







 本文介绍了如何使用Python和VSCode开发清华社外语助手,包括图像识别验证码、登录及语音题目的处理。通过二值化图像识别验证码,并对接第三方语音SDK进行口语评测。
本文介绍了如何使用Python和VSCode开发清华社外语助手,包括图像识别验证码、登录及语音题目的处理。通过二值化图像识别验证码,并对接第三方语音SDK进行口语评测。
注:博文代码功能已经集成到下面的小程序中了
清华社外语助手
先上结果图:
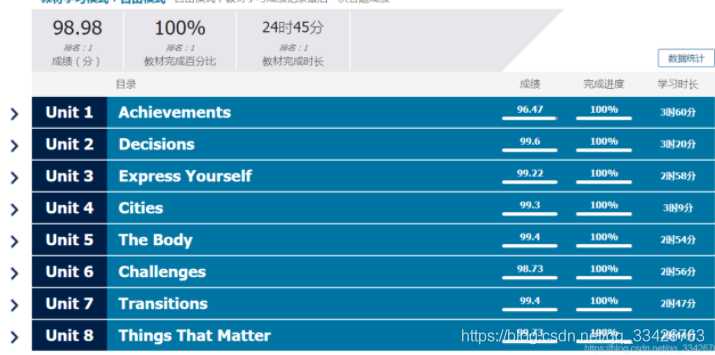
教程正文:
一、首先需要安装python运行环境,推荐下载python3.6以上,因为登录验证码识别库pil 需要用到levenstin 图像相似都对比,貌似低于3.5的版本不支持。安装时最好勾选添加python路径到系统,这样可以直接在命令行中调用。
二、下载Vscode 开发工具,安装python插件

python官网下载地址:
(https://www.python.org/downloads/)
三、复制代码到编辑器,保存为shuati.py 文件,ctrl+~ 调出命令行模式,输入 python shuati.py 即可自动完成题目
一、登录:
1.解决验证码:验证码基本都是像下面这样子
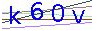
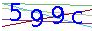

2.解决思路:可以看到中间加了其他颜色的干扰,但验证码本身以蓝色为主,可以对图像每个像素点获取其rgb色值,提取蓝色分量较大的色值,从而进行二值化,二值化后 提取每个象限的投影特征值,下面的代码中把背景色设为0,主题色设为1。
# !/usr/bin/env python3
# @Description : 清华社英语在线自动做题和时长
# @Author : wx ooooops0301
# @Email : 1846093422@qq.com
# @File : shuati.py
def OCR_lmj(imageData):
# image = Image.open(img_path) # 打开图片文件
image = Image.open(io.BytesIO(imageData))
# image = imageData
cols, rows = image.size # 90,30 cols:列数=90 rows:行数=30
data = np.zeros([rows, cols], dtype=int)
for i in range(0, rows):
for j in range(0, cols):
r, g, b = image.getpixel((j, i))
# print(r, g, b)
if r < 55 and g < 55 and b > 75:
data[i][j] = '1'
else:
data[i][j] = '0'
3.制作验证码字库0-9,a-z的不同方向的投影特征值,不同的截取规则,生成的字符特征值是不一样的,你需要根据自己的截取规则获取特征值。有了标准特征值,只需要对比每个字符与标准库里面哪个最相近,就可达到识别的目的。这里我把用到的字符都扒了下来,可以参考,其中有个别可能有两种,分别记录。
# !/usr/bin/env python3
# @Description : 清华社英语在线自动做题和时长
# @Author : wx ooooops0301
# @Email : 1846093422@qq.com
# @File : shuati.py
def search(data):
goalDatas = {
'0': ['0008e84444448e8000000', '486444444444444684'],
'1': ['00004444ii22220000000', '4642222222222222aa'],
'2': ['000566666688a60000000', '6a53222232222233bb'],
'3': ['000224666667ca4000000', '6922222167322234a6'],
'4': ['0035556554hh222000000', '343444444444dd222'],
'5': ['0002ba666688a60000000', '992222784322223497'],
'6': ['0008dc9866688a6000000', '584322798755546785'],
'7': ['000223678787520000000', 'bb2232222322223222'],
'8': ['0008e8a6666a8e8000000', '6a64444688644446a6'],
'9': ['0006a8866689cd8000000', '587645557897223485'],
'a': ['00467566667ba00000000', '672227a5457a7'],
'a_1': ['00477666667ca00000000', '69322895457a7'],
'b': ['000ii6444446695000000', '222227a754444457a7'],
'c': ['005954444444000000000', '5842222222475'],
'd': ['005966444446ii0000000', '222227a754444457a7'],
'e': ['005986666666640000000', '58544cc222396'],
'f': ['0022gh444400000000000', '452228822222222222'],
'g': ['005988666679gf0000000' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









