









 本文介绍如何在Linux系统中调整home和根分区的存储空间大小,包括卸载分区、压缩分区大小及重新分配空闲空间的方法。
本文介绍如何在Linux系统中调整home和根分区的存储空间大小,包括卸载分区、压缩分区大小及重新分配空闲空间的方法。
在安装新系统的时候,有时候没法预估或者说错误的划分了分区大小,常常会导致我们后面的操作出现极大地不方便,比如某个分区分的太小了,导致
软件安装的时候会报安装空间不够,这就很麻烦。在这里我就记录一下错误分区后对home和根分区存储空间大小调整的整个过程!
1.查看我们机器现有的分区状况

注意红色框中的信息,这是我们后面要更改的分区路径。
通过上面我们可以发现根分区和home分区产生极大的不合理性,home分区太大了,所以这里我们将对home分区缩小存储空间并把压缩的存储空间添加到root下面。
2.卸载我们的home分区,并压缩我们的home分区大小
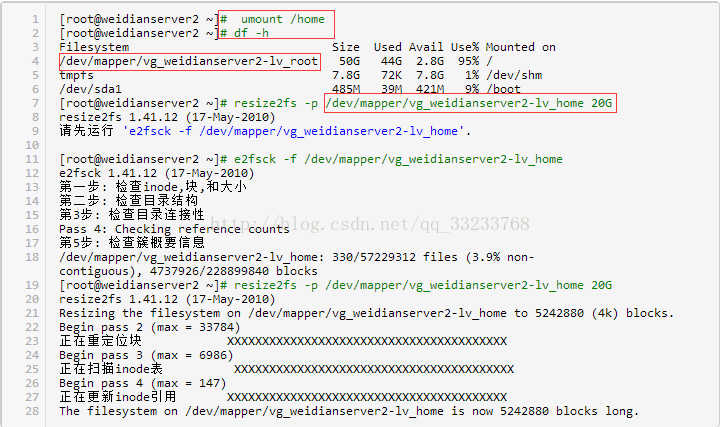
3.这个时候我们重新装载我们的home目录,通过运行结果可以看到我们将home分区压缩到20G

这样对home的压缩并重新装载就完成了,如下图:
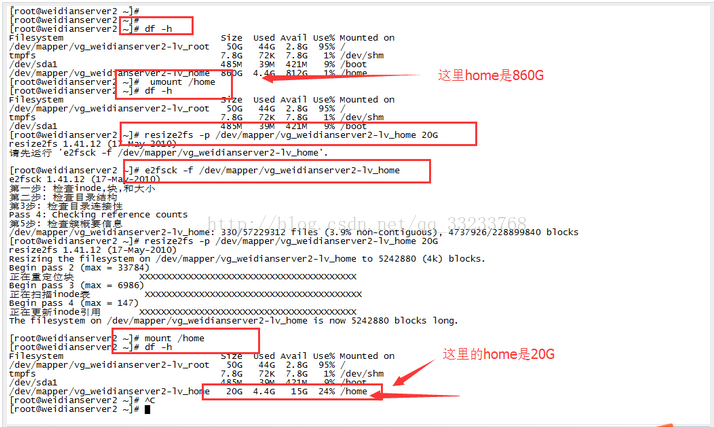
4.我们上面的三步将home的块处理好了,但是我们空闲的硬盘并没有添加到root下,所以下面的步骤就是将压缩出来的磁盘空间添加到root下:

这个重新加载和挂载的过程中需要花费一点时间,不过我们也可以在这段时间中不断的查看盘符的大小,这个时候我们会发现root盘符的大小会一点点的增加上来,如下图:
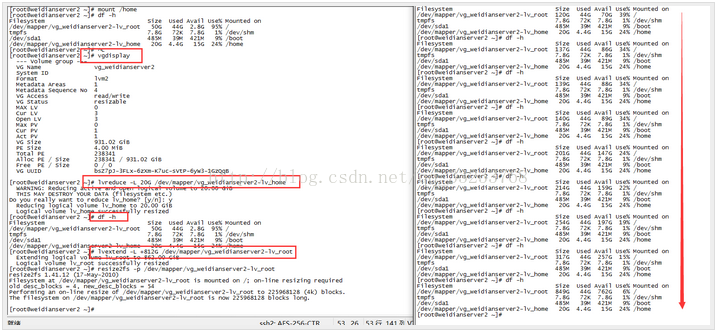
从上图最后的结果我们可以看出我们将home中的空闲盘符压缩出来812G添加到了root下面,这样我们的root空间就瞬间增加了。这样我们的目的就达到了。
欢迎大家留言讨论,谢谢!

















 3358
3358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









