






摘要: Requests 和 Scrapy 中的代理 IP 设置方法。
目标测试网页如下,请求该网页可以返回当前 IP 地址:
先来说说 Requests 中如何设置代理 IP。
▌不使用代理
先来看一下不使用代理 IP 的情况:
import requests
url = 'http://icanhazip.com'
try:
response = requests.get(url) #不使用代理
print(response.status_code)
if response.status_code == 200:
print(response.text)
except requests.ConnectionError as e:
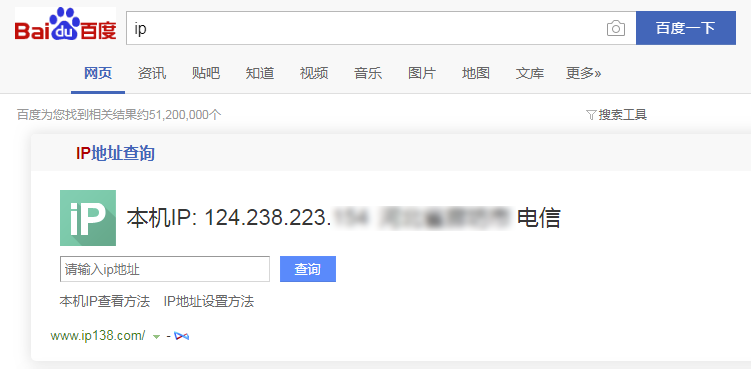
print(e.args)运行上面的程序,会返回我们电脑本机的 IP,可以通过百度查询 IP 地址对比一下就知道了。
200
124.238.223.xxx # 后三位隐去了
[Finished in 0.8s]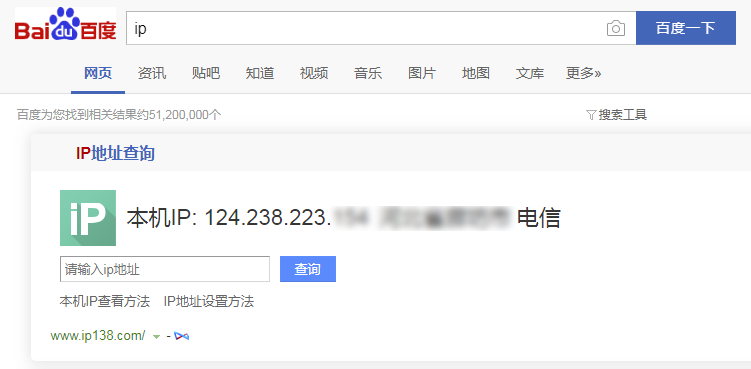
▌使用代理
然后我们测试一下使用代理后的情况。
常见的代理包括 HTTP 代理和 SOCKS5 代理,前者可以找一些免费代理 IP 进行测试,由于我电脑上使用的是 Shadowsocks,所以就介绍一下 SOCKS5 代理的设置。
启动该软件后默认会在 1080 端口下创建 SOCKS5 代理服务,代理为:127.0.0.1:1080,然后我们在 Requests 中使用该代理,方法很简单只需要添加一项 proxies 参数即可:
proxies = [
{'http':'socks5://127.0.0.1:1080'},
{'https':'socks5://127.0.0.1:1080'}
]
proxies = random.choice(proxies)
print(proxies)
url = 'http://icanhazip.com'
try:
response = requests.get(url,proxies=proxies) #使用代理
print(response.status_code)
if response.status_code == 200:
print(response.text)
except requests.ConnectionError as e:
print(e.args)这里,proxies 参数是字典类型,键名'http' 表示协议类型,键值 'socks5://127.0.0.1:1080'表示代理,这里添加了 http 和 https 两个代理,这样写是因为有些网页采用 http 协议,有的则是采用 https 协议,为了在这两类网页上都能顺利使用代理,所以一般都同时写上,当然,如果确定了某网页的请求类型,可以只写一种,比如这里我们请求的 url 使用的是 http 协议,那么使用 http 代理就可以,random 函数用来随机选择一个代理,我们来看一下结果:
{'http': 'socks5://127.0.0.1:1080'}
200
45.78.42.xxx #xxx表示隐去了部分信息可以看到,这里随机选择了 http 协议的代理后,返回的 IP 就是我真实的 IP 代理地址,成功代理后就可以爬一些墙外的网页了。
延伸一下,假如随机选择的是 https 代理,那么返回的 IP 结果还一样么?我们尝试重复运行一下上面的程序:
{'https': 'socks5://127.0.0.1:1080'}
200
124.238.223.xxx可以看到这次使用了 https 代理,返回的 IP 却是本机的真实 IP,也就是说代理没有起作用。
进一步地,我们将 url 改为 https 协议 'https://icanhazip.com',然后再尝试分别用 http 和 https 代理请求,查看一下结果:
#http 请求
{'http': 'socks5://127.0.0.1:1080'}
200
124.238.223.xxx
#https 请求
{'https': 'socks5://127.0.0.1:1080'}
200
45.78.42.xxx可以看到,两种请求的结果和之前的刚好相反了,由于 url 采用了 https 协议,则起作用的是 https 代理,而 http 代理则不起作用了,所以显示的是本机 IP。
因此,可以得到这样的一个结论:
HTTP 代理,只代理 HTTP 网站,对于 HTTPS 的网站不起作用,也就是说,用的是本机 IP。
HTTPS 代理则同理。
▌使用付费代理
上面,我们只使用了一个代理,而在爬虫中往往需要使用多个代理,那有如何构造呢,这里主要两种方法:
- 一种是使用免费的多个 IP;
- 一种是使用付费的 IP 代理;
免费的 IP 往往效果不好,那么可以搭建 IP 代理池,但对新手来说搞一个 IP 代理池成本太高,如果只是个人平时玩玩爬虫,完全可以考虑付费 IP,几块钱买个几小时动态 IP,多数情况下都足够爬一个网站了。
这里推荐一个付费代理「阿布云代理」,效果好也不贵,如果你不想费劲地去搞 IP 代理池,那不妨花几块钱轻松解决。
首次使用的话,可以选择购买一个小时的动态版试用下,点击生成隧道代理信息作为凭证加入到代码中。
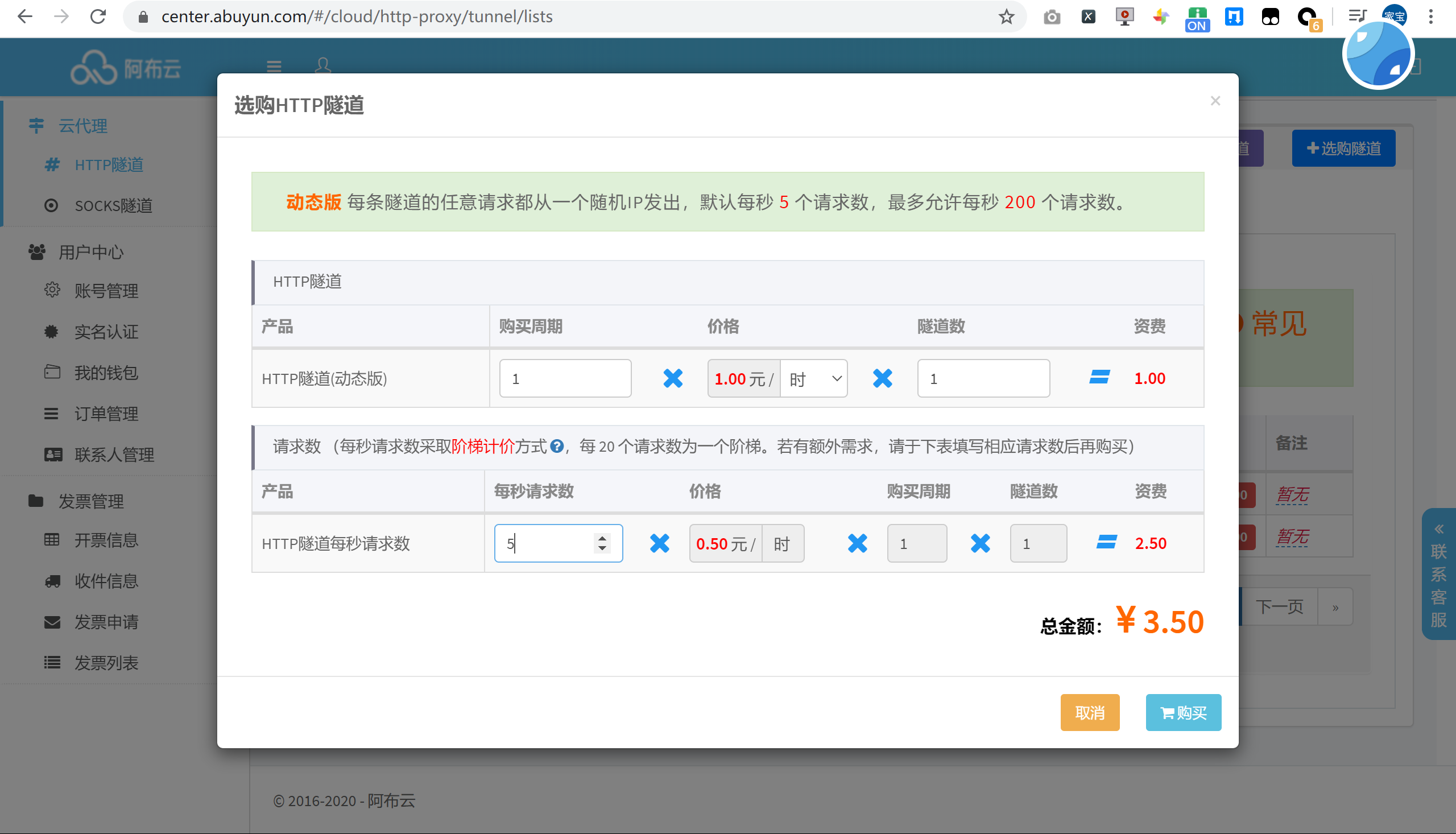
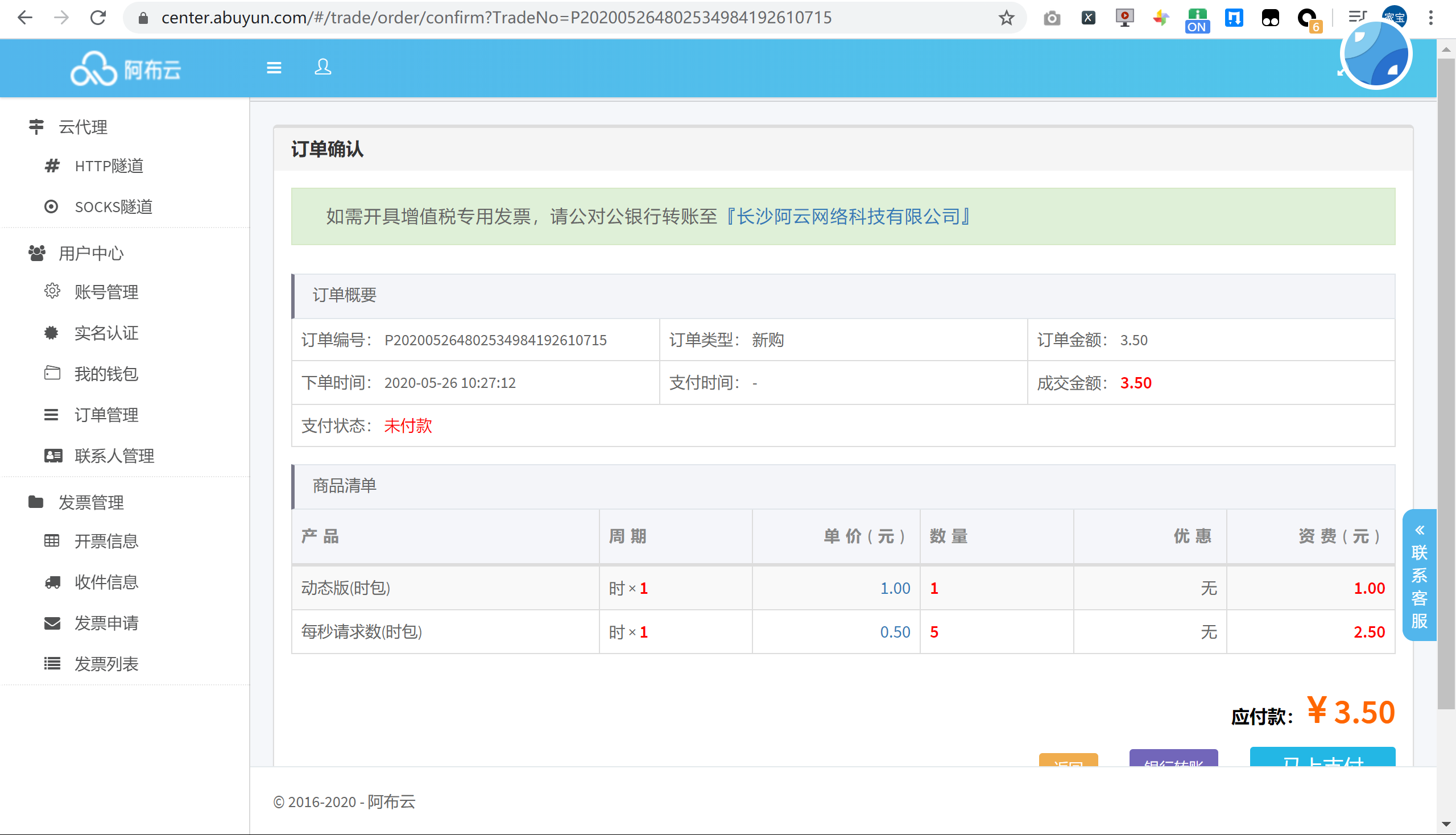
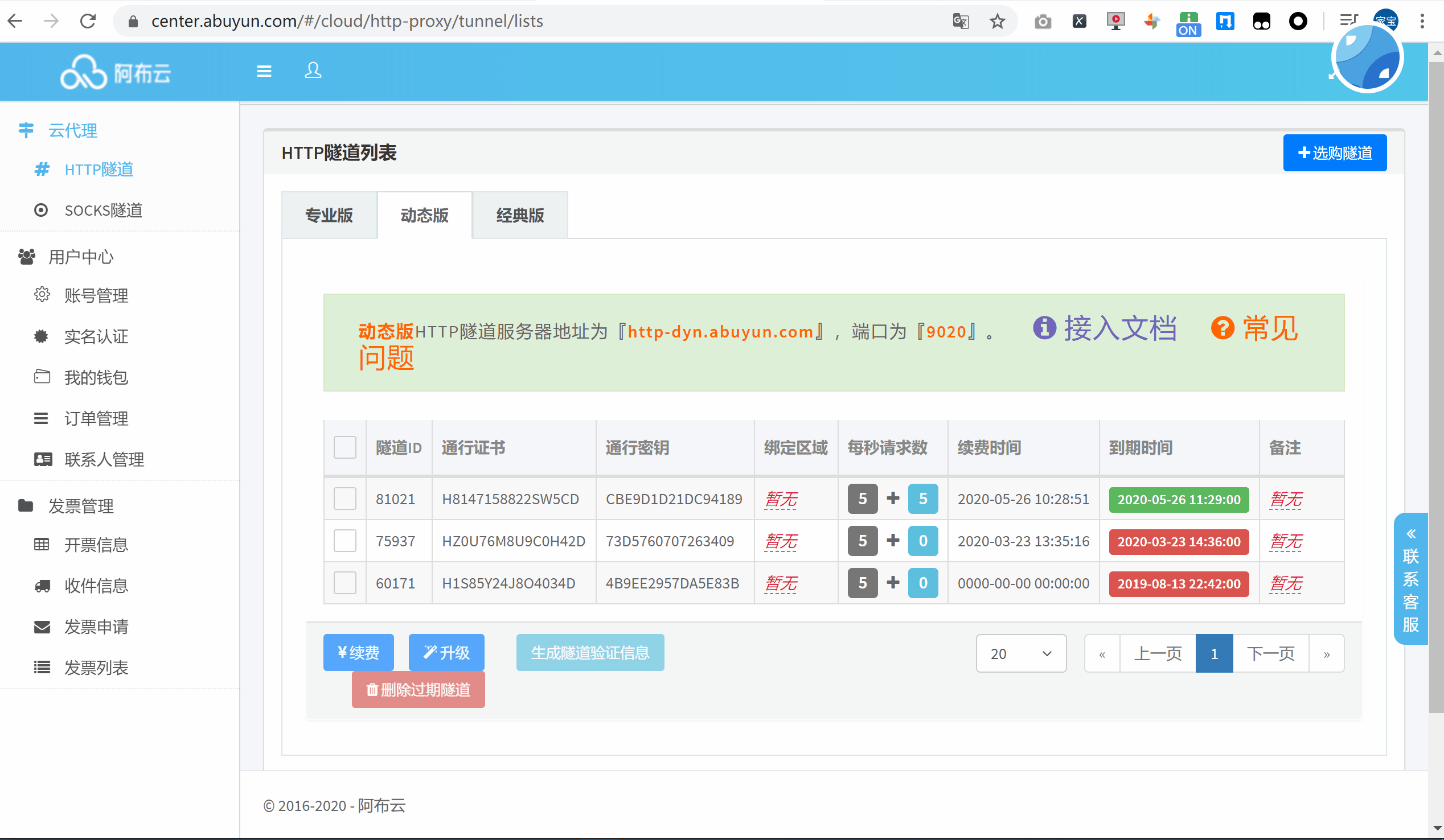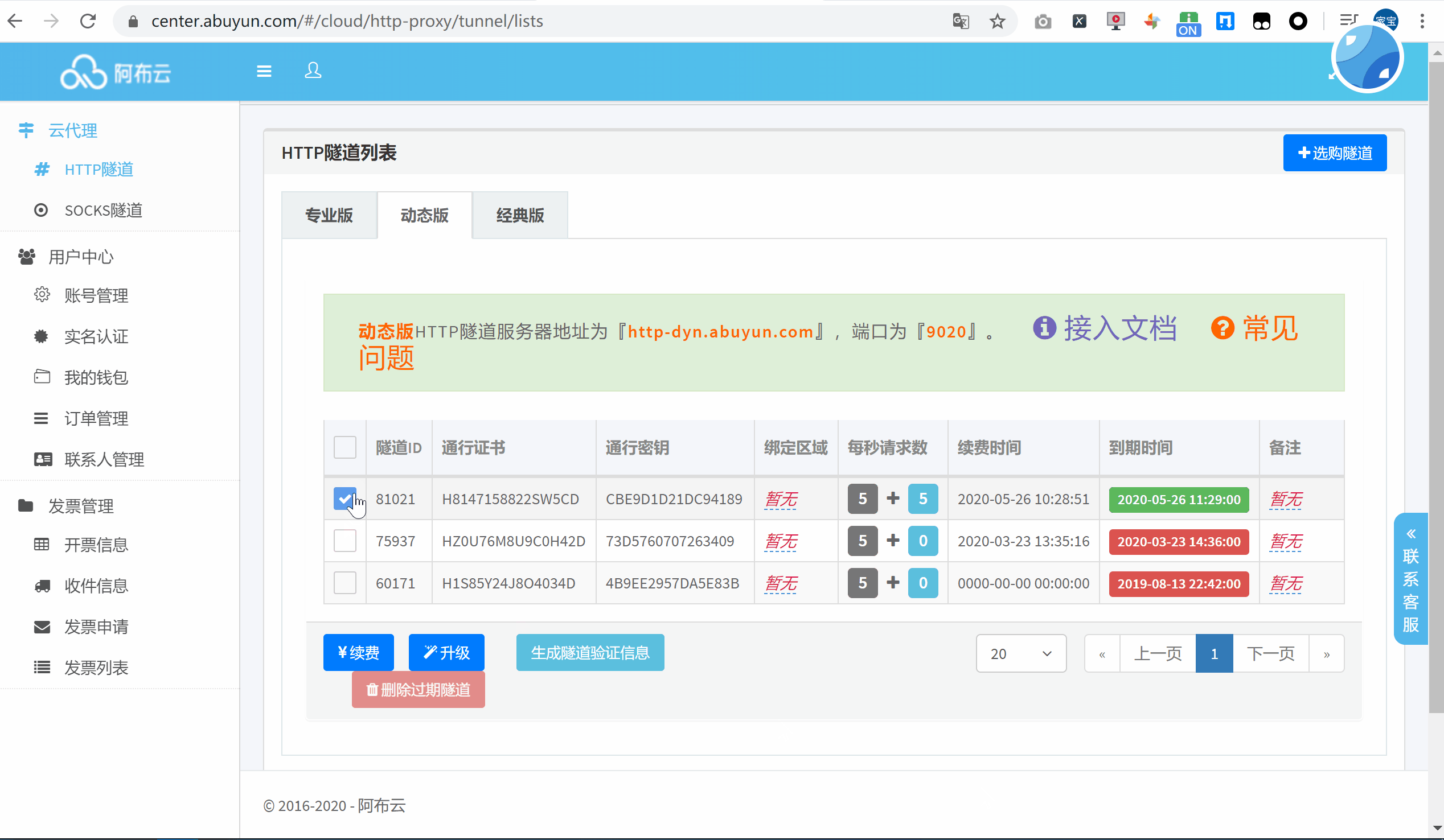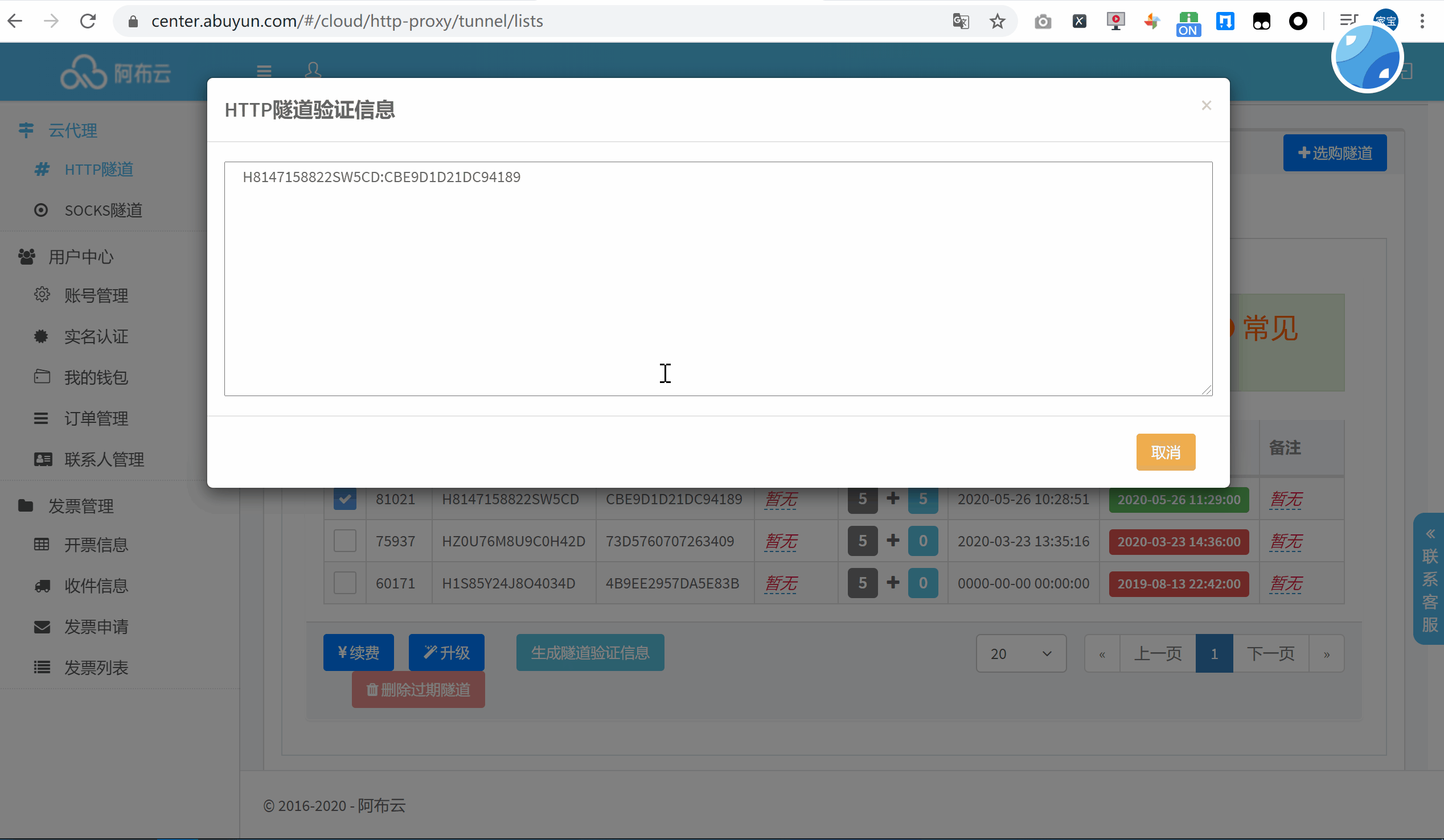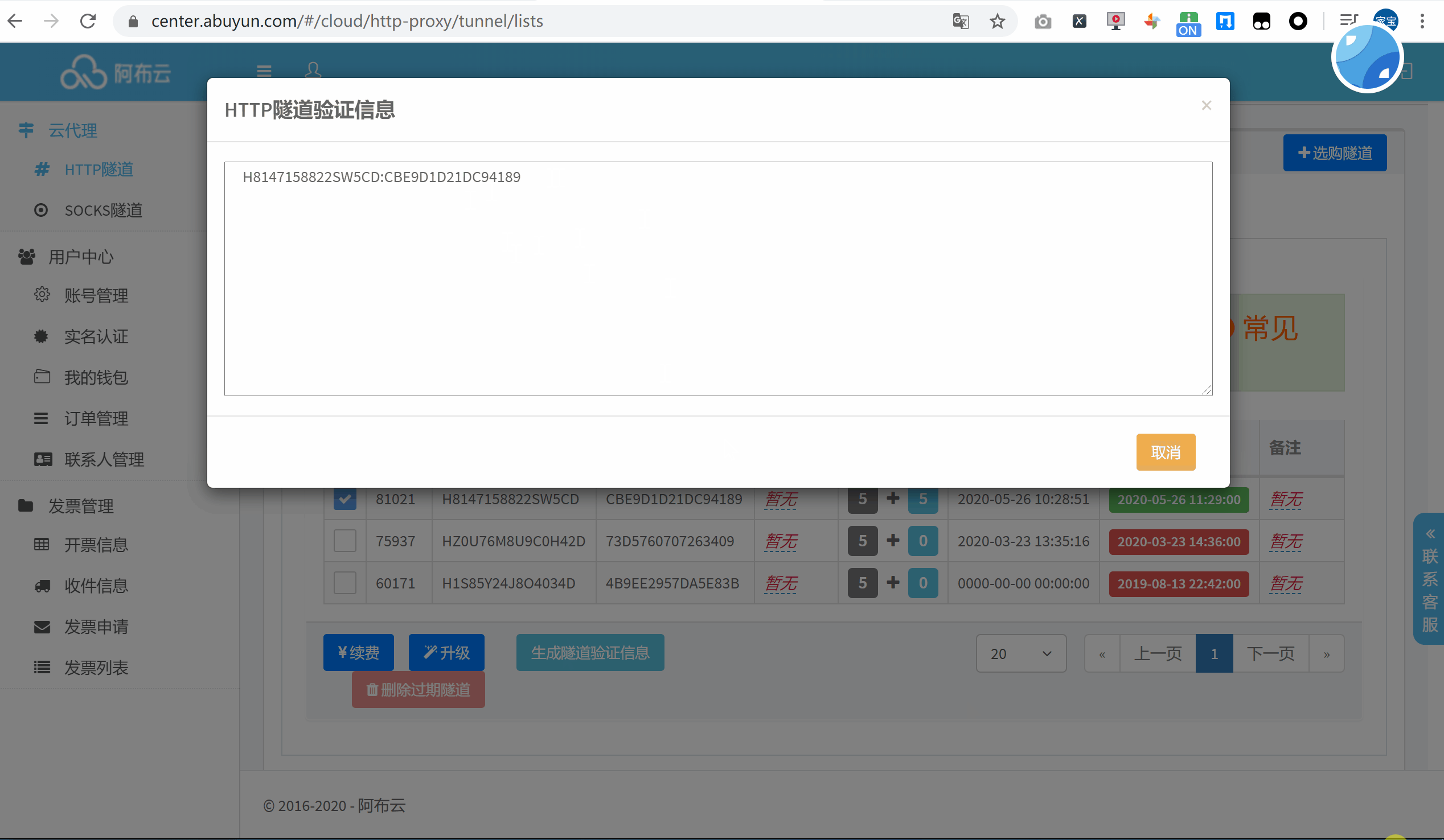
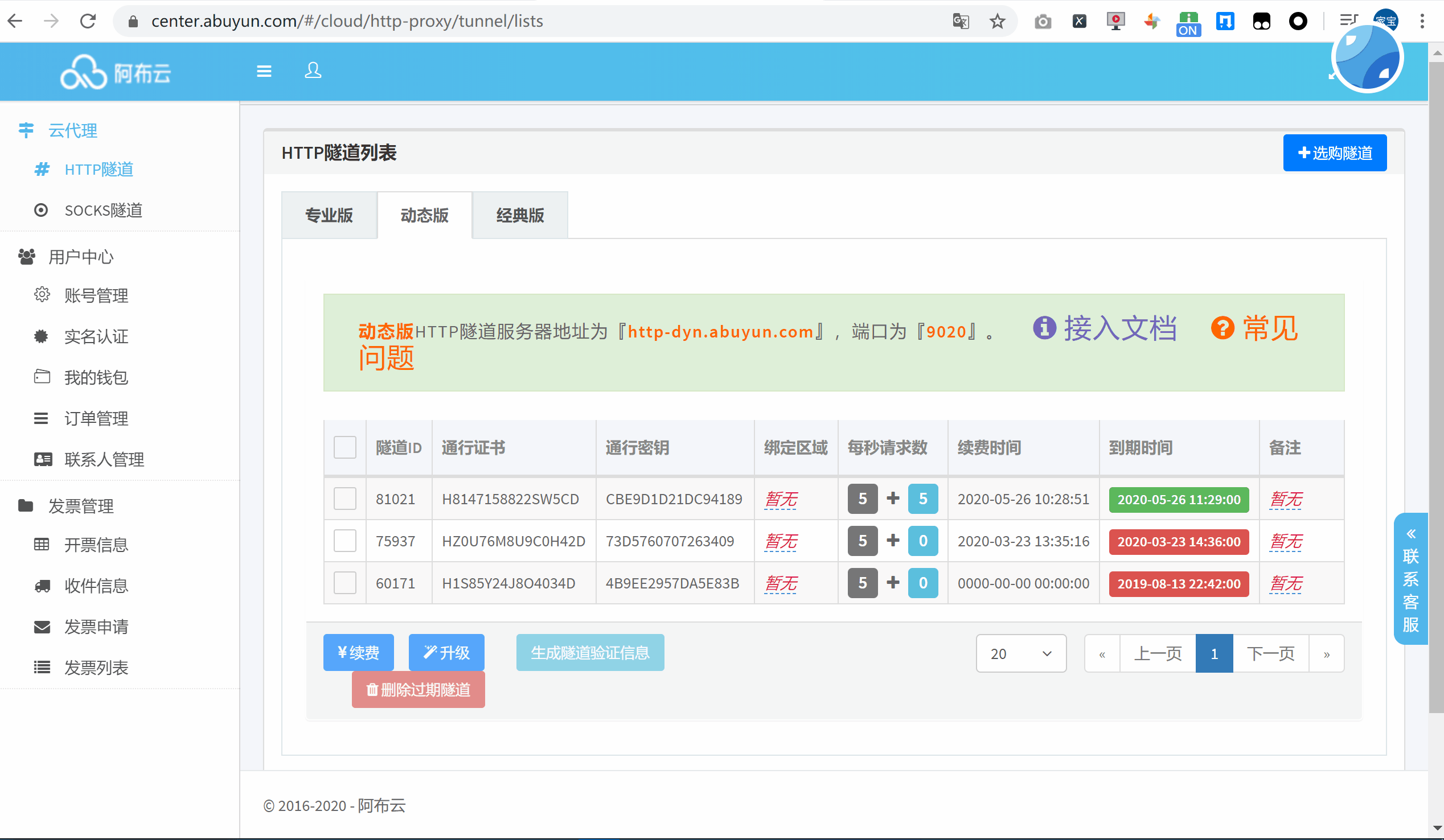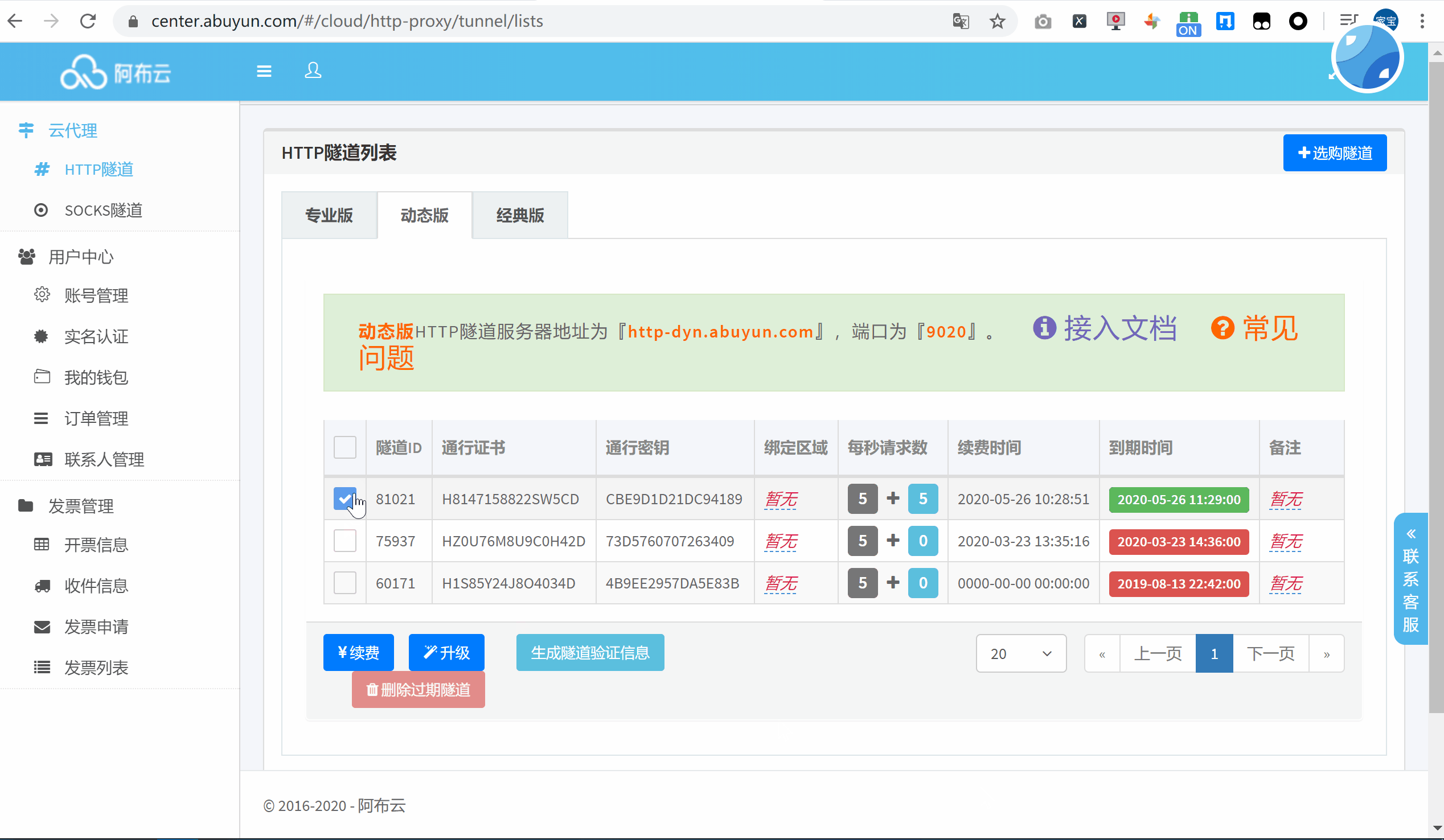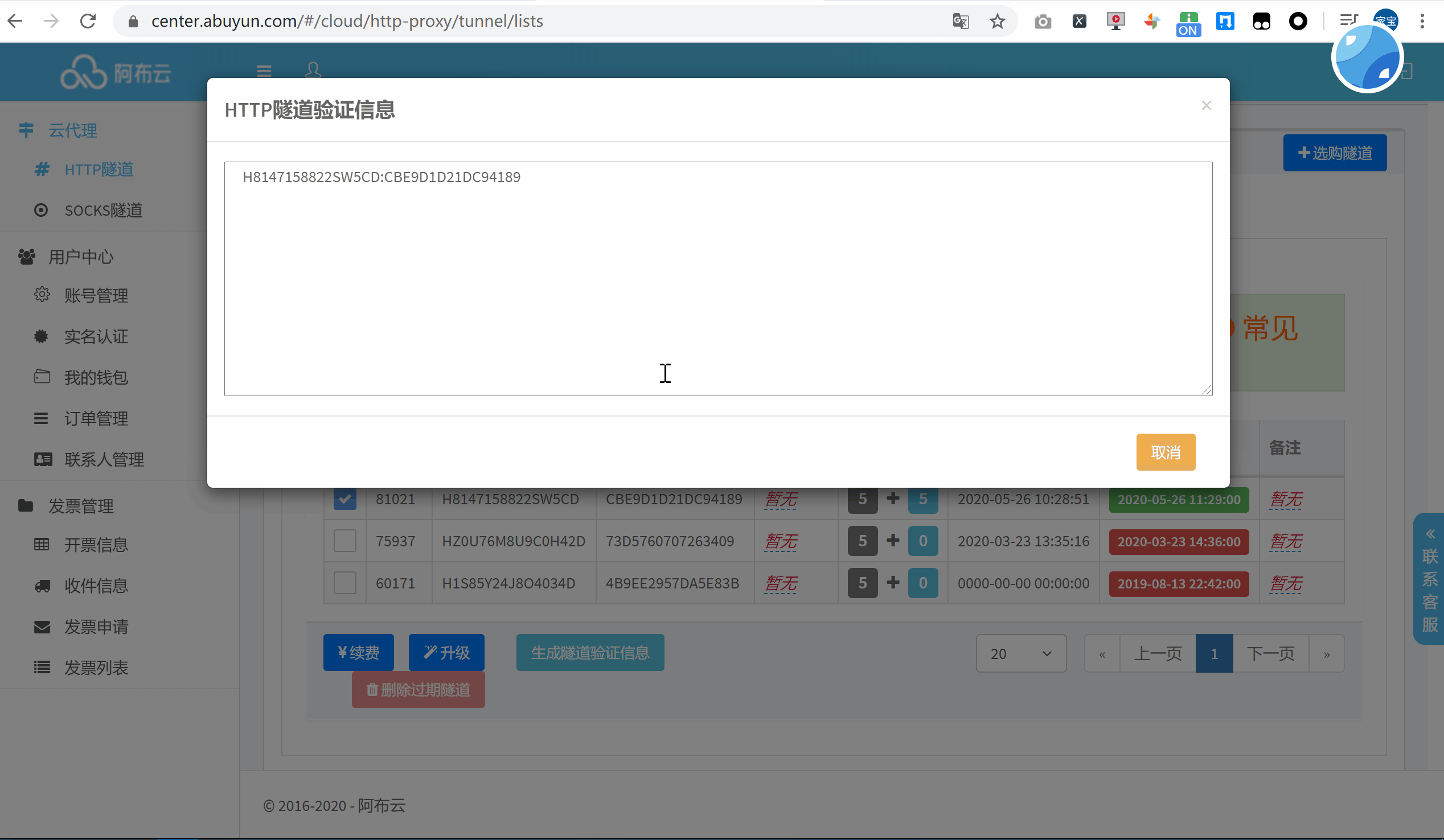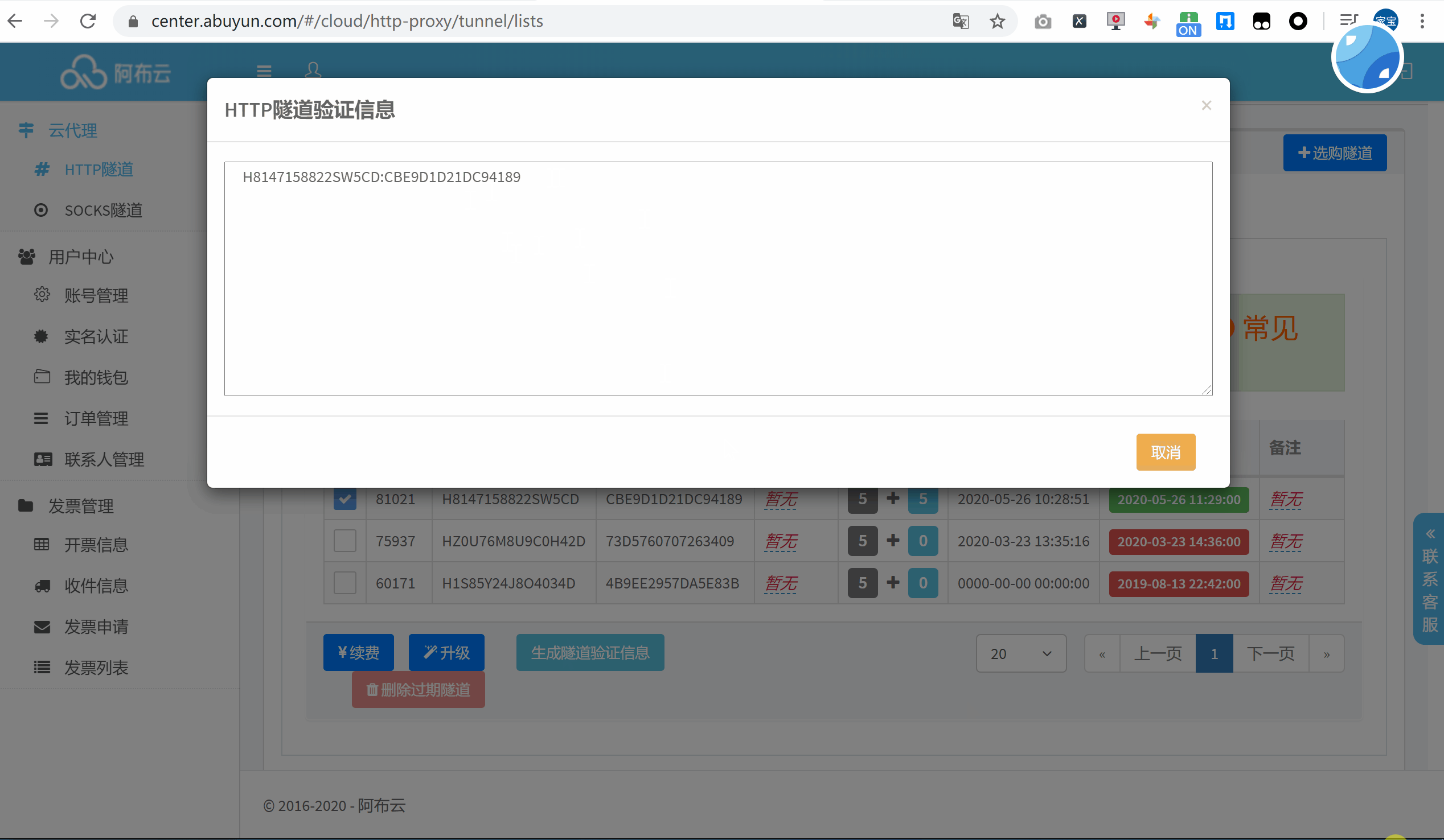
将信息复制到官方提供的 Requests 代码中,运行来查看一下代理 IP 的效果:
import requests
# 待测试目标网页
targetUrl = "http://icanhazip.com"
def get_proxies():
# 代理服务器
proxyHost = "http-dyn.abuyun.com"
proxyPort = "9020"
# 代理隧道验证信息
proxyUser = "H8147158822SW5CD"
proxyPass = "CBE9D1D21DC94189"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
for i in range(1,6):
resp = requests.get(targetUrl, proxies=proxies)
# print(resp.status_code)
print('第%s次请求的IP为:%s'%(i,resp.text))
get_proxies()可以看到每次请求都会使用不同的 IP,是不是很简单?比搞 IP 代理池省事多了。
第1次请求的IP为:125.117.134.158
第2次请求的IP为:49.71.117.45
第3次请求的IP为:112.244.117.94
第4次请求的IP为:122.239.164.35
第5次请求的IP为:125.106.147.24
[Finished in 2.8s]当然,还可以这样设置:
"""
project = 'Code', file_name = 'lession', author = 'AI悦创'
time = '2020/5/26 10:36', product_name = PyCharm, 公众号:AI悦创
code is far away from bugs with the god animal protecting
I love animals. They taste delicious.
"""
import requests
# 112.48.28.233
url = 'http://icanhazip.com'
# 下面的 try:......except:......是一个防错机制
# username:password@代理服务器ip地址:port
proxy = {'http':'http://H8147158822SW5CD:CBE9D1D21DC94189@http-dyn.abuyun.com:9020'}
try:
response = requests.get(url, proxies = proxy)
print(response.status_code)
if response.status_code == 200:
print(response.text)
except requests.ConnectionError as e:
# 如果报错,则输出报错信息
print(e.args)以上,介绍了 Requests 中设置代理 IP 的方法,下面我们接着介绍在 Scrapy 中如何设置。
▌middlewares.py 中设置
这种方法需要先在 middlewares.py 中设置代理 IP 中间件:
import random
class ProxyMiddleware(object):
def __init__(self, ip):
self.ip = ip
@classmethod
def from_crawler(cls, crawler):
return cls(ip=crawler.settings.get('PROXIES'))
def process_request(self, request, spider):
ip = random.choice(self.ip)
request.meta['proxy'] = ip
logging.debug('Using Proxy:%s'%ip)接着,需要在 settings.py 添加几个在西刺上找的代理 IP,格式如下:
PROXIES = [
'https://127.0.0.1:8112',
'https://119.101.112.176:9999',
'https://119.101.115.53:9999',
'https://119.101.117.226:9999']然后,我们仍然以 "http://icanhazip.com" 为目标网页,运行 Scrapy 项目重复请求 5 次,查看一下每次返回的 IP 情况:
def start_requests(self):
items = []
for i in range(1,6):
item = yield scrapy.Request(self.cate_url,callback=self.get_category)
items.append(item)
return items
def get_category(self, response):
print(response.text)结果如下:
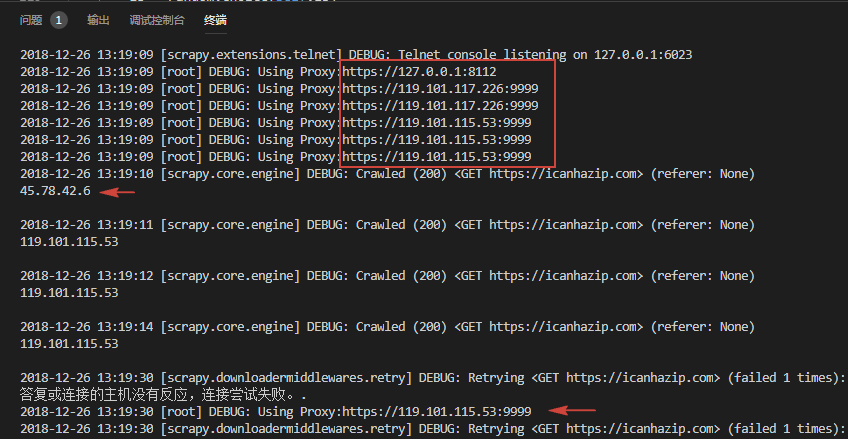
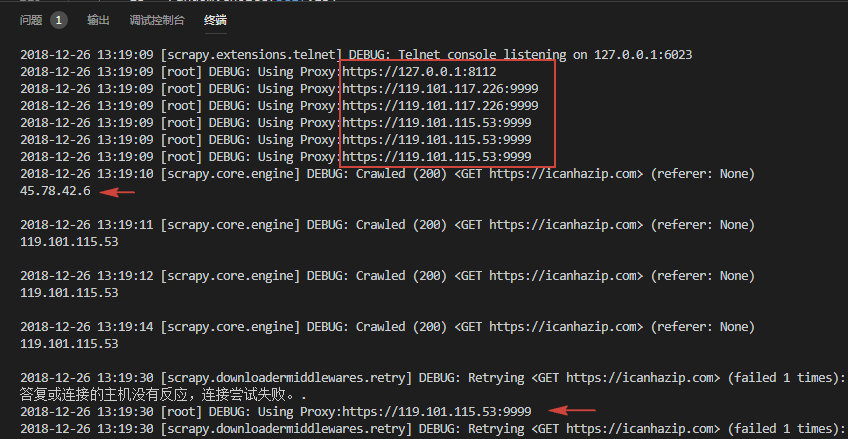
可以看到部分 IP 成功请求得到了相应,部分 IP 则无效请求失败,因为这几个 IP 是免费的 IP,所有失效很正常。
▌使用付费代理
接下来我们使用阿布云付费代理,继续尝试一下,在 middlewares.py 中添加下面的代码:
""" 阿布云ip代理配置,包括账号密码 """
# 阿布云scrapy 写法
import base64
proxyServer = "http://http-dyn.abuyun.com:9020"
proxyUser = "HS77K12Q77V4G9MD" # 购买后点击生成获得
proxyPass = "4131FFDFCE27F104" # 购买后点击生成获得
# for Python3
proxyAuth = "Basic " + base64.urlsafe_b64encode(bytes((proxyUser + ":" + proxyPass), "ascii")).decode("utf8")
class AbuyunProxyMiddleware(object):
""" 阿布云ip代理配置 """
def process_request(self, request, spider):
request.meta["proxy"] = proxyServer
request.headers["Proxy-Authorization"] = proxyAuth
logging.debug('Using Proxy:%s'%proxyServer)由于,在阿布云购买的是最基础的代理,即每秒 5 个请求,因为 Scrapy 默认的并发数是 16 个,所以需要对 Scrapy 请求数量进行一下限制,可以设置每个请求的延迟时间为 0.2s ,这样一秒就刚好请求 5 个,最后启用上面的代理中间件类即可:
""" 启用限速设置 """
AUTOTHROTTLE_ENABLED = True
DOWNLOAD_DELAY = 0.2 # 每次请求间隔时间
DOWNLOADER_MIDDLEWARES = {
#'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #启用随机UA
#'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 100, #启用随机UA
'wandoujia.middlewares.AbuyunProxyMiddleware': 200, # 启用阿布云代理
#value值越小优先级越高
}然后同样地请求 5 次,查看每次请求返回的 IP :
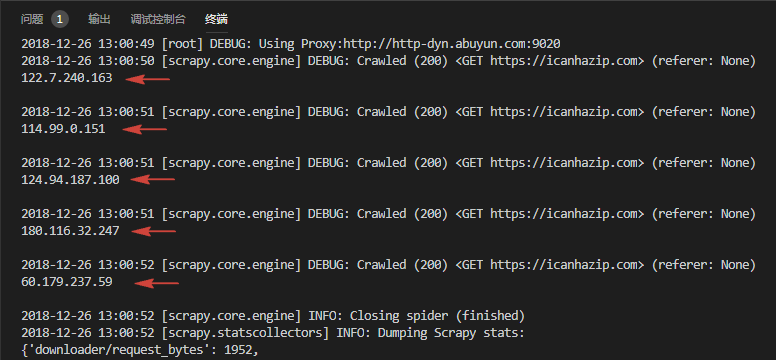
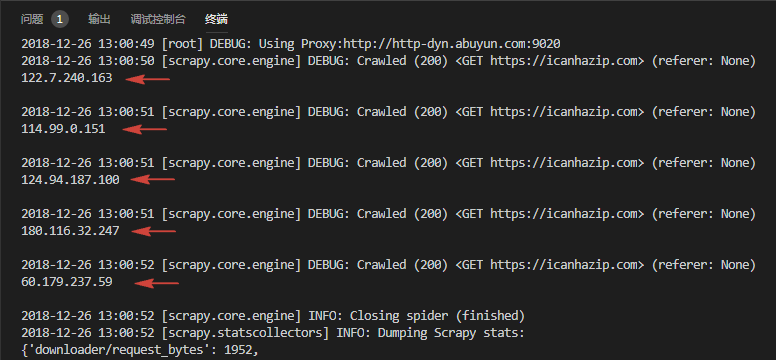
可以看到,每个 IP 都顺利请求成功了,所以说付费地效果还是好。
▌使用 scrapy-proxies 库代理
除了上述两种方法,我们还可以使用 GitHub 上的一个 IP 代理库:scrapy-proxies,库的使用方法很简单, 三个步骤就可以开启代理 IP。
首先,运行下面命令安装好这个库:
pip install scrapy_proxies然后,在 Scrapy 项目中的 settings.py 文件中,添加下面一段代码:
RETRY_TIMES = 3 # 自定义请求失败重试次数
#重试的包含的错误请求代码
RETRY_HTTP_CODES = [500, 503, 504, 400, 403, 404, 408]
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 90,
'scrapy_proxies.RandomProxy': 100,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
}
PROXY_LIST = r'/proxies.txt' # proxy 代理文件存放位置,此处为程序所在磁盘根目录下
PROXY_MODE = 0 # 每次请求都使用不同的代理最后,需要提供多个代理 IP,我们在西刺上随便找几个 IP,然后存放在 PROXY_LIST 指定的 txt 文件中即可,格式如下:
https://119.101.112.176:9999
https://119.101.115.53:9999
https://119.101.117.53:999然后重复之前的操作,查看代理 IP 的设置效果。
我在使用该库的过程中,发现有一些问题,不知道是配置不对还是怎么回事,效果不是太好,所以推荐使用前两种方法。
好,以上就是在 Requests 和 Scrapy 中使用代理 IP 的方法总结,如果爬虫项目不大、追求稳定且不差钱的话,建议直接上付费代理。
















 4460
4460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











