










检索策略
Hibernate的Session在加载一个Java对象时,可以将与这个对象相关联的其他Java对象都加载到缓存中,以便程序及时调用。但有些情况下,我们不需要加载太多无用的对象到缓存中,一来这样会撑爆内存,二来增加了访问数据库的次数。所以为了合理的使用缓存,Hibernate提供了几种检索策略来供用户选择。
几种策略简介
<1>.Hibernate的检索策略
在Hibernate中主要有三种检索策略,它们是立即检索策略、延迟检索策略、左外连接检索策略。
下面分别介绍一下这三种检索策略。
立即检索策略
采用立即检索策略,会将被检索的对象,以及和这个对象关联的一对多对象都加载到缓存中。Session的get方法就使用的立即检索策略。
优点:频繁使用的关联对象能够被加载到缓存中。
缺点:1、占用内存。2、Select语句过多。
<2>.延迟检索策略:
采用延迟检索策略,就不会加载关联对象的内容。直到第一次调用关联对象时,才去加载关联对象。在不涉及关联类操作时,延迟检索策略只适用于Session的load方法。涉及关联类操作时,延迟检索策略也能够适用于get,list等操作。
在类级别操作时(也就是只涉及一张表时), 延迟检索策略,只加载类的OID不加载类的其他属性,只用当第一次访问其他属性时,才会访问数据库去加载内容。
在关联级别操作时(也就是有一对多,多对多…关联关系时, 涉及多张表时),延迟检索策略,只加载类本身,不加载关联类,直到第一次调用关联对象时,才去加载关联对象
程序的默认模式都是用延迟加载策略。如果需要指定使用延迟加载策略。在配置文件中设置<class>的lazy=true,<set>的lazy=true或extra(增强延迟)<many-to-one>的lazy=proxy和no-proxy。
优点:由程序决定加载哪些类和内容,避免了大量无用的sql语句和内存消耗。
缺点:在Session关闭后,就不能访问关联类对象了。强行访问就会发生赖加载异常, 所以需要确保在Session.close方法前,调用关联对象。
<3>.左外连接检索策略:
采用左外连接检索,能够使用Sql的外连接查询,将需要加载的关联对象加载在缓存中。<set>fetch设置为join,<many-to-one>的fetch设置为 join
fetch除join取值外, 还有select和subselect的取值,它们决定了发起的sql语句的形式, 分开独立的select查询, 还是子查询, 还是外连接查询.
优点:1.对应用程序完全透明,不管对象处于持久化状态,还是游离状态,应用程序都可以方便的从一个对象导航到与它关联的对象。2.使用了外连接,select语句数目少。
缺点:1.可能会加载应用程序不需要访问的对象,白白浪费许多内存空间。2.复杂的数据库表连接也会影响检索性能。
batch-size属性:
无论是立即检索还是延迟检索,都可以指定关联查询的数量,这就需要使用batch-size属性来指定,指定关联查询数量,以减少批量检索的数据数目。从而提高检索的性能。
检索策略举例与比较
在一个类的情况下,比较立即检索和延迟检索:
<class>标签上默认模式下: load方法,和<class lazy="false">会话的load方法。
什么时候用懒加载,什么时候不用: 如果程序加载一个对象的目的是为了访问它的某个属性, 就用立即加载, 如果加载对象是为了拿到它的应用, 就用延迟加载!
在关联级别操作时(也就是有一对多,多对多…关联关系时, 涉及多张表时),延迟检索策略,只加载类本身,不加载关联类,直到第一次调用关联对象时,才去加载关联对象, 这里主要说一下lazy=extra(增强延迟)表示,加载对象的时间,能延迟就尽可能的延迟,比lazy=true进一步的延迟。
例1:比较立即加载与延迟加载,用前面学的Teacher,Student双向多对一的例子为基础测试
本多对一关联表,由学生维护关系,老师用<set>属性来包果所有他带的学生,所以延迟(加载)性在该标签内设置
1例.我不在标签中设置lazy=“true”,即不显示的写出它,默认为lazy=“true",看看get,load方法的sql语句执行情况
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Teacher" table="t_teacher">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="tname" type="java.lang.String">
<column name="t_name" />
</property>
<set name="students" table="t_students" inverse="true">
<key>
<column name="teacher_id" />
</key>
<one-to-many class="Student" />
</set>
</class>
</hibernate-mapping>
测试:先创建8个学生(zs1-4,ls1-4),4个老师(yx1-4),再我们获取第一个老师,和它学生的情况
@Test //检索策略测试
public void selectpolicyTest() {
//先加八个学生(zs1-4,ls1-4),四个老师(yx1-4)
/*Teacher teacher =new Teacher();
teacher.setTname("yx4");
Student student1=new Student();
student1.setSname("zs4");
student1.setTeacher(teacher);
Student student2=new Student();
student2.setSname("ls4");
student2.setTeacher(teacher);
Set<Student> students = new HashSet<>();
students.add(student1);
students.add(student2);
teacher.setStudents(students);
session.save(teacher);
session.save(student1);
session.save(student2);*/
Teacher teacher=session.get(Teacher.class, 1);
//Teacher teacher=session.load(Teacher.class, 1);
teacher.getStudents();
Sysout.out.println(teacher);
}
----------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_
from
t_teacher teacher0_
where
teacher0_.id=?
//System.out.println(teacher);发送的sql语句,说明懒加载没用到关联类时不加载它
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_
from
t_teacher teacher0_
where
teacher0_.id=?
上面的代码,get,load一样效果
Teacher teacher=session.get(Teacher.class, 1);
//Teacher teacher=session.load(Teacher.class, 1);
System.out.println(teacher.getStudents());
System.out.println(teacher);
-------------------------------------------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_
from
t_teacher teacher0_
where
teacher0_.id=?
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
[Student [id=1, sname=zs1], Student [id=2, sname=ls1]]
//System.out.println(teacher);发送的sql语句,说明懒加载没用到关联类时不加载它
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_
from
t_teacher teacher0_
where
teacher0_.id=?
Teacher [id=1, tname=yx1]
上面的代码get,load一样效果
2例:我在<set>标签中设置lazy=“false”,即显示的写出它,看看get,load方法的sql语句执行情况
Teacher teacher=session.get(Teacher.class, 1);
//Teacher teacher=session.load(Teacher.class, 1);
System.out.println(teacher);
----------------------------------------------------------------------------
//没有设置懒加载性能,即get方法,即使没有要查询关联对象,也会立即载它
//load也会失去懒加载性质,此时发送的sql语句和get方法一样
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_
from
t_teacher teacher0_
where
teacher0_.id=?
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
Teacher [id=1, tname=yx1]
3.例:我在<set>标签中设置lazy=“true”,即显示的写出它,看看get,load方法的sql语句执行情况
//用上面的经测试,和上面的效果一样
Teacher teacher=session.get(Teacher.class, 1);
System.out.println("学生有:"+teacher.getStudents().size()+"个");
-------------------------------------------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_
from
t_teacher teacher0_
where
teacher0_.id=?
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
学生有:2个
4.例:.lazy=extra(增强延迟)实验
<set name="students" table="t_students" inverse="true" lazy="extra">
Teacher teacher=session.get(Teacher.class, 1);
System.out.println("学生有:"+teacher.getStudents().size()+"个");
----------------------------------------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_
from
t_teacher teacher0_
where
teacher0_.id=?
Hibernate:
select
count(id)
from
student
where
teacher_id =?
学生有:2个
注意一下,这里的增强延迟性用上了后,连关联学生查询sql语句都不用了,只用了个count方法统计记录数了
5例:lazy=true的时候, 也可以让延迟失效,Hibernate.initialize()这个静态方法
Teacher teacher=session.get(Teacher.class, 1);
Hibernate.initialize(teacher.getStudents());
-----------------------------------------------------------------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_
from
t_teacher teacher0_
where
teacher0_.id=?
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
上面的代码执行效果,与1例,比较发现,这里加载了Student关联对象了,而1例中,只加载了Teacher对象,说明此上面的代码initial(xxx)使懒加载(延[迟性)失效了。这种方式适合在大环境是延迟性,局部要用到立即加载的情况下。*
6例.batch-size=“xxx”实验,没有batch-size, 有几个老师发起几条sql语句, 配置batch-size, 就会发起这个值整数倍的sql语句
无论是立即检索还是延迟检索,都可以指定关联查询的数量,这就需要使用batch-size属性来指定,指定关联查询数量,以减少批量检索的数据数目。从而提高检索的性能。
<set name="students" table="t_students" inverse="true"
lazy="true" batch-size="4">
//batch-size=“xxx" 测试
String hql="from Teacher";
Query<Teacher> query=session.createQuery(hql);
List<Teacher> lists=query.list();
for(Teacher t:lists) {
System.out.println(t.getStudents());
}
-------------------------------------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_,
teacher0_.t_name as t_name2_1_
from
t_teacher teacher0_
Hibernate:
select
students0_.teacher_id as teacher_3_0_1_,
students0_.id as id1_0_1_,
students0_.id as id1_0_0_,
students0_.s_name as s_name2_0_0_,
students0_.teacher_id as teacher_3_0_0_
from
student students0_
where
students0_.teacher_id in (
?, ?, ?, ?
)
[Student [id=1, sname=zs1], Student [id=2, sname=ls1]]
[Student [id=3, sname=zs2], Student [id=4, sname=ls2]]
[Student [id=6, sname=ls3], Student [id=5, sname=zs3]]
[Student [id=7, sname=zs4], Student [id=8, sname=ls4]]
另看一个,不设置batch-size的实验
<set name="students" table="t_students" inverse="true"
lazy="true">
//batch-size=“xxx" 测试
String hql="from Teacher";
Query<Teacher> query=session.createQuery(hql);
List<Teacher> lists=query.list();
for(Teacher t:lists) {
System.out.println(t.getStudents());
}
-------------------------------------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_,
teacher0_.t_name as t_name2_1_
from
t_teacher teacher0_
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
[Student [id=2, sname=ls1], Student [id=1, sname=zs1]]
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
[Student [id=3, sname=zs2], Student [id=4, sname=ls2]]
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
[Student [id=6, sname=ls3], Student [id=5, sname=zs3]]
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
[Student [id=7, sname=zs4], Student [id=8, sname=ls4]]
有关fetch实验,包括左外连接检索策略
select—>subselect,把in(?,?)语句变成了子查询!从原来的发起4条sql变成1条了! 这个时候, lazy有效, batch-size失效!
取值是join时,不能和batch-size属性一起用, 加载一这端对象时,它会用左外连接将关联对象一起加载进来 ! 而且这时lazy属性没有作用了!
7例:取值为: “select”(默认值)和"subselect"时发起的sql语句有什么不同?
fetch=“select”
<set name="students" table="t_students" inverse="true" lazy="true" fetch="select">
String hql="from Teacher";
Query<Teacher> query=session.createQuery(hql);
List<Teacher> lists=query.list();
for(Teacher t:lists) {
System.out.println("该老师有"+t.getStudents().size()+"个学生");
}
-------------------------------------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_,
teacher0_.t_name as t_name2_1_
from
t_teacher teacher0_
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
该老师有2个学生
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
该老师有2个学生
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
该老师有2个学生
Hibernate:
select
students0_.teacher_id as teacher_3_0_0_,
students0_.id as id1_0_0_,
students0_.id as id1_0_1_,
students0_.s_name as s_name2_0_1_,
students0_.teacher_id as teacher_3_0_1_
from
student students0_
where
students0_.teacher_id=?
该老师有2个学生
fetch=“subselect”
<set name="students" table="t_students" inverse="true" lazy="true" fetch="subselect">
String hql="from Teacher";
Query<Teacher> query=session.createQuery(hql);
List<Teacher> lists=query.list();
for(Teacher t:lists) {
System.out.println("该老师有"+t.getStudents().size()+"个学生");
}
-------------------------------------------------------------------------------
Hibernate:
select
teacher0_.id as id1_1_,
teacher0_.t_name as t_name2_1_
from
t_teacher teacher0_
Hibernate:
select
students0_.teacher_id as teacher_3_0_1_,
students0_.id as id1_0_1_,
students0_.id as id1_0_0_,
students0_.s_name as s_name2_0_0_,
students0_.teacher_id as teacher_3_0_0_
from
student students0_
where
students0_.teacher_id in (
select
teacher0_.id
from
t_teacher teacher0_
)
该老师有2个学生
该老师有2个学生
该老师有2个学生
该老师有2个学生
8例:fetch="join"左外连接查询
//hql语法的sql名,在fetch="join“,后面的配置无效,所以join测试不能用hql查询
Teacher teacher = session.load(Teacher.class, 1);
System.out.println(teacher.getStudents().size());
-------------------------------------------------------------------------
/*只有一条sql查询语锯,没有了上面的共公的
select
teacher0_.id as id1_1_,
teacher0_.t_name as t_name2_1_
from
t_teacher teacher0_*/
Hibernate:
select
teacher0_.id as id1_1_0_,
teacher0_.t_name as t_name2_1_0_,
students1_.teacher_id as teacher_3_0_1_,
students1_.id as id1_0_1_,
students1_.id as id1_0_2_,
students1_.s_name as s_name2_0_2_,
students1_.teacher_id as teacher_3_0_2_
from
t_teacher teacher0_
left outer join
student students1_
on teacher0_.id=students1_.teacher_id
where
teacher0_.id=?
2
HQL检索方式
Hibernate的检索方式的概述
Hibernate检索数据的五种方式:
1.导航对象图检索方式。(根据已经加载的对象,导航到其他对象--如关联对象的查询。)
2.OID检索方式。(按照对象的OID来检索对象。前面讲的get,load就是这种)
3.HQL检索方式。(使用面向对象的HQL查询语言。)
4.QBC检索方式。(使用QBC(Qurey By Criteria) API来检索对象。用的不多)
5.本地SQL检索方式。(使用本地数据库的SQL查询语句。)
HQL检索方式
HQL(Hibernate Query Language)是面向对象的查询语言,它和SQL查询语言有些相似。在Hibernate提供的各种检索方式中,HQL是使用最广的一种检索方式。它具有以下功能:
在查询语句中设定各种查询条件。
支持投影查询,即仅检索出对象的部分属性。
支持分页查询。
支持分组查询,允许使用group by和having关键字。
提供内置聚集函数,如sum()、min()和max()。
能够调用用户定义的SQL函数。
支持子查询,即嵌套查询。
支持动态绑定参数,如sql语句的?占位符。
Session类的Qurey接口支持HQL检索方式,它提供了以上列出的各种查询功能。
注:Qurey接口支持方法链编程风格,它的set方法都返回自身实例,而不是返回void类型。方法链编程风格能使程序代码更加简洁。
示例代码:Teacher,Student中的双向多对一关联的例子中的代码为基础
//HQL
@Test
public void HqlTest() {
//写hql
/*String hql = "from Teacher";
Query<Teacher> query=session.createQuery(hql);
//如果hql有条件,使用?占位符,动态的参数绑定
List<Teacher> teachers = query.list();*/
//或可写成方法链方式
List<Teacher> teachers =session.createQuery("from Teacher").list();
System.out.println(Arrays.toString(teachers.toArray()));
}
QBC(Qurey By Criteria)
和QBC的子功能QBE(Qurey By Example)检索方式
criteria = session.createCriteria(User.class)
1.获取CriteriaBuilder对象
CriteriaBuilder build = session.getCriteriaBuilder();
2.获取CriteriaQuery
CriteriaQuery<Department> criteriaQuery=build.createQuery(Department.class);
3.指定根条件
Root<Department> root=criteriaQuery.from(Department.class);
crq.select(root);
crq.where(build.like(root.get("departmentName"),"%A%"));
4.执行查询
Query<Department> query = session.createQuery(criteriaQuery);
5.返回查询结果集
List<Department> lists =query.getResultList();
本地SQL检索方式
采用HQL检索方式时,Hibernate生成标准的SQL查询语句,使用于所有的数据库平台,因此这种检索方式是跨平台的。有的应用程序可能需要根据底层数据库的SQL方言,来生成一些特殊的查询语句。在这种需求情况下,Hibernate提供的原生SQL检索方式。
示例代码:
Query<Object[]> query = session.createNativeQuery("select t.* from teacher as t where t.name like :tname and t.id=:tid");
// 动态绑定参数
query.setParameter("tname", "zs").setParameter("tid", 1);
// 执行检索
List<Object[]> result = query.list();
for(Object[] objs:result) {
System.out.println(Arrays.toString(objs));
}
以上我们看到了五种检索方式的应用的概述
HQL基础知识
准备
1.把employees数据库的两个表,复制到hibernate5数据库中,然后通过手工修改dept_no为int数据类型,前提是要先删除所有的给约束和外键,我们只是利用一下员工中数据,再通自已定义Department,Employee来建立两者对应的双向多对一关联,在employees中将建立一个外键,对应departments中的主键关联。
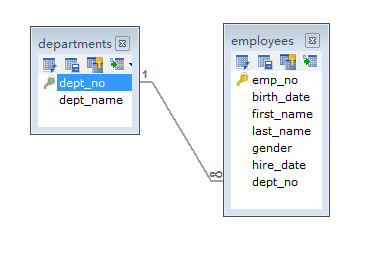
2.建两个类,Deptemp.java,Employee.java形式多对一双向的关系,由多端(Employee)维护关系
Department.java—Department.hbm.xml
public class Department {
private int deptNo;
private String deptName;
private Set<Employee> employees; //多对一双向的,一个部门有多个员工
//get,set,toString()不显示关联对象信息,避免栈溢出,无参构造
}
------------------------------------------------------------------------------------------------------------------------
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Department" table="departments">
<id name="deptNo" type="int">
<column name="dept_no" />
<generator class="native" />
</id>
<property name="deptName" type="string">
<column name="dept_name" />
</property>
<set name="employees" table="employees" inverse="true" lazy="true">
<key>
<column name="dept_no" />
</key>
<one-to-many class="Employee" />
</set>
</class>
</hibernate-mapping>
Employee.java ----Employee.hbm.xml
public class Employee {
private int empNo;
private Date birthDate;
private String firstName;
private String lastName;
private String gender;
private Date hireDate;
private Department department; //每个员工都员一个部门
//get,set,toString()不显示关联对象信息,避免栈溢出,无参构造
}
------------------------------------------------------------------------------------------------------------------------
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Employee" table="employees">
<id name="empNo" type="int">
<column name="emp_no" />
<generator class="native" />
</id>
<property name="birthDate" type="java.util.Date">
<column name="birth_date" />
</property>
<property name="firstName" type="java.lang.String">
<column name="first_name" />
</property>
<property name="lastName" type="java.lang.String">
<column name="last_name" />
</property>
<property name="gender" type="java.lang.String">
<column name="gender" />
</property>
<property name="hireDate" type="java.util.Date">
<column name="hire_date" />
</property>
<many-to-one name="department" class="Department" >
<column name="dept_no" />
</many-to-one>
</class>
</hibernate-mapping>
hibernate.cfg.xml核心配置文件
<mapping resource="cn/ybzy/hibernatedemo/model/Employee.hbm.xml"/>
<mapping resource="cn/ybzy/hibernatedemo/model/Department.hbm.xml"/>
测试1:动态参数绑定,只查询大于5的编号的部门并且是包含 Q字母的部门
/*String hql="from Department d where d.deptNo>? and d.deptName like ?";
Query<Department> query=session.createQuery(hql);
List<Department> departments=query.setParameter(0,5).setParameter(1, "%Q%").list();
System.out.println(Arrays.toString(departments.toArray()));*/
//这里要0,1是占位符起始位置,可读性差,我们可用别名来代替,
String hql="from Department d where d.deptNo> :did and d.deptName like :dname";
Query<Department> query=session.createQuery(hql);
List<Department> departments=query.setParameter("did",5).setParameter("dname", "%Q%").list();
System.out.println(Arrays.toString(departments.toArray()));
------------------------------------------------------------------------------------------------------------------------------------
Hibernate:
select
department0_.dept_no as dept_no1_0_,
department0_.dept_name as dept_nam2_0_
from
departments department0_
where
department0_.dept_no>?
and (
department0_.dept_name like ?
)
[Department [deptNo=6, deptName=Quality Management]]
测试2: 查询1号部站下的所有员工,直接可用部门对象查,这在传统的sql语句中是不可能这样做的
String hql="from Employee e where e.department=?";
Department department=new Department();
department.setDeptNo(1);
System.out.println(Arrays.toString(session.createQuery(hql)
.setParameter(0, department)
.list().toArray()));
------------------------------------------------------------------------------------------------------------------------
Hibernate:
select
employee0_.emp_no as emp_no1_1_,
employee0_.birth_date as birth_da2_1_,
employee0_.first_name as first_na3_1_,
employee0_.last_name as last_nam4_1_,
employee0_.gender as gender5_1_,
employee0_.hire_date as hire_dat6_1_,
employee0_.dept_no as dept_no7_1_
from
employees employee0_
where
employee0_.dept_no=?
[Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, lastName=Facello, gender=M, hireDate=1986-06-26 01:00:00.0], Employee [empNo=10002, birthDate=1964-06-02 00:00:00.0, firstName=Bezalel, lastName=Simmel, gender=F, hireDate=1985-11-21 00:00:00.0], Employee [empNo=10003, birthDate=1959-12-03 00:00:00.0, firstName=Parto, lastName=Bamford, gender=M, hireDate=1986-08-28 01:00:00.0], Employee [empNo=10004, birthDate=1954-05-01 00:00:00.0, firstName=Chirstian, lastName=Koblick, gender=M, hireDate=1986-12-01 00:00:00.0], Employee [empNo=10032, birthDate=1960-08-09 00:00:00.0, firstName=Jeong, lastName=Reistad, gender=F, hireDate=1990-06-20 01:00:00.0], Employee [empNo=10033, birthDate=1956-11-14 00:00:00.0, firstName=Arif, lastName=Merlo, gender=M, hireDate=1987-03-18 00:00:00.0],......
HQL查询分页-HQL映射文件中-查询表的部分字段
1.分页查询主要靠两个方法来实现:
1.setFirstResult(index) : 从index这个索引值开始查询数据库的记录, index从0开始
2.setMaxResults(数量) : 表示从起始的索引对应的记录开始, 最多查询出的记录数目
String hql= "from Employee";
int pageNo=2;
int pageSize=2;
Query<Employee> query=session.createQuery(hql);
query.setFirstResult((pageNo-1)*pageSize);
query.setMaxResults(pageSize);
List<Employee> emp = query.list();
System.out.println(Arrays.toString(emp.toArray()));
2.HQL语句放到映射文件中
把hql语句放到映射文件中的查询又叫做命名查询!
命名查询HQL语句,通过Session的getNameQuery()方法来获得查询语句,具体应用看例子:
...
</class>
<query name="nameQuery"><![CDATA[from Employee e where e.empNo >? and e.empNo<?]]></query>
</hibernate-mapping>
Query<Employee> query=session.getNamedQuery("nameQuery");
query.setParameter(0, 11001).setParameter(1, 11100);
List<Employee> employees=query.list();
//System.out.println(Arrays.toString(employees.toArray()));
for(Employee e:employees) {
System.out.println(e.getEmpNo()+" 姓名:"+e.getFirstName()+e.getLastName());
3.只查询出表中的部分字段
只查询出表中的部分字段, 在Hibernate中叫做投影查询:
第一种解决方案:
String hql="select e.firstName,e.hireDate from Employee e";
//String hql="select e.firstName from Employee e";
Query<Object[]> query=session.createQuery(hql);
//Query<String> query=session.createQuery(hql);
List<Object[]> objs=query.list();
//List<String> objs=query.list();
for(String objes:objs) {
System.out.println(Arrays.toString(objes));
//System.out.println(objes);
}
解析:从方法的返回值来看,我们可以发现投影查询返回的是一个List<Object[]>类型,这是因为我们查询的字段是多个,所以是Object[]数组,如果我们业务层很多方法都是以对象来传递的,突然来了一个Object[]数组,可能我又要重写一个对应的方法来处理这个家伙,那样投影查询也就得不偿失了!
第二种解决方案:对象查询
1.先到Employee.java中定义构造方法,只含有要查询字段构造方法
public Employee(String firstName, Date hireDate) {
this.firstName = firstName;
this.hireDate = hireDate;
}
2.再测试,这里我设置一个占位符,用于动态设定要查找的员工编号范围
String hql="select new Employee(e.firstName,e.hireDate) from Employee e where e.empNo<?";
List<Employee> lists = session.createQuery(hql).setParameter(0, 10031).list();
System.out.println(Arrays.toString(lists.toArray()));
------------------------------------------------------------------
Hibernate:
select
employee0_.first_name as col_0_0_,
employee0_.hire_date as col_1_0_
from
employees employee0_
where
employee0_.emp_no<?
[Employee [empNo=0, birthDate=null, firstName=Georgi, lastName=null, gender=null, hireDate=1986-06-26 01:00:00.0], 。。。。
解析:可以看出第二种解决方案返回的对象(被泛型限定的Employee),这种方式解决了传递Object[]方式,只传递对象了,且也实现了,只查询部分属性,需要注意的是Employee 映射对象中必须要有对应查询语句的参数的构造方法
4.HQL语句汇总使用聚合函数
String hql = "select sum(e.empNo),min(e.empNo),max(e.empNo),e. department from Employee e"
+ " group by e.department.deptNo having e.department.deptNo > ?";
List<Object[]> lists = session.createQuery(hql).setParameter(0, 5).list();
for(Object[] objs:lists) {
System.out.println(Arrays.toString(objs));
}
----------------------------------------------------------------------------------------------------------------
Hibernate:
select
sum(employee0_.emp_no) as col_0_0_,
min(employee0_.emp_no) as col_1_0_,
max(employee0_.emp_no) as col_2_0_,
employee0_.dept_no as col_3_0_,
department1_.dept_no as dept_no1_0_,
department1_.dept_name as dept_nam2_0_
from
employees employee0_
inner join
departments department1_
on employee0_.dept_no=department1_.dept_no
group by
employee0_.dept_no
having
employee0_.dept_no>?
[60213, 10021, 10050, Department [deptNo=6, deptName=Quality Management]]
[60231, 10024, 10053, Department [deptNo=7, deptName=Sales]]
[388649, 10027, 10278, Department [deptNo=8, deptName=Research]]
[307026, 10030, 10301, Department [deptNo=9, deptName=Customer Service]]
HQL连接查询
和SQL查询一样,HQL也支持各种各样的连接查询,如内连接、外连接。我们知道在SQL中可通过join子句实现多表之间的连接查询。HQL同样提供了连接查询机制,还允许显式指定迫切内连接和迫切左外连接。HQL提供的连接方式:
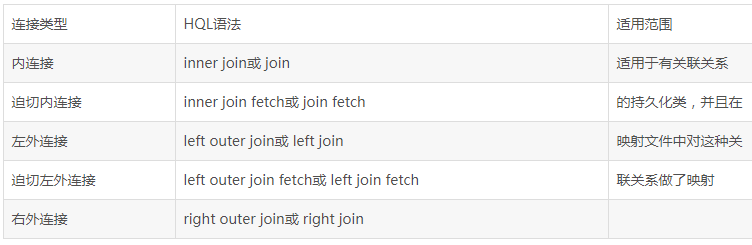
迫切连接是指在指定连接方式时不仅指定了连接查询方式,而且显式地指定了关联级别的查询策略。Hibernate使用fetch关键字实现,fetch关键字表明“左边”对象用于与“右边”对象关联的属性会立即被初始化(立即加载)。平时项目中都建议使用fetch!
1.内连接
String hql = "from Employee e inner join e.department d where e.empNo<10031";
List<Object[]> lists = session.createQuery(hql).list();
for(Object[] objs:lists) {
System.out.println(Arrays.toString(objs));
}
----------------------------------------------------------------------------------------------------------------
[Employee [empNo=10002, birthDate=1964-06-02 00:00:00.0, firstName=Bezalel, lastName=Simmel, gender=F, hireDate=1985-11-21 00:00:00.0], Department [deptNo=1, deptName=Marketing]]
[Employee [empNo=10003, birthDate=1959-12-03 00:00:00.0, firstName=Parto, lastName=Bamford, gender=M, hireDate=1986-08-28 01:00:00.0], Department [deptNo=1, deptName=Marketing]]
....
2.迫切内连接,仍用上面的hql,这次返回的不是Object[]数据,而Employee对象,
String hql = "from Employee e inner join fetch e.department d where e.empNo<10031";
List<Employee> lists = session.createQuery(hql).list();
for(Employee e:lists) {
System.out.println(e);
}
----------------------------------------------------------------------------------------------------------------
Employee [empNo=10017, birthDate=1958-07-06 00:00:00.0, firstName=Cristinel, lastName=Bouloucos, gender=F, hireDate=1993-08-03 00:00:00.0]
Employee [empNo=10019, birthDate=1953-01-23 00:00:00.0, firstName=Lillian, lastName=Haddadi, gender=M, hireDate=1999-04-30 00:00:00.0]
有,fetch,没有fetch的区别测试
//3.有,fetch,没有fetch的区别测试
String hql = "select e from Employee e inner join e.department d where e.empNo<? and d.deptNo>?";
List<Employee> lists = session.createQuery(hql).setParameter(0, 10031).
setParameter(1, 5).list();
System.out.println(lists);
使用结论:
①使用from…没加fetch和加了,得到的结果类型是不一样的
②使用select指定查询对象时, 加了fetch, 获取employee对象的关联对象department时, 只发起一条sql, 反之发起多条sql, 根据发起的sql条数越少效率越高的原则,项目开发中, 我们推荐都加fetch
fetch关键字只对inner join和left join有效。right join基本也不用,这里都不多说了!
HQL批量增删改
批量处理数据是指在一个事务场景中处理大量数据。
HQL可以批量查询数据-前面已看到很多例子,也可以批量插入、更新和删除数据。HQL批量操作实际上直接在数据库中完成,处理的数据不需要加载至Session缓存中。使用Query接口的executeUpdate()方法执行用于插入、更新和删除的HQL语句。不过我没用到批量增加。要用的话也不会用HQL.
准备一个关系映射Test类表,除了关联Department,即不建与其它表的关系,其它都与Employee一样,测试用,省得搞乱了我的Employee映射表
1.批量添加,下面添加数据到Test表中,数据来源于子查询得到的Employee映射表数据
注意:HQL单条是插入不了,可以用原生SQL或session.save()来做
String hql = "insert into Test (empNo,firstName,lastName)"
+" select empNo,firstName,lastName from Employee";
int rs = session.createQuery(hql).executeUpdate();
System.out.println(rs);
2.批量删除,用得比较多
//2.批量删除
String hql="delete from Test t where t.empNo >11000";
int rs=session.createQuery(hql).executeUpdate();
System.out.println(rs);
3.批量修改
String hql = "update Test set firstName=?";
int rs=session.createQuery(hql).setParameter(0, "xiongshaowen").executeUpdate();
System.out.println(rs);
QBC检索和本地SQL检索
QBC检索
Hibenate的QBC查询:
1.获取到CriteriaBuilder对象
CriteriaBuilder builder = session.getCriteriaBuilder();
2.获取CriteriaQuery
CriteriaQuery<Department> criteriaQuery = builder.createQuery(Department.class);
3.获取到根对象, 构造各种各样的查询条件
Root<Department> root=criteriaQuery.from(Department.class);
Predicate predicate = builder.like(root.get("departmentName"), "%A%");
Predicate predicate2 = builder.equal(root.get("departmentId"), 10);
Predicate predicate3 = builder.and(predicate,predicate2);
criteriaQuery.select(root.get("departmentId"));
criteriaQuery.where(predicate3);
4.获取到Query对象
Query<Department> query = session.createQuery(criteriaQuery);
5.执行并返回查询结果集
query.list();
例:查询员工编号在10001到20000之间所有员工的第一姓名
CriteriaBuilder builder = session.getCriteriaBuilder();
CriteriaQuery<Employee> criteriaQuery=builder.createQuery(Employee.class);
Root<Employee> root = criteriaQuery.from(Employee.class);
//构造条件,即empNo>10001,且小于20000,且部门号等于5
Predicate predicate1 = builder.gt(root.get("empNo"), 10001);
Predicate predicate2 = builder.lt(root.get("empNo"), 20000);
Predicate predicate3 = builder.equal(root.get("department"), 5);
Predicate predicate = builder.and(predicate1,predicate2,predicate3); //and,or ,not...
//构造条件,这里只查第一名字
criteriaQuery.select(root.get("firstName"));
criteriaQuery.where(predicate);
Query<Employee> query=session.createQuery(criteriaQuery);
List<Employee> employees = query.list();
System.out.println(employees);
--------------------------------------------------------
Hibernate:
select
employee0_.first_name as col_0_0_
from
employees employee0_
where
employee0_.emp_no>10001
and employee0_.emp_no<20000
and employee0_.dept_no=5
[Cristinel, Lillian, Mayuko, Moss, Lucien, Zvonko, Yongmin, Zhenhua, Genta, K。。。。。
本地SQL检索,注:占位符位置从1开始,而前面的HQL是从0开始的
String sql="select * from employees e where emp_no < ?";
//String sql="insert into employees(first_name) values(?);
NativeQuery<Object[]> query=session.createNativeQuery(sql);
List<Object[]> lists = query.setParameter(1, 10031).list();
for(Object[] objs:lists) {
System.out.println(Arrays.toString(objs));
}
----------------------------------------------------------------------------------------------------------------
Hibernate:
select
*
from
employees e
where
emp_no < ?
[10001, 1953-09-02, Georgi, Facello, M, 1986-06-26, 1]
[10002, 1964-06-02, Bezalel, Simmel, F, 1985-11-21, 1]
[10003, 1959-12-03, Parto, Bamford, M, 1986-08-28, 1]
[10004, 1954-05-01, Chirstian, Koblick, M, 1986-12-01, 1]
Hibernate二级缓存
Cache就是缓存,它往往是提高系统性能的最重要手段,对数据起到一个蓄水池和缓冲的作用。
Cache对于大量依赖数据读取操作的系统而言尤其重要。在大并发量的情况下,如果每次程序都需要向数据库直接做查询操作,它们所带来的性能开销是显而易见的,频繁的网络请求,数据库磁盘的读写操作都会大大降低系统的性能。
此时如果能让数据库在本地内存中保留一个镜像,下次访问的时候只需要从内存中直接获取,那么显然可以带来不小的性能提升。
引入Cache机制的难点是如何保证内存中数据的有效性,否则脏数据的出现将会给系统带来难以预知的严重后果。
虽然一个设计得很好的应用程序不用Cache也可以表现出让人接受的性能,但毫无疑问,一些对读取操作要求比较高的应用程序可以通过Cache获得更高的性能。
对于应用程序,Cache通过内存或磁盘保存了数据库中的当前有关数据状态,它是一个存储在本地的数据备份。Cache位于数据库和应用程序之间,从数据库更新数据,并给程序提供数据。
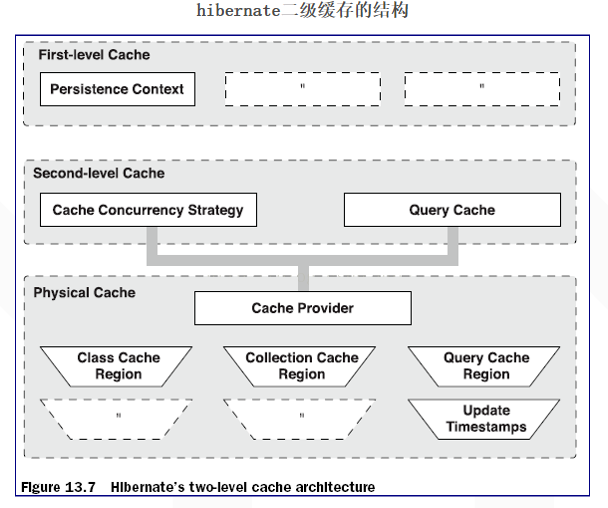
Hibernate实现了良好的Cache机制,可以借助Hibernate内部的Cache迅速提高系统的数据读取性能。Hibernate中的Cache可分为两层:一级Cache和二级Cache。
一级缓存:
Hibernate默认是开启一级缓存的,一级缓存存放在session上,属于事务级数据缓冲。
二级缓存:
二级缓存是在SessionFactory,所有的Session共享同一个二级Cache。二级Cache的内部如何实现并不重要,重要的是采用哪种正确的缓存策略,以及采用哪个Cache提供器。
二级缓存也分为了两种
1.内置缓存:Hibernate自带的,不可卸载,通常在Hibernate的初始化阶段,Hibernate会把映射元数据和提前定义的SQL语句放置到SessionFactory的缓存中。该内置缓存是仅仅读的。
2.外置缓存:通常说的二级缓存也就是外置缓存,在默认情况下SessionFactory不会启用这个缓存插件,外置缓存中的数据是数据库数据的复制,外置缓存的物理介质能够是内存或者硬盘。
并发訪问策略

适合放入二级缓存中数据
非常少被改动
不是非常重要的数据。同意出现偶尔的并发问题
不适合放入二级缓存中的数据
常常被改动
財务数据,绝对不同意出现并发问题
与其它应用数据共享的数据
二级缓存的配置
hibernate支持的缓存插件
•EHCache: 可作为进程范围内的缓存,存放数据的物理介质能够是内存或硬盘,对Hibernate的查询缓存提供了支持
•OpenSymphony`:可作为进程范围内的缓存,存放数据的物理介质能够是内存或硬盘,提供了丰富的缓存数据过期策略,对Hibernate的查询缓存提供了支持
•SwarmCache:可作为集群范围内的缓存,但不支持Hibernate的查询缓存
•JBossCache:可作为集群范围内的缓存,支持Hibernate的查询缓存
二级缓存配置步骤
以下以EHCache缓存为例,来讲一下二级缓存的配置
先看一下没有缓存时发起sql语句的条数, 和配置缓存后对比
例:正因为有一级缓存获取数据后后,封装成对象放在缓存中,如果有二级缓存开启了,即使一级缓存中没有对象,也会从二级缓存中存取
当第二次拿同样的对象时,不会发送sql语句了,会从缓存中拿。
我假如在提交后,再关闭会话,同样清理了一级缓存,再获同样的对象时,又会发送一条sql语句,去获取对象。
@Test //级缓存配置测试
public void cacheTest() {
Employee employee=session.get(Employee.class, 10001);
System.out.println(employee);
//transaction,session都在测试类的init方法定义,并一开机初始化了
//transaction.commit();
//session.close();
//session = sessionFactory.openSession();
//transaction = session.beginTransaction();
Employee employee2 = session.get(Employee.class, 10001);
System.out.println(employee2);
}
----------------------------------------------------------------------------------------------------------------
Hibernate:
select
employee0_.emp_no as emp_no1_1_0_,
employee0_.birth_date as birth_da2_1_0_,
employee0_.first_name as first_na3_1_0_,
employee0_.last_name as last_nam4_1_0_,
employee0_.gender as gender5_1_0_,
employee0_.hire_date as hire_dat6_1_0_,
employee0_.dept_no as dept_no7_1_0_
from
employees employee0_
where
employee0_.emp_no=?
Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, lastName=Facello, gender=M, hireDate=1986-06-26 01:00:00.0]
Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, lastName=Facello, gender=M, hireDate=1986-06-26 01:00:00.0]
1 拷贝jar包和创建配置文件ehcache.xml到src目录下
导包,如果是 maven工程的话,就十分简单,不是的话也同样可以到mvnrepository.com网站中查找-
hibernate ehcache,用IE或Edge是最容易打开网站的。
如果没用到maven,则手动去下载如下包
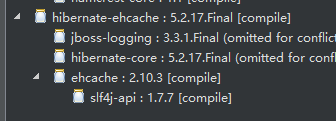
pom.xml
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-ehcache</artifactId>
<version>5.2.17.Final</version>
</dependency>
ehcache.xml
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<diskStore path="c:/ehcache/"></diskStore>
<!-- 默认缓存配置 -->
<defaultCache maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"/>
</ehcache>
2 在hibernate.cfg.xml中开启二级缓存
<property name="hibernate.cache.use_second_level_cache">true</property>
3 hibernate.cfg.xml配置二级缓存技术提供者
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property
4 hibernate.cfg.xml配置使用缓存的类,可以配多个类
<class-cache usage="read-write" class="cn.ybzy.hibernatedemo.model.Employee"/>
例:现在开启了二级缓存,又对Employee起作用,仍用上面的测试代码重新执行一下,发现只发送了一条sql查询语句,说明二级缓存起作用了
@Test //二级缓存配置
public void cacheTest() {
//先看看,有和没有缓存的情况
Employee employee=session.get(Employee.class, 10001);
System.out.println(employee);
transaction.commit();
session.close();
session = sessionFactory.openSession();
transaction = session.beginTransaction();
Employee employee2 = session.get(Employee.class, 10001);
System.out.println(employee2);
}
----------------------------------------------------------------------------------------------------------------
Hibernate:
select
employee0_.emp_no as emp_no1_1_0_,
employee0_.birth_date as birth_da2_1_0_,
employee0_.first_name as first_na3_1_0_,
employee0_.last_name as last_nam4_1_0_,
employee0_.gender as gender5_1_0_,
employee0_.hire_date as hire_dat6_1_0_,
employee0_.dept_no as dept_no7_1_0_
from
employees employee0_
where
employee0_.emp_no=?
Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, lastName=Facello, gender=M, hireDate=1986-06-26 01:00:00.0]
Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, lastName=Facello, gender=M, hireDate=1986-06-26 01:00:00.0]
例:如果我要输出关联对象的话,也要配关联对象类的开启二级缓存,要不然的话仍发送二条sql语句
@Test //二级缓存配置
public void cacheTest() {
Employee employee=session.get(Employee.class, 10001);
System.out.println(employee.getDepartment());
transaction.commit();
session.close();
session = sessionFactory.openSession();
transaction = session.beginTransaction();
Employee employee2 = session.get(Employee.class, 10001);
System.out.println(employee2.getDepartment());
}
----------------------------------------------------------------------------------------------------------------
Hibernate:
select
employee0_.emp_no as emp_no1_1_0_,
employee0_.birth_date as birth_da2_1_0_,
employee0_.first_name as first_na3_1_0_,
employee0_.last_name as last_nam4_1_0_,
employee0_.gender as gender5_1_0_,
employee0_.hire_date as hire_dat6_1_0_,
employee0_.dept_no as dept_no7_1_0_
from
employees employee0_
where
employee0_.emp_no=?
Hibernate:
select
department0_.dept_no as dept_no1_0_0_,
department0_.dept_name as dept_nam2_0_0_
from
departments department0_
where
department0_.dept_no=?
Department [deptNo=1, deptName=Marketing]
Hibernate:
select
department0_.dept_no as dept_no1_0_0_,
department0_.dept_name as dept_nam2_0_0_
from
departments department0_
where
department0_.dept_no=?
Department [deptNo=1, deptName=Marketing]
把类,和关联类都配二级缓存
<!-- 开启了二级缓存配对那些类有作用 -->
<class-cache usage="read-write" class="cn.ybzy.hibernatedemo.model.Employee"/>
<class-cache usage="read-write" class="cn.ybzy.hibernatedemo.model.Department"/>
Hibernate:
select
employee0_.emp_no as emp_no1_1_0_,
employee0_.birth_date as birth_da2_1_0_,
employee0_.first_name as first_na3_1_0_,
employee0_.last_name as last_nam4_1_0_,
employee0_.gender as gender5_1_0_,
employee0_.hire_date as hire_dat6_1_0_,
employee0_.dept_no as dept_no7_1_0_
from
employees employee0_
where
employee0_.emp_no=?
Hibernate:
select
department0_.dept_no as dept_no1_0_0_,
department0_.dept_name as dept_nam2_0_0_
from
departments department0_
where
department0_.dept_no=?
Department [deptNo=1, deptName=Marketing]
Department [deptNo=1, deptName=Marketing]
集合二缓存的设置
如果把上面的代码,换成如下:把所有Employee换成Department,Department换成Employee,则又会发送两个sql语句,这不是自相矛盾了吗?为什么呢,因为这里我们打印的是集合,双向多对一关系中的结果集是多端的Employee,它在Department中定义的是集合Set引用。
@Test //二级缓存配置
public void cacheTest() {
Department department=session.get(Department.class, 10001);
System.out.println(department.getEmployees());
transaction.commit();
session.close(); //清理一级缓存,开启的二级缓存不会清的
session = sessionFactory.openSession();
transaction = session.beginTransaction();
Department department2=session.load(Department.class, 1);
System.out.println(department2.getEmployees());
}
集合二级缓存开启
<!-- 开启了二级缓存配对那些类有作用 -->
<class-cache usage="read-write" class="cn.ybzy.hibernatedemo.model.Employee"/>
<class-cache usage="read-write" class="cn.ybzy.hibernatedemo.model.Department"/>
<!-- 开启集合二级缓存,employees是在部门中的一个集合定义,前提:Employee已开启发二级缓存 -->
<collection-cache usage="read-write" collection="cn.ybzy.hibernatedemo.model.Department.employees"/>
EHCACHE缓存的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<diskStore path="c:/ehcache/"></diskStore>
<!-- 默认缓存配置 -->
<defaultCache
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"/>
<!-- 命名缓存配置 -->
<cache
name="cacheTest"
maxElementsInMemory="10000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
/>
</ehcache>
1.<diskStore path="c:/ehcache/"></diskStore>,当缓存默认大小用完了,就会根据策略,存放在磁盘上,这里是指定磁盘位置,可指定磁盘中的文件夹位置。样例中配置位置为“c:/ehcache/”, 什么意思呢? 内存中的缓存满了,装不下了,就放这里,注意:它是临时的文件, sessionFactory.close后, 这里的文件会自动删除!
2.defaultCache
默认缓存配置
3.cache
指定对象的缓存配置,其中 name 属性为指定缓存的名称(必须唯一)
<class-cache region="cacheTest" usage="read-write" class="cn.ybzy.hibernatedemo.model.Employee"/>
4.配置属性中的元素说明
(1)maxElementsInMemory(正整数):
在内存中缓存的最大对象数量
(2)maxElementsOnDisk(正整数):
在磁盘上缓存的最大对象数量,默认值为0,表示不限制。
(3)eternal:
设定缓存对象保存的永久属性,默认为 false 。当为 true 时 timeToIdleSeconds、timeToLiveSeconds 失效。 表示这个缓存永远不清除!
(4)timeToIdleSeconds(单位:秒):
对象空闲时间,指对象在多长时间没有被访问就会失效。只对eternal为false的有效。默认值0,表示一直可以访问。失效时间!
(5)timeToLiveSeconds(单位:秒):
对象存活时间,指对象从创建到失效所需要的时间。只对eternal为false的有效。默认值0,表示一直可以访问。
(6)overflowToDisk:
如果内存中数据超过内存限制,是否要缓存到磁盘上。
(7)diskPersistent:
是否在磁盘上持久化。指重启jvm后,数据是否有效。默认为false。
(8)diskSpoolBufferSizeMB(单位:MB):
DiskStore使用的磁盘大小,默认值30MB。每个cache使用各自的DiskStore。
( 9)memoryStoreEvictionPolicy:
如果内存中数据超过内存限制,向磁盘缓存时的策略。默认值LRU,可选FIFO、LFU。
3.清空策略
(1).FIFO(first in first out):
先进先出
(2).LFU(Less Frequently Used):
最少被使用,缓存的元素有一个hit属性,hit值最小的将会被清除缓存。
(3).LRU(Least Recently Used)默认策略:
最近最少使用,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清除缓存。
例:设置二缓存,设置内存中只缓存一条记录,而我要获取四条记录,则其余三条记录会缓存到磁盘中
ehcache.xml
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<diskStore path="c:/ehcache/"></diskStore>
<!-- 默认缓存配置,内存中只允许放一个元素,这样就容易看到磁盘上有存了元素效果, -->
<defaultCache
maxElementsInMemory="1"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"/>
</ehcache>
因为session.close();会清理一级缓存,sessionFactory.close()会清理二级缓存,又这两个方法在destory()方中调用,我在sesssionFactory.close()打一个断点,再DEBUG,这样我可以看到磁盘上保存缓存对象的效果。
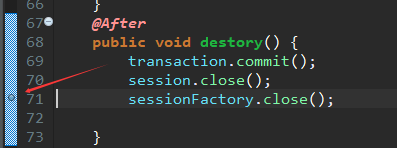
测试类中:
@Test
public void secondlevelTest(){
//缓存配置文件的使用测试,这里我,我配置了在内存只缓存一个对象,其它都放到磁盘上,
String hql ="from Department d where d.deptNo<?";
Query<Department> query = session.createQuery(hql).setParameter(0, 5);
List<Department> employees = query.list();
System.out.println(employees);
}
查询缓存:
查询缓存的测试,当我们两次查询同一个对象时,没有开查询二级缓存,会发送两条SQL语句
String hql="from Employee e where e.empNo <10005";
Query<Employee> query = session.createQuery(hql);
List<Employee> emps = query.list();
System.out.println(emps);
List<Employee> emps2=query.list();
System.out.println(emps2);
----------------------------------------------------------------------------------------------------------------
Hibernate:
select
employee0_.emp_no as emp_no1_1_,
employee0_.birth_date as birth_da2_1_,
employee0_.first_name as first_na3_1_,
employee0_.last_name as last_nam4_1_,
employee0_.gender as gender5_1_,
employee0_.hire_date as hire_dat6_1_,
employee0_.dept_no as dept_no7_1_
from
employees employee0_
where
employee0_.emp_no<10005
[Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, lastName=Facello, gender=M, hireDate=1986-06-26 01:00:00.0], .....
Hibernate:
select
employee0_.emp_no as emp_no1_1_,
employee0_.birth_date as birth_da2_1_,
employee0_.first_name as first_na3_1_,
employee0_.last_name as last_nam4_1_,
employee0_.gender as gender5_1_,
employee0_.hire_date as hire_dat6_1_,
employee0_.dept_no as dept_no7_1_
from
employees employee0_
where
employee0_.emp_no<10005
[Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, lastName=Facello, gender=M, hireDate=1986-06-26 01:00:00.0], .....
开启查询缓存的步骤1:
hibernate.cfg.xml—最后一行
<!-- 二级缓存配置, 开启缓存-->
<property name="hibernate.cache.use_second_level_cache">true</property>
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
<property name="hibernate.cache.use_query_cache">true</property>
开启查询缓存步骤2:
String hql="from Employee e where e.empNo <10005";
Query<Employee> query = session.createQuery(hql);
query.setCacheable(true); //开启查询二级缓存
List<Employee> emps = query.list();
System.out.println(emps);
List<Employee> emps2=query.list();
System.out.println(emps2);
----------------------------------------------------------------------------------------------------------------
Hibernate:
select
employee0_.emp_no as emp_no1_1_,
employee0_.birth_date as birth_da2_1_,
employee0_.first_name as first_na3_1_,
employee0_.last_name as last_nam4_1_,
employee0_.gender as gender5_1_,
employee0_.hire_date as hire_dat6_1_,
employee0_.dept_no as dept_no7_1_
from
employees employee0_
where
employee0_.emp_no<10005
[Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, l
[Employee [empNo=10001, birthDate=1953-09-02 00:00:00.0, firstName=Georgi, l
查询性能优化
1.Hibernate主要从以下几方面来优化查询性能
(1)使用迫切左外连接或迫切内连接查询策略、查询缓存等方式,减少select语句的数目,降低访问数据库的频率。inner join fetch, left join fetch
(2)使用延迟查询策略等方式避免加载多余的不需要访问的数据。默认就是!基本上不会把lazy设为lazy=“false”,默认是true.
(3)使用Query接口的iterate()方法减少select语句中的字段,从而降低访问数据库的数据量。这个只是稍稍提高性能,用的不好,反而坏事!
Query接口的iterate()方法和list()方法都用来执行SQL查询语句。在某些情况下,iterate()方法能提高查询性能。注意iterate()方法是依赖二级缓存,没有二级缓存它也无法提高性能!
2.HQL优化
HQL优化是Hibernate程序性能优化的一个方面,HQL的语法与SQL非常类似。HQL是基于SQL的,只是增加了面向对象的封装。如果抛开HOL同Hibernate本身一些缓存机制的关联,HQL的优化技巧同SQL的优化技巧一样。在编写HQL时,需注意以下几个原则。
(1)避免or操作的使用不当。如果where子句中有多个条件,并且其中某个条件没有索引,使用or,将导致全表扫描。假定在HOUSE表中TITLE有索引,PRICE没有索引,执行以下HQL语句:
from House where title= ‘出租-居室’ or price<1500
当PRICE比较时,会引起全表扫描。
(2)避免使用not。如果where子句的条件包含not关键字,那么执行时该字段的索引失效。这些语句需要分成不同情况区别对待,如查询租金不多于1800元的店铺出租转让信息的HQL语句:
from House as h where not (h.price>1800)
对于这种不大于(不多于)、不小于(不少于)的条件,建议使用比较运算符来替代not,如不大于就是小于等于。例如:
from House as h where h.price<=1800
如果知道某一字段所允许的设置值,那么就有其他的解决方法。例如,在用户表中增加性别字段,规定性别字段仅能包含M和F,当要查询非男用户时,为避免使用not关键字,将条件设定为查询女用户即可。
(3)避免like的特殊形式。某些情况下,会在where子句条件中使用like。如果like以一个“%” 或“_”开始即前模糊,则该字段的索引不起作用。但是非常遗憾的是,对于这种问题并没有额外的解决方法,只能通过改变索引字段的形式变相地解决。
(4)避免having予句。在分组的查询语句中,可在两个位置指定条件,一是where子旬中,二是在having子句中。尽可能地在where子句而不是having子句中指定条件。Having是在检索出所有记录后才对结果集进行过滤,这个处理需要一定的开销,而where子句限制记录数目,能减少这方面的开销。
(5)避免使用distinct。指定distinct会导致在结果中删除重复的行。这会对处理时间造成一定的影响,因此在不要求或允许冗余时,应避免使用distinct。
(6)索引在以下情况下失效,应注意使用。
Ø 只要对字段使用函数,该字段的索引将不起作用,如substring(aa,1,2)=‘xx’。
Ø 只要对字段进行计算,该字段的索引将不起作用,如price+10。
Hibernate管理Session
前面我们都是在测试类里获取到的hibernate访问数据库的会话session对象, 但是很明显这和我们项目中的实际开发, 不可能这样搞的, 回到我们JavaWeb里讲的MVC开发结构, dao层里怎么获取到这个session的对象呢? 我们讨论一下!
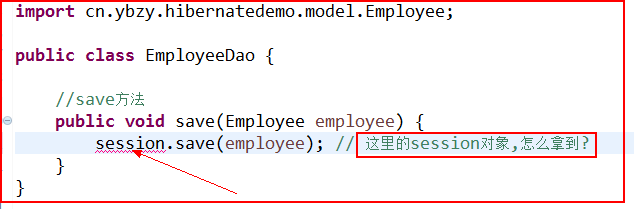
两种方案, 先看不可取的方案:
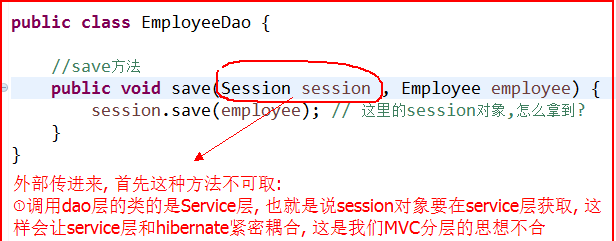
不能从外部传进来, 只能在内部获取了, 所以应该采用第二方案:
步骤一: 创建一个HibernateUtils工具类来获取session
public class HibernateUtil {
//单例模式,懒汉模式
private static HibernateUtil hibernateUtil = null;
private HibernateUtil() { //重写无双参构造为私有的,外部不能实例化,
}
public static HibernateUtil getInstance() {
if(hibernateUtil ==null) {
hibernateUtil = new HibernateUtil();
}
return hibernateUtil;
}
public SessionFactory getSessionFactory() {
Configuration configuration=new Configuration().configure();
ServiceRegistry serviceRegistry=configuration.getStandardServiceRegistryBuilder().build();
return new MetadataSources(serviceRegistry).buildMetadata().buildSessionFactory();
}
//Session是org.hibernate包中的类,不是我们以前的JSP,servelt中的Session
public Session getSession() {
return getSessionFactory().getCurrentSession();
}
}
第二个步骤在核心配置文件中配置Session的管理方式为thread线程管理方式
<!-- 开启session的线程管理模式 -->
<property name="current_session_context_class">thread</property>
thread线程方式来管理session对象, 当事务提交的时候, hibernate会自动的关闭session, 我们就更方便了,不用手动去session.close();
例:增加一个员工信息
EmployeeDao.java---这里为了简单测试,我不写接口了,直接模拟实现类
public class EmploeeDao {
public void add(Employee employee) {
Session session=HibernateUtil.getInstance().getSession();
Transaction transaction=session.beginTransaction();
session.save(employee);
transaction.commit();
//由于配置了线程管理会话,我们不用手动的关闭会话
System.out.println("事务提交后,会话还是打开的吗?"+session.isOpen());
}
}
EmployeeService.java---这里为了简单测试,我不写接口了,直接模拟实现类
public class EmployeeService {
private static EmploeeDao emploeeDao=new EmploeeDao();
public static void main(String[] args) {
Employee employee=new Employee();
Department department=new Department();
department.setDeptNo(9);
department.setDeptName("财务部1分部");
//employee.setEmpNo(101); //自增,设了也没有用,该employees表,最后emp_no是500000,所以自动加1,设置emp_no
employee.setFirstName("xiong");
employee.setLastName("shaowen");
employee.setBirthDate(new Date());
employee.setGender("M");
employee.setHireDate(new Date());
employee.setDepartment(department);
emploeeDao.add(employee);
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











