







本博客参考官方文档进行介绍,全网仅此一家进行中文翻译,走过路过不要错过。
官方网址:https://docs.nvidia.com/cuda/cuda-c-programming-guide/
本文档分成多个博客进行介绍,在本人专栏中含有所有内容:
https://blog.csdn.net/qq_33345365/category_12610860.html
CUDA 12.4为2024年3月2日发表,本专栏开始书写日期2024/4/8,当时最新版本4.1
本人会维护一个总版本,一个小章节的版本,总版本会持续更新,小版本会及时的调整错误和不合理的翻译,内容大部分使用chatGPT 4翻译,部分内容人工调整
开始编辑时间:2024/4/8;最后编辑时间:2024/4/18
CUDA 12.4文档1:使用GPU好处&CUDA&可扩展编程模型
文章目录
- 第一章 使用GPU好处
- 第二章 CUDA: 通用并行计算和平台和编程模型
- 第三章 可扩展编程模型
- 第四章 文档结构
- 第五章 编程模型
- 5.4 异构编程
- 第六章 编程接口
- 6.1 使用NVCC编译
- 6.2 CUDA运行时
- 6.2.1 初始化
- 6.2.2 设备内存 Device Memory
- 6.2.3.1 为持久访存设置的L2缓存预留 L2 cache Set-Aside for Persisting Accesses
- 6.2.3.2 持节访存的L2策略 L2 Policy for Persisting Accesses
- 6.2.3.5 重置L2访问为常规 Reset L2 Access to Normal
- 6.2.3.6 管理L2预留缓存的利用 Manage Utilization of L2 set-aside cache
- 6.2.3.7 查询L2缓存属性 Manage Utilization of L2 set-aside cache
- 6.2.3.8 Control L2 Cache Set-Aside Size for Persisting Memory Access
- 6.2.4 共享内存 Shared Memory
- 6.2.5 分布式共享内存
- 6.2.6 锁业主存 Page-Locked Host Memory
- 6.2.7 内存同步域 Memory Synchronization Domains
- 6.2.8 异步并发执行
- 6.2.9 多设备系统
- 6.2.10 统一虚拟地址空间 Unified Virtual Address Space
- 6.2.11 进程间通信 Interprocess Communication
- 6.2.12 错误检查 Error Checking
- 6.2.13 调用栈 Call Stack
- 6.2.14 纹理和表面内存 Texture and Surface Memory
- 6.2.15 图形的互操作性 Graphics Interoperability
- 6.2.16 外部资源的互操作性 External Resource Interoperability
- 6.3 版本控制和兼容性 Versioning and Compatibility
- 6.4 计算模式 Compute Modes
- 6.5 模式转换 Mode Switches
- 6.6 Windows上的Tesla计算集群模式 Tesla Compute Cluster Mode for Windows
- 第七章 硬件实现 Hard Implementation
- 第八章 性能指导 Performance Guidelines
- 第九章 支持CUDA的GPU CUDA-Enabled GPUs
- 第十章 C++语言扩展
- 10.3 内置向量类型
- 10.4 内置的变量
- 10.5 内存栅栏函数 Memory Fence Functions
- 10.6 同步函数 Synchronization Functions
- 10.7 算数函数 Mathematical Functions
- 10.8 纹理函数
- 10.9 表面函数 Surface Functions
- 10.10 只读数据缓存加载函数 Read-Only Data Cache Load Function
- 10.11 使用缓存提示的加载函数 Load Functions Using Cache Hints
- 10.12 使用缓存提示的存储函数 Store Functions Using Cache Hints
- 10.13 计数函数 Time Function
- 10.14 原子操作 Atomic Functions
- 10.15 地址空间预测函数 Address Space Predicate Functions
- 10.16 地址空间转换函数 Address Space Conversion Functions
- 10.17 Alloca函数 Alloca Function
- 10.18 编译优化提示函数 Compiler Optimization Hint Functions
- 10.19 Warp Vote函数 Warp Vote Functions
- 10.20 Warp Match 函数 Warp Match Functions
- 10.21 Warp规约函数 Warp Reduce Function
- 10.22 Warp混洗函数 Warp Shuffle Function
- 10.23 Nanosleep 函数 Nanosleep Function
- 10.24 Warp矩阵函数 Warp Reduce Function
- 10.26 异步Barrier
- 10.27 异步数据拷贝 Asynchronous Data Copies
- 10.28 使用cuda:pipeline进行异步数据 Asynchronous Data Copies using cuda::pipeline
- 10.29 使用张量内存访问(TMA)进行异步数据拷贝 Asynchronous Data Copies using Tensor Memory Access (TMA)
- 10.30 性能分析器计数器函数 Profiler Counter Function
- 10.31 断言 Assertion
- 10.32 Trap函数
- 10.33 Breakpoint函数 Breakpoint Function
- 10.34 格式化输出 Formatted Output
- 10.35 动态全局内存分配和操作 Dynamic Global Memory Allocation and Operations (可以看看)
- 10.36 执行配置 Execution Configuration
- 10.37 Launch Bounds
- 10.38 每个线程的最大寄存器数 Maximum Number of Registers per Thread
- 10.39 \#pragma unroll
- 10.40 SIMD视频指令 \#pragma unroll SIMD Video Instructions
- 10.41 诊断语法 Diagnostic Pragmas
- 第11章 合作组 Cooperative Groups
- 第12章 CUDA动态并行 CUDA Dynamic Parallelism
- 第13章 虚拟内存管理 Virtual Memory Management
- 第14章 流顺序内存分配器 Stream Ordered Memory Allocator
- 第15章 图内存节点 Graph Memory Nodes
- 第16章 数学函数 Mathematical Functions
- 第17章 C++语言支持 C++ Language Support
- 第18章 纹理获取 Texture Fetching
- 第19章 计算能力 Compute Capabilties
- 第20章 驱动API Driver API
- 第21章 CUDA环境变量 CUDA Environment Variables
- 第22章 统一内存编程 Unified Memory Programming
- 第23章 懒加载 Lazy Loading
- 第24章 注意事项
第一章 使用GPU好处
图形处理单元(GPU)在相似的价格和功耗范围内,比CPU提供更高的指令吞吐量和内存带宽。许多应用都利用了这些更高的能力,使得在GPU上运行的速度比在CPU上更快。其他计算设备,如FPGA,也非常节能,但比GPU提供的编程灵活性要少得多。
"图形"这个限定词源于二十年前GPU最初创造时的情况,它当时被设计为一种专门的处理器,用来加速图形渲染。由于市场对实时、高清、3D图形的需求不断增长,它已经发展成为一种通用处理器,不仅仅用于图形渲染,还用于处理许多其他工作负载。
GPU和CPU之间的这种能力差异存在是因为它们设计的目标不同。CPU设计为尽可能快地执行一系列的操作,称为线程,并可以并行执行几十个这样的线程,而GPU则设计为能并行执行成千上万个线程(通过分摊较慢的单线程性能来实现更大的吞吐量)。
GPU专门为高度并行计算设计,因此设计上更多的晶体管用于数据处理,而不是数据缓存和流控。图示图1展示了CPU和GPU的芯片资源分布的示例。

图1:GPU将更多的晶体管用于数据处理
比如,将更多的晶体管用于数据处理,例如浮点计算,对于高度并行计算是有益的;GPU可以通过计算来隐藏内存访问的延迟,而不是依赖大型数据缓存和复杂的流控来避免长时间的内存访问延迟,这两者在晶体管方面都很昂贵。
通常情况下,一个应用会有并行部分和顺序部分的混合,所以系统是用GPU和CPU混合设计的,以便最大化整体性能。具有高度并行性的应用程序可以利用GPU的大规模并行性质,以实现比在CPU上更高的性能。
第二章 CUDA: 通用并行计算和平台和编程模型
2006年11月,NVIDIA®推出了CUDA®,这是一个通用的并行计算平台和编程模型,它利用NVIDIA GPU中的并行计算引擎,以比在CPU上更有效的方式解决许多复杂的计算问题。
CUDA配备了一个软件环境,允许开发人员使用C++作为高级编程语言。如图2所示,CUDA还支持其他语言、应用程序编程接口或基于指令的方法,例如FORTRAN,DirectCompute,OpenACC等。

图2:GPU计算应用。CUDA旨在支持多种语言和应用编程接口。
第三章 可扩展编程模型
多核CPU和众核GPU的出现意味着主流处理器芯片现在已经是并行系统。挑战在于开发能够透明地扩展其并行性以利用越来越多的处理器核心的应用软件,就像3D图形应用程序透明地扩展其并行性到拥有大量不同核心数量的众核GPU一样。
CUDA并行编程模型旨在克服这个挑战,同时也让熟悉如C等标准编程语言的程序员能够轻松上手。
它的核心是三个关键的抽象概念 - 线程组的层次结构、共享内存和屏障同步 - 这些都以一套最小化的语言扩展简单地暴露给程序员。
这些抽象提供了精细的数据并行性和线程并行性,这些都嵌套在粗粒度的数据并行性和任务并行性中。他们指导程序员将问题分割成可以由线程块并行独立解决的粗粒度子问题,以及将每个子问题进一步细分成可以由块内所有线程协同并行解决的更细小的部分。
这种分解在允许线程在解决每个子问题时进行协作的同时保留了语言表达性,并且同时使其具有自动可扩展性。实际上,每一个线程块都可以按任何顺序在GPU中的任何可用的多处理器上进行调度,同时或顺序执行,这样一个编译后的CUDA程序就可以在任何数量的多处理器上执行,就如图3所示,只有运行时系统需要知道物理多处理器的数量。
这种可扩展的编程模型让GPU架构能够通过简单地扩展多处理器和内存分区的数量来覆盖广泛的市场范围:从高性能的游戏爱好者使用的GeForce GPU和专业的Quadro和Tesla计算产品,到各种价格实惠的主流GeForce GPU。

图3:自动扩展
注意:GPU是围绕一组流多处理器(SMs)构建的。一个多线程程序被划分为独立执行的线程块,以便拥有更多多处理器的GPU会自动用比拥有较少多处理器的GPU更短的时间来执行程序。
第四章 文档结构
这个文档按如下章节进行组织:
- 简介是对CUDA的总体介绍。
- 编程模型概述了CUDA的编程模型。
- 编程接口描述了编程接口。
- 硬件实现描述了硬件实现。
- C++语言扩展是对所有扩展到C++语言的详细描述。
- 共享组描述了CUDA线程的各种组的同步原语。
- CUDA动态并行性描述了如何从另一个内核启动和同步内核。
- 虚拟内存管理描述了如何管理统一的虚拟地址空间。
- 流有序内存分配器描述了应用程序如何对内存分配和回收进行排序。
- 图形存储节点描述了图形如何创建和拥有内存分配。
- 数学函数列出了CUDA支持的数学函数。
- C++语言支持列出了设备代码支持的C++特性。
- 纹理获取提供了关于纹理获取的更多细节。
- 计算能力给出了各种设备的技术规格,以及更多的架构细节。
- 驱动API介绍了低级驱动API。
- CUDA环境变量列出了所有的CUDA环境变量。
- 统一内存编程介绍了统一内存编程模型。
- 性能指南提供了如何实现最大性能的一些指导。
- 支持CUDA的GPU列出了所有支持CUDA的设备。
第五章 编程模型
本章通过概述它们在C++中的表现形式,介绍了CUDA编程模型背后的主要概念。
关于CUDA C++的详细描述在编程接口中给出。
本章和下一章中使用的向量加法示例的完整代码可以在vectorAdd CUDA样本中找到。
CUDA 12.4文档2 内核&线程架构
5.1 内核Kernels
CUDA C++通过允许程序员定义C++函数,称为内核,当被调用时,这些函数由N个不同的CUDA线程并行执行N次,而不是像常规的C++函数那样只执行一次。
内核使用 global 声明说明符定义,并且给定内核调用的执行该内核的CUDA线程数使用新的 <<<...>>>执行配置语法指定。执行内核的每个线程都被赋予一个在内核内通过内置变量可以访问的唯一线程ID。
作为示例,以下样本代码使用内置变量 threadIdx,将两个大小为N的向量A和B相加,并将结果存储到向量C中:
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
∕∕ Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
在这里,执行VecAdd()的N个线程中的每一个都执行一次成对的加法。
5.2 线程架构
为了方便,threadIdx是一个三组件向量,因此可以使用一维、二维或三维的线程索引来标识线程,形成一个一维、二维或三维的线程块,称为线程块。这为在像向量、矩阵或体积等域中的元素之间调用计算提供了一种自然的方式。
线程的索引和线程ID之间的关系很直接:对于一维的块,它们是相同的;对于大小为(Dx, Dy)的二维块,索引为(x, y)的线程的线程ID为(x + y Dx);对于大小为(Dx, Dy, Dz)的三维块,索引为(x, y, z)的线程的线程ID为(x + y Dx + z Dx Dy)。
下面的代码就是一个例子,它将两个NxN大小的矩阵A和B加在一起,并将结果存储到矩阵C中:
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
∕∕ Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
每个块的线程数量是有限的,因为所有的线程都应该存在于同一个流式多处理器核心上,并且必须共享这个核心的有限的内存资源。在当前的GPU上,一个线程块可能包含多达1024个线程。
然而,一个内核可以被多个形状相同的线程块执行,这样总的线程数量等于每个块的线程数量乘以块的数量。
块被组织成一个一维、二维或三维的线程块网格,如图4所示。网格中线程块的数量通常由被处理的数据的大小决定,这通常超过了系统中的处理器数量。
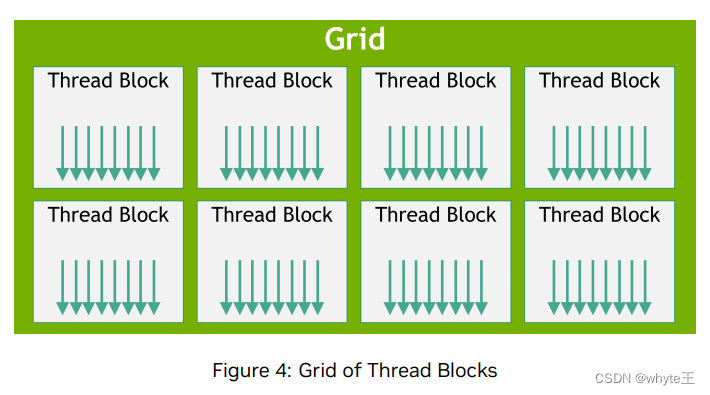
图4:线程块的网格
在 <<<...>>>语法中指定的每个块的线程数量和每个网格的块数量可以是int类型或dim3类型。可以像上面的例子那样指定二维的块或网格。
网格内的每个块都可以通过一个一维、二维或三维的唯一索引来标识,这个索引在内核中可以通过内置的blockIdx变量访问。线程块的维度在内核中可以通过内置的blockDim变量访问。
下面的代码是将前面的MatAdd()示例扩展为处理多个块的情况:
// 内核定义
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
∕∕ Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N ∕ threadsPerBlock.x, N ∕ threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
线程块的大小为16x16(256个线程),尽管在这种情况下是任意的,但这是一个常见的选择。如前所述,创建足够的块,每个矩阵元素有一个线程。为了简单起见,这个例子假设每个维度的网格线程数可以被该维度的块线程数整除,尽管并非一定是这种情况。
线程块需要独立执行:它们必须能够按任何顺序执行,可以并行也可以串行。这种独立性要求允许线程块按任何顺序在任何数量的核心上调度,如图3所示,使程序员能写出随核心数量扩展的代码。
块内的线程可以通过共享一些共享内存和同步它们的执行来协调内存访问来合作。更精确地说,可以在内核中通过调用__syncthreads()内在函数来指定同步点;__syncthreads()充当一个屏障,所有的块内线程都必须在这里等待,直到允许任何线程继续。共享内存章节给出了一个使用共享内存的例子。除了__syncthreads(),协作组API章节还提供了一整套丰富的线程同步原语。
为了有效的合作,预计共享内存是接近每个处理器核心的低延迟内存(很像L1缓存),并且__syncthreads()预计是轻量级的。
5.2.1 线程块集群 Thread Block Clusters
设计线程数:共享内存上同步 < 线程块集群内同步 < 全局同步
随着NVIDIA计算能力9.0的引入,CUDA编程模型引入了一个叫做线程块群集的可选等级层次,这些都是由线程块构成的。与线程块中的线程保证在流式多处理器上被并行调度类似,线程块群集中的线程块也保证在GPU处理集群(GPC)上进行并行调度。
与线程块类似,群集也以一维、二维或三维的方式组织,如图5所示。群集中的线程块数量可以由用户定义,CUDA中支持以8个线程块为单位的群集大小作为最大限制。注意,在GPU硬件或MIG配置中,如果太小以致不能支持8个多处理器,那么最大群集大小将相应减小。识别这些较小的配置,以及支持线程块群集大小超过8的较大配置,是架构特定的,并可以使用cudaOccupancyMaxPotentialClusterSize API进行查询。
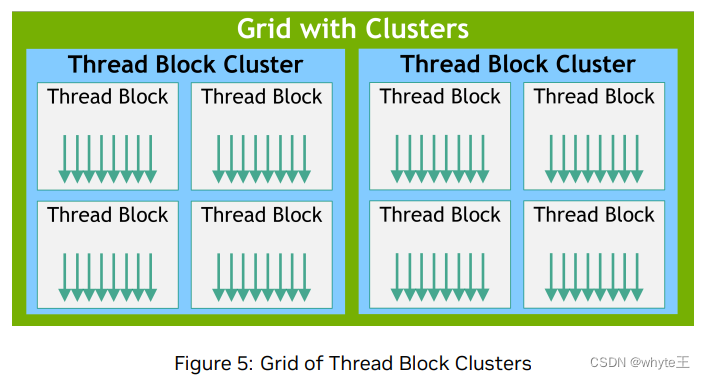
图5:线程块集群的网格
在使用群集支持启动的内核中,为了兼容性,gridDim变量仍然表示线程块数量的大小。可以通过使用Cluster Group API找到群集中块的等级。
线程块群集可以通过使用__cluster_dims__(X,Y,Z)的编译器时间内核属性或使用CUDA内核启动API cudaLaunchKernelEx在内核中启用。下面的例子展示了如何使用编译器时间内核属性启动一个群集。使用内核属性的群集大小在编译时固定,然后可以使用经典的<<<,>>>来启动内核。如果内核使用编译时群集大小,那么在启动内核时,群集大小不能被修改。
∕∕ 内核定义, Compile time cluster size 2 in X-dimension and 1 in Y and Z dimension
__global__ void __cluster_dims__(2, 1, 1) cluster_kernel(float *input, float* output)
{ }
int main()
{
float *input, *output;
∕∕ Kernel invocation with compile time cluster size
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N ∕ threadsPerBlock.x, N ∕ threadsPerBlock.y);
∕∕ The grid dimension is not affected by cluster launch, and is still enumerated
∕∕ using number of blocks.
∕∕ The grid dimension must be a multiple of cluster size.
cluster_kernel<<<numBlocks, threadsPerBlock>>>(input, output);
}
线程块群集大小也可以在运行时设置,并通过CUDA内核启动API cudaLaunchKernelEx启动内核。下面的代码示例展示了如何使用可扩展API启动一个群集内核。
∕∕ 内核定义
∕∕ No compile time attribute attached to the kernel
__global__ void cluster_kernel(float *input, float* output)
{ }
int main()
{
float *input, *output;
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N ∕ threadsPerBlock.x, N ∕ threadsPerBlock.y);
∕∕ Kernel invocation with runtime cluster size
{
cudaLaunchConfig_t config = {0};
∕∕ The grid dimension is not affected by cluster launch, and is still enumerated
∕∕ using number of blocks.
∕∕ The grid dimension should be a multiple of cluster size.
config.gridDim = numBlocks;
config.blockDim = threadsPerBlock;
cudaLaunchAttribute attribute[1];
attribute[0].id = cudaLaunchAttributeClusterDimension;
attribute[0].val.clusterDim.x = 2; ∕∕ Cluster size in X-dimension
attribute[0].val.clusterDim.y = 1;
attribute[0].val.clusterDim.z = 1;
config.attrs = attribute;
config.numAttrs = 1;
cudaLaunchKernelEx(&config, cluster_kernel, input, output);
}
}
在具有9.0计算能力的GPU中,群集中的所有线程块都保证在单个GPU处理集群(GPC)上进行协同调度,并允许群集中的线程块使用Cluster Group API cluster.sync()执行硬件支持的同步。群集组还提供成员函数,使用num_threads()和num_blocks()API分别查询群集组大小,以线程数量或块数量表示。群集组中的线程或块的排名可以使用dim_threads()和dim_blocks()API分别进行查询。
属于群集的线程块可以访问分布式共享内存。群集中的线程块具有读取、写入和执行分布式共享内存中任何地址的原子操作的能力。分布式共享内存章节给出了在分布式共享内存中执行直方图的示例。
CUDA 12.4文档3 内存层次&异构变成&计算能力
5.3 内存层次 Memory Hierarchy
CUDA线程在执行过程中可能会访问多个内存空间的数据,如图6所示。每个线程都有自己的私有本地内存。
每个线程块都有一个对块内所有线程可见的共享内存,并且其生命周期与块相同。线程块集群中的线程块可以对彼此的共享内存执行读、写和原子操作。所有线程都可以访问同一块全局内存。
此外,还有两个只读内存空间可以被所有线程访问:常量内存空间和纹理内存空间。全局内存、常量内存和纹理内存空间都针对不同的内存使用进行了优化(参见设备内存访问章节)。纹理内存也提供了不同的寻址模式,以及针对某些特定数据格式的数据过滤(参见纹理和表面内存章节)。
全局内存(global)、常量内存(constant)和纹理内存(texture)空间在相同应用程序的内核启动间都是持久的。
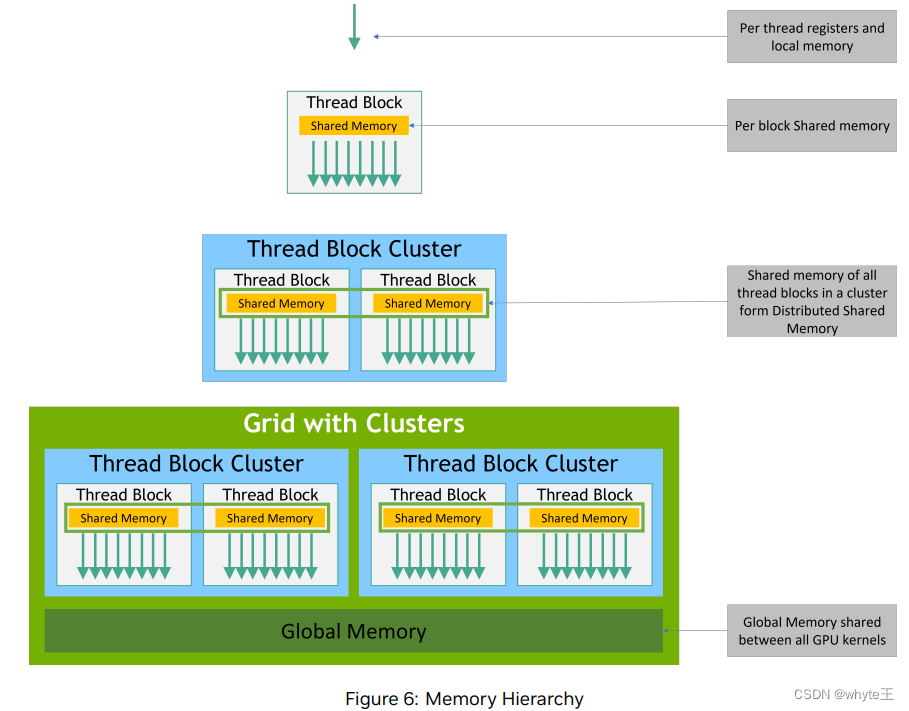
图6:内存层次
5.4 异构编程
如图7所示,CUDA编程模型假设CUDA线程在一个物理独立的设备上运行,该设备作为运行C++程序的主机的协处理器。例如,当内核在GPU上运行,而C++程序的其余部分在CPU上运行时,就是这种情况。
CUDA编程模型还假设主机和设备在DRAM中分别维护自己的独立内存空间,分别称为主机内存和设备内存。因此,一个程序通过调用CUDA运行时(在编程接口章节中描述)来管理内核可以看到的全局内存、常量内存和纹理内存空间。这包括设备内存的分配和释放,以及主机和设备内存之间的数据传输。
统一内存提供了管理内存,以连接主机和设备的内存空间。管理内存可以作为一个统一、连贯的内存映像,通过一个共享的地址空间,从系统中的所有CPU和GPU访问。这一能力使设备内存能被过度订阅,并且可以大大简化转换应用程序的任务,因为它消除了在主机和设备之间明确镜像数据的需要。请参阅统一内存编程章节来了解统一内存的介绍。
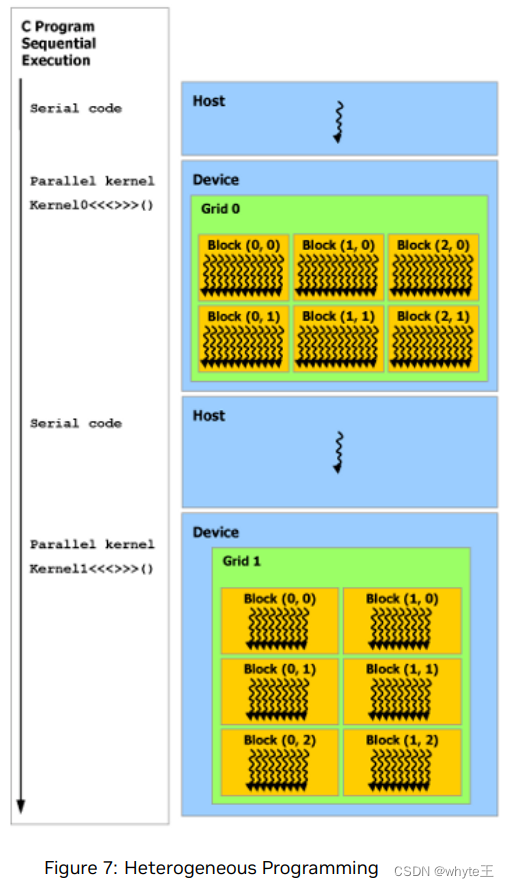
图7:异构编程
串行代码在主机上执行,而并行代码在设备上执行
5.5 异步SIMT编程模型
在CUDA编程模型中,线程是执行计算或内存操作的最低级别的抽象。从基于NVIDIA Ampere GPU架构的设备开始,CUDA编程模型通过异步编程模型为内存操作提供加速。异步编程模型定义了异步操作相对于CUDA线程的行为。
异步编程模型定义了异步屏障的行为,用于CUDA线程之间的同步。该模型还解释和定义了如何使用cuda::memcpy_async在GPU进行计算的同时异步地从全局内存移动数据。
5.5.1 异步操作
异步操作被定义为由CUDA线程启动并由另一个线程异步执行的操作。在一个规范的程序中,一个或多个CUDA线程与异步操作同步。启动异步操作的CUDA线程并不需要在同步线程中。
这样的异步线程(即作为线程)总是与启动异步操作的CUDA线程关联。异步操作使用同步对象来同步操作的完成。这样的同步对象可以由用户显式管理(例如,cuda::memcpy_async),也可以在库中隐式管理(例如,cooperative_groups::memcpy_async)。
同步对象可以是cuda::barrier或cuda::pipeline。这些对象在“异步屏障章节”和“使用cuda::pipeline进行异步数据复制章节”中有详细的解释。这些同步对象可以在不同的线程范围内使用。范围定义了可能使用同步对象与异步操作同步的线程集。下表定义了CUDA C++中可用的线程范围,以及可以与每个范围同步的线程。
| Thread Scope | Description |
|---|---|
| cuda::thread_scope::thread_scope_thread | 只有发起异步操作的CUDA线程才会同步。 |
| cuda::thread_scope::thread_scope_block | 与初始化线程相同的线程块中的所有或任何CUDA线程都会同步。 |
| cuda::thread_scope::thread_scope_device | 作为初始线程的同一GPU设备中的所有或任何CUDA线程都会同步。 |
| cuda::thread_scope::thread_scope_system | 启动线程的同一系统中的所有或任何CUDA或CPU线程都会同步。 |
这些线程范围在CUDA标准C++库中作为标准C++的扩展来实现。
5.6 计算能力 Compute Capability
设备的计算能力用一个版本号表示,有时也被称为其“SM版本”。这个版本号标识了GPU硬件支持的特性,应用程序在运行时使用它来确定当前GPU上可用的硬件特性和/或指令。
计算能力由一个主要修订号X和一个次要修订号Y组成,表示为X.Y。
具有相同主修订号的设备具有相同的核心架构。主修订号为9的设备是基于NVIDIA Hopper GPU架构的,为8的设备是基于NVIDIA Ampere GPU架构的,为7的设备是基于Volta架构的,为6的设备是基于Pascal架构的,为5的设备是基于Maxwell架构的,为3的设备是基于Kepler架构的。
次修订号对应于对核心架构的增量改进,可能包括新的特性。
Turing是计算能力为7.5的设备的架构,是基于Volta架构的增量更新。
CUDA启用的GPU列表包含所有启用CUDA的设备及其计算能力。每种计算能力的技术规格在计算能力中提供。Tesla和Fermi架构从CUDA 7.0和CUDA 9.0开始分别不再支持。
特定GPU的计算能力版本不应与CUDA版本(例如,CUDA 7.5、CUDA 8、CUDA 9)混淆,后者是CUDA软件平台的版本。CUDA平台被应用开发者用来创建可以在许多代的GPU架构上运行的应用,包括尚未发明的未来GPU架构。虽然新版本的CUDA平台通常通过支持该架构的计算能力版本来增加对新GPU架构的本地支持,但新版本的CUDA平台通常也包括独立于硬件生成的软件特性。
CUDA 12.4文档4 编程接口之使用NVCC编译
第六章 编程接口
CUDA C++为熟悉C++编程语言的用户提供了一个简单的路径,可以轻松地编写用于设备执行的程序。
它由C++语言的最小扩展和一个运行时库组成。
核心语言扩展已在编程模型章节中介绍。它们允许程序员将内核定义为一个C++函数,并使用一些新的语法来指定网格和块维度,每次调用该函数时使用。所有扩展的完整描述可以在C++语言扩展章节中找到。任何包含这些扩展的源文件都必须使用nvcc编译,如在NVCC编译章节中概述的那样。
运行时在CUDA运行时章节中介绍。它提供在主机上执行的C和C++函数,用于分配和释放设备内存,传输主机内存和设备内存之间的数据,管理多设备系统等。运行时的完整描述可以在CUDA参考手册中找到。
运行时是在一个更低级别的C API之上构建的,即CUDA驱动程序API,该API也可由应用程序访问。驱动程序API通过公开诸如CUDA上下文(设备的主机进程的类似物)和CUDA模块(设备的动态加载库的类似物)等较低级别概念,提供了额外的控制级别。大多数应用程序不使用驱动程序API,因为它们不需要这种额外的控制级别,而当使用运行时时,上下文和模块管理是隐式的,从而使代码更加简洁。由于运行时与驱动程序API互通,因此,大多数需要使用驱动程序API功能的应用程序可以默认使用运行时API,并且只在需要的时候使用驱动程序API。驱动程序API在驱动程序API章节中介绍,并在参考手册中完全描述。
6.1 使用NVCC编译
内核可以使用CUDA指令集架构编写,称为PTX,其在PTX参考手册中有描述。然而,通常使用如C++这样的高级编程语言更有效。在这两种情况下,内核必须由nvcc编译成二进制代码以在设备上执行。
nvcc是一个编译器驱动程序,简化了编译C++或PTX代码的过程:它提供简单且熟悉的命令行选项,并通过调用实现不同编译阶段的工具集来执行它们。本节给出了nvcc工作流程和命令选项的概述。完整的描述可以在nvcc用户手册中找到。
6.1.1 编译工作流
6.1.1.1 离线编译
使用nvcc编译的源文件可以包含一些主机代码(即,在主机上执行的代码)和设备代码(即,在设备上执行的代码)的混合。 nvcc的基本工作流程包括将设备代码从主机代码中分离出来,然后:
- 将设备代码编译成汇编形式(PTX代码)和/或二进制形式(cubin对象),
- 并通过替换内核中引入的<<<…>>>语法(在执行配置中有更详细的描述)修改主机代码,从PTX代码和/或cubin对象加载和启动每个编译好的内核所需的CUDA运行时函数调用。
修改的主机代码输出为C++代码,该代码将留待使用其他工具进行编译,或者通过让nvcc在最后的编译阶段调用主机编译器,直接以对象代码的形式输出。
然后,应用程序可以:
- 链接到已编译的主机代码(这是最常见的情况),
- 或者忽略修改的主机代码(如果有的话)并使用CUDA驱动程序API(参见驱动程序API)来加载和执行PTX代码或cubin对象。
6.1.1.2 实时编译 Just-in-Time Compilation
任何在运行时由应用程序加载的PTX代码都将由设备驱动程序进一步编译为二进制代码。这被称为即时编译。即时编译会增加应用程序的加载时间,但允许应用程序受益于每个新设备驱动程序带来的任何新的编译器改进。这也是应用程序在编译时尚不存在的设备上运行的唯一方式,如在应用程序兼容性章节中详细描述的那样。
当设备驱动程序为某些应用程序即时编译一些PTX代码时,它会自动缓存生成的二进制代码的一个副本,以避免在随后的应用程序调用中重复编译。缓存 - 称为计算缓存 - 在升级设备驱动程序时会自动失效,以便应用程序可以从内置在设备驱动程序中的新即时编译器的改进中受益。
环境变量可用于控制即时编译,如在CUDA环境变量章节中所描述的那样。
作为使用nvcc编译CUDA C++设备代码的替代方案,可以使用NVRTC在运行时将CUDA C++设备代码编译为PTX。 NVRTC是一个用于CUDA C++的运行时编译库;更多信息可以在NVRTC用户指南中找到。
6.1.2 二进制兼容性 Binary Compatibility
二进制代码是特定于架构的。 使用编译器选项-code生成cubin对象,该选项指定目标架构:例如,使用-code=sm_80编译将为计算能力为8.0的设备生成二进制代码。 从一个次要版本到下一个次要版本保证了二进制兼容性,但在一个次要版本到上一个次要版本或者在主要版本之间并不保证。换句话说,为计算能力X.y生成的cubin对象只能在计算能力为X.z的设备上执行,其中 z > y z>y z>y。
6.1.3 PTX兼容性
一些PTX指令只在具有更高计算能力的设备上支持。例如,Warp Shuffle函数只在计算能力为5.0及以上的设备上支持。-arch编译器选项指定在将C++编译为PTX代码时假定的计算能力。因此,包含warp shuffle的代码,例如,必须使用-arch=compute_50(或更高)进行编译。
为某特定计算能力生产的PTX代码总是可以编译为具有更大或等同计算能力的二进制代码。注意,从早期PTX版本编译的二进制文件可能无法使用某些硬件功能。例如,针对计算能力为7.0(Volta)的设备的二进制目标,由为计算能力6.0(Pascal)生成的PTX编译,不会使用Tensor Core指令,因为Pascal上没有这些功能。因此,最终的二进制文件可能比使用最新版本的PTX生成的二进制文件性能差。
编译为目标架构条件特性的PTX代码只在完全相同的物理架构上运行,其他地方无法运行。架构条件PTX代码不具有向前和向后的兼容性。例如,使用sm_90a或compute_90a编译的代码只能在计算能力为9.0的设备上运行,而且不向后或向前兼容。
6.1.4 应用兼容性
要在具有特定计算能力的设备上执行代码,应用程序必须加载与此计算能力兼容的二进制或PTX代码,如在二进制兼容性章节和PTX兼容性章节中所述。特别是,要能够在具有更高计算能力的未来架构上执行代码(对于这些架构,尚无法生成二进制代码),应用程序必须加载将为这些设备进行即时编译的PTX代码(参见即时编译章节)。
在CUDA C++应用程序中嵌入哪些PTX和二进制代码由-arch和-code编译器选项或-gencode编译器选项控制,详情请见nvcc用户手册。例如:
nvcc x.cu -gencode arch=compute_50,code=sm_50 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_70,code=\"compute_70,sm_70\"
嵌入与计算能力5.0和6.0兼容的二进制代码(第一和第二个-gencode选项)以及与计算能力7.0兼容的PTX和二进制代码(第三个-gencode选项)。
生成主代码以在运行时自动选择最合适的代码进行加载和执行,上述示例将会是:
- 对于计算能力为5.0和5.2的设备,执行5.0的二进制代码,
- 对于计算能力为6.0和6.1的设备,执行6.0的二进制代码,
- 对于计算能力为7.0和7.5的设备,执行7.0的二进制代码,
- 对于计算能力为8.0和8.6的设备,执行在运行时编译为二进制代码的PTX代码。
例如,x.cu可以有一个优化的代码路径,该路径使用Warp Reduction操作,这些操作只在计算能力为8.0及以上的设备上支持。__CUDA_ARCH__宏可以用来区分基于计算能力的各种代码路径。它仅为设备代码定义。例如,使用-arch=compute_80编译时,__CUDA_ARCH__等于800。
如果x.cu针对架构条件特性以sm_90a或compute_90a编译,代码只能在计算能力为9.0的设备上运行。
使用驱动API的应用程序必须将代码编译为单独的文件,并在运行时显式加载和执行最合适的文件。
Volta架构引入了独立线程调度,这改变了GPU上线程的调度方式。对于依赖于前一架构中SIMT调度的特定行为的代码,独立线程调度可能会改变参与的线程集,导致结果不正确。为了在实施独立线程调度中详细描述的的纠正操作时帮助迁移,Volta开发者可以选择使用编译器选项组合-arch=compute_60 -code=sm_70以选择Pascal的线程调度。
nvcc用户手册列出了-arch、-code和-gencode编译器选项的各种简写。例如,-arch=sm_70是-arch=compute_70 -code=compute_70,sm_70的简写(它与-gencode arch=compute_70,code="compute_70,sm_70"相同)。
6.1.5 C++兼容性
编译器的前端按照C++语法规则处理CUDA源文件。主机代码支持完整的C++。然而,对于设备代码,只有一部分C++得到了完全支持,如在C++语言支持章节中所述。
6.1.6 64位兼容性
nvcc的64位版本以64位模式编译设备代码(即,指针为64位)。只有与64位模式的主机代码结合使用时,64位模式编译的设备代码才受支持。
CUDA 12.4文档5 编程接口-使用CUDA运行时-初始化&设备内存
6.2 CUDA运行时
运行时是在cudart库中实现的,该库链接到应用程序,可以静态地通过cudart.lib或libcudart.a链接,也可以动态地通过cudart.dll或libcudart.so链接。需要cudart.dll和/或cudart.so进行动态链接的应用程序通常将它们作为应用程序安装包的一部分包含进来。只有在链接到相同CUDA运行时实例的组件之间传递CUDA运行时符号的地址才是安全的。
所有的入口点都以cuda为前缀。
如在异构编程章节中提到,CUDA编程模型假定一个系统由主机和设备组成,二者各自拥有独立的内存。设备内存章节给出了用于管理设备内存的运行时函数的概览。
共享内存章节阐述了在线程层次章节结构中引入的共享内存的使用,以最大化性能。
锁业内存章节的主机内存引入了与数据传输(数据在主机和设备内存之间传输)同时进行的内核执行所需要的页锁定主机内存。
异步并行章节执行描述了用于在系统各级别启用异步并行执行的概念和API。
多设备系统章节展示了编程模型如何扩展到拥有多个设备连接到同一主机的系统。
错误检查章节描述了如何适当地检查运行时生成的错误。
调用栈章节提到了用于管理CUDA C++调用栈的运行时函数。
纹理和表面内存章节介绍了纹理和表面内存空间,这提供了另一种访问设备内存的方式;它们也展示了GPU纹理硬件的一个子集。
图形互操作性章节介绍了运行时提供的与两个主要的图形API,OpenGL和Direct3D,进行互操作的各种函数。
6.2.1 初始化
从CUDA 12.0开始,cudaInitDevice()和cudaSetDevice()调用初始化运行时和与指定设备相关联的主要上下文。如果没有这些调用,运行时将隐式地使用设备0并根据需要自我初始化以处理其他运行时API请求。在计时运行时函数调用以及解释第一次调用运行时的错误代码时,需要记住这一点。在12.0之前,cudaSetDevice()不会初始化运行时,应用程序通常使用无操作的运行时调用cudaFree(0)来将运行时初始化与其他api活动隔离(无论是为了计时还是错误处理)。
运行时为系统中的每个设备创建一个CUDA上下文(关于CUDA上下文的更多详细信息,请参见上下文章节)。这个上下文是这个设备的主要上下文,并在第一个运行时函数中初始化,该函数需要在这个设备上有一个活动的上下文。它在应用程序的所有主机线程之间共享。作为这个上下文创建的一部分,如果需要(参见实时编译章节),设备代码会被实时编译并加载到设备内存中。这一切都是透明的。如果需要,例如,对于驱动API的互操作性,设备的主要上下文可以从驱动API中访问,如在运行时和设备APIs的互操作性章节中所述。
当主机线程调用cudaDeviceReset()时,这将销毁主机线程当前操作的设备的主要上下文(即,当前设备如在设备选择章节中定义)。任何具有此设备为当前设备的主机线程所做的下一个运行时函数调用将为该设备创建一个新的主要上下文。
注:CUDA接口使用的全局状态在主程序启动时初始化,在主程序终止时销毁。CUDA运行时和驱动程序无法检测这个状态是否无效,所以在程序启动或终止(在main之后)期间使用任何这些接口(隐式或显式)都会导致未定义的行为。
从CUDA 12.0开始,cudaSetDevice()现在在更改主机线程的当前设备后,将显式初始化运行时。CUDA的上一版本将新设备上的运行时初始化延迟到在cudaSetDevice()之后进行第一次运行时调用。这个变化意味着,现在检查cudaSetDevice()的返回值是否有初始化错误变得非常重要。参考手册中的错误处理和版本管理部分的运行时函数不会初始化运行时。
6.2.2 设备内存 Device Memory
如在异构编程中所述,CUDA编程模型假设一个由主机和设备组成的系统,每个设备都有自己独立的内存。内核操作设备内存,因此运行时提供了分配、回收和复制设备内存的函数,以及在主机内存和设备内存之间传输数据的函数。
设备内存可以以线性内存或CUDA数组的形式分配。
CUDA数组是为纹理获取优化的不透明内存布局。它们在Texture和Surface Memory中有描述。
线性内存在单一统一的地址空间中分配,这意味着分别分配的实体可以通过指针相互引用,例如在二叉树或链表中。地址空间的大小取决于主机系统(CPU)和使用的GPU的计算能力:
表1:线性内存地址空间
| x86_64 (AMD64) | POWER (ppc64le) | ARM64 | |
|---|---|---|---|
| up to compute capability 5.3 (Maxwell) | 40bit | 40bit | 40bit |
| compute capability 6.0 (Pascal) or newer | up to 47bit | up to 49bit | up to 48bit |
注:在计算能力为5.3(Maxwell)及更早的设备上,CUDA驱动程序创建了一个未提交的40位虚拟地址预留,以确保内存分配(指针)落入支持的范围内。这个预留出现为保留的虚拟内存,但在程序实际分配内存之前不会占用任何物理内存。
线性内存通常使用cudaMalloc()分配并使用cudaFree()释放,主机内存和设备内存之间的数据传输通常使用cudaMemcpy()完成。在Kernels的向量加法代码示例中,需要将向量从主机内存复制到设备内存:
∕∕ Device code
__global__ void VecAdd(float* A, float* B, float* C, int N)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N)
C[i] = A[i] + B[i];
}
∕∕ Host code
int main()
{
int N = ...;
size_t size = N * sizeof(float);
∕∕ Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
∕∕ Initialize input vectors
...
∕∕ Allocate vectors in device memory
float* d_A;
cudaMalloc(&d_A, size);
float* d_B;
cudaMalloc(&d_B, size);
float* d_C;
cudaMalloc(&d_C, size);
∕∕ Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
∕∕ Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) ∕ threadsPerBlock;
VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
∕∕ Copy result from device memory to host memory
∕∕ h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
∕∕ Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
∕∕ Free host memory
...
}
线性内存也可以通过cudaMallocPitch()和cudaMalloc3D()分配。这些函数被推荐用于二维或三维数组的分配,因为它们可以确保分配适当地填充以满足在设备内存访问章节中描述的对齐要求,因此可以确保在访问行地址或在二维数组和设备内存的其他区域之间进行复制时(使用cudaMemcpy2D()和cudaMemcpy3D()函数)得到最佳的性能。返回的pitch(或stride)必须用来访问数组元素。下面的代码示例分配了一个width x height的浮点值二维数组,并展示了如何在设备代码中循环遍历数组元素:
∕* Host code */
int width = 64, height = 64;
float* devPtr;
size_t pitch;
cudaMallocPitch(&devPtr, &pitch, width * sizeof(float), height);
MyKernel<<<100, 512>>>(devPtr, pitch, width, height);
∕∕ Device code
__global__ void MyKernel(float* devPtr, size_t pitch, int width, int height)
{
for (int r = 0; r < height; ++r) {
float* row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; ++c) {
float element = row[c];
}
}
}
以下代码示例分配了一个宽度x高度x深度的浮点值三维数组,并展示了如何在设备代码中循环遍历数组元素:
∕∕ Host code
int width = 64, height = 64, depth = 64;
cudaExtent extent = make_cudaExtent(width * sizeof(float), height, depth);
cudaPitchedPtr devPitchedPtr;
cudaMalloc3D(&devPitchedPtr, extent);
MyKernel<<<100, 512>>>(devPitchedPtr, width, height, depth);
∕∕ Device code
__global__ void MyKernel(cudaPitchedPtr devPitchedPtr, int width, int height, int depth)
{
char* devPtr = devPitchedPtr.ptr;
size_t pitch = devPitchedPtr.pitch;
size_t slicePitch = pitch * height;
for (int z = 0; z < depth; ++z) {
char* slice = devPtr + z * slicePitch;
for (int y = 0; y < height; ++y) {
float* row = (float*)(slice + y * pitch);
for (int x = 0; x < width; ++x) {
float element = row[x];
}
}
}
}
注:为了避免分配过多的内存从而影响整个系统的性能,您可以根据问题的规模向用户请求分配参数。如果分配失败,您可以回退到其他较慢的内存类型(如
cudaMallocHost(),cudaHostRegister()等),或者返回一个错误告诉用户需要多少被拒绝的内存。如果您的应用程序出于某种原因无法请求分配参数,我们建议在支持的平台上使用cudaMallocManaged()。
参考手册列出了所有用于在通过cudaMalloc()分配的线性内存、通过cudaMallocPitch()或cudaMalloc3D()分配的线性内存、CUDA数组以及为在全局或常数内存空间中声明的变量分配的内存之间复制内存的各种函数。下面的代码示例展示了通过运行时API访问全局变量的各种方法:
__constant__ float constData[256];
float data[256];
cudaMemcpyToSymbol(constData, data, sizeof(data));
cudaMemcpyFromSymbol(data, constData, sizeof(data));
__device__ float devData;
float value = 3.14f;
cudaMemcpyToSymbol(devData, &value, sizeof(float));
__device__ float* devPointer;
float* ptr;
cudaMalloc(&ptr, 256 * sizeof(float));
cudaMemcpyToSymbol(devPointer, &ptr, sizeof(ptr));
cudaGetSymbolAddress()用于检索指向为在全局内存空间中声明的变量分配的内存的地址。通过cudaGetSymbolSize()获取分配的内存的大小。
6.2.3 设备内存L2访问管理
当一个CUDA核重复访问全局内存中的数据区域时,这种数据访问可以被认为是持久的。另一方面,如果数据只被访问一次,那么这种数据访问可以被认为是流式的。
从CUDA 11.0开始,计算能力8.0和以上的设备具有影响L2缓存中数据持久性的能力,可能提供更高带宽和更低延迟的全局内存访问。
6.2.3.1 为持久访存设置的L2缓存预留 L2 cache Set-Aside for Persisting Accesses
可以设置L2缓存的一部分用于持久化访问全局内存的数据。持久化访问优先使用这部分预留的L2缓存,而正常或流式访问全局内存只能在持久化访问未使用此部分L2缓存时才能使用它。
持久访问的L2缓存预留大小可以在限制内进行调整:
cudaGetDeviceProperties(&prop, device_id);
size_t size = min(int(prop.l2CacheSize * 0.75), prop.persistingL2CacheMaxSize);
cudaDeviceSetLimit(cudaLimitPersistingL2CacheSize, size); ∕* set-aside 3∕4 of L2 cache, for persisting accesses or the max allowed*∕
当GPU配置为多实例GPU(MIG)模式时,L2缓存预留功能将被禁用。
使用多进程服务(MPS)时,不能通过cudaDeviceSetLimit来改变L2缓存预留大小。相反,预留大小只能在MPS服务器启动时通过环境变量CUDA_DEVICE_DEFAULT_PERSISTING_L2_CACHE_PERCENTAGE_LIMIT来指定。
6.2.3.2 持节访存的L2策略 L2 Policy for Persisting Accesses
访问策略窗口指定了连续的全局内存区域以及该区域内访问的L2缓存的持久性属性。
下面的代码示例展示了如何使用CUDA Stream设置一个L2持久访问窗口。
CUDA Stream例子
cudaStreamAttrValue stream_attribute; ∕∕ Stream level attributes data structure
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(ptr); ∕∕ Global Memory data pointer
stream_attribute.accessPolicyWindow.num_bytes = num_bytes; ∕∕ Number of bytes for persistence access.
∕∕ (Must be less than cudaDeviceProp::accessPolicyMaxWindowSize)
stream_attribute.accessPolicyWindow.hitRatio = 0.6; ∕∕ Hint for cache hit ratio
stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; ∕∕ Type of access property on cache hit
stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; ∕∕ Type of access property on cache miss.
∕∕Set the attributes to a CUDA stream of type cudaStream_t
cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_
attribute);
当一个核函数随后在CUDA流中执行时,全局内存范围[ptr…ptr+num_bytes)内的内存访问比访问其他全局内存位置更可能在L2缓存中持久化。
如下面的例子所示,L2的持久化也可以为CUDA图形Kernel节点设置:
CUDA GraphKernelNode 例子:
cudaKernelNodeAttrValue node_attribute; ∕∕ Kernel level attributes data structure
node_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(ptr); ∕∕ Global Memory data pointer
node_attribute.accessPolicyWindow.num_bytes = num_bytes; ∕∕ Number of bytes for persistence access.
∕∕ (Must be less than cudaDeviceProp::accessPolicyMaxWindowSize)
node_attribute.accessPolicyWindow.hitRatio = 0.6; ∕∕ Hint for cache hit ratio
node_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; ∕∕ Type of access property on cache hit
node_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; ∕∕ Type of access property on cache miss.
∕∕Set the attributes to a CUDA Graph Kernel node of type cudaGraphNode_t
cudaGraphKernelNodeSetAttribute(node, cudaKernelNodeAttributeAccessPolicyWindow, & node_attribute);
hitRatio参数可以用来指定接收hitProp属性的访问的比例。在上述两个例子中,全局内存区域[ptr…ptr+num_bytes)中的60%内存访问具有持久化属性,40%的内存访问具有流式属性。被分类为持久化(即hitProp)的特定内存访问是随机的,概率大约为hitRatio;概率分布取决于硬件架构和内存范围。
例如,如果L2预留缓存大小为16KB,而accessPolicyWindow中的num_bytes为32KB:
- 对于hitRatio为0.5的情况,硬件将随机选择32KB窗口的16KB,标为持久化,并缓存在预留的L2缓存区域。
- 对于hitRatio为1.0的情况,硬件将尝试将整个32KB窗口缓存在预留的L2缓存区。由于预留区域小于窗口,缓存行将会被驱逐,以保持最近使用的32KB数据的16KB在L2缓存的预留部分。
因此,hitRatio可以用来避免缓存行的抖动,总体上减少数据进出L2缓存的数量。
小于1.0的hitRatio值可以用来人为控制并发CUDA流的不同accessPolicyWindow可以在L2中缓存的数据量。例如,设置L2预留缓存大小为16KB;两个并发的内核在两个不同的CUDA流中,每个都有一个16KB的accessPolicyWindow,并且都有1.0的hitRatio值,它们可能会在竞争共享的L2资源时驱逐彼此的缓存行。然而,如果两个accessPolicyWindow的hitRatio值都为0.5,它们就不太可能驱逐自己或彼此的持久化缓存行。
6.2.3.3 L2访问属性 L2 Access Properties
为不同的全局内存数据访问定义了三种访问属性:
- cudaAccessPropertyStreaming:带有流式属性的内存访问不太可能在L2缓存中持久化,因为这些访问会优先被驱逐。
- cudaAccessPropertyPersisting:带有持久性属性的内存访问更可能在L2缓存中持久化,因为这些访问会被优先保留在L2缓存的预留部分。
- cudaAccessPropertyNormal:此访问属性强制将之前应用的持久访问属性重置为正常状态。来自之前CUDA核心的带有持久属性的内存访问可能会在其预期使用后长期保留在L2缓存中。这种持久化会减少后续不使用持久化属性的核函数可用的L2缓存量。使用cudaAccessPropertyNormal属性重置访问属性窗口会移除先前访问的持久化(优先保留)状态,就像先前的访问没有访问属性一样。
6.2.3.4 L2持久化例子 L2 Persistence Example
以下示例展示了如何为持久访问预留L2缓存,通过CUDA Stream在CUDA内核中使用预留的L2缓存,然后重置L2缓存。
cudaStream_t stream;
cudaStreamCreate(&stream);
∕∕ Create CUDA stream
cudaDeviceProp prop;
∕∕ CUDA device properties variable
cudaGetDeviceProperties( &prop, device_id);
∕∕ Query GPU properties
size_t size = min( int(prop.l2CacheSize * 0.75) , prop.persistingL2CacheMaxSize );
cudaDeviceSetLimit( cudaLimitPersistingL2CacheSize, size);
∕∕ set-aside 3∕4 of L2 cache for persisting accesses or the max allowed
size_t window_size = min(prop.accessPolicyMaxWindowSize, num_bytes);
∕∕ Select minimum of user defined num_bytes and max window size.
cudaStreamAttrValue stream_attribute;
∕∕ Stream level attributes data structure
stream_attribute.accessPolicyWindow.base_ptr = reinterpret_cast<void*>(data1);
∕∕ Global Memory data pointer
stream_attribute.accessPolicyWindow.num_bytes = window_size;
∕∕ Number of bytes for persistence access
stream_attribute.accessPolicyWindow.hitRatio = 0.6;
∕∕ Hint for cache hit ratio
stream_attribute.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting;
∕∕ Persistence Property
stream_attribute.accessPolicyWindow.missProp = cudaAccessPropertyStreaming;
∕∕ Type of access property on cache miss
cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_
attribute); ∕∕ Set the attributes to a CUDA Stream
for(int i = 0; i < 10; i++) {
cuda_kernelA<<<grid_size,block_size,0,stream>>>(data1);
∕∕ This data1 is used by a kernel multiple times
}
∕∕ [data1 + num_bytes) benefits from L2 persistence
cuda_kernelB<<<grid_size,block_size,0,stream>>>(data1);
∕∕ A different kernel in the same stream can also benefit
∕∕ from the persistence of data1
stream_attribute.accessPolicyWindow.num_bytes = 0;
∕∕ Setting the window size to 0 disable it
cudaStreamSetAttribute(stream, cudaStreamAttributeAccessPolicyWindow, &stream_
attribute); ∕∕ Overwrite the access policy attribute to a CUDA Stream
cudaCtxResetPersistingL2Cache();
∕∕ Remove any persistent lines in L2
cuda_kernelC<<<grid_size,block_size,0,stream>>>(data2);
∕∕ data2 can now benefit from full L2 in normal mode
6.2.3.5 重置L2访问为常规 Reset L2 Access to Normal
之前CUDA内核中的持久化L2缓存行可能会在使用后长时间保留在L2中。因此,将L2缓存重置为正常对于流式或正常内存访问使用正常优先级的L2缓存很重要。有三种方法可以将持久访问重置为正常状态。
- 使用访问属性cudaAccessPropertyNormal重置之前的持久化内存区域。
- 通过调用cudaCtxResetPersistingL2Cache()将所有持续的L2缓存行重置为正常。
- 最终未被触及的行会自动重置为正常。强烈不建议依赖自动重置,因为自动重置所需的时间长度不确定。
6.2.3.6 管理L2预留缓存的利用 Manage Utilization of L2 set-aside cache
在不同的CUDA流中并行执行的多个CUDA内核可能会有不同的访问策略窗口分配给他们的流。然而,L2预留缓存部分是被所有这些并发的CUDA内核共享的。因此,这一预留缓存部分的总体利用率是所有并发内核单独使用的总和。当持久访问的容量超过预留的L2缓存的容量时,将内存访问标记为持久的好处就会减少。
为了管理预留的L2缓存部分的利用率,一个应用程序必须考虑以下因素:
- L2预留缓存的大小。
- 可能会并发执行的CUDA内核。
- 可能会并发执行的所有CUDA内核的访问策略窗口。
- 当何时以及如何需要重置L2以允许正常或流式访问以等同优先级使用之前预留的L2缓存。
6.2.3.7 查询L2缓存属性 Manage Utilization of L2 set-aside cache
和L2缓存相关的属性是cudaDeviceProp结构的一部分,可以使用CUDA运行时API cudaGetDeviceProperties进行查询。
CUDA设备属性包括:
- l2CacheSize:GPU上可用的L2缓存量。
- persistingL2CacheMaxSize:可为持久内存访问预留的L2缓存的最大量。
- accessPolicyMaxWindowSize:访问策略窗口的最大大小。
6.2.3.8 Control L2 Cache Set-Aside Size for Persisting Memory Access
用于持久内存访问的L2预留缓存大小是通过CUDA运行时API cudaDeviceGetLimit查询的,并使用CUDA运行时API cudaDeviceSetLimit设置为cudaLimit。设置此限制的最大值是cudaDeviceProp::persistingL2CacheMaxSize。
enum cudaLimit {
∕* other fields not shown *∕
cudaLimitPersistingL2CacheSize
};
CUDA 12.4文档6,
6.2.4 共享内存 Shared Memory
6.2.5 分布式共享内存
6.2.6 锁业主存 Page-Locked Host Memory
6.2.7 内存同步域 Memory Synchronization Domains
6.2.8 异步并发执行
6.2.9 多设备系统
6.2.10 统一虚拟地址空间 Unified Virtual Address Space
6.2.11 进程间通信 Interprocess Communication
6.2.12 错误检查 Error Checking
6.2.13 调用栈 Call Stack
6.2.14 纹理和表面内存 Texture and Surface Memory
6.2.14.1 纹理内存 Texture Memory
6.2.15 图形的互操作性 Graphics Interoperability
6.2.16 外部资源的互操作性 External Resource Interoperability
6.3 版本控制和兼容性 Versioning and Compatibility
6.4 计算模式 Compute Modes
6.5 模式转换 Mode Switches
6.6 Windows上的Tesla计算集群模式 Tesla Compute Cluster Mode for Windows
第七章 硬件实现 Hard Implementation
7.1 SIMT架构
7.2 硬件多线程 Hardware Multithreading
第八章 性能指导 Performance Guidelines
8.1 整体性能优化策略
性能优化围绕四个基本策略展开:
- 最大化并行执行以实现最大利用率;
- 优化内存使用以实现最大的内存吞吐量;
- 优化指令使用以实现最大的指令吞吐量;
- 最小化内存抖动。
对于应用程序的某一部分来说,哪些策略会带来最好的性能提升取决于那部分的性能限制因素;例如,优化一个主要受内存访问限制的核心的指令使用效率并不会带来任何显著的性能提升。因此,优化工作应通过度量和监控性能限制因素来进行,例如使用CUDA分析器。同样,比较某个特定核心的浮点操作吞吐量或者内存吞吐量(看哪个更有意义)与设备的对应的理论峰值吞吐量,可以指示出这个核心有多少改进的空间。
8.2 最大利用率 Maximize Utilization
为了最大化利用率,应用程序应该以一种方式进行结构化,使其尽可能暴露出更多的并行性,并有效地将这种并行性映射到系统的各个组件上,以保持它们大部分时间都在忙碌。
8.2.1 应用级 Application Level
8.2.2 设备级 Device Level
8.2.3 多处理器级 Multiprocessor Level
8.3 最大内存吞吐
8.3.1 CPU和GPU之间的数据传输 Data Transfer between Host and Device
8.3.2 设备内存访问
8.4 最大指令吞吐
为了最大化指令吞吐量,应用程序应该:
- 最小化使用具有低吞吐量的算术指令;这包括在不影响最终结果的情况下,以速度换取精度,例如使用内置函数代替常规函数(内置函数在内置函数章节中列出),使用单精度代替双精度,或者将非规范化的数字清零;
- 最小化由控制流指令引起的发散线程束,详见控制流指令章节
- 减少指令的数量,例如,尽可能优化掉同步点,如同步指令中所描述,或者使用__restrict__中描述的受限指针。
在本节中,吞吐量以每个多处理器每时钟周期的操作数量给出。对于大小为32的线程束,一个指令对应32个操作,所以如果N是每个时钟周期的操作数量,那么指令吞吐量就是N/32个指令每时钟周期。
所有的吞吐量都是针对一个多处理器的。它们必须乘以设备中的多处理器数量,以得到整个设备的吞吐量。
8.4.1 算术指令
8.4.2 控制流指令
8.4.3 同步指令 Synchronization Instruction
8.5 最小化内存抖动 Minimize Memory Thrashing
频繁进行内存分配和释放的应用程序可能会发现,随着时间的推移,内存分配调用可能会变慢,直到达到一个限制。这通常是由于向操作系统释放内存以供其自己使用的特性所致。在这方面,为了获得最佳的性能,我们建议以下操作:
- 尝试根据手头的问题来确定分配的大小。不要试图使用cudaMalloc / cudaMallocHost / cuMemCreate分配所有可用的内存,因为这会强制内存立即驻留,并阻止其他应用程序使用这些内存。这可能会对操作系统的调度器产生更大的压力,或者完全阻止使用同一GPU的其他应用程序运行。
- 尝试在应用程序的早期以适当的大小分配内存,并仅在应用程序无需使用时进行分配。减少应用程序中
cudaMalloc+cudaFree的调用次数,特别是在性能关键区域。 - 如果应用程序无法分配足够的设备内存,考虑退回到其他类型的内存,如
cudaMallocHost或cudaMallocManaged,它们可能性能不高,但会使应用程序继续运行。 - 对于支持该特性的平台,cudaMallocManaged允许超额订阅,并且在启用正确的cudaMemAdvise策略后,将允许应用程序保持大部分(如果不是全部)cudaMalloc的性能。cudaMallocManaged也不会强制分配驻留,直到它被需要或者被预取,从而减少了对操作系统调度器的整体压力,并更好地实现多租户使用案例。
第九章 支持CUDA的GPU CUDA-Enabled GPUs
https://developer.nvidia.com/cuda-gpus 列出了所有支持CUDA的设备及其计算能力。
可以使用运行时(查阅参考手册)查询计算能力、多处理器数量、时钟频率、设备内存总量和其他属性。
第十章 C++语言扩展
10.3 内置向量类型
10.4 内置的变量
10.5 内存栅栏函数 Memory Fence Functions
10.6 同步函数 Synchronization Functions
10.7 算数函数 Mathematical Functions
10.8 纹理函数
10.9 表面函数 Surface Functions
10.10 只读数据缓存加载函数 Read-Only Data Cache Load Function
10.11 使用缓存提示的加载函数 Load Functions Using Cache Hints
10.12 使用缓存提示的存储函数 Store Functions Using Cache Hints
10.13 计数函数 Time Function
10.14 原子操作 Atomic Functions
10.15 地址空间预测函数 Address Space Predicate Functions
10.16 地址空间转换函数 Address Space Conversion Functions
10.17 Alloca函数 Alloca Function
10.18 编译优化提示函数 Compiler Optimization Hint Functions
10.19 Warp Vote函数 Warp Vote Functions
10.20 Warp Match 函数 Warp Match Functions
10.21 Warp规约函数 Warp Reduce Function
10.22 Warp混洗函数 Warp Shuffle Function
10.23 Nanosleep 函数 Nanosleep Function
10.24 Warp矩阵函数 Warp Reduce Function
10.25 DPX
DPX是一组函数,它们使得能够寻找最小和最大值,以及最多三个16位和32位有符号或无符号整数参数的融合加法和最小/最大值,还可以选择ReLu(将其限制在零)。



















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











