







可以有控制台输入:https://www.onlinegdb.com/
可以很强:https://godbolt.org/
vector 动态数组
用 new 创建动态数组的替代品
 vector 包含在头文件< vector >中:
vector 包含在头文件< vector >中:
#include <vector>
在此头文件内,类型 vector 是一个定义于 namespace std 内的 template:
namespace std {
template <typename T,
typename Allocator = allocator<T> >
class vector;
}
模板类 vector 类似于 string 类,也是一种动态数组。可以在运行阶段设置 vector 对象的长度,可在末尾附加新数据,还可以在中间插入新数据。
vector 构造
| 操作 | 描述 |
|---|---|
| vector< Elem > c | Default 构造函数,产生一个空 vector,没有任何元素 |
| vector< Elem > c(c2) | Copy 构造函数,建立 c2 的同型 vector 并成为 c2 的一份铂贝(所有元素都被复制) |
| vector< Elem > c = c2 | Copy 构造函数,建立一个新的 vector 作为 c2 的拷贝(每个元素都被复制) |
| vector< Elem > c = rv | Move 构造函数,建立一个新的 vector,取 rvalue rv 的内容(始自C++11) |
| vector< Elem > c(n) | 利用元素的 default 构造函数生成一个大小为 n 的 vector |
| vector< Elem > c(n, elem) | 建立一个大小为 n 的 vector,每个元素值都是 elem |
| vector< Elem > c(beg, end) | 建立一个 vector,以区间 [beg, end) 作为元素初值 |
| vector< Elem > c(initlist) | 建立一个 vector,以初值列 initlist 的元素为初值(始自C++11) |
| vector< Elem > c = initlist | 建立一个 vector,以初值列 initlist 的元素为初值(始自C++11) |
| c.~vector() | 销毁所有元素,释放内存 |
#include <iostream>
#include <vector>
using namespace std;
int main(){
vector<int> c;//创建一个空vector
vector<int> c1(20);//创建一个大小为20的vector
vector<int> c2(20, 1);//创建一个大小为20,每个元素值都是1的vector
int n = 10;
vector<int> c3(n);//创建一个大小为n的vector
int a[5] = {1, 2, 3, 4, 5};
vector<int> c4(a, a + 5);//复制[a, a + 5)之间的元素到vector
vector<int> c5{1, 2, 3, 4, 5};
vector<int> c6 = {1, 2, 3, 4, 5};
vector< vector<int> > c7(8, vector<int> (12, 0));//二维数组
return 0;
}
vector 非更易型操作
| 操作 | 描述 |
|---|---|
| c.empty() | 返回是否容器为空(相当于 size() == 0 但也许较快) |
| c.size() | 返回目前的元素个数 |
| c.max_size() | 返回元素个数之最大可能量 |
| c.capacity() | 返回 “不进行空间重新分配” 条件下的元素最大容纳量 |
| c.reserve(num) | 如果容量不足,扩大之 |
| c.shrink_to_fit() | 要求降低容量,以符合元素个数(始自C++11) |
| c1 == c2 | 返回 c1 是否等于 c2(对每个元素调用==) |
| c1 != c2 | 返回 c1 是否不等于 c2(相当于!(c1==c2)) |
| c1 < c2 | 返回 c1 是否小于 c2 |
| c1 > c2 | 返回 c1 是否大于 c2(相当于 c2 < c1) |
| c1 <= c2 | 返回 c1 是否小于等于 c2(相当于 !(c2<c1)) |
| c1 >= c2 | 返回 c1 是否大于等于 c2(相当于 !(c1<c2)) |
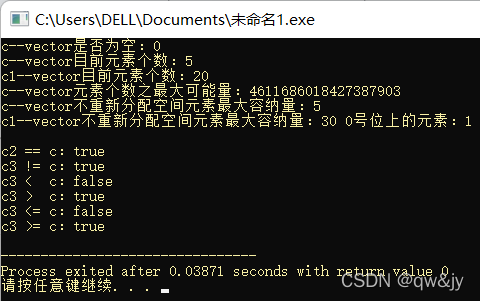
#include <iostream>
#include <vector>
using namespace std;
int main(){
int a[7] = {1, 2, 3, 4, 5, 6, 7};
vector<int> c(a, a + 5);//复制[a, a + 5)之间的元素到vector
vector<int> c1(20);
c1[0] = 1;
vector<int> c2(a, a + 5);
vector<int> c3(a + 1, a + 6);
printf("c--vector是否为空:%d\n", c.empty());
printf("c--vector目前元素个数:%d\n", c.size());
printf("c1--vector目前元素个数:%d\n", c1.size());
printf("c--vector元素个数之最大可能量:%lld\n", c.max_size());
printf("c--vector不重新分配空间元素最大容纳量:%d\n", c.capacity());
c1.reserve(30);
printf("c1--vector不重新分配空间元素最大容纳量:%d 0号位上的元素:%d\n\n", c1.capacity(), c1[0]);
printf("c2 == c:%s\n", c2 == c ? "true" : "false");
printf("c3 != c:%s\n", c3 != c ? "true" : "false");
printf("c3 < c:%s\n", c3 < c ? "true" : "false");
printf("c3 > c:%s\n", c3 > c ? "true" : "false");
printf("c3 <= c:%s\n", c3 <= c ? "true" : "false");
printf("c3 >= c:%s\n", c3 >= c ? "true" : "false");
return 0;
}
vector 赋值
| 操作 | 描述 |
|---|---|
| c = c2 | 将 c2 的全部元素赋值给 c |
| c = rv | 将 rvalue rv 的所有元素以 move assign 方式给予 c(始自C++11) |
| c = initlist | 将初值列 initlist 的所有元素赋值给 c(始自C++11) |
| c.assign(n, elem) | 复制 n 个 elem,赋值给 c |
| c.assign(beg, end) | 将区间 [beg, end) 内的元素赋值给 c |
| c.assign(initlist) | 将初值列 initlist 的所有元素赋值给 c |
| c1.swap(c2) | 置换 c1 和 c2 的数据 |
| swap(c1, c2) | 置换 c1 和 c2 的数据 |
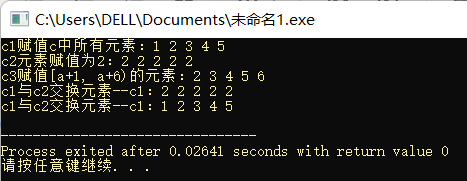
#include <iostream>
#include <vector>
using namespace std;
int main(){
int a[7] = {1, 2, 3, 4, 5, 6, 7};
vector<int> c(a, a + 5);//复制[a, a + 5)之间的元素到vector
vector<int> c1(5);
vector<int> c2(5);
vector<int> c3(5);
c1 = c;
printf("c1赋值c中所有元素:");
for(int i = 0; i < c1.size(); i ++)
printf("%d ", c1[i]);
printf("\n");
c2.assign(5, 2);
printf("c2元素赋值为2:");
for(int i = 0; i < c2.size(); i ++)
printf("%d ", c2[i]);
printf("\n");
c3.assign(a+1, a+6);
printf("c3赋值[a+1, a+6)的元素:");
for(int i = 0; i < c3.size(); i ++)
printf("%d ", c3[i]);
printf("\n");
c1.swap(c2);
printf("c1与c2交换元素--c1:");
for(int i = 0; i < c1.size(); i ++)
printf("%d ", c1[i]);
printf("\n");
swap(c1, c2);
printf("c1与c2交换元素--c1:");
for(int i = 0; i < c1.size(); i ++)
printf("%d ", c1[i]);
printf("\n");
return 0;
}
123456789101112131415161718192021222324252627282930313233343536373839404142
vector 元素访问
| 操作 | 描述 |
|---|---|
| c[idx] | 返回索引 idx 所指的元素(不检查范围) |
| c.at(idx) | 返回索引 idx 所指的元素(如果 idx 超出范围就抛出 range-error 异常) |
| c.front() | 返回第一元素(不检查是否存在第一元素) |
| c.back() | 返回最末元素(不检查是否存在最末元素) |
vector 安插和移除元素
| 操作 | 描述 |
|---|---|
| c.push_back(elem) | 附加一个 elem 的拷贝于末尾 |
| c.pop_back() | 移除最后一个元素,但是不返回它 |
| c.insert(pos, elem) | 在 iterator 位置 pos 之前方插入一个 elem 拷贝,并返回新元素的位置 |
| c.insert(pos, n, elem) | 在 iterator 位置 pos 之前方插入 n 个 elem 拷贝,并返回第一个新元素的位置(或返回 pos———如果没有新元素的话) |
| c.insert(pos, beg, end) | 在 iterator 位置 pos 之前方插入区间 [beg, end) 内所有元素的一份铂贝,并返回第一个新元素的位置(或返回pos——如果没有新元素的话) |
| c.insert(pos, initlist) | 在 iterator 位置 pos 之前方插入初值列 initlist 内所有元素的一份拷贝,并返回第一个新元素的位置(或返回 pos——如果没有新元素的话;始自C++11) |
| c,emplace(pos, args…) | 在 iterator 位置 pos 之前方插入一个以 args 为初值的元素,并返回新元素的位置(始自C++11) |
| c.emplace_back(args…) | 附加一个以 args 为初值的元素于末尾,不返回任何东西(始自C++11) |
| c.erase(pos) | 移除 iterator 位置 pos 上的元素,返回下一元素的位置 |
| c.erase(beg, end) | 移除 [beg, end) 区间内的所有元素,返回下一元素的位置 |
| c.resize(num) | 将元素数量改为 num(如果 size() 变大,多出来的新元素都需以 default 构造函数完成初始化) |
| c.resize(num, elem) | 将元素数量改为 num(如果 size() 变大,多出来的新元素都是 elem 的拷贝) |
| c.clear() | 移除所有元素,将容器清空 |
| c.begin() | 返回一个 random-access iterator 指向第一元素 |
| c.end() | 返回一个 random-access iterator 指向最末元素的下一位置 |
| c.cbegin() | 返回一个 const random-access iterator 指向第一元素(始自C++11) |
| c.cend() | 返回一个 const random-access iterator 指向最末元素的下一位置(始自C++11) |
| c.rbegin() | 返回一个反向的 (reverse)iterator 指向反向迭代的第一元素 |
| c.rend() | 返回一个反向的 (reverse) iterator 指向反向迭代的最末元素的下一位置 |
| c.crbegin() | 返回一个 const reverse iterator 指向反向迭代的第一元素(始自C++11) |
| c.crend() | 返回一个 const reverse iterator 指向反向迭代的最末元素的下一位置(始自C++11) |
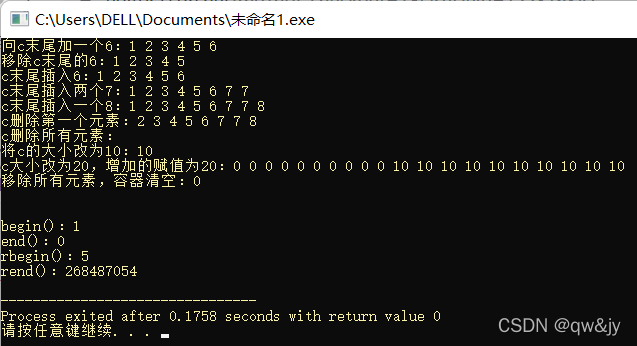
#include <iostream>
#include <vector>
using namespace std;
int main(){
int a[8] = {1, 2, 3, 4, 5, 6, 7, 8};
vector<int> c(a, a + 5);//复制[a, a + 5)之间的元素到vector
vector<int> c1(5);
vector<int> c2(5);
vector<int> c3(5);
c.push_back(6);
printf("向c末尾加一个6:");
for(int i = 0; i < c.size(); i ++)
printf("%d ", c[i]);
printf("\n");
c.pop_back();
printf("移除c末尾的6:");
for(int i = 0; i < c.size(); i ++)
printf("%d ", c[i]);
printf("\n");
c.insert(c.end(), 6);
printf("c末尾插入6:");
for(int i = 0; i < c.size(); i ++)
printf("%d ", c[i]);
printf("\n");
c.insert(c.end(), 2, 7);
printf("c末尾插入两个7:");
for(int i = 0; i < c.size(); i ++)
printf("%d ", c[i]);
printf("\n");
c.insert(c.end(), a + 7, a + 8);
printf("c末尾插入一个8:");
for(int i = 0; i < c.size(); i ++)
printf("%d ", c[i]);
printf("\n");
c.erase(c.begin());
printf("c删除第一个元素:");
for(int i = 0; i < c.size(); i ++)
printf("%d ", c[i]);
printf("\n");
c.erase(c.begin(), c.end());
printf("c删除所有元素:");
for(int i = 0; i < c.size(); i ++)
printf("%d ", c[i]);
printf("\n");
c.resize(10);
printf("将c的大小改为10:%d\n", c.size());
c.resize(20, 10);
printf("c大小改为20,增加的赋值为20:");
for(int i = 0; i < c.size(); i ++)
printf("%d ", c[i]);
printf("\n");
c.clear();
printf("移除所有元素,容器清空:%d\n", c.size());
for(int i = 0; i < 5; i ++)
c.push_back(i + 1);
printf("\n\nbegin():%d\n", *c.begin());
printf("end():%d\n", *c.end());
printf("rbegin():%d\n", *c.rbegin());
printf("rend():%d\n", *c.rend());
return 0;
}
string 字符数组
在很多方面,使用 string 对象的方式与使用字符数组相同。
- 可以使用 C 风格字符串来初始化 string 对象。
- 可以使用 cin 来将键盘输入存储到 string 对象中。
- 可以使用 cout 来显示 string 对象。
- 可以使用数组表示法来访问存储在 string 对象中的字符。
构造
| 方法 | 描述 |
|---|---|
| string(const char *s) | 将 string 对象初始化为 s 指向的 NBTS |
| string(size_type n, char c) | 创建一个包含 n 个元素的 string 对象,其中每个元素都被初始化为字符 c |
| string(const string &str) | 将一个 string 对象初始化为 string 对象 str(复制构造函数) |
| string() | 创建一个默认的 string 对象,长度为 0(默认构造函数) |
| string(const char *s, size_type n) | 将 string 对象初始化为 s 指向的 NBTS 的前 n 个字符,即使超过了 NBTS 结尾 |
| template string(Iter begin, Iter end) | 将 string 对象初始化为区间 [begin,end) 内的字符,其中 begin 和 end 的行为就像指针,用于指定位置,范围包括 begin 在内,但不包括 end |
| string(const string &str, string size_type pos = 0, size_type n = npos) | 将一个 string 对象初始化为对象 str 中从位置 pos 开始到结尾的字符,或从位置 pos 开始的 n 个字符 |
| string(string &&str) noexcept | C++11 新增,它将一个 string 对象初始化为 string 对象 str,并可能修改 str(移动构造函数) |
| string(initializer_list il) | C++11 新增,它将一个 string 对象初始化为初始化列表 il 中的字符 |
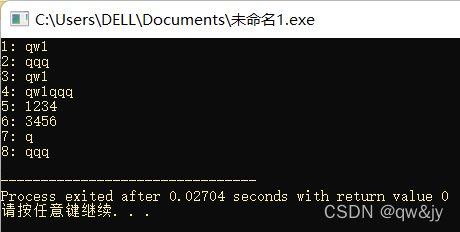
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str1("qw1");//#case1
cout << "1: " << str1 << endl;
string str2(3, 'q');//#case2
cout << "2: " << str2 << endl;
string str3(str1);//#case3
cout << "3: " << str3 << endl;
string str4;//#case4
str4 = str1 + str2;
cout << "4: " << str4 << endl;
char s5[] = "123456789";
string str5(s5, 4);//#case5
cout << "5: " << str5 << endl;
string str6(s5 + 2, s5 + 6);//#case6 也可以用string str6(&s5[2], &s5[5]);
cout << "6: " << str6 << "\n";
string str7(str4, 3, 1);//#case7
cout << "7: " << str7 << endl;
string str8(str4, 3);//#case7
cout << "8: " << str8 << endl;
return 0;
}
构造函数 string(string &&str) 类似于复制构造函数,导致新创建的 string 为 str 的副本。但于复制构造函数不同的是,它不保证将 str 视为 const。
构造函数 string(initializer_list il) 能够将列表初始化语法用于 string 类。如下所示是合法的:
string str1 = {'q', 'w', 'j', 'y'};
string str2 = {'1', '2', '3', '4'};
数据方法
| 方法 | 返回值 |
|---|---|
| begin() | 指向字符串第一个字符的迭代器 |
| cbegin() | 一个 const_iterator,指向字符串中的第一个字符(C++11) |
| end() | 为超尾值的迭代器 |
| cend() | 为超尾值得 const_interator(C++11) |
| rbegin() | 为超尾值的反转迭代器 |
| crbegin() | 为超尾值的反转 const_interator(C++11) |
| rend() | 指向第一个字符的反转迭代器 |
| crend() | 指向第一个字符的反转 const_interator(C++11) |
| size() | 字符串中的元素数,等于 begin() 到 end() 之间的距离 |
| length() | 与 size() 相同 |
| capacity() | 给字符串分配的元素数。这可能大于实际的字符数,capacity() - size() 的值表示在字符串末尾附加多少字符后需要分配更多的内存 |
| max_size() | 字符串的最大长度 |
| data() | 一个指向数组第一个元素的 const charT* 指针,其第一个 size() 元素等于 *this 控制的字符串中对应的元素,其下一个元素为 charT 类型的 char(0) 字符(字符串末尾标记)。当 string 对象本身被修改后,该指针可能无效 |
| c_str() | 一个指向数组第一个元素的 const charT* 指针,其第一个 size() 元素等于 *this 控制的字符串中对应的元素,其下一个元素是 charT 类型的 char T(0) 字符(字符串尾标识)。当 string 对象本身被修改后,该指针可能无效 |
| get_allocator() | 用于为字符串 object 分配内存的 allocator 对象的副本 |
| 内存方法 | 描述 |
|---|---|
| void resize(size_type n) | 如果 n>npos,将引发 out_of_range 异常;否则,将字符串的长度改为 n,如果 n<size(),则截短字符串,如果 n>size(),则使用 charT(0) 中的字符填充字符串 |
| void resize(size_type n, charT c) | 如果 n>npos,将引发 out_of_range 异常;否则,将字符串的长度改为 n,如果 n<size(),则截短字符串,如果 n>size(),则使用字符 c 填充字符串 |
| void reserve(size_type res_arg = 0) | 将 capacity() 设置为大于或等于 res_arg。由于这将重新分配字符串,因此以前的引用、迭代器和指针将无效 |
| void shrink_to_fit() | C++11新增,请求让 capacity() 的值与 size() 相同 |
| void clear() noexcept | 删除字符串中所有字符 |
| bool empty() const noexcept | 如果 size() == 0,则返回 0 |
字符串存取
| 数据方法 | 描述 |
|---|---|
| [ ] 运算符 | ① reference operator [ ] (size_type pos); 第一个 operator [ ] 方法使得能够使用数组表示法来访问字符串的元素,可用于检索或更改值 ② const_renference operator [ ] (size_type pos) const; 第二个 operator [ ] 方法可用于 const 对象,但只能用于检索值 |
| at() 方法 | ① reference at (size_type n); ② const_refference at (size_type n) const; at() 方法提供了相似的访问功能,只是索引是通过函数参数提供的 |
| substr() 方法 | basic_string substr(size_type pos = 0, size_type n = npos) const; 返回原始字符串的子字符串——从 pos 开始,复制 n 个字符(或到字符串尾部)得到的。 |
| front() 方法 | C++11新增 front() 方法访问 string 的第一个元素,相当于 operator [ ] (0) |
| back() 方法 | C++11新增 brack() 方法访问 string 的最后一个元素,相当于 operator [ ] (size() - 1) |
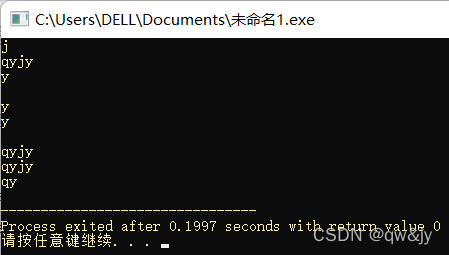
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1("qwjy");
cout << str1[2] << endl;
str1[1] = 'y';
cout << str1 << endl;
const string str2("qyjy");
cout << str2[1] << "\n\n";
cout << str1.at(1) << endl;
cout << str2.at(1) << "\n\n";
cout << str1.substr() << endl;//默认从0到size()复制
cout << str1.substr(0) << endl;//默认复制size()个字符
cout << str1.substr(0,2) << endl;//复制从0开始的2个字符
return 0;
}
12345678910111213141516171819
[ ] 运算符和 at() 方法差别在于(除语法差别外):at() 方法执行边界检查,如果 pos >= size(),将引发 out_of_range 异常。pos 的类型为 size_type,是无符号的,因此 pos 的值不能为负;而 operator [ ] ( ) 方法不进行边界检查,因此,如果 pos >= size(),则其行为将是不确定的(如果 pos == size(),const 版本将返回空值字符的等价物)。
可以在安全性(使用 at() 检测异常)和执行速度(使用数组表示)之间进行选择。
赋值
| 方法 | 描述 |
|---|---|
| basic_string& operator=(const basic_string& str); | 将一个 string 对象赋值给另一个 string str("qw"); string str1 = str; |
| basic_string& operator=(const charT* s); | 将 C 风格字符串赋值给 string 对象 string str2 = "qw"; |
| basic_string& operator=(charT c); | 将一个字符赋给 string 对象 string str3 = 'q'; |
| basic_string& operator=(basic_string&& str) noexcept; //C++ | 使用移动语义,将一个右值 string 对象赋给一个 string 对象 |
| basic_string& operator=(initializer_list < charT >); //C++ | 使用初始化列表进行赋值 string str5 = {'q', 'w', 'j', 'y'}; |
| basic_string& assign(const basic_string& str); | 将一个string 对象 str 赋值给另一个 string str6; str6.assign(str); |
| basic_string& assign(const basic_string& str, size_type pos, size_type n); | 将一个string 对象 str 的指定子串(从 pos 开始的 n 个字符)赋值给另一个 string str7; str7.assign(str, 1, 1); |
| basic_string& assign(const charT* s); | 将 C 风格字符串 s 赋值给 string 对象 string str8; str8.assign("qw"); |
| basic_string& assign(const charT* s, size_type n); | 将 C 风格字符串 s 的指定子串(从 0 开始的 n 个字符)赋值给 string 对象 string str9; str9.assign("qw", 1); |
| basic_string& assign(size_type n, charT c); | 将 n 个字符 c 赋值给 string 对象 string str10; str10.assign(5, 'q'); |
| basic_string& assign(initializer_list< charT >); | 使用初始化列表进行赋值 string str11; str11.assign({'q', 'w', 'j', 'y'}); |
字符串搜索
find()
| find() 函数原型 | 描述 |
|---|---|
| size_type find (const basic_string& str, size_type pos = 0) const noexcept; | .返回 str 在调用对象中第一次出现时的起始位置。搜索从 pos 开始(默认为 0),如果没有找到子字符串,将返回 npos string longer("QW is not very good, it is a waste."); string shorter("good"); size_type loc1 = longer.find(shorter); loc1 = longer.find(shorter, loc1 + 1); |
| size_type find (const charT* s, size_type pos = 0) const; | 完成同样的工作,但它使用字符数组而不是 string 对象作为子字符串 size_type loc2 = longer.find("QW"); |
| size_type find (const charT* s, size_type pos, size_type n) const; | 完成同样的工作,但它只使用字符串 s 的前 n 个字符 size_type loc3 = longer.find("not", 2); |
| size_type find (charT c, size_type pos = 0) const noexcept; | 功能与第一个相同,但它使用一个字符而不是 string 对象作为子字符串 size_type loc5 = longer.find('a'); |
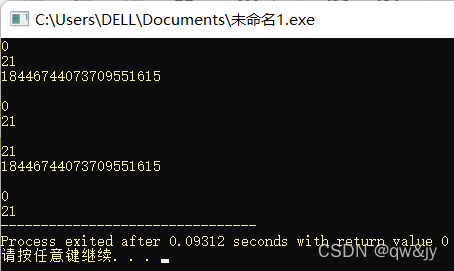
#include<iostream>
#include<string>
using namespace std;
int main(){
string str("qw is not very good, qw's English is too bad.");
string str1("qw"), str2("qy");
cout << str.find(str1) << endl;//#1: 从默认下标0开始查找
cout << str.find(str1, 1) << endl;//#1: 从指定下标1开始查找
cout << str.find(str2) << "\n\n";//#1: 没有找到
cout << str.find("qw") << endl;//#2:从默认下标0开始查找
cout << str.find("qw", 10) << "\n\n";//#2:从指定下标10开始查找
cout << str.find("qw", 1) << endl;//#3:从指定下标1开始查找
cout << str.find("qw", 1, 10) << "\n\n";//#3:从指定下标1至其后10个字符之间查找
cout << str.find('q') << endl;//#4:从默认下标0开始查找
cout << str.find('q', 1);//#4:从指定下标1开始查找
return 0;
}
1234567891011121314151617181920
rfind()
| rfind() 函数原型 | 描述 |
|---|---|
| size_type rfind(const basic_string& str, size_type pos = npos) const noexcept; | 返回 str 在调用对象中最后一次出现时的起始位置。搜索从 pos 开始(默认为 npos),如果没有找到子字符串,将返回 npos |
| size_type rfind(const charT* s, size_type pos = npos) const; | 完成同样的工作,但它使用字符数组而不是 string 对象作为子字符串 |
| size_type rfind(const charT* s, size_type pos, size_type n) const; | 完成同样的工作,但它只使用字符串 s 的后 n 个字符 |
| size_type rfind(charT c, size_type pos = npos) const noexcept; | 功能与第一个相同,但它使用一个字符而不是 string 对象作为子字符串 |
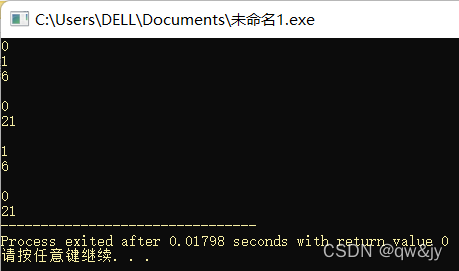
#include<iostream>
#include<string>
using namespace std;
int main(){
string str("qw is not very good, qw's English is too bad.");
string str1("qw"), str2("qy");
cout << str.rfind(str1) << endl;//#1: 从默认下标npos开始向前查找
cout << str.rfind(str1, 1) << endl;//#1: 从指定下标1开始向前查找
cout << str.rfind(str2) << "\n\n";//#1: 没有找到
cout << str.rfind("qw") << endl;//#2:从默认下标npos开始向前查找
cout << str.rfind("qw", 10) << "\n\n";//#2:从指定下标10开始向前查找
cout << str.rfind("qw", 1) << endl;//#3:从指定下标1开始向前查找
cout << str.rfind("qw", 25, 10) << "\n\n";//#3:从指定下标25至其前10个字符之间查找
cout << str.rfind('q') << endl;//#4:从默认下标npos开始向前查找
cout << str.rfind('q', 1);//#4:从指定下标1开始向前查找
return 0;
}
1234567891011121314151617181920

find_first_of()
| find_first_of() 函数原型 | 描述 |
|---|---|
| size_type find_first_of(const basic_string& str, size_type pos = 0) const noexcept; | 与对应 find() 方法的工作方法相似,但它们不是搜索整个子字符串,而是搜索子字符串中的字符首次出现的位置 |
| size_type find_first_of(const charT* s, size_type pos, size_type n) const; | |
| size_type find_first_of(const charT* s, size_type pos = 0) const; | |
| size_type find_first_of(charT c, size_type pos = 0) const noexcept; |
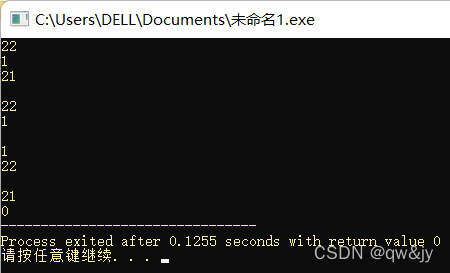
#include<iostream>
#include<string>
using namespace std;
int main(){
string str("qw is not very good, qw's English is too bad.");
string str1("qw"), str2("not");
//q是第一个在“qw”中的字符
cout << str.find_first_of(str1) << endl;//#1: 从默认下标0开始查找
cout << str.find_first_of(str1, 1) << endl;//#1: 从指定下标1开始查找
cout << str.find_first_of(str2) << "\n\n";//#1: 从默认下标0开始查找
cout << str.find_first_of("qw") << endl;//#2:从默认下标0开始查找
cout << str.find_first_of("qw", 10) << "\n\n";//#2:从指定下标10开始查找
cout << str.find_first_of("qw", 1) << endl;//#3:从指定下标1开始查找
cout << str.find_first_of("qw", 2, 10) << "\n\n";//#3:从指定下标2至其后10个字符之间查找
cout << str.find_first_of('q') << endl;//#4:从默认下标0开始查找
cout << str.find_first_of('q', 1);//#4:从指定下标1开始查找
return 0;
}
123456789101112131415161718192021
find_last_of()
| find_last_of() 函数原型 | 描述 |
|---|---|
| size_type find_last_of(const basic_string& str, size_type pos = npos) const noexcept; | 与对应 rfind() 方法的工作方式相似,但它们不是搜索整个子字符串,而是搜索子字符串中出现的最后位置 |
| size_type find_last_of(const charT* s, size_type pos, size_type n) const; | |
| size_type find_last_of(const charT* s, size_type pos = npos) const; | |
| size_type find_last_of(charT c, size_type pos = npos) const noexcept; |
#include<iostream>
#include<string>
using namespace std;
int main(){
string str("qw is not very good, qw's English is too bad.");
string str1("qw"), str2("qy");
//w是最后一个在“qw”中的字符
cout << str.find_last_of(str1) << endl;//#1: 从默认下标npos开始向前查找
cout << str.find_last_of(str1, 1) << endl;//#1: 从指定下标1开始向前查找
cout << str.find_last_of(str2) << "\n\n";//#1: 从默认下标npos开始向前查找
cout << str.find_last_of("qw") << endl;//#2:从默认下标npos开始向前查找
cout << str.find_last_of("qw", 10) << "\n\n";//#2:从指定下标10开始向前查找
cout << str.find_last_of("qw", 1) << endl;//#3:从指定下标1开始向前查找
cout << str.find_last_of("qw", 25, 10) << "\n\n";//#3:从指定下标25至其前10个字符之间查找
cout << str.find_last_of('q') << endl;//#4:从默认下标npos开始向前查找
cout << str.find_last_of('q', 1);//#4:从指定下标1开始向前查找
return 0;
}
123456789101112131415161718192021
find_first_not_of()
| find_first_not_of() 函数原型 | 描述 |
|---|---|
| size_type find_first_not_of(const basic_string& str, size_type pos = 0) const noexcept; | 与对应 find_first_of() 方法的工作方式相似,但它们搜索第一个不位于子字符串中的字符 |
| size_type find_first_not_of(const charT* s, size_type pos, size_type n) const; | |
| size_type find_first_not_of(const charT* s, size_type pos = 0) const; | |
| size_type find_first_not_of(charT c, size_type pos = 0) const noexcept; |
#include<iostream>
#include<string>
using namespace std;
int main(){
string str("qw is not very good, qw's English is too bad.");
string str1("qw"), str2("qy");
//空格是第一个没有在“qw”中出现的字符
cout << str.find_first_not_of(str1) << endl;//#1: 从默认下标0开始查找
cout << str.find_first_not_of(str1, 1) << endl;//#1: 从指定下标1开始查找
//w是第一个没有在“qy”中出现的字符
cout << str.find_first_not_of(str2) << "\n\n";//#1: 从默认下标0开始查找
cout << str.find_first_not_of("qw") << endl;//#2:从默认下标0开始查找
cout << str.find_first_not_of("qw", 10) << "\n\n";//#2:从指定下标10开始查找
cout << str.find_first_not_of("qw", 1) << endl;//#3:从指定下标1开始查找
cout << str.find_first_not_of("qw", 2, 10) << "\n\n";//#3:从指定下标2至其后10个字符之间查找
cout << str.find_first_not_of('q') << endl;//#4:从默认下标0开始查找
cout << str.find_first_not_of('q', 1);//#4:从指定下标1开始查找
return 0;
}
12345678910111213141516171819202122

find_last_not_of()
| find_last_not_of() 函数原型 | 描述 |
|---|---|
| size_type find_last_not_of(const basic_string& str, size_type pos = npos) const noexcept | 与对应 find_last_of() 方法的工作方式相似,但它们搜索的是最后一个没有在子字符串中的字符 |
| size_type find_last_not_of(const charT* s, size_type pos, size_type n) const; | |
| size_type find_last_not_of(const charT* s, size_type pos = npos) const; | |
| size_type find_last_not_of(charT c, size_type pos = npos) const noexcept; |
#include<iostream>
#include<string>
using namespace std;
int main(){
string str("qw is not very good, qw's English is too bad.");
string str1("qw"), str2("qy");
//.是最后一个没有出现在“qw”中的字符
cout << str.find_last_not_of(str1) << endl;//#1: 从默认下标npos开始向前查找
cout << str.find_last_not_of(str1, 1) << endl;//#1: 从指定下标1开始向前查找
cout << str.find_last_not_of(str2) << "\n\n";//#1: 从默认下标npos开始向前查找
cout << str.find_last_not_of("qw") << endl;//#2:从默认下标npos开始向前查找
cout << str.find_last_not_of("qw", 10) << "\n\n";//#2:从指定下标10开始向前查找
cout << str.find_last_not_of("qw", 1) << endl;//#3:从指定下标1开始向前查找
cout << str.find_last_not_of("qw", 25, 10) << "\n\n";//#3:从指定下标25至其前10个字符之间查找
cout << str.find_last_not_of('q') << endl;//#4:从默认下标npos开始向前查找
cout << str.find_last_not_of('q', 1);//#4:从指定下标1开始向前查找
return 0;
}
123456789101112131415161718192021
比较方法和函数
| 方法 | 描述 |
|---|---|
| int compare(const basic_string& str) const noexcept; | ①第一个字符串位于第二个字符串之前(小于),则返回一个小于 0 的值 ②如果两个字符串相同,则它将返回 0 ③如果第一个字符串位于第二个字符串后面(大于),则返回一个大于 0 的值 |
| int compare(size_type pos1, size_type n1, const basic_string& str) const; | 与第一个方法相似,但它进行比较时,只使用第一个字符串中从位置 pos1 开始的 n1 个字符 |
| int compare(size_type pos1, size_type n1, const basic_string& str, size_type pos2, size_type n2) const; | 与第一个方法相似,但它使用第一个字符串中从 pos1 位置开始的 n1 个字符和第二个字符串中从 pos2 位置开始的 n2 个字符进行比较 |
| int compare(const charT* s) const; | 与第一个方法相似,但它将一个字符数组而不是 string 对象作为第二个字符串 |
| int compare(size_type pos1, size_type n1, const charT* s) const; | 与第三个方法相似,但它将一个字符数组而不是 string 对象作为第二个字符串 |
| int compare(size_type pos1, size_type n1, const charT* s, size_type n2) const; | 与第三个方法相似,但它将一个字符数组而不是 string 对象作为第二个字符串 |
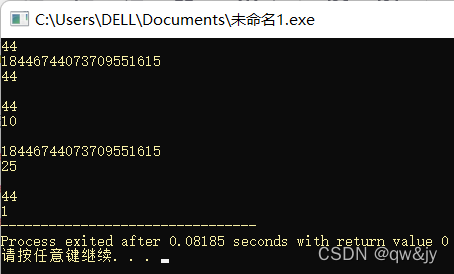
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1("abcdefg"), str2("abcdefg"), str3("bcdefg"), str4("bcdf");
cout << str1.compare(str2) << endl;//#1: str1和str2相同,返回0
cout << str1.compare(str3) << endl;//#1: str1小于str3,返回-1
cout << str3.compare(str1) << "\n\n";//#1: str3大于str1,返回1
cout << str1.compare(1, 6, str3) << "\n\n";//#2: str1中下标1后6个字符的字串与str3比较——相同0
cout << str1.compare(1, 3, str4, 0, 3) << "\n\n";//#3: str1中下标1后3个字符的字串与str4中下标0后3个字符的子串比较——相同 0
cout << str1.compare("abcdefg") << "\n\n";//#4: str1与“abcdefg”比较——相同 0
cout << str1.compare(1, 3, "bcd") << "\n\n";//#5: str1中下标1后3个字符的子串与“bcd”比较——相同 0
cout << str1.compare(1, 3, "bcdf", 3) << "\n";//#6: str1中下标1后3个字符的子串与“bcdf”中下标0后3个字符的子串比较——相同0
cout << str1.compare(1, 3, "bcdf", 2) << "\n\n";//#6: str1中下标1后3个字符的子串与“bcdf”中下标0后2个字符的子串比较——大于1
return 0;
}
123456789101112131415161718192021
非成员比较函数是重载的关系运算符
| 运算符 | 描述 |
|---|---|
| operator == () | 等于 |
| operator < () | 小于 |
| operator <= () | 小于等于 |
| operator > () | 大于 |
| operator >= () | 大于等于 |
| operator != () | 不等于 |
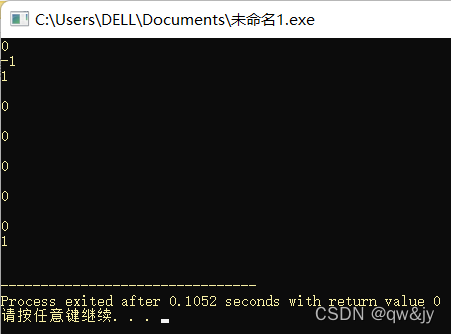
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1("abcdefg"), str2("abcdefg"), str3("bcdefg"), str4("bcdf");
printf("%d\n", str1 == str2);
printf("%d\n", str1 < str2);
printf("%d\n", str1 <= str2);
printf("%d\n", str1 > str2);
printf("%d\n", str1 >= str2);
printf("%d\n", str1 != str2);
return 0;
}
1234567891011121314
字符串修改方法
追加和相加
可以使用重载 += 运算符或 append() 方法将一个字符串追加到另一个字符串的后面。如果得到的字符串长于最大字符串长度。
| +=运算符 | 描述 |
|---|---|
| basic_string& operator += (const basic_string& str); | 将 strinig 对象追加到 string 对象后面 |
| basic_string& operator += (const charT* s); | 将字符串数组追加到 string 对象后面 |
| basic_string& operator += (charT c); | 将单个字符追加到 string 对象后面 |
| append() 方法原型 | 描述 |
|---|---|
| basic_string& append(const basic_string& str); | 在 string 字符串的末尾添加 string 对象 str |
| basic_string& append(const basic_string& str, size_type pos, size_type n); | 在 string 字符串的末尾添加 string 对象 str 的子串,子串以 pos 索引开始,长度为 n |
| basic_string& append(const charT* s); | 在 string 字符串的末尾添加字符数组 s |
| basic_string& append(const charT* s, size_type n); | 在 string 字符串的末尾添加 n 个字符数组 s |
| basic_string& append(size_type n, charT c); | 在 string 字符串的末尾添加 n 个字符 c |
| basic_string& append(InputIterator first, InputIterator last); | 在 string 字符串的末尾添加以迭代器 first 和 last 表示的字符序列 |
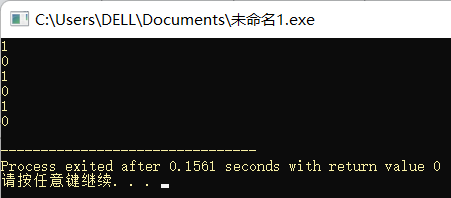
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1 = "qw is not very good";
string str2 = ", qw's English is too bad.";
string str3 = "Hi,";
str1.append(str2);
cout << str1 << endl;
str3.append(str2, 2, 2);
cout << str3 << endl;
str2.append(6, '6');
cout << str2 << endl;
return 0;
}
12345678910111213141516171819
| 其他方法 | 描述 |
|---|---|
| void push_back(charT c); | 将字符 c 添加到 string 字符串的末尾 |
| operator + () | 能够拼接字符串 |
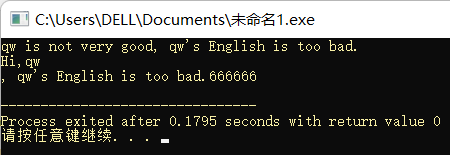
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1 = "qw is not very good";
str1.push_back('.');
cout << str1 << endl;
string str2 = str1 + ", qw's English is too bad.";
cout << str2 << endl;
string str3 = str2 + str1;
cout << str3 << endl;
return 0;
}
1234567891011121314
插入方法
| 方法 | 描述 |
|---|---|
| basic_string& insert(size_type pos1, const basic_string& str); | 在 pos1 位置插入一个 string 对象 str |
| basic_string& insert(size_type pos1, const basic_string& str, size_type pos2, size_type n); | 在 pos1 位置插入一个 string 对象的子串(从 pos2 开始的 n 个字符) |
| basic_string& insert(size_type pos, const charT* s); | 在 pos 位置插入一个常量字符串 |
| basic_string& insert(size_type pos, const charT* s, size_type n); | 在 pos 位置插入常量字符串的一个子串(从 0 开始的 n 个字符) |
| basic_string& insert(size_type pos, size_type n, charT c); | 在 pos 位置插入 n 个字符 c |
#include<iostream>
#include<string>
using namespace std;
int main(){
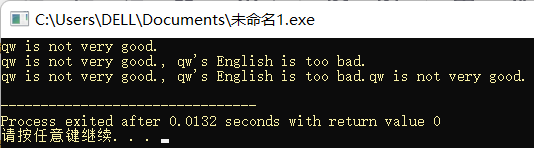
string str1 = "qy";
string str2 = "wj";
str1.insert(1, str2);
cout << str1 << endl;
string str3 = "qwjy";
str1 = "qy";
str1.insert(1, str3, 1, 2);
cout << str1 << endl;
string str4 = "w";
str4.insert(0, "q");
cout << str4 << endl;
string str5 = "w";
str5.insert(0, "qwqwqw", 1);
cout << str5 << endl;
string str6 = "w";
str6.insert(0, 6, 'q');
cout << str6 << endl;
return 0;
}
123456789101112131415161718192021222324252627
清除方法
| 方法 | 描述 |
|---|---|
| basic_string& erase(size_type pos = 0, size_type n = npos); | 从 pos 位置开始,删除 n 个字符或删除到字符串尾 |
| iterator erase(const_iterator position); | 删除迭代器位置引用的字符,并返回指向下一个元素的迭代器;如果后面没有其他元素,则返回 end() |
| iterator erase(const_iterator first, iterator last); | 删除区间 [first, last) 中的字符,即从 first(包括)到 last(不包括)之间的字符;返回最后一个迭代器,该迭代器指向最后一个被删除的元素后面的一个元素 |
| void pop_back(); | 删除字符串中的最后一个字符 |
#include<iostream>
#include<string>
using namespace std;
int main(){
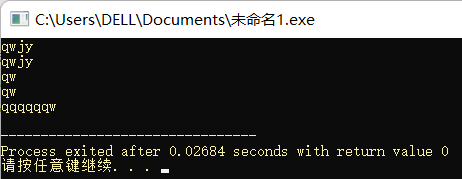
string str1 = "qw is not very good";
str1.erase(0, 3);
cout << str1 << endl;
str1.pop_back();
cout << str1 << endl;
return 0;
}
123456789101112

替换方法
| 方法 | 描述 |
|---|---|
| basic_string& replace (size_type pos1, size_type n1, const basic_string& str); | 用 str 替换指定字符串从起始位置 pos1 开始长度为 n 的字符 |
| basic_string& replace (size_type pos1, size_type n1, const basic_string& str, size_type pos2, size_type n2); | 用 str 的指定子串(给定起始位置 pos2 和长度 n2)替换从指定位置上的字符串(从起始位置 pos1 开始长度为 n 的字符) |
| basic_string& replace (size_type pos, size_type n1, const charT* s); | 用字符数组 str 替换从起始位置 pos1 开始长度为 n 的字符 |
| basic_string& replace (size_type pos, size_type n1, const charT* s, size_type n2); | 用字符数组 str 指定位置(从起始位置 0 开始长度为 n2 的子串)替换从起始位置 pos1 开始长度为 n 的字符 |
| basic_string& replace (size_type pos, size_type n1, size_type n2, charT c); | 用重复 n2 次的 c 字符替换从指定位置pos 长度为 n1 的字符 |
#include<iostream>
#include<string>
using namespace std;
int main(){
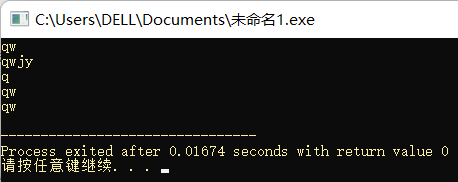
string str1 = "qy";
string str2 = "w";
str1.replace(1, 1, str2);
cout << str1 << endl;
string str3 = "qwjy";
str1 = "qy";
str1.replace(1, 1, str3, 1, 3);
cout << str1 << endl;
string str4 = "w";
str4.replace(0, 1, "q");
cout << str4 << endl;
string str5 = "w";
str5.replace(0, 1, "qwqwqw", 2);
cout << str5 << endl;
string str6 = "qqqqw";
str6.replace(0, 4, 1, 'q');
cout << str6 << endl;
return 0;
}
123456789101112131415161718192021222324252627
其他方法
| 其他方法 | 描述 |
|---|---|
| size_type copy(charT* s, size_type n, size_type pos = 0) const; | 将 string 对象或其中一部分复制到指定的字符串数组中。其中,s 指向目标数组,n 是要复制的字符数,pos 指出从 string 对象的什么位置开始复制。注意长度是否足够。 |
| void swap(basic_string& str); | 使用一个时间恒定的算法来交换两个 string 对象 |
#include<iostream>
#include<string>
using namespace std;
int main(){
string str1 = "qw is not very good";
string str2 = "qw's English is too bad.";
char str3[60];
str1.copy(str3, 30);
cout << str3 << endl;
char str4[60];
str2.copy(str4, 7, 5);
printf("%s\n", str4);
str1.swap(str2);
cout << str1 << endl;
cout << str2 << endl;
return 0;
}
123456789101112131415161718
输出与输入
| 方法 | 描述 |
|---|---|
| << 和 >> | “<<” 和 “>>” 提供了 C++ 语言的字符串输入和字符串输出功能,到达文件尾、读取字符串允许的最大字符数或遇到空白字符后,输入将终止 |
| getline() | getline() 从输入中读取字符,可以设置分界符(不设置,默认为“\n”) |
| c_str() | 用转换函数c_str(),该函数将 string 类型的变量转换为一个 const 的字符串数组的指针 |
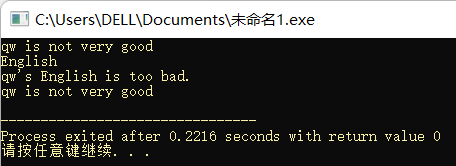
“<<” 和 “>>” 提供了 C++ 语言的字符串输入和字符串输出功能。
#include <iostream>
using namespace std;
int main()
{
string str;
cin >> str;//将输入读入到字符串
cout << str << endl;//输出
return 0;
}
123456789
到达文件尾、读取字符串允许的最大字符数或遇到空白字符后,输入将终止(空白的定义取决于字符集以及 charT 表示的类型)。
还有一个常用的 getline() 函数,该函数的原型包括两种形式:
template <class CharT, class traits, class Allocator > basic_istream<CharT, traits>& getline (basic_istream<CharT, traits>& is, basic_string <CharT,traits, Allocator> & str);
//上述原型包含 2 个参数:第 1 个参数是输入流;第 2 个参数是保存输入内容的字符串
template <class CharT, class traits, class Allocator > basic_istream<CharT, traits>& getline (basic_istream<CharT, traits>& is, basic_string <CharT,traits, Allocator> & str, charT delim);
//上述原型包含 3 个参数:第 1 个参数是输入流,第 2 个参数保存输入的字符串,第 3 个参数指定分界符。
这个函数将输入流 is 中的字符读入到字符串 str 中,直到遇到定界字符 delim、到达文件尾或者到达字符串的最大长度。delim 字符将被读取(从输入流中删除),但不被存储。
#include <iostream>
using namespace std;
int main()
{
string str1, str2;
getline(cin, str1);
getline(cin, str2, '.');//以“.”为分界符
cout << "str1: " << str1 << endl;
cout << "str2: " << str2 << endl;
return 0;
}
1234567891011
也可以用转换函数c_str(),该函数将 string 类型的变量转换为一个 const 的字符串数组的指针。
#include <iostream>
using namespace std;
int main()
{
string str;
getline(cin, str);
printf("%s", str.c_str()) ;
return 0;
}
123456789

list 双向链表

list 包含在头文件< list >中:
#include <list>
List 的能力
可以双向添加,粘结splice,排序sort,去重unique,合并merge
List 的内部结构完全迥异于 array、vector 或 deque。List 对象自身提供了两个 pointer,或称 anchor (锚点),用来指向第一个和最末一个元素。每个元素都有 pointer 指向前一个和下一个元素(或是指回 anchor)。如果想要安插新元素,只需操纵对应的 pointer即可(如下图所示)。

因此,list 在几个主要方面与 array、 vector 或 deque 不同:
- List 不支持随机访问。如果你要访问第 5 个元素,就得顺着串链逐一爬过前 4 个元素。所以,在 list 中随机巡访任意元素是很缓慢的行为。然而你可以从两端开始航行整个 list,所以访问第一个或最末一个元素的速度很快。
- 任何位置上(不只两端)执行元素的安插和移除都非常快,始终都是常量时间内完成,因为无须移动任何其他元素。实际上内部只是进行了一些 pointer 操作而已。
- 安插和删除动作并不会造成指向其他元素的各个 pointer、reference 和 iterator 失效。
- List 对于异常的处理方式是:要么操作成功,要么什么都不发生。你绝不会陷入“只成功一半”这种进退维谷的尴尬境地。
List 所提供的成员函数反映出它和 array、vector 以及 deque 的不同:
- List 提供 front()、 push_front() 和 pop_front()、back()、 push_back() 和 pop_back() 等操作函数。
- 由于不支持随机访问,list 既不提供 subscript (下标)操作符,也不提供 at()。
- List 并未提供容量、空间重新分配等操作函数,因为全无必要。每个元素有自己的内存,在元素被删除前一直有效。
- List 提供不少特殊成员函数,专门用于移动和移除元素。较之同名的 STL 通用算法,这些函数执行起来更快速,因为它们无须复制或搬移元素,只需调整若干 pointer 即可。
List 构造
| 操作 | 描述 |
|---|---|
| list< Elem > c | Default 构造函数,产生一个空 list,没有任何元素 |
| list< Elem > c(c2) | Copy 构造函数,建立 c2 的同型 list 并成为 c2 的一份拷贝(所有元素都被复制) |
| list< Elem > c = c2 | Copy 构造函数,建立一个新的 list 作为 c2 的拷贝(每个元素都被复制) |
| list< Elem > c(rv) | Move 构造函数,建立一个新的 list,取 rvalue rv 的内容(始自 C++11) |
| list< Elem > c = rv | Move 构造函数,建立一个新的 list,取 rvalue rv 的内容(始自 C++11) |
| list< Elem > c(n) | 利用元素的 default 构造函数生成一个大小为 n 的 list |
| list< Elem > c(n, elem) | 建立一个大小为 n 的 list,每个元素值都是 elem |
| list< Elem > c(beg, end) | 建立一个 list,以区间 [beg, end) 作为元素初值 |
| list< Elem > c(initlist) | 建立一个 list,以初值列 initlist 的元素为初值(始自 C++11) |
| list< Elem > c = initlist | 建立一个 list,以初值列 initlist 的元素为初值(始自 C++11) |
| c.~list() | 销毁所有元素,释放内存 |
非更易型操作
| 操作 | 描述 |
|---|---|
| c.empty() | 返回是否容器为空(相当于 size() == 0 但也许较快 |
| c.size() | 返回目前的元素个数 |
| c.max_size() | 返回元素个数之最大可能量 |
| c1 ==c2 | 返回 c1 是否等于 c2 (对每个元素调用 ==) |
| c1 != c2 | 返回 c1 是否不等于 c2(相当于 !(c1 == c2)) |
| c1 < c2 | 返回 c1 是否小于 c2 |
| c1 > c2 | 返回 c1 是否大于 c2(相当于 c2 < c1) |
| c1 <= c2 | 返回 c1 是否小于等于 c2 (相当于 !(c2 < c1) ) |
| c1 >= c2 | 返回 c1 是否大于等于 c2(相当于 !(c1 < c2)) |
List 赋值操作
| 操作 | 描述 |
|---|---|
| c = c2 | 将 c2 的全部元素赋值给 c |
| c = rv | 将 rvalue rv 的所有元素以 move assign 方式给予 c (始自 C++11) |
| c = initlist | 将初值列 initlist 的所有元素赋值给 c (始自 C++11) |
| c.assign(n,elem) | 复制 n 个 elem,赋值给 c |
| c.assign(beg , end) | 将区间 [beg, end) 内的元素赋值给 c |
| c.assign(initlist) | 将初值列 initlist 的所有元素赋值给 c |
| c1.swap( c2) | 置换 c1 和 c2 的数据 不抛出异常 |
| swap(c1 , c2) | 置换 c1 和 c2 的数据 不抛出异常 |
List 访问
| 操作 | 描述 |
|---|---|
| c.front() | 返回第一元素(不检查是否存在第一元素) |
| c.back() | 返回最末元素(不检查是否存在最末元素) |
迭代器相关操作
| 操作 | 描述 |
|---|---|
| c.begin() | 返回一个 bidirectional iterator 指向第一元素 |
| c.end() | 返回一个bidirectional iterator 指向最末元素的下一位置 |
| c.cbegin() | 返回一个 const bidirectional iterator 指向第一元素(始自 C++11) |
| c.cend() | 返回一个 const bidirectional iterator 指向最末元素的下一位置(始自 C++11) |
| c.rbegin() | 返回一个反向的( reverse ) iterator 指向反向迭代的第一元素 |
| c.rend() | 返回一个反向的( reverse ) iterator 指向反向迭代的最末元素的下一位置 |
| c.crbegin() | 返回一个 const reverse iterator 指向反向迭代的第一元素(始自 C++11) |
| c.crend() | 返回一个 const reverse iterator 指向反向迭代的最末元素的下一位置(始自 C++11) |
元素的安插和移入
| 操作 | 描述 |
|---|---|
| c.push_back(elem) | 附加一个 elem 的拷贝于未尾 要么成功,要么无任何作用(no effect ) |
| c.pop_back() | 移除最后一个元素,但是不返回它 不抛出异常 |
| c.push_front(elem) | 在头部插入 elem 的一个拷贝 要么成功,要么无任何作用(no effect) |
| c.pop_front() | 移除第一元素(但不返回) 不抛出异常 |
| c.insert(pos , elem) | 在 iterator 位置 pos 之前方插人一个 elem 拷贝,并返回新元素的位置 要么成功,要么无任何作用(no effect) |
| c.insert(pos ,n ,elem) | 在 iterator 位置 pos 之前方插入 n 个 elem 拷贝,并返回第一个新元素的位置(或返回 pos——如果没有新元素的话) 要么成功,要么无任何作用(no effect) |
| c.insert(pos , beg , end) | 在 iterator 位置 pos 之前方插入区间 [beg, end) 内所有元素的一份拷贝,并返回第一个新元素的位置(或返回 pos——如果没有新元素的话) 要么成功,要么无任何作用(no effect) |
| c.insert(pos , initlist) | 在 iterator 位置 pos 之前方插入初值列 initlist 内所有元素的一份拷贝,并返回第一个新元素的位置(或返回 pos—如果没有新元素的话;始自 C++11) 要么成功,要么无任何作用(no effect) |
| c.emplace(pos , args . . .) | 在 iterator 位置 pos 之前方插入一个以 args 为初值的元素,并返回新元素的位置(始自C++11) |
| c.emplace_back(args . . .) | 附加一个以 args 为初值的元素于未尾,不返回任何东西(始自 C++11) |
| c.emplace_front(args . . .) | 插入一个以 args 为初值的元素于起点,不返回任何东西(始自 C++11) |
| c.erase(pos) | 移除 iterator 位置 pos 上的元素,返回下一元素的位置 不抛出异常 |
| c.erase(beg , end) | 移除 [beg, end) 区间内的所有元素,返回下一元素的位置 不抛出异常 |
| c.remove(val) | 移除所有其值为 val 的元素 只要元素比较动作不抛出异常,它就不抛出异常 |
| c.remove_if(op) | 移除所有“造成 op (elem)结果为 true”的元素 只要判断式(predicate)不抛出异常,它就不抛出异 |
| c.resize(num) | 将元素数量改为 num (如果 size() 变大,多出来的新元素都需以 default 构造函数完成初始化) 要么成功,要么无任何作用(no effect) |
| c.resize(num , elem) | 将元素数量改为 num (如果 size() 变大,,多出来的新元素都是 elem 的拷贝) 要么成功,要么无任何作用(no effect) |
| c.clear() | 移除所有元素,将容器清空 不抛出异常 |
特殊更易型操作
| 操作 | 描述 |
|---|---|
| c.unique() | 如果存在若干相邻而数值相同的元素,就移除重复元素,只留一个 只要元素比较动作不抛出异常,它就不抛出异常 |
| c.unique(op) | 如果存在若干相邻元素都使 op() 的结果为 true,则移除重复元素,只留一个 只要元素比较动作不抛出异常,它就不抛出异常 |
| c.splice(pos , c2) | 将 c2 内的所有元素转移(move)到 c 之内、迭代器 pos 之前 不抛出异常 |
| c.splice(pos , c2 , c2pos) | 将 c2 内的 c2pos 所指元素转移到 c 内的 pos 所指位置( c 和 c2 可相同) 不抛出异常 |
| c.splice(pos , c2, c2beg , c2end) | 将 c2 内的 [c2beg, c2end) 区间内所有元素转移到 c 内的 pos 之前( c 和 c2 可相同) 不抛出异常 |
| c.sort() | 以 operator < 为准则对所有元素排序 |
| c.sort(op) | 以 op() 为 i 准则对所有元素排序 |
| c.merge(c2) | 假设 c 和 c2 容器都包含 op() 准则下的已排序(sorted)元素,将 c2 的全部元素转移到 c,并保证合并后的 list 仍为已排序 只要元素比较时不抛出异常,它便保证“要么成功,要么无任何作用” |
| c.merge(c2 , op) | 假设 c 和 c2 容器都包含已排序(sorted)元素,将 c2 的全部元素转移到 c,并保证合并后的 list 在 op() 准则下仍为已排序 只要元素比较时不抛出异常,它便保证“要么成功,要么无任何作用” |
| c.reverse() | 将所有元素反序(reverse the order) 不抛出异常 |
实例
#include <iostream>
#include <list>
#include <algorithm>
#include <iterator>
using namespace std;
void printList(const list<int>& l){
printf("list: ");
copy(l.cbegin(), l.cend(), ostream_iterator<int>(cout, " "));
printf("\n");
}
int main()
{
list<int> l1, l2;
for(int i = 0; i < 6; i ++){
l1.push_back(i);
l2.push_front(i);
}
printList(l1);
printList(l2);
printf("\n");
l2.splice(l2.end(), l1);
printList(l1);
printList(l2);
l2.splice(l2.end(), l2, l2.begin());
printList(l2);
printf("\n");
l2.sort();//排序
l1 = l2;
printList(l1);
l2.unique();//去重排序
printList(l2);
printf("\n");
l1.merge(l2);//合并,同时排序
printList(l1);
printList(l2);
return 0;
}
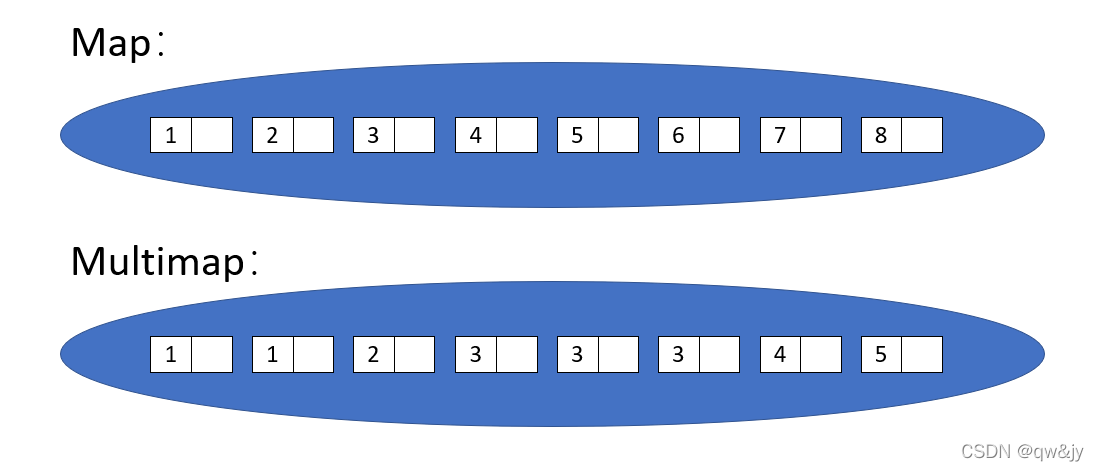
map 关联容器
Map 和 multimap 将 key/value pair 当作元素进行管理。它们可根据 key 的排序准则自动为元素排序。Multimap 允许重复元素,map 不允许,如下图所示。
map 和 multimap 包含在头文件中:
#include <map>
- Key 和 value 都必须是 copyable (可复制的)或 movable (可搬移的)。
- 对指定的排序准则而言,key 必须是comparable (可比较的)。
注意,元素类型(value_type)是个 pair < const Key,T>。
第三个 template 实参可有可无,用来定义排序准则。和 set 一样,这个排序准则必须定义为 strict weak ordering。元素的次序由它们的 key 决定和 value 无关。排序准则也可以用来检查相等性:如果两个元素的 key 彼此都不小于对方,两个元素被视为相等。
如果用户未传入某个排序准则,就使用默认的 less<> 排序准则——以 operator < 进行比较。
关于multimap,我们无法预测所有“拥有等价 key ”的元素的彼此次序,不过它们的次序是稳固不变的。C++11保证 multimap 的安插和抹除动作都会保留等价元素的相对次序。
第四个 template 实参也是可有可无,用来定义内存模型。默认的内存模型是 allocator,由 C++ 标准库提供。
“排序准则”,必须定义 strict weak ordering,其意义如下:
- 必须是非对称的
对 operator < 而言,如果 x < y 为 true,则 y < x 为 false。
对判断式(predicate)op() 而言,如果 op(x, y) 为 true,则 op(y, x) 为 false。 - 必须是可传递的
对 operator < 而言,如果 x < y 为 true 且 y < z 为 true,则 x < z 为 true。
对判断式 op() 而言,如果 op(x, y) 为 true 且 op(y, z) 为 true,则 op(x, z) 为 true。 - 必须是非自反的
对 operator < 而言,x < x 永远为 false。
对判断式 op() 而言,op(x, x) 永远为 false。 - 必须有等效传递性。大体意义是:如果 a 等于 b 且 b 等于 c,那么 a 必然等于 c。
这意味着对于操作符 <,若 !(a<b) && !(b<a) 为 true 且 !(b<c) && !(c<b) 为 true,那么 !(a<c) && ! (c<a) 亦为 true。
这也意味着对于判断式 op(),若 op(a, b)、 op(b, a)、 op(b, c)和 op(c, b) 都为 false,那么 op(a, c)和 op(c, a) 为 false。
结构
和其他所有关联式容器一样, map/multimap 通常以平衡二叉树完成(红黑树),如下图所示。C++standard 并未明定这一点,但是从 map和 multimap各项操作的复杂度自然可以得出这一结论。通常set、 multiset、map 和 multimap 使用相同的内部结构,因此,你可以把因 set 和 multiset 视为特殊的 map 和 multimap,只不过 set 元素的 value 和 key 是同一对象。因此,map 和 multimap 拥有 set 和 multiset 的所有能力和所有操作。当然,某些细微差异还是有的:首先,它们的元素是 key/value pair,其次,map 可作为关联式数组(associative array)来运用。
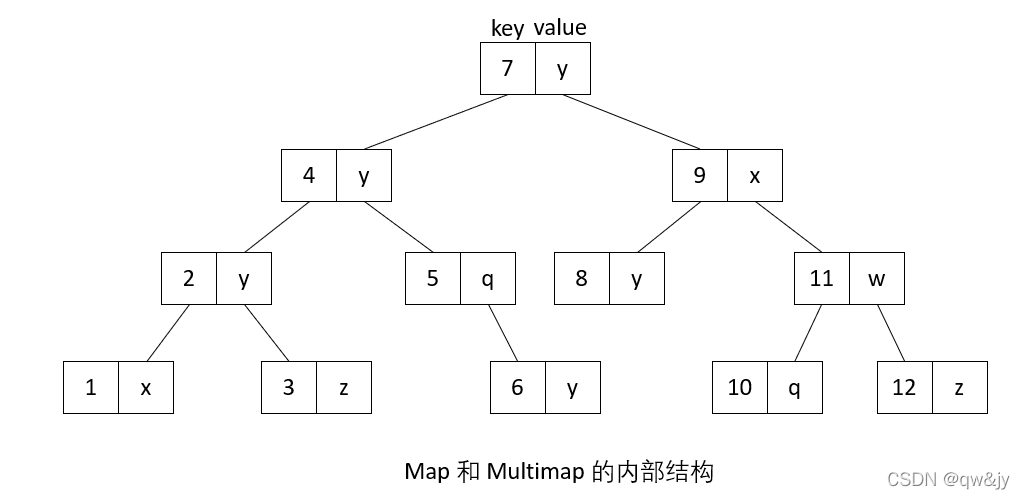
Map 和 multimap 会根据元素的 key 自动对元素排序。这么一来,根据已知的 key 查找某个元素时就能够有很好的效率,而根据已知 value 查找元素时,效率就很糟糕。“自动排序”这一性质使得 map 和 multimap 身上有了一条重要限制:你不可以直接改变元素的 key,因为这会破坏正确次序。要修改元素的 key,必须先移除拥有该 key 的元素,然后插入拥有新 key/value 的元素。从迭代器的观点看,元素的 key 是常量。至于元素的 value 倒是可以直接修改,当然前提是 value 并非常量。
构造操作
| 操作 | 描述 |
|---|---|
| map c | Default 构造函数,建立一个空 map/multimap,不含任何元素 |
| map c(op) | 建立一个空 map/multimap,以 op 为排序准则 |
| map c(c2) | Copy 构造函数,为相同类型之另一个 map/multimap 建立一份拷贝,所有元素均被复制 |
| map c = c2 | Copy 构造函数,为相同类型之另一个 map/multimap 建立一份拷贝,所有元素均被复制 |
| map c(rv) | Move 构造函数,建立一个新的 map/multimap,有相同类型,取 rvalue rv 的内容(始自C++11) |
| map c = rv | Move 构造函数,建立一个新的 map/multimap,有相同类型,取 rvalue rv 的内容(始自C++11) |
| map c(beg, end) | 以区间 [beg, end) 内的元素为初值,建立一个 map/multimap |
| map c(beg, end, op) | 以区间 [beg, end) 内的元素为初值,并以 op 为排序准则,建立一个 map/multimap |
| map c(initlist) | 建立一个 map/multimap,以初值列 initlist 的元素为初值(始自C++11) |
| map c = initlist | 建立一个 map/multimap,以初值列 initlist 的元素为初值(始自C++11) |
| c.~map() | 销毁所有元素,释放内存 |
| 其中,map 可为下列形式: | |
| map | 描述 |
| – | – |
| map< Key, Val > | 一个 map,以 less<>(operator <)为排序准则 |
| map< Key, Val, Op > | 一个 map,以 Op 为排序准则 |
| multimap< Key, Val > | 一个 multimap,以 less<>(operator <)为排序准则 |
| multimap< Key, Val, Op > | 一个 multimap,以 Op 为排序准则 |
#include <iostream>
#include <map>
#include <string>
using namespace std;
struct op{
bool operator() (const string& a, const string& b) const{
return a > b;
}
};
int main(){
map<string, float> c;
c.insert(pair<string, float>("qw", 6.6));
c.insert(pair<string, float>("qy", 6.6));
c.insert(pair<string, float>("qwjy", 66.6));
map<string, float> c1;
map<string, float> c2(op);
map<string, float> c3(c);
map<string, float> c4 = c;
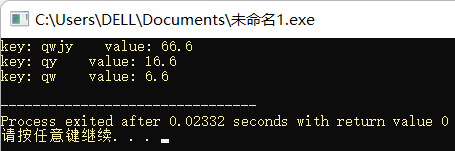
printf("map_c4:\n");
for(map<string, float>::iterator p = c4.begin(); p != c4.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
return 0;
}
1234567891011121314151617181920212223242526272829303132
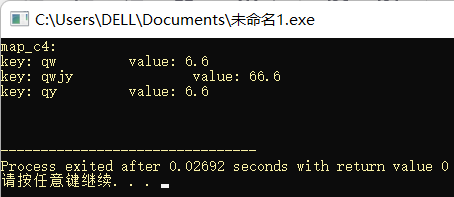
非更易型操作
| 操作 | 描述 |
|---|---|
| c.key_comp() | 返回“比较准则”(comparison criterion) |
| c.value_comp() | 返回针对 value 的“比较准则”(那是个对象,用来在一个 key/value pair 中比较 key) |
| c.empty() | 返回是否容器为空(相当于 size() == 0 但也许较快) |
| c.size() | 返回目前的元素个数 |
| c.max_size() | 返回元素个数之最大可能量 |
| c1 == c2 | 返回 c1 是否等于 c2(对每个元素调用==) |
| c1 != c2 | 返回 c1 是否不等于 c2(相当于 !(c1 == c2)) |
| c1 < c2 | 返回 c1 是否小于 c2 |
| c1 > c2 | 返回 c1 是否大于 c2(相当于c2 < c1) |
| c1 <= c2 | 返回 c1 是否小于等于 c2(相当于!(c2 < c1)) |
| c1 >= c2 | 返回 c1 是否大于等于 c2(相当于!(c1 < c2)) |
#include <iostream>
#include <map>
#include <string>
using namespace std;
struct op{
bool operator() (const string& a, const string& b) const{
return a > b;
}
};
int main(){
map<string, float, op> c;
c.insert(pair<string, float>("qw", 6.6));
c.insert(pair<string, float>("qy", 6.6));
c.insert(pair<string, float>("qwjy", 66.6));
map<string, float, op> c1 = c;
map<string, float, op> c2;
c2.insert(pair<string, float>("qwjy", 66.6));
c2.insert(pair<string, float>("qy", 6.6));
c2.insert(pair<string, float>("qw", 6.6));
printf("map_c:\n");
for(map<string, float>::iterator p = c.begin(); p != c.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
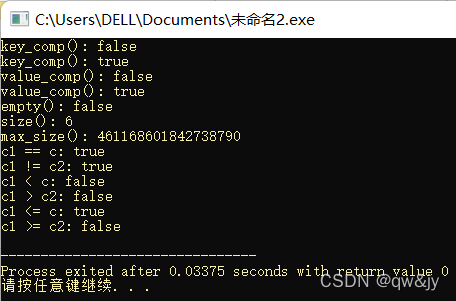
printf("key_comp: %s\n", c.key_comp()("qw", "qa") ? "true" : "false");
printf("key_comp: %s\n", c.key_comp()("qa", "qw") ? "true" : "false");
printf("value_comp: %s\n", c.value_comp()(pair<string, float>("qw", 0.6), pair<string, float>("qy", 66.6)) ? "true" : "false");
printf("value_comp: %s\n", c.value_comp()(pair<string, float>("qy", 0.6), pair<string, float>("qw", 66.6)) ? "true" : "false");
printf("empty: %s\n", c.empty() ? "true" : "false");
printf("size: %d\n", c.size());
printf("max_size: %lld\n", c.max_size());
printf("c1 == c2: %s\n", c1 == c2 ? "true" : "false");
return 0;
}
1234567891011121314151617181920212223242526272829303132333435363738
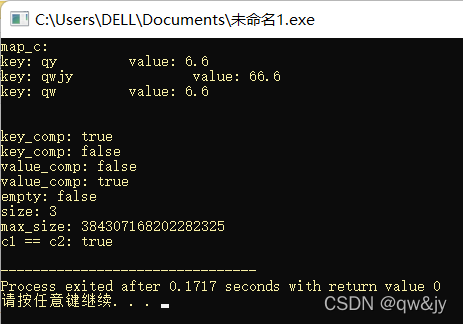
查找操作
| 操作 | 描述 |
|---|---|
| c.count(val) | 返回“key 为 val”的元素个数:如果 key 存在于容器中,则返回1,因为映射仅包含唯一 key 。如果键在Map容器中不存在,则返回0。 |
| c.find(val) | 返回“key 为 val”的第一个元素,找不到就返回 end()。该函数返回一个迭代器或常量迭代器,该迭代器或常量迭代器引用键在映射中的位置。 |
| c.lower_bound(val) | 返回“key 为 val”之元素的第一个可安插位置,也就是“key >= val”的第一个元素位置 |
| c.upper_bound(val) | 返回“key 为 val”之元素的最后一个可安插位置,也就是“key > val”的第一个元素位置 |
| c.equal_range(val) | 返回“key 为 val”之元素的第一个可安插位置和最后一个可安插位置,也就是“key == val”的元素区间 |
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main(){
map<string, float> c;
c.insert(pair<string, float>("qw", 6.6));
c.insert(pair<string, float>("qy", 6.6));
c.insert(pair<string, float>("qwjy", 66.6));
printf("map_c:\n");
for(map<string, float>::iterator p = c.begin(); p != c.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
printf("count: %d\n", c.count("qw"));
printf("find: key-%s value-%.1f\n", c.find("qwjy")->first.c_str(), c.find("qwjy")->second);
printf("lower_bound: key-%s value-%.1f\n", c.lower_bound("q")->first.c_str(), c.lower_bound("q")->second);
printf("upper_bound: key-%s value-%.1f\n", c.upper_bound("qw")->first.c_str(), c.upper_bound("qw")->second);
cout << "equal_range: " << c.equal_range("qw").first->first << "\t" <<
c.equal_range("qw").second->first << endl;
return 0;
}
12345678910111213141516171819202122232425
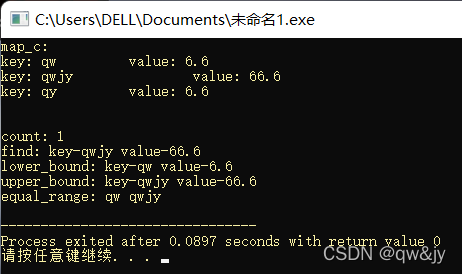
赋值
| 操作 | 描述 |
|---|---|
| c = c2 | 将 c2 的全部元素赋值给 c |
| c = rv | 将 rvalue rv 的所有元素以 move assign 方式给予 c (始自C++11) |
| c = initlist | 将初值列 initlist 的所有元素赋值给 c (始自C++11) |
| c1.swap(c2) | 置换 c1 和 c2 的数据 |
| swap(c1, c2) | 置换 c1 和 c2 的数据 |
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main(){
map<string, float> c;
c.insert(pair<string, float>("qw", 6.6));
c.insert(pair<string, float>("qy", 6.6));
c.insert(pair<string, float>("qwjy", 66.6));
map<string, float> c1 = c;
map<string, float> c2;
printf("map_c1:\n");
for(map<string, float>::iterator p = c1.begin(); p != c1.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
swap(c1, c2);
printf("map_c2:\n");
for(map<string, float>::iterator p = c2.begin(); p != c2.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
return 0;
}
123456789101112131415161718192021222324252627
元素访问
关联式容器并不提供元素的直接访问,你必须依靠 range-based for 循环或迭代器进行访问。但 map 是个例外,提供了如下表所述的方法直接访问元素。
先看看 range-based for 循环(C++11新特性):
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main(){
map<string, float> coll;
coll.insert(pair<string, float>("qw", 6.6));
for(auto elem : coll){
cout << "key: " << elem.first << "\t"
<< "value: " << elem.second << endl;
}
return 0;
}
1234567891011121314
其中的 elem 是个 reference,指向“容器 coll 中目前正被处理的元素”。因此 elem 的类型是 pair<string, float>。表达式
elem.first 取得元素的 key,而表达式 elem.second 取得元素的 value。
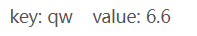
下面看看迭代器访问(C++11之前使用的方法):(迭代器操作的详细操作方法见下节)
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main(){
map<string, float> coll;
coll.insert(pair<string, float>("qw", 6.6));
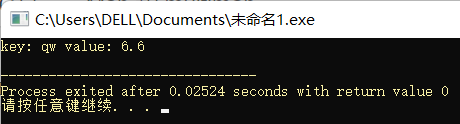
for(map<string, float>::iterator p = coll.begin(); p != coll.end(); p ++)
cout << "key: " << p->first << "\t"
<< "value: " << p->second << endl;
return 0;
}
1234567891011121314
在这里,迭代器 pos 被用来迭代穿越整个由“以 const string 和 float 组成的 pair”所构成的序列,你必须使用 operator -> 访问每次访问的那个元素的 key 和 value。所以 key (first)值是无法改变的,会引发错误;value(second)值是可以改变的。
如果你一定得改变元素的 key,只有一条路:以一个“value 相同”的新元素替换掉旧元素。
| 操作 | 描述 |
|---|---|
| c[key] | 安插一个带着 key 的元素——如果尚未存在于容器内。返回一个 reference 指向带着 key 的元素( only for nonconstant maps ) |
| c.at(key) | 返回一个 reference 指向带着 key 的元素(始自C++11) |
| at() 会依据它收到的“元素的 key”取得元素的 value;如果不存在这样的元素则抛出 out_of_range 异常。 | |
| 至于operator [ ],其索引就是 key。这意味着 operator [ ] 的索引可能属于任何类型,不一定是整数。如此的接口就是所谓的关联式数组(associative array)接口。“operator [ ] 的索引类型不必然是整数”。 | |
| 如果你选择某 key 作为索引,容器内却没有相应元素,那么 map 会自动安插一个新元素,其 value 将被其类型的 default 构造函数初始化。因此,你不可以指定一个“不具 default 构造函数”的 value 类型。注意,基础类型都有一个 default 构造函数,设立初值 0。 |
提供类似数组的访问方式有好也有坏:
- 优点是你可以通过更方便的接口对map安插新元素。例如:
map<string, float> coll;
coll["otto"] = 6.6;
12
语句:coll[“otto”] = 6.6; 处理过程如下:
- 处理 coll[“otto”]:
①如果存在 key 为"otto"的元素,上式会返回元素的 reference。
②如果没有任何元素的 key 是"otto",上式便为 map 自动安插一个新元素,令其 key 为"otto",其 value 则以, default 构造函数完成,并返回一个 reference 指向新元素。 - 将 6.6 赋值给 value:
接下来便是将 7.7 赋值给上述刚刚诞生的新元素。
这样, map 之内就包含了一个 key 为"otto"的元素,其 value 为 7.7。
- 缺点是你有可能不小心误置新元素。例如以下语句可能会做出意想不到的事情:
cout << coll["ottto"];
1
它会安插一个 key 为"ottto"的新元素,然后打印其 value,默认值是 0。然而按道理它其实应该产生一条报错信息,告诉你你把"otto"拼写错了。
同时亦请注意,这种元素安插方式比惯常的 map 安插方式慢,原因是新元素必须先使用 default 构造函数将 value 初始化,而该初值马上又被真正的 value 覆盖。
迭代器相关操作
| 操作 | 描述 |
|---|---|
| c.begin() | 返回一个 bidirectional iterator 指向第一元素 |
| c.end() | 返回一个 bidirectional iterator 指向最末元素的下一位置 |
| c.cbegin() | 返回一个 const bidirectional iterator 指向第一元素(始自C++11) |
| c.cend() | 返回一个 const bidirectional iterator 指向最末元素的下一位置(始自C++11) |
| c.rbegin() | 返回一个反向的(reverse) iterator 指向反向迭代的第一元素 |
| c.rend() | 返回一个反向的(reverse) iterator 指向反向迭代的最末元素的下一位置 |
| c.crbegin() | 返回一个 const reverse iterator 指向反向迭代的第一元素(始自C++11) |
| c.crend() | 返回一个 const reverse iterator 指向反向迭代的最末元素的下一位置(始自C++11) |
#include <iostream>
#include <map>
#include <string>
using namespace std;
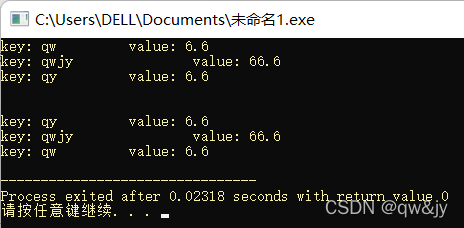
int main(){
map<string, float> coll;
coll.insert(pair<string, float>("qw", 6.6));
coll.insert(pair<string, float>("qy", 6.6));
coll.insert(pair<string, float>("qwjy", 66.6));
for(map<string, float>::iterator p = coll.begin(); p != coll.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
for(map<string, float>::reverse_iterator p = coll.rbegin(); p != coll.rend(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
return 0;
}
123456789101112131415161718192021
插入和移除
| 操作 | 描述 |
|---|---|
| c.insert(val) | 安插一个 val 拷贝,返回新元素位置,不论是否成功——对 map 而言 |
| c.insert(pos , val) | 安插一个 val 拷贝,返回新元素位置(pos 是个提示,指出安插动作的查找起点。若提示恰当可加快速度) |
| c.insert(beg , end) | 将区间 [beg, end) 内所有元素的拷贝安插到 c (无返回值) |
| c.insert(initlist) | 安插初值列 initlist 内所有元素的一份拷贝(无返回值;始自C++11) |
| c.emplace(args . . .) | 安插一个以 args 为初值的元素,并返回新元素的位置,不论是否成功——对 map 而言(始自C++11) |
| c.emplace_hint(pos , args . . .) | 安插一个以 args 为初值的元素,并返回新元素的位置(pos 是个提示,指出安插动作的查找起点。若提示恰当可加快速度) |
| c.erase(val) | 移除“与 val 相等”的所有元素,返回被移除的元素个数 |
| c.erase(pos) | 移除 iterator 位置 pos 上的元素,无返回值 |
| c.erase(beg , end) | 移除区间 [beg, end) 内的所有元素,无返回值 |
| c.clear() | 移除所有元素,将容器清空 |
#include <iostream>
#include <map>
#include <string>
using namespace std;
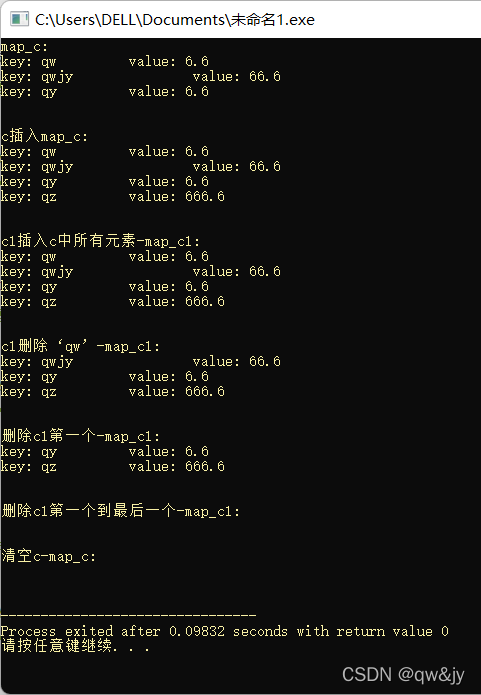
int main(){
map<string, float> c;
c.insert(pair<string, float>("qw", 6.6));
c.insert(pair<string, float>("qy", 6.6));
c.insert(pair<string, float>("qwjy", 66.6));
printf("map_c:\n");
for(map<string, float>::iterator p = c.begin(); p != c.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
c.insert(c.end(), pair<string, float>("qz", 666.6));
printf("c插入map_c:\n");
for(map<string, float>::iterator p = c.begin(); p != c.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
map<string, float> c1(c.begin(), c.end());
printf("c1插入c中所有元素-map_c1:\n");
for(map<string, float>::iterator p = c1.begin(); p != c1.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
c1.erase("qw");
printf("c1删除‘qw’-map_c1:\n");
for(map<string, float>::iterator p = c1.begin(); p != c1.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
c1.erase(c1.begin());
printf("删除c1第一个-map_c1:\n");
for(map<string, float>::iterator p = c1.begin(); p != c1.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
c1.erase(c1.begin(), c1.end()) ;
printf("删除c1第一个到最后一个-map_c1:\n");
for(map<string, float>::iterator p = c1.begin(); p != c1.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
c.clear();
printf("清空c-map_c:\n");
for(map<string, float>::iterator p = c.begin(); p != c.end(); p ++)
cout << "key: " << p->first << "\t\t"
<< "value: " << p->second << endl;
printf("\n\n");
return 0;
}
自定义排序规则
按 key 值排序
- 默认按照 less< key > 升序排列
- 定义 map 时,用greater< key >实现按 key 值降序排列
map<int,int,greater<int> > c;
1
- 可以通过定义结构体(或类),并在其中重载()运算符,来自定义排序函数。然后,在定义set的时候,将结构体加入其中例如如下代码中的 map<int, int, op> 或 map< int, int > c(op)。
//结构体
struct op{
bool operator() (const int& a, const int& b) const{
return a > b;
}
};
//类
class op1{
public:
bool operator() (const int& a, const int& b) const{
return a > b;
}
};
- 若 key 为结构体,也可以在自定义结构体中重载< 也可以实现默认排序,示例代码如下:
struct Student{
string id;
string college;
int age;
bool operator <(const Student& a) const{
if(college != a.college)
return college < a.college;
else if(id != a.id)
return id < a.id;
else
return age < a.age;
}
};
123456789101112131415
按 value 值排序
map 无法使用 sort 函数排序,所以将 map 存入可以用 sort 函数排序的容器之中。
#include <iostream>
#include <map>
#include <string>
#include <algorithm>
#include <vector>
using namespace std;
typedef pair<string, float> PAIR;
bool cmp(const PAIR& a, const PAIR& b){
return a.second > b.second;
}
int main(){
map<string, float> c;
c.insert(pair<string, float>("qw", 6.6));
c.insert(pair<string, float>("qy", 16.6));
c.insert(pair<string, float>("qwjy", 66.6));
vector<PAIR> v(c.begin(), c.end());
sort(v.begin(), v.end(), cmp);
for(int i = 0; i < v.size(); i ++)
printf("key: %s value: %.1f\n", v[i].first.c_str(), v[i].second);
return 0;
}
12345678910111213141516171819202122232425
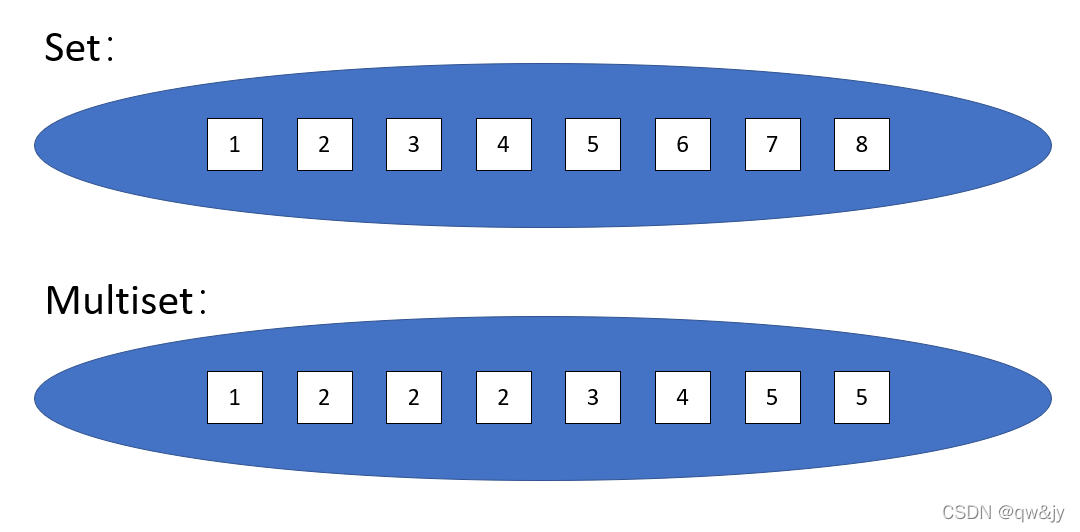
set 集合容器
Set 和 multiset 会根据特定的排序准则,自动将元素排序。两者不同之处在于 multiset 允许元素重复而 set 不允许。
set 和 multiset 包含在头文件中:
#include <set>
结构
和所有标准的关联式容器类似,set 和 multiset 通常以平衡二叉树(如下图)完成——C++ standard 并未明定,但由 set和 multiset 各项操作的复杂度可以得出这个结论——事实上,set 和 multiset 通常以红黑树实现。红黑树在改变元素数量和元素搜寻方面都很出色,它保证节点安插时最多只会做两个重新链接动作,而且到达某一元素的最长路径的深度,至多只是最短路径的深度的两倍。
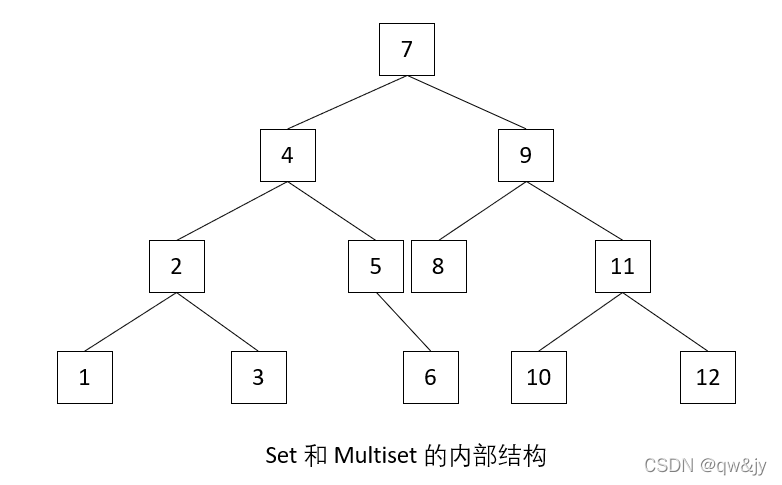
自动排序的主要优点在于令二叉树于查找元素时拥有良好效能。其查找函数具有对数复杂度。在拥有 1000 个元素的 set 或 multiset 中查找元素,二叉树查找动作(由成员函数执行)的平均时间为线性查找(由STL 算法执行)的 1/50。。
但是,自动排序造成 set 和 multiset 的一个重要限制:你不能直接改变元素值,因为这样会打乱原本正确的顺序。
因此,要改变元素值,必须先删除旧元素,再插入新元素。以下接口反映了这种行为:
- Set 和 multiset 不提供任何操作函数可以直接访问元素。
- 通过迭代器进行元素间接访问,有一个限制:从迭代器的角度看,元素值是常量。
构造
| 操作 | 描述 |
|---|---|
| set c | Default 构造函数,建立一个空 set / multiset,不含任何元素 |
| set c(op) | 建立一个空 set / multiset,以 op 为排序准则 |
| set c(c2) | Copy 构造函数,为相同类型之另一个 set / multiset 建立一份拷贝,所有元素均被复制 |
| set c = c2 | Copy 构造函数,为相同类型之另一个 set / multiset 建立一份拷贝,所有元素均被复制 |
| set c(rv) | Move 构造函数,建立一个新的 set / multiset,有相同类型,取 rvalue rv 的内容(始自C++11) |
| set c = rv | Move 构造函数,建立一个新的 set / multiset,有相同类型,取 rvalue rv 的内容(始自C++11) |
| set c(beg, end) | 以区间 [beg, end) 内的元素为初值,建立一个 set / multiset |
| set c(beg, end, op) | 以区间 [beg, end) 内的元素为初值,并以 op 为排序i准则,建立一个 set / multiset |
| set c(initlist) | 建立一个 set / multiset,以初值列 initlist 的元素为初值(始自C++11) |
| set c = initlist | 建立一个 set / multiset,以初值列 initlist 的元素为初值(始自C++11) |
| c.~set() | 销毁所有元素,释放内存 |
| 其中set可为下列形式: | |
| set | 描述 |
| – | – |
| set< Elem > | 一个 set,以 less<> (operator <) 为排序准则 |
| set< Elem, Op > | 一个 set,以 Op 为排序准则 |
| multiset< Elem > | 一个 multiset,以 less<> (operator <) 为排序准则 |
| multiset< Elem, Op > | 一个 multiset,以 Op 为排序准则 |
#include <iostream>
#include <set>
using namespace std;
struct op{
bool operator() (const int& a, const int& b) const{
return a > b;
}
};
int main(){
int a[] = {1, 2, 3, 4, 5, 6, 7, 8};
set<int> c(a, a + 6);
set<int> c1;
set<int> c2(op);
set<int> c3(c);
set<int> c4 = c;
printf("c: ");
for(set<int>::iterator i = c.begin(); i != c.end(); i ++)
cout << *i << " ";
printf("\n");
printf("c3: ");
for(set<int>::iterator i = c3.begin(); i != c3.end(); i ++)
cout << *i << " ";
printf("\n");
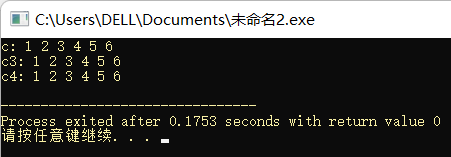
printf("c4: ");
for(set<int>::iterator i = c4.begin(); i != c4.end(); i ++)
cout << *i << " ";
printf("\n");
return 0;
}
1234567891011121314151617181920212223242526272829303132333435
非更易型操作
| 操作 | 描述 |
|---|---|
| c.key_comp() | 返回“比较准则” |
| c.value_comp() | 返回针对 value 的“比较准则”(和 key_comp() 相同) |
| c.empty() | 返回是否容器为空(相当于 size()==0 但也许较快) |
| c.size() | 返回目前的元素个数 |
| c.max_size() | 返回元素个数之最大可能量 |
| c1 == c2 | 返回 c1 是否等于 c2(对每个元素调用==) |
| c1 != c2 | 返回 c1 是否不等于 c2(相当于 !(c1 == c2) ) |
| c1 < c2 | 返回 c1 是否小于 c2 |
| c1 > c2 | 返回 c1 是否大于 c2(相当于 c2 < c1) |
| c1 <= c2 | 返回 c1 是否小于等于 c2(相当于 !(c2 < c1) ) |
| c1 >= c2 | 返回 c1 是否大于等于 c2(相当于 !(c1 < c2) ) |
#include <iostream>
#include <set>
using namespace std;
struct op{
bool operator() (const int& a, const int& b) const{
return a > b;
}
};
int main(){
int a[] = {1, 2, 3, 4, 5, 6, 7, 8};
set<int, op> c(a, a + 6);
set<int, op> c1 = c;
set<int, op> c2(a + 1, a + 7);
printf("key_comp(): %s\n", c.key_comp()(1, 2) ? "true" : "false");//1>2: false
printf("key_comp(): %s\n", c.key_comp()(2, 1) ? "true" : "false");//2>1: true
printf("value_comp(): %s\n", c.value_comp()(1, 2) ? "true" : "false");//1>2: false
printf("value_comp(): %s\n", c.value_comp()(2, 1) ? "true" : "false");//2>1: true
printf("empty(): %s\n", c.empty() ? "true" : "false");
printf("size(): %d\n", c.size());
printf("max_size(): %lld\n", c.max_size());
printf("c1 == c: %s\n", c1 == c ? "true" : "false");
printf("c1 != c2: %s\n", c1 != c2 ? "true" : "false");
printf("c1 < c: %s\n", c1 < c ? "true" : "false");
printf("c1 > c2: %s\n", c1 > c2 ? "true" : "false");
printf("c1 <= c: %s\n", c1 <= c ? "true" : "false");
printf("c1 >= c2: %s\n", c1 >= c2 ? "true" : "false");
return 0;
}
12345678910111213141516171819202122232425262728293031
查找操作
| 操作 | 描述 |
|---|---|
| c.count(val) | 返回“元素值为 val ”的元素个数 |
| c.find(val) | 返回“元素值为 val ”的第一个元素,如果找不到就返回 end() |
| c.lower_bound(val) | 返回 val 的第一个可安插位置,也就是“元素值 >= val ”的第一个元素位置 |
| c.upper_bound(val) | 返回 val 的最后一个可安插位置,也就是“元素值 > val ”的第一个元素位置 |
| c.equal_range(val) | 返回 val 可被安插的第一个位置和最后一个位置,也就是“元素值 == val ”的元素区间。将 lower_bound() 和 upper_bound() 的返回值做成一个 pair 返回。 如果 lower_bound() 或“ equal_range() 的 first 值”等于“ equal_range() 的 second 值”或 upper_bound(),则此 set 或 multiset 内不存在同值元素。 |
#include <iostream>
#include <set>
using namespace std;
int main(){
set<int> c;
c.insert(1);
c.insert(2);
c.insert(3);
c.insert(4);
c.insert(5);
c.insert(6);
printf("count(): %d\n", c.count(2));
printf("find(): %d\n", c.find(3));
cout << "lower_bound(3): " << *c.lower_bound(3) << endl;
cout << "upper_bound(3): " << *c.upper_bound(3) << endl;
cout << "equal_range(3): " <<*c.equal_range(3).first <<
*c.equal_range(3).second << endl;
cout <<endl;
cout << "lower_bound(5): " << *c.lower_bound(5) << endl;
cout << "upper_bound(5): " << *c.upper_bound(5) << endl;
cout << "equal_range(5):" << *c.equal_range(5).first <<
*c.equal_range(5).second << endl;
return 0;
}
1234567891011121314151617181920212223242526

赋值操作
| 操作 | 描述 |
|---|---|
| c = c2 | 将 c2 的全部元素赋值给 c |
| c = rv | 将 rvalue rv 的所有元素以 move assign 方式给予 c (始自C++11) |
| c = initlist | 将初值列 initlist 的所有元素赋值给 c (始自C++11) |
| c1.swap(c2) | 置换 c1 和 c2 的数据 |
| swap(c1, c2) | 置换 c1 和 c2 的数据 |
#include <iostream>
#include <set>
using namespace std;
int main(){
int a[] = {1, 2, 3, 4, 5, 6, 7, 8};
set<int> c(a, a + 6);
set<int> c1 = c;
set<int> c2 = {2, 3, 4, 5, 6, 7};
printf("c1: ");
for(set<int>::iterator i = c1.begin(); i != c1.end(); i ++)
cout << *i << " ";
printf("\n");
printf("c2: ");
for(set<int>::iterator i = c2.begin(); i != c2.end(); i ++)
cout << *i << " ";
printf("\n");
swap(c1, c2);
printf("\n交换c1和c2!\n");
printf("c1: ");
for(set<int>::iterator i = c1.begin(); i != c1.end(); i ++)
cout << *i << " ";
printf("\n");
return 0;
}
1234567891011121314151617181920212223242526272829

迭代器相关操作
| 操作 | 描述 |
|---|---|
| c.begin() | 返回一个 bidirectional iterator 指向第一元素 |
| c.end() | 返回一个 bidirectional iterator 指向最末元素的下一位置 |
| c.cbegin() | 返回一个 const bidirectional iterator 指向第一元素(始自C++11) |
| c.cend() | 返回一个 const bidirectional iterator 指向最末元素的下一位置(始自C++11) |
| c.rbegin() | 返回一个反向的 (reverse) iterator 指向反向迭代的第一元素 |
| c.rend() | 返回一个反向的 (reverse) iterator 指向反向迭代的最末元素的下一位置 |
| c.crbegin() | 返回一个 const reverse iterator 指向反向迭代的第一元素(始自C++11) |
| c.crend() | 返回一个 const reverse iterator 指向反向迭代的最未元素的下一位置(始自C++11) |
#include <iostream>
#include <set>
using namespace std;
int main(){
int a[] = {1, 2, 3, 4, 5, 6, 7, 8};
set<int> c(a, a + 6);
set<int> c1 = c;
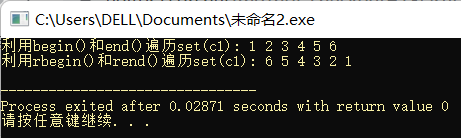
printf("利用begin()和end()遍历set(c1): ");
for(set<int>::iterator i = c1.begin(); i != c1.end(); i ++)
cout << *i << " ";
printf("\n");
printf("利用rbegin()和rend()遍历set(c1): ");
for(set<int>::reverse_iterator i = c1.rbegin(); i != c1.rend(); i ++)
cout << *i << " ";
printf("\n");
return 0;
}
1234567891011121314151617181920
插入和移除操作
| 操作 | 描述 |
|---|---|
| c.insert(val) | 安插一个 val 拷贝,返回新元素位置,不论是否成功——对 set 而言 |
| c.insert(pos, val) | 安插一个 val 拷贝,返回新元素位置( pos 是个提示,指出安插动作的查找起点。若提示恰当可加快速度) |
| c.insert(beg, end) | 将区间 [beg, end) 内所有元素的拷贝安插到 c (无返回值) |
| c.insert(initlist) | 安插初值列 initlist 内所有元素的一份拷贝(无返回值;始自C++11) |
| c.emplace(args . . .) | 安插一个以 args 为初值的元素,并返回新元素的位置,不论是否成功——对 set 而言(始自C++11) |
| c.emplace_hint(pos , args . . .) | 安插一个以 args 为初值的元素,并返回新元素的位置( pos 是个提示,指出安插动作的查找起点。若提示恰当可加快速度) |
| c.erase(val) | 移除“与 val 相等”的所有元素,返回被移除的元素个数 |
| c.erase(pos) | 移除 iterator 位置 pos 上的元素,无返回值 |
| c.erase(beg, end) | 移除区间 [beg, end) 内的所有元素,无返回值 |
| c.clear() | 移除所有元素,将容器清空 |
Set 提供如下接口:
pair<iterator, bool> insert(const value_type& val);
iterator insert(const_iterator posHint, const value_type& val);
template <typename... Args> pair<iterator, bool> emplace(Args&&... args);
template <typename... Args> iterator emplace_hint(const_iterator posHint, Args&&... args);
1234
Multiset 提供如下接口:
iterator insert(const value_type& val);
iterator insert(const_iterator posHint, const value_type& val);
template <typename... Args> iterator emplace(Args&&... args);
template <typename... Args> iterator emplace_hint(const_iterator posHint, Args&&... args);
1234
返回类型之所以不相同,原因是: multiset 允许元素重复而 set 不允许。因此,如果将某元素安插至 set 内,而该 set 已经内含同值元素,安插动作将告失败。所以 set 的返回类型是以 pair 组织起来的两个值:
- pair 结构中的 second 成员表示安插是否成功。
- pair 结构中的 first 成员表示新元素的位置,或现存的同值元素的位置。
其他任何情况下,此函数都返回新元素的位置(如果 set 已经内含同值元素,则返回同值元素的位置)。
#include <iostream>
#include <set>
using namespace std;
int main(){
int a[] = {1, 2, 3, 4, 5, 6, 7, 8};
set<int> c(a, a + 6);
set<int> c1;
pair<set<int>::iterator, bool> p = c.insert(7);
printf("%s%d: ", p.second ? "成功插入" : "插入失败", *p.first);
for(set<int>::iterator i = c.begin(); i != c.end(); i ++)
cout << *i << " ";
printf("\n");
set<int>::iterator p1 = c.insert(c.end(), 8);
printf("成功插入%d: ", *p1);
for(set<int>::iterator i = c.begin(); i != c.end(); i ++)
cout << *i << " ";
printf("\n");
c1.insert(a, a + 6);
printf("c1插入a到a+6的数据: ");
for(set<int>::iterator i = c1.begin(); i != c1.end(); i ++)
cout << *i << " ";
printf("\n\n");
p = c1.emplace(7);
printf("%s%d: ", p.second ? "成功插入" : "插入失败", *p.first);
for(set<int>::iterator i = c1.begin(); i != c1.end(); i ++)
cout << *i << " ";
printf("\n");
p1 = c1.emplace_hint(c1.end(), 8);
printf("成功插入%d: ", *p1);
for(set<int>::iterator i = c1.begin(); i != c1.end(); i ++)
cout << *i << " ";
printf("\n\n");
int cnt = c.erase(4);
printf("成功移除%d个4: ", cnt);
for(set<int>::iterator i = c.begin(); i != c.end(); i ++)
cout << *i << " ";
printf("\n");
c.erase(c.begin());
printf("成功移除首位元素: ");
for(set<int>::iterator i = c.begin(); i != c.end(); i ++)
cout << *i << " ";
printf("\n");
c.erase(c.begin(), c.end());
printf("成功移除所有元素: ");
for(set<int>::iterator i = c.begin(); i != c.end(); i ++)
cout << *i << " ";
printf("\n");
c1.clear();
printf("成功清除所有元素: ");
for(set<int>::iterator i = c1.begin(); i != c1.end(); i ++)
cout << *i << " ";
printf("\n");
return 0;
}

自定义排序准则
利用set内部默认的compare函数,可以将整数从小到大排序。
可以通过定义结构体(或类),并在其中重载()运算符,来自定义排序函数。然后,在定义set的时候,将结构体加入其中例如如下代码中的 set<int, op> 或 set< int > c(op)。
规则代码如下:
//结构体
struct op{
bool operator() (const int& a, const int& b) const{
return a > b;
}
};
//类
class op1{
public:
bool operator() (const int& a, const int& b) const{
return a > b;
}
};
12345678910111213
看一个示例:
#include <iostream>
#include <set>
using namespace std;
struct op{
bool operator() (const int& a, const int& b) const{
return a > b;
}
};
class op1{
public:
bool operator() (const int& a, const int& b) const{
return a > b;
}
};
int main(){
int a[] = {1, 2, 3, 4, 5, 6, 7, 8};
set<int> c1(a, a + 6);
set<int, op> c2(a, a + 6);
set<int, op1> c3(a, a + 6);
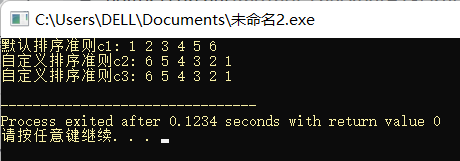
printf("默认排序准则c1: ");
for(set<int>::iterator i = c1.begin(); i != c1.end(); i ++)
cout << *i << " ";
printf("\n");
printf("自定义排序准则c2: ");
for(set<int>::iterator i = c2.begin(); i != c2.end(); i ++)
cout << *i << " ";
printf("\n");
printf("自定义排序准则c3: ");
for(set<int>::iterator i = c3.begin(); i != c3.end(); i ++)
cout << *i << " ";
printf("\n");
return 0;
}
123456789101112131415161718192021222324252627282930313233343536373839
在自定义结构体中重载< 也可以实现默认排序,示例代码如下:
struct Student{
string id;
string college;
int age;
bool operator <(const Student& a) const{
if(college != a.college)
return college < a.college;
else if(id != a.id)
return id < a.id;
else
return age < a.age;
}
};
Stack(堆栈)
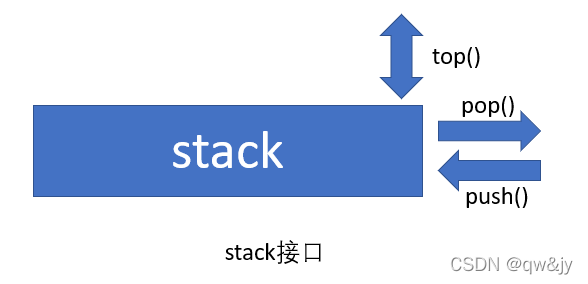
Class stack<>实现出一个 stack(也称为 LIFO,后进先出)。你可以使用 push() 将任意数量的元素放入 stack(如下图所示),也可以使用 pop() 将元素依其插入的相反次序从容器中移除(此即所谓“后进先出[LIFO]”)。
stack 包含在头文件< stack >中:
#include <stack>
定义一个 int 类型的 stack:
stack<int> st;
Stack 的实现中只是很单纯地把各项操作转化为内部容器的对应调用(如下图所示)。你可以使用任何 sequence 容器支持 stack,只要它们提供以下成员函数: back()、push_back() 和 pop_back()。例如你可以使用 vector 或 list 来容纳元素;
stack<int, vector<int> > st;
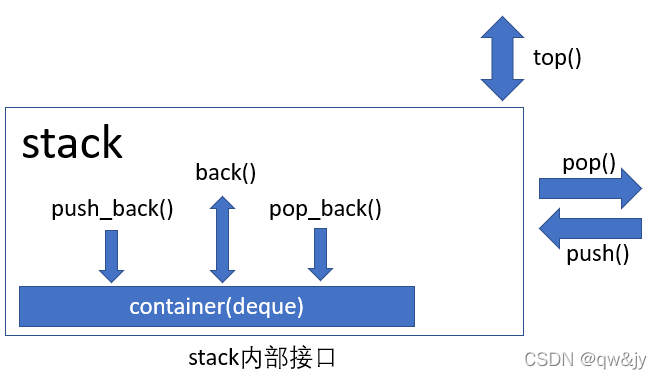
核心接口
Stack 的核心接口由三个成员函数提供:push()、 top() 和 pop()。
- push():将一个元素放入 stack 内。
- top():返回 stack 内的“下一个”元素。
- pop():从 stack 中移除元素。
注意, pop() 移除下一个元素,但是并不返回它;top() 返回下一个元素,但是并不移除它。所以,如果你想移除 stack 的下一个元素同时返回它,那么这两个的接口可能有点麻烦,但如果你只是想移除下一个元素而并不想处理它,这样的安排就比较好。注意,如果 stack 内没有元素,调用 top() 和 pop() 会导致不明确的行为。你可以采用成员函数 size() 和 empty() 来检验容器是否为空。
如果你不喜欢 stack<> 的标准接口,轻易便可写出若干更方便的接口。
stack 运用实例
#include <iostream>
#include <stack>
using namespace std;
int main(){
stack<int> st;
st.push(1);st.push(2);st.push(3);
printf("%d\n", st.top());//1--2--3
st.pop();
printf("%d\n", st.top());//1--2
st.pop();
st.top() = 66;//1-->66
st.push(4);//66--4
st.push(5);//66--4--5
st.pop();//66--4
while(!st.empty()){
printf("%d ", st.top());
st.pop();
}
return 0;
}
注意,当使用 nontrivial (译注:意指不凡的、复杂的)元素类型时,你可以考虑在安插“不再被使用的元素”时采用 move(),或是采用 emplace(),由 stack 内部创建元素(二者都始自C++11):
#include <iostream>
#include <stack>
using namespace std;
int main(){
stack<pair<string, string> > s;
auto p = make_pair("qw", "666");
s.push(move(p));
cout << s.top().first << " " << s.top().second << endl;
s.emplace("qwjy", "666");
cout << s.top().first << " " << s.top().second << endl;
return 0;
}
用户自定义 Stack Class
标准的 stack<> class 将运作速度置于方便性和安全性之上。但我通常并不很重视这些,所以我自己写了一个 stack class,拥有以下优势:
- pop() 会返回下一元素。
- 如果 stack 为空,pop() 和 top() 会抛出异常。
此外,我把一般人不常使用的成员函数如比较动作(comparison)略去。我的 stack class定义如下:
编写 hpp 文件,dev C++编写只需要保存是改成 .hpp 文件即可。
#ifndef STACK_HPP
#define STACK_HPP
#include <deque>
#include <exception>
template <typename T>
class Stack{
protected:
std:: deque<T> c;
public:
class ReadEmptyStack : public std::exception{
public:
virtual const char* what() const throw(){
return "read empty stack";
}
};
typename std::deque<T>::size_type size() const{
return c.size();
}
bool empty() const{
return c.empty();
}
void push(const T& elem){
c.push_back(elem);
}
T pop(){
if(c.empty()){
throw ReadEmptyStack();
}
T elem(c.back());
c.pop_back();
return elem;
}
T& top(){
if(c.empty()){
throw ReadEmptyStack();
}
return c.back();
}
};
#endif
下面看一下使用的例子,代码如下:
#include <iostream>
#include <exception>
#include "Stack.hpp"
using namespace std;
int main(){
try{
Stack<int> st;
st.push(1);//1
st.push(2);//1--2
st.push(3);//1--2--3
cout << st.pop() << endl;//1--2
cout << st.pop() << endl;//1
st.top() = 66;//1-->55
st.push(4);//66--4
st.push(5);//66--4--5
st.pop();//66--4
cout << st.pop() << endl;//66
cout << st.pop() << endl;//空
cout << st.pop() << endl;//报错
}catch(const exception& e){
cerr << "EXCEPTION: " << e.what() << endl;
}
return 0;
}
Queue(队列)
Class queue<> 实现出一个 queue(也称为 FIFO [先进先出])。你可以使用 push() 将任意数量的元素放入 queue 中(如下图所示),也可以使用 pop() 将元素依其插入次序从容器中移除(此即所谓“先进先出 [FIFO]”)。换句话说,queue 是一个典型的数据缓冲构造。

queue 包含在头文件< queue > 中:
#include <queue>
1
在头文件< queue >中,class queue 定义如下:
namespace std{
template <typename T,
typename Container = deque<T> >
class queue;
}
12345
- 第一个 template 参数代表元素类型。
- 第二个 template 参数带有默认值,定义 queue 内部用来存放元素的实际容器,默认采用 deque。
例如下面的例子定义出了一个内含 string 的 queue:
queue<string> q;
实际上 queue 只是很单纯地把各项操作转化为内部容器的对应调用(如下图所示)。你可以使用任何 sequence 容器支持 queue,只要它们支持 front()、 back()、push_back() 和 pop_front() 等操作。
例如你可以使用 list 来容纳元素:
queue<string, list<string> > q;
1
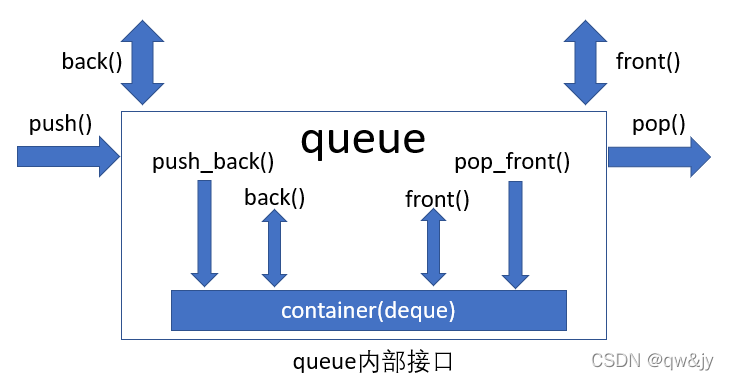
核心接口
Queue 的核心接口主要由成员函数push()、 front()、 back() 和 pop() 构成:
- push():将一个元素放入 queue 内。
- front():返回 queue 内的下一个元素(也就是第一个被放入的元素)。
- back():返回 queue 内的最后一个元素(也就是第一个被插入的元素)。
- pop():从 queue 中移除一个元素。
注意,pop() 虽然移除下一个元素,但是并不返回它,front() 和 back() 返回下一个元素,但并不移除它。所以,如果你想移除 queue 的下一一个元素,又想处理它,那就得同时调用 front() 和 pop()。这样的接口可能有点麻烦,但如果你只是想移除下一个元素而并不想处理它,这样的安排就比较好。注意,如果 queue 内没有元素,则 front()、back() 和 pop() 的执行会导致不确定的行为。你可以采用成员函数 size() 和 empty() 来检验容器是否为空。
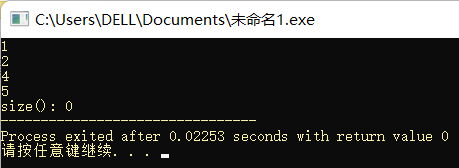
Queue运用实例
#include <iostream>
#include <queue>
using namespace std;
int main(){
queue<int> q;
q.push(1);q.push(2);q.push(3); //3--2--1
printf("%d\n", q.front());
q.pop(); //3--2
printf("%d\n", q.front());
q.pop(); //3
q.push(4); //4--3
q.push(5); //5--4--3
q.pop(); //5--4
printf("%d\n", q.front()); //4
q.pop(); //5
printf("%d\n", q.front());//5
q.pop(); //
printf("q.size(): %d", q.size());
return 0;
}
自定义Queue Class
标准的 queue<> class 将运作速度置于方便性和安全性之上。但不是所有程序员都喜欢这样。你可以轻松提供你自己完成的一个 queue class,就像先前自己完成一个 stack class 一样(如上 stack class)。
- pop() 会返回下一元素。
- 如果 stack 为空,pop()、 front() 和 bush() 会抛出异常。
#ifndef Queue_HPP
#define Queue_HPP
#include <deque>
#include <exception>
template <typename T>
class Queue{
protected:
std:: deque<T> c;
public:
class ReadEmptyQueue : public std::exception{
public:
virtual const char* what() const throw(){
return "read empty queue";
}
};
typename std::deque<T>::size_type size() const{
return c.size();
}
bool empty() const{
return c.empty();
}
void push(const T& elem){
c.push_back(elem);
}
T pop(){
if(c.empty()){
throw ReadEmptyQueue();
}
T elem(c.front());
c.pop_front();
return elem;
}
T front(){
if(c.empty()){
throw ReadEmptyQueue();
}
T elem(c.front());
return elem;
}
T back(){
if(c.empty()){
throw ReadEmptyQueue();
}
T elem(c.back());
return elem;
}
};
#endif
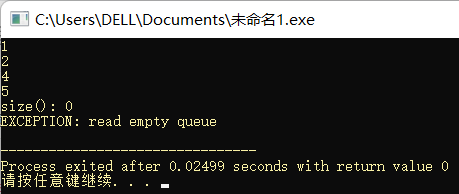
下面看使用 Queue 的代码:
#include <iostream>
#include <exception>
#include "Queue.hpp"
using namespace std;
int main(){
try{
Queue<int> q;
q.push(1);q.push(2);q.push(3);
printf("%d\n", q.front());//1--2--3
q.pop();
printf("%d\n", q.front());//2--3
q.pop();
q.push(4);//3--4
q.push(5);//3--4--5
q.pop();//4--5
printf("%d\n", q.pop());//4--5
printf("%d\n", q.pop());//5
printf("size(): %d\n", q.size());
q.pop();//报错
// q.front();//报错
// q.back();//报错
}catch (const exception& e){
cerr << "EXCEPTION: " << e.what() << endl;
}
return 0;
}














 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









