










Hibernate框架介绍
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO(简单java对象)与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用.
从中,我们可以得出这样的结论:Hibernate是一个轻量级的JDBC封装,也就是说,我们可以使用Hibernate来完成原来我们使用JDBC完成的操作,也就是与数据库的交互操作。它是在dao层去使用的。
什么是ORM?
对象关系映射(英语:Object Relation Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
对象-关系映射,是随着面向对象的软件开发方法发展而产生的。
面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。
对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。
内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。
因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。ORM模型的简化了数据库查询过程。使用ORM查询工具,用户可以访问期望数据,而不必理解数据库的底层结构。

简单来说,我们使用ORM可以将我们的对象(或类)去进行映射,使得我们可以去操作对象就能完成对表的操作。
为什么使用Hibernate框架原因如下:
Hibernate对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现,它很大程度的简化了dao层编码工作。
总结:Hibernate是企业级开发中的主流框架,映射的灵活性很出色。它支持很多关系型数据库。
Hiberate框架学习目标,对于Hiberate框架的学习重点,可以总结为:
掌握Hiberate的基本配置——即搭建Hiberate开发环境
掌握Hiberate常用API——即如何使用Hiberate框架进行开发
掌握Hiberate的关联映射——解决表与表之间存在的关系问题,有1:n(一对多)、 1:1(一对一)、m:n(多对多)关系
掌握Hiberate的检索方式——即掌握Hiberate的查询
掌握Hiberate的优化方式——即提高Hiberate的效率
配置Hiberante开发环境
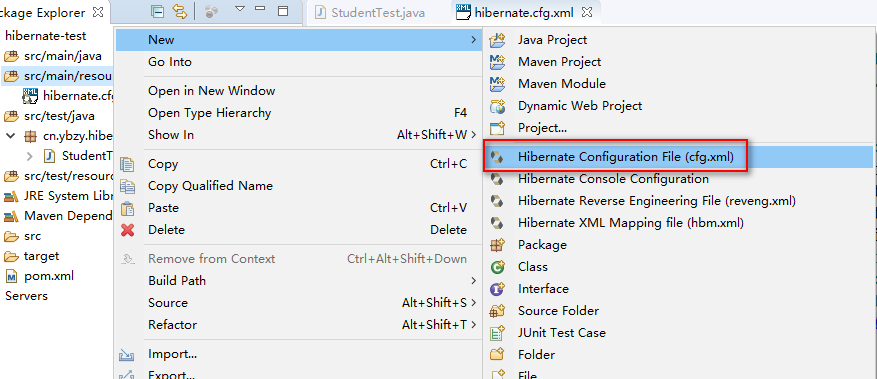
正式学习Hibernate之前,我们要先安装一个Eclipse的Hibernate插件m在使用Hibernate开发时,大多数情况下涉及到其XML配置文件的编辑,尤其是.cfg.xml(配置文件)和hbm.xml(关系映射文件)这两种。为了更方便的使用此框架,其插件的安装是很有必要的。
下载Hibernate框架的插件:JBOSS Tools
在Eclipse Marketplace 搜索 jboos tools, 然后install—只选选一个项:Hibernate Tools,安装完成,会在工具中加入如下图的工具选项:

本人用的是STS3.9X版
1.导包:Hibernate Core核心包都到了7.x版本了,但我还用5.x版,为了测试方便
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.2.17.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>5.3.0.Final</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
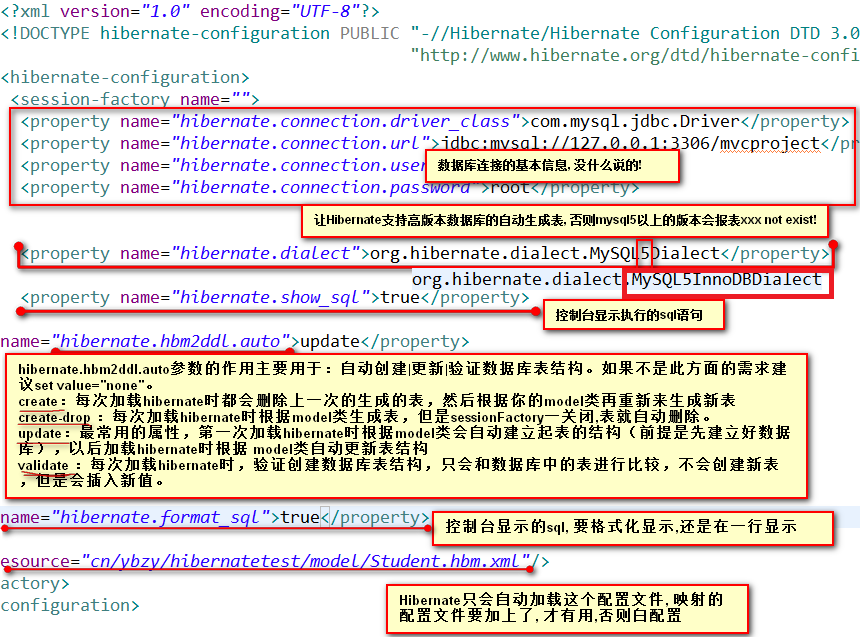
2.配置hibernate.cfg.xml
src/main/resources下,新建hibernate.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="">
<!-- 连接数据库的基本信息 -->
<property name="hibernate.connection.driver_class">com.mysql.cj.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://124.220.60.104:3306/hibernate5</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">xiong</property>
<!-- 方言,开发的过程时要在控制台显示的格式,自动更新。。。,方言在MYSQL后加一个5,我们现在用的是mysql5版本以上-->
<property name="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</property>
<property name="hibernate.show_sql">true</property>
<property name="hibernate.format_sql">true</property>
<property name="hibernate.hbm2ddl.auto">update</property>
</session-factory>
</hibernate-configuration>
3.建模型类即POJO简单类--Student.java
public class Student {
private int id;
private String username;
private String sex;
private Date regDate;
//get,set,空构造,有参构造(如果对应的表id是自增长,不用它),toString()
}
4.创建对象-关系映射文件Student.hbm.xml,然后把它加到hibernate.cfg.xml配置文件中,配置映射关系
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="cn.ybzy.hibernatedemo.model.Student" table="STUDENT">
<id name="id" type="int"><!--这个id要与类属性一模一样,下面的username,regDate一样弄的-->
<column name="ID" /> <!--可以小写,即自定义即可-,即数据库中表的列名->
<generator class="native" /> <!-- assigned改为native,随数据库自增长模式生成id -->
</id>
<property name="username" type="java.lang.String">
<column name="USERNAME" />
</property>
<property name="sex" type="java.lang.String">
<column name="SEX" />
</property>
<property name="regDate" type="java.util.Date">
<column name="REGDATE" />
</property>
</class>
</hibernate-mapping>
hibernate.cfg.xml配置Student与Studemt.hbm.xml映射 关系
-----
<mapping resource="cn/ybzy/hibernatedemo/model/Student.hbm.xml"/>
</session-factory>
----
5.通过hibernate API编写访问数据库的代码
已导junit4.10包,所以我们建一个测试类 new ----junit Test Case—HibernateTest.java
如果测试成功,即使我们没有建表,也会自动帮我们建表,并增删改查数据。
public class HibernateTest {
@Test
public void test() {
/*①创建一个SessionFactory工厂类:通过它建立一个与数据库连接会话,Session*/
SessionFactory sessionFactory=null;
//sessionFactory又需要另一个类,配置类,封装有我们的配置文件里的配置信息
Configuration configuration=new Configuration().configure();
//返回回来的configureation对象:包含有配置文件里的信息,hibernate规定,所有的配置信息或服务,要生效,
//必须配置或注册到一个服务注册类中
ServiceRegistry serviceRegistry=configuration.getStandardServiceRegistryBuilder().build();
sessionFactory =new MetadataSources(serviceRegistry).buildMetadata().buildSessionFactory();
/*②通过工厂类开启Session对象,*/
Session session=sessionFactory.openSession();
/*③开始事务*/
Transaction transaction = session.beginTransaction();
/*④执行数据库的操作*/
Student student=new Student("张三","男",new Date());
session.save(student);
/*⑤提交事务*/
transaction.commit();
/*⑥关闭Session*/
/*⑦关闭工厂类*/
}
}
对例子里的东西解释和知识扩展一下
首先看配置文件hibernate.cfg.xml:
再来说模型层里的Java类Student :
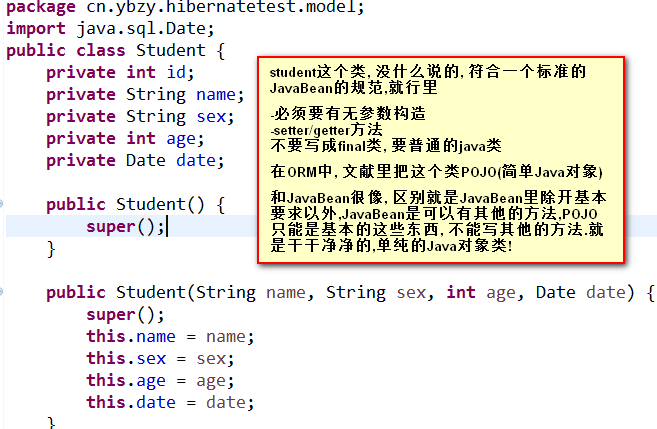
然后再来说映射配置文件 :
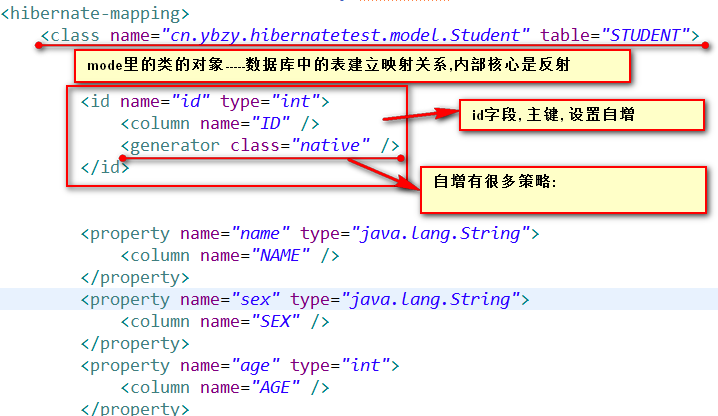
-
assigned
主键由外部程序负责生成,在 save() 之前必须指定一个。Hibernate不负责维护主键生成。与Hibernate和底层数据库都无关,可以跨数据库。在存储对象前,必须要使用主键的setter方法给主键赋值,至于这个值怎么生成,完全由自己决定,这种方法应该尽量避免。 -
increment
由Hibernate从数据库中取出主键的最大值(每个session只取1次),以该值为基础,每次增量为1,在内存中生成主键,不依赖于底层的数据库,因此可以跨数据库。
特点:跨数据库,不适合多进程并发更新数据库,适合单一进程访问数据库,不能用于群集环境。 -
hilo
hilo(高低位方式high low)是hibernate中最常用的一种生成方式,需要一张额外的表保存hi的值。保存hi值的表至少有一条记录(只与第一条记录有关),否则会出现错误。可以跨数据库。
<id name="id" column="id">
<generator class="hilo">
<param name="table">hibernate_hilo</param>
<param name="column">next_hi</param>
<param name="max_lo">100</param>
</generator>
</id>
<param name="table">hibernate_hilo</param> 指定保存hi值的表名
<param name="column">next_hi</param> 指定保存hi值的列名
<param name="max_lo">100</param> 指定低位的最大值
特点:跨数据库,hilo有自己内部一套算法生成标志值, 这个值只能在一个数据库中保证唯一。
-
seqhilo
与hilo类似,通过hi/lo算法实现的主键生成机制,只是将hilo中的数据表换成了序列sequence,需要数据库中先创建sequence,适用于支持sequence的数据库,如Oracle。 -
sequence
采用数据库提供的sequence机制生成主键,需要数据库支持sequence。如oralce、DB、SAP DB、PostgerSQL、McKoi中的sequence。MySQL这种不支持sequence的数据库则不行(可以使用identity)。 -
identity
identity由底层数据库生成标识符。identity是由数据库自己生成的,但这个主键必须设置为自增长,使用identity的前提条件是底层数据库支持自动增长字段类型,如DB2、SQL Server、MySQL、Sybase和HypersonicSQL等,Oracle这类没有自增字段的则不支持。 -
native
native由hibernate根据使用的数据库自行判断采用identity、hilo、sequence其中一种作为主键生成方式,灵活性很强。如果能支持identity则使用identity,如果支持sequence则使用sequence。
特点:根据数据库自动选择,项目中如果用到多个数据库时,可以使用这种方式,使用时需要设置表的自增字段或建立序列,建立表等。 -
uuid
Hibernate在保存对象时,生成一个UUID字符串作为主键,保证了唯一性,但其并无任何业务逻辑意义,只能作为主键,唯一缺点长度较大,32位(Hibernate将UUID中间的“-”删除了)的字符串,占用存储空间大,但是有两个很重要的优点,Hibernate在维护主键时,不用去数据库查询,从而提高效率,而且它是跨数据库的,以后切换数据库极其方便。
特点:uuid长度大,占用空间大,跨数据库,不用访问数据库就生成主键值,所以效率高且能保证唯一性,移植非常方便,推荐使用。 -
guid
Hibernate在维护主键时,先查询数据库,获得一个uuid字符串,该字符串就是主键值,该值唯一,缺点长度较大,支持数据库有限,优点同uuid,跨数据库,但是仍然需要访问数据库。
特点:需要数据库支持查询uuid,生成时需要查询数据库,效率没有uuid高,推荐使用uuid。 -
foreign
使用另外一个相关联的对象的主键作为该对象主键。主要用于一对一关系中。
特点:很少使用,大多用在一对一关系中。 -
select
使用触发器生成主键,主要用于早期的数据库主键生成机制,能用到的地方非常少。
最后看看,Hibernate的编程里用到的API的对象:

Session缓存
Session接口是Hibernate向应用程序提供的操纵数据库的最主要的接口,它提供了基本的保存,更新,删除和查询的方法。
Session是有一个缓存, 又叫Hibernate的一级缓存
session缓存是由一系列的Java集合构成的。当一个对象被加入到Session缓存中,这个对象的引用就加入到了java的集合中,以后即使应用程序中的引用变量不再引用该对象,只要Session缓存不被清空,这个对象一直处于生命周期中。
Session缓存的作用:
1)减少访问数据库的频率。如下示例:因为有缓存,所以第二次获取记录,没有发起查询句执行,
/*
* 这里为了测试方便,我把配置,关闭提出来放到init,destory方法里,它们分别在测试方法的前后,进行。
* 生产环境中不能这么干,因为用了多线程,如果一条线程,执行测试时,另一个线程(初始化的线程)没有赶上趟,就完了
*/
public class HibernateStuTest {
private Session session=null;
private Transaction transaction;
private SessionFactory sessionFactory=null;
@Before
public void init() {
Configuration configuration=new Configuration().configure();
ServiceRegistry serviceRegistry=configuration.getStandardServiceRegistryBuilder().build();
sessionFactory =new MetadataSources(serviceRegistry).buildMetadata().buildSessionFactory();
session=sessionFactory.openSession();
transaction = session.beginTransaction();
}
@After
public void destory() {
transaction.commit();
session.close();
sessionFactory.close();
}
//Session缓存,测试
@Test
public void getLoadtest() {
//get方法、load方法:通过id,获取数据库中对应的记录数据,转对象,放到session的缓存中
Student student = session.get(Student.class, 1);
System.out.println(student);
Student student2 = session.get(Student.class, 1);
System.out.println(student2); //因为有缓存,所以第二次获取记录,没有发起查询句执行,
}
}
----------------------------------------------------------------------------
Hibernate:
select
student0_.ID as ID1_0_0_,
student0_.USERNAME as USERNAME2_0_0_,
student0_.SEX as SEX3_0_0_,
student0_.REGDATE as REGDATE4_0_0_
from
STUDENT student0_
where
student0_.ID=?
Student [id=1, username=张三, sex=男, regDate=2025-05-29 10:46:40.0]
Student [id=1, username=张三, sex=男, regDate=2025-05-29 10:46:40.0]
2)保证缓存中的对象与数据库中的相关记录保持同步。
Hibernate提供了哪些方法去保证缓存中的对象数据和数据库中的数据记录之间一定同步呢?
①flush():强制让数据库里的数据记录和session中缓存的对象数据保存一致,不一致就发起update这条sql语句修改数据让其一致, 一致, 它不动作,不会发去sql语句.
有关于flush()方法的知识点:
a、在事务的commit()提交之前自动调用了session的flush()方法,然后再提交事务,这样可以不显示写出session.flush()。
b、flush()可能会发送sql语句,但是不会提交事务。
②refresh():它会强制发出一条select语句, 保证session缓存中的数据和数据库里数据记录是一致的, 如果发现不一致它会修改缓存中的对象中的数据让其一致。
Session清理缓存的时机:
- 当调用Transaction的commit()方法时,commit()方法先清理缓存(前提是FlushMode.COMMIT/AUTO),然后再向数据库提交事务。
- 当应用程序调用Session的find()或者iterate()等查询数据的方法时,如果缓存中的持久化对象的属性发生了变化,就会先清理缓存,以保证查询结果能反映持久化对象的最新状态。
- 当应用程序显示调用Session的flush()方法的时候。

Hibernate处理的对象在不同的程序执行阶段存在不同的状态:
我们知道Hibernate的核心就是对数据库的操作,里面的核心接口就是org.hibernate.Session接口。要想对数据库操作我们就要理清楚Hibernate里的对象在整个操作中的所属的状态(主要有三个:临时,持久,游离)。
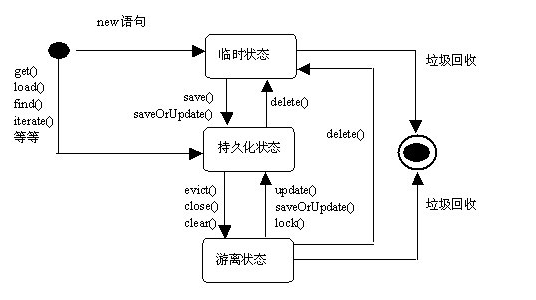
临时状态的测试:
Student student = new Student("张三", "男", 22, new Date());
以上student就是一个Transient(临时状态),此时student并没有被session进行托管,即在session的缓存中还不存在student这个对象,当执行完save方法后,此时student被session托管,且数据库中也存在了该对象,student就变成了一个Persistent(持久化对象)
session.save(student); //save方法就是往数据库插入一条记录
结论: 此时我们知道hibernate会发出一条insert的语句,执行完save方法后,该student对象就变成了持久化的对象了
持久状态的测试1:
Student student = new Student("张三", "男", 22, new Date());
以上student就是Transient(瞬时状态),表示没有被session管理并且数据库中没有执行save之后,被session所管理,而且,数据库中已经存在,此时就是Persistent状态
session.save(student);
此时student是持久化状态,已经被session所管理,当在commit()提交时,会把session中的对象和目前的对象进行比较如果两个对象中的值不一致就会继续发出相应的sql语句
student.setSex("女");
此时会发出2条sql,一条用户做插入,一条用来做更新
结论: 在调用了save方法后,此时student已经是持久化对象了,被保存在了session缓存当中,这时student又重新修改了属性值,那么在提交事务时,此时hibernate对象就会拿当前这个student对象和保存在session缓存中的student对象进行比较,如果两个对象相同,则不会发送update语句,否则,如果两个对象不同,则会发出update语句。
注意: 在调用save方法后,student此时已经是持久化对象了,记住一点:如果一个对象已经是持久化状态了,那么此时对该对象进行各种修改,或者调用多次update、save方法时,hibernate都不会发送sql语句,只有当事物提交的时候,此时hibernate才会拿当前这个对象与之前保存在session中的持久化对象进行比较,如果不相同就发送一条update的sql语句,否则就不会发送update语句.
持久状态的测试2:
Student student = session.load(Student.class, 1); // 取出id等于1的学生记录
上面的student是持久状态的对象
student.setAge(77); //修改了属性,让session提交commit事务的时候,student这个对象和session中的对象不一致,所以会发出sql完成更新
结论:当session调用load、get方法时,此时如果数据库中有该对象,则从数据库取出该对象也变成了一个持久化对象,被session所托管。因此,这个时候如果对对象进行操作,在提交事务时同样会去与session中的持久化对象进行比较,因此这里会发送两条sql语句,一条查询,一条修改。
持久状态的测试3:
Student student = session.load(Student.class, 1);
load方法的作用:取出id等于1的学生记录
上面的student是取出后就是持久状态的对象
student.setAge(67);
修改了属性,让session提交commit事务的时候,student这个对象和session中的对象不一致,所以会发出sql完成更新
但是提交事务之前, 我们清空session里的缓存
session.clear();
结论:这个时候在提交事务,发现已经session中已经没有该对象了,所以就不会进行任何操作
游离状态测试1:
Student student = new Student();
student.setId(2);
student.setName("李四");
程序执行到这里,student就是一个游离对象的状态, 因为数据库中存在id=2的记录, 且这个student对象,又没被session托管,是离线状态的,所以它是游离状态
session.save(student);
执行save, hibernate会以自己的规则,重新insert一条记录
结论: 修改游离状态的对象的ID值不会报错,也没有任何效果,要把游离状态的对象转持久不能用save方法,要用update方法
游离状态测试2:
Student student = new Student();
student.setId(2);
student.setName("李四");
程序执行到这里,student就是一个游离对象的状态, 因为数据库中存在id=2的记录, 并且这个student对象,又没被session托管,是离线状态的,所以它是游离状态
session.update(student);
执行update方法时,这个student对象,就从游离状态转变为了持久的状态了
student.setId(77); //报错, 不准修改
结论:持久状态的对象的ID值是不准修改的
游离状态测试3:
Student student = new Student();
student.setId(2);
程序执行到这里,student就是一个游离对象的状态, 因为数据库中存在id=2的记录, 并且这个student对象,又没被session托管,是离线状态的,所以它是游离状态
session.delete(student);
执行delete方法,作用是讲对象的游离或持久状态删除,同时删除数据库中对应的记录。
结论: 这个时候的student对象已经不再是session托管的了,缓存中也不存在了,变成临时状态的对象了, 这时没有后续的操作,它会被垃圾回收机制从内存中处理掉!
游离状态测试4:
Student student = new Student();
student.setId(2);
程序执行到这里,student就是一个游离对象的状态, 因为数据库中存在id=2的记录, 并且这个student对象,又没被session托管,是离线状态的,所以它是游离状态
session.saveOrUpdate(student);
saveOrUpdate这个方法,是个偷懒的方法,当对象的状态是游离的,Hibernate就会去调用update方法,如果对象是临时状态的话,就调用save方法,这个方法不常用!
结论:有student.setId(2)这条语句,这个对象就会被假设是游离的,执行update方法,没有这条语句, 它会被Hibernate认为是临时状态,就执行save方法。
游离状态测试5:
Student student = session.load(Student.class, 1);
// load方法的作用:取出id等于1的学生记录
// 上面的student是取出后就是持久状态的对象
Student student2 = new Student();
//这时候的stutent2是临时的状态
student2.setId(1);
// 修改里student2的ID值,它就转游离的状态了
session.saveOrUpdate(student2);
//执行更新操作,它的状态会从游离转持久,我们的对象是用ID值来辨别身份的,所以在session的缓存中就存在了两份同样的对象,在session中不能存在两份拷贝, 所以报错
结论: Hibernate的session的缓存中不许用出现两个或两个以上有相同ID值的对象
最后总结一下:
①.对于刚创建的一个对象,如果session中和数据库中都不存在该对象,那么该对象就是瞬时对象(Transient)
②.瞬时对象调用save方法,或者离线对象调用update方法可以使该对象变成持久化对象,如果对象是持久化对象时,那么对该对象的任何修改,都会在提交事务时才会与之进行比较,如果不同,则发送一条update语句,否则就不会发送语句
③.离线对象就是,数据库存在该对象,但是该对象又没有被session所托管,如果托管了,则会重新插入一条到数据库中,不会重复ID值
Session中的核心方法梳理:
① save方法
这个方法表示将一个对象保存到数据库中,可以将一个不含OID的new出来的临时对象转换为一个处于Session缓存中具有OID的持久化对象。
需要注意的是: 在save方法前设置OID是无效的但是也不会报错,在save方法之后设置OID程序会抛出异常,因为持久化之后的对象的OID是不可更改的,因为对象的OID此时和数据库中的一条记录对应。
@Test
public void savetest() {
Student student = new Student("熊少文","男",new Date());
session.save(student);
System.out.println(student);
}
----------------------------------------------------------------------------
Hibernate:
insert
into
STUDENT
(USERNAME, SEX, REGDATE)
values
(?, ?, ?)
Student [id=3, username=熊少文, sex=男, regDate=Fri May 30 09:39:05 CST 2025]
结论总结:
- 临时对象变持久对象
- 给对象分配id,这个id叫oid, 它和数据库的记录id对应一致
- 执行save方法时会发起一条insert语句, 但要等到事务提交时才会作用到数据库(例子中我把transcation.commit()写在destory()方法中了,它会在测试方法后执行,会提交的不用担心)
- save方法前设置id无效, save方法后设置id报异常,持久对象的id不准修改
② persist方法
这个方法基本个save方法差不多,唯一的区别是,在这个方法之前也不可以设置对象的OID,否则不会执行插入操作,而是会抛出异常。
③ get/load方法
get这个方法是从数据库中获取一条数据记录转成对象放到Session缓存中,load方法也是这个功能。二者有着明显的区别先看代码:
结论1.get方法会立即加载对象发起sql语句, load方法后面如果没有使用到加载的对象,不会立即加载对象发起sql语句,返回一个代理对象,当使用到该对象的时候才会通过代理对象加载真正需要对象并发起sql语句,这种做法我们又叫做延迟加载或懒加载!
//get立即载,load懒加载(要用到了才加载)
@Test
public void get_loadtest() {
Student student = session.load(Student.class,3);
//Student student2=session.get(Student.class, 3);
}
----------------------------------------------------------------------------
//get立即载,load懒加载(要用到了才加载)
@Test
public void get_loadtest() {
//Student student = session.load(Student.class,3);
Student student2=session.get(Student.class, 3);
}
----------------------------------------------------------------------------
Hibernate:
select
student0_.ID as ID1_0_0_,
student0_.USERNAME as USERNAME2_0_0_,
student0_.SEX as SEX3_0_0_,
student0_.REGDATE as REGDATE4_0_0_
from
STUDENT student0_
where
student0_.ID=?
五月 30, 2025 9:55:16 上午
结论2: 如果查询的数据在数据库中没有对应的id的记录值, get方法返回null, 不报异常, load方法,它不会立即加载对象发起sql, 直接返回一个代理对象, 当使用加载对象的时候, 代理对象才加载真正的对象并发起sql,这时才发现查不到对象,所以就只能报出异常了!如果混合使用get,load,会优先使用懒加载。
//get立即载,load懒加载(要用到了才加载)
@Test
public void get_loadtest() {
Student student = session.load(Student.class,3);
Student student2=session.get(Student.class, 3);
System.out.println(student.getClass().getName());
System.out.println(student2.getClass().getName());
}
----------------------------------------------------------------
Hibernate:
select
student0_.ID as ID1_0_0_,
student0_.USERNAME as USERNAME2_0_0_,
student0_.SEX as SEX3_0_0_,
student0_.REGDATE as REGDATE4_0_0_
from
STUDENT student0_
where
student0_.ID=?
cn.ybzy.hibernatedemo.model.Student_$$_jvst38f_0
cn.ybzy.hibernatedemo.model.Student_$$_jvst38f_0
//get立即载,load懒加载(要用到了才加载)
@Test
public void get_loadtest() {
//Student student = session.load(Student.class,3);
Student student2=session.get(Student.class, 3);
//System.out.println(student.getClass().getName());
System.out.println(student2.getClass().getName());
}
----------------------------------------------------------------
Hibernate:
select
student0_.ID as ID1_0_0_,
student0_.USERNAME as USERNAME2_0_0_,
student0_.SEX as SEX3_0_0_,
student0_.REGDATE as REGDATE4_0_0_
from
STUDENT student0_
where
student0_.ID=?
cn.ybzy.hibernatedemo.model.Student
//get立即载,load懒加载(要用到了才加载)
@Test
public void get_loadtest() {
Student student = session.load(Student.class,3);
//Student student2=session.get(Student.class, 3);
System.out.println(student.getClass().getName());
//System.out.println(student2.getClass().getName());
}
----------------------------------------------------------------
cn.ybzy.hibernatedemo.model.Student_$$_jvst38f_0
结论3: load方法可能会抛出懒加载异常! 什么时候回抛出这个异常呢? 执行了laod方法, 返回了代理对象了, 往后还没有执行到使用这个预加载的对象的时候,session(数据库连接会话)关闭了, 后面再执行到使用加载对象, 代理对象才想起去加载真正的对象发起sql执行查询,啊!才发现数据库连接断掉了, 就报懒加载异常!
//get立即载,load懒加载(要用到了才加载)
@Test
public void get_loadtest() {
Student student = session.load(Student.class,3);
session.close();
System.out.println(student);
transaction.commit();
}
---------------------------------------------------------------------------
org.hibernate.LazyInitializationException: could not initialize proxy [cn.ybzy.hibernatedemo.model.Student#3] - no Session
④ update方法
-
这个方法顾名思义就是更新一个对象在数据库中的对照情况,从而使一个游离对象转换为一个持久化对象。
-
若是更新一个持久化对象,不需要再显式的进行update方法,因为在commit方法中已经进行过flush了,它会自动发起update语句。
//update方法测试:持久化对象,更新,不用显示的写出update代码,commit()方法的调用flush会调用它
@Test
public void updatetest() {
Student student = session.load(Student.class,3);
student.setUsername("xiongshaowen");
//transcation.commit(); //写在destory()方法中了,最上面有,去查
}
-------------------------------------------------------------------------
Hibernate:
select
student0_.ID as ID1_0_0_,
student0_.USERNAME as USERNAME2_0_0_,
student0_.SEX as SEX3_0_0_,
student0_.REGDATE as REGDATE4_0_0_
from
STUDENT student0_
where
student0_.ID=?
Hibernate:
update
STUDENT
set
USERNAME=?,
SEX=?,
REGDATE=?
where
ID=?
- 若是关闭了一个session,而又打开了一个session,这时,前一个session对象相对于第二个session来说就是游离的对象了,此时,做更新的时候, 必须显式的用第二个session进行update一下才可以将这个对象变成相对于第二个session的持久化对象。才会发起sql语句.
@Test
public void updatetest() {
Student student = session.get(Student.class,3);
transaction.commit();
session.close(); //会话关闭了,student成为了游离对象了
session = sessionFactory.openSession();
transaction=session.beginTransaction();
student.setUsername("熊少文"); //显示的写出更新方法,不然靠commit去更新不得行的
session.update(student);
}
- 需要注意的是,3中此时在更新游离对象时无论Java对象中的内容和数据库中记录是否一样都会发送update语句,若是在数据库中将update语句和某个触发器绑定在了一起,那么就会造成触发器的错误触发。而我们在更新持久化对象时Hibernate会验证一下,若是Java对象和数据库中对应的记录一致的话就不会发送update语句。那么我们怎么避免这种在更新游离对象时多发update语句的情况呢?可以在
hbm.xml文件的class节点设置一个属性叫做select-before-update为true,就可以避免了。通常我们不需要设置这个属性,除非多发送update语句触发触发器二者相关联使用。
@Test
public void updatetest() {
Student student = session.get(Student.class,3);
transaction.commit();
session.close(); //会话关闭了,student成为了游离对象了
session = sessionFactory.openSession();
transaction=session.beginTransaction();
//student.setUsername("熊少文"); //显示的写出更新方法,不然靠commit去更新不得行的
session.update(student); //后面再执行提交的话,会造成误发
}
student.hbm.xml中加入select-before-update=“true”
<hibernate-mapping>
<class name="cn.ybzy.hibernatedemo.model.Student" table="STUDENT"
select-before-update="true">
- 若表中没有与Java对象对应的记录,则会抛出异常
- 在update语句之前在用get方法,获取同一个id的数据记录, update会同时将两个相同id的对象往session缓存里放,那么会抛出异常,注意:同一个session中不可以存在两个相同OID的对象。
⑤ saveOrUpdate⑥delete ⑦ evict⑧doWork方法
这个方法同时包含了前边save和update的功能。当对象时临时的,那么执行save方法,当对象时游离的,那么执行update方法。
⑥ delete方法
顾名思义,这个方法就是来删除游离的或者持久化的对象及其在数据库中对应的记录。
总结:
- 删除对象
- 删除持久对象
- 删除数据库里对应的记录
- 当删除的对象数据库里没有对应的id值的记录是抛出异常
- 默认的删除的时候,会把缓存从对象和数据库中记录删除,但这个对象会保留id, 妨碍后面重复利用这个对象, 这个问题通过配置来处理,作用删除操作后把对象的id设置null
<property name="hibernate.use_identifier_rollback">true</property>
Hibernate 的 cfg.xml 配置文件中有一个 hibernate.use_identifier_rollback 属性,其默认值为 false,若把它设为 true,将改变 delete() 方法的运行行为:delete() 方法会把持久化对象或游离对象的 OID 设置为 null,使它们变为临时对象。这样程序就可以重复利用这些对象了,基本不这么干,了解一下即可。
⑦ evict方法
这个方法就是将持久化对象从session缓存中删除,使其成为一个游离的对象。
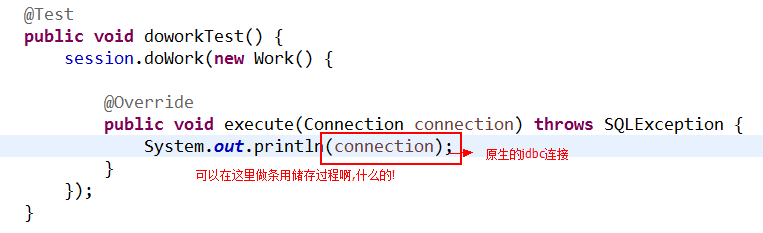
⑧doWork方法,
jdbc: 存储过程, 批量操作, jdbc原生conn,这个方法是在hibernate中拿到jdbc的原生的connection
Hibernate的配置文件
企业级应用里, 都必须使用一款数据库连接池, 这里我们讲一下c3p0的连接池怎么中Hibernate里配置:
①: 导入jar包:
hibernate连接c3p0的jar包
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.2.17.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>5.3.0.Final</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
</dependencies>
②: 配置C3P0-----hibernate.cfg.xml
<!-- C3P0连接池配置 -->
<property name="hibernate.connection.provider_class">org.hibernate.c3p0.internal.C3P0ConnectionProvider</property>
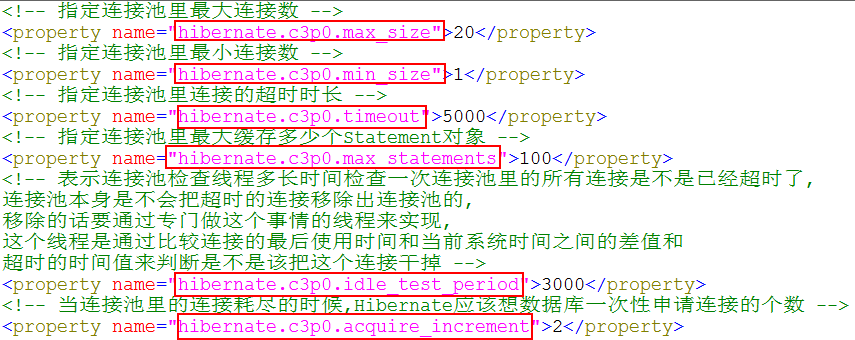
<property name="hibernate.c3p0.acquire_increment">20</property>
<property name="hibernate.c3p0.idle_test_period">2000</property>
<property name="hibernate.c3p0.max_size">20</property>
<property name="hibernate.c3p0.max_statements">10</property>
<property name="hibernate.c3p0.min_size">5</property>
<property name="hibernate.c3p0.timeout">2000</property>
<mapping resource="cn/ybzy/hibernatedemo/model/Student.hbm.xml"/>
② 测试配置成功不? 用dowork打印一下连接看看是不是c3p0提供的就可以了
//测试数据连接否,打印输出,如果含 有c3p0字样,说明c3p0连接池配置成功
@Test
public void doWorkTest() {
/*<session-factory >
name=""我测试时不要 ,不然会报错,但每次更新该文件会自动加上
连接数据库的基本信息 */
session.doWork(new Work() {
@Override
public void execute(Connection connection) throws SQLException {
System.out.println("数据库连接:"+connection);
}
});
}
--------------------------------------------------------------------------
数据库连接:com.mchange.v2.c3p0.impl.NewProxyConnection@13c612bd [wrapping: com.mysql.cj.jdbc.ConnectionImpl@6e6616f]
最后在补充介绍两个配置项:但可惜的是MYSQL不支持这两个功能
<property name="hibernate.jdbc.batch_size">30</property>
<property name="hibernate.jdbc.fetch_size">100</property>
Fetch Size是设定JDBC的Statement读取数据的时候每次从数据库中取出的记录条数。例如一次查询1万条记录,对于Oracle的JDBC驱动来说,是不会1次性把1万条取出来的,而只会取出Fetch Size条数,当纪录集遍历完了这些记录以后,再去数据库取Fetch Size条数据。因此大大节省了无谓的内存消耗。当然Fetch Size设的越大,读数据库的次数越少,速度越快;Fetch Size越小,读数据库的次数越多,速度越慢。这有点像平时我们写程序写硬盘文件一样,设立一个Buffer,每次写入Buffer,等Buffer满了以后,一次写入硬盘,道理相同。
Oracle数据库的JDBC驱动默认的Fetch Size=10,是一个非常保守的设定,根据测试,当Fetch Size=50的时候,性能会提升1倍之多,当Fetch Size=100,性能还能继续提升20%,Fetch Size继续增大,性能提升的就不显著了。因此建议使用Oracle的一定要将Fetch Size设到50。
不过并不是所有的数据库都支持Fetch Size特性,例如MySQL就不支持。MySQL就像我上面说的那种最坏的情况,他总是一下就把1万条记录完全取出来,内存消耗会非常非常惊人!这个情况就没有什么好办法了,所以小型项目才用mysql,真正大的项目还是用ORACLE!
Batch Size是设定对数据库进行批量删除,批量更新和批量插入的时候的批次大小,有点相当于设置Buffer缓冲区大小的意思。Batch Size越大,批量操作的向数据库发送sql的次数越少,速度就越快。做的一个测试结果是当Batch Size=0的时候,使用Hibernate对Oracle数据库删除1万条记录需要25秒,Batch Size = 50的时候,删除仅仅需要5秒!!! 可见有多么大的性能提升!很多人做Hibernate和JDBC的插入性能测试会奇怪的发现Hibernate速度至少是JDBC的两倍,就是因为Hibernate使用了Batch Insert,而他们写的JDBC没有使用Batch的缘故。Oracle数据库 Batch Size = 30 的时候比较合适,50也不错,性能会继续提升,50以上,性能提升的非常微弱,反而消耗内存更加多,就没有必要了。
映射关系的基本配置
<hibernate-mapping>
<class name="cn.ybzy.hibernatedemo.model.Student" table="STUDENT" select-before-update="true">
<id name="id" type="int">
<column name="ID" />
<generator class="native" /> <!-- assigned改为native,随数据库自增长模式生成id -->
</id>
<property name="username" type="java.lang.String">
<column name="USERNAME" />
</property>
<property name="sex" type="java.lang.String">
<column name="SEX" />
</property>
<property name="regDate" type="java.util.Date">
<column name="REGDATE" />
</property>
</class>
</hibernate-mapping>
Hibernate的持久化类和关系数据库之间的映射通常是用一个XML文档来定义的。该文档通过一系列XML元素的配置,来将持久化类与数据库表之间建立起一一映射。这意味着映射文档是按照持久化类的定义来创建的,而不是表的定义。
一、根元素:<hibernate-mapping>,每一个hbm.xml文件都有唯一的一个根元素,包含一些可选的属性:
1)package:指定一个包前缀,如果在映射文档中没有明确写出完整的包全名的类,会默认使用这个作为包名做前缀,如:
这个很有用。

(2).schema: 指定当前映射文件对应的数据库表的schema名
(3).catalog: 指定当前映射文件对应的数据库表的catalog名
(4).default-cascade: 设置默认的级联方式(默认值为none)
(5).default-access: 设置默认的属性访问方式(默认值为property)
(6).default-lazy: 设置对没有指定配置是否延迟加载映射类和集合设定是否默认延迟加载(默认值为true)
(7).auto-import: 设置当前映射文件中是否可以在HQL中使用非完整的类名(默认值为true)
hibernate-mapping节点的子节点:
(1).class: 为当前映射文件指定对应的持久类名和对应的数据库表名,常见的
(2).subclass: 指定多态持久化操作时当前映射文件对应的持久类的子类
(3).meta: 设置类或属性的元数据属性
(4).typedef: 设置新的Hibernate数据类型
(5).joined-subclass: 指定当前联结的子类
(6).union-subclass: 指定当前联结的子类
(7).query: 定义一个HQL查询
(8).sql-query: 定义一个SQL查询
(9).filter-def: 指定过滤器
二、<class>定义类:根元素的子元素,用以定义一个持久化类与数据表的映射关系,如下是该元素包含的一些可选的属性
(1).name: 为当前映射文件指定对应的持久类名,没有package要求包全名
(2).table: 为当前映射文件指定对应的数据库表名
(3).schema: 设置当前指定的持久类对应的数据库表的schema名
(4).catalog: 设置当前指定的持久类对应的数据库表的catalog名
(5).lazy: 设置是否使用延迟加载
(6).batch-size: 设置批量操作记录的数目(默认值为1)
(7).check: 指定一个SQL语句用于Schema前的条件检查
(8).where: 指定一个附加的SQL语句的where条件
(9).rowid: 指定是否支持ROWID
(10).entity-name:实体名称,默认值为类名
(11).subselect: 将不可变的只读实体映射到数据库的子查询中
(12).dynamic-update: 指定用于update的SQL语句是否动态生成 默认值为false
(13).dynamic-insert: 指定用于insert的SQL语句是否动态生成 默认值为false
(14).insert-before-update: 设定在Hibernate执行update之前是否通过select语句来确定对象是否确实被修改了,如果该对象的值没有改变,update语句将不会被执行(默认值为false)
(15).abstract: 用于在联合子类中标识抽象的超类(默认值为false)
(16).emutable: 表明该类的实例是否是可变的 默认值为fals
(17).proxy: 指定延迟加载代理类
(18).polymorphism: 指定使用多态查询的方式 默认值为implicit
(19).persister: 指定一个Persister类
(20).discriminator-value: 子类识别标识 默认值为类名
(21).optimistic-lock: 指定乐观锁定的策略 默认值为vesion
class节点的字节点:
(1).id: 定义当前映射文件对应的持久类的主键属性和数据表中主键字段的相关信息
(2).property: 定义当前映射文件对应的持久类的属性和数据表中字段的相关信息
(3).sql-insert: 使用定制的SQL语句执行insert操作
(4).sql-delete: 使用定制的SQL语句执行delete操作
(5).sql-update: 使用定制的SQL语句执行update操作
(6).subselect: 定义一个子查询
(7).comment: 定义表的注释
(8).composite-id: 持久类与数据库表对应的联合主键
(9).many-to-one: 定义对象间的多对一的关联关系
(10).one-to-one: 定义对象间的一对一的关联关系
(11).any: 定义any映射类型
(12).map: map类型的集合映射
(13).set: set类型的集合映射
(14).list: list类型的集合映射
(15).array: array类型的集合映射
(16).bag: bag类型的集合映射
(17).primitive-array: primitive-array类型的集合映射
(18).query: 定义装载实体的HQL语句
(19).sql-query: 定义装载实体的SQL语句
(20).synchronize: 定义持久化类所需要的同步资源
(21).query-list: 映射由查询返回的集合
(22).natural-id: 声明一个唯一的业务主键
(23).join: 将一个类的属性映射到多张表中
(24).sub-class: 声明多态映射中的子类
(25).joined-subclass: 生命多态映射中的来连接子类
(26).union-subclass: 声明多态映射中的联合子类
(27).loader: 定义持久化对象的加载器
(28).filter: 定义Hibernate使用的过滤器
(29).component: 定义组件映射
(30).dynamic-component: 定义动态组件映射
(31).properties: 定义一个包含多个属性的逻辑分组
(32).cache: 定义缓存的策略
(33).discriminator: 定义一个鉴别器
(34).meta: 设置类或属性的元数据属性
(35).timestamp: 指定表中包含时间戳的数据
(36).vesion: 指定表所包含的附带版本信息的数据
三、<id>定义主键:
Hibernate使用OID(对象标识符)来标识对象的唯一性,OID是关系数据库中主键在Java对象模型中的等价物,在运行时,Hibernate根据OID来维持Java对象和数据库表中记录的对应关系
id节点的属性:
(1).name: 指定当前映射对应的持久类的主键名
(2).column: 指定当前映射对应的数据库表中的主键名(默认值为对应持久类的属性名)
(3).type: 指定当前映射对应的数据库表中的主键的数据类型
(4).unsaved-value: 判断此对象是否进行了保存
(5).daccess: Hibernate访问主键属性的策略(默认值为property)
四、generator节点的属性:
(1).class: 指定主键生成器,id作为主键的生成策略: 前面详细讲过,这里不说了!
(2).name: 指定当前映射对应的持久类的主键名
(3).column: 指定当前映射对应的数据库表中的主键名(默认为对应持久类的主键名)
(4).type: 指定当前映射对应的数据库中主键的数据类型
(5).unique: 设置该字段的值是否唯一(默认值为false)
(6).not-null: 设置该字段的值是否可以为null(默认值为false)
(7).update: 设置update操作时是否包含本字段的数据(默认值为true)
(8).insert: 设置insert操作时是否包含本字段的数据(默认值为true)
(9).formula: 设置查询操作时该属性的值用指定的SQL来计算
(10).access: Hibernate访问这个属性的策略(默认值为property)
(11).lazy: 设置该字段是否采用延迟加载策略(默认值为false)
(12).optimistic-lock: 指定此属性做更新操作时是否需要乐观锁定(默认值为true)
五、property节点的属性:
用于持久化类的属性与数据库表字段之间的映射,包含如下属性:
(1)name:持久化类的属性名,以小写字母开头
(2)column:数据库表的字段名,也就是可以将子节点中的column标签提到属性上
(3)type:Hibernate映射类型的名字,这个类型是Java里的POJO里的属性类型和Hibernate自己内部的映射类型和数据库里表格的字段类型链接纽带,具体设置来讲可以设置java的类型
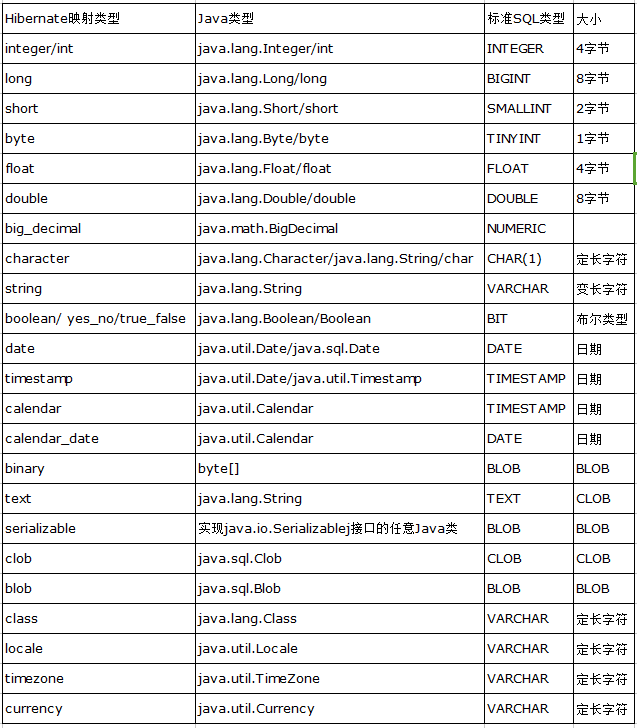
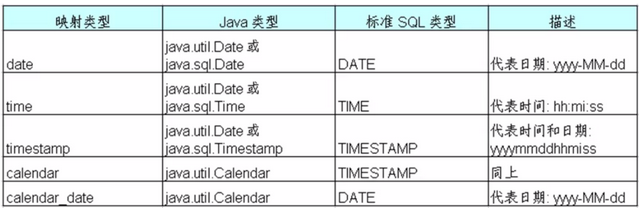
日期时间类型:
在java中日期时间类型: java.util.Date, java.util.Calendar
在JDBC的API中扩展里java.util.Date类:
java.sql.Date, java.sql.Time,java.sql.Timestamp
分别对应数据库中:
DATE, TIME, TIMESTAMP
大对象映射:
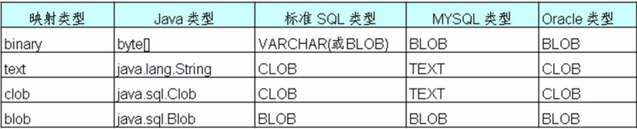
但是: 有时候,不是很精准,这个时候我们可以用sql-type属性做精准的类型映射:
(4).formula: 设置当前节点对应的持久类中的属性的值由指定的SQL从数据库获取,主要用在派生属性上面,这个配置里有里formula就不要再配置column了,
看例子:
注:指定的SQL必须用()括起来,指定SQL中使用表里的列名时必须用表的别名加.加列名的方式访问,但如果指定SQL中要使用当前映射对应的列名时不能用表的别名加.加列名的方式访问,而是直接访问即可
Student.java
public class Student {
private int id;
private String username;
private String sex;
private Date regDate;
private int regAge; //派生字段,没必要放到数据库中,通过regDate获取到
//get,set,toString(),无参构造
}
Student.hbm.xml
<hibernate-mapping>
<class name="cn.ybzy.hibernatedemo.model.Student" table="students">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="username" type="java.lang.String">
<column name="username" />
</property>
<property name="sex" type="java.lang.String">
<column name="sex" />
</property>
<property name="regDate" type="java.util.Date">
<column name="regdate" />
</property>
<!-- <property name="age" type="int">
<column name="regage" />
</property> -->
<property name="regAge" type="int"
formula="(select floor(datediff(now(),s.regdate)/365.25)
from students s where s.id=id )"></property>
</class>
</hibernate-mapping>
测试先加一条数据,注册日期设为2000-12-12,再全注释,再重新获取Student记录,打印输出,即可看到效果:24(相对于现在的2025年)
//插入一第学生信息记录,测试
@Test
public void test() throws ParseException {
/*SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date bd=sdf.parse("2000-12-12");
Student student=new Student();
student.setUsername("xiongshaowen");
student.setSex("男");
student.setRegDate(bd);
session.save(student);*/
Student student=session.get(Student.class, 1);
System.out.println(student);
System.out.println(student.getRegAge());
}
----------------------------------------------------------------
Student [id=1, username=xiongshaowen, sex=男, regDate=2000-12-12 00:00:00.0, regAge=24]
24
(5).unique: 设置该字段的值是否唯一(默认值为false)
6).not-null: 设置该字段的值是否可以为null(默认值为false)
(7).not-found: 设置当当前节点对应的数据库字段为外键时引用的数据不存在时如何让处理(默认值为exception:产生异常,可选值为ignore:对不存在的应用关联到null)
(8).property-ref: 设置关联类的属性名,此属性和本类的关联相对应 默认值为关联类的主键
(9).entity-name: 被关联类的实体名
(10).lazy: 指定是否采用延迟加载及加载策略(默认值为proxy:通过代理进行关联,可选值为true:此对象采用延迟加载并在变量第一次被访问时抓取、false:此关联对象不采用延迟加载)
(11).access: Hibernate访问这个属性的策略(默认值为property),所有的访问策略具体的, 值是property,Hibernate获取model实体类(POJO类/持久化类)的属性值时使用getter、setter方法,如果设置为field,则Hibernate会忽略getter和setter方法,直接用反射的方式访问成员变量的值
(12).optimistic-lock: 指定此属性做更新操作时是否需要乐观锁定(默认值为true)
(13).length: 指定数据类型的长度,并不是都指数据的大小, 数据的大小只和数据类型有关。具体说就是:
CHAR、VARCAHR的长度是指字符的长度,例如CHAR[3]则只能放字符串"123",如果插入数据"1234",则从高位截取,变为"123"。 VARCAHR同理。
TINYINT、SMALLINT、MEDIUMINT、INT和BIGINT的长度,其实和数据的大小无关!Length指的是显示宽度,如id的显示宽度为3,不足的左边补0,数据长度超过的则原样输出
FLOAT、DOUBLE和DECIMAL的长度指的是全部数位(包括小数点后面的),例如DECIMAL(4,1)指的是全部位数为4,小数点后1位,如果插入1234,则查询的数据是999.9。
但是注意: Hibernate内部有限制机制,它是不允许插入数据库的数据超出类型长度的!超出了Hibernate会报异常!
(14).update: 设置执行update的sql语句的时候,这个字段会不会被修改! false的话,修改操作对数据库失效,这个字段的值不允许修改!
(15).index: 设置数据库中该字段的索引
很多人机械的理解索引的概念,认为增加索引只有好处没有坏处。
首先明白为什么索引会增加速度,DB在执行一条Sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件的就加入搜索结果集合。
如果我们对某一字段增加索引,查询时就会先去索引列表中定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。
那么在任何时候都应该加索引么?这里有几个反例:
1、如果每次都需要取到所有表记录,无论如何都必须进行全表扫描了,那么是否加索引也没有意义了。
2、对非唯一的字段,例如“性别”这种大量重复值的字段,增加索引也没有什么意义。
3、对于记录比较少的表,增加索引不会带来速度的优化反而浪费了存储空间,因为索引是需要存储空间的,而且有个致命缺点是对于update/insert/delete的每次执行,字段的索引都必须重新计算更新。
那么在什么时候适合加上索引呢?我们看一个Mysql手册中举的例子,这里有一条sql语句:
SELECT c.companyID, c.companyName FROM Companies c, User u
WHERE c.companyID = u.fk_companyID
AND c.numEmployees >= 0
AND c.companyName LIKE '%i%'
AND u.groupID
IN (SELECT g.groupID FROM Groups g
WHERE g.groupLabel = 'Executive')
这条语句涉及3个表的联接,并且包括了许多搜索条件比如大小比较,Like匹配等。在没有索引的情况下Mysql需要执行的扫描行数是77721876行。而我们通过在companyID和groupLabel两个字段上加上索引之后,扫描的行数只需要134行。可以看出来在这种联表和复杂搜索条件的情况下,索引带来的性能提升远比它所占据的磁盘空间要重要得多。
(16).scale:指的是所映射的数据列的小数位数, 只对double,float,decimal等小数类型的数据列有效!
上面是Hibernate的关系映射配置文件中最核心和基本的配置, 接下来就是具体的关联关系的映射配置了, 下一节来开始!
单向多对一的映射
具体来讲数据表间存在的多种关系:多对一(单向和双向)、多对多 和 一对一等几种:
在Hibernate中单向多对一关系怎么样实现:
应用场景:每个班主任老师可以带很多个学生,反过来每个学生只能有一个班主任老师!
单向的多对一: 只需要n(多)这端访问1(一)这端的情况!没有1端访问多的端的时候:
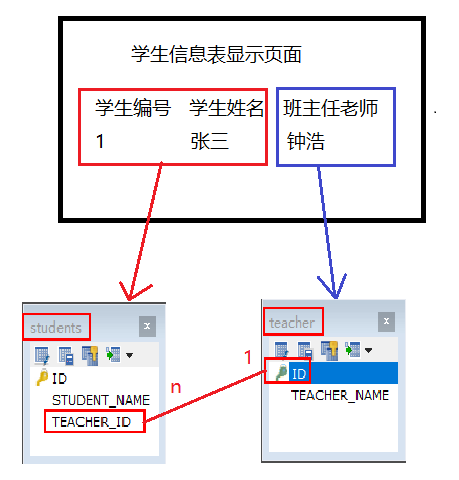
Student.java-----Teacher.java
public class Student {
private int id;
private String sname;
private Teacher teacher;
//get,set,toString(),无参构造
}
public class Teacher {
private int id;
private String tname;
//get,set,toString(),无参构造
}
Student.hbm.xml-------Teacher.hbm.xml
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Student" table="STUDENT">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="sname" type="java.lang.String">
<column name="s_name" />
</property>
<!-- 单向多对一的关系配置,一端不能访问多端 -->
<many-to-one name="teacher" class="Teacher">
<column name="teacher_id" />
</many-to-one>
</class>
</hibernate-mapping>
<hibernate-mapping>
<class name="cn.ybzy.hibernatedemo.model.Teacher" table="TEACHER">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="tname" type="java.lang.String">
<column name="t_name" />
</property>
</class>
</hibernate-mapping>
测试:插入三条数据,两个学生,一个老师
1,先插入老师(一端)
2,先插入所有学生,再插入老师,两个插入顺序结果看看:
//单向多对一的关系测试:只有多端多问一端,反之不能
@Test
public void manytooneTest() {
//save
Teacher teacher =new Teacher();
teacher.setTname("黄刚");
Student student1=new Student();
Student student2=new Student();
student1.setSname("张三三");
student1.setTeacher(teacher);
student2.setSname("李四四");
student2.setTeacher(teacher);
session.save(student1);
session.save(student2);
session.save(teacher);
}
结论: 先增加一的一端的数据,发起的sql语句少, 先增加多的一端的数据发起sql语句条数多, 建议先加一的一端, 效率高些!
3.查询
Student student= session.load(Student.class, 2);
System.out.println();
session.close();
System.out.println(student.getTeacher());
结论: 默认情况下, 使用的懒加载,查询多的一端对象, 只要没使用到关联的对象, 不会发起关联的对象的查询! 因为使用的懒加载, 所以在使用关联对象之前关闭session, 必然发生赖加载异常!
4.修改没什么要说的,都是正常情况!
5.删除的时候, 删除多的一端的对象和数据没问题, 删除一的一端,有外键约束! 也没什么好说的!
Student student=session.get(Student.class, 4);
Teacher teacher=session.get(Teacher.class, 2);
session.delete(student); //删除没问题
session.delete(teacher); //删除有问题,有外键约束,他对应的学生还有在的
双向一对多的联系
首先: 双向一对多,或者双向多对一是个相同的概念
如果只需要在学生信息的页面显示这个学生的班主任老师的信息, 就是单向多一对一, 但是如果班主任老师从信息显示页面也要显示老师班上有哪些学生的话, 那么就变成双向多对一/双向一对多的情形了!
在数据表结构上来看,双向和单向没什么区别, 都是要学生信息表中加外键字段teacher_id, 来关联teacher表的主键id ! 反过来, 在一的这端, 也可以通过teacher_id来找到所有的对应学生!
还要补充一下, set元素标签上还有几个属性:
①inverse: 它的作用是指定双向多对一的映射中, 由那一边来维护关系 , 默认值是inverse=“false” 要维护, 建议在一的那端的set元素上还是都设置为true! 在双向联系中让一端不维护, 多端不用设置默认会维护的!,不过,先插入一端数据,再插入多端数据是最合理的,这样插入时没有update语句发出。
②cascade: 这个属性在实际开发中是不建议用的, 怕出问题! 它的作用是设置级联的模式, 如果设置为delete, 表示执行级联删除, 也就是说删除多的这端的某条记录, 它会连着将与之有关联的一的那端的记录一块儿删除掉; 如果设置save-update级联保存, 会保存对象关联的临时对象到数据库. (只做了解)
③order-by: 设置查询出来的数据的排序, 实质就是在sql语句后面加order by语句, 看下例子!
例:以上单向多对一的资源为依据,这里只要改Teacher的资源即可
public class Teacher {
private int id;
private String tname;
private Set<Student> students=new HashSet<>(); //new一个,避免空指针异常
//get,set,toString(),无参构造,
//toString()方法不要显示关联对象信息,可能会在查询关联表对象数据时造成stackoverfloerror,因为这样递归太深了,造成栈满
}
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Teacher" table="t_teaches"> <!--如果把表名写成类名一样,可能会在查询关联表对象数据时造成stackoverfloerror-->
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="tname" type="java.lang.String">
<column name="t_name" />
</property>
<set name="students" table="t_students" inverse="true"> <!-- t_studentsg与学生表名字,要一样 -->
<key>
<column name="teacher_id"></column> <!-- teacher_id外键关联的表列名 -->
</key>
<one-to-many class="Student"/>
</set>
</class>
</hibernate-mapping>
测试
//双向多对一测试:即老师也能查看学生信息,学生也可查老师信息
@Test
public void doublemanytooneTest() {
//save
/*Teacher teacher =new Teacher();
teacher.setTname("yx1");
Student student1=new Student();
student1.setSname("zs1");
student1.setTeacher(teacher);
Student student2=new Student();
student2.setSname("ls1");
student2.setTeacher(teacher);
Set<Student> students = new HashSet<>();
students.add(student1);
students.add(student2);
teacher.setStudents(students);
session.save(teacher);
session.save(student1);
session.save(student2);*/
//session.save(teacher);
Teacher teacher=session.get(Teacher.class, 1);
//System.out.println(teacher);
Student student=session.get(Student.class, 1);
System.out.println(student);
//Set<Student> students=teacher.getStudents();
//System.out.println(Arrays.toString(students.toArray()));
}
Hibernate一对一的联系
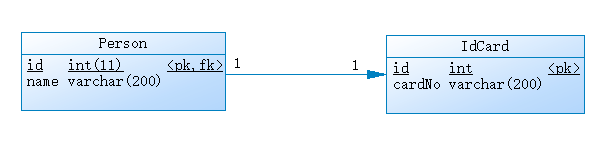
从上图中可以看出:
1、一个人只有一张身份证,唯一的一个身份证号, 反之亦然,两个对象(两张表中的对应记录)之间是一对一的关系;
2、场景中应该是人(Person)持有身份证(IdCard)的引用,所以两个对象关系维护应该由person端来控制。
一对一关联,有两种方式:
主键关联(不推荐用)和唯一外键关联(实际应用中我们推荐用后面这种)
主键关联的关系模型:
数据结构上两个表里都没有外键, 直接让对应记录的id值相同!
Person.java,IdCard.java
public class Person {
private int id;
private String name;
private IdCard idCard;
//get,set,toString()不显示关联对象信息,无参构造
}
public class IdCard {
private int id;
private String idCardNo;
private Person person;
//get,set,toString()不显示关联对象信息,无参构造
}
Person.hbm.xml,IdCard.hbm.xml
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Person" table="t_persons">
<id name="id" type="int">
<column name="id" />
<generator class="foreign">
<param name="property">idCard</param> <!-- private IdCard idCard; -->
</generator>
</id>
<property name="name" type="java.lang.String">
<column name="name" />
</property>
<one-to-one name="idCard" class="IdCard" constrained="true"></one-to-one>
</class> <!-- 让外表主键ID充当外键 -->
</hibernate-mapping>
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="IdCard" table="t_idcard">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="idCardNo" type="java.lang.String">
<column name="id_card_no" />
</property>
<one-to-one name="person" class="Person" property-ref="idCard"></one-to-one>
</class> <!-- Person中private IdCard idCard; -->
</hibernate-mapping>
hibernate.cfg.xml
<session-factory>
....
<mapping resource="cn/ybzy/hibernatedemo/model/Person.hbm.xml"/>
<mapping resource="cn/ybzy/hibernatedemo/model/IdCard.hbm.xml"/>
....
</session-factory>
测试:
@Test //一对一关系测试, Person,IdCard两个类和表
public void onetooneTest() {
Person person=new Person();
person.setName("zs1");
IdCard idCard=new IdCard();
idCard.setIdCardNo("360428198704056028");
idCard.setPerson(person);
person.setIdCard(idCard);
session.save(idCard); //谁前谁后插入,不影响发起的sql语句的条数,都一样
session.save(person); //谁前谁后插入,不影响发起的sql语句的条数,都一样用的是关联查询插入
/*Person person = session.get(Person.class, 1);
System.out.println(person);
System.out.println(person.getIdCard());*/
}
唯一外键关联关系模型
只修改Person.hbm.xml
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
.....
<!--主键方式-->
<!-- <one-to-one name="idCard" class="IdCard" constrained="true"></one-to-one> -->
<!-- 让外表主键ID充当外键 -->
<!-- 唯一外键方式:在多对一的标签上加唯一性的约束,实质上也就变成一对一 ,下面条是一样的配置-->
<!--<many-to-one name="idCard" class="IdCard" unique="true" column="id_card_id"></many-to-one>-->
<many-to-one name="idCard" class="IdCard" unique="true">
<column name="id_card_id"></column>
</many-to-one>
</class>
</hibernate-mapping>
多对多的联系
应用场景:每个老师可以上多门课程,反过来每门课程也有多个老师来上!这样子, 老师------课程之间就构成一个多对多的关系, 那么这种关系,在具体的应用中, 表现要在老师页面去显示, 具体某个具体老师所上的所有课程, 反过来在课程页面也要去显示某门课程都有哪些老师在上的时候用!
在数据表结构的层面, 我们一般是将多对多的两个数据表转换为两组多对一的关系,(中间表,两个数据表总共三个表)来实现:
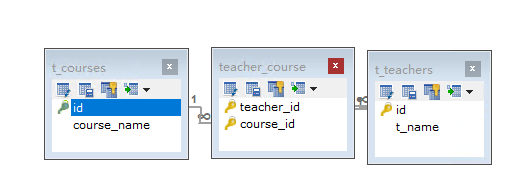
单向多对多
teacher里查询course, 反过来没有:
Teacher.java,Course.java
public class Teacher {
private int id;
private String tname;
private Set<Course> courses=new HashSet<>();
//get,set,toString()不显示关联对象信息避免栈溢出,无参构造
}
public class Course {
private int id;
private String courseName;
//get,set,toString(),无参构造
}
Teacher.hbm.xml,Course.hbm.xml
单向多对多,由Teacher端来控制维护关系。
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Teacher" table="t_teachers">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="tname" type="java.lang.String">
<column name="t_name" />
</property>
<!-- 单向多对多,双向多对多,设置都不变 -->
<set name="courses" table="teacher_course">
<key>
<column name="teacher_id" />
</key>
<many-to-many class="Course" column="course_id" />
</set>
</class>
</hibernate-mapping>
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Course" table="t_courses">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="courseName" type="java.lang.String">
<column name="course_name" />
</property>
</class>
</hibernate-mapping>
hibernate.cfg.xml
<mapping resource="cn/ybzy/hibernatedemo/model/Teacher.hbm.xml"/>
<mapping resource="cn/ybzy/hibernatedemo/model/Course.hbm.xml"/>
测试:在测试类中,任一方法(没有插入语句),执行之,就会自动生成三张表,因为已经配了三个表的关系了,如上图所示:。
双向多对多
双向的多对多:
注意1: 中间表用同一个
注意2: 其中一端一定要设置inverse=“true”, 避免两房都去维护中间, 造成冲突
注意3: 两端的many-to-many指定的类交叉相同
修改Course.java,Course.hbm.xml
public class Course {
private int id;
private String courseName;
private Set<Teacher> teachers=new HashSet<>();
//get,set,toString()不显示关联对象信息避免栈溢出,无参构造
}
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Course" table="t_courses">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="courseName" type="java.lang.String">
<column name="course_name" />
</property>
<!-- 单向多对多时,不用在Course.hbm.xml中设置 <set> -->
<!-- 双向多对多,设置Course端不维护关系表inverse="true",key是外键设置,中间表与Teacher.hbm.xml中设置一样 -->
<set name="teachers" table="teacher_course" inverse="true">
<key>
<column name="course_id"></column>
</key>
<many-to-many class="Teacher" column="teacher_id"></many-to-many>
</set>
</class>
</hibernate-mapping>
测试:
@Test //单向多对多关系测试, Teacher,Course两个类和中间表
public void manytomanyTest() {
//双向多对多,两个老师都上了两门课
Teacher teacher=new Teacher();
teacher.setTname("yx");
Teacher teacher2 = new Teacher();
teacher2.setTname("xsw");
Course course=new Course();
course.setCourseName("javaweb");
Course course2 = new Course();
course2.setCourseName("Hibernate");
Set<Course> courses=new HashSet<>();
courses.add(course);
courses.add(course2);
Set<Teacher> teachers=new HashSet<>();
teachers.add(teacher);
teachers.add(teacher2);
//两个老师都上了两门课
teacher.setCourses(courses);
teacher2.setCourses(courses);
course.setTeachers(teachers);
course2.setTeachers(teachers);
session.save(teacher);
session.save(teacher2);
session.save(course);
session.save(course2);
}
组件映射
组件映射中, 组件也是一个类, 但是这个类它不独立称为一个实体, 也就是说, 数据库中没有一个表格单独的和它对应, 最明显的是没有ID,但要有POJO一样的方法.组件类,就是组装到实体类的类。
如:Student.java,StudentInfo.java,后面一个类是组件类,包含地址,生日,班组等信息属性。
Student.java
public class Student {
private int id;
private String sname;
private StudentInfo studentInfo; //它是Student对象的的组件
//get,set,toString(),无参构造
}
StudentInfo.java
public class StudentInfo {
private String address;
private Date birthday;
private String classes;
//get,set,toString(),无参构造
}
Student.hbm.xml(StudentInfo.hbm.xml不用建的)
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Student" table="student">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<property name="sname" type="java.lang.String">
<column name="s_name" />
</property>
<!-- 组件测试,加入组件StudentInfo -->
<component name="studentInfo" class="StudentInfo">
<property name="address" type="string">
<column name="address"></column>
</property>
<property name="birthday" type="date">
<column name="birthday"></column>
</property>
<property name="classes" type="string">
<column name="classes"></column>
</property>
</component>
</class>
</hibernate-mapping>
hibernate.cfg.xml
<mapping resource="cn/ybzy/hibernatedemo/model/Student.hbm.xml"/>
测试:只要在测试类中写一个方法即可,可以没有内容,再junit test运行,会自动生成一个student表(xxxx.hbm.xml中<class name="Student" table="student">中定义的名字),包含五个字段,不仅仅是主体类的两个字段。
//组件测试:Student,StudentInfo
@Test
public void componetTest() {
}
映射继承关系
我们前面讲过,Hibernate是ORM框架的一个具体实现,最大的一个优点就是我们的开发更加的能体现出“面向对象”的思想。在面向对象开发中,类与类之间是可以相互继承的(单向继承),而Hibernate中也对这种继承关系提供了自己风格的封装,这就是我们接下来要介绍的Hibernate继承映射的三种策略:
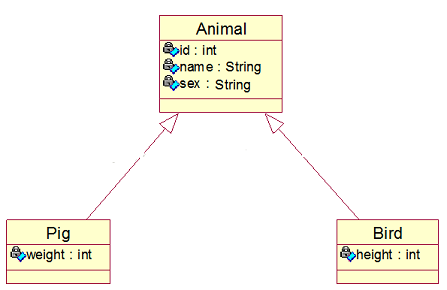
我们把这三个类, 看成一颗倒过来的树, Animal类是树根, Pig和Bird是两条树枝
- 第一种策略是把树上的三个类, 映射到一张数据表上
- 每个类一张表(父类Animal、子类Pig、子类Bird各一张表,父表中有公共字段,子表中有个性字段+外键约束)
- 每个具体类一张表(每个子类一张表,每张表都有自己所有的属性字段包括父类的公共字段)
第一种策略
Animal.hbm.xml
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Animal" table="t_animals" discriminator-value="animal">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<!--辨别字段配置,定义一定要放在id之后 ,辨别值放在subclass中-->
<discriminator column="type" type="string"></discriminator>
<property name="name" type="java.lang.String">
<column name="name" />
</property>
<property name="sex" type="java.lang.String">
<column name="sex" />
</property>
<subclass name="Pig" discriminator-value="pig">
<property name="weight"></property>
</subclass>
<subclass name="Bird" discriminator-value="bird">
<property name="height"></property>
</subclass>
</class>
</hibernate-mapping>
hibernate.cfg.xml
<mapping resource="cn/ybzy/hibernatedemo/model/Animal.hbm.xml"/>
测试:
//继承测试:
@Test
public void extendsTest() {
//1.Animal,Pig,Bird三个类同一张表测试,只有一个.hbm.xml文件---Animal.hbm.xml
Pig pig=new Pig();
pig.setName("zs");
pig.setSex("公");
pig.setWeight(200);
Bird bird = new Bird();
bird.setName("ls");
bird.setSex("母");
bird.setHeight(500);
session.save(pig);
session.save(bird);
}

这种映射方式可以把多个类放在一张表中,但是粒度比较粗,有冗余字段;但又是因为多个类的相关记录都存放在一张表中,查询时不用关联,因此效率较高。
第二策略每个类一张表
每个类一张表(父类Animal、子类Pig、子类Bird各一张表,父表中有公共字段,子表中有个性字段+外键约束)用joined-subclass, 其他没变化:
这种方案相对于上层实现(增删改查等操作)不变,因为对象模型并没有改变,只是关系模型改了,只需要修改映射文件即可。
缺点:查询时需要关联表,效率差;插入时也要执行多个insert语句,适合继承程度不深的情况。
优点:粒度较细,条理清楚,没有冗余。
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class name="Animal" table="t_animals">
<id name="id" type="int">
<column name="id" />
<generator class="native" />
</id>
<!--辨别字段配置不需要了-->
<property name="name" type="java.lang.String">
<column name="name" />
</property>
<property name="sex" type="java.lang.String">
<column name="sex" />
</property>
<joined-subclass name="Pig" table="t_pig" >
<key column="pid"></key>
<property name="weight" type="int" column="weight"></property>
</joined-subclass>
<joined-subclass name="Bird" table="t_bird" >
<key column="bid"></key>
<property name="height" type="int" column="height"></property>
</joined-subclass>
</class>
</hibernate-mapping>
其它都不变,包括测试
不知为什么,t_bird表,插不了记录,但程序运行也不报错。
第三种策略每个类一张表
每个具体类一张表(每个子类一张表,每张表都有自己所有的属性字段包括父类的公共字段)<union-subclass>
Animal.java把id字段的数据类型改为String
Animal.hbm.xml

上面的表有个特点就是,t_pig和t_bird的主键永远都不会相同。
因为表面上看起来这是两张表,但实际上存储的都是动物(同一类型),所以还可以看做是一张表。
在配置文件中 <union-subclass>标签中不需要key值了,注意Animal的主键生成策略不能是自增(native)了,如果自增的话,pig表中第一条记录id为1,bird表中第一条记录也为1,而它们在实际意义上属于同一类型(可以看做在一张表中),可能造成不同子类对应表中的主键相同,所以主键不可一致。
配置映射文件时,父类还用<class>标签来定义;用<union-subclass>标签定义两个子类,且每个类对应的表的信息是完全的,包含了所有从父类继承下来的属性。
子类的特有属性同样用<property>定义即可。
用abstract属性表示父类Animal为抽象类,这样Animal就不会映射成表了。
<hibernate-mapping package="cn.ybzy.hibernatedemo.model">
<class abstract="true" name="Animal" table="t_animals">
<id name="id" type="string">
......
总结:
如果系统需要经常进行查操作且子类数量较多,则建议用第一种方案,即每棵生成树映射一张表,这也是最常用的方法,效率较高。如果追求细粒度的设计且子类数量不多,则可以用后两种方案:每个类映射一张表或每个具体类映射一张表。
hibernate5 ID生成策略的改变
1、uuid2:使用JDK自带的UUID生成36位的ID
2、guid:
3、uuid:生成32位的uuid,不符合ETF(Internet工程委员会) RFC 4122标准,已被uuid2取代。
4、uuid.hex:等同uuid。
5、assigned:自己指定ID。
6、identity:需要数据库支持。
7、select:需要数据库支持。
8、sequence:需要数据库支持。
9、seqhilo:序列高低已废弃。
10、increment:需要数据库支持
11、foreign
12、sequence-identity:已废弃。
13、enhanced-sequence
14、enhanced-table:
native还是用的最多的。


















 2283
2283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











