







shardingsphere mybatisplus properties和yml配置实现
目录结构
model
package com.oujiong.entity;
import com.baomidou.mybatisplus.annotation.TableName;
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import org.springframework.format.annotation.DateTimeFormat;
import java.util.Date;
/**
* user表
*/
@TableName("user")
@Data
public class User {
/**
* 主键
*/
private Long id;
/**
* 姓名
*/
private String name;
/**
* 性别
*/
private String sex;
/**
* 年龄
*/
private Integer age;
/**
*
*/
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date createTime;
/**
*
*/
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date updateTime;
/**
* 是否删除 1删除 0未删除
*/
private Integer status;
public User(Long id, String name, String sex, Integer age) {
this.id = id;
this.name = name;
this.sex = sex;
this.age = age;
}
}
mapper
package com.oujiong.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.oujiong.entity.User;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
/**
* @Description: 用户mapper
*/
@Mapper
public interface UserMapper extends BaseMapper<User> {
/**
* 批量插入
*
* @param list 插入集合
* @return 插入数量
*/
int insertForeach(List<User> list);
/**
* 获取所有用户
*/
List<User> selectAll();
}
servie
package com.oujiong.service;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.oujiong.entity.User;
import com.oujiong.mapper.UserMapper;
import org.springframework.web.bind.annotation.PathVariable;
import java.util.List;
/**
* @Description: 用户相关接口
*
*/
public interface UserService {
/**
* 获取所有用户信息
*/
List<User> list();
/**
* 批量 保存用户信息
*
* @param userVOList
*/
String insertForeach(List<User> userVOList);
IPage<User> pageUser(Integer currentPage, Integer pageSize);
}
seviceImp
package com.oujiong.service.impl;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.oujiong.entity.User;
import com.oujiong.mapper.UserMapper;
import com.oujiong.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* @Description: 用户实现类
*/
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Autowired
private UserMapper userMapper;
@Override
public List<User> list() {
// List<User> users =new ArrayList<>();
// users= this.lambdaQuery().orderByAsc(User::getAge).list();
// User user = userMapper.selectById(102);
// users.add(user);
List<User> users = userMapper.selectAll();
return users;
}
@Override
public String insertForeach(List<User> userList) {
for (User user : userList) {
user.setCreateTime(new Date());
user.setUpdateTime(new Date());
user.setStatus(0);
userMapper.insert(user);
}
// //批量插入数据
// userMapper.insertForeach(userList);
return "保存成功";
}
@Override
public IPage<User> pageUser(Integer currentPage, Integer pageSize){
IPage<User> page =new Page<>();
page.setCurrent(currentPage);
page.setSize(pageSize);
IPage<User> users= this.lambdaQuery().orderByAsc(User::getAge).page(page);
return users;
}
}
Application
package com.oujiong;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @Description: 启动类
*
* @author xub
* @date 2019/10/08 下午6:33
*/
@MapperScan("com.oujiong.mapper.**")
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
分页配置
package com.oujiong.config;
import com.baomidou.mybatisplus.extension.plugins.PaginationInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
}
mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.oujiong.mapper.UserMapper">
<resultMap id="BaseResultMap" type="com.oujiong.entity.User">
<id column="id" jdbcType="BIGINT" property="id" />
<result column="name" jdbcType="VARCHAR" property="name" />
<result column="sex" jdbcType="VARCHAR" property="sex" />
<result column="age" jdbcType="INTEGER" property="age" />
<result column="create_time" jdbcType="TIMESTAMP" property="createTime" />
<result column="update_time" jdbcType="TIMESTAMP" property="updateTime" />
<result column="status" jdbcType="INTEGER" property="status" />
</resultMap>
<sql id="Base_Column_List">
id, name, sex, age, create_time, update_time, status
</sql>
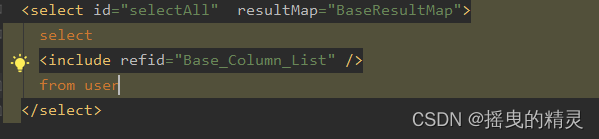
<select id="selectAll" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from user
</select>
<insert id="insertForeach" parameterType="java.util.List" useGeneratedKeys="false">
insert into user (id, name, sex,
age, create_time, update_time,
status)
values
<foreach collection="list" item="item" index="index" separator=",">
(#{item.id,jdbcType=BIGINT}, #{item.name,jdbcType=VARCHAR}, #{item.sex,jdbcType=VARCHAR},
#{item.age,jdbcType=INTEGER}, #{item.createTime,jdbcType=TIMESTAMP}, #{item.updateTime,jdbcType=TIMESTAMP},
#{item.status,jdbcType=INTEGER})
</foreach>
</insert>
</mapper>
properties和yml配置 目录结构和java文件配置都一致
properties
server.port=8088
#指定mybatis信息
mybatis.config-location=classpath:mybatis-config.xml
## 一个实体类对应多张表,覆盖
spring.main.allow-bean-definition-overriding=true
#数据库
spring.shardingsphere.datasource.names=master0,slave0
spring.shardingsphere.datasource.master0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master0.url=jdbc:mysql://139.155.6.193:3306/test?characterEncoding=utf-8
spring.shardingsphere.datasource.master0.username=root
spring.shardingsphere.datasource.master0.password=MyNewPass4!
spring.shardingsphere.datasource.slave0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave0.url=jdbc:mysql://139.155.237.188:3306/test?characterEncoding=utf-8
spring.shardingsphere.datasource.slave0.username=root
spring.shardingsphere.datasource.slave0.password=MyNewPass4!
#数据分表规则
#指定所需分的表
spring.shardingsphere.sharding.tables.user.actual-data-nodes=master0.tab_user$->{0..1}
#指定主键
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
#分表规则为主键除以2取模
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=tab_user$->{id % 2}
# 读写分离
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
spring.shardingsphere.masterslave.name=ms
#这里配置读写分离的时候一定要记得添加主库的数据源名称 这里为master0
spring.shardingsphere.sharding.master-slave-rules.master0.master-data-source-name=master0
spring.shardingsphere.sharding.master-slave-rules.master0.slave-data-source-names=slave0
#spring.shardingsphere.sharding.binding-tables[0]=user
#spring.shardingsphere.mode.type=Memory
#spring.shardingsphere.mode.repository.type=File
#spring.shardingsphere.mode.overwrite=true
#打印sql
spring.shardingsphere.props.sql.show=true
# mybatis-plus
mybatis-plus.mapper-locations=classpath:mapper/**/*.xml
mybatis-plus.type-aliases-package=com.oujiong.entity
#打印带参数sql
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
spring.shardingsphere.sharding.tables.user注意user与实体类、xml相对应

yml
#服务器设置
server:
port: 8090
spring:
# 文件上传需要
main:
allow-bean-definition-overriding: true
shardingsphere:
# 数据库名称
datasource:
names: master0,slave0
master0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://139.155.6.193:3306/sharding_test_1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: MyNewPass4!
slave0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://139.155.6.193:3306/sharding_test_2?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: MyNewPass4!
# 配置主从规则
# ====================== ↓↓↓↓↓↓ 读写分离配置 ↓↓↓↓↓↓ ======================
master-slave-rules:
master0:
# 主库
masterDataSourceName: master0
# 从库
slaveDataSourceNames:
- slave0
# 从库查询数据的负载均衡算法 目前有2种算法 round_robin(轮询)和 random(随机)
# 算法接口 org.apache.shardingsphere.spi.masterslave.MasterSlaveLoadBalanceAlgorithm
# 实现类 RandomMasterSlaveLoadBalanceAlgorithm 和 RoundRobinMasterSlaveLoadBalanceAlgorithm
loadBalanceAlgorithmType: ROUND_ROBIN
# 配置分片规则
sharding:
tables:
user:
logicTable: tab_user
actual-data-nodes: master0.tab_user$->{0..1}
# database-strategy:
# inline:
# sharding-column: id
# algorithm-expression: master0
table-strategy:
inline:
sharding-column: id
algorithm-expression: tab_user$->{id % 2}
props:
sql:
show: true # 打印SQL
pom依赖
<properties>
<java.version>1.8</java.version>
<mybatis-spring-boot>2.0.1</mybatis-spring-boot>
<druid>1.1.16</druid>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.mybatis.spring.boot</groupId>-->
<!-- <artifactId>mybatis-spring-boot-starter</artifactId>-->
<!-- <version>${mybatis-spring-boot}</version>-->
<!-- </dependency>-->
<!--mybatis驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--druid数据源-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid}</version>
</dependency>
<!--shardingsphere最新版本-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!--lombok实体工具-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
</dependencies>
百亿级数据 分库分表 后面怎么分页查询?
1. 全局查询法
在数据拆分之后,如果还是上述的语句,在两个表中直接执行,变成如下两条SQL:
select * from t_order_1 order by time asc limit 5,5;
select * from t_order_2 order by time asc limit 5,5;
将获取的数据然后在内存中再次进行排序,那么最终的结果如下:

可以看到上述的结果肯定是不对的。
所以正确的SQL改写成如下:
select * from t_order_1 order by time asc limit 0,10;
select * from t_order_2 order by time asc limit 0,10;
也就是说,要在每个表中将前两页的数据全部查询出来,然后在内存中再次重新排序,最后从中取出第二页的数据,这就是全局查询法
该方案的缺点非常明显:
- 随着页码的增加,每个节点返回的数据会增多,性能非常低
- 服务层需要进行二次排序,增加了服务层的计算量,如果数据过大,对内存和CPU的要求也非常高
不过这种方案也有很多的优化方法,比如Sharding-JDBC中就对此种方案做出了优化,采用的是流式处理 + 归并排序的方式来避免内存的过量占用,有兴趣的可以自行去了解一下。
2. 禁止跳页查询法
数据量很大时,可以禁止跳页查询,只提供下一页的查询方法,比如APP或者小程序中的下拉翻页,这是一种业务折中的方案,但是却能极大的降低业务复杂度
比如第一页的排序数据如下:

那么查询第二页的时候可以将上一页的最大值1664088392作为查询条件,此时的两个表中的SQL改写如下:
select * from t_order_1 where time>1664088392 order by time asc limit 5;
select * from t_order_2 time>1664088392 order by time asc limit 5;
然后同样是需要在内存中再次进行重新排序,最后取出前5条数据
但是这样的好处就是不用返回前两页的全部数据了,只需要返回一页数据,在页数很大的情况下也是一样,在性能上的提升非常大
此种方案的缺点也是非常明显:不能跳页查询,只能一页一页地查询,比如说从第一页直接跳到第五页,因为无法获取到第四页的最大值,所以这种跳页查询肯定是不行的。
3. 二次查询法
以上两种方案或多或少的都有一些缺点,下面介绍一下二次查询法,这种方案既能满足性能要求,也能满足业务的要求,不过相对前面两种方案理解起来比较困难。
还是上面的SQL:
select * from t_order order by time asc limit 5,5;
1. SQL改写
第一步需要对上述的SQL进行改写:
select * from t_order order by time asc limit 2,5;
**注意:**原先的SQL的offset=5,称之为全局offset,这里由于是拆分成了两张表,因此改写后的offset=全局offset/2=5/2=2
最终的落到每张表的SQL如下:
select * from t_order_1 order by time asc limit 2,5;
select * from t_order_2 order by time asc limit 2,5;
执行后的结果如下:

下图中红色部分则为最终结果:

2. 返回数据的最小值
t_order_1:5条数据中最小值为:1664088479
t_order_2:5条数据中最小值为:1664088392
那么两张表中的最小值为1664088392,记为time_min,来自t_order_2这张表,这个过程只需要比较各个分库第一条数据,时间复杂度很低
3. 查询二次改写
第二次的SQL改写也是非常简单,使用between语句,起点就是第2步返回的最小值time_min,终点就是每个表中在第一次查询时的最大值。
t_order_1这张表,第一次查询时的最大值为1664088581,则SQL改写后:
select * from t_order_1 where time between $time_min and 1664088581 order by time asc;
t_order_2这张表,第一次查询时的最大值为1664088481,则SQL改写后:
select * from t_order_2 where time between $time_min and 1664088481 order by time asc;
此时查询的结果如下(红色部分):

上述例子只是数据巧合导致第2步的结果和第3步的结果相同,实际情况下一般第3步的结果会比第2步的结果返回的数据会多。
4. 在每个结果集中虚拟一个time_min记录,找到time_min在全局的offset
在每个结果集中虚拟一个time_min记录,找到time_min在全局的offset,下图蓝色部分为虚拟的time_min,红色部分为第2步的查询结果集
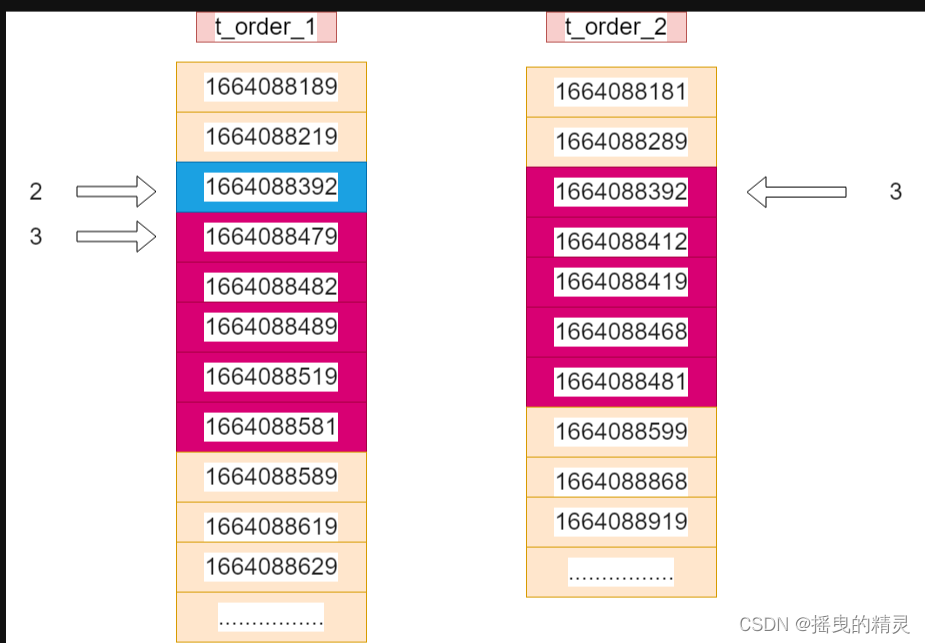
因为第1步改后的SQL的offset为2,所以查询结果集中每个分表的第一条数据offset为3(2+1);
t_order_1中的第一条数据为1664088479,这里的offset为3,则向上推移一个找到了虚拟的time_min,则offset=2
t_order_2中的第一条数据就是time_min,则offset=3
那么此时的time_min的全局offset=2+3=5
5. 查找最终数据
找到了time_min的最终全局offset=5之后,那么就可以知道排序的数据了。
将第2步获取的两个结果集在内存中重新排序后,结果如下:

现在time_min也就是1664088392的offset=5,那么原先的SQL:select * from t_order order by time asc limit 5,5;的结果显而易见了,向后推移一位,则结果为:

刚好符合之前的结果,说明二次查询的方案没问题
这种方案的优点:可以精确地返回业务所需数据,每次返回的数据量都非常小,不会随着翻页增加数据的返回量
缺点也是很明显:需要进行两次查询
总结
分库分表后的分页查询的三种方案:
- 全局查询法:这种方案最简单,但是随着页码的增加,性能越来越低
- 禁止跳页查询法:这种方案是在业务上更改,不能跳页查询,由于只返回一页数据,性能较高
- 二次查询法:数据精确,在数据分布均衡的情况下适用,查询的数据较少,不会随着翻页增加数据的返回量,性能较高















 2558
2558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









