







kubernetes集群日志收集ELK
ELK,分别指Elastic公司的Elasticsearch、Logstash、Kibana。在比较旧的ELK架构中,Logstash身兼日志的采集、过滤两职。但由于Logstash基于JVM,性能有一定限制,因此,目前业界更推荐使用Go语言开发FIiebeat代替Logstash的采集功能,Logstash只作为了日志过滤的中间件。
ELK架构

角色功能如下:
- 多个Filebeat在各个业务端进行日志采集,然后上传至Logstash
- 多个Logstash节点并行(负载均衡,不作为集群),对日志记录进行过滤处理,然后上传至Elasticsearch集群
- 多个Elasticsearch构成集群服务,提供日志的索引和存储能力
- Kibana负责对Elasticsearch中的日志数据进行检索、分析
根据业务特点,还可以加入某些中间件,如Redis、Kafak等:

Kafka集群作为消息缓冲队列,可以降低大量FIlebeat对Logstash的并发访问压力。
日志采集方式
使用ELK+Filebeat架构,还需要明确Filebeat采集K8S集群日志的方式。
方式1:Node级日志代理
在每个节点(即宿主机)上可以独立运行一个Node级日志代理,通常的实现方式为DaemonSet。用户应用只需要将日志写到标准输出,Docker 的日志驱动会将每个容器的标准输出收集并写入到主机文件系统,这样Node级日志代理就可以将日志统一收集并上传。另外,可以使用K8S的logrotate或Docker 的log-opt 选项负责日志的轮转。

Docker默认的日志驱动(LogDriver)是json-driver,其会将日志以JSON文件的方式存储。所有容器输出到控制台的日志,都会以*-json.log的命名方式保存在/var/lib/docker/containers/目录下。对于Docker日志驱动的具体介绍,请参考官方文档。另外,除了收集Docker容器日志,一般建议同时收集K8S自身的日志以及宿主机的所有系统日志,其位置都在var/log下。
所以,简单来说,本方式就是在每个node上各运行一个日志代理容器,对本节点/var/log和 /var/lib/docker/containers/两个目录下的日志进行采集,然后汇总到elasticsearch集群,最后通过kibana展示。
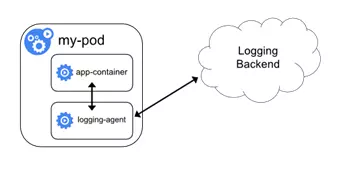
方式2:伴生容器(sidecar container)作为日志代理
创建一个伴生容器(也可称作日志容器),与应用程序容器在处于同一个Pod中。同时伴生容器内部运行一个独立的、专门为收集应用日志的代理,常见的有Logstash、Fluentd 、Filebeat等。日志容器通过共享卷可以获得应用容器的日志,然后进行上传。
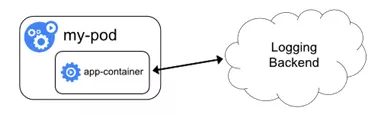
方式3:应用直接上传日志
应用程序容器直接通过网络连接上传日志到后端,这是最简单的方式。
对比

相对来说,方式1在业界使用更为广泛,并且官方也更为推荐。因此,最终我们采用ELK+Filebeat架构,并基于方式1,如下:

部署
目前相关的文件已经上传github直接可以下载用:
部署文件下载
git clone https://github.com/hkj123/kubernetes-elk.git
cd kubernetes-elk
创建 logging namespace
kubectl apply -f logging-namespace.yaml
kubectl 基本操作命令总结
创建service
kubectl create -f service.yaml
查看创建的service当后端代理的pod的ip
get endpoints my-service
查找目录下的所有文件中是否含有某个字符串
find .|xargs grep -ri "xxxx"
更新对象
kubectl replace -f <filename|url>
删除对象
kubectl delete -f <filename|url>
浏览对象
kubectl get -f <filename|url> -o yaml
加载对象
kubectl apply -f <filename|url>
查看名称空间
kubectl get namespaces
查看创建的service
kubectl get svc --all-namespaces
kubectl describe pod name
查看目前所有的deployment
kubectl get deployment --all-namespaces
kubectl describe deployment name
查看目前所有的replica set
kubectl get rs --all-namespaces
kubectl describe rs name
查看目前所有的pod
kubectl get pods --all-namespaces
kubectl describe pod name
查看具体的日志
kubectl --namespace=logging logs name
kubectl logs name
部署elastisearch
# 本次部署虽然使用 StatefulSet 但是没有使用pv进行持久化数据存储
# pod重启之后,数据会丢失,生产环境一定要使用pv持久化存储数据
# 部署elasticsearch
kubectl apply -f elasticsearch.yaml
# 查看状态
kubectl get pods,svc -n logging -o wide
[root@saas98 ~]$ kubectl get pod --namespace=logging
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-0 1/1 Running 0 3d23h
elasticsearch-logging-1 1/1 Running 0 3d23h
# 等待所有pod变成running状态
# 访问测试
# 如果测试都有数据返回代表部署成功
kubectl run curl -n logging --image=radial/busyboxplus:curl -i --tty
nslookup elasticsearch-logging
curl 'http://elasticsearch-logging:9200/_cluster/health?pretty'
curl 'http://elasticsearch-logging:9200/_cat/nodes'
exit
# 清理测试
kubectl delete deploy curl -n logging
部署kibana
# 部署
kubectl apply -f kibana.yaml
# 查看状态
kubectl get pods,svc -n logging -o wide
[root@saas98 ~]$ kubectl get pod --namespace=logging
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-0 1/1 Running 0 3d23h
elasticsearch-logging-1 1/1 Running 0 3d23h
kibana-logging-5df7d57b77-wmm2d 1/1 Running 0 3d23h
部署filebeat收集日志
# 部署
kubectl apply -f filebeat.yaml
[root@saas98 ~]$ kubectl get pod --namespace=logging
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-0 1/1 Running 0 3d23h
elasticsearch-logging-1 1/1 Running 0 3d23h
filebeat-kjvxb 1/1 Running 0 2d5h
filebeat-rm426 1/1 Running 0 2d5h
filebeat-sbhzz 1/1 Running 0 2d5h
filebeat-whrxq 1/1 Running 0 2d5h
kibana-logging-5df7d57b77-wmm2d 1/1 Running 0 3d23h
kibana查看日志
创建index fluentd-*,由于需要拉取镜像启动容器,可能需要等待几分钟才能看到索引和数据



参考
https://blog.csdn.net/java_zyq/article/details/82179175
https://www.jianshu.com/p/604a7149a632















 4805
4805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









