







1、定义
程序:例如pychram、QQ都是程序
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源,在操作系统中,通常都
是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位,由于线
程比进程更小,基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,
一组寄存器和栈),故对它的调度所付出的开销就会小得多,能更高效的提高系统内多个程序
间并发执行的程度
进程:比如 在一台电脑上能够同时运行多个软件
线程:比如 一个QQ中的多个聊天窗口
2、状态
工作中,任务数往往大于cpu的核数,所以一定会有一些任务正在执行,而另外一些任务在等待
cpu进行执行,各个进程就有了不同的状态
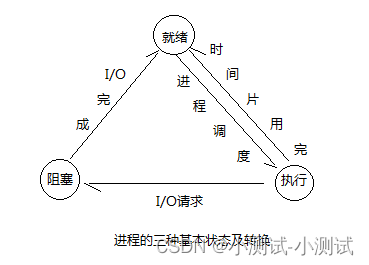
就绪状态:运行的条件都已经满足了,随时可以给操作系统调度执行
执行状态:cpu正在执行
等待状态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
3、创建进程
from multiprocessing import Process
import time
def func1(name):
print('func1执行的进程ID{},父进程的ID:{}'.format(os.getpid(),os.getppid()))
for i in range(5):
print("{}------正在做事情1------".format(name))
time.sleep(1)
def func2(name):
print('func2执行的进程ID{},父进程的ID:{}'.format(os.getpid(),os.getppid()))
for i in range(6):
print("{}-----正在做事情2------".format(name))
time.sleep(1)
# # 创建进程
# p1 = Process(target=func1, args=('func1',))
# p2 = Process(target=func2, kwargs={'name': "func1"})
# # 启动进程
# p1.start()
# p2.start()
def run():
p1 = Process(target=func1, args=('func1',))
p2 = Process(target=func2, kwargs={'name': "func1"})
# 启动进程
p1.start()
p2.start()
if __name__ == '__main__':
# 创建进程
print('主进程的进程ID',os.getpid())
run()
print('主进程的结束')
# 结果(子进程的pid为新的pid,子线程的父进程为主进程pid)
主进程的进程ID 5160
主进程的结束
func1执行的进程ID10232,父进程的ID:5160
func1------正在做事情1------
func2执行的进程ID4308,父进程的ID:5160
func1-----正在做事情2------
func1------正在做事情1------
func1-----正在做事情2------
func1------正在做事情1------
func1-----正在做事情2------
func1-----正在做事情2------
func1------正在做事情1------
func1-----正在做事情2------
func1------正在做事情1------
func1-----正在做事情2------
# 如果使用的是线程(Thread),则结果为:(子线程的pid为主进程的pid,子线程的父进程为其他进程id,但都一样)
主进程的进程ID 4372
func1执行的进程ID4372,父进程的ID:12280
func1------正在做事情1------
func2执行的进程ID4372,父进程的ID:12280
func2-----正在做事情2------
主进程结束
func1------正在做事情1------
func2-----正在做事情2------
func2-----正在做事情2------
func1------正在做事情1------
func1------正在做事情1------
func2-----正在做事情2------
func1------正在做事情1------
func2-----正在做事情2------
func2-----正在做事情2------
创建进程的参数:
target:指定进程执行的任务函数
name:设置进程名称
args:给任务函数传递参数(元组)
kwargs:给任务函数传递参数(字典)
daemon:是否设为守护进程
守护进程:主进程执行结束、子进程不管有没有执行完,都终止执行(要方法内的所有进程都设置为守护进程时才有用)
进程对象的方法:
start():启动进程
join():设置主进程等待子进程执行的时间(默认等待执行完)
注意点:进程之间数据的独立的(不共享)
from multiprocessing import Process
a = 0
def work1():
global a
for i in range(10000):
a += 1
print('work1 --- a的值', a)
def work2():
global a
for i in range(9999):
a += 1
print('work1 --- a的值', a)
def run():
p1 = Process(target=work1)
p2 = Process(target=work2)
# 启动进程
p1.start()
p2.start()
p1.join()
p2.join()
if __name__ == '__main__':
run()
print('主程序的a:',a)
# 结果
work1 --- a的值 10000
work1 --- a的值 9999
主程序的a: 0
4、进程间的通信
Queue.Queue是进程内队列,同一个进程中多个线程之间通信用。
multiprocess.Queue是跨进程通信队列。
import time
from multiprocessing import Process, Queue
# 假设队列中有50个url,每个请求需要花0.5秒的时间,尝试通过5个进程去发送请求,并统计总耗时
def work(que):
for i in range(10):
url = que.get()
print('发送请求:', url)
time.sleep(0.5)
if __name__ == '__main__':
# multiprocessing.Queue:进程之间数据通信的队列
q = Queue()
for i in range(50):
url = 'http://www.baidu.com/{}'.format(i)
q.put(url)
for i in range(5):
Process(target=work, args=(q,)).start()
注意:这里的Queue不能用 from queue import Queue,queue.Queue使用了线程锁的,但是线程锁无法被进程打包,如果使用这个类,将会报错:TypeError: can’t pickle _thread.lock objects,如果将Process(target=work, args=(q,)).start()改成Process(target=work, args=(q,)).run()就不会报错,但此时并没有启动多进程
run和start方法的区别:
start() 方法来启动进程,真正实现了多进程运行,这时无需等待 run 方法体代码执行完毕而直接继续执行下面的代码:调用 Process 类的 start() 方法来启动一个进程,这时此进程处于就绪(可运行)状态,并没有运行,一旦得到 cpu 时间片,就开始执行 run() 方法,这里方法 run() 称为进程体,当进程结束后,不可以重新启动。
run() 方法只是类的一个普通方法,如果直接调用 run 方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待 run 方法体执行完毕后才可继续执行下面的代码,这样就没有达到多进程的目的。














 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









