,将CIFAR10的图片处理完后,像素值范围变成了[-2.22, 2.62]。应该是归一化处理后的上下界。
模型架构:
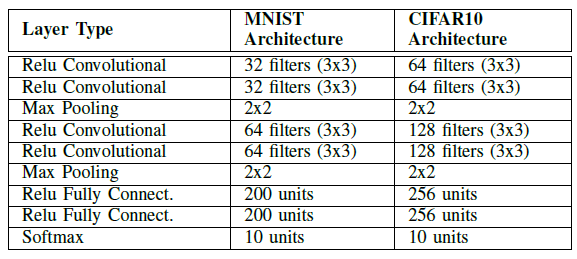 | 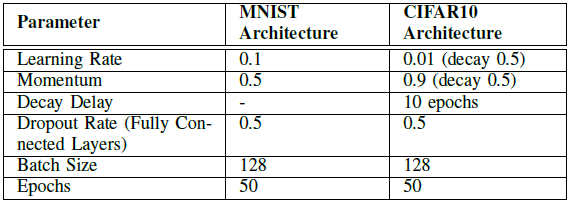 |
MNIST的分类精度可达99.51%;CIFAR10分类精度可达80.95%。
Adversarial Crafting:本文主要的攻击方法是基于Jacobian相关的方法。(后面也会分析对其他方法的防御)即首先根据图片的显著图(saliency map)的雅可比矩阵确定最容易改变输出的像素点,然后在这些点上进行扰动。
与之前方法的区别是:这种方法需要修改的像素点较少,但是修改量级较大;而之前的方法一般是基于所有像素点修改,但是每个像素值的扰动量较小。
对于扰动的特征数量有上限约束,即应小于112,因为过大的扰动会被人眼或异常检测软件检测到。
B. Defensive Distillation and Adversarial Samples
Impact on Adversarial Crafting:使用蒸馏温度 T = 20 T=20 T=20。
测试精度
| 数据集 | 测试精度 |
|---|---|
MNIST | 99.05% |
CIFAR10 | 81.39% |
在对抗样本防御上的表现,随机抽取100个样本,然后分别目标攻击9次(MNIST和CIFAR10都是10分类问题),评价攻击成功率。
| 数据集 | before | after | decrease |
|---|---|---|---|
MNIST | 98.89% | 1.34% | 98.6% |
CIFAR10 | 89.9% | 16.76% | 83.36% |
Distillation Temperature:训练阶段才有蒸馏温度。
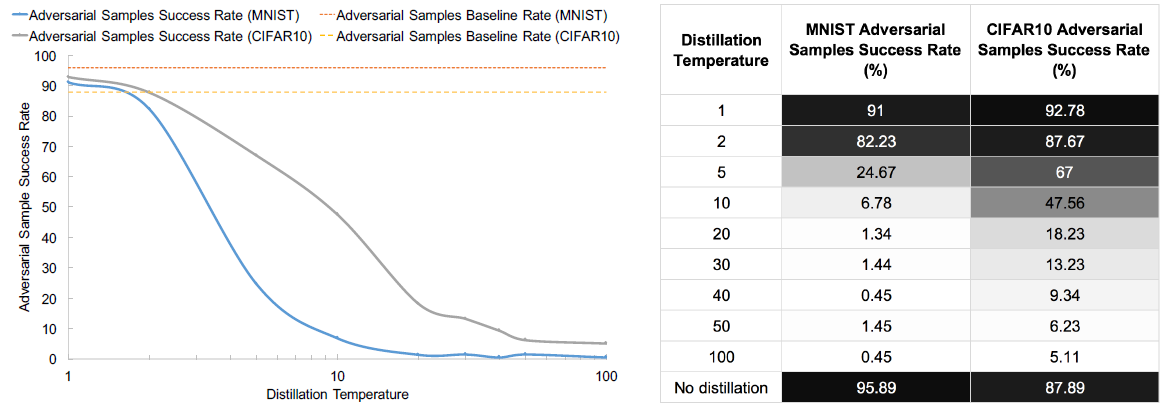
Observations:
- 随着温度的增加,对抗攻击成功率逐渐降低;
- 但是并不是随着温度的上升会一直降低,而是存在肘点。这一点可以从蒸馏防御的计算式子解释。随着温度的上升,得到的
softmax输出越来越平滑(平均),并最终都会收敛到 1 / N 1/N 1/N,因此在蒸馏温度达到一定值后,温度 T T T不再有不同的影响。
Classification Accuracy:蒸馏的引入可以进行防御,另外对蒸馏对分类结果影响进行分析。
对于原始的测试精度分别为99.51%、80.95%。
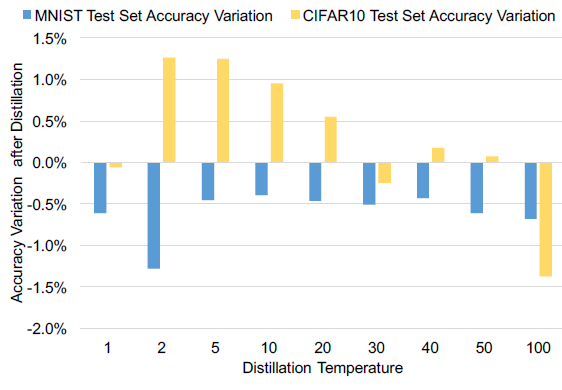
- 对于
MNIST,随着温度的增大,影响基本是negative的,但是最大相差也只有1.28%(因为本来精度已经将近100%(99.51%)); - 对于
CIFAR10,影响有正有负(且positive的居多),在 T = 100 T=100 T=100的时候,影响最大,但是也只有1.37%(是否在一定程度上,蒸馏也提高了模型的泛化性)。
总结:蒸馏温度对蒸馏防御和模型的泛化性都有影响,如何选择
T
T
T,需要同时考虑这两部分的影响(例如,对于MNIST,根据上两图,最好的文图
T
=
20
T=20
T=20)。
C. Distillation and Sensitivity
Our hypothesis is that our defense mechanism reduces gradients exploited by adversaries to craft perturbations.
有个假设:为什么蒸馏可以进行防御,是因为蒸馏操作将计算模型的梯度变得更难。
为了对这个假设进行验证,分别评估有无防御蒸馏方法参与计算的梯度的平均辐值。
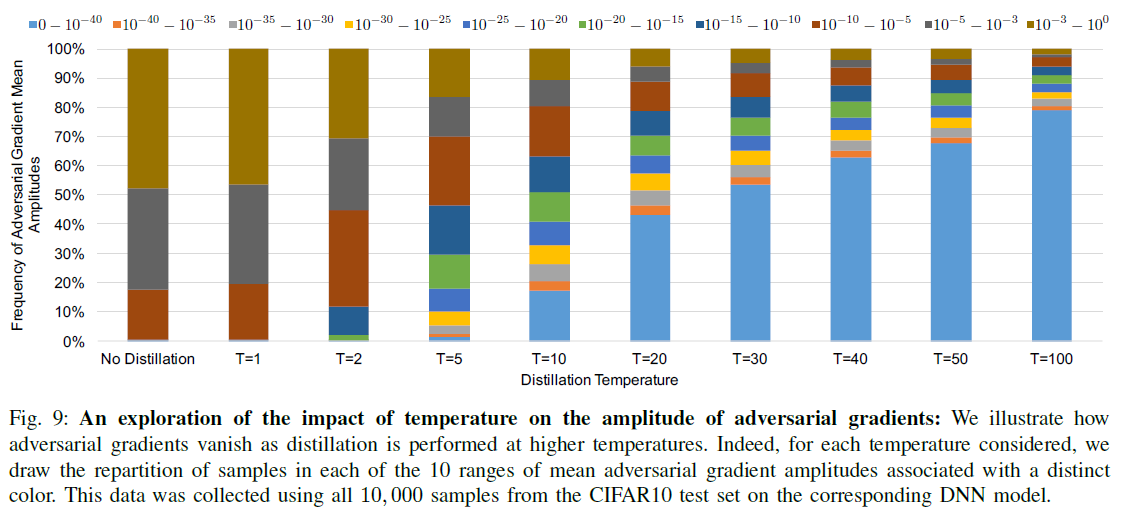
横坐标是温度,纵坐标是对抗梯度平均辐值的频率。
-
蒸馏有效的减小了对抗梯度值,例如,之前梯度绝对值超过
0.01的有4763个(在10000个测试样本中),在蒸馏温度是 T = 100 T=100 T=100时,这个值是172。梯度绝对值小于 1 0 40 10^{40} 1040的之前只有8个,但是在蒸馏温度 T = 100 T=100 T=100的时候,这个量级是7908个; -
简单来看,就是整体的梯度辐值频率都从较大的转移到了较小的范围。
-
梯度辐值整体都变的很小,这说明训练学习到的模型更加的平滑。也可以说基于梯度的攻击方法计算梯度更加复杂,为了要生成对抗样本需要更大的扰动;
D. Distillation and Robustness
Robustness:蒸馏使得训练得到的模型更加的平滑,本小结对训练得到分类器模型的平滑性和鲁棒性之间的相互作用进行研究。
鲁棒性的定义:
ρ
a
d
v
(
F
)
=
E
μ
[
Δ
a
d
v
(
X
,
F
)
]
\rho_{a d v}(F)=E_{\mu}\left[\Delta_{a d v}(X, F)\right]
ρadv(F)=Eμ[Δadv(X,F)]
Δ
a
d
v
(
X
,
F
)
\Delta_{adv}(X,F)
Δadv(X,F)是生成对抗样本所需要的最小扰动。根据这个值的大小可评估模型的鲁棒性。
最终在整个测试集上计算模型的鲁棒性公式为:
ρ
a
d
v
(
F
)
≃
1
∣
X
∣
∑
X
∈
X
min
δ
X
∥
δ
X
∥
\rho_{a d v}(F) \simeq \frac{1}{|\mathcal{X}|} \sum_{X \in \mathcal{X}} \min _{\delta X}\|\delta X\|
ρadv(F)≃∣X∣1X∈X∑δXmin∥δX∥
其中的限制条件是:
- δ X \delta X δX是将一个类别目标攻击成其它目标的扰动;
- 但是本文使用的方法不是扰动的大小,而是扰动所需要的特征数量(扰动量大小有上限),如下图所示。
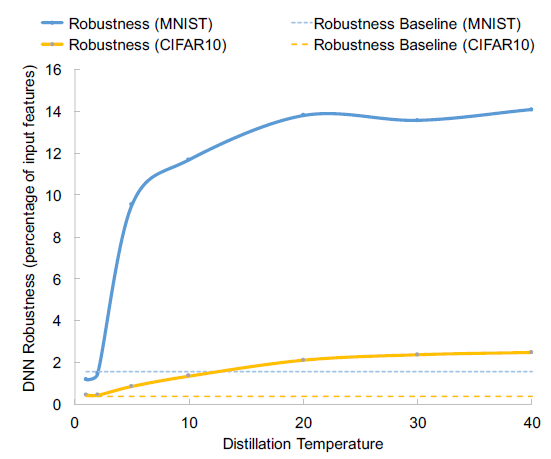
横坐标是蒸馏温度
T
T
T,纵坐标是基于Jacobian方法所需要的输入特征扰动百分比。
- 整体来讲,随着蒸馏温度的增加,这里定义的鲁棒性也增加;
- 对于
MNIST,从最开始的1.55%最高增加到了13.79%,增长了790%。13.79%已经达到了被检测程序检测出来的程度,同时,之前的工作表明,当扰动量大于13.79%的时候,人类也会开始错误分类(被人眼识别); - 对于
CIGAR10,从最开始的0.39%最高增加到了2.56%,涨幅达556%。(需要的扰动量不断增大,也说明了模型的泛化性逐渐变好)
小结:在蒸馏模型下,为了生成对抗样本需要更大的扰动值,即蒸馏有效的提高了模型的鲁棒性。
Distillation and Confidence:研究蒸馏温度对DNN模型的分类置信度的影响。
定义评价指标
C
(
X
)
C(X)
C(X):
C
(
X
)
=
{
0
if
arg
max
i
F
i
(
X
)
≠
t
(
X
)
arg
max
i
F
i
(
X
)
otherwise
C(X)=\left\{\begin{array}{c} 0 \text { if } \arg \max _{i} F_{i}(X) \neq t(X) \\ \arg \max _{i} F_{i}(X) \text { otherwise } \end{array}\right.
C(X)={0 if argmaxiFi(X)=t(X)argmaxiFi(X) otherwise
其中
t
(
X
)
t(X)
t(X)是正确类别。

小结:蒸馏同样提高了模型分类的置信度。
6. Discussion
- 蒸馏可有提高模型的对抗鲁棒性;
- 使用第一个模型训练预测的概率向量训练第二个模型又有利于提高模型的泛化性;
- 适用于类似与
softmax输出的网络,对于其它不同于DNN的模型需要进一步研究; - 本文定义的
adversarial distance metric是输入样本需要的扰动数量,与一般的 L p − n o r m s L_p-norms Lp−norms不一样; - 另一个问题是,能够用
soft label代替正文的probability vecotr进行训练?
soft label的定义是:
将目标分类的标签值从1转换成0.9,其它的都变成
1
10
⋅
N
\frac {1}{10\cdot N}
10⋅N1(不应该是
1
10
⋅
N
−
1
\frac{1}{10\cdot N-1}
10⋅N−11?)。发现使用这种方法训练得到的模型不剧本鲁棒性。猜测可能最终有利于模型分类的信息(鲁棒信息)还是与模型的概率输出(probability vectors)有关,而不是这里的软标签。
- 本文针对的攻击方法是基于梯度信息的
Jacobian方法,未来的一个方向是要评估是否对其它方法也鲁棒;
二个模型又有利于提高模型的泛化性; - 适用于类似与
softmax输出的网络,对于其它不同于DNN的模型需要进一步研究; - 本文定义的
adversarial distance metric是输入样本需要的扰动数量,与一般的 L p − n o r m s L_p-norms Lp−norms不一样; - 另一个问题是,能够用
soft label代替正文的probability vecotr进行训练?
soft label的定义是:
将目标分类的标签值从1转换成0.9,其它的都变成
1
10
⋅
N
\frac {1}{10\cdot N}
10⋅N1(不应该是
1
10
⋅
N
−
1
\frac{1}{10\cdot N-1}
10⋅N−11?)。发现使用这种方法训练得到的模型不剧本鲁棒性。猜测可能最终有利于模型分类的信息(鲁棒信息)还是与模型的概率输出(probability vectors)有关,而不是这里的软标签。
- 本文针对的攻击方法是基于梯度信息的
Jacobian方法,未来的一个方向是要评估是否对其它方法也鲁棒; - 本文没有将防御蒸馏和一些经典的正则化级数进行对比,因为首先,对抗样本不是一种过拟合现象,其次以前的工作已经证明了,正则化方法并不能提高模型的鲁棒性,相反,可能在一定程度上会影响模型的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









