







Towards Deep Learning Models Resistant to Adversarial Attacks
Towards Deep Learning Models Resistant to Adversarial Attacks (PGD),ICLR2018,涉及PGD和对抗训练。
Abstract:本文从优化的角度研究了神经网络的对抗鲁棒性问题。本文提出的方法提供了一个广阔、统一的观点来看待对抗样本的问题。本文提出方法的自然性质使得我们可以可靠的选择训练和攻击神经网络的方法,并且某种程度上是全局的。特别的,本文提出的方法在某种程度上提出了一种可以防御住任意攻击思路。这类方法训练神经网络极大的提高了网络对攻击的抵抗能力。
1. Introduction
对抗样本的存在一方面给神经网络的应用造成了安全隐患,另一方面也说明了目前神经网络/模型从鲁棒性角度来看,距离实际应用还远远不够。
之前也有很多方法用于攻击防御,例如防御蒸馏(defensive distillation)、特征压缩(feature squeezing)或其它对抗检测的方法。这些方法虽然在某种程度或应用上是有效的,但是它们也并没有明确地给出这些方法的适用性及适用范围。
本文思想是:
How can we train deep neural networks that are robust to adversarial inputs?
即如何训练模型,使其能对某一类攻击都鲁棒。本文从优化角度老研究神经网络的对抗鲁棒性问题。使用一个鞍点方程(min-max)来严格的描述对抗鲁棒性问题。这个方程使我们能精确的确定我们想要实现的安全保证问题(对哪些(哪类)攻击方法适用)。
Contributions:
- 给出了一种提高模型鲁棒性的方案.尽管目标(提出的鞍点问题)是个非凸、非凹的问题,但是最终这个问题还是可以求解的。并且,本文给出了证明,即基于一阶的方法可以可靠的解决这个问题。本文使用的是
Projeccted Gradient Descent(PGD)方法,这是一种利用局部一阶信息求解的优化方法(局部线性是成立的); - 对模型容量对鲁棒性影响进行了分析.本文对网络结构在对抗鲁棒问题上的影响,结果表明模型的容量扮演着很重要的角色。为了抵抗对抗攻击,网络的模型容量需要大大的大于仅有干净样本情况下所需要的容量。这表明对抗鲁棒模型的边界可能比正常模型的边界更加复杂;
- 基于PGD对抗训练给出了一些结果与结论。基于以上的分析,本文使用
PGD作为攻击方法生成对抗样本来训练鲁棒模型,训练得到的模型大大提高了模型鲁棒性。
2. An Optimization View on Adversarial Robustness
- Traditional goal of model training:
E ( x , y ) ∼ D [ L ( x , y , θ ) ] \mathbb E_{(x,y) \sim \mathcal D}[L(x,y,\theta)] E(x,y)∼D[L(x,y,θ)]
然而,正常的训练方法通常对抗鲁棒性能很差,为了提高模型的对抗鲁棒特性,需要适当的对范式进行扩展(to augment the Empirical Risk Minimization)。本文方法是思路不是聚焦于提高某个特定方法的鲁棒性,而是提出了一个具有通用性的范式。
- 第一步,需要明确攻击的方法(生成对抗样本)。对攻击方法需要明确允许的扰动大小 S \mathcal S S;
- 对风险期望范式进行修正,不同于(1)式直接基于原始样本求期望,而是首先要基于原始干净样本生成对抗样本,然后再基于对抗样本求解风险期望:
min θ ρ ( θ ) , where ρ ( θ ) = E ( x , y ) ∼ D [ max δ ∈ S L ( θ , x + δ , y ) ] \min _{\theta} \rho(\theta), \quad \text { where } \quad \rho(\theta)=\mathbb{E}_{(x, y) \sim \mathcal{D}}\left[\max _{\delta \in \mathcal{S}} L(\theta, x+\delta, y)\right] θminρ(θ), where ρ(θ)=E(x,y)∼D[δ∈SmaxL(θ,x+δ,y)]
- 首先,本文提出的范式给出了以大一统的形式,基本上可以涵盖之前提出的方法。
- 内层最大化问题用于寻找对抗样本;
- 外层问题是优化网络(基于内层对抗样本最小化损失函数)。
- 其次,该范式也对鲁棒模型应该满足的条件提出了明确的目标(通过优化损失函数实现)。特别地,当通过该范式求解得到的网络参数有消失的风险时,可能正说明此时的模型具有对抗鲁棒性。

2.1 A Unified View on Attacks and Defenses
之前工作的重点:
- 如何生成对抗样本;
- 如何防御对抗样本。

对于攻击方法:
FGSM:
x
+
ε
sgn
(
∇
x
L
(
θ
,
x
,
y
)
)
x+\varepsilon \operatorname{sgn}\left(\nabla_{x} L(\theta, x, y)\right)
x+εsgn(∇xL(θ,x,y))
本文提出了PGD:
x
t
+
1
=
Π
x
+
S
(
x
t
+
α
sgn
(
∇
x
L
(
θ
,
x
,
y
)
)
)
x^{t+1}=\Pi_{x+\mathcal{S}}\left(x^{t}+\alpha \operatorname{sgn}\left(\nabla_{x} L(\theta, x, y)\right)\right)
xt+1=Πx+S(xt+αsgn(∇xL(θ,x,y)))
在防御领域,使用对抗样本对训练数据进行增广是一个常见的方法。在本文提出的范式(2)中,这个条件自动满足,因为内部生成的对抗样本就直接用于外层的优化。
3. Towards Universally Robust Neural Networks
对于范式(2),一个很重要的特征就是通过训练获得较小的对抗loss保证了模型对对抗攻击的鲁棒性。
根据定义,因为这样训练得到的模型对所有的干扰loss都很小,所以模型不存在“对抗扰动”是可能的。
An important feature of formulation (2) is that attaining small adversarial loss gives a guarantee that no allowed attack will fool the network. By definition, no adversarial perturbations are possible because the loss is small for all perturbations allowed by our attack model. Hence, we now focus our attention on obtaining a good solution to (2).
对于给出的范式(2),有个重要的特征:因为它本来就是基于对抗样本(或者说是扰动样本)训练得到的,因此它对该方法生成的对抗样本应该是鲁棒的。
但是,对于求解该范式存在一定的问题,因为不管是内层的最大化优化问题还是外层的最小化优化问题,都是一个nonconvex问题。本文的一个很重要工作就是给出了如何求解该问题的方法。最后,实验也表明,只要训练的网络足够大,模型的鲁棒就能大大提高。
3.1 The Landscape of Adversarial Examples
本节首先对MNIST和CIFAR10数据集,内部最大化问题的landscape进行探索。(investigate the landscape of local maxima for multiple models on MNIST and CIFAR10)
因为一般的,神经网络训练得到的模型具有很多的局部最小点,而理论上,要求解(2)式,需要得到内部优化问题的最大值。为了得到更多的关于训练模型的landscape信息,本文选择从不同的起始点出发进行探索。
本文的一个结论是,实验表明内部最大化问题通过一阶方法是可以求解的。即使在使用PGD求解问题时,因为最终要将
x
′
x'
x′约束在
x
i
+
S
x_i+\mathcal S
xi+S内。在
x
i
+
S
x_i+ \mathcal S
xi+S会分布有很多的初始点,因此也将导致很多的局部最大值点。但是最后这些极大值点都会收敛到一个较集中的loss values(收敛接近)。这也验证了一个观点:虽然神经网络是个高度非凸的问题,具有很多的局部极小值点,但是这些极小值是很相似的,也即该方法仍然可解。
发现的现象:
- 使用
PGD作为攻击方法时,得到的损失值在不同初始条件下具有一致性:
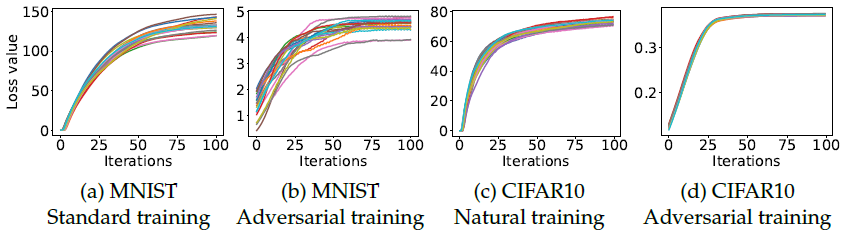
不同的颜色表示不同的其实条件,共有20组。初始条件为扰动内的均匀分布。
(1)不管初始条件怎样,最后都将收敛(到差不多的水准),CIFAR10更集中;
(2)对抗训练的loss明显比标准训练的loss小。
- 在经过大量(
10e5)的随机初始化(random restarts)训练后,模型的loss都是很集中(well-concentrated distribution)的。
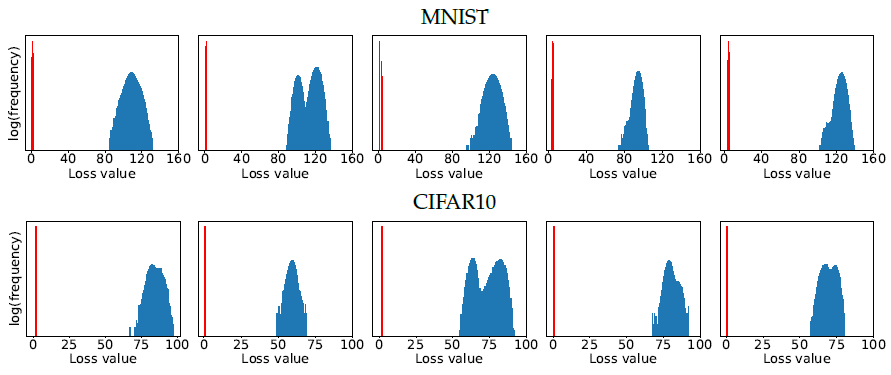
给出的是内部优化的CE-Loss。
(1)蓝色的是对抗样本在原始模型上的CE-Loss,红色的是对抗训练得到的CE-Loss;
(2)可以看出,经过对抗训练后,对抗样本的loss远远小于正常训练得到模型的loss,同时更加(完全)集中。
(3)同时,对不同maxima之间的区别进行研究。比较了他们之间的
ℓ
2
\ell_2
ℓ2距离和角度,表明,在
ℓ
∞
\ell_{\infty}
ℓ∞球上,$\ell_2 $距离很接近(distributed close to the expected distance),且角度正交(接近90度)。另外,连接两个极值点,在两个极值点间是convex的,即极值点在端点,中间不再存在其它的极值点。同时其它点得到的loss值都要远大于随机初始点得到的loss值。
所有这些实验结论都表明PGD是一个通用的一阶攻击方法。
3.2 First-Order Adversaries
通过上面的实验发现:不管是正常训练的模型还是对抗训练的模型,最终的loss都是很接近(集中)的,这个集中现象说明了一个问题:即对于所有的一阶攻击方法,只要对PGD鲁棒,则对其它所有的方法也鲁棒。
本文的实验表明,PGD攻击方法是目前最强的一阶攻击方法,虽然目前用于求解机器学习的优化方法有很多中,但是目前最有效的仍然是基于一阶的方法,PGD及其变种是目前最有效的方法。因此,本文根据实验及以上分析,大胆提出,基于一阶信息训练/攻击的方法具有通用性。
如果我们训练的网络对
PGD攻击鲁棒,则它会对目前所有方法都鲁棒。
同时,这个结论也具有一般性,即不仅适用于白盒问题, 也同样适用于黑盒攻击问题。
对攻击的迁移性也进行了分析。实验观察到:通过增加模型的容量且强化训练对手(使用FGSM或PGD训练,而不是对抗训练)能提高模型对迁移性攻击的抵抗能力。
3.3 Descent Directions for Adversarial Training
对训练进行对抗训练进行分析。
首先,在神经网络训练过程中,最小化损失函数(用于训练)的方法是SGD。对于(2)式给出的鞍点问题,通常直接求解是比较困难的,但是Danskin's theorem指出:
对内层最大值求梯度,确实就是求解梯度的下降方向。
虽然不满足严格的要求,即神经网络因为ReLU和最大池化操作的存在,并不能满足连续性可导,但是我们仍然可是使用这个理论进行鲁棒训练,即使用内层生成的对抗样本去训练网络,仍然是有效的(实验也证明了这一点)。
4. Network Capacity and Adversarial Robustness
motivation:仅仅通过解决(2)式并不足以保证该分类问题的鲁棒性和精度。
对于训练神经网络而言,最终评价训练过程/网络性能的指标归根结底是loss value,即最终模型对对抗样本的损失。一般地,认为一个小的loss说明训练出来的模型是较好的模型,并且也能对对抗样本表现出鲁棒性。
所以,接下来还要对如何实现问题的完全求解进行分析。
训练神经网络需要匹配的三要素:
- 问题复杂度;
- 模型复杂度;
- 数据复杂度。
对于对抗鲁棒性问题,数据和问题都是确定的,那么问题的关键就取决于模型复杂度。
相应地,模型的架构容量也就成了影响最终性能的关键因素。某种意义上来说,因为对抗样本的存在,将原始问题的边界变得更加复杂,也需要容量更大的模型。
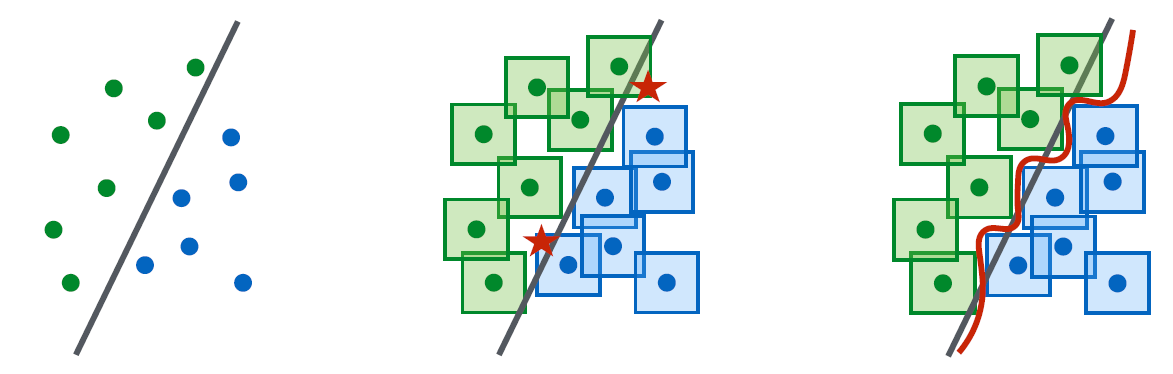
- 对于原始简单的样本,最左侧情况,此时决策边界也简单,则需要使用的模型架构/容量也简单;
- 有对抗样本的情况,如中间图所示( ℓ ∞ \ell_{\infty} ℓ∞),此时如果仍然使用线性分类器,则已经不能很好的说明问题,图中的红点为此时的对抗样本;
- 需要更复杂的边界/模型,如最右边所示,才能表征问题。
同时,还能说明一些问题,即对抗训练出来的模型在测试集上的分类精度会有所下降。根据上面的分析,对抗训练得到的模型边界更加复杂,则对于干净样本来说模型此时是过拟合状态,即模型在测试集上的精度有所下降。
以下对不同模型容量在不同对抗样本下的训练结果进行实验:
使用的都是卷积模型:
- 对于
MNIST数据集,原始模型是2个卷积核(通道数分别是2、4)“+”一个全连接层(64神经元),卷积核后接 2 × 2 2 \times2 2×2的最大池化, ϵ = 0.3 \epsilon = 0.3 ϵ=0.3。为了分析模型容量对结果的影响,每一个将卷积核的通道数和全连接层的神经元翻倍; - 对于
CIFAR10数据集,使用的是wideResNet-32模型。
模型说明:使用的Wide-ResNet-32,如下所示:

 |  |
共有三种类型的block,map size分别为32、16、8,通道数分别为160、320、640(原始ResNet-32是16、32、64).每种类型block内是5个卷积单元。
这个网络在原始样本上的训练精度可达95.2%,使用PGD攻击时,
ϵ
=
8.
/
255
(
≈
0.03
)
\epsilon = 8./255 (\approx0.03)
ϵ=8./255(≈0.03)。
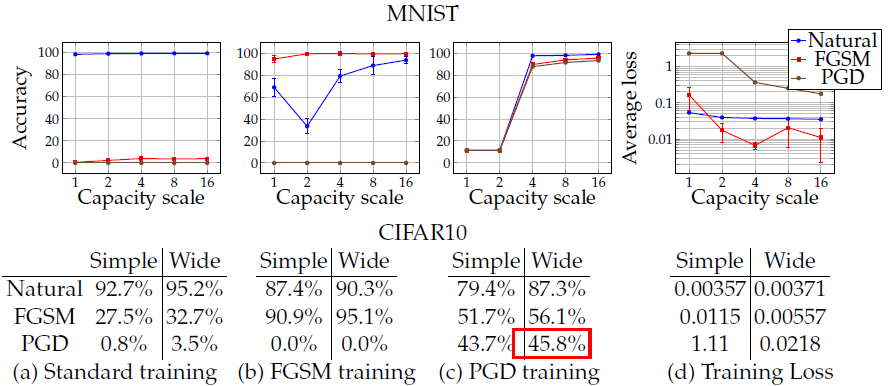
上图给出的PGD training下wide模型鲁棒结果45.8应该是在7-PGD训练好后模型,使用20-PGD攻击得到的鲁棒结果。如第5张CIFAR10结果图式。
结论就是模型的容量对模型的鲁棒性至关重要,具体:
- 对于正常训练,可能很简单的模型就够了,因此训练精度变化很小;
- 在
FGSM训练中,对FGSM对抗样本分类准确率最高;对PGD样本无效;正常样本会先下降;但是随着模型容量的增加又会趋于高精度; - 对于
PGD训练,三种样本的规律是一致的,即随着模型容量的增大,精度都变好了; - 最后,给出三种训练模式下的
loss,其中正常训练的loss变化不大,但是FGSM和PGD的loss随着模型容量的增大会逐渐减小。
同时,观察到了一下的现象:
- 仅通过改变模型的容量就能有效提高模型的鲁棒性。对于最左侧图片,对于正常训练模型,随着模型容量的增大,对
FGSM对抗样本的精度也增高了(在小扰动下更明显); - **使用
FGSM训练得到的模型不能提高模型的鲁棒性(对于扰动较大的情况)。**当使用FGSM生成的对抗样本训练神经网络时,训练到的网络会对对抗样本表现出过拟合。这种情况叫做标签泄露(label leaking),其缘由可能是训练出来的网络生成的是非常局限的对抗样本,使得模型过拟合。同时,网络在自然样本和PGD生成的对抗样本上都表现的很差。在扰动较小是,生成的对抗样本和PGD生成的很像,所以对PGD也有效,但是对于大扰动就失效; - 容量小的模型(weak models)可能并不能学到有效的结果。如果使用容量较小的模型去进行对抗训练(特别是
PGD对抗训练),可能会最终使得模型学不到任何有价值的东西。对于中间两幅图,特别是第三幅图,在模型容量较小时,模型对三类样本分类效果都很差。这种情况下可能会使得模型仅仅对一些固定的类别有效果(即使正常训练下该模型能有较好的性能),训练过程中,模型会牺牲对正常样本的分类效果来换取对对抗样本的分类精度,但因为模型容量较小,最终可能什么都没学到; - 随着模型容量的增大,(2)式逐渐求解的较好。也即增大模型的容量,模型对对抗样本更加鲁棒;
- 越大容量的模型和更强的攻击方法会降低攻击迁移性。要么增大模型的容量,要么在求解内层优化问题时使用更强的攻击方法都会降低模型的攻击迁移性。实验表明,随着网络容量的增加,训练网络和迁移网络键的梯度相关性越来越低。
5. Experiments:Adversarial Robust Deep Learning Models
实验部分要说明两点:
- 训练一个模型容量足够大的网络;
- 使用最强攻击方法(
PGD去训练)。
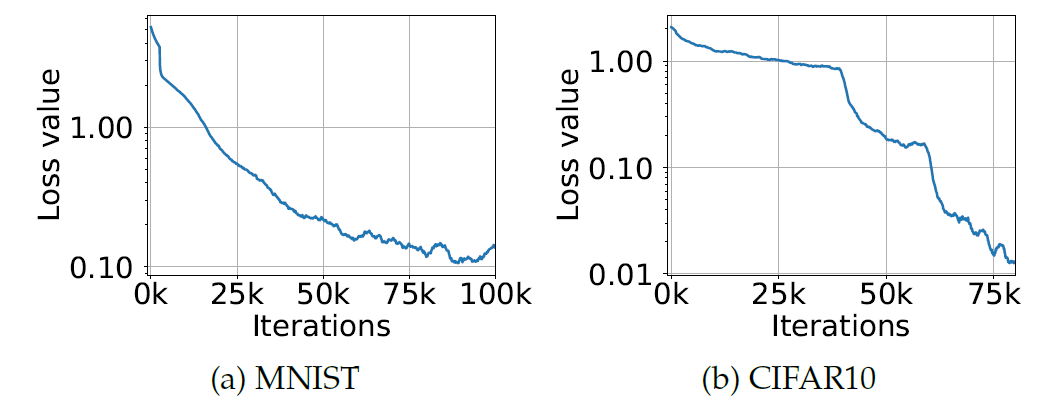
下图所示,分别是使用PGD在MNIST和CIFAR10上的训练loss曲线。
- 两种情况下
Training Loss都会持续下降,即暗示了训练过程确实有效;
对对抗训练得到模型的性能进行评估:
 |  |
-
A表示使用PGD下的白盒攻击,使用不同的迭代步和restarts; -
A'表示模型和A一样,但是使用黑盒攻击方法进行攻击; -
使用
PGD作为adversary对抗训练时候的一些参数(CIFAR10):- steps:7
- α \alpha α:2/(2.0/255 = 0.0078)
- ϵ \epsilon ϵ:8/(8.0/255 = 0.03)
-
在测试阶段,仍然是
PGD进行攻击,最终的扰动大小仍是 ϵ = 8 \epsilon=8 ϵ=8,但是迭代步分别为7、20。其中20迭代步认为是最强攻击方式。
一些结论:
- 对于
MNIST数据集,若直接使用干净样本训练,则在evaluation set上的精度可达99.2%,但是使用FGSM攻击准确率就下降到了6.4%.在对抗训练下,干净样本的分类精度降了一点点(99.2%-98.8%),但是对攻击方法鲁棒性大大提高。 - 对于
CIFAR10数据集,对抗模型在自然样本上的分类精度是87.3%,对抗训练后模型的精度虽没有像MNIST那么明显,但是也大大提高了; - 模型使用的是
7-PGD对抗训练得到,使用不同K-PGD进行攻击时,表现不同。其中7-PGD攻击分类精度有50.0%,使用20-PGD攻击时下降到45.8%; - 通过更复杂的模型(容量),效果应该能进一步提高。
Resistance for different values of ϵ \epsilon ϵ and ℓ 2 \ell_2 ℓ2-bounded attacks
为了进一步对对抗训练模型的鲁棒性进行分析,本文又进行了两个实验,分别是在测试阶段,对 ℓ ∞ \ell_{\infty} ℓ∞下不同攻击扰动值 ϵ \epsilon ϵ大小对分类精度的影响和 ℓ 2 \ell_2 ℓ2范数下模型的鲁棒性进行评估。
- 在
ℓ
2
\ell_2
ℓ2-bounded约束下,使用的不再是模型梯度的符号,而直接是梯度的方向,且对步长大小进行归一化。最终,每次
PGD攻击都使用100迭代步,同时设置步长为 2.5 ⋅ ϵ / 100 2.5 \cdot \epsilon /100 2.5⋅ϵ/100。这样仍然满足最终的大小是小于单步步长与迭代步数的乘积和( 100 ⋅ ( 2.5 ⋅ ϵ / 100 ) > ϵ 100 \cdot (2.5 \cdot \epsilon/100)>\epsilon 100⋅(2.5⋅ϵ/100)>ϵ)。
在原始对抗训练下,即
7-PGD对抗训练得到模型,在不同扰动大小下的分类精度表型:
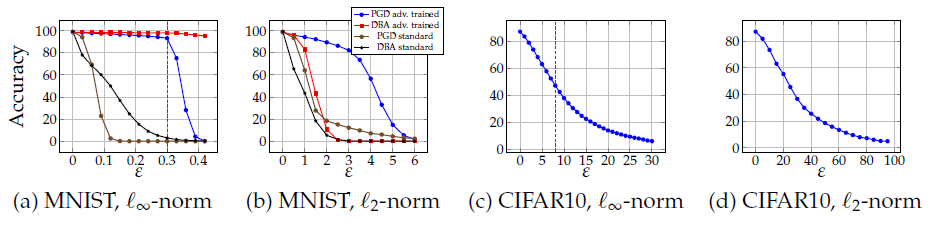
-
对于(a)、(b)图,主要比较其中的蓝色线和黑色线,即
PGD对抗训练和PGD标准攻击。在MNIST数据集下,模型的表现在扰动超过某个阈值后立刻(大幅度)下降(CIFAR10是缓慢下降)。但是正常训练模型和对抗训练模型下降的阈值不同。这种阈值不同现象可能是因为对抗训练根据给定的扰动不同而学习到了不同的新阈值。 -
对于(c)、(d)图,两种格式范数约束下,随着扰动的增大(表示攻击强度变大),精度逐步下降((a)、(c)图中的红虚竖线分别表示扰动是0.3和8的情况);
-
此外,对于 ℓ 2 \ell_2 ℓ2约束下对
MNIST的攻击,发现PGD方法,即使使用较大的 ϵ \epsilon ϵ也不能攻击成功。以下图为例,虽然最终分类错误了,但是已经不能较对抗样本,因为人眼已经能够识别出来。(也有文献指出,PGD在 ℓ 2 \ell_2 ℓ2约束下表现出了overestimating的性质)。这可能是因为学习到的网络将梯度信息隐藏了,这样PGD方法不再那么有效。若使用decision-based的方法进行攻击,则模型表现的较 ℓ 2 \ell_2 ℓ2约束下更脆弱。

6. Related Work
7. Conclusion
- 本文的工作说明了神经网络,使用对抗训练可以抵抗对抗样本现象;
- 本文的实验也说明了一个问题,即使最终的训练任务是个非凸、多局部极值点的问题,但是问题仍然是可解的,因为这些极值点比较集中;
- 本文的方法/实验在
MNIST数据集上表现很好,但是在CIFAR10上表现的不是太好,但已经能说明问题了。















 2728
2728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









