







数据类型(下篇 )主要讲解 bitmap, bitfield, Geo, Hyperlog, Stream.
1 Redis数据类型概览
1.1 概览

1.2 基本介绍
1. String(字符串)
- 基本介绍: 存储的是文本或二进制数据,最大存储容量为 512MB。
- 底层结构: 简单动态字符串 SDS(Simple Dynamic String)。
- 应用场景: 缓存、计数器、分布式锁。
2. Hash(哈希表)
- 基本介绍: 存储键值对集合,适合存储对象属性。
- 底层结构: 基于哈希表实现。
- 应用场景: 存储对象、缓存存储、实时更新数据。
3. List(列表)
- 基本介绍: 双向链表,可进行头尾插入和删除操作。
- 底层结构: 双向链表。
- 应用场景: 消息队列、实时排行榜。
4. Set(集合)
- 基本介绍: 存储唯一值的无序集合。
- 底层结构: 基于哈希表实现。
- 应用场景: 数据去重、共同好友查找。
5. Sorted Set(有序集合)
- 基本介绍: 类似 Set,但每个元素都关联一个分数,可按分数排序。
- 底层结构: 结合了哈希表和跳跃表。
- 应用场景: 实时排行榜、范围查询。
6. HyperLogLog(基数)
- 基本介绍: 用于估算集合中的基数(基数:不重复元素的个数)。
- 底层结构: 基于概率统计算法实现。
- 应用场景: 统计UV(独立访客数)、大数据场景中的基数统计。
7. Geo(地理位置)
- 基本介绍: 存储地理空间信息,如经纬度坐标。
- 底层结构: 使用 ZSET 结构存储地理位置信息。
- 应用场景: 地理位置信息查询、附近的人功能。
8. Bitmap(位图)
- 基本介绍: 位数组,可进行位操作。
- 底层结构: 使用字符串实现。
- 应用场景: 用户在线状态统计、周/月/年签到、布隆过滤器等。
9. Streams(流)
- 基本介绍: 类似消息队列,但支持更丰富的操作。
- 底层结构: 内部使用列表和哈希表实现。
- 应用场景: 消息队列、事件日志等。
10. Bitfield(位域)
- 基本介绍: 允许用户对字符串指定偏移量的位进行操作。
- 底层结构: 使用字符串实现,支持对位进行原子级别的操作。
- 应用场景: 适用于位操作相关的需求,比如统计、压缩数据等。
2 数据类型详解
2.1 Redis位图(Bitmap)
说明:用String类型作为底层数据结构实现的一种统计二值状态的数据类型
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们称之为一个索引)。
Bitmap支持的最大位数是2^32位,它可以极大的节约存储空间,使用512M内存就可以存储多达42.9亿的字节信息(2^32 = 4294967296)

2.1.1实战演示
SETBIT key offset value //设置key的值,偏移量为offset,value只能是0或1。这个命令通常用于设置或清除位图的特定位。
GETBIT key offset //获取位图key在offset偏移量上的值。
STRLEN key //获取字符串key的长度。
BITCOUNT key [start end] //计算位图key中值为1的位的数量。
BITOP AND result key1 key2 //两个位图与运算
BITOP OR result key1 key2 //两个位图或运算
BITOP XOR result key1 key2 //两个位图异或运算,只有一个1时返回1 否则返回0 也就是相同得0不同得1
BITOP NOT result key1 //对自身完全取反SETBIT key offset value: 设置key的值,偏移量为offset,value只能是0或1。这个命令通常用于设置或清除位图的特定位。
STRLEN key: 获取字符串key的长度。
BITCOUNT key [start end]: 计算位图key中值为1的位的数量。
GETBIT key offset: 获取位图key在offset偏移量上的值。

BITOP: 这是一个Redis命令,用于对多个位图进行位运算。
BITOP AND result key1 key2 //两个位图与运算
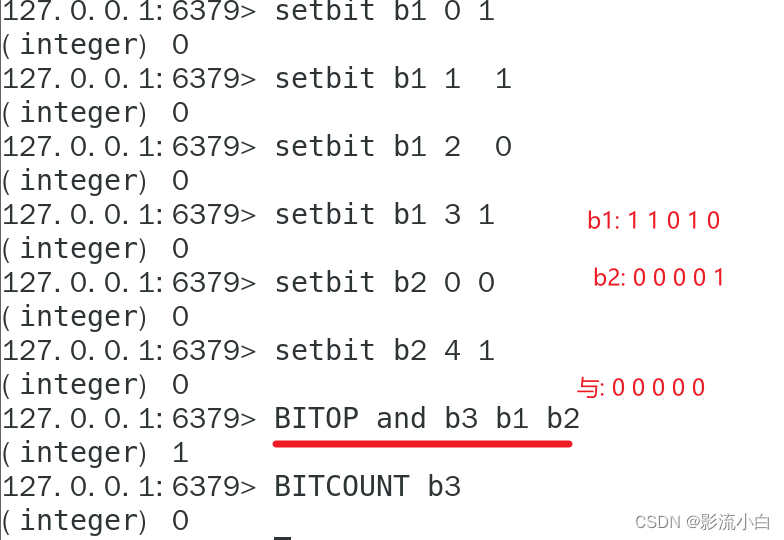
BITOP OR result key1 key2 //两个位图或运算
BITOP XOR result key1 key2 //两个位图异或运算,只有一个1时返回1 否则返回0 也就是相同得0不同得1
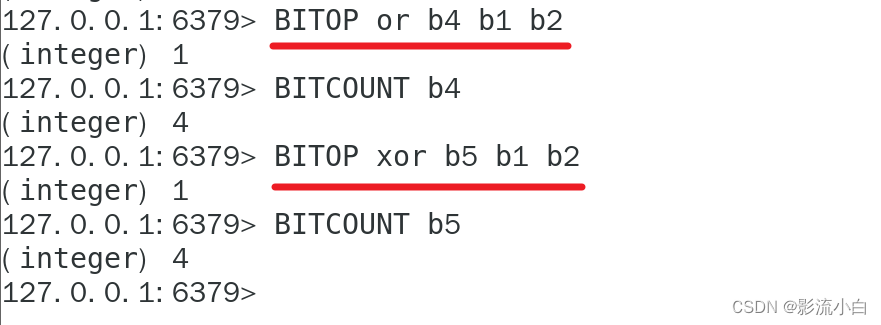
BITOP NOT result key1 //对自身完全取反

2.2.2 应用场景
签到:
对于一个用户 按年统计
setbit user01 0 1
setbit user01 1 1
......
setbit user01 364 1
这样统计也只需要 365/8 约 46字节
若是千万级用户量 一天也只需 10000000*1/1024/1024=9.5MB 内存
若是千万级用户量 一年也只需 10000000*46/1024/1024=435MB 内存
对比其他数据结构还是非常节省空间的!
2.2 Redis基数统计(HyperLogLog)
HyperLogLog是什么?
hyperloglog 只记录去重后的value的个数,属于String类型.
注意,只记录去重后的个数,而不记录数据本身.
举例:{1,1,2,2,3,4,5,6}这些数据被存入基数统计, 得到的值为 6 而不是8
更不是{1,1,2,2,3,4,5,6}
Hyperloglog的误差率:
约为0.81%
什么是基数?
数据去重后的个数统计称为基数.
2.2.1 HyperLogLog命令汇总
为什么基数统计的命令是pf开头?
答:
PF实际上是对Philippe Flajolet的致敬,他是这个算法的共同发明者之一,对概率算法和组合数学做出了巨大贡献。如何记忆?P也是概率统计(Probabilistic)的首字母,F可以视为Filter。概率过滤器是一种数据结构,用于估计一个集合中不同元素的数量,而不需要存储每个元素,只需要存储一些元素的哈希值。
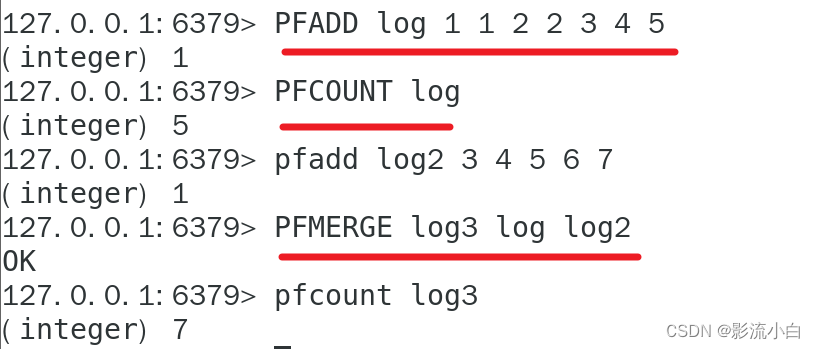
PFADD key element [element ...]
将指定的元素添加到 HyperLogLog 中。如果 HyperLogLog 不存在,这个命令会创建一个新的 HyperLogLog。
PFCOUNT key_[key ...]
返回给定 HyperLogLog 的基数估算值。如果给定的 HyperLogLog 不存在,这个命令会返回 0。
PFMERGE destkey sourcekey_[sourcekey ....]
将多个 HyperLogLog 合并为一个 HyperLogLog。如果目标 HyperLogLog 不存在,这个命令会创建一个新的 HyperLogLog。2.2.2 实战演示
-
PFADD key element [element ...]:将指定的元素添加到 HyperLogLog 中。如果 HyperLogLog 不存在,这个命令会创建一个新的 HyperLogLog。 -
PFCOUNT key_[key ...]:返回给定 HyperLogLog 的基数估算值。如果给定的 HyperLogLog 不存在,这个命令会返回 0。 -
PFMERGE destkey sourcekey_[sourcekey ....]:将多个 HyperLogLog 合并为一个 HyperLogLog。如果目标 HyperLogLog 不存在,这个命令会创建一个新的 HyperLogLog。
2.2.3应用场景
网页点击量, 广告点击量, 等等需要去重的数值统计场景
比如网页点击量 我们就可以存入ip hyperloglog就会自动的帮我们去重
非常节省空间, 完美的契合该场景
2.3 Redis地理空间(Geo)
Geo是什么?
Redis 的 GEO 数据类型通过将地理位置(经度、纬度)和位置名称(成员)存储在有序集合(Zset)中,实现了地理位置的定位。它提供了一系列的命令,可以用于添加位置、计算位置之间的距离、以及在给定的范围内搜索位置。
key 经纬度1 地点1 经纬度2 地点2
Geo如何实现的?
核心思想就是将球体转换为平面,区块转换为一点
二维变一维就是用一个哈希值来表示某成员的经纬度,方便程序员们提取和使用
geohash key member
经纬度到底是如何计算的?怎么表示?举例说明?
在 Redis 的 GEO 数据类型中,经纬度是通过浮点数来表示的。
经度(longitude)是一个在 -180 到 180 之间的浮点数,表示地球上的东西方向;
纬度(latitude)是一个在 -90 到 90 之间的浮点数,表示地球上的南北方向。
这些经纬度的值通常是通过 GPS(全球定位系统)或其他地理定位服务(如谷歌地图、百度地图等)来获取的。例如,当你在手机上使用地图应用时,应用会通过 GPS 来获取你的当前位置的经纬度。
在 Redis 中,你可以使用
GEOADD命令来将经纬度和位置名称添加到 GEO 数据类型中。例如,
GEOADD key 116.405285 39.904989 "Beijing"就是将经度 116.405285、纬度 39.904989 和位置名称 "Beijing" 添加到名为 "key" 的 GEO 数据类型中。乱码问题解决命令:
redis-cli -a 111111 --raw

2.3.1 Geo相关命令汇总
GEOADD key longitude latitude member [longitude latitude member ...]
将给定的经度、纬度、位置名称添加到指定的 key 中。
GEOPOS key member [member ...]
从键里面返回所有给定位置元素的位置(经度和纬度)。
GEODIST key member1 member2 [unit]
返回两个给定位置之间的距离。
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
以给定的经纬度为中心,返回与中心的距离不超过给定最大距离的所有位置元素。
key: 有序集合的键名。
longitude 和 latitude: 中心点的经纬度。
radius: 查找的半径,单位由 m|km|ft|mi 参数决定。
m|km|ft|mi: 半径的单位,可以是米(m)、千米(km)、英尺(ft)或英里(mi)。
WITHCOORD: 返回成员的经纬度。
WITHDIST: 返回成员与中心点的距离。
WITHHASH: 返回成员的 geohash 值。
COUNT count: 返回的成员数量。
ASC|DESC: 返回结果的排序方式,可以是升序(ASC)或降序(DESC)。
STORE key: 将结果保存到指定的有序集合。
STOREDIST key: 将结果保存到指定的有序集合,并且保存的值是成员与中心点的距离。
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
与 GEORADIUS 类似,但是以位置元素为中心。
GEOHASH key member [member ...]
返回一个或多个位置元素的 Geohash 表示。实现了二维变一维2.3.2 实战演示
GEOADD key longitude latitude member [longitude latitude member ...]:将给定的经度、纬度、位置名称添加到指定的 key 中。

GEOPOS key member [member ...]:从键里面返回所有给定位置元素的位置(经度和纬度)。

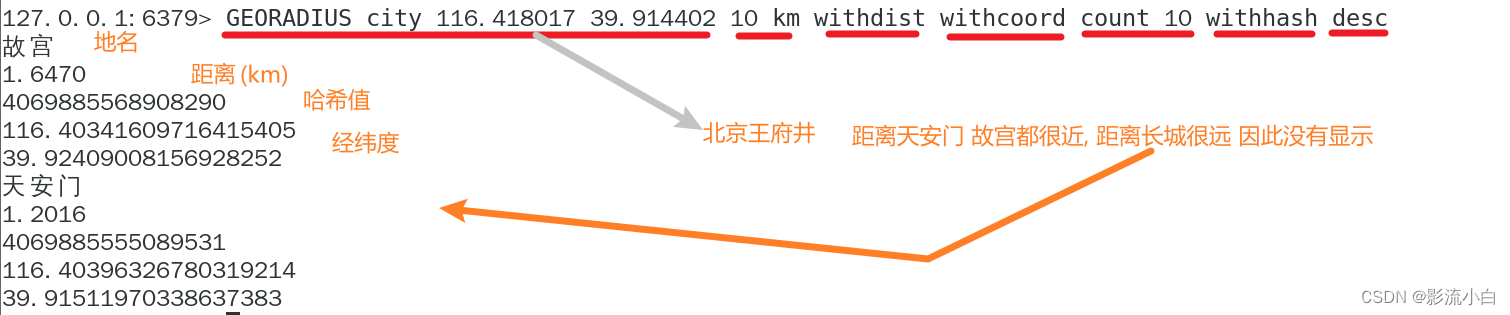
GEODIST key member1 member2 [unit]:返回两个给定位置之间的距离。不写单位默认是m

![]()
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]:以给定的经纬度为中心,返回与中心的距离不超过给定最大距离的所有位置元素。
重要方法,我们详细讲解一下(因为完美契合特定场景,比如附近的人 附近的酒店)
key: 有序集合的键名。longitude和latitude: 中心点的经纬度。radius: 查找的半径,单位由m|km|ft|mi参数决定。m|km|ft|mi: 半径的单位,可以是米(m)、千米(km)、英尺(ft)或英里(mi)。WITHCOORD: 返回成员的经纬度。就是输出时携带着结果地点的经纬度WITHDIST: 返回成员与中心点的距离。就是输出时携带着两点间距离.WITHHASH: 返回成员的 geohash 值。 就是输出时携带着结果地点的哈希值COUNT count: 返回的成员数量。就是你要找几个?ASC|DESC: 返回结果的排序方式,可以是升序(ASC)或降序(DESC)。STORE key: 将结果保存到指定的有序集合。STOREDIST key: 将结果保存到指定的有序集合,并且保存的值是成员与中心点的距离。
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]:与 GEORADIUS 类似,但是以位置元素为中心。
- 也就是把上面的命令的中心地点改为 key中的某个成员地点 换句话说 中心地点不在需要你提供经纬度了,只需要你从geo列表zset里面选一个存在的地点即可

GEOHASH key member [member ...]:返回一个或多个位置元素的 Geohash 表示。

2.3.3 应用场景
以你自身定位为中心获取该定位附近的酒店
georadius key 经度 纬度 radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
以某景点定位为中心获取该景点附近的餐馆
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
2.4 Redis流(Stream)
Redis 的流(Stream)是一种redis 5新出的数据结构,用于在 Redis 中实现消息队列。它是一个有序的消息集合,每个消息都有一个唯一的 ID,消息可以按照添加的顺序来读取,也可以按照 ID 来读取。流支持消费者组,每个消费者组可以有多个消费者,每个消费者可以读取流中的消息,消费者组可以协调消息的消费,确保每个消息只被消费一次。
总结:Redis 的流是一种有序的消息队列,支持多个消费者组,每个消费者组可以有多个消费者,消费者组可以协调消息的消费。
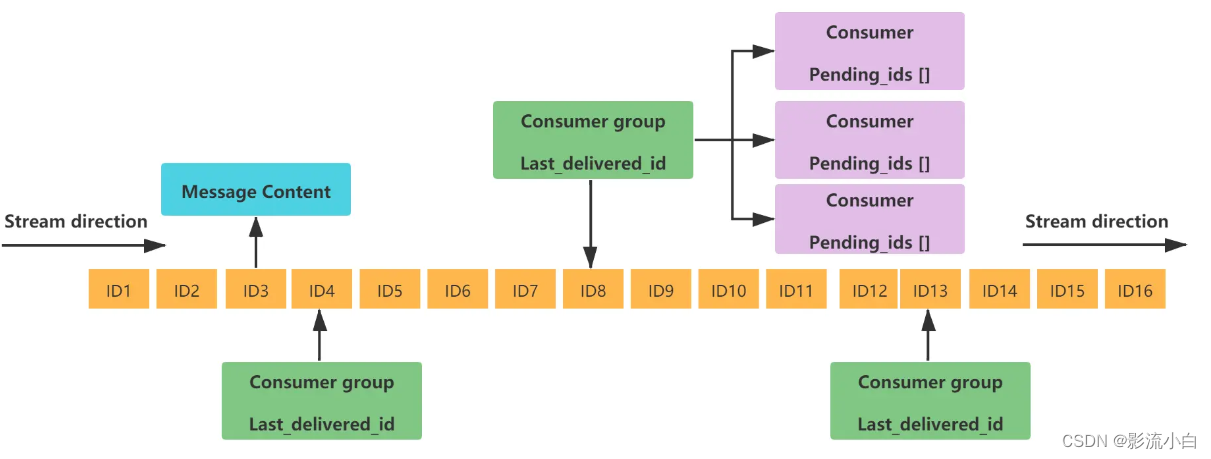
2.4.1 队列相关指令汇总
XADD 用于向 Stream 中添加新的消息。
XTRIM 用于限制 Stream 的长度,如果 Stream 的长度已经超过指定的长度,那么会进行截取。
XDEL 用于删除 Stream 中的消息。
XLEN 用于获取 Stream 中的消息数量。
XRANGE 用于获取 Stream 中的消息列表,可以指定范围。
XREVRANGE 与 XRANGE 类似,区别在于 XREVRANGE 是从大到小的顺序获取消息。
XREAD 用于获取 Stream 中的消息,可以指定阻塞或非阻塞模式。2.4.2 消费组相关指令
XGROUP CREATE 创建消费者组
XREADGROUP GROUP 读取消费者组中的消息
XACK ack消息,消息被标记为”已处理
XGROUP SETID 设置消费者组最后递送消息的ID
XGROUP DELCONSUMER 删除消费者组
XPENDING 打印待处理消息的详细信息
XCLAIM 转移消息的归属权 (长期未被处理/无法处理的消息,转交给其他消费者组进行处理)
XINFO 打印Stream\Consumer Group的详细信息
XINFO GROUPS 打印消费者组的详细信息
XINFO STREAM 打印Stream的详细信息2.4.3 四种特殊符号
- + 最小和最大可能出现的id
$ 表示只消费新的消息,当前流中最大的 id,可用于将要到来的信息
> 用于XREADGROUP命令,表示迄今还没有发送给组中使用者的信息,会更新消费者组的最后ID
* 用于XADD命令中,让系统自动生成 id2.4.4 队列指令实战演示
XADD: 将消息添加到 Redis Stream 的末尾。这个命令需要一个 Stream 的键名,一个消息的 ID(如果不提供,Redis 会自动生成),以及一个或多个字段和值。这些字段和值会被添加到消息的内容中。
id组成 : 毫秒级时间戳-当前毫秒级时间戳的第几条消息

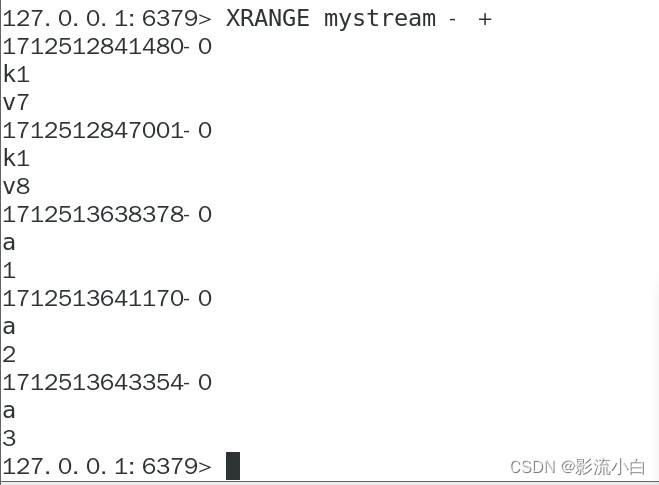
XRANGE: 获取 Redis Stream 中的消息列表。这个命令需要一个 Stream 的键名,一个最小的 ID 和一个最大的 ID。它会返回在这个范围内的所有消息。
xrange stream - + 表示按照消息从最旧的到最新的顺序输出
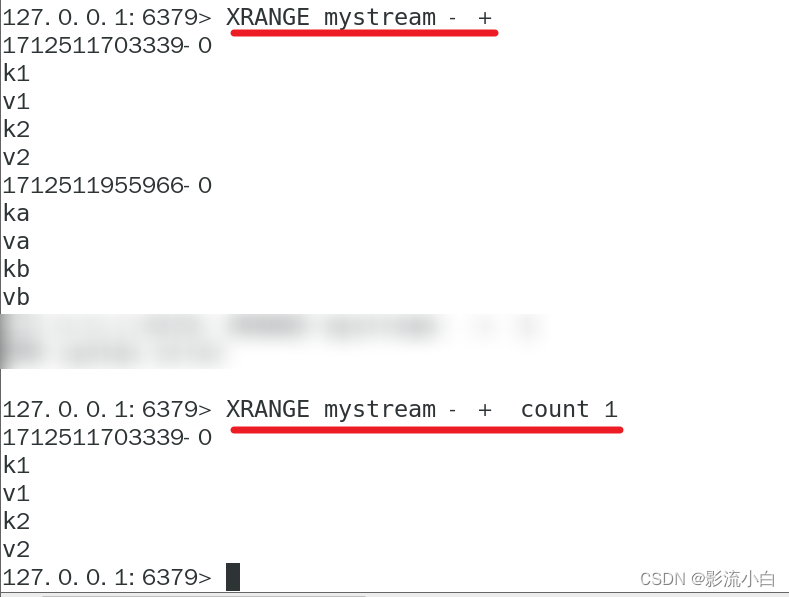
XREVRANGE: 与 XRANGE 类似,区别在于 XREVRANGE 是从大到小的顺序获取消息。
按 从新到旧的顺序输出消息:

XDEL: 从 Redis Stream 中删除一个或多个消息。这个命令需要一个 Stream 的键名,以及一个或多个消息的 ID。

XLEN: 获取 Redis Stream 中的消息数量。这个命令需要一个 Stream 的键名。
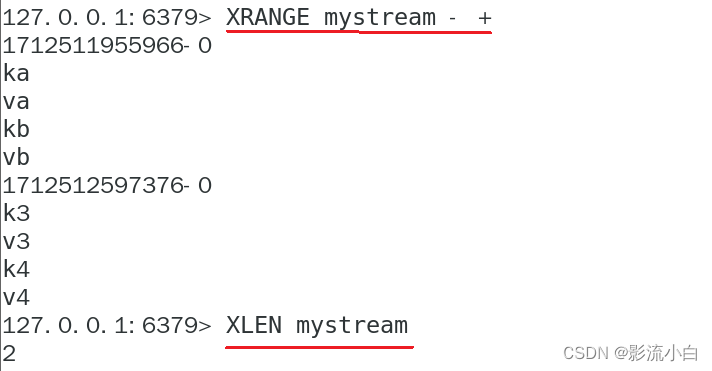
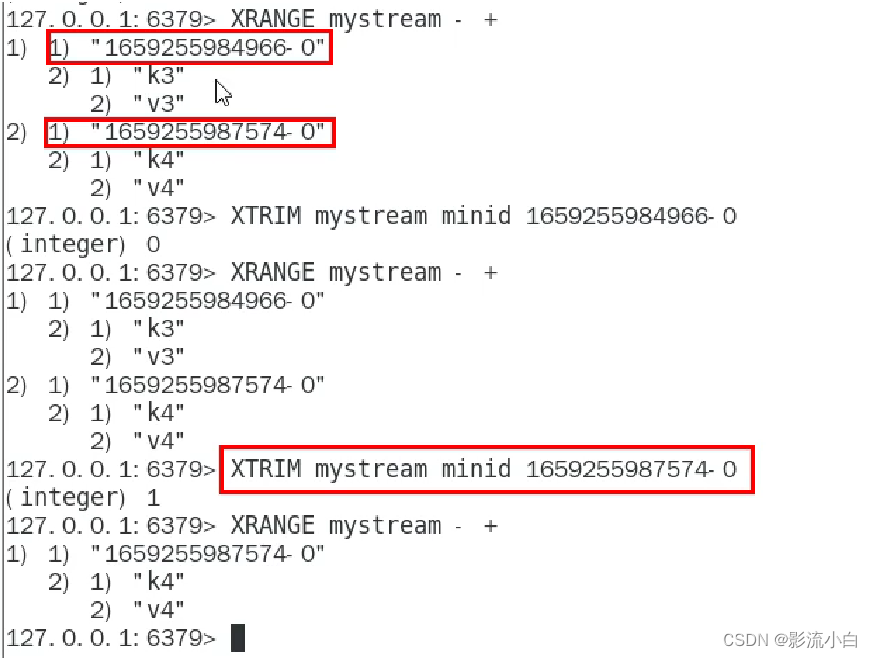
XTRIM: 限制 Redis Stream 的长度。如果 Stream 的长度已经超过指定的长度,那么会进行截取。这个命令需要一个 Stream 的键名,以及一个长度。
XTRIM key MAXLEN|MINID [=|~] threshold [LIMIT count]
key:Stream 的名字。MAXLEN|MINID:保留的消息数量或者最小的消息 ID。threshold:消息的数量或者最小的消息 ID。LIMIT count:删除的消息数量。


也可以 minid 删掉比指定id还要小的所有消息
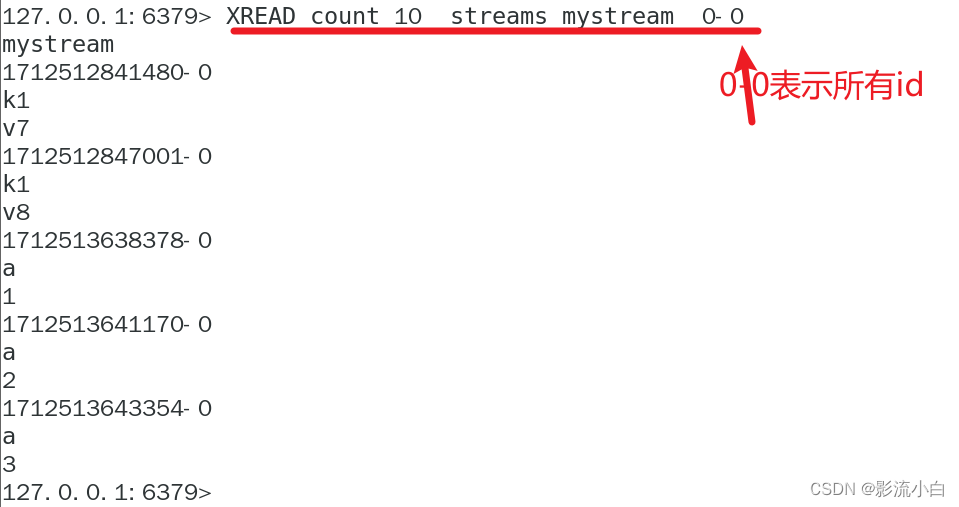
XREAD: 获取 Redis Stream 中的消息。这个命令需要一个或多个 Stream 的键名,以及一个或多个消息的 ID。它会返回在这些 Stream 中的所有消息。
XREAD [COUNT count] [BLOCK milliseconds] STREAMS stream-name ID [ID ...]
COUNT count:这个参数用于限制返回的消息数量。如果没有指定,那么XREAD会返回所有可用的消息。BLOCK milliseconds:这个参数用于设置阻塞的时间。如果没有指定,那么XREAD会立即返回。如果设置为 0,那么XREAD会一直阻塞,直到有新的消息可用。STREAMS stream-name ID [ID ...]:这个参数用于指定要读取的 Stream 和消息的 ID。ID [ID ...]是一个或多个消息的 ID。如果ID是>,那么XREAD会返回所有可用的消息。如果ID是0,那么XREAD会返回所有消息。
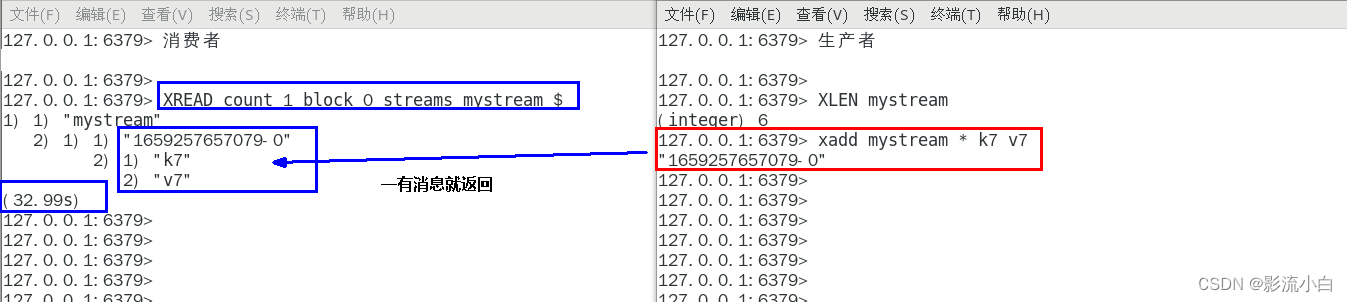
使用$ 来获取比当前消息队列中最大id还要大 的消息(一般要配合阻塞使用)

若 使用$的同时使用阻塞 则可以实时的获取最新消息
获取所有消息
2.4.5 消费者相关指令实战演示
XGROUP CREATE:用于创建消费者组。
XGROUP CREATE mystream groupA $ 表示从最新的消息开始消费
XGROUP CREATE mystream groupB 0 表示从最旧的消息开始消费

XREADGROUP:消费组 groupA 内的消费者 consumer1 从 mystream 消息队列中读取所有消息。
XREADGROUP GROUP groupA consumer1 STREAMS mystream >
这个命令会让 groupA 内的 consumer1 从 mystream Stream 中读取所有消息。
注意这个groupA是从最旧的消息开始读的
如果是从最新消息开始读,可能因为没有更新的消息而没反应.

若不加控制 ,队列中的所有消息被某消费者读取完毕后,其他消费者无法再读取里面的消息,因为此时游标已经到了队尾
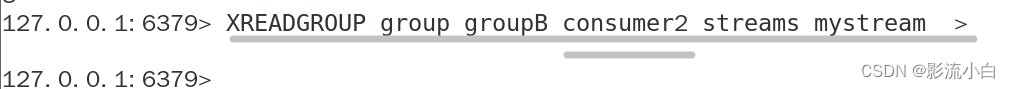
但是不同消费组的消费者 可以 读取同一个消息

同组内,可以让每个消费者均衡读取消息,实现消息均衡
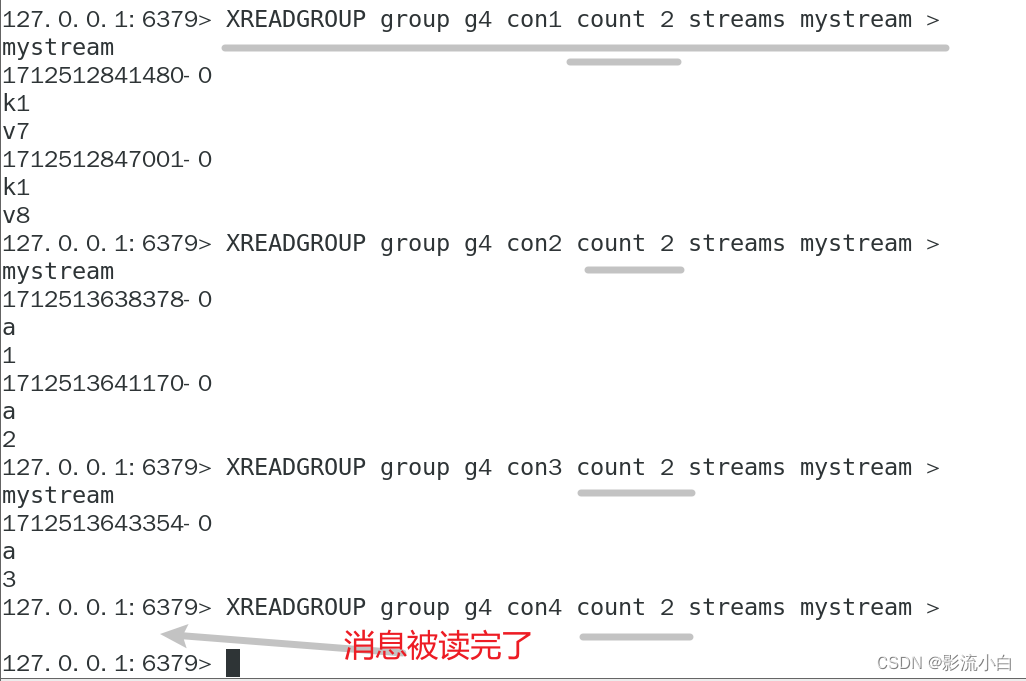
XPENDING:查询每个消费者组内所有消费者[已读取、但尚未确认]的消息。
XPENDING mystream groupA
这个命令会查询 groupA 消费者组内所有消费者已读取、但尚未确认的消息。

查询group中指定消费者 已读取但未确认的消息
返回值包括
- 消息ID:每条消息的唯一标识符。
- 消费者名称:消息被哪个消费者读取。
- 已过去的毫秒数:消息被读取后,到现在已经过去的时间(毫秒)。
- 传递计数:消息被传递(即读取)的次数。
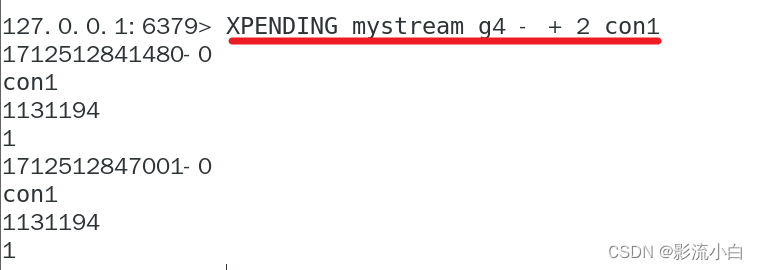
XACK:向消息队列确认消息处理已完成。
XACK mystream groupA 1600000000000-0
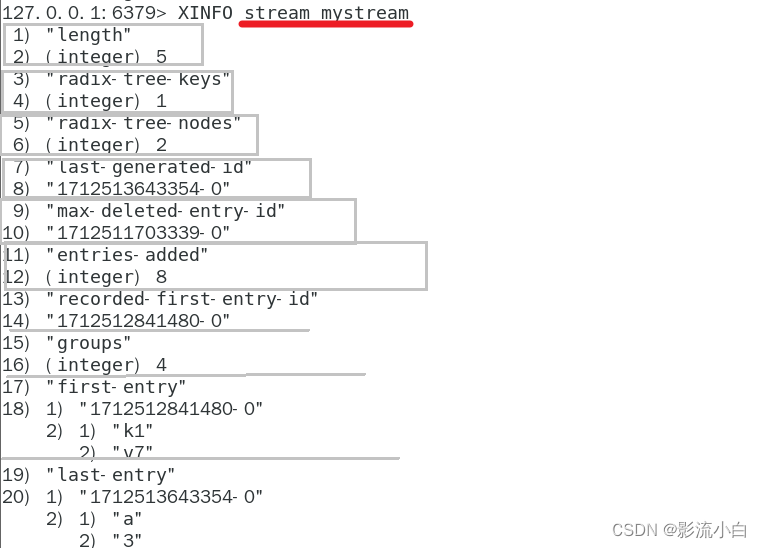
XINFO stream stream1
通过 XINFO STREAM stream1 命令,可以获取有关名为 stream1 的 Stream 的详细信息,这些信息包括:
- Length(长度):Stream 中消息的数量。
- Radix tree keys(基数树键):基数树的键数量。基数树是用于快速查找消息的数据结构。
- Radix tree nodes(基数树节点):基数树的节点数量。
- Groups(消费组):订阅 Stream 的消费组的数量。
- Last generated ID(最后生成的 ID):Stream 中最新消息的 ID。
- First entry offset(第一个条目的偏移量):Stream 中第一个消息的偏移量。
- Last entry offset(最后一个条目的偏移量):Stream 中最后一个消息的偏移量。
- Memory usage(内存使用量):Stream 占用的内存量。
2.5 Redis位域(bitfield)
该类型 了解即可
位域是什么?
位域(bitfield)是Redis中用于对字符串中的位进行操作的命令(把字符串看做位数组),提供了灵活的位级别数据处理功能。
2.5.1 bitfield命令汇总
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]
语法解析
- key: 操作的键名。
- GET type offset: 获取位字段的一部分。
type是位字段的类型,表示操作的位数和是否是有符号整数,格式为[u]int<size>,例如u8表示无符号的 8 位整数,i8表示有符号的 8 位整数。offset是位的偏移量,表示从哪个位开始操作。 - SET type offset value: 设置位字段的一部分。参数与
GET类似,value是要设置的值。 - INCRBY type offset increment: 增加位字段的一部分的值。
increment是要增加的值,可以是负数。 - OVERFLOW WRAP|SAT|FAIL: 指定溢出行为。
WRAP表示环绕(默认行为),SAT表示饱和(达到最大或最小值时停止),FAIL表示操作失败。
参数填写
- type: 必须是
[u]int<size>格式,其中size可以是任何从 1 到 64 的整数,表示操作的位数。 - offset: 是位的偏移量,可以是正数或负数。正数表示从左边开始的偏移量,负数表示从右边开始的偏移量。
- value: 是
SET操作要设置的值。 - increment: 是
INCRBY操作要增加的值。
命令作用
BITFIELD命令允许你在一个字符串值中执行多种位操作,包括获取位字段、设置位字段、增加位字段的值,以及指定溢出行为。- 这个命令非常适合用于位图操作,比如统计、标记等场景,因为它可以非常灵活地操作位,而不需要先获取值,修改后再设置回去。
BITFIELD通过提供原子操作,可以在不锁定整个数据库的情况下,对位进行高效的并发修改。
示例
假设你想在一个名为 mykey 的键上执行以下操作:
- 设置一个无符号的 8 位整数在偏移量 0 的位置。
- 增加在偏移量 0 的无符号 8 位整数的值,增加 1。
- 获取在偏移量 0 的无符号 8 位整数的值。
命令如下:
BITFIELD mykey SET u8 0 100 INCRBY u8 0 1 GET u8 02.5.2 实战演示
- BITFIELD key [GET type offset]
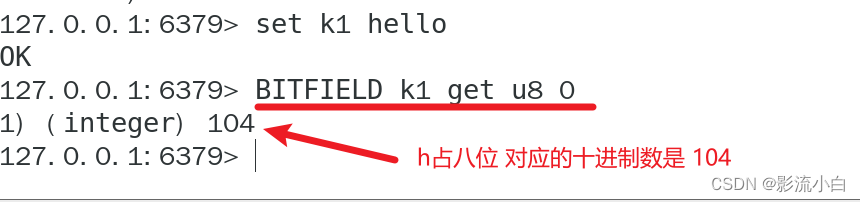 2.BITFIELD key [SET type offset value]
2.BITFIELD key [SET type offset value]

3.BITFIELD key [INCRBY type offset increment]

溢出问题:
1.Wrap溢出策略(默认策略)
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]
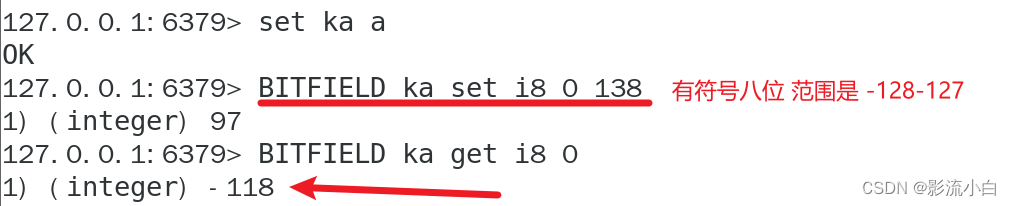
为什么会变成-118呢?
因为bitfield溢出时默认使用wrap策略,WRAP 溢出策略会将超出的值“包裹”回到这个范围内。
更具体的原因如下:
在二进制中,138 的表示超出了有符号 8 位整数的上限。具体来说:
- 无符号 8 位整数的 138 表示为二进制的
10001010。 - 对于有符号 8 位整数,最高位(左边第一位)是符号位,
0表示正数,1表示负数。 - 当你尝试将
10001010作为有符号整数解释时,由于最高位是1,它被解释为负数。 - 在有符号整数中,负数通常使用补码形式表示。补码的计算方法是取反加一。但在这里,我们是从二进制直接解读为负数,所以我们直接看结果。
将 10001010 直接按照有符号 8 位整数解读,它代表的是 -118,因为:
- 最高位为 1,表示这是一个负数。
- 剩余的位
0001010转换为十进制是 10。 - 根据补码表示,
10001010实际上是 -128 + 10 = -118。
也可以先转为反码 再转为原码来计算
反码: 10001010 - 1 = 10001001
原码 : 反码取反(符号位不参与): 1 1110110
最高位为1 表示负数 因此结果为 -(64+32+16+4+2)=-118
2.SAT溢出策略
BITFIELD key OVERFLOW SAT [SET type offset value] [INCRBY type offset increment]

3.Fail溢出策略
BITFIELD key OVERFLOW Fail [SET type offset value] [INCRBY type offset increment]

至此,Redis7 基础篇 Redis十大数据类型就讲解完毕了.
















 2227
2227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











