






关于spark的性能,基于YDB的对比,做了一个测试,保留备用。
一、YDB与spark sql在排序上的性能对比测试
在排序上,YDB具有绝对优势,无论是全表,还是基于任意条件组合过滤,基本秒杀spark任何格式。
测试结果(时间单位为秒)
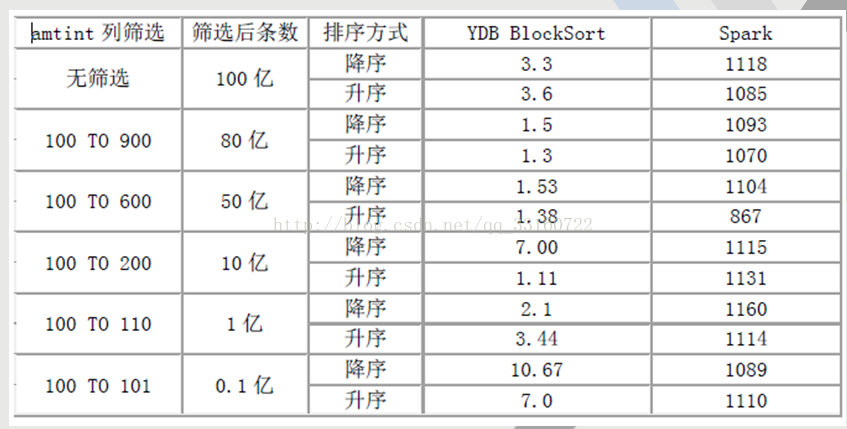
详细测试地址:http://blog.csdn.NET/qq_33160722/article/details/54447022
300亿条数据的排序 演示视频 http://blog.csdn.Net/qq_33160722/article/details/54834896二、与Spark txt在检索上的性能对比测试。
注释:备忘。下图的这块,其实没什么特别的,只不过由于YDB本身索引的特性,不想spark那样暴力,才会导致在扫描上的性能远高于spark,性能高百倍不足为奇。
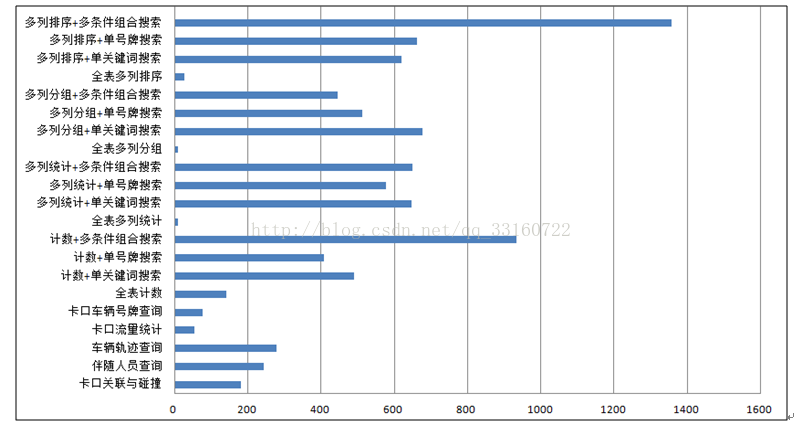
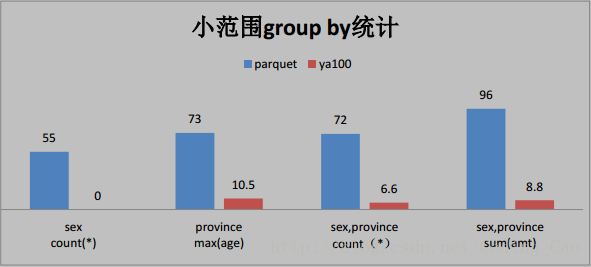
三、这些是与 Parquet 格式对比(单位为秒)
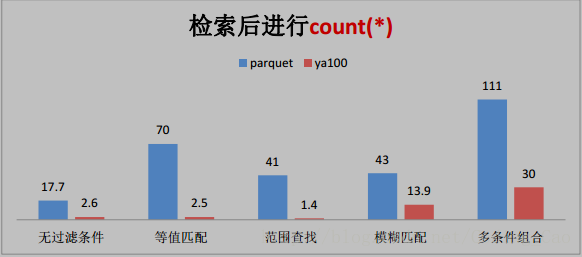
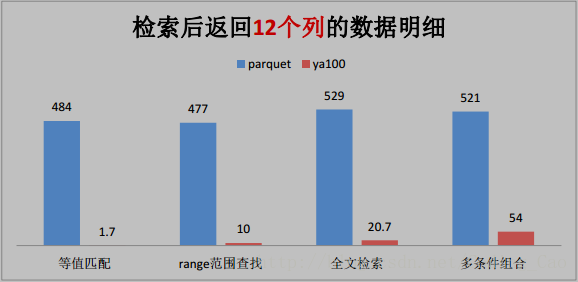
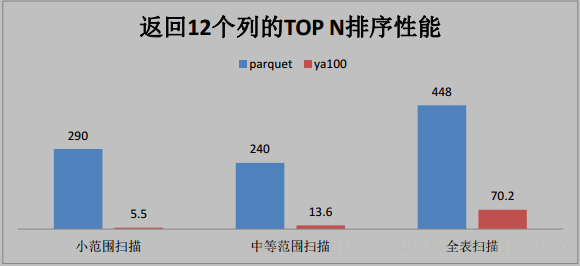
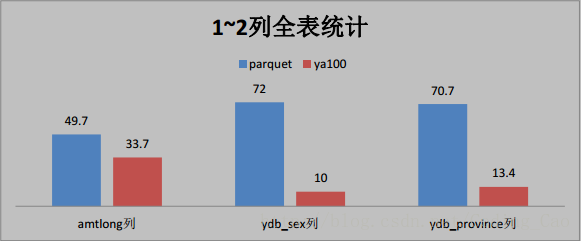
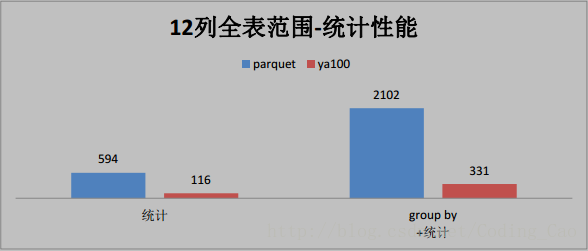
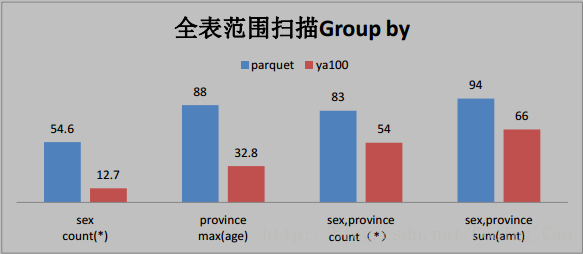
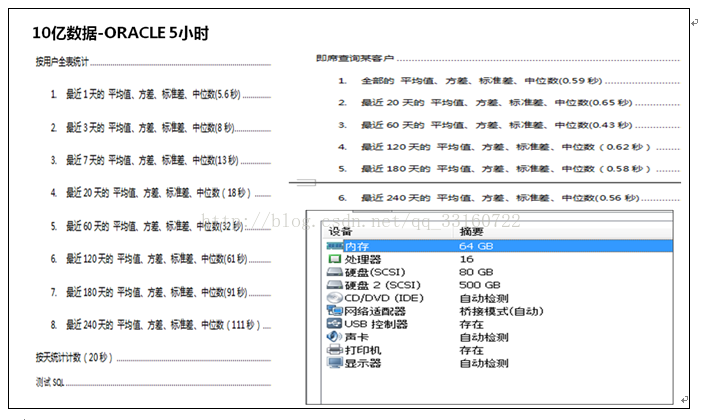
四、与ORACLE性能对比
跟传统数据库的对比,已经没啥意义,oracle不适合大数据,任意一个大数据工具都远超oracle 性能。
| |
五、稽查布控场景性能测试

六、YDB是怎么样让spark加速的?
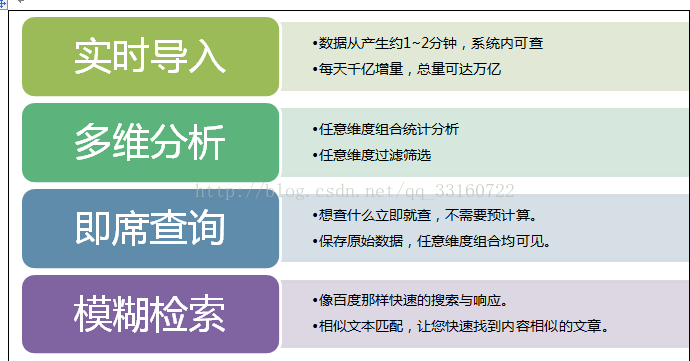
基于Hadoop分布式架构下的实时的、多维的、交互式的查询、统计、分析引擎,具有万亿数据规模下的秒级性能表现,并具备企业级的稳定可靠表现。
YDB是一个细粒度的索引,精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。YDB与Spark深度集成,Spark对YDB检索结果集直接分析计算,同样场景让Spark性能加快百倍。
哪些用户适合使用YDB?
1.传统关系型数据,已经无法容纳更多的数据,查询效率严重受到影响的用户。
2.目前在使用SOLR、ES做全文检索,觉得solr与ES提供的分析功能太少,无法完成复杂的业务逻辑,或者数据量变多后SOLR与ES变得不稳定,在掉片与均衡中不断恶性循环,不能自动恢复服务,运维人员需经常半夜起来重启集群的情况。
3.基于对海量数据的分析,但是苦于现有的离线计算平台的速度和响应时间无满足业务要求的用户。
4.需要对用户画像行为类数据做多维定向分析的用户。
5.需要对大量的UGC(User Generate Content)数据进行检索的用户。
6.当你需要在大数据集上面进行快速的,交互式的查询时。
7.当你需要进行数据分析,而不只是简单的键值对存储时。
8.当你想要分析实时产生的数据时。















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









