







1.节点语法
Cypher 使用一对括号来表示一个节点:(). 这让人想起带有圆形端盖的圆形或矩形。以下是一些节点示例,提供了不同类型和数量的详细信息:
()
(matrix)
(:Movie)
(matrix:Movie)
(matrix:Movie {title: 'The Matrix'})
(matrix:Movie {title: 'The Matrix', released: 1997})最简单的形式()表示一个匿名的、无特征的节点。如果我们想在别处引用该节点,我们可以添加一个变量,例如:(matrix). 变量仅限于单个语句。它在另一个语句中可能有不同的含义或没有含义。
该:Movie模式声明了节点的标签。这允许我们限制模式,使其无法匹配(例如)具有Actor该位置节点的结构。
节点的属性,例如title,表示为键值对列表,括在一对大括号中,例如:{name: 'Keanu Reeves'}. 属性可用于存储信息和/或限制模式。
2.关系语法
Cypher 使用一对破折号 ( --) 来表示无向关系。有向关系的一端有一个箭头 ( <--, -->)。括号表达式 ( [...]) 可用于添加详细信息。这可能包括变量、属性和类型信息:
-->
-[role]->
-[:ACTED_IN]->
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ['Neo']}]->在关系的括号对中找到的语法和语义与节点括号之间的语法和语义非常相似。role可以定义一个变量(例如, ),以在语句的其他地方使用。关系的类型(例如,:ACTED_IN)类似于节点的标签。属性(例如,roles)完全等同于节点属性。
3. 模式语法
结合节点和关系的语法,我们可以表达模式。以下可能是该领域中的一个简单模式(或事实):
(keanu:Person:Actor {name: 'Keanu Reeves'})-[role:ACTED_IN {roles: ['Neo']}]->(matrix:Movie {title: 'The Matrix'})等价于节点标签,:ACTED_IN模式声明了关系的关系类型。变量(例如,role)可以在语句的其他地方使用来表示关系。
与节点属性一样,关系属性表示为包含在一对大括号内的键/值对列表,例如:{roles: ['Neo']}. 在这种情况下,我们为 使用了一个数组属性roles,允许指定多个角色。属性可用于存储信息和/或限制模式。
4. 模式变量
为了增加模块化和减少重复,Cypher 允许将模式分配给变量。这允许检查匹配路径,将其用于其他表达式等。
acted_in = (:Person)-[:ACTED_IN]->(:Movie)该acted_in变量将包含两个节点以及找到或创建的每个路径的连接关系。有许多函数可以访问路径的详细信息,例如:nodes(path)、relationships(path)和length(path)。
5. 条款
Cypher 语句通常具有多个子句,每个子句执行特定任务,例如:
-
在图中创建和匹配模式
-
过滤、项目、排序或分页结果
-
撰写部分陈述
通过组合 Cypher 子句,我们可以编写更复杂的语句来表达我们想知道或创建的内容。
-------------------------------------------------------------------------------------
------------------------------------- 实践 -----------------------------------------
-------------------------------------------------------------------------------------
1. 创建数据
CREATE (:Movie {title: 'The Matrix', released: 1997})
--返回变量
CREATE (p:Person {name: 'Keanu Reeves', born: 1964})
RETURN p
--创建多个元素
CREATE (a:Person {name: 'Tom Hanks', born: 1956})-[r:ACTED_IN {roles: ['Forrest']}]->(m:Movie {title: 'Forrest Gump', released: 1994})
CREATE (d:Person {name: 'Robert Zemeckis', born: 1951})-[:DIRECTED]->(m)
RETURN a, d, r, m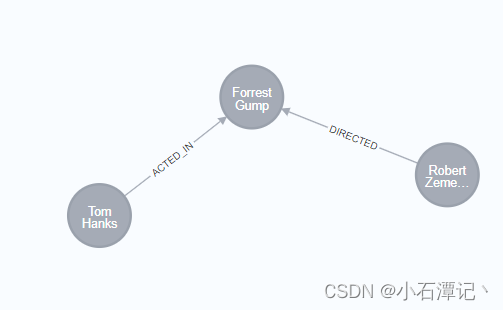
2.匹配模式
匹配模式是MATCH语句的任务。我们传递了迄今为止我们用来MATCH描述我们正在寻找的东西的相同类型的模式。它类似于通过示例查询,只是我们的示例还包括结构。
|
一条 |
为了找到到目前为止我们创建的数据,我们可以开始寻找所有带有Movie标签的节点。
MATCH (m:Movie)
RETURN m
查找具体的某个人:
MATCH (p:Person {name: 'Keanu Reeves'})
RETURN p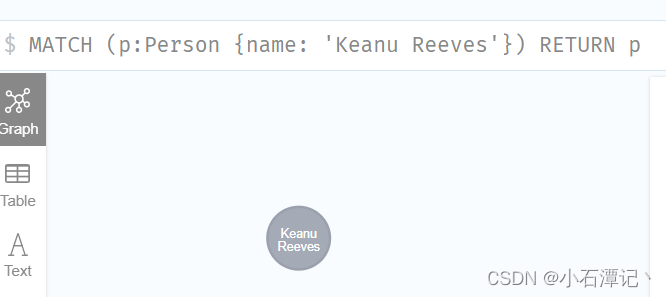
MATCH (p:Person {name: 'Tom Hanks'})-[r:ACTED_IN]->(m:Movie)
RETURN m.title, r.roles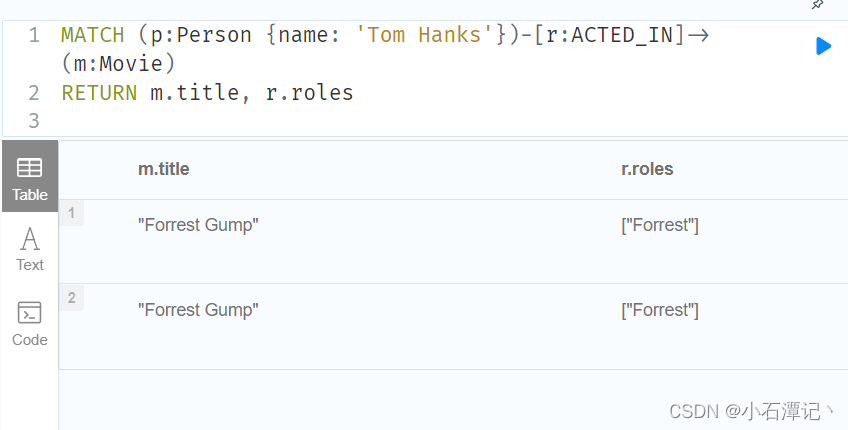
创建电影和人物的关系
MATCH (p:Person {name: 'Tom Hanks'})
CREATE (m:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (p)-[r:ACTED_IN {roles: ['Zachry']}]->(m)
RETURN p, r, m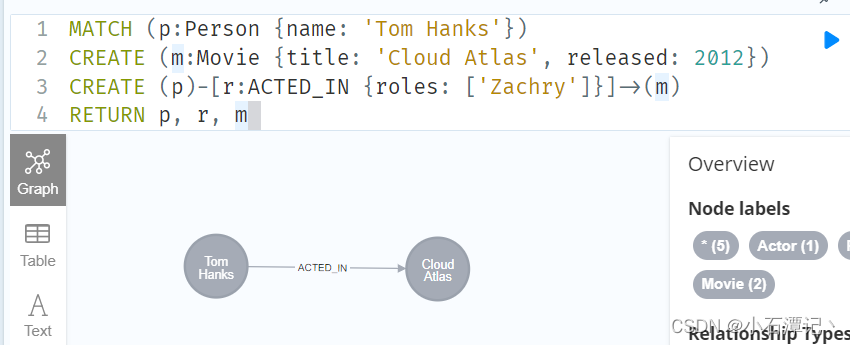
4.完成模式
每当我们从外部系统获取数据或不确定图中是否已经存在某些信息时,我们希望能够表达可重复(幂等)的更新操作。在 CypherMERGE中有这个功能。它的作用类似于MATCH or CREATE的组合,在创建数据之前首先检查数据是否存在。与MERGE您一起定义要查找或创建的模式。通常,就像MATCH您只想在核心模式中包含要查找的关键属性一样。 MERGE允许您提供要设置的附加属性ON CREATE。
MERGE (p:Person {name: 'Tom Hanks'})
CREATE (m:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (p)-[r:ACTED_IN {roles: ['Zachry']}]->(m)
RETURN p, r, m*************************************************************************
******************** 查询语句实例 *******************************
*************************************************************************
1.数据源
CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964})
CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)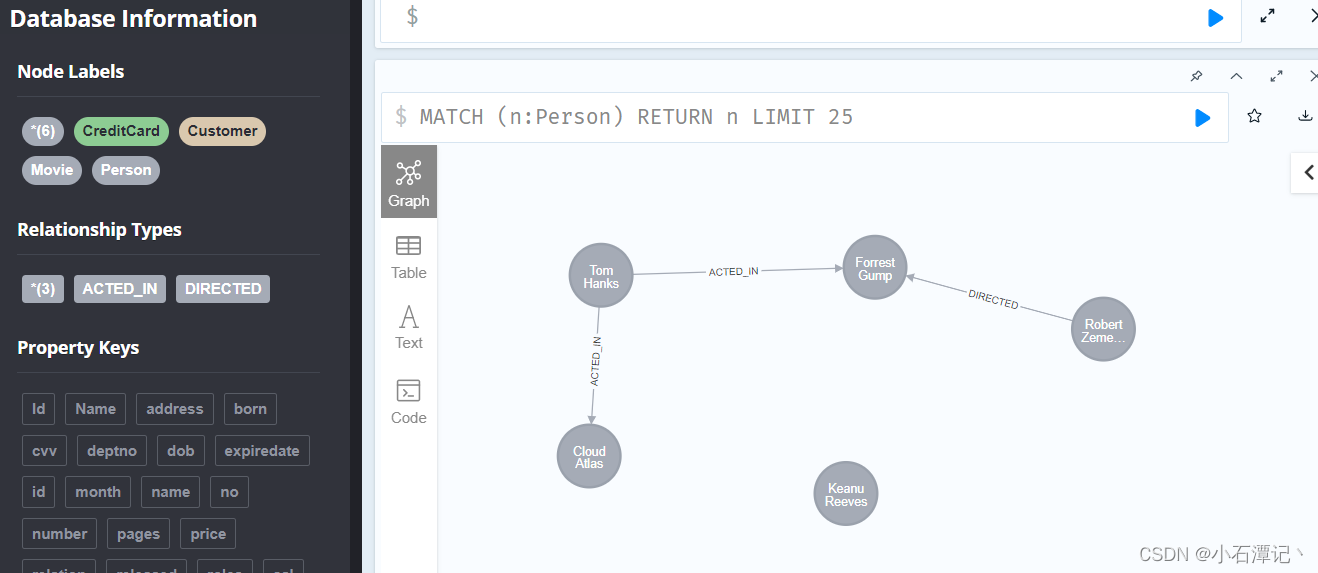
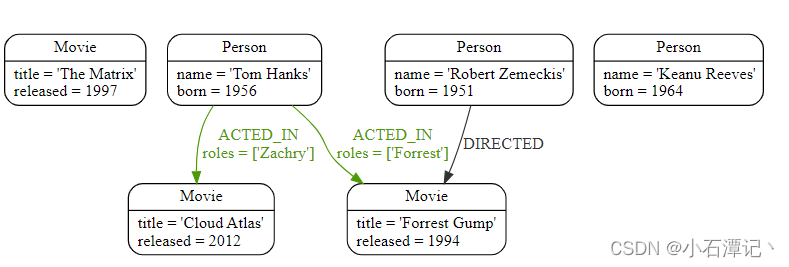
查询数据:
MATCH (m:Movie) WHERE m.title = 'The Matrix' RETURN m
或者
MATCH (m:Movie {title: 'The Matrix'}) RETURN m
以下示例中的WHERE子句包括正则表达式匹配、大于比较以及查看列表中是否存在值的测试:
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
WHERE p.name =~ 'K.+' OR m.released > 2000 OR 'Neo' IN r.roles
RETURN p, r, m
MATCH (p:Person)-[:ACTED_IN]->(m)
WHERE NOT (p)-[:DIRECTED]->()
RETURN p, m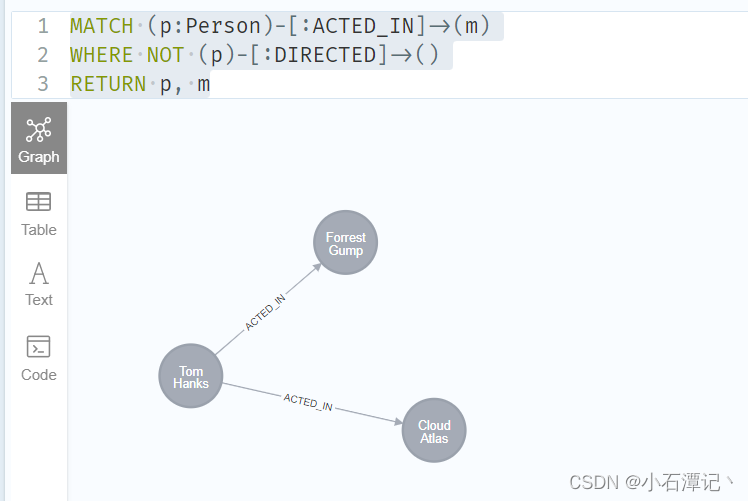
MATCH (p:Person)
RETURN
p,
p.name AS name,
toUpper(p.name),
coalesce(p.nickname, 'n/a') AS nickname,
{name: p.name, label: head(labels(p))} AS person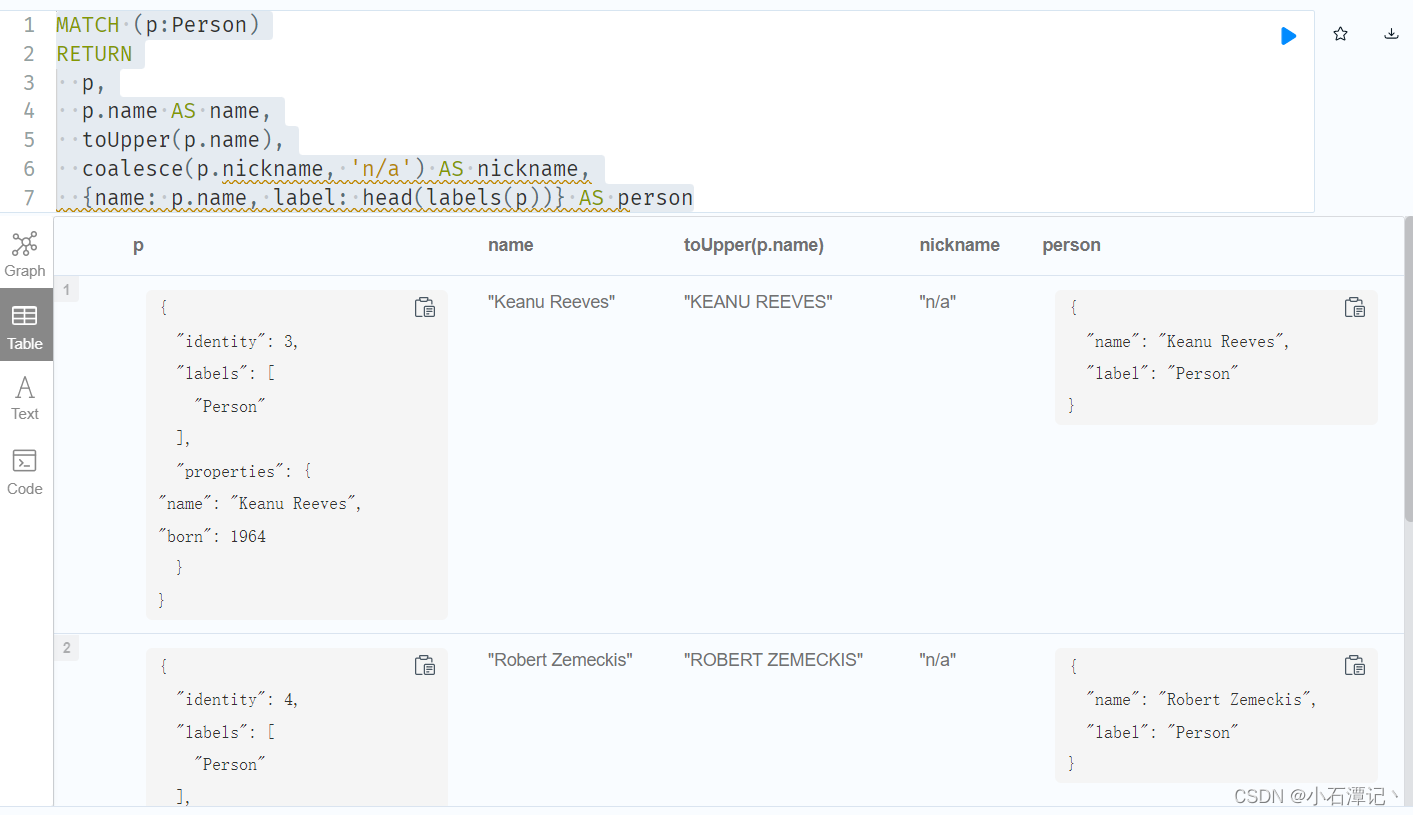
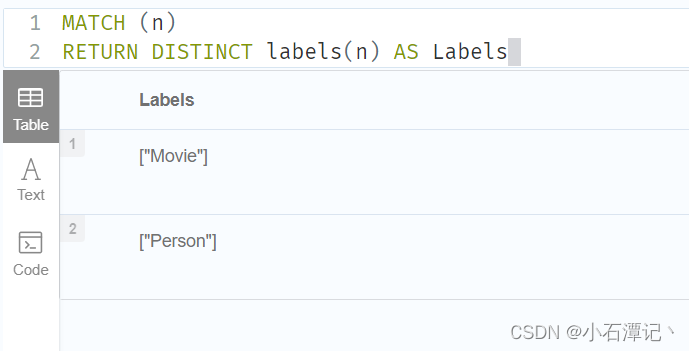
MATCH (n) RETURN DISTINCT labels(n) AS Labels
汇总信息
MATCH (:Person)
RETURN count(*) AS people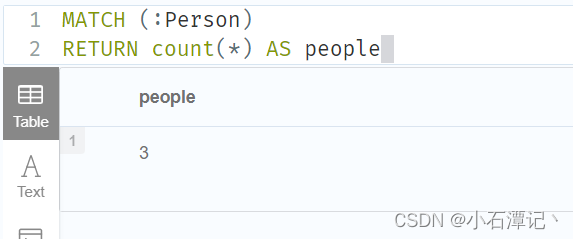
请注意,NULL在聚合过程中会跳过值。对于仅聚合唯一值,请使用DISTINCT,例如:count(DISTINCT role).
找出了演员和导演一起工作的频率:
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(director:Person)
RETURN actor, director, count(*) AS collaborations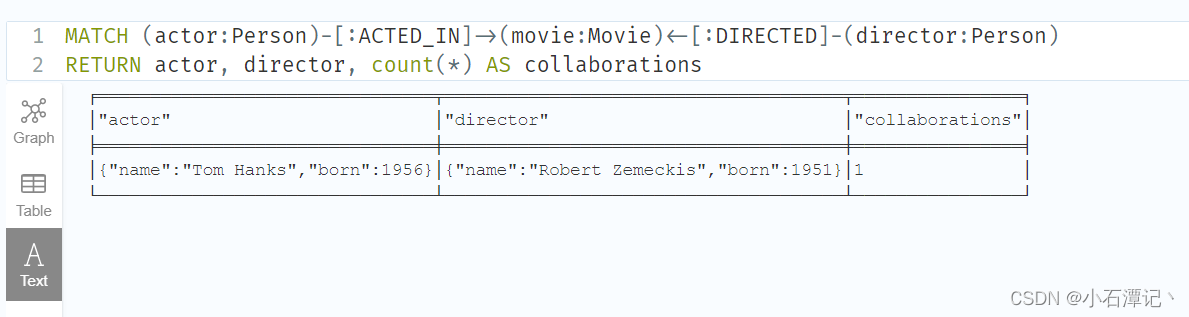
查询演电影最多的人员降序:
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN a, count(*) AS appearances
ORDER BY appearances DESC LIMIT 10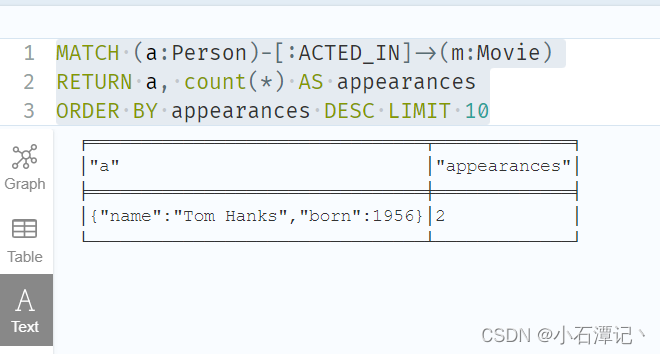
查询电影的演员列表:
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person)
RETURN m.title AS movie, collect(a.name) AS cast, count(*) AS actors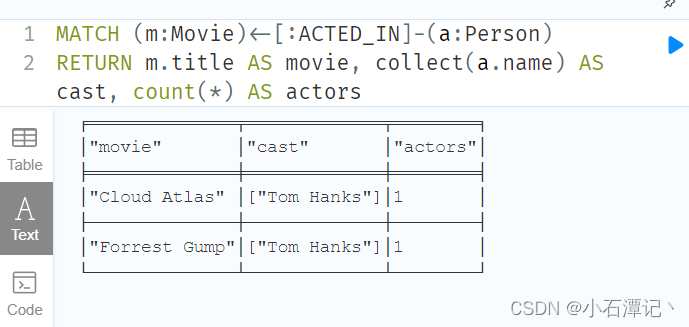
删除所有的节点数据和关系:
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n,r
或者:
match (n) detach delete n
-------------------------------------------------------------------------------------------
------------------------------------复杂语句-------------------------------------------
-------------------------------------------------------------------------------------------
CREATE (matrix:Movie {title: 'The Matrix', released: 1997})
CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964})
CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)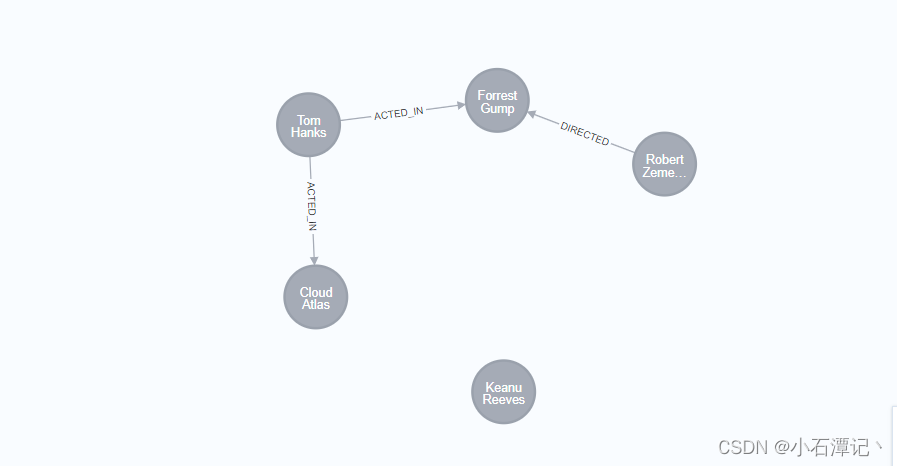
如果要合并两个具有相同结果结构的语句的结果,可以使用UNION [ALL].
例如,以下语句同时列出了演员和导演:
MATCH (actor:Person)-[r:ACTED_IN]->(movie:Movie)
RETURN actor.name AS name, type(r) AS type, movie.title AS title
UNION
MATCH (director:Person)-[r:DIRECTED]->(movie:Movie)
RETURN director.name AS name, type(r) AS type, movie.title AS title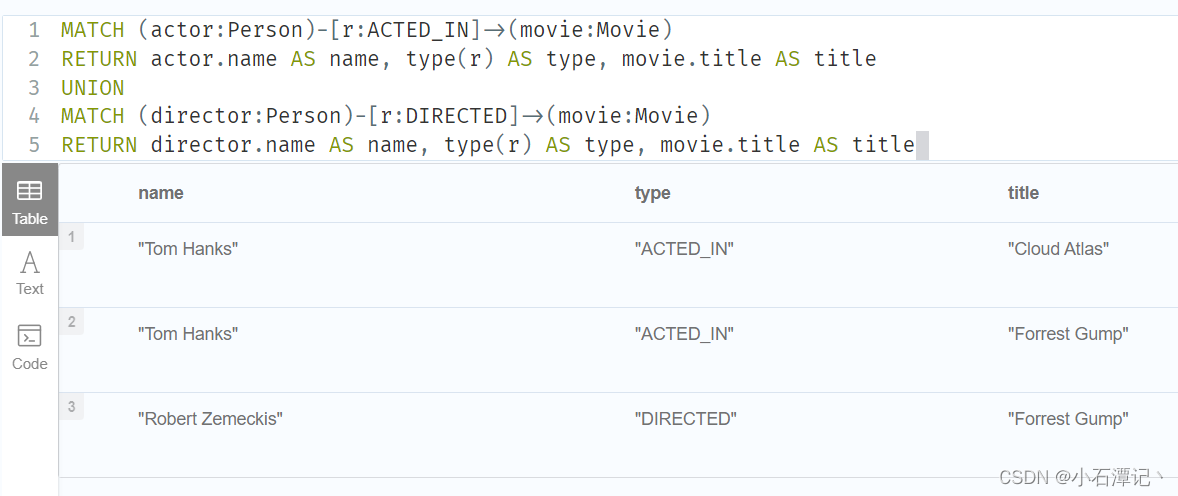
MATCH (actor:Person)-[r:ACTED_IN|DIRECTED]->(movie:Movie)
RETURN actor.name AS name, type(r) AS type, movie.title AS title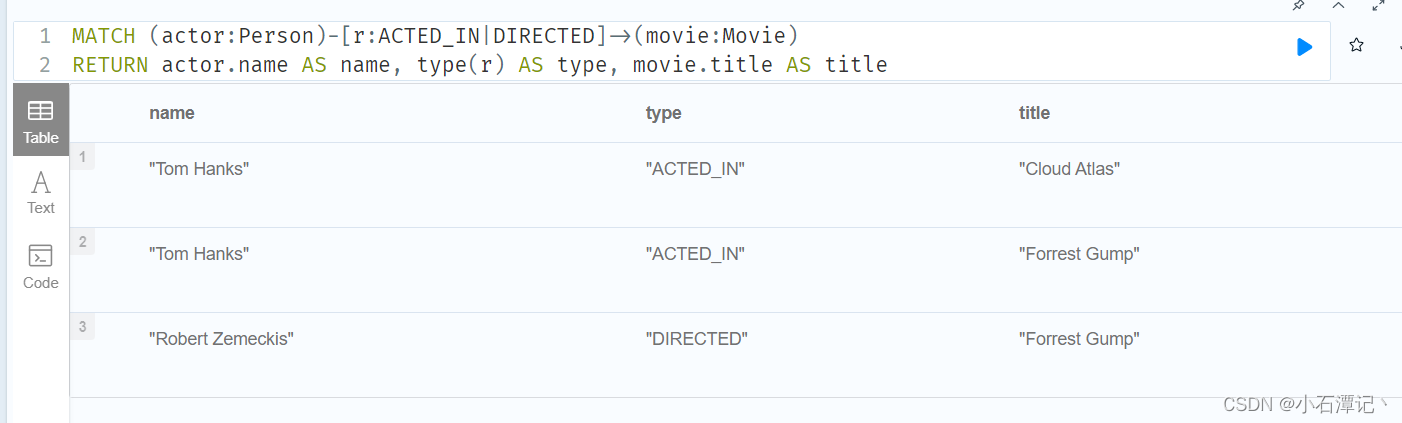
with用法
在 Cypher 中,可以将语句片段链接在一起,类似于在数据流管道中完成的方式。每个片段都处理前一个片段的输出,其结果可以输入下一个片段。 只有在子句中声明的列WITH在后续查询部分中可用。
该WITH子句用于组合各个部分并声明哪些数据从一个部分流向另一个部分。 WITH类似于RETURN从句。不同之处在于该WITH子句不会完成查询,而是为下一部分准备输入。表达式、聚合、排序和分页可以以与RETURN子句中相同的方式使用。唯一的区别是所有列都必须有别名。
MATCH (person:Person)-[:ACTED_IN]->(m:Movie)
WITH person, count(*) AS appearances, collect(m.title) AS movies
WHERE appearances > 1
RETURN person.name, appearances, movies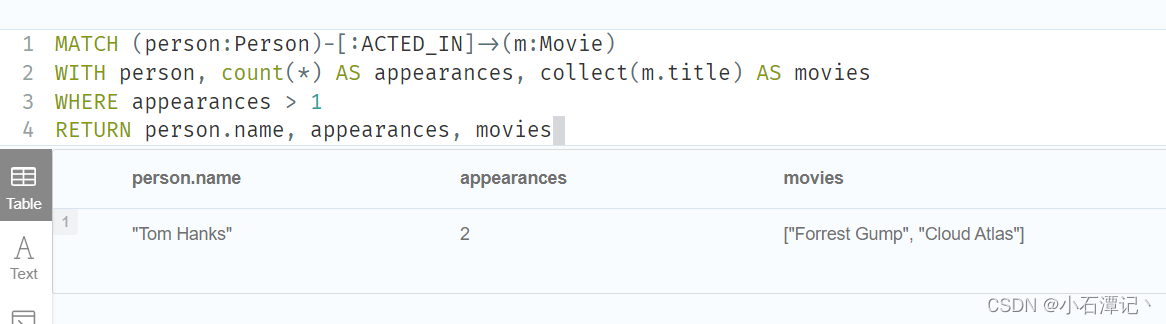
定义模式
准备数据:
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (robert:Person:Director {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person:Actor {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (robert)-[:DIRECTED]->(forrestGump)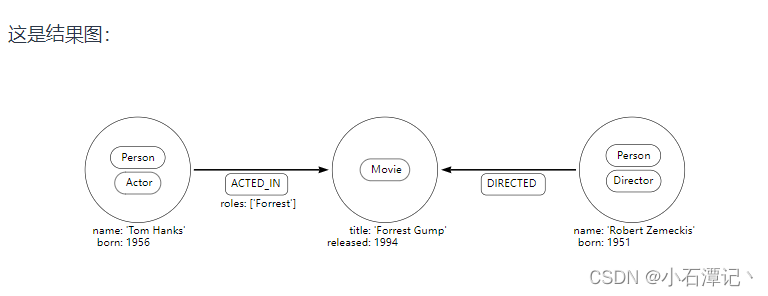
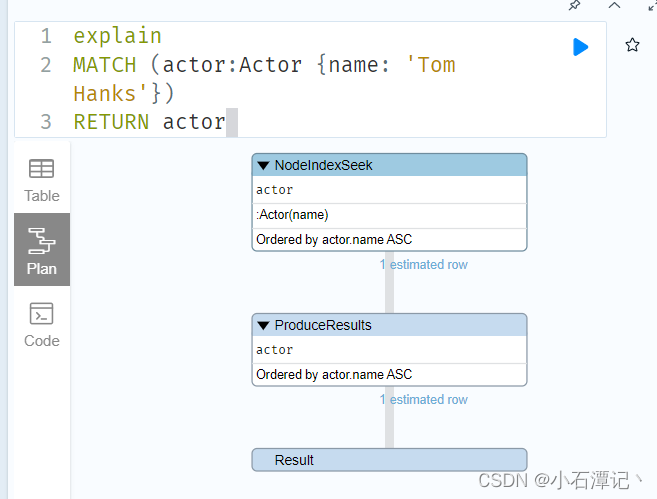
2.使用索引
在图数据库中使用索引的主要原因是找到图遍历的起点。一旦找到该起点,遍历就依靠图内结构来实现高性能。
可以随时添加索引。给节点Actor的name属性创建索引
CREATE INDEX on :Actor(name)explain
MATCH (actor:Actor {name: 'Tom Hanks'})
RETURN actor
查看是否走索引
官方文档 https://neo4j.com/docs/cypher-manual/current/introduction/
https://neo4j.com/docs/cypher-manual/current/introduction/

















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









