







一、在k8s部署elk
1.1 准备镜像
先在dockers官网下载sebp/elk:622镜像,并将其上传到harbor仓库中。
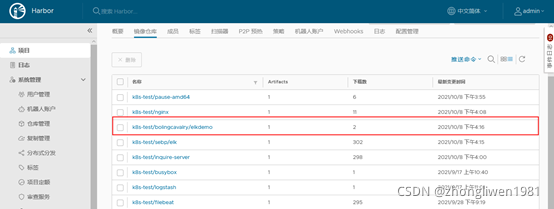
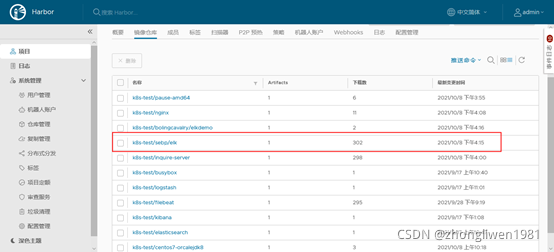 官方提供了elkdemo用于测试elk服务,这里也将其下载并上传到本地Harbor仓库中。
官方提供了elkdemo用于测试elk服务,这里也将其下载并上传到本地Harbor仓库中。
1.2 部署服务
1.2.1 部署elkhost
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: elkhost
spec:
replicas: 1
template:
metadata:
labels:
name: elkhost
spec:
containers:
- name: elkhost
image: sebp/elk:622
tty: true
ports: [{
"containerPort": 5601
}, {
"containerPort": 5044
}]
---
apiVersion: v1
kind: Service
metadata:
name: elkhost-kibana
spec:
type: NodePort
ports:
- port: 5601
nodePort: 30001
selector:
name: elkhost
---
apiVersion: v1
kind: Service
metadata:
name: elkhost
spec:
type: ClusterIP
ports:
- port: 5044
targetPort: 5044
selector:
name: elkhost
kibana默认使用5601端口号,logstash默认使用5044端口号。
1.2.2 部署elkdemo
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: elkdemo
spec:
replicas: 1
template:
metadata:
labels:
name: elkdemo
spec:
containers:
- name: elkdemo
image: elkdemo:0.0.1-SNAPSHOT
tty: true
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: elkdemo
spec:
type: NodePort
ports:
- port: 8080
nodePort: 30002
selector:
name: elkdemo准备好部署文件后,开始执行部署:
kubectl apply –f elkhost.yaml
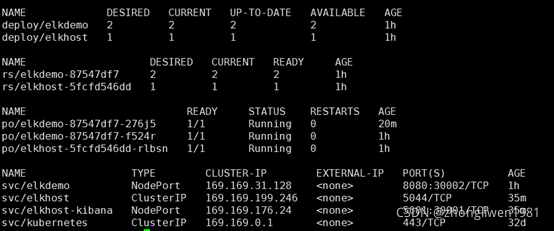
kubectl apply –f elkdemo.yaml部署效果如下:
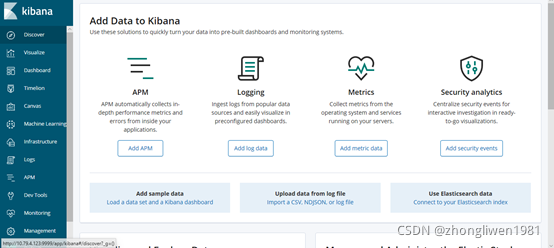
部署完成后,在浏览器输入:http://k8s-node:30001,效果如下图所示:
 在浏览器输入
在浏览器输入http://k8s-node:30002/hello/tom,效果如下所示:

1.3 配置kibana
重新点击Discover菜单栏,这时候会看到Kibana检测到了filebeat开头的索引。这是因为elkdemo容器中已经集成了filebeat组件,该组件会监控容器下web项目的日志变化。
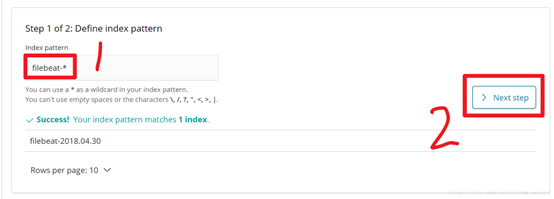
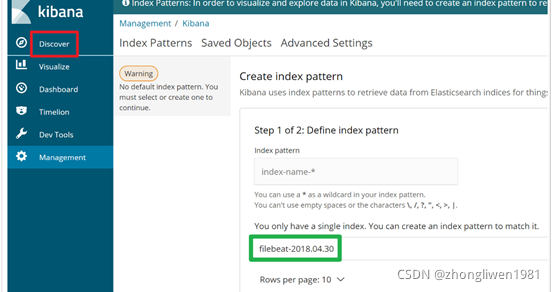 这时候在Index pattern输入框输入“filebeat-*”,然后点击“Next step”按钮。
这时候在Index pattern输入框输入“filebeat-*”,然后点击“Next step”按钮。
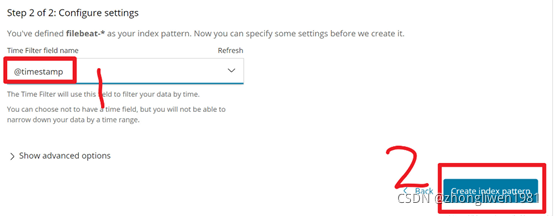
最后选择@timestamp,然后点击“Create Index pattern”按钮即可。
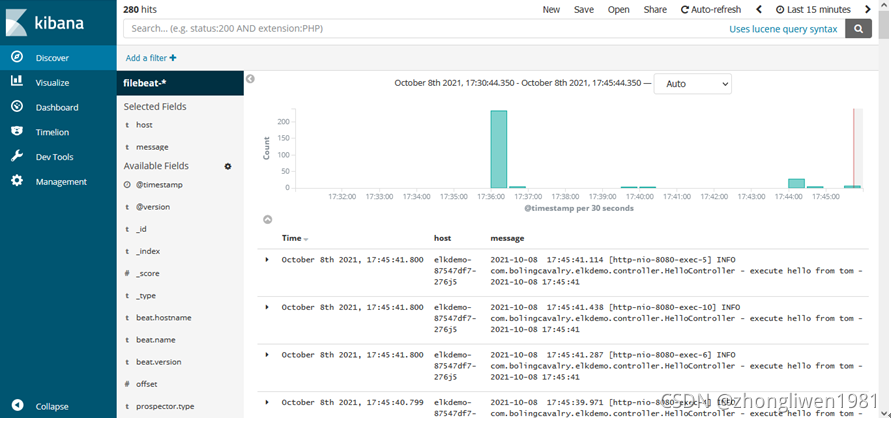
最终效果:
二、在主机上安装elk
2.1 安装Elasticsearch
先下载elasticsearch-6.6.0压缩包并解压缩。因为安全问题,不能将elasticsearch解压缩在/root目录下,所以这里解压缩项目到/usr/local目录下。另外,也不能以root运行./elasticsearch,需要先创建一个用户。
第一步:创建一个用户并指定用户组;
groupadd esgroup
useradd es -g esgroup -p es第二步:更改elasticsearch目录的所属用户;
chown -R es:esgroup elasticsearch-7.0.0第三步:切换es用户;
su es2.2 配置elasticsearch
修改elasticsearch.yml文件,分别修改network.host和bootstrap.memory_lock参数。
network.host: 0.0.0.0
bootstrap.memory_lock: false修改/etc/sysctl.conf配置文件,设置vm的最大内存书。
vi /etc/sysctl.conf
vm.max_map_count=262144执行sysctl -p使配置生效后,启动elasticsearch服务:
bin/elasticsearch -d启动后,在浏览器上输入http://[ip]:9200,效果如下所示:
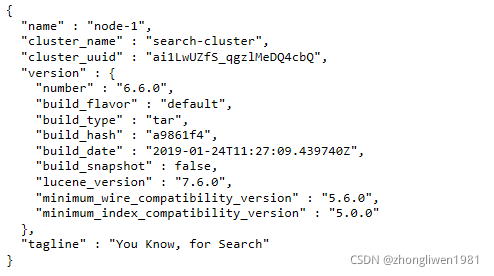
上面ip为安装elasticsearch软件所在主机的ip地址。
2.2 安装logstash
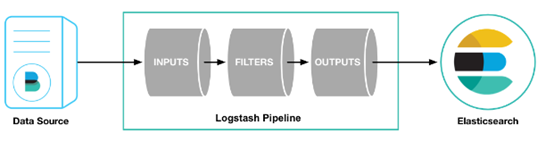
logstash pipeline 包含两个必须的元素:input和output,和一个可选元素:filter。Input代表输入数据来源,filter负责对数据进行解析处理,output代表将处理后数据输出到指定目标,比如Elasticsearch。
Logstash的安装步骤:
第一步:下载logstash-6.6.0压缩包,并解压缩到/usr/local目录下;
第二步:进入config目录,修改logstash.conf配置文件;
input {
beats {
port => 5044
}
}
filter {
grok {
patterns_dir => "/usr/local/patterns/"
match => {
"message" => "%{TOMCAT_DATESTAMP:timestamp}\[%{DATA:req_id}\]\[%{USER_ID:USER_ID}\]\[%{DATA:thread_name}\]%{LOGLEVEL:level}%{SPACE}*-%{SPACE}*%{JAVACLASS:logger_name}%{SPACE}*-%{SPACE}*%{GREEDYDATA:logmessage}"
}
remove_field => ["tags","beat","host","prospector","offset","log","@version","@timestamp","source","input","message","agent"]
}
date {
match => ["timestamp","yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
}
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*3600)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
rename => { "logmessage" => "message" }
remove_field => ["timestamp"]
}
}
output{
elasticsearch {
hosts => ["eshost:9200"]
index => "tomcat-%{+YYYY-MM-dd}"
document_type => "tomcat"
user => "es"
password => "es123"
}
}上面eshost应该替换成elasticsearch所在主机的ip地址。另外,编辑/usr/local/patterns/java文件,配置logstach模式。
REQUEST_ID (\w+((\s|\.|\-|\_){1}\w+)+)|\w?
USER_ID \d+|\d?
APPTYPE [a-zA-Z]+|\w?
VERSION \d+(\.{1}\d+)+|\d?
DEVICE_ID (\w+(\-{1}\w+)+)|\w?
DEVICE_TYPE (\w+((\s|\,|\-){1}\w+)+)|\w?
TOMCATLOG %{TOMCAT_DATESTAMP:timestamp} \[%{REQUEST_ID:req_id}\] \[%{USER_ID:USER_ID}\] \[%{APPTYPE:APPTYPE}\] \[%{VERSION:VERSION}\] \[%{DEVICE_ID:DEVICE_ID}\] \[%{DEVICE_TYPE:DEVICE_TYPE}\] \[%{JAVATHREAD:thread}\]-%{LINE:line} %{LOGLEVEL:level} %{JAVACLASS:class} -%{JAVALOGMESSAGE:logmessage}在实际开发中,需要先对Grok模式进行有效性验证。这里可以使用kibana自带的开发工具进行验证。
 样例数据可以在pod容器日志中获取。这里值得注意的是,需要将样例数据使用英文双引号包含起来。
样例数据可以在pod容器日志中获取。这里值得注意的是,需要将样例数据使用英文双引号包含起来。
填入Grok模式后,点击“模拟”按钮。如果匹配成功,那么在下面会显示匹配到的样例数据。
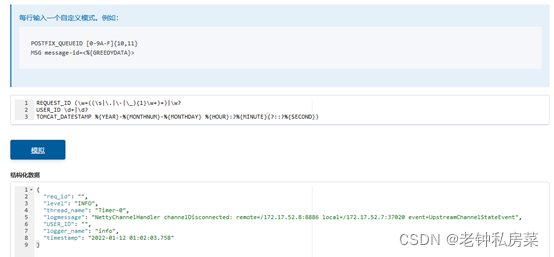
第三步:启动logstash服务;
nohup ./bin/logstash -f ./config/logstash.conf &
tail -f ./logs/logstash-plain.log2.3 安装kibana
第一步:下载kibana-6.6.0压缩包并解压缩;
第二步:进入config目录,编辑kibana.yml文件;
server.port: 5601
server.host: “0.0.0.0”
elasticsearch.hosts: ["http://[ip]:9200"]上面ip地址修改为elasticsearch所在主机的地址。
第三步:启动服务;
nohup ./bin/kibana &启动成功后,在浏览器上输入http://[主机IP]:5601,效果如下图所示:

三、ELK监控项目日志
3.1 重新生成filebeat镜像
第一步:先下载filebeat压缩包;
第二步:编写Dockerfile文件,使用filebeat.yml配置文件启动filebeat服务;
FROM centos7-orcalejdk8:v1
WORKDIR /usr/local
ADD filebeat-7.15.0-linux-x86_64.tar.gz .
RUN ln -s filebeat-7.15.0-linux-x86_64 filebeat \
&& cd filebeat \
&& mkdir config \
&& chmod +x filebeat \
&& cp filebeat.yml config/
ENTRYPOINT ["/usr/local/filebeat/filebeat","-c","/usr/local/filebeat/config/filebeat.yml"]第三步:生成新的filebeat镜像;
docker build -t filebeat:7.15.0 .3.2 编写filebeat.yml
第一步:编写filebeat.yml文件;
filebeat.inputs:
- type: log
enabled: true
paths:
- /log/*.log
multiline.pattern: ^[0-9]{4}-[0-9]{2}
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ["ip:5044"]
setup.template.enabled: false上面指定filebeat监控/log目录下所有以.log结尾文件的变化。
第二步:根据上面文件生成configmap;
kubectl create cm filebeat-config --from-file=filebeat.yml3.3 修改web部署文件
增加filebeat容器的配置:
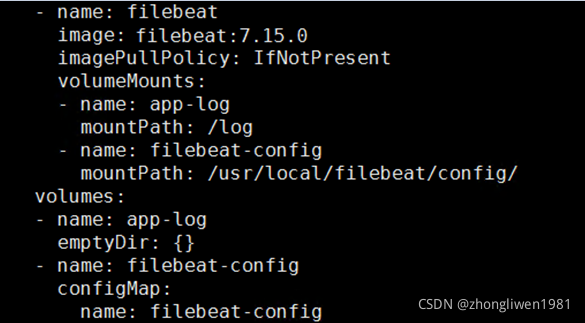
上面最后一行filebeat-config为configmap名称。完整的配置内容如下:
apiVersion: v1
kind: ReplicationController
metadata:
name: web
namespace: default
spec:
replicas: 1
selector:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: web
image: web:v1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: app-log
mountPath: /logs
- name: filebeat
image: filebeat:7.15.0
imagePullPolicy: IfNotPresent
volumeMounts:
- name: app-log
mountPath: /log
- name: filebeat-config
mountPath: /usr/local/filebeat/config/
volumes:
- name: app-log
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
---
apiVersion: v1
kind: Service
metadata:
name: web
namespace: default
spec:
selector:
app: web
type: ClusterIP
ports:
- port: 8080
targetPort: 8080由于web项目的日志文件保存在容器的/log目录下。所以将通过app-log配置将web和filebeat都绑定在同一个数据卷中,这样能够实现web容器中保存日志的/log目录与filebeat容器中/log目录之间的映射。
最后,执行部署即可。到目前为止,已经完成了elk的部署和安装。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









