







目录
背景:
为预防大量黑客故意发起非法的时间查询请求,造成缓存击穿,建议采用布隆过滤器的方法解决。布隆过滤器通过一个很长的二进制向量和一系列随机映射函数(哈希函数)来记录与识别某个数据是否在一个集合中。如果数据不在集合中,能被识别出来,不需要到数据库中进行查询,所以能将数据库查询返回值为空的查询过滤掉。
缓存穿透: 缓存穿透是查询一个根本不存在的数据,由于缓存是不命中时需要从数据库查询,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
1.什么是布隆过滤器
布隆过滤器(Bloom Filter): 1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列的随机映射函数(哈希函数)两部分组成的数据结构。
用途: 用于检索一个元素是否在一个集合中。
优点:
- 时间复杂度低,增加及查询元素的时间复杂度都是O(k),k为Hash函数的个数;
- 占用存储空间小,布隆过滤器相对于其他数据结构(如Set、Map)非常节省空间。
缺点:
- 存在误判,只能证明一个元素一定不存在或者可能存在,返回结果是概率性的,但是可以通过调整参数来降低误判比例;
- 删除困难,一个元素映射到bit数组上的k个位置为1,删除的时候不能简单的直接置为0,可能会影响到其他元素的判断。
2.布隆过滤器的原理
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为1。
当我们需要判断一个元素是否位于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在布隆过滤器中。
举个简单的例子:
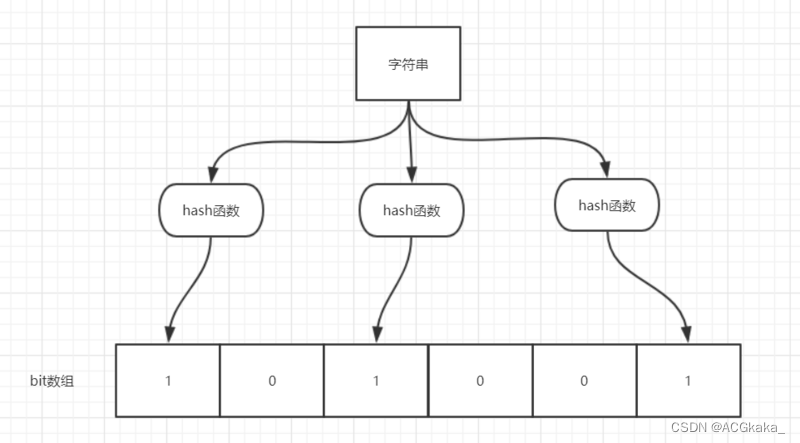
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1 (当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便);
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的某个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不存在,那么这个元素一定不在。
3.布隆过滤器的使用场景
判断给定数据是否存在:比如判断一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上)、防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)、邮箱的垃圾邮件过滤、黑名单功能等。去重:爬给定网址的时候对已经爬取过的URL去重。
4.Java实现布隆过滤器
MyBloomFilter.java
import java.util.BitSet;
/**
* <p> @Title MyBloomFilter
* <p> @Description 布隆过滤器实现
*
* @author zhj
* @date 2022/11/10 9:06
*/
public class MyBloomFilter {
/**
* 位数组大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{6, 18, 64, 89, 126, 189, 223};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
}
测试代码:
public static void main(String[] args) {
String s1 = "Hello";
MyBloomFilter myBloomFilter = new MyBloomFilter();
System.out.println("s1是否存在:" + myBloomFilter.contains(s1));
myBloomFilter.add(s1);
System.out.println("s1是否存在:" + myBloomFilter.contains(s1));
}
执行结果:
s1是否存在:false
s1是否存在:true
5.Guava工具实现布隆过滤器
guava是由谷歌公司提供的工具包,里面提供了布隆过滤器的实现。
Maven:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1.1-jre</version>
</dependency>
测试代码:
public static void main(String[] args) {
// 初始化布隆过滤器,设计预计元素数量为100_0000L,误差率为1%
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 100_0000, 0.01);
int n = 100_0000;
for (int i = 0; i < n; i++) {
bloomFilter.put(String.valueOf(i));
}
int count = 0;
for (int i = 0; i < (n * 2); i++) {
if (bloomFilter.mightContain(String.valueOf(i))) {
count++;
}
}
System.out.println("过滤器误判率:" + 1.0 * (count - n) / n);
}
执行结果:
过滤器误判率:0.010039
6.Redis实现布隆过滤器
Redis实现布隆过滤器的底层是通过bitmap位图数据结构。
Maven:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.17.4</version>
</dependency>
测试代码:
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
/// redis有密码时打开
// config.useSingleServer().setPassword("123456");
config.useSingleServer().setDatabase(0);
RedissonClient client = Redisson.create(config);
RBloomFilter<Object> bloomFilter = client.getBloomFilter("bloomnumber");
// 初始化布隆过滤器,设计预计元素数量为100_0000L,误差率为1%
int n = 1_0000;
bloomFilter.tryInit(1_0000L, 0.01);
for (int i = 0; i < n; i++) {
bloomFilter.add(String.valueOf(i));
}
int count = 0;
for (int i = 0; i< (n * 2); i++) {
if (bloomFilter.contains(String.valueOf(i))) {
count++;
}
}
System.out.println("过滤器误判率:" + 1.0 * (count - n) / n);
}
执行结果:
过滤器误判率:0.0211
(不知是不是配置问题,redisson的误判率比预设高了不少)
7.RedisTemplate模拟guava通过bitmap实现布隆过滤器
Maven:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1.1-jre</version>
</dependency>
Redis配置:
@Configuration
public class RedisConfig {
@Bean//定义第三方的Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory){
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
template.setKeySerializer(RedisSerializer.string());
//设置value的序列化方式
template.setValueSerializer(RedisSerializer.json());
//设置hash的key的序列化方式
template.setHashKeySerializer(RedisSerializer.string());
//设置hash的value的序列化方式
template.setHashValueSerializer(RedisSerializer.json());
template.afterPropertiesSet();//使上面参数生效
return template;
}
}
自定义布隆过滤器内置计算相关方法:
public class CustomBloomFilterHelper<T> {
private int numHashFunctions;
private long bitSize;
private Funnel<T> funnel;
public CustomBloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
/**
* 计算bit数组的长度
* m = -n * lnp / Math.pow(ln2,2)
* @param n 插入数据条数
* @param p 误判率
* @return
*/
private long optimalNumOfBits(long n, double p) {
if (p == 0.0D) {
p = 4.9E-324D;
}
return (long)((double)(-n) * Math.log(p) / (Math.log(2.0D) * Math.log(2.0D)));
}
/**
* 计算hash方法执行次数
* k = m/n * ln2
* @param n 插入数据条数
* @param m 数据位数
* @return
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int)Math.round((double)m / (double)n * Math.log(2.0D)));
}
/**
* 计算经过多个函数处理之后数据的偏移数组
* @param value
* @return
*/
public List<Long> murmurHashOffset(T value) {
List<Long> offset = new ArrayList<>();
byte[] bytes = Hashing.murmur3_128().hashObject(value, funnel).asBytes();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
long hash = (combinedHash & 9223372036854775807L) % bitSize;
offset.add(hash);
combinedHash += hash2;
}
return offset;
}
private long lowerEight(byte[] bytes) {
return Longs.fromBytes(bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
}
private long upperEight(byte[] bytes) {
return Longs.fromBytes(bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9], bytes[8]);
}
}
Lua文件:
// 添加数据
for i=1, #ARGV
do
redis.call('SETBIT',KEYS[1], ARGV[i], 1)
end
// 获取数据
local values = table.getn(ARGV)
for i=1, values
do
local value = redis.call('GETBIT', KEYS[1], ARGV[i])
if value == 0
then return 0
end
end
return 1
布隆过滤器添加及判断存在方法:
@Component
public class RedisBloomFilter<T> {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public <T> void put(CustomBloomFilterHelper<T> bloomFilter, String key, T value) {
Preconditions.checkArgument(bloomFilter != null, "bloomFilter不能为空");
List<Long> offset = bloomFilter.murmurHashOffset(value);
if (CollectionUtils.isEmpty(offset)) {
return;
}
DefaultRedisScript<Boolean> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("bloomFilterPut.lua")));
redisScript.setResultType(Boolean.class);
List<String> keys = new ArrayList<>();
keys.add(key);
redisTemplate.execute(redisScript, keys, offset.toArray());
}
public <T> void batchPut(CustomBloomFilterHelper<T> bloomFilter, String key, List<T> values) {
Preconditions.checkArgument(bloomFilter != null, "bloomFilter不能为空");
// 数据整合批量提交
List<Long> offset = new ArrayList<>();
for (T value : values) {
offset.addAll(bloomFilter.murmurHashOffset(value));
}
if (CollectionUtils.isEmpty(offset)) {
return;
}
Set<Long> set = new HashSet<>(offset);
DefaultRedisScript<Boolean> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("bloomFilterPut.lua")));
redisScript.setResultType(Boolean.class);
List<String> keys = new ArrayList<>();
keys.add(key);
redisTemplate.execute(redisScript, keys, set.toArray());
}
public <T> boolean mightContain(CustomBloomFilterHelper<T> bloomFilter, String key, T value) {
Preconditions.checkArgument(bloomFilter != null, "bloomFilter不能为空");
List<Long> offset = bloomFilter.murmurHashOffset(value);
if (CollectionUtils.isEmpty(offset)) {
return false;
}
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("bloomFilterMightContain.lua")));
redisScript.setResultType(Long.class);
List<String> keys = new ArrayList<>();
keys.add(key);
Long result = redisTemplate.execute(redisScript, keys, offset.toArray());
if(result == 1){
return true;
}
return false;
}
}
测试代码:
@Component
public class BloomFilterApplication implements ApplicationRunner {
private static CustomBloomFilterHelper<CharSequence> bloomFilterHelper;
@Autowired
RedisBloomFilter redisBloomFilter;
// @PostConstruct启动的时候执行
@PostConstruct
public void init() {
bloomFilterHelper = new CustomBloomFilterHelper<>(Funnels.stringFunnel(Charset.defaultCharset()), 1000000, 0.01);
}
@Override
public void run(ApplicationArguments args) throws Exception {
int j = 0;
List<String> data = new ArrayList<>();
for (int i = 0; i < 1000000; i++) {
data.add(i+"");
}
List<List<String>> lists = Lists.partition(data, 1000);
long start = System.currentTimeMillis();
for (List<String> list : lists) {
redisBloomFilter.batchPut(bloomFilterHelper, "bloom", list);
}
long end = System.currentTimeMillis();
start = System.currentTimeMillis();
for (int i = 0; i < 2000000; i++) {
boolean result = redisBloomFilter.mightContain(bloomFilterHelper, "bloom", i+"");
if (result) {
j++;
}
}
end = System.currentTimeMillis();
System.out.println("误判率:" + ((j - 1000000) /1000000.0));
}
}
执行结果:
误判率:0.010328
整理完毕,完结撒花~
















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











