







在对hive进行优化之前应理解mapreduce的原理
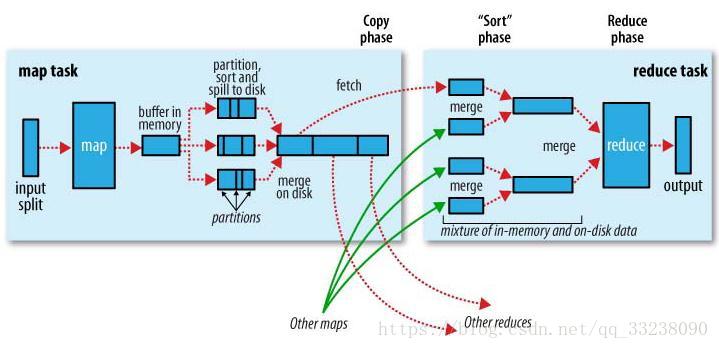
map task
程序会根据InputFormat将输入文件分割成splits,每个split会作为一个map task的输入,每个map task会有一个内存缓冲区,输入数据经过map阶段处理后的中间结果以及Partition结果都序列化成字节数组写入到缓冲区,而整个内存缓冲区就是一个字节数组。缓冲区的作用:批量收集map结果,减少磁盘IO的影响。 当写入的数据到达内存缓冲区的的阀值(默认是0.8), 当缓冲区的数据达到阀值,溢写线程启动,锁定这80MB的内存,执行溢写过程。剩下的20MB继续写入map task的输出结果。互不干涉!当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是mapreduce模型的默认行为,也是对序列化的字节做的排序。排序规则:字典排序!MapReduce框架会对key进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件(最少有一个溢写文件),如果是多个溢写文件,则最后归并排序所有的溢写文件为一个文件,称为merge。 merge是将所有的溢写文件归并到一个文件,结合上面所描述的combiner的作用范围,归并得到的文件内键值对有可能拥有相同的key,这个过程如果client设置过 Combiner,也会合并相同的key值的键值对,如果没有,merge得到的就是键值集合,如{“aaa”, [5, 8, 2, …]}
reduce task
当所有的map task完成后,reduce task就不断通过RPC从appmaster那里获取map task是否完成的信息,如果获知某台TaskTracker上的map task,就会启动线程来拉取map结果数据到相应的reduce task,不断地归并排序数据,为reduce的数据输入做准备,并对不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件,reduce task 启动,最终将输出输出结果存入HDFS上。
只有一个reduce的场景:
a、没有group by 的汇总
b、order by
c、笛卡尔积
1.Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fether),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘。
2.Merge过程。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy过来的数值。Copy过来的数据会先放入内存缓冲区中,这里缓冲区的大小要比map端的更为灵活,它是基于JVM的heap size设置,因为shuffler阶段reducer不运行,所以应该把绝大部分的内存都给shuffle用。
merge的三种形式:
内存到内存、内存到磁盘、磁盘到磁盘
默认情况下,第一种形式不启用。当内存中的数据量达到一定的阀值,就启动内存到磁盘的merge。与map端类似,这也是溢写过程,当然如果这里设置了Combiner,也是会启动的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3.reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。这个最终文件可能在磁盘中也可能在内存中。当然我们希望它在内存中,直接作为reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当reducer的输入文件已定,整个shuffle才最终结束。然后就是reducer执行,把结果存放到HDFS上。
MapReduce中Shuffle期望,过程详见上面
Shuffle的过程:描述数据从map task输出到reduce task输入的这段过程。
我们对Shuffle过程的期望是:
★ 完整地从map task端拉取数据到reduce task端
★ 跨界点拉取数据时,尽量减少对带宽的不必要消耗
★ 减小磁盘IO对task执行的影响
可以使用explan解释器来查看hive将查询语句转化为多少个mapreduce任务以及运行流程
•EXPLAIN [EXTENDED | DEPENDENCY]
在使用查询语句前,可以使用EXPLAIN关键字查看HIVE将为某个查询使用多个MapReduce作业。 EXPLAIN的输出中有很多查询执行计划的详细信息,包括抽象语法树、Hive执行各阶段之间的依赖图以及每个阶段的信息。如果要查看更详细的信息,可以在查询时加上EXTENDED。
DEPENDENCY 以json格式输出执行语句会读取的input table和input partition信息,这样debug语句会读取哪些表就很方便了。
explain select sum(id) from my;
了解以上的shuffle期望以后就可以明白hive优化需要做什么了。
可以从以下几点进行优化。
一.hive表优化
分区(不同文件夹):
动态分区开启:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
默认值:strict
描述:strict是避免全分区字段是动态的,必须有至少一个分区字段是指定有值的
避免产生大量分区
分桶(不同文件):
set hive.enforce.bucketing=true;
set hive.enforce.sorting=true;开启强制排序,插数据到表中会进行强制排序,默认false;
(2)mapjoin(map端执行join)
启动方式一:(自动判断)
set.hive.auto.convert.join=true;
hive.mapjoin.smalltable.filesize 默认值是25mb
小表小于25mb自动启动mapjoin
mapjoin支持不等值条件
reducejoin不支持在ON条件中不等值判断
(3)bucketjoin(数据访问可以精确到桶级别)
使用条件:1.两个表以相同方式划分桶
2.两个表的桶个数是倍数关系
例子:
create table order(cid int,price float) clustered by(cid) into 32 buckets;
create table customer(id int,first string) clustered by(id) into 32/64 buckets;
select price from order t join customer s on t.cid=s.id;
1.选择合理的Writable类型,创建表格时指定合适的格式。
为应用程序处理的数据选择合适的Writable类型可大大提升性能。
比如处理整数类型数据时,直接采用IntWritable比先以Text类型读入在转换为整数类型要高效。
如果输出整数的大部分可用一个或两个字节保存,那么直接采用VIntWritable或者VLongWritable,它们采用了变长整型的编码方式,可以大大减少输出数据量。
hive的文件格式
TEXTFILE //文本,默认值
SEQUENCEFILE // 二进制序列文件
RCFILE //列式存储格式文件 Hive0.6以后开始支持
ORC //列式存储格式文件,比RCFILE有更高的压缩比和读写效率,Hive0.11以后开始支持
PARQUET //列出存储格式文件,Hive0.13以后开始支持
TextFile每一行都是一条记录,每行都以换行符(\ n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
RCFile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
AVRO是开源项目,为Hadoop提供数据序列化和数据交换服务。您可以在Hadoop生态系统和以任何编程语言编写的程序之间交换数据。Avro是基于大数据Hadoop的应用程序中流行的文件格式之一。
ORC文件代表了优化排柱状的文件格式。ORC文件格式提供了一种将数据存储在Hive表中的高效方法。这个文件系统实际上是为了克服其他Hive文件格式的限制而设计的。Hive从大型表读取,写入和处理数据时,使用ORC文件可以提高性能。
Parquet是一个面向列的二进制文件格式。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。Parquet桌子使用压缩Snappy,gzip;目前Snappy默认。
我们都是用hive做存储和查询的。所以就选择了ORC格式,不仅压缩比很小,查询快,快速列存取。读取全量数据的操作 性能可能比sequencefile没有明显的优势。
建表语句:
CREATE TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [fields terminated by ] [STORED AS file_format] SEQUENCEFILE|TEXTFILE|RCFILE //如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。 [LOCATION hdfs_path] //文件的路径
1、列裁剪、分区裁剪
只查询需要的字段和分区,不使用select*
2、join优化
让服务器尽量少做事情,走最优的路径,以资源消耗最少为目标
若其中有一个表很小使用map join,否则使用普通的reduce join,注意hive会将join前面的表数据装载内存,所以较小的一个表在较大的表之前,减少内存资源的消耗
set hive.auto.convert.join=true; 开启mapjoin,默认就是开启的。
set hive.auto.convert.join.noconditionaltask = true;
set hive.auto.convert.join.noconditionaltask.size = 10000;
hive.mapjoin.smalltable.filesize=5000000;mapjoin的小表的大小。
解释:hive.auto.convert.join.noconditionaltask.size表明可以转化为MapJoin的表的大小总合。例如有A、B两个表,他们的大小都小于该属性值,那么他们都会都会分别被转化为MapJoin,如果两个表大小总和加起来也小于该属性值,那么这两个表会被合并为一个MapJoin。
使用map join解决数据倾斜的常景下小表关联大表的问题,但如果小表很大,怎么解决。这个使用的频率非常高,但如果小表很大,大到map join会出现bug或异常,这时就需要特别的处理。以下例子:
Select * from log a
Left outer join members b
On a.memberid = b.memberid.
Members有600w+的记录,把members分发到所有的map上也是个不小的开销,而且map join不支持这么大的小表。如果用普通的join,又会碰到数据倾斜的问题。
解决方法:
Select * from log a
Left outer join (select d.*
From ( select distinct memberid from log ) c
Join members d
On c.memberid = d.memberid
)x
On a.memberid = b.memberid。
先根据log取所有的memberid,然后mapjoin 关联members取今天有日志的members的信息,然后在和log做mapjoin。
假如,log里memberid有上百万个,这就又回到原来map join问题。所幸,每日的会员uv不会太多,有交易的会员不会太多,有点击的会员不会太多,有佣金的会员不会太多等等。所以这个方法能解决很多场景下的数据倾斜问题。
3、空值处理
(1)在创建表的时候指定null处理。
NULL转化为空字符串,可以节省磁盘空间,实现方法有几种
1)建表时直接指定(两种方式)
a、用语句ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’
with serdeproperties('serialization.null.format' = '')
实现,注意两者必须一起使用,如
CREATETABLE hive_tb (idint,name STRING)
PARTITIONED BY (`day` string,`type` tinyint COMMENT'0 as bid, 1 as win, 2 as ck',`hour` tinyint)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’
WITH SERDEPROPERTIES (‘field.delim’='/t’,‘escape.delim’='//’,serialization.null.format'='' )
STORED AS TEXTFILE;
b、或者通过ROW FORMAT DELIMITED NULL DEFINED AS ''如
CREATETABLE hive_tb (idint,name STRING)
PARTITIONED BY (`day` string,`type` tinyint COMMENT'0 as bid, 1 as win, 2 as ck',`hour` tinyint)
ROW FORMAT DELIMITED
NULL DEFINEDAS''
STORED AS TEXTFILE;
2)修改已存在的表
alter table hive_tb set serdeproperties('serialization.null.format' = '');
(2)NULL 值关联时,可排除掉不参与关联,也可随机分散开避免倾斜
Select *
From log a
Join bmw_users b
On a.user_id is not null
And a.user_id = b.user_id
Union all
Select *
from log a
where a.user_id is null.
解决方法2 :
Select *
from log a
left outer join bmw_users b
on case when a.user_id is null then concat(‘dp_hive’,rand() ) else a.user_id = b.user_id end ;
总结:2比1效率更好,不但io少了,而且作业数也少了。1方法log读取两次,jobs是2。2方法job数是1 。这个优化适合无效id(比如-99,’’,null等)产生的倾斜问题。
4. 排序优化
不需要全局排序时,可用distribute by sort by 而不用order by
order by 排序,只存在一个reduce,这样效率比较低。
可以用sort by操作,通常结合distribute by使用做reduce分区键
数据类型优化
不同数据类型id的关联会产生数据倾斜问题。
一张表s8的日志,每 个商品一条记录,要和商品表关联。但关联却碰到倾 斜的问题。s8的日志中有字符串商品id,也有数字的商品id,类型是string的,但商品中的数字id是bigint的。猜测问题的原因是把s8的商 品id转成数字id做hash来分配reduce,所以字符串id的s8日志,都到一个reduce上了,解决的方法验证了这个猜测。
方法:把数字类型转换成字符串类型
Select * from s8_log a
Left outer join r_auction_auctions b
On a.auction_id = cast(b.auction_id as string);
6. 多维度
1)涉及到多个维度统计数据的,用grouping set 代替多个union all
select
A,
B,
C,
group_id,
count(A)
from
tableName
group by --declare columns
A,
B,
C
grouping sets
(
(A,C),
(A,B),
(B,C),
(C)
)
其中grouping sets中的(A,C), (A,B), (B,C), (C) 代表4个group by 组合, 相当于写了四个sql查询语句使用了四个不同的group by策略。
group_id是为了区分每条输出结果是属于哪一个group by的数据。它是根据group by后面声明的顺序字段是否存在于当前group by中的一个二进制位组合数据。 比如(A,C)的group_id: group_id(A,C) = grouping(A)+grouping(B)+grouping (C) 的结果就是:二进制:101 也就是5.
2)利用hive 对UNION ALL的优化的特性
hive对union all优化只局限于非嵌套查询。
比如以下的例子:
select * from
(select * from t1
Group by c1,c2,c3
Union all
Select * from t2
Group by c1,c2,c3) t3
Group by c1,c2,c3;
从业务逻辑上说,子查 询内的group by 怎么都看显得多余(功能上的多余,除非有count(distinct)),如果不是因为hive bug或者性能上的考量(曾经出现如果不子查询group by ,数据得不到正确的结果的hive bug)。所以这个hive按经验转换成
select * from
(select * from t1
Union all
Select * from t2
) t3
Group by c1,c2,c3;
经过测试,并未出现union all的hive bug,数据是一致的。mr的作业数有3减少到1。
t1相当于一个目录,t2相当于一个目录,那么对map reduce程序来说,t1,t2可以做为map reduce 作业的mutli inputs。那么,这可以通过一个map reduce 来解决这个问题。Hadoop的计算框架,不怕数据多,就怕作业数多。
3)用insert into替换union all
如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,实际测试过程中,执行时间能提升50%
如:
insert overwite table tablename partition (dt= ....)
select ..... from ( select ... from A
union all
select ... from B union all select ... from C ) R
where ...;
可以改写为:
insert into table tablename partition (dt= ....) select .... from A WHERE ...; insert into table tablename partition (dt= ....) select .... from B WHERE ...; insert into table tablename partition (dt= ....) select .... from C WHERE ...;
尽早执行过滤条件
1):尽量尽早地过滤数据,减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段
select ... from A
join B
on A.key = B.key
where A.userid>10
and B.userid<10
and A.dt='20120417'
and B.dt='20120417';
应该改写为:
select .... from (select .... from A
where dt='201200417'
and userid>10
) a
join ( select .... from B
where dt='201200417'
and userid < 10
) b
on a.key = b.key;
2)where条件优化
优化前(关系数据库不用考虑会自动优化):
select m.cid,u.id from order m join customer u on m.cid =u.id where m.dt='2013-12-12';
优化后(where条件在map端执行而不是在reduce端执行):
select m.cid,u.id from (select * from order where dt='2013-12-12') m join customer u on m.cid =u.id;
5. 去重优化
1.根据实际需要,用group by 替换distinct
2.多次用到的子查询,可以单独拎出来存入临时表或者变量中以备后续使用。
count distinct的操作,先转成group,再count
distinct 本身就是group by 的一种简写,我原先以为count(distinct x)这种跟group by 是一样的,但是发现hive 里面distinct 明显比group by 要慢,可能跟group by 会有map 端的combiner有关, 另外观察到hive 在预估count(distinct x) 的reduce 个数比group by 的个数要少 , 所以hive 中使用count(distinct x) , 要么尽量把reduce 个数设置大,直接设置reduce 个数或者hive.exec.reducers.bytes.per.reducer 调小,
select count(1) from (select distinct id from tablename) tmp;
下面的效率比上面的高很多,原因就是distinct启动的reduce数就一个。group by维度过小
select count(1) from (select id from tablename group by id) tmp;
set mapred.reduce.tasks=3;
6.自定义UDF函数
public class ToProvince extends UDF{
static HashMap<String, String> provinceMap = new HashMap<String, String>();
static{
provinceMap.put("138", "beijing");
provinceMap.put("139", "shanghai");
provinceMap.put("137", "dongjing");
provinceMap.put("156", "huoxing");}
//我们需要重载这个方法,来适应我们的业务逻辑
public String evaluate(String phonenbr){
String res = provinceMap.get(phonenbr.substring(0, 3));
return res==null?"wukong":res; }
public int evaluate(int x,int y){
return x+y; }}
5 、left semi jioin的使用
6、count(distinct)变为union all
优化前:
select a,sum(b),count(distinct c),count(distinct d) from test group by a;
优化后:
select a,sum(b) as b,count(c) as c,count(d) as d from
(
select a, 0 as b,c,null as d from test group by a,c
union all
select a,0 as b, null as c,d from test group by a,d
union all
select a, b,null as c ,null as d from test) tmp group by a;
善用multi insert,union all
multi insert适合基于同一个源表按照不同逻辑不同粒度处理插入不同表的场景,做到只需要扫描源表一次,job个数不变,减少源表扫描次数
union all用好,可减少表的扫描次数,减少job的个数,通常预先按不同逻辑不同条件生成的查询union all后,再统一group by计算,不同表的union all相当于multiple inputs,同一个表的union all,相当map一次输出多条
in/exists(not)
通过left semi join 实现 in操作,一个限制就是join右边的表只能出现在join条件中
6.压缩数据(多个job)
(1)中间压缩处理hive查询的多个job之间的数据,对于中间压缩,最好选择一个节省cpu耗时的压缩方式
set hive.exec.compress.intermediate=true;
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
set hive.intermediate.compression.type=BLOCK;按块压缩,而不是记录
(2)最终输出压缩(选择压缩效果好的,减少储存空间)
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compression.type=BLOCK;按块压缩,而不是记录
增加副本数
•如果磁盘不是问题,增加副本数,找到平衡
增加副本数,会较大概率增加从本地获取数据。减少网络传输,加快运行。
7. 参数优化
1、设置map数量
set mapred.max.split.size=536870912; 每个切片的最大大小
set mapred.min.split.size.per.node=1;看这个节点剩余的大小情况并进行合并,如果值为1,表示a中每个剩余文件都会自己起一个map,如果小于设置的值,会合并为一个map。
set mapred.min.split.size.per.rack=1; 看这个机架剩余的大小情况并进行合并,如果值为1,表示a中每个剩余文件都会自己起一个map,如果小于设置的值,会合并为一个map。
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; #执行Map前进行小文件合并
在开启了org.apache.hadoop.hive.ql.io.CombineHiveInputFormat后,一个data node节点上多个小文件会进行合并,合并文件数由mapred.max.split.size限制的大小决定。
2.合理设置reduce个数,
set mapred.reduce.tasks=200; 这个最好不设置,数据量会变化,可以通过下面的参数设置每个reduce节点处理的数据量进行调整最好。
set hive.exec.reducers.bytes.per.reducer=536870912;#每个reduce节点处理的数据量
set hive.merge.mapfiles = true;#在Map-only的任务结束时合并小文件,map阶段Hive自动对小文件合并。默认值就是true,不需要设置。
set hive.merge.mapredfiles = true ;#默认false, true时在MapReduce的任务结束时合并小文件
set hive.merge.size.per.task = 536870912;设置合并的文件大小。
set hive.merge.smallfiles.avgsize=536870912; #当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
3.写SQL要先了解数据本身的特点,如果有join ,group操作的话,要注意是否会有数据倾斜
如果出现数据倾斜,应当做如下处理:
set hive.exec.reducers.max=200;设置最大的reduce个数,如果 input / bytes per reduce > max 则会启动这个参数所指定的reduce个数。 这个并不会影响mapre.reduce.tasks参数的设置。默认的max是999。
set mapred.reduce.tasks= 200;制定reduce的个数,一般不设置。
set hive.groupby.mapaggr.checkinterval=100000 ;--这个是group的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.groupby.skewindata=true; --如果是group by过程出现倾斜 应该设置为true,这种方法会启动两个job,第一个job会在key前面添加一个随机数,将数据散列到reduce中,第二个job就是将key前面的随机数去掉进行聚合。
上面的方法对业务数据没有进行分析,所以当某个领域知识告诉你数据分布的显著类型,比如hadoop definitive guide 里面的温度问题,一个固定的组合(观测站点的位置和温度) 的分布是固定的, 对于特定的查询如果前面两种方式都没用,实现自己的partitioner 也许是一个好的方式.
set hive.skewjoin.key=100000; --这个是join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.optimize.skewjoin=true;--如果是join 过程出现倾斜 应该设置为true
(1) 启动一次job尽可能的多做事情,一个job能完成的事情,不要两个job来做
通常来说前面的任务启动可以稍带一起做的事情就一起做了,以便后续的多个任务重用,与此紧密相连的是模型设计,好的模型特别重要.
(2) 合理设置reduce个数
reduce个数过少没有真正发挥hadoop并行计算的威力,但reduce个数过多,会造成大量小文件问题,数据量、资源情况只有自己最清楚,找到个折衷点,
(3) 使用hive.exec.parallel参数控制在同一个sql中的不同的job是否可以同时运行,提高作业的并发
设计并行。控制同一个节点,可以运行的job的最大值
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=8; 值可选
4.内存调整
set mapreduce.map.memory.mb=4096;
set mapreduce.reduce.memory.mb=8192;
set mapreduce.map.java.opts=-Xmx3072m;
set mapreduce.reduce.java.opts=-Xmx6144m;
5.io.sort.spill.percent
这个值就是上面提到的buffer的阈值,默认是0.8,既80%,当buffer中的数据达到这个阈值,后台线程会起来对buffer中已有的数据进行排序,然后写入磁盘,此时map输出的数据继续往剩余的20% buffer写数据,如果buffer的剩余20%写满,排序还没结束,map task被block等待。
如果你确认map输出的数据基本有序,排序时间很短,可以将这个阈值适当调高,更理想的,如果你的map输出是有序的数据,那么可以把buffer设的更大,阈值设置为1.
6.mapred.reduce.parallel.copies
Reduce copy数据的线程数量,默认值是5
Reduce到每个完成的Map Task 拷贝数据(通过RPC调用),默认同时启动5个线程到map节点取数据。这个配置还是很关键的,如果你的map输出数据很大,有时候会发现map早就100%了,reduce却在缓慢的变化,那就是copy数据太慢了,比如5个线程copy 10G的数据,确实会很慢,这时就要调整这个参数,但是调整的太大,容易造成集群拥堵,所以 Job tuning的同时,也是个权衡的过程,要熟悉所用的数据!
7.设置map side的环形环城区的大小,增大以后可以减少map任务的IO开销,从而提高性能,io.sort.mb默认值时100,可一调大一些,但是越大对配置要求越高。
8.Merge
该阶段是map产生spill之后,对spill进行处理的过程,通过对其进行配置也可以达到优化IO开销的目的map产生spill之后必须将些spill进行合并,这个过程叫做merge ,merge过程是并行处理spill的,每次并行多少个spill是由参数io.sort.factor指定的,默认为10个
9.Combine
set hive.map.aggr=true;相当于map端执行combiner,那么会根据设定的函数对map输出的数据进行一次类reduce的预处理
但是和分组、排序分组不一样的是,combine发生的阶段可能是在merge之前,也可能是在merge之后,这个时机可以由一个参数控制:min.num.spill.for.combine,默认值为3 当job中设定了combiner,并且spill数最少有3个的时候,那么combiner函数就会在merge产生结果文件之前运行
例如,产生的spill非常多,虽然我们可以通过merge阶段的io.sort.factor进行优化配置,但是在此之前我们还可以通过先执行combine对结果进行处理之后再对数据进行merge ,这样一来,到merge阶段的数据量将会进一步减少,IO开销也会被降到最低
10.set hive.fetch.task.conversion=more;
默认是minial 这种模式下select * ,limit,filter在一个表所属的分区表上操作,这三种情况都会直接进行数据的拿去,也就是直接把数据从对应的表格拿出来,不用跑mr代码,这样会快点儿运行程序。
在more模式下,运行select,filter,limit,都是运行数据的fetch,不跑mr应用,所以感觉more模式会更好点儿。
11.Sort-Merge-Bucket Join 如果表已经排序并且已经bucketed,可以启用SMB joins
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
set hive.auto.convert.sortmerge.join.bigtable.selection.policy= org.apache.hadoop.hive.ql.optimizer.TableSizeBasedBigTableSelectorForAutoSMJ;
参考文档:https://blog.csdn.net/zhong_han_jun/article/details/50814246














 3113
3113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









