







第四章 分组
学习参考:https://github.com/datawhalechina/joyful-pandas
Ex1:汽车数据集
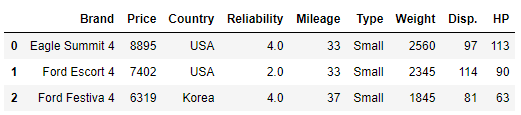
现有一份汽车数据集,其中Brand, Disp., HP分别代表汽车品牌、发动机蓄量、发动机输出。
import numpy as np
import pandas as pd
df = pd.read_csv('../data/car.csv')
df.head(3)
- 先过滤出所属
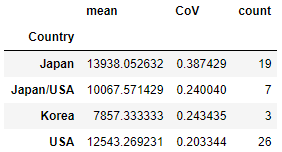
Country数超过2个的汽车,即若该汽车的Country在总体数据集中出现次数不超过2则剔除,再按Country分组计算价格均值、价格变异系数、该Country的汽车数量,其中变异系数的计算方法是标准差除以均值,并在结果中把变异系数重命名为CoV。 - 按照表中位置的前三分之一、中间三分之一和后三分之一分组,统计
Price的均值。 - 对类型
Type分组,对Price和HP分别计算最大值和最小值,结果会产生多级索引,请用下划线把多级列索引合并为单层索引。 - 对类型
Type分组,对HP进行组内的min-max归一化。 - 对类型
Type分组,计算Disp.与HP的相关系数。
#1. 过滤出所属Country数超过2个的汽车,再按Country分组计算价格均值、价格变异系数、该Country的汽车数量
df1 = df.groupby("Country").filter(lambda x:x.shape[0]>2)
df1.shape
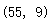
df1.groupby('Country')['Price'].agg(['mean',('CoV',lambda x:x.std()/x.mean()),'count'])
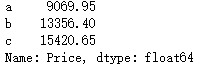
#2.按照表中位置的前三分之一、中间三分之一和后三分之一分组,统计Price的均值
length = df.shape[0] # 60
copy_num = int(length/3)
location = ["a"]*int(copy_num)+["b"]*int(copy_num)+["c"]*(length-2*copy_num)
df.groupby(location)['Price'].mean()
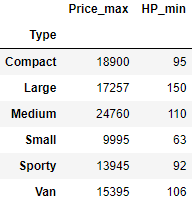
#3.对类型Type分组,对Price和HP分别计算最大值和最小值,结果会产生多级索引,请用下划线把多级列索引合并为单层索引。
df2 = df.groupby('Type').agg({'Price':['max'],'HP':['min']})
df2.columns = ['Price_max','HP_min']
df2
#答案做法:
df3 = df.groupby('Type').agg({'Price':['max'],'HP':['min']})
df3.columns = df3.columns.map(lambda x:'_'.join(x))
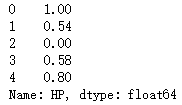
#4.对类型Type分组,对HP进行组内的min-max归一化。
df4 = df.groupby('Type')['HP'].transform(lambda x:(x-x.min())/(x.max()-x.min()))
df4.head()
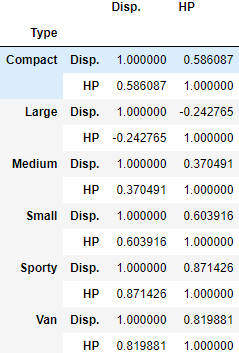
#5.对类型Type分组,计算Disp.与HP的相关系数。
df5 = df.groupby('Type')[['Disp.','HP']].corr()
df5
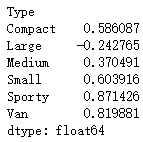
#答案做法:
df6 = df.groupby('Type')[['Disp.','HP']].apply(lambda x:
np.corrcoef(x['HP'].values,x['Disp.'].values)[0,1])
df6 #结果得到的是Series对象















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









