







## nodejs 制作网络爬虫,实现爬取浙江农林大学官网的新闻 ##
由于最近一直在研究nodejs ,所以便萌生了制作网络爬虫的想法,本人是浙农林的一个学生,自然便将官网当作是一个实验对象,那么话不多说,直接入正题:
首先我们需要预装 nodejs,下载地址为https://nodejs.org/en/download/ 。本人采取用的ide为webstorm,让我们打开终端,cd到当前目录,新建一个js页面。
爬虫所用到的模块为http,cheerio,fs,request,
node 自带fs和http;直接引入即可,cheerio和request
通过npm即可安装
var http = require('http');
var fs = require('fs');
var cheerio = require('cheerio');
var request = require('request');下面开始:
//设置一个变零url,地址为浙江农林大学官网的某条新闻。可以自己点进去看,不过稍后我也会进行分析;
var url = 'http://news.zafu.edu.cn/articles/75/30247/';
//调用http木块的get请求方法
http.get(url, function(res){
var html = '';
res.on('data', function(data){
html += data;
})
res.on('end',function(){
console.log(html);
})
}).on('error', function(){
console.log('爬取页面错误');
});示例中首先引用了 nodejs 的核心模块 http 和提供了爬取路径,然后通过 http 中的 get 接口给 url 发送 get 请求,最后在回调函数中对请求回来的数据进行处理。
这时候,我们就可以在控制台中看到网页对应源码的输出,请务必动手尝试。
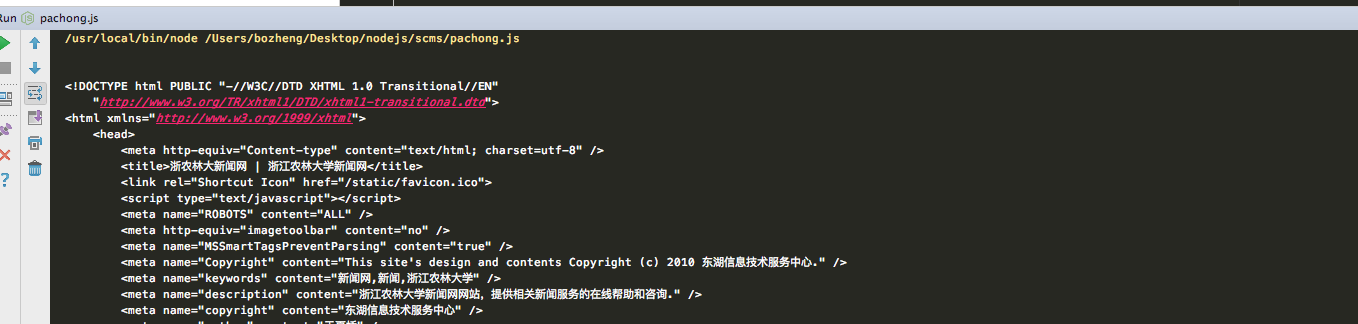
接下来我们来分析一下这张网页的html结构,看下图
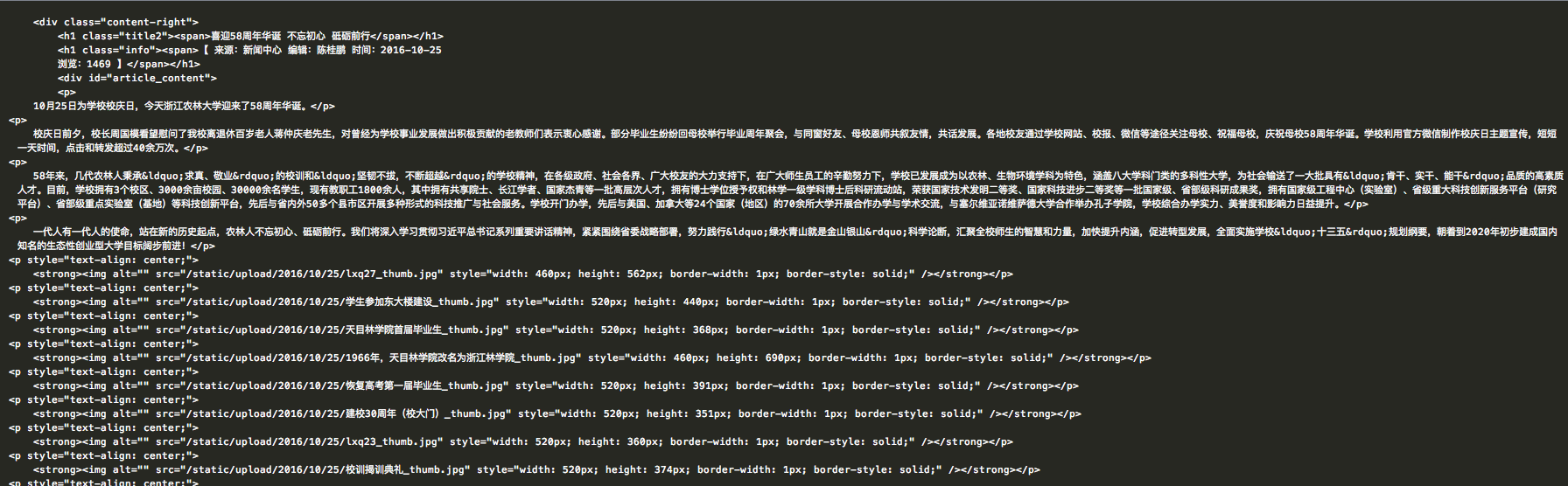
我们要做的是取到该页面文章的标题(title),信息(info),以及内容(content)和图片,分别讲文字内容和图片内容存储到本地。
我们先来处理文字内容:
为了是代码清晰,我们打算新建一个名为getContent的函数来进行对内容的操作:
function getContent(html){
var $ = cheerio.load(html);
var title = $('.title2').text().trim();
var come = $('.info').text().trim();
var pages = $('#article_content').find('p');
console.log(title)
console.log(come);
var x = ''
pages.map(function(node){
var page= $(this).text().trim();
x = x+ page+'/n';
console.log(page)
})
}
函数创建成功后,我们将其放到上文的end方法中
res.on('end',function(){
getContent(html)
})解析:首先通过cheerio的 load 方法把html加载;然后通过cheerio对文档进行操作获取文章的标题,信息和内容,再通过 map 对获取到的段落进行遍历段落。分别输出其中的内容来验证成功获取。代码运行成功后,出现一下结果

这样我们就已经成功获取到了想要的内容,接下来要做的是将信息保存到本地
我们将新建一个saveContent 的函数来进行操作:
function savedContent(news_title,x) {
var local = '/Users/bozheng/Desktop/nodejs/data/' ;//此处为你想要保存的文件目录
fs.appendFile(local + news_title + '.txt', x, 'utf-8', function (err) {
if (err) {
console.log(err);
}
console.log('success')
});
}将该方法加入到getContent的末尾,即更新为:
function getContent(html){
var $ = cheerio.load(html);
var title = $('.title2').text().trim();
var come = $('.info').text().trim();
var pages = $('#article_content').find('p');
console.log(title)
console.log(come);
var x = ''
pages.map(function(node){
var page= $(this).text().trim();
x = x+ page+'/n';
console.log(page)
})//讲段落连接
savedContent(title,x);
}这里我们就传了两个参数,标题和内容。
解析:
saveContent 方法将内容通过fs模块的appenFile方法,传入到本地的目录中,并创建对应格式的文件。这时运行js文件,我们就可以在目录中得到想要的文件。到此,我们就已经完成了文字内容的保存。
接下来我们进行图片内容的保存:
function saveImg($,news_title){
var imgs = $('strong>img');
console.log(imgs.length);
var i = 0;
imgs.each(function(){
var imgsrc = 'http://news.zafu.edu.cn'+$(this).attr('src');
imgsrc = encodeURI(
imgsrc
)
request.head(imgsrc
,function(err,res,body){
if(err){
return console.log(err);
}
});
request(imgsrc).pipe(fs.createWriteStream('/Users/bozheng/Desktop/nodejs/imgs/'+i+'.jpg'));
i++;
})
}将上述方法加入到getContent的末尾,即更新为:
function getContent(html){
var $ = cheerio.load(html);
var title = $('.title2').text().trim();
var come = $('.info').text().trim();
var pages = $('#article_content').find('p');
console.log(title)
console.log(come);
var x = ''
pages.map(function(node){
var page= $(this).text().trim();
x = x+ page+'/n';
console.log(page)
})
savedContent(title,x)
saveImg($,title)
}
现在,我们便可以在图片目录下,看到我们所保存下来的图片了

大功告成!















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









