







看到有人通过Xpath实现爬虫功能,就写了一个Java版本的。
网上的其他教程看着都是用过时的方法实现的,我这是用的新方法,不会报错。
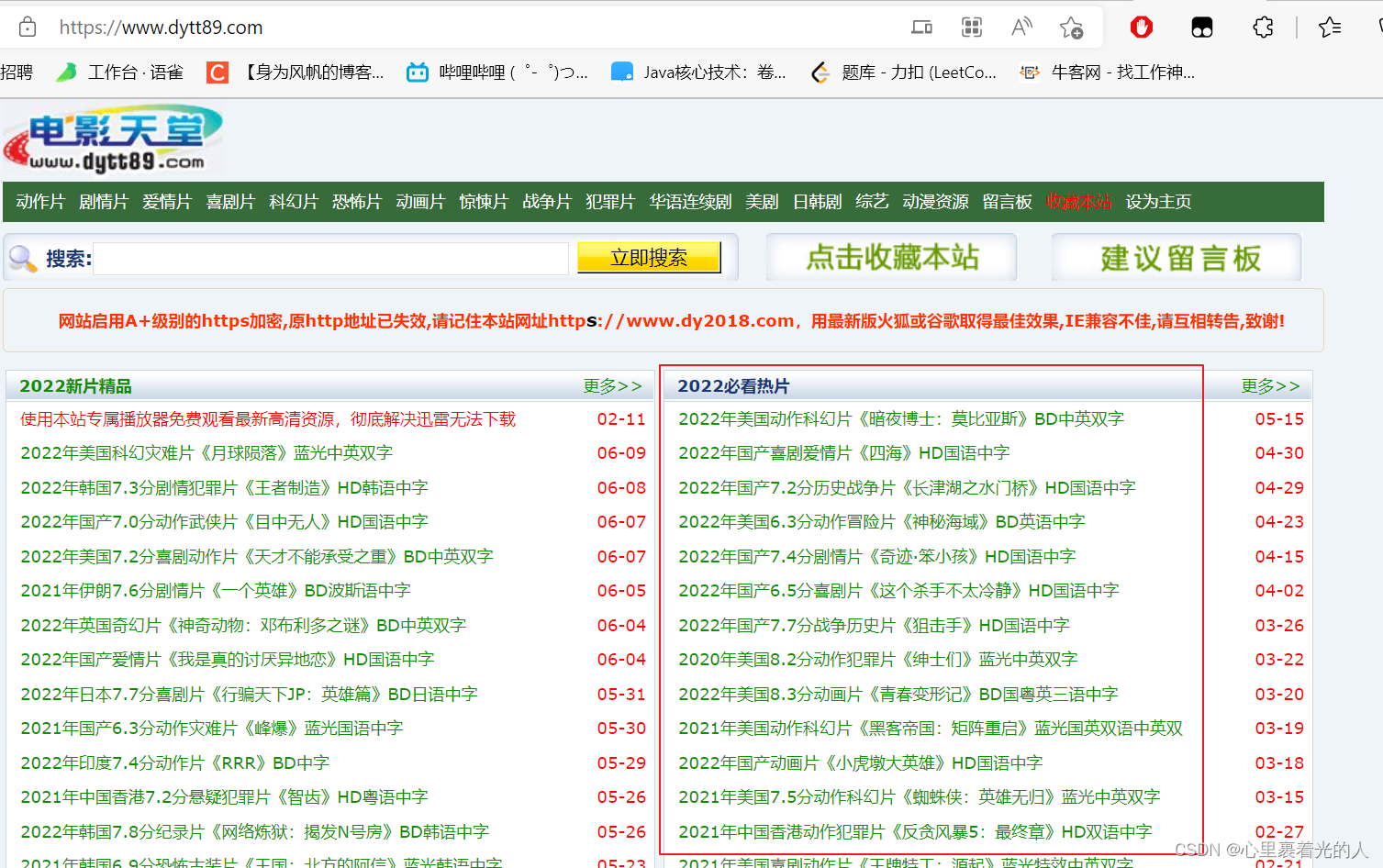
爬取了电影天堂 2022必看热片 里面的《电影名称》和对应下载链接。
下面贴代码:
需要先引入Xpath的jar包
// https://mvnrepository.com/artifact/cn.wanghaomiao/JsoupXpath
implementation 'cn.wanghaomiao:JsoupXpath:2.2'
package xpath;
import org.jsoup.nodes.Attributes;
import org.jsoup.nodes.Element;
import org.jsoup.nodes.Node;
import org.seimicrawler.xpath.JXDocument;
import org.seimicrawler.xpath.JXNode;
import java.util.List;
/**
* Xpath测试
*
* @author zhao.hualuo
* Create at 2022/6/9
*/
public class XpathTest {
public static void main(String[] args) {
String html= "https://www.dytt89.com/";
// 基于URL创建JXDocument
JXDocument jxDocument = JXDocument.createByUrl(html);
// Xpath语句
String str = "//*[@id=\"header\"]/div/div[3]/div[4]/div[2]/div[2]/ul";
// 获取节点集合
List<JXNode> list = jxDocument.selN(str);
Element element = list.get(0).asElement();
// 遍历节点
for (Node childNode : element.childNodes()) {
if (childNode.childNodes().size() == 0) {
continue;
}
Attributes attributes = childNode.childNodes().get(0).attributes();
String href = childNode.baseUri() + attributes.get("href").substring(1);
String title = attributes.get("title");
System.out.println(href + "\t" + title);
}
}
}
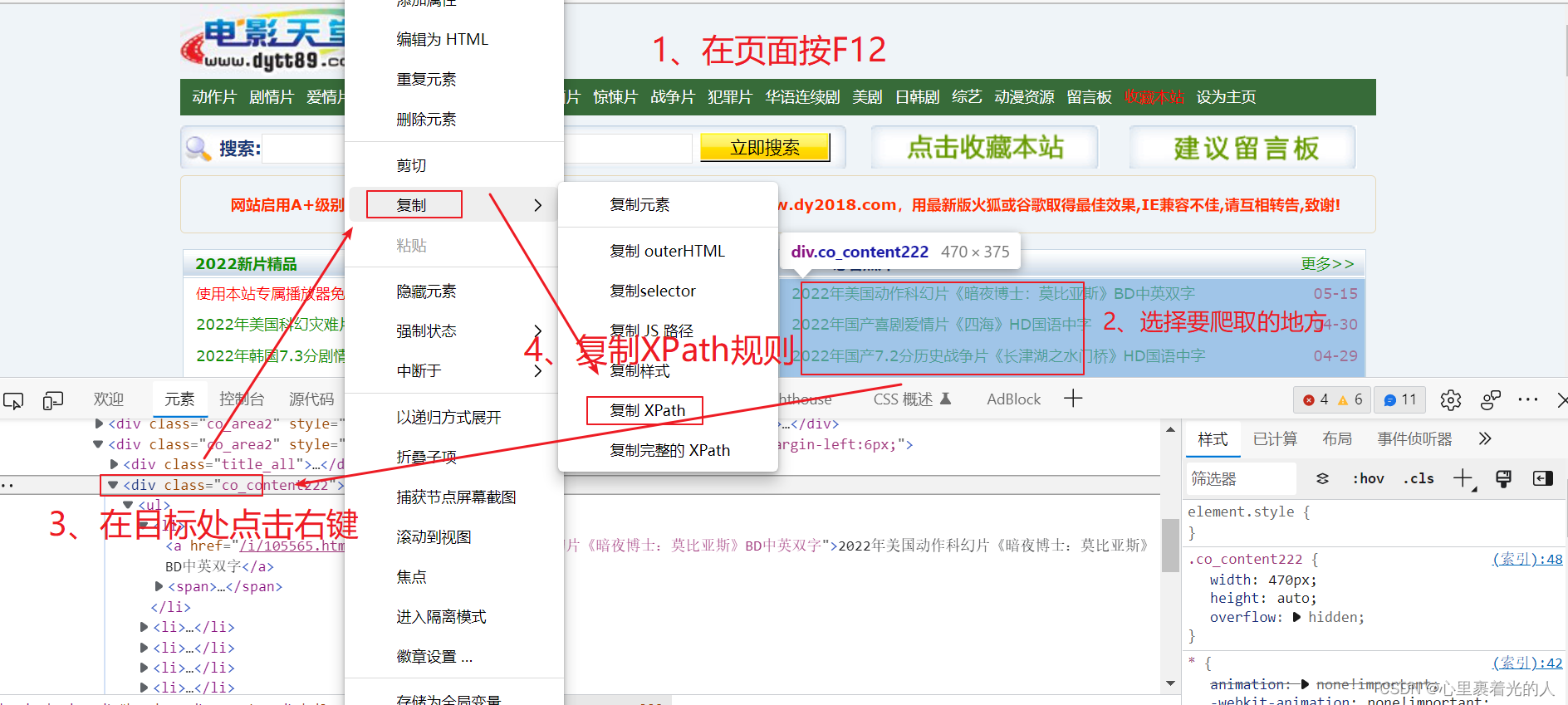
下面讲解一下2个核心参数
//这个是要爬取的网站
String html= "https://www.dytt89.com/";
//这个是xpath规则,可以直接在网页获取,下面是获取方法
String str = "//*[@id=\"header\"]/div/div[3]/div[4]/div[2]/div[2]/ul";
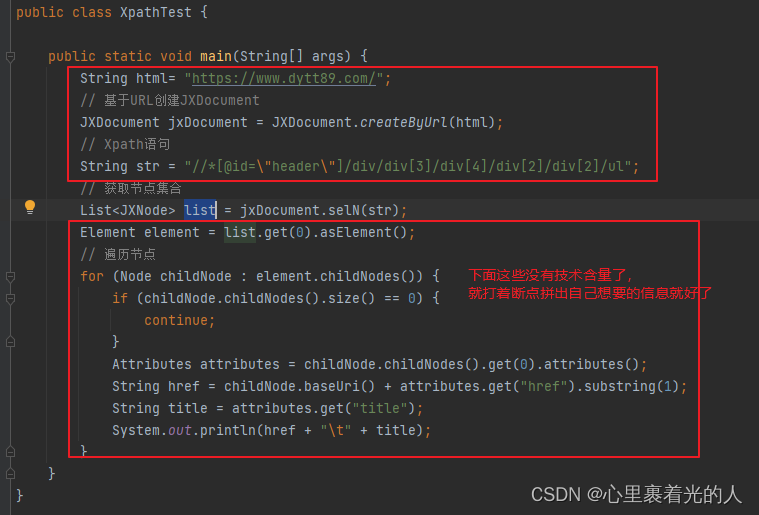
代码其实没啥东西,可以拆成两部分
- 我上面讲的2个参数
- 拼接自己需要的数据
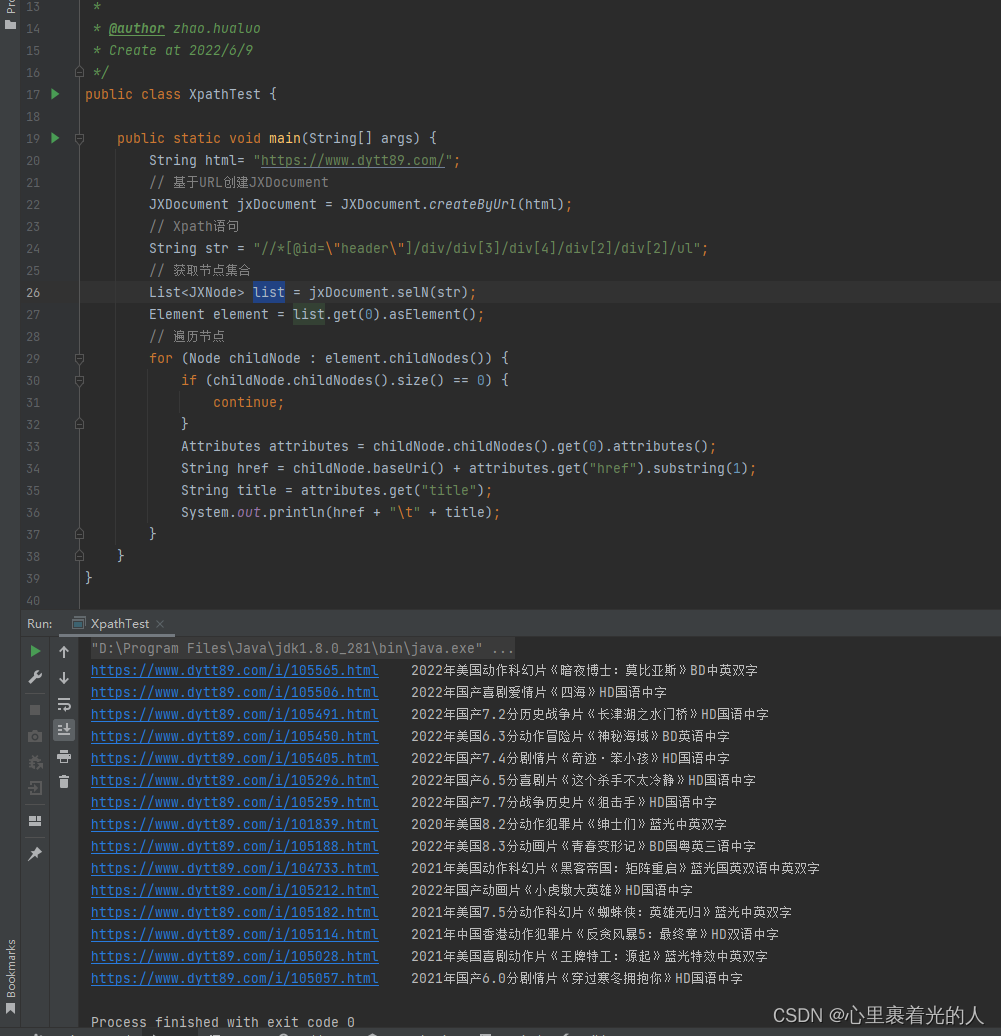
代码执行结果如下:















 2332
2332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









