






前言
本文不讲“索引是什么和索引如何创建”这类问题,本文从索引建立时发生了什么 讲到 索引与B+树的关系 再讲到索引如何作用于查找,能在一定程度上深入理解索引
索引这个老大难问题一直是我在多年的数据库学习过程中每次都会看,但是一直搞不太懂的部分。
每次查资料都只有“索引是什么和索引如何创建”这类回答
但我一直困惑于一下几个问题:
- 索引在哪里用,怎么用?
- 索引如何作用于查找过程并最终使查找速度变快
- 索引与B+树这种数据结构之间有什么关系【注:在本文仅讨论B+树索引的情况】
- 索引、表、记录、查询之间是怎么关联起来的
分析索引
要了解索引,我们首先要清除索引构建了一个什么数据结构——这个结构便是B+树
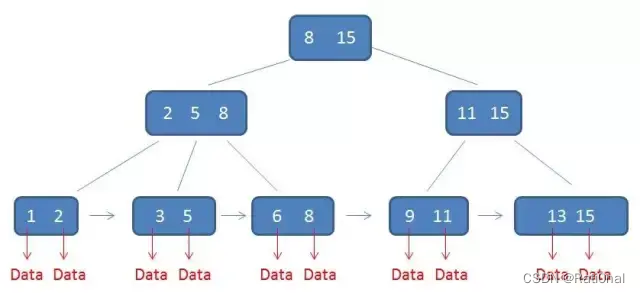
我们结合B+树的图和SQL语句来理解:
1. CREATE INDEX 索引名 ON 表名(列名1)
2. CREATE INDEX 索引名 ON 表名(列名1,列名2,列名3)
以第一句SQL为例,在建立索引时,我们是针对列1建立的索引【假设列名1为ID列,具体为1-15】。
那么此时会用所有行的Col1作为数据以字典序构建B+树【即1-15】;此时我们观察B+树的结构,每一个树的所有节点其实都是只存放Col1的所有数据【即一个int型变量】,而每个数据都对应着一个记录【】即数据表中的一列】,这刚好与B+树的实际Data是在叶子结点下面的非常契合
建立索引可以理解为 :用所有行此列的数据作为B+树的节点去建立一个B+树
对于第二句SQL创建的复合索引(A,B,C),会建立三颗即以(A)、(A,B)、(A,B,C)为结点数据的B+树
数据库在查询的时候——select时where语句是要找哪个列或者哪几个列,如果已经建立了索引,那就可以把查找时间复杂度降为O(logn)
【所以在数据库建表的时候如何高效地建立索引? 看什么列在where语句里出现得多】
注:几个会直接屏蔽索引的情况(即以O(n)的时间复杂度查找)
- 一般的返回查询都可以走索引;;例外为:Between关键字的范围查询、!=、查询字段未被索引覆盖的范围查询
- 运算于索引列上
- 字符串不加引号
- 遇见like就不用索引
- 只有or前后都有索引才有用














 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









