







 本文总结了在高并发场景下,Spark存在的内存泄露问题,包括AsynchronousListenerBus、Cleaner、线程池与ThreadLocal、文件泄露、deleteOnExit、JDO内存泄露和Listener的内存泄露。并详细介绍了每个问题的成因及相应的解决策略,如调整配置、限制SQL执行等待队列长度和改进线程池实现等。
本文总结了在高并发场景下,Spark存在的内存泄露问题,包括AsynchronousListenerBus、Cleaner、线程池与ThreadLocal、文件泄露、deleteOnExit、JDO内存泄露和Listener的内存泄露。并详细介绍了每个问题的成因及相应的解决策略,如调整配置、限制SQL执行等待队列长度和改进线程池实现等。
最近为了测试延云YDB在高并发请求和持续性请求情况下的表现,发现了spark的不少关于内存泄露的问题,这些问题均在延云YDB提供的SPARK版本中得以修正,现将问题总结如下。
1. 高并发情况下的内存泄露
很遗憾,spark的设计架构并不是为了高并发请求而设计的,我们尝试在网络条件不好的集群下,进行100并发的查询,在压测3天后发现了内存泄露。
a) 在进行大量小SQL的压测过程中发现,有大量的activejob在spark ui上一直处于pending状态,且永远不结束,如下图所示

b) 并且发现driver内存爆满
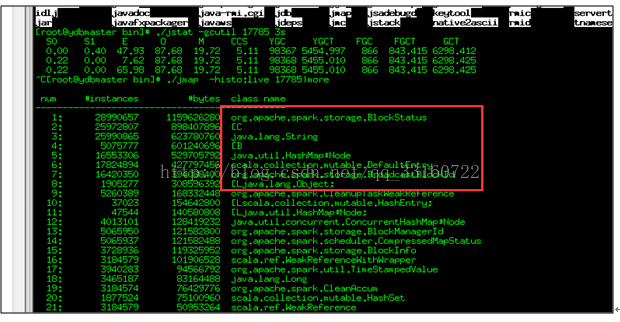
c) 用内存分析分析工具分析了下
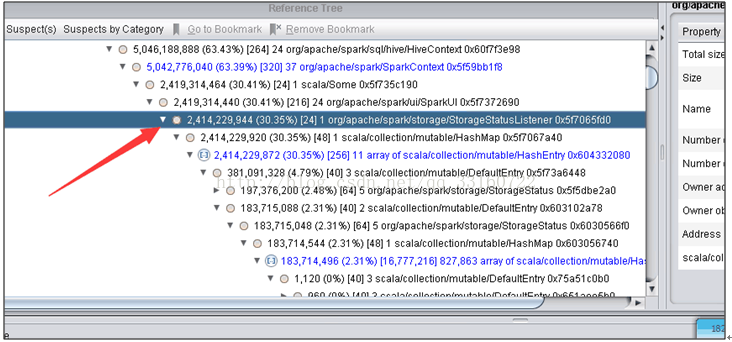
2. 定位到最终内存泄露的原因以及解决办法
1) AsynchronousListenerBus引起的WEB UI的内存泄露
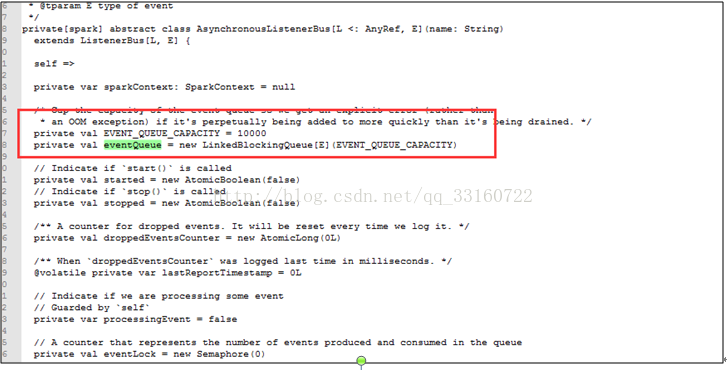
短时间内 SPARK 提交大量的SQL ,而且SQL里面存在大量的 union与join的情形,会创建大量的event对象,使得这里的 event数量超过10000个event ,
一旦超过10000个event就开始丢弃 event,而这个event是用来回收 资源的,丢弃了 资源就无法回收了。 针对UI页面的这个问题,我们将这个队列长度的限制给取消了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









