






参考:百度安全验证
本文基于python第三方数据分析库pandas,分享这几天所遇到的3个爬坑的案例,希望对也在爬坑的同学们尽一份绵薄之力,如有错误或者写得不好的地方,烦请指正,谢谢。
01df中startswith的坑
这两天我在工作中碰到一个非常奇葩的情况,简单来讲需求大概是这个样子:
两个数据集合,需要联合后,查询某两个特殊字段是否是包含的关系,如果包含则输出1,否则输出0
需求的意思大概如下所示

按理说,上图应该正常会生成新的列tmp,但是,发生了如下的事情,上图
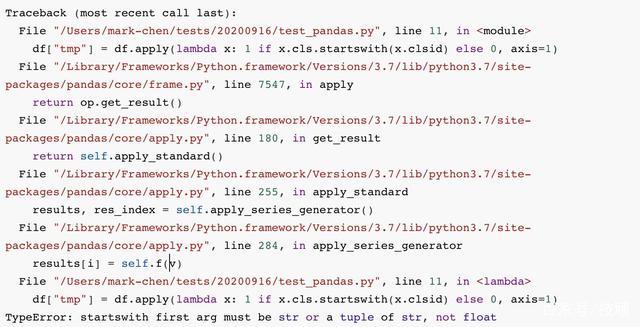
说startswith函数不能以float函数开头,直接给我整懵逼了,我这上面明明就已经设置了数据类型为str类型了,怎么拼接完又变成float类型了。
于是我就验证clsid 和cls字段在读取文件后的数据类型,发现是string,没有问题。然后又检查了拼接后的这两个字段,也都是string,也没有问题。那么就神奇了,明明都是string,但是却显示不能以float开头
没办法,只能对数据集合做修改,修改如下

这样便正常了,你说坑不坑!
02csv文件读和写的坑
读文件相关
建议读取csv文件,最好带有列的类型属性,pandas遇到这种"0100"的,会自动变更为int类型,建议代码如下
不指定数据类型

指定数据类型但是却有nan值

写文件相关
需求描述
在向指定路径写文件(df.to_csv())时,遇到过一个追加写的问题,大概意思是:程序跑完,正常来讲应该有两次往同一个文件写日志,但是后面需求变动为程序跑完。有可能出现只写一次或者一次都不写的情况问题在利用pandas接口写文件,要么带列名,要么不带列名,你需要判断此次的写文件属于第一次写(覆盖写)还是第二次写(追加写),来决定是否需要加列名写文件解决方案

03遍历相关(iterrows)
使用df.iterrows()循环数据集合
datdaframe.iterrows()是返回迭代器,一般是用for语句调用, 返回为当前df所在行索引以及那一行具体数据用for循环调用取值,不可以直接把当前行的数据进行计算,应该把要计算的数据用变量先接收,再进行整合计算索引在你需要更改df的某一列的值时特别好用

使用df.values()循环数据集合
用for循环每一行会生成一个列表,方便的是可以用列表的命令操作,一般用于对数据的处理和集成,相比较iterrows来说,可能唯一的好处是可以根据列表方法对数据进行操作
















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









