







RAC是什么?
和单机概念进行对比:单机是一个实例,1个数据库;RAC是多个实例,一个数据库,多个实例之间共享一个数据库,但是不是分布式,这就是RAC,简单来说就是一个集群。
为什么会有RAC的需求?
为了实现数据的高可用,以数据的高可用为目标,这也是RAC最大的特点:
就像每家每户用电一样,作为用电户总是不希望家里出现停电的情况,因为停电将对日常生活带来极大的不便。同样,作为信息系统的客户也不希望系统出现异常情况,这同样会影响客户正常的生产和生活。
1)从硬件来说,为了追求信息系统更加高效稳定的运行,支撑信息系统运行的各个硬件组成部分,在产品长时间高效稳定运行方面得到了巨大的发展。
例如,UPS电源保证机房在断电的情况下能支撑较长时间的供电,服务器有非常多不同于一般PC的设计来保证服务器能够长时间稳定的运行,存储系统也在不断地发展与进步,这些是硬件方面的内容,是信息系统运行的基础。
2)从软件上来说,作为信息系统核心的数据库产品在不断增强产品质量的同时,也提出了自己的高可用性解决方案,并且这些方案也在不断地增强和普及。而RAC数据库就是Oracle公司针对数据库的高可用性解决方案。
数据库的高可用性依赖于硬件的稳定运行和设备的冗余,软硬件高效稳定的协同工作才能够保证系统更加安全、稳定和高效地运行。
RAC有什么优势?
1)高可用性:RAC是Oracle数据库产品高可用性的解决方案,能够保证在集群中只要有一个节点存活,就能正常对外提供服务。
单节点数据库,如果实例宕机了,如果一个业务链接在实例上面,那么这个业务就中断了。这个时候系统就不具有可用性了,那么这个时候单节点的可用性是很差的。
2)双机并行:RAC是一种并行模式,并不是传统的主备模式。也就是说,RAC集群的所有成员都可以同时接收客户端的请求。
RAC是一种充分利用服务器资源的高可用性实现方案,RAC的并行模式实现方式与传统的双机热备实现方式截然不同,图是两者的比较。
如图所示,两个节点在传统的双机热备环境中,始终有一台机器作为备用机,只有当主节点出现问题的时候才会切换到备用机上;如果主机一直没有出现问题,那么备用机始终处于空闲状态,这在资源的利用上以及成本方面都是巨大的浪费。但RAC是一种并行模式的架构,也就是说,两个节点的集群节点间是一种并行运行的关系,当一台机器出现问题,请求会自动转发到另一台机器,没有任何一台机器作为备用机一直不被使用,这样就充分利用了服务器资源。同时,传统的双机热备构架在出现问题时,常常需要数分钟的切换时间,而RAC在出现问题时,针对存在的会话只需要数十秒的时间就可以完成失败切换过程,对新会话的创建不会产生影响,在切换时间上也有比较大的优势。

3)易伸缩性:RAC可以非常容易地添加、删除节点,以满足系统自身的调整。
RAC为需要重新规划的应用提供了易扩展性。为了在系统初始阶段保持较低的成本,避免造成不必要的浪费,集群可以按照标准硬件配置,选择适当的服务器资源、存储资源来搭建数据库环境。当系统需要更多的处理能力或者需要增加存储时,通过添加另一台服务器或存储设备到集群中,能够在不停机的情况下获得水平的扩展。在一个集群中, Clusterware和RAC支持多达100个集群节点。
当某个集群的处理能力过剩,另一个集群的处理能力不够时,可以从处理能力过剩的集群移动一个节点到处理能力不够的集群中。这样能够充分利用服务器资源,节约成本。11gR2版本中推出了网格即插即用(Grid Plug and Play,GPnP),可以实现节点的快速添加。
4)低成本:能使用较低廉的服务器来实现高可用性、高吞吐量的集群环境,这要比通过对某台高端服务器增加硬件实现高可用性、高吞吐量花费的成本低很多。
通过多台普通的PC服务器组成一个集群,可以提高集群的处理能力,这样要比采用一台高性能的服务器的成本低很多。如果想提高系统的处理能力,给集群添加节点比为高性能服务器添加硬件要容易得多。另外,使用集群还能动态地移除节点,更加充分地利用管理者掌握的所有服务器资源,从服务器整体使用上降低了服务器的采购成本。越来越多的企业愿意将集群解决方案应用到他们的系统中,以降低成本,提高系统的可用性。
5)高吞吐量:随着节点数的增加,整个RAC的吞吐量也在不断增长。
RAC是由多台服务器构成的逻辑主体,比单台数据库服务器能接收更多的客户端请求。这在要求高吞吐量的系统中,能够得到非常明显的体现。在RAC的架构中,多个实例分布在多个服务器上,能同时打开同一个数据库,而每个实例能够接收相等数量的客户端请求,这样,随着服务器的增加,吞吐量也在不断地增加。
RAC有什么劣势?
1)RAC不能够解决在数据安全方面的问题
尽管有多个实例,但是只有一份数据文件,这样只要数据文件损坏了,那么整个数据库就损坏了。
2)RAC的稳定性很难保证
数据库的稳定运行是系统稳定运行的基础和前提,数据库的运行依赖于操作系统、服务器、存储设备等软硬件设备的运行情况。
由于各种硬件设备、操作系统的厂商不同,有时候在兼容性上会存在问题,即使同一个厂商的服务器,由于驱动、固件版本的不同也可能导致硬件出现问题以及与其他设备的兼容性问题。同时,由于RAC本身也存在不少bug,很多部署的RAC环境缺乏在上线前对环境的检查和测试,导致在运行过程中出现一系列不稳定的情况,这样高可用性并没有得到充分的体现。
由此来看,稳定的硬件环境加上稳定的RAC版本,决定着RAC运行的稳定性。数据库工程师与硬件工程师在安装配置前大量的环境检查、验证,以及部署后的大量测试工作都是非常重要的。
3)RAC的高性能也很难保证
高性能也是大部分从单机环境迁移到RAC环境比较头疼的问题,RAC并不是高性能的解决方案。在目前普遍使用千兆网络的硬件环境中,很多时候系统的数据库从原来的单机迁移至RAC环境,系统的性能反而下降。在这种情况下,数据库管理员应该根据RAC的特点对系统调整提出合理的建议,经过合理的设计、开发,使用RAC是能够提高系统的处理性能的。
RAC适用于什么场景?
1)对高可用要求比较高的场景
RAC和一般的“1个实例,1个数据库”有什么区别?
1)实现更加复杂
2)需要了解的技术更多,搭建环境难度更大,可能遇到的问题更多,尤其是稳定性和高性能方面
3)高可用
要想了解透彻RAC,除了上面所述的基本知识,还需要了解什么?
RAC架构

在RAC里面,最重要的就是实例和实例之间的交互,即使是分离的实例,但是读取的数据是相同的,RAC不是分布式的系统,因为它只有一个存储,分布式系统是指数据发布在不同的数据库上面,然后通过中间件来协调做查询。RAC还是一台数据库,多个实例。
对于RAC来说至少有两套物理上不同的网络,私有网络是专门用来实例之间的数据交互。如果私有网络,所有的数据都在一个网络下面,那么那么就会对数据造成影响,严重的影响RAC的性能了。实例之间数据之间传递使用私有网络和对外服务提供的网络之间是物理分开的。所以RAC至少有两套网络,一个是实例之间的数据的传递,另外一个是公有网络,是对外提供服务的,外面的业务是提供公有网络的IP链接到数据库的。
RAC的特点
除了具有普通的数据库特性外:
每一个节点的instance都有自己的SGA
每一个节点的instance都有自己的background process
每一个节点的instance都有自己的redo logs
每一个节点的instance都有自己的undo表空间
每一个节点的实例都有自己的SGA,但是之间在SGA里面的数据块都是需要相互传递的。
每一个节点都有自己的redo,redo不是共用的。虽然redo是放在共享磁盘上面,但是每个实例都有自己的redo,各有各的。当实例2坏了,实例1做恢复的时候可以通过实例2的redo信息来进行恢复。
每个实例都要处理自己的一套事务,所以需要使用自己的UNDO。
所以在RAC架构下面,每一套实例都有自己的东西。
RAC相关的后台进程?

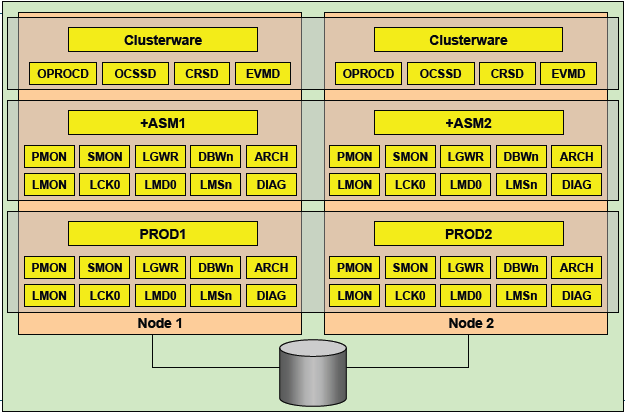
一、RAC后台进程
LMON:LOCK Monitor Processes 也被称为Global enqueue service monitor
监控整个集群状况,维护GCS的内存结构 监控非正常终止的进程和实例 当实例离开和加入集群时,锁和资源的重新配置 管理全局的锁和资源 监控全局的锁资源、处理死锁和阻塞
LCK:Lock Process
LCK进程主要用来管理实例间资源请求和跨实例调用操作,调用操作包括数据字典等对像访问,并处理非
CACEH FUSION的CHACE资源请求,(例如dictionary cache或row cache的请求) 由于LMS进程负责主要的锁管理功能,所以每个实例只有一个LCK进程
LMD:Lock Monitor Deamon Process
LMD进程主要管理对全局队列和资源的访问,并更新相应队列状态,处理来自于其它实例的资源请,每一个全局队列的当前状态存储在相应的实例共享内存中,该状态表明该实例具有相应的权利使用该资源,一个实例master的共享内存中存在一个特殊的队列,该队列记录来自其它远程实例的资源请求,当远程实例的LMD进程发出一个资源请求时,该请求指向master实例的LMD,当master实例的LMD进程受到该请求后,在共享内存中的特殊队列中监测该资源是否有无效,如果有效LMD进程更新该资源对列的状态,并通知请求资源的LMD进程该资源队列可以使用了,如果资源队列正被其它实例使用或当前无效,则LMD进程通知正在使用中的实例的LMD进程应用释放该资源,等资源释放变得有效时,master实例的LMD进程更新该资源队列的状态,并通知请求资源实例的LMD进程,该资源队列可以使用了
全局队列服务(GES):主要负责维护字典缓存和库缓存内的一致性。字典缓存是实例的 SGA 内所存储的对数据字典信息的缓存,用于高速访问。由于该字典信息存储在内存中,因而在某个节点上对字典进行的修改(如DDL)必须立即被传播至所有节点上的字典缓存。GES 负责处理上述情况,并消除实例间出现的差异。出于同样的原因,为了分析影响这些对象的 SQL 语句,数据库内对象上的库缓存锁会被去掉。这些锁必须在实例间进行维护,而全局队列服务必须确保请求访问相同对象的多个实例间不会出现死锁。LMON、LCK 和 LMD 进程联合工作来实现全局队列服务的功能。GES 是除了数据块本身的维护和管理(由 GCS 完成)之外,在 RAC 环境中调节节点间其他资源的重要服务。
LMSn:Lock Monitor Services也称作GCS(Global Cache Services)processes
LMS进程主要用来管理集群内数据库的访问,并在不同实例的buffer cache中传输块镜像,当在某个数据块上
发生一致性读时,LMS负责回滚该数据块,并将它copy到请求的实例上 每个RAC节点至少有2个LMS进程
全局缓存服务(GCS):要和 Cache Fusion 结合在一起来理解,全局缓存要涉及到数据块。全局缓存服务负责维护该全局缓冲存储区内的缓存一致性,确保一个实例在任何时刻想修改一个数据块时,都可获得一个全局锁资源,从而避免另一个实例同时修改该块的可能性。进行修改的实例将拥有块的当前版本(包括已提交的和未提交的事物)以及块的前象(post image)。如果另一个实例也请求该块,那么全局缓存服务要负责跟踪拥有该块的实例、拥有块的版本是什么,以及块处于何种模式。LMS 进程是全局缓存服务的关键组成部分。
DIAG:Diagnostic Deamon
oracle10g新的后台进程 例行对实例的健康情况进行监控,同时也监控实例是否挂起或者出现死锁 收集实例和进程出错时的关键诊断信息 这个进程会更新alert日志文件,写入一些重要告警信息
二、RAC服务进程
CRS-集群资源服务(cluster ready services)
管理集群内高可用操作的基本程序 CRS管理的任何事务被称之为资源 数据库、实例、监听、虚拟IP、应用进程等等 CRS是跟据存储于OCR中的资源配置信息来管理这些资源 当一资源的状态改变时,CRS进程生成一个事件,操作包括启动、关闭、监控及故障切换,该进程由 root 用户管理和启动,CRSD如果有故障会导致系统重启
CSS-集群同步服务(Cluster Synchronization Service)
管理集群节点的成员资格 控制哪 个结点为集群的成员、节点在加入或离开集群时通知集群成员来控制集群配置信息,此进程发生故障导致集群重启,提供心跳机制监控集群状态(DISK HEARTBEAT 和 NETWORK HEARBEAT),该进程由 oracle 用户运行管理
EVMD事件管理服务(Event Management)
事件管理守护进程 发布CRS创建事件的后台进程
ONS-事件的发布及订阅服务(Oracle Notification Service)
通信的快速应用通知事件的发布及订阅服务
OCR- Oracle Cluster Register
集群注册文件,记录每个节点的相关信息 保存RAC集群的各种资源信息 类似于windows注册表 存储于共享磁盘上,所有实例共享 默认有2个互备磁盘
Voting Disk 表决磁盘
仲裁机制用于仲裁多个节点向共享节点财时写的行为,避免发生冲突 存储于共享磁盘上,所有实例共享 用于确定各个实例的关系 当有节点失效时,通过voting disk来决定驱逐哪个实例 默认有3个互备磁盘
OPROCD(Process Monitor Daemon)检测 CPU hang(非 Linux 平台使用),集群进程管理 —Process monitor for the cluster. 用于保护共享数据 IO fencing
其他不理解的问题
Oracle 12c中的Flex概念
概述
12c的两个新特性“Flex ASM”和“Flex 集群”两个属性,支持面向云计算的环境的各种苛刻需求。
Oracle 12c引入的两个新概念
-
中心节点(HUB NODE): 和以前的版本一样,它们通过专用网络相互连接,并且可以直接访问共享存储。这些节点可以直接访问 Oracle 集群注册表 (OCR) 和表决磁盘 (VD)。这种结点上主要用来跑数据库实例,也就是数据库服务。每个hub node之间通过私网连接,而且需要配置ssh对等性。hub node上既运行ASM实例又运行db实例。每个flex cluster至少一个hub node最多64个hub node。
-
叶节点(LEAF NODE): 这些节点是轻型节点,彼此不互连,也不能像中心节点一样访问共享存储。每个叶节点与所连接的中心节点通信,并通过所连接的中心节点连接到集群。这种结点上主要用来跑应用,比如说什么系统之类的。不需要与集群中的其它数据库服务器进行通信,只需要和它所连接的中心节点进行通信即可。虽然leaf node不要求直接访问共享存储,但最好还是连上共享存储,因为说不准未来哪天就要把这个leaf node转为hub node使用。leaf node上面不能运行ASM实例,也不能在上面建库,因为上面运行的实例打开方式只能是只读的。leaf node上可运行多种应用,例如中间件、EBS、IDM等,leaf node上的应用会在leaf node挂掉后自动切换到其他leaf node。
-
综述:即使flex cluster中没有一个leaf node, hub node也可以正常的像传统rac节点一样工作。但如果flex cluster中只有leaf node没有一个hub node是万万不可的,因为leaf node需要通过hub node上的asm实例获取数据。
当集群件启动在leaf node上时,leaf node就会根据GNS信息查找所有hub node,然后选择其中一个hub node来获取数据(配置GNS是使用leaf node的重要前提)。一个hub node同时可能被0个或多个leaf node连接,而一个leaf node同时只能连接一个hub node。hub node和leaf node之间也会交换心跳信息,只有这样leaf node才能加入集群并作为集群的一部分。
在 Oracle 12c 之前,对于要使用 ASM 的数据库实例来说,所有节点上的 ASM 实例必须已处于运行状态,才能启动数据库实例。如果 ASM 实例未运行,则意味着在存储级使用 ASM 的数据库实例不能启动。这实际上意味着无论采用何种技术(即 RAC、ASM 和共享存储),均不能访问数据库实例。
随着 Oracle 12c 的推出,一个名为 Oracle Flex ASM 的特性解除了上述限制,它的一个主要特性是故障切换到集群中的其他节点。本质上是一个中心和叶架构,Oracle Clusterware 通过一个替代 ASM 实例将故障节点的连接将无缝转移到另一个成员节点。(如果 Oracle 12c 数据库实例与一个 ASM 实例的连接断开,数据库连接将故障切换至其他服务器上的另一个 ASM 实例)在给定集群中运行的 ASM 实例数被称作 ASM 基数,默认值为 3。但此基数值可以使用 Clusterware 命令修改。
一个典型的 Oracle Flex 集群:
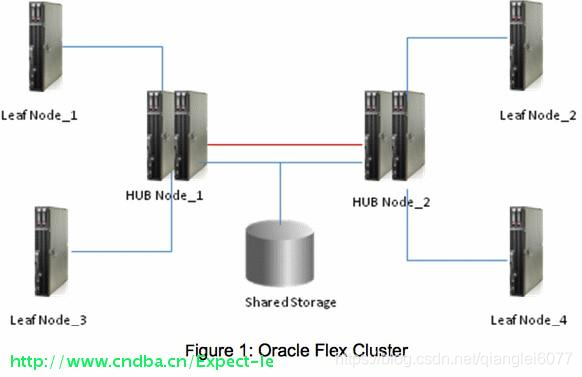
标准 Oracle Flex ASM 配置:
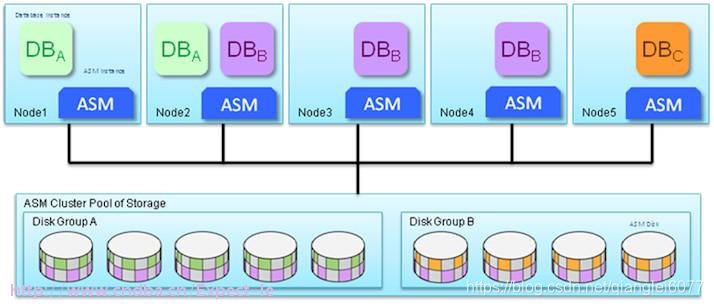
Oracle Flex ASM 配置上的 ASM 实例故障:

故障转移如何理解?
当作为集群的一部分的某hub node挂了,将发生什么?
当发生如下情况时,hub node会被从集群中移除:
-
被驱逐
-
服务器关机
-
手动停止Oracle集群件
这种情况发生时,连接着这个hub node的leaf node会自动挑一个活着的hub node来作为数据源。也就是说,如果hub node挂了,那么通过这个hub node访问集群的leaf node会自动切换至某存活的hub node继续访问集群。
Oracle RAC和Oracle cluster之间的关联是什么?他们之间有什么区别?集群和分布式之间的关联又是什么?节点的概念又是什么?
常见集群术语
服务硬件:指提供计算服务的硬件,比如 PC 机、PC 服务器。
服务实体:服务实体通常指服务软体和服务硬体。
节点的概念
节点(node):运行 Heartbeat 进程的一个独立主机称为节点,节点是 HA 的核心组成部分,每个节点上运行着操作系统和Heartbeat 软件服务。
资源(resource):资源是一个节点可以控制的实体,当节点发生故障时,这些资源能够被其他节点接管。如: 磁盘分区、文件系统、IP 地址、应用程序服务、共享存储
事件(event):事件也就是集群中可能发生的事情,例如节点系统故障、网络连通故障、网卡故障和应用程序故障等。这些事件都会导致节点的资源发生转移,HA 的测试也是基于这些事件进行的。
集群的概念
集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源,这些单个的计算机系统就是集群的节点(node)。集群提供了以下关键的特性。
(一) 可扩展性。集群的性能不限于单一的服务实体,新的服务实体可以动态的加入到集群,从而增强集群的性能。
(二) 高可用性。集群通过服务实体冗余使客户端免于轻易遭遇到“out of service”警告。当一台节点服务器发生故障的时候,这台服务器上所运行的应用程序将在另一节点服务器上被自动接管。消除单点故障对于增强数据可用性、可达性和可靠性是非常重要的。
(三) 负载均衡。负载均衡能把任务比较均匀的分布到集群环境下的计算和网络资源,以便提高数据吞吐量。
(四) 错误恢复。如果集群中的某一台服务器由于故障或者维护需要而无法使用,资源和应用程序将转移到可用的集群节点上。这种由于某个节点中的资源不能工作,另一个可用节点中的资源能够透明的接管并继续完成任务的过程叫做错误恢复。
分布式与集群的联系与区别
(一) 分布式是指将不同的业务分布在不同的地方。
(二) 而集群指的是将几台服务器集中在一起,实现同一业务。
(三) 分布式的每一个节点,都可以做集群,而集群并不一定就是分布式的。而分布式,从狭义上理解,也与集群差不多,但是它的组织比较松散,不像集群,有一定组织性,一台服务器宕了,其他的服务器可以顶上来。分布式的每一个节点,都完成不同的业务,一个节点宕了,这个业务就不可访问了。
集群主要分成三大类:
HA:高可用集群(High Availability Cluster)。
LBC:负载均衡集群/负载均衡系统(Load Balance Cluster)
HPC:科学计算集群(High Performance Computing Cluster)/高性能计算(High Performance Computing)集群。
为什么搭建数据库集群
随着经济的高速发展,企业规模的迅猛扩张,企业用户的数量、数据量的爆炸式增长,对数据库提出了严峻的考验。对于所有的数据库而言,除了记录正确的处理结果之外,还面临着以下几方面的挑战。
- l 如何提高处理速度,实现数据库的均衡负载。
- l 如何保证数据库的可用性、数据安全性、以及如何实现数据集群可扩性。
- l 怎么综合解决这些问题成为众多企业关注的焦点。
在数据库上,组建集群也是同样的道理,主要有以下几个原因:
(一) 伴随着企业的成长,业务量提高,数据库的访问量和数据量快速增长,其处理能力和计算速度也相应增大,使得单一的设备根本无法承担。
(二) 在以上情况下,若扔掉现有设备,做大量的硬件升级,势必造成现有资源的浪费,而且下一次业务量提升时,又将面临再一次硬件升级的高额投入。于是,人们希望通过几个中小型服务器组建集群,实现数据库的负载均衡及持续扩展;在需要更高数据库处理速度时,只要简单的增加数据库服务器就可以得到扩展。
(三) 数据库作为信息系统的核心,起着非常重要的作用,单一设备根本无法保证系统的下持续运行,若发生系统故障,将严重影响系统的正常运行,甚至带来巨大的经济损失。于是,人们希望通过组建数据库集群,实现数据库的高可用,当某节点发生故障时,系统会自动检测并转移故障节点的应用,保证数据库的持续工作。
(四) 企业的数据库保存着企业的重要信息,一些核心数据甚至关系着企业的命脉,单一设备根本无法保证数据库的安全性,一旦发生丢失,很难再找回来。于是,人们希望通过组建数据库集群,实现数据集的冗余,通过备份数据来保证安全性。
数据库集群的分类
数据库集群技术是将多台服务器联合起来组成集群来实现综合性能优于单个大型服务器的技术,这种技术不但能满足应用的需要,而且大幅度的节约了投资成本。数据库集群技术分属两类体系:基于数据库引擎的集群技术和基于数据库网关(中间件)的集群技术。在数据库集群产品方面,其中主要包括基于数据库引擎的集群技术的 Oracle RAC、Microsoft MSCS、IBM DB2UDB、Sybase ASE,以及基于数据库网关(中间件)的集群技术的 ICX-UDS 等产品。
一般来讲,数据库集群软件侧重的方向和试图解决的问题划分为三大类:
- l 负载均衡集群(Load Balance Cluster,LBC)侧重于数据库的横向扩展,提升数据库的性能。
- l 高可用性集群(High Availability Cluster,HAC)侧重保证数据库应用持续不断。大部分的数据库集群侧重与此。
- l 高安全性集群(High Security Cluster,HSC)侧重于容灾。
只有 Oracle RAC 能实现以上三方面
可扩展的分布式数据库架构(此处详述了Oracle RAC和集群之间的关系)
(一) Oracle RAC:
其架构的最大特点是共享存储架构(Shared-storage),整个 RAC 集群是建立在一个共享的存储设备之上的,节点之间采用高速网络互联。OracleRAC 提供了非常好的高可用特性,比如负载均衡和应用透明切块(TAF),其最大的优势在于对应用完全透明,应用无需修改便可切换到RAC 集群。但是RAC 的可扩展能力有限,首先因为整个集群都依赖于底层的共享存储,所以共享存储的 I/O 能力和可用性决定了整个集群的可以提供的能力,对于 I/O 密集型的应用,这样的机制决定后续扩容只能是 Scale up(向上扩展)类型,对于硬件成本、开发人员的要求、维护成本都相对比较高。Oracle显然也意识到了这个问题,在 Oracle 的 MAA(Maximum Availability Architecture)架构中,采用 ASM 来整合多个存储设备的能力,使得 RAC 底层的共享存储设备具备线性扩展的能力,整个集群不再依赖于大型存储的处理能力和可用性。
RAC 的另外一个问题是,随着节点数的不断增加,节点间通信的成本也会随之增加,当到某个限度时,增加节点可能不会再带来性能上的提高,甚至可能造成性能下降。这个问题的主要原因是 Oracle RAC 对应用透明,应用可以连接集群中的任意节点进行处理,当不同节点上的应用争用资源时,RAC 节点间的通信开销会严重影响集群的处理能力。所以对于使用 ORACLE RAC 有以下两个建议:
- l 节点间通信使用高速互联网络;
- l 尽可能将不同的应用分布在不同的节点上。
基于这个原因,Oracle RAC 通常在 DSS 环境(决策支持系统Decision Support System ,简称DSS)中可以做到很好的扩展性,因为 DSS 环境很容易将不同的任务分布在不同计算节点上,而对于 OLTP 应用(On-Line Transaction Processing联机事务处理系统),Oracle RAC 更多情况下用来提高可用性,而不是为了提高扩展性。
(二) MySQL Cluster
MySQL cluster 和 Oracle RAC 完全不同,它采用 无共享架构Shared nothing(shared nothing architecture)。整个集群由管理节点(ndb_mgmd),处理节点(mysqld)和存储节点(ndbd)组 成,不存在一个共享的存储设备。MySQL cluster 主要利用了 NDB 存储引擎来实现,NDB 存储引擎是一个内存式存储引擎,要求数据必须全部加载到内存之中。数据被自动分布在集群中的不同存 储节点上,每个存储节点只保存完整数据的一个分片(fragment)。同时,用户可以设置同一份数据保存在多个不同的存储节点上,以保证单点故障不会造 成数据丢失。MySQL cluster 主要由 3 各部分组成:
- l SQL 服务器节点
- l NDB 数据存储节点
- l 监控和管理节点
这样的分层也是与 MySQL 本身把 SQL 处理和存储分开的架构相关系的。MySQL cluster 的优点在于其是一个分布式的数据库集群,处理节点和存储节点都可以线性增加,整个集群没有单点故障,可用性和扩展性都可以做到很高,更适合 OLTP 应用。但是它的问题在于:
- l NDB(“NDB” 是一种“内存中”的存储引擎,它具有可用性高和数据一致性好的特点。) 存储引擎必须要求数据全部加载到内存之中,限制比较大,但是目前 NDB 新版本对此做了改进,允许只在内存中加 载索引数据,数据可以保存在磁盘上。
- l 目前的 MySQL cluster 的性能还不理想,因为数据是按照主键 hash 分布到不同的存储节点上,如果应用不是通过主键去获取数据的话,必须在所有的存储节点上扫描, 返回结果到处理节点上去处理。而且,写操作需要同时写多份数据到不同的存储节点上,对节点间的网络要求很高。
虽然 MySQL cluster 目前性能还不理想,但是 share nothing 的架构一定是未来的趋势,Oracle 接手 MySQL之后,也在大力发展 MySQL cluster,我对 MySQL cluster 的前景抱有很大的期待。
(三) 分布式数据库架构
MySQL 5 之后才有了数据表分区功能(Sharding), Sharding 不是一个某个特定数据库软件附属的功能,而是在具体技术细节之上的抽象处理,是水平扩展(Scale Out,亦或横向扩展、向外扩展)的解决方案,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。比如 Oracle 的 RAC 是采用共享存储机制,对于 I/O 密集型的应用,瓶颈很容易落在存储上,这样的机制决定后续扩容只能是 Scale Up(向上扩展) 类型,对于硬件成本、开发人员的要求、维护成本都相对比较高。Sharding 基本上是针对开源数据库的扩展性解决方案,很少有听说商业数据库进行 Sharding 的。目前业界的趋势基本上是拥抱 Scale Out,逐渐从 Scale Up 中解放出来。
Sharding 架构的优势在于,集群扩展能力很强,几乎可以做到线性扩展,而且整个集群的可用性也很高,部分节点故障,不会影响其他节点提供服务。Sharding 原理简单,容易实现,是一种非常好的解决数据库扩展性的方案。Sharding 并不是数据库扩展方案的银弹,也有其不适合的场景,比如处理事务型的应用它可能会造成应用架构复杂或者限制系统的功能,这也是它的缺陷所在。读写分离是架构分布式系统的一个重要思想。不少系统整体处理能力并不能同业务的增长保持同步,因此势必会带来瓶颈,单纯的升级硬件并不能一劳永逸。针对业务类型特点,需要从架构模式进行一系列的调整,比如业务模块的分割,数据库的拆分等等。集中式和分布式是两个对立的模式,不同行业的应用特点也决定了架构的思路。如互联网行业中一些门户站点,出于技术和成本等方面考虑,更多的采用开源的数据库产品(如 MYSQL),由于大部分是典型的读多写少的请求,因此为 MYSQL 及其复制技术大行其道提供了条件。而相对一些传统密集交易型的行业,比如电信业、金融业等,考虑到单点处理能力和可靠性、稳定性等问题,可能更多的采用商用数据库,比如 DB2、Oracle 等。就数据库层面来讲,大部分传统行业核心库采用集中式的架构思路,采用高配的小型机做主机载体,因为数据库本身和主机强大的处理能力,数据库端一般能支撑业务的运转,因此,Oracle 读写分离式的架构相对MYSQL 来讲,相对会少。读写分离架构利用了数据库的复制技术,将读和 写分布在不同的处理节点上,从而达到提高可用性和扩展性的目的。最通常的做法是利用 MySQL Replication 技术,Master DB 承担写操作,将数据变化复制到多台 Slave DB上,并承担读的操作。这种架构适合 read-intensive 类型的应用,通过增加 Slave DB 的数量,读的性能可以线性增长。为了避免 Master DB 的单点故障,集群一般都会采用两台 Master DB 做双机热备,所以整个集群的读和写的可用性都非常高。除了 MySQL,Oracle 从 11g 开始提供 Active Standby 的功能,也具备了实现读写分离架构的基础。读写分离架构的缺陷在于,不管是 Master 还是 Slave,每个节点都必须保存完整的数据,如 果在数据量很大的情况下,集群的扩展能力还是受限于单个节点的存储能力,而且对于 Write-intensive 类型的应用,读写分离架构并不适合。
采用 Oracle 读写分离的思路,Writer DB 和 Reader DB 采用日志复制软件实现实时同步; Writer DB 负责交易相关的实时查询和事务处理,Reader DB 负责只读接入,处理一些非实时的交易明细,报表类的汇总查询等。同时,为了满足高可用性和扩展性等要求,对读写端适当做外延,比如 Writer DB 采用 HA 或者 RAC 的架构模式,目前,除了数据库厂商的 集群产品以外,解决数据库扩展能力的方法主要有两个:数据分片和读写分离。数据分片(Sharding)的原理就是将数据做水平切分,类似于 hash 分区 的原理,通过应用架构解决访问路由和Reader DB 可以采用多套,通过负载均衡或者业务分离的方式,有效分担读库的压力。
对于 Shared-nothing 的数据库架构模式,核心的一个问题就是读写库的实时同步;另外,虽然 Reader DB只负责业务查询,但并不代表数据库在功能上是只读的。只读是从应用角度出发,为了保证数据一致和冲突考虑,因为查询业务模块可能需要涉及一些中间处理,如果需要在数据库里面处理(取决与应用需求和设计),所以Reader DB 在功能上仍然需要可写。下面谈一下数据同步的技术选型问题:
能实现数据实时同步的技术很多,基于 OS 层(例如 VERITAS VVR),基于存储复制(中高端存储大多都支持),基于应用分发或者基于数据库层的技术。因为数据同步可能并不是单一的 DB 整库同步,会涉及到业务数据选择以及多源整合等问题,因此 OS 复制和存储复制多数情况并不适合做读写分离的技术首选。基于日志的 Oracle 复制技术,Oracle 自身组件可以实现,同时也有成熟的商业软件。选商业的独立产品还是 Oracle 自身的组件功能,这取决于多方面的因素。比如团队的相应技术运维能力、项目投入成本、业务系统的负载程度等。
采用 Oracle 自身组件功能,无外乎 Logical Standby、Stream 以及 11g 的 Physical Standby(Active Data Guard),对比来说,Stream 最灵活,但最不稳定,11g Physical Standby 支持恢复与只读并行,但由于并不是日志的逻辑应用机制,在读写分离的场景中最为局限。如果技术团队对相关技术掌握足够充分,而选型方案的处理能力又能支撑数据同步的要求,采用 Oracle 自身的组件完全可行。选择商业化的产品,更多出于稳定性、处理能力等考虑。市面上成熟的 Oracle 复制软件也无外乎几种,无论是老牌的 Shareplex,还是本土 DSG 公司的 RealSync 和九桥公司的 DDS,或是 Oracle 新贵 Goldengate,都是可供选择的目标。随着 GoldenGate 被 Oracle 收购和推广,个人认为 GoldenGate 在容灾、数据分发和同步方面将大行其道。当然,架构好一个可靠的分布式读写分离的系统,还需要应用上做大量设计,不在本文讨论范围内。
(四) CAP 和 BASE 理论
分布式领域 CAP 理论:
- l Consistency(一致性), 数据一致更新,所有数据变动都是同步的
- l Availability(可用性), 好的响应性能
- l Partition tolerance(分区容错性) 可靠性
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
忠告:架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
关系数据库的 ACID 模型拥有 高一致性 + 可用性 很难进行分区:
- l Atomicity 原子性:一个事务中所有操作都必须全部完成,要么全部不完成。
- l Consistency 一致性. 在事务开始或结束时,数据库应该在一致状态。
- l Isolation 隔离层. 事务将假定只有它自己在操作数据库,彼此不知晓。
- l Durability. 一旦事务完成,就不能返回。
(五) 跨数据库事务
2PC (two-phase commit), 2PC is the anti-scalability pattern (Pat Helland) 是反可伸缩模式的,也就是说传统关系型数据库要想实现一个分布式数据库集群非常困难,关系型数据库的扩展能力十分有限。而近年来不断发展壮大的 NoSQL(非关系型的数据库)运动,就是通过牺牲强一致性,采用 BASE 模型,用最终一致性的思想来设计分布式系统,从而使得系统可以达到很高的可用性和扩展性。那么,有没有可能实现一套分布式数据库集群,既保证可用性和一致性,又可以提供很好的扩展能力呢?
BASE 思想的主要实现有按功能划分数据库 sharding 碎片BASE 思想主要强调基本的可用性,如果你需要 High 可用性,也就是纯粹的高性能,那么就要以一致性或容错性为牺牲,BASE 思想的方案在性能上还是有潜力可挖的。
- l 共同点:都是关系数据库 SQL 以外的可选方案,逻辑随着数据分布,任何模型都可以自己持久化,将数据处理和数据存储分离,将读和写分离,存储可以是异步或同步,取决于对一致性的要求程度。
- l 不同点:NOSQL 之类的 Key-Value 存储产品是和关系数据库头碰头的产品 BOX,可以适合非 Java 如 PHP RUBY等领域,是一种可以拿来就用的产品,而领域模型 + 分布式缓存 + 存储是一种复杂的架构解决方案,不是产品,但这种方式更灵活,更应该是架构师必须掌握的。
目前,已经有很多分布式数据库的产品,但是绝大部分是面向 DSS 类型的应用,因为相比较 OLTP 应用,DSS 应用更容易做到分布式扩展,比如基于 PostgreSQL 发展的 Greenplum,就很好的解决了可用性和扩展性的问题,并且提供了很强大的并行计算能力。对于 OLTP 应用,业务特点决定其要求:高可用性,一致性, 响应时间短,支持事务和 join 等等。数据库和 NoSQL当越来越多的 NoSQL 产品涌现出来,它们具备很多关系型数据库所不具备的特性,在可用性和扩展性方面都可以做到很好。
第一,NoSQL 的应用场景非常局限,某个类型的 NoSQL 仅仅针对特定类型的应用场景而设计。而关系型数据库则要通用的多,使用 NoSQL 必须搞清楚自己的应用场景是否适合。
第二,利用关系型数据库配合应用架构, 比如 Sharding 和读写分离技术,同样可以搭建出具备高可用和扩展性的分布式数据库集群。
第三,关系型数据库厂商依然很强大,全世界有大量的 用户,需求必然会推动新的产品问世。
第四,硬件的发展日新月异,比如闪存的技术的不断成熟,未来闪存可以作为磁盘与内存之间的 cache,或者完 全替代磁盘。而内存价格越来越低,容量越来越大,In-memory cache 或 database 的应用越来越广泛,可以给应用带来数量级的性能提升。数据库面临的 IO 问题将被极大改善。
Oracle RAC中的“双活”概念
简单来说,顾名思义,就是不止一个活着,而是至少有2个活着,对于数据库而言,就是两个节点都可以读写。
详情需要后续继续学习。
Oracle RAC中“心跳”的概念
RAC心跳分为3类,分别是网络心跳、磁盘心跳和本地心跳:
(1)网络心跳:所有节点每秒向其他所有节点发送信息确认对方是否“存活”。例如,在11.2版本以后,若某节点1超过30S未接受到某节点2的网络心跳应答,则节点1认为节点2“死亡”,节点1会发起对节点2的驱逐。
(2)磁盘心跳:所有节点每秒与所有的VD通信,读取VD的kill block信息判断自己是否需要重启,写入自己通过网络心跳了解到的集群信息到VD的OCR信息中。RAC 不允许任何节点与超过一半数目的VD失去访问:
1)若节点的网络心跳正常,RAC允许的VD超时时间为200S(LDTO)。若超过200S以后,节点不能访问的VD数目超过了总VD数目的一半,则节点需要被驱逐和重启。
2)若节点的网络心跳失败,RAC要求在27S(SDTO)内完成集群的重配置。
3)RAC对于VD也有相应的配置策略,要求配置N/2+1个VD,建议配置成奇数个。若某个VD长期不能被访问,RAC会将其踢出,使用冗余的VD。
(4)本地心跳:所有节点需要对自己进行监控,若判断自己无法正常工作将进行自我重启,并在重启前通知主控节点,将此集群变更信息广播出去。重启后,若节点判断自己能正常工作,则再向主控节点发送加入集群的请求。(集群任何时候都有一个节点担任主控节点)

















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









