







通过线程合作完成点积运算的操作,中间涉及到的知识内容在代码注释中解释。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "H:\cuda_by_example\common\book.h"
#include "H:\cuda_by_example\common\cpu_bitmap.h"
#include "device_functions.h"
#include <stdio.h>
using namespace std;
#define imin(a,b) (a<b?a:b)
const int N = 33 * 1024;
const int threadsPerBlock = 256;
const int blocksPerGrid = imin( 32, (N+threadsPerBlock-1) / threadsPerBlock );
__global__ void dot( float *a, float *b, float *c ) {
//共享内存的缓冲区cache,实际上是一个保存线程块内每个线程加和计算值,
//一旦建立这样一个共享数组,就意味着每一个线程块都有一个这样的cache,一一对应
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
//由于线程块之间不能共享内存,只有一个线程块中的线程才能共享内存,因此,
//cacheIndex也就是共享内存的索引就是线程索引
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
//在共享内存中相应位置存下线程计算的值,以便接下来的求和操作
cache[cacheIndex] = temp;
//对线程块中的线程进行同步
__syncthreads();
//归约算法
int i = blockDim.x/2;
//每一轮循环都将还需求和的前半个数组与对应在后半个数组相应位置的值相加
//并且保存在前半个数组里
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
//结束循环后每个线程块都得到一个值
//在将这个值保存到全局内存当中
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
int main( void ) {
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
// allocate memory on the cpu side
a = (float*)malloc( N*sizeof(float) );
b = (float*)malloc( N*sizeof(float) );
partial_c = (float*)malloc( blocksPerGrid*sizeof(float) );
// allocate the memory on the GPU
HANDLE_ERROR( cudaMalloc( (void**)&dev_a,
N*sizeof(float) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_b,
N*sizeof(float) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_partial_c,
blocksPerGrid*sizeof(float) ) );
// fill in the host memory with data
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = i*2;
}
// copy the arrays 'a' and 'b' to the GPU
HANDLE_ERROR( cudaMemcpy( dev_a, a, N*sizeof(float),
cudaMemcpyHostToDevice ) );
HANDLE_ERROR( cudaMemcpy( dev_b, b, N*sizeof(float),
cudaMemcpyHostToDevice ) );
dot<<<blocksPerGrid,threadsPerBlock>>>( dev_a, dev_b,
dev_partial_c );
// copy the array 'c' back from the GPU to the CPU
HANDLE_ERROR( cudaMemcpy( partial_c, dev_partial_c,
blocksPerGrid*sizeof(float),
cudaMemcpyDeviceToHost ) );
// finish up on the CPU side
c = 0;
for (int i=0; i<blocksPerGrid; i++) {
c += partial_c[i];
}
#define sum_squares(x) (x*(x+1)*(2*x+1)/6)
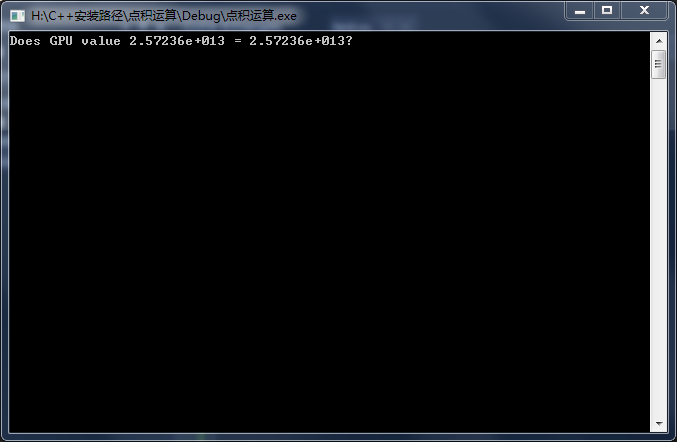
printf( "Does GPU value %.6g = %.6g?\n", c,
2 * sum_squares( (float)(N - 1) ) );
getchar();
// free memory on the gpu side
HANDLE_ERROR( cudaFree( dev_a ) );
HANDLE_ERROR( cudaFree( dev_b ) );
HANDLE_ERROR( cudaFree( dev_partial_c ) );
// free memory on the cpu side
free( a );
free( b );
free( partial_c );
} 
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









