









知识点的梳理:
-
虚拟机中,常量池专门用于存放字符串常量。在JDK1.6之前,它在永久区。JDK1.7之后,它转移到了堆中;
-
String对象的特点
-
String的特点:
- 不变性;
- 针对常量池的优化;
- 类的final定义;
-
不变性
- 能力说明:String对象一旦生成,则不能再对它进行改变;
-
能力作用:当一个对象需要被多线程共享,且访问频繁时,可以省略同步和锁等待的时间,提升性能;
- 为啥能提高性能?因为对象不可变,对于所有线程都是只读的,多线程访问时,即使不加同步也不会产生数据的不一致,减少了系统的开销;
- 注意:String.substring(),String.concat()这些修改操作,实际上并没有修改原来的字符串,而是产生了一个新的字符串!
- 可以使用StringBuffer或StringBuilder来创建一个可以修改的字符串;
-
针对常量池的优化
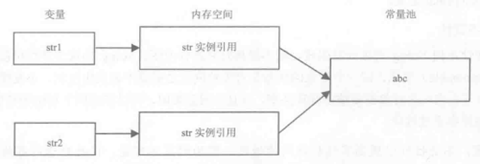
- 能力说明:当两个String对象拥有相同的值时,它们只引用常量池中的同一个拷贝。
- 能力作用:当同一个字符串反复出现时,可以大幅节省内存空间!
- 示例:
-
| String str1 = new String("abc"); String str2 = new String("abc"); System.out.println(str1==str2);//false System.out.println(str1==str2.intern());//false System.out.println("abc"==str2.intern());//true | String.intern()返回字符串在常量池的引用 |
-
图示:
-
类的final定义
- 能力说明:String被final修饰,提高系统安全性;
- 能力作用:在JDK1.5之前,使用final定义有助于虚拟机内联所有的final方法,提高系统效率。但在JDK1.5之后,这种方法效果不在明显~
-
String的内存泄漏
-
String的结构
-
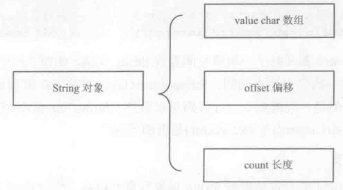
JDK1.6中,java.lang.String由3部分组成:代表字符数组的value,偏移量offset,长度count:
- 字符串的实际内容由三者共同决定,而非value一项;
-
问题来了!如果字符串value数组包含100个字符,而count长度只有一个字节,那么这个String实际上只有一个字符,那剩余的99个就属于泄漏部分!直到这个字符串被回收才会被释放!
-
-
-
String常量池的位置
-
常量池的位置
- 虚拟机中,常量池专门用于存放字符串常量。在JDK1.6之前,它在永久区。JDK1.7之后,它转移到了堆中;
- 示例:
-

| public class StringInternOOM { public static void main(String[] args) { List<String> list = new ArrayList<>(); int i =0; while(true){ list.add(String.valueOf(i++).intern()); } } } | 运行参数: |
| JDK1.6抛出的错误: | JDK1.7抛出的错误: |


-
注意
-
String.intern()的返回值永远等于字符串常量,但这不代表在系统的任何时刻,相同字符串的intern()返回都会是一样的;
- 例如:在一次intern()调用之后,该字符串在某一个时刻被回收,之后,再进行一次intern()调用,那么字面值相同的字符串重新被加入常量池,但是引用位置已经不同~~~~
- 示例:
-
| public class ConstantPool { public static void main(String[] args) { if(args.length==0){ return; } System.out.println(System.identityHashCode((args[0]+Integer.toString(0)))); System.out.println(System.identityHashCode((args[0]+Integer.toString(0)).intern())); System.gc(); System.out.println(System.identityHashCode((args[0]+Integer.toString(0)).intern())); } } | 代码说明:接收一个参数,用于构造字符串,构造的字符串都是在原有字符串后加上字符串"0".输出3次字符出的Hash值,第一次为字符串本身,第二次为常量池引用,第三次进行了常量池回收后的相同字符串的常量池引用。结果三次Hash值都是不同的。 |















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









