







第六章 连接
学习参考:https://github.com/datawhalechina/joyful-pandas
Ex1:美国疫情数据集
现有美国4月12日至11月16日的疫情报表,请将New York的Confirmed, Deaths, Recovered, Active合并为一张表,索引为按如下方法生成的日期字符串序列:
date = pd.date_range('20200412', '20201116').to_series()
date = date.dt.month.astype('string').str.zfill(2) +'-'+ date.dt.day.astype('string').str.zfill(2) +'-'+ '2020'
date = date.tolist()
date[:5]
#示例数据:
file = "../data/us_report/"+"04-12-2020"+".csv"
!head -n 5 $file
Province_State,Country_Region,Last_Update,Lat,Long_,Confirmed,Deaths,Recovered,Active,FIPS,Incident_Rate,People_Tested,People_Hospitalized,Mortality_Rate,UID,ISO3,Testing_Rate,Hospitalization_Rate
Alabama,US,2020-04-12,23:18:15,32.3182,-86.9023,3563,93,3470,1,75.98802021,21583,437,2.610159978,84000001,USA,460.3001516,12.26494527
Alaska,US,2020-04-12,23:18:15,61.3707,-152.4044,272,8,66,264,2,45.50404936,8038,31,2.941176471,84000002,USA,1344.711576,11.39705882
Arizona,US,2020-04-12,23:18:15,33.7298,-111.4312,3542,115,3427,4,48.66242224,42109,3.246753247,84000004,USA,578.5222863,
Arkansas,US,2020-04-12,23:18:15,34.9697,-92.3731,1280,27,367,1253,5,49.43942261,19722,130,2.109375,84000005,USA,761.7533537,10.15625

文件格式规范,最直接的思路是用文件读写的方法获取目的数据:
%%timeit
ny_plague = "../data/ny_plague.csv"
of = open(ny_plague,"w")
of.write("date,Confirmed,Deaths,Recovered,Active\n")
for i in date:
flag = 0
f = "../data/us_report/"+i+".csv"
with open(f) as f:
for line in f:
if flag == 0:
flag += 1
continue
line_list = line.strip().split(",")
city = line_list[0]
if city == "New York":
Confirmed = line_list[5]
Deaths = line_list[6]
Recovered = line_list[7]
Active = line_list[8]
of.write(','.join([i,Confirmed,Deaths,Recovered,Active])+"\n")
break
of.close()
df = pd.read_csv(ny_plague)
41.2 ms ± 457 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
df.head(5)
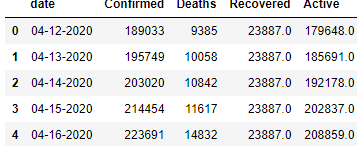
答案提供了更加简洁的思路,但速度慢了一个数量接
%%timeit
res = []
for i in date:
f = "../data/us_report/"+i+".csv"
df = pd.read_csv(f, index_col='Province_State')
ny = df.loc['New York',['Confirmed','Deaths','Active','Recovered']]
res.append(ny.to_frame().T)
dt = pd.concat(res)
dt.index = date
726 ms ± 3.26 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
dt.head(5)
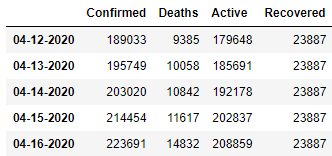















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









