







在Spring中关于资源文件的解析和BeanDefinition装载、注册是这个方法,目的就是把BeanDefinition放到beanFactory中
/**
* Load bean definitions into the given bean factory, typically through
* delegating to one or more bean definition readers.
* @param beanFactory the bean factory to load bean definitions into
* @throws BeansException if parsing of the bean definitions failed
* @throws IOException if loading of bean definition files failed
* @see org.springframework.beans.factory.support.PropertiesBeanDefinitionReader
* @see org.springframework.beans.factory.xml.XmlBeanDefinitionReader
*/
protected abstract void loadBeanDefinitions(DefaultListableBeanFactory beanFactory)
throws BeansException, IOException;
此方法定义在AbstractRefreshableApplicationContext,关于这个方法的继承体系跳回去自己看图(容器类图结构):不看后悔系列-Spring源码(二):IOC阅读导航篇
这里我们主要以XmlWebApplicationContext的实现往下看
/**
* Loads the bean definitions via an XmlBeanDefinitionReader.
* @see org.springframework.beans.factory.xml.XmlBeanDefinitionReader
* @see #initBeanDefinitionReader
* @see #loadBeanDefinitions
*/
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// Create a new XmlBeanDefinitionReader for the given BeanFactory.
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
loadBeanDefinitions(beanDefinitionReader);
}
从代码可以看出来,这一段代码就是创建了一个XmlBeanDefinitionReader 对象,然后调用loadBeanDefinitions(beanDefinitionReader);
先看一下XmlBeanDefinitionReader 的继承类图
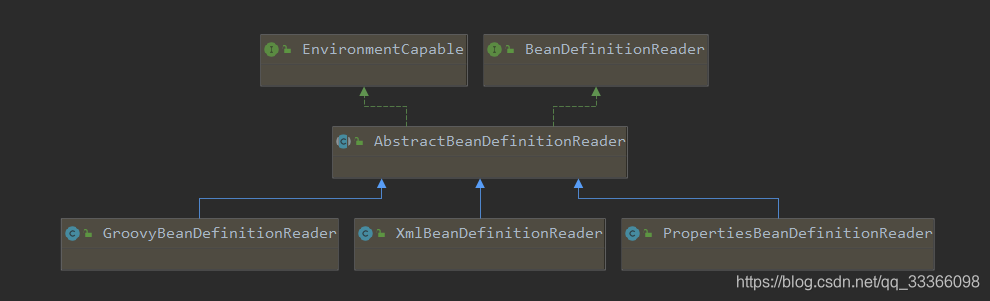
BeanDefinitionReader: 主要定义资源文件读取并转换为 BeanDefinition 的各个功能。
EnvironmentCapable: 定义获取 Environment 方法。
DocumentLoader: 定义从资源文件加载到转换为 Document 的功能。
AbstractBeanDefinitionReader: 对 EnvironmentCapable 、BeanDefinitionReader 类定义的功能进行实现。
跟着 loadBeanDefinitions(beanDefinitionReader),我们继续往下看
/**
* Load the bean definitions with the given XmlBeanDefinitionReader.
* <p>The lifecycle of the bean factory is handled by the refreshBeanFactory method;
* therefore this method is just supposed to load and/or register bean definitions.
* <p>Delegates to a ResourcePatternResolver for resolving location patterns
* into Resource instances.
* @throws IOException if the required XML document isn't found
* @see #refreshBeanFactory
* @see #getConfigLocations
* @see #getResources
* @see #getResourcePatternResolver
*/
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws IOException {
Resource[] configResources = getConfigResources(); //获取资源文件
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
String[] configLocations = getConfigLocations(); //获取资源文件
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
这里插个眼(是梦开始的地方,后面会有方法从这里显示的两个调用方法递归)
看官们可以看到,这里有一个判断,根据获取到的类型不一样(Resource和String)来执行不同的策略。这里的Resource和configLocations 都是在初始化的时候定义的
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("spring-bean.xml");
看过Resource和ResourceLoader的应该知道,Spring是将资源文件抽象成Resource来处理的,所以针对String[] configLocations这种类型的资源文件,其实还没有进行资源文件的定位,所以需要先定位到资源文件,具体各位可以看看里面的处理,最终其实都是跳转到reader.loadBeanDefinitions(configResources);这个方法里的。
于此便完成了IOC第一阶段的第一个步骤(资源文件的定位)
跟着reader.loadBeanDefinitions(configResources);方法
@Override
public int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException {
Assert.notNull(resources, "Resource array must not be null");
int counter = 0;
for (Resource resource : resources) {
counter += loadBeanDefinitions(resource);
}
return counter;
}
这里有一个counter是干嘛的?
提前告诉你count统计的是总的BeanDefiniton数目,(针对本次提供的resources)。
往下跟
/**
* Load bean definitions from the specified resource.
* @param resource the resource descriptor
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException;
此方法定义在BeanDefinitionReader中,就是我们刚刚说的XmlBeanDefinitionReader 的父接口。因为我们用的XmlBeanDefinitionReader类,所以此方法的实现在XmlBeanDefinitionReader中,跟下去
/**
* Load bean definitions from the specified XML file.
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
我们发现它把这里把resource包装成EncodedResource,这里的EncodedResource 为 Resource添加了编码方式和字符集两个属性。
/**
* Load bean definitions from the specified XML file.
* @param encodedResource the resource descriptor for the XML file,
* allowing to specify an encoding to use for parsing the file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
//获取正在解析的资源文件
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get(); //获取已经解析完成的resource
//如果为null,则初始化 resourcesCurrentlyBeingLoaded
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
//将encodedResource(方法参数)添加到集合中
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
//获取encodedResource的输入流
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
//包装成inputSource
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
//可以在此设置编码方式
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource()); //继续执行装载和注册
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
这个方法看起来很长,其实是虚胖,真正做事的也就doLoadBeanDefinitions(inputSource, encodedResource.getResource())这个方法(看源码莫慌啊,仔细看还是能懂的!)
跟进doLoadBeanDefinitions(inputSource, encodedResource.getResource())之后
/**
* Actually load bean definitions from the specified XML file.
* @param inputSource the SAX InputSource to read from
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
* @see #doLoadDocument
* @see #registerBeanDefinitions
*/
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource); //关键点1
return registerBeanDefinitions(doc, resource); //关键点2
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
到这里,就到了整个过程的核心。
看官看下整个方法其实也就关键点1、2
Document doc = doLoadDocument(inputSource, resource); //根据 xml 文件,获取 Document 实例
return registerBeanDefinitions(doc, resource); //根据 Document 实例,加载注册 BeanDefinition
那么接下来我们先分析关键点1
- 关键点1
/**
* Actually load the specified document using the configured DocumentLoader.
* @param inputSource the SAX InputSource to read from
* @param resource the resource descriptor for the XML file
* @return the DOM Document
* @throws Exception when thrown from the DocumentLoader
* @see #setDocumentLoader
* @see DocumentLoader#loadDocument
*/
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
在这个核心逻辑方法中,主要做了两件事
(1)调用 getValidationModeForResource() 获取 xml 文件的验证模式
(2)调用 loadDocument() 根据 xml 文件获取相应的 Document 实例
这块的内容涉及到了有关xml文件知识,各位看官要去补补课了(菜鸟教程XML教程),主要了解一下
(1)XML文件的解析方式(DOM、SAX【Spring采用的解析方式】、StAX)
(2)XML文件命名空间
(3)XML文件的验证模型(DTD、XSD)
因为感觉这块别人比我自己写要好,所以直接就引用了。qaq
关于获取验证模型方法getValidationModeForResource(resource),的解析各位看官可以参考
死磕Spring-IOC 之 获取验证模型
这里直接写个结论
主要是通过读取 XML 文件的内容,判断内容中是否包含有 DOCTYPE ,如果是 则为 DTD,否则为 XSD,当然只会读取到 第一个 “<” 处,因为 验证模式一定会在第一个 “<” 之前。如果当中出现了 CharConversionException 异常,则为 XSD模式
关于获取document对象方法的解析各位看官可以参考
死磕Spring-IOC 之 获取 Document 对象
- 关键点2
registerBeanDefinitions(doc, resource); 这个方法主要完成了三件事
(1)资源文件的解析
(2)BeanDefinition装载
(3)BeanDefinition注册
我们看下它的代码
/**
* Register the bean definitions contained in the given DOM document.
* Called by {@code loadBeanDefinitions}.
* <p>Creates a new instance of the parser class and invokes
* {@code registerBeanDefinitions} on it.
* @param doc the DOM document
* @param resource the resource descriptor (for context information)
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of parsing errors
* @see #loadBeanDefinitions
* @see #setDocumentReaderClass
* @see BeanDefinitionDocumentReader#registerBeanDefinitions
*/
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
(1)创建一个BeanDefinitionDocumentReader
(2)获得注册前的BeanDefinition数量
(3)documentReader.registerBeanDefinitions(doc, createReaderContext(resource)); 资源文件解析,装载注册BeanDefinition
(4)返回本次注册BeanDefinition数量
注意!!!
这里有一个createReaderContext(resource)方法,如果我在这里讲你肯定不会明白的,所以我们现在这里插个眼,然后后面讲到bean标签解析的时候会再说这个方法。这里先和你说它的作用是注册事件监听器。
先看下createBeanDefinitionDocumentReader()
private Class<?> documentReaderClass = DefaultBeanDefinitionDocumentReader.class;
/**
* Create the {@link BeanDefinitionDocumentReader} to use for actually
* reading bean definitions from an XML document.
* <p>The default implementation instantiates the specified "documentReaderClass".
* @see #setDocumentReaderClass
*/
protected BeanDefinitionDocumentReader createBeanDefinitionDocumentReader() {
return BeanDefinitionDocumentReader.class.cast(BeanUtils.instantiateClass(this.documentReaderClass));
}
利用反射创建DefaultBeanDefinitionDocumentReader对象
这个DefaultBeanDefinitionDocumentReader是用来解析document的类
看下它的类图
然后看下documentReader.registerBeanDefinitions(doc, createReaderContext(resource));方法
/**
* Read bean definitions from the given DOM document and
* register them with the registry in the given reader context.
* @param doc the DOM document
* @param readerContext the current context of the reader
* (includes the target registry and the resource being parsed)
* @throws BeanDefinitionStoreException in case of parsing errors
*/
void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
throws BeanDefinitionStoreException;
方法接收两个参数,待解析的 Document 对象,以及解析器的当前上下文,包括目标注册表和被解析的资源。
看下DefaultBeanDefinitionDocumentReader的实现
/**
* This implementation parses bean definitions according to the "spring-beans" XSD
* (or DTD, historically).
* <p>Opens a DOM Document; then initializes the default settings
* specified at the {@code <beans/>} level; then parses the contained bean definitions.
*/
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
/**
* Register each bean definition within the given root {@code <beans/>} element.
*/
protected void doRegisterBeanDefinitions(Element root) {
// Any nested <beans> elements will cause recursion in this method. In
// order to propagate and preserve <beans> default-* attributes correctly,
// keep track of the current (parent) delegate, which may be null. Create
// the new (child) delegate with a reference to the parent for fallback purposes,
// then ultimately reset this.delegate back to its original (parent) reference.
// this behavior emulates a stack of delegates without actually necessitating one.
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent); //创建BeanDefinitionParserDelegate对象(这是一个BeanDefinition辅助解析类)
if (this.delegate.isDefaultNamespace(root)) {
//处理profile
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
//解析前处理(在这里是空实现,留给子类实现)
preProcessXml(root);
//解析
parseBeanDefinitions(root, this.delegate);
//解析后处理(在这里是空实现,留给子类实现)
postProcessXml(root);
this.delegate = parent;
}
/**
* Parse the elements at the root level in the document:
* "import", "alias", "bean".
* @param root the DOM root element of the document
*/
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
//默认命名空间
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
//自定义命名空间
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
这块代码进入到了资源文件的解析和BeanDefinition装载,主要内容为如果根节点或者子节点采用默认命名空间的话,则调用 parseDefaultElement() 进行默认标签解析,否则调用 delegate.parseCustomElement() 方法进行自定义解析
由于篇幅原因,关于后续内容讲解请跳转:不看后悔系列-Spring源码(七):标签解析——BeanDefinition装载、注册,IOC第一阶段完结














 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









