







分布式计算平台Spark:Core(二)
一、重点
-
Spark集群环境
-
开发流程:SparkCore、SparkSQL、SparkStreaming
- step1:在IDEA中开发代码
- 基于本地模式测试代码逻辑
- step2:打成jar放入HDFS
- 为什么要放入HDFS存储
- 需要实现在任何一台机器提交代码,都可以读取到对应的jar包
- step3:通过调度工具来进行自动化调度运行
- step1:在IDEA中开发代码
-
集群环境
-
Standalone
-
YARN
-
提交程序到集群
-
spark-submit
- 用法:spark-submit 【option】 < jar 包 | Python文件> 【args】
- 选项
- –master:指定master地址,指定运行模式
- local:本地模式
- spark://hostname:7077:Standalone集群模式
- yarn:yarn集群模式
- ……
- –class:指定运行jar包中的哪一个类
- –deploy-mode:指定driver的client或者cluster模式
- –conf:临时修改或者定义属性的
- 资源属性
- driver:负责初始化
- –driver-mem
- executor:负责Task的运行
- CPU:–executor-core
- 每个Task需要1coreCPU来运行这个task
- Mem:–executor-mem
- RDD每次构建数据的时候
- RDD的缓存数据
- Shuffle过程中需要用内存
- CPU:–executor-core
- YARN:指定executor的个数
- –num-executors
- Standalone:指定executor的个数
- –total-executor-nums
- driver:负责初始化
- –master:指定master地址,指定运行模式
-
命令
spark-submit \ --master --class --driver-mem --exeuctor-mem hdfs://node1:8020/xxx.jar args
-
-
–deploy-mode
- 功能:决定了driver这个进程启动在什么位置
- driver进程
- executor进程:启动在从节点【Worker、NodeManger】
- 类型
- client:默认类型,driver运行在客户端的机器上
- 问题:导致客户端机器的负载过高以及driver故障率变高,影响程序的运行
- cluster:将driver运行在从节点【Worker、NodeManger】中
- 工作中要使用的模式
- 举个栗子:区分客户端和服务端
- 服务端:Linux:MySQL-server
- 客户端:Windows:Navicat
- client:默认类型,driver运行在客户端的机器上
- 功能:决定了driver这个进程启动在什么位置
-
Driver与Executor进程的功能
- Driver:申请资源、解析代码变成Task任务、调度、监控
- Executor:运行Task
-
Spark on YARN模式下:deploy-mode
- client:driver与APPMaster进程都存在,但是分工不一样
- 资源申请由AppMaster来实现
- cluster:driver与appmaster合并的
- client:driver与APPMaster进程都存在,但是分工不一样
-
-
代码开发
- RDD:数据结构抽象:弹性分布式数据集
- 弹性:数据可以放在内存中,如果内存不足,利用磁盘来实现缓存
- 分布式:数据分布式存储在不同机器上的集合
- 任何一种分布式:分区:Partition
- HDFS:文件:分块机制:每128M
- 副本机制
- HBASE:表:Region:Rowkey的范围
- WAL+副本
- Kafka:Topic:Partition:根据Key的Hash取余/轮询/指定分区/自定义分区规则
- 副本机制
- HDFS:文件:分块机制:每128M
- 任何一种分布式:分区:Partition
- 数据集:理解为类似于Scala中的集合概念
- 五个特征
- 每个RDD都由一些列的分区构成
- 每个操作都会对分区并行执行
- 每个RDD都会记录着与其他RDD的依赖关系:血脉
- 可选的:对于二元组类型的RDD可以选择分区的规则
- 可选的:所有RDD的计算处理,计算最优路径解【本地优先计算】
- 创建
- 原则:所有数据读到SPark程序中都会变成RDD
- 分布式计算一般数据来源:分布式存储
- 方式一:并行化一个Scala集合
- 方式二:读取外部数据源:HDFS/Hbase/Hive/kafka
- 原则:所有数据读到SPark程序中都会变成RDD
- 函数:算子
- 转换算子:返回一个新的RDD
- 执行模式是Lazy模式,并不会直接调用Task执行转换,等待触发算子的触发
- 定义了转换的逻辑:返回一个新的RDD
- 常见:map、flatMap、filter、reduceByKey
- 触发算子:触发一个job运行
- 当需要调用RDD中的数据时候,就会触发
- 常见:saveTextFile、foreach、take(N)、top(N)、count、first
- 转换算子:返回一个新的RDD
- RDD:数据结构抽象:弹性分布式数据集
-
-
反馈问题
-
关于Seq以及英文熟练度
-
代码
val list = List(1,2,3,……) val seq = Seq(1,2,3……) / 1.to(10) / 1 to 10
-
-
有些代码在Executor中执行,有些代码是在Driver中执行的,有什么区别
-
Driver:运行所有代码:逻辑计划
-
一个:内存在一台机器上,内存比较小
-
普通类型的实例
-
解释了:为了top只能用于小数据,而且top没有走shuffle就是实现全局排序
- top将RDD的分布式数据全部放到了driver中做排序
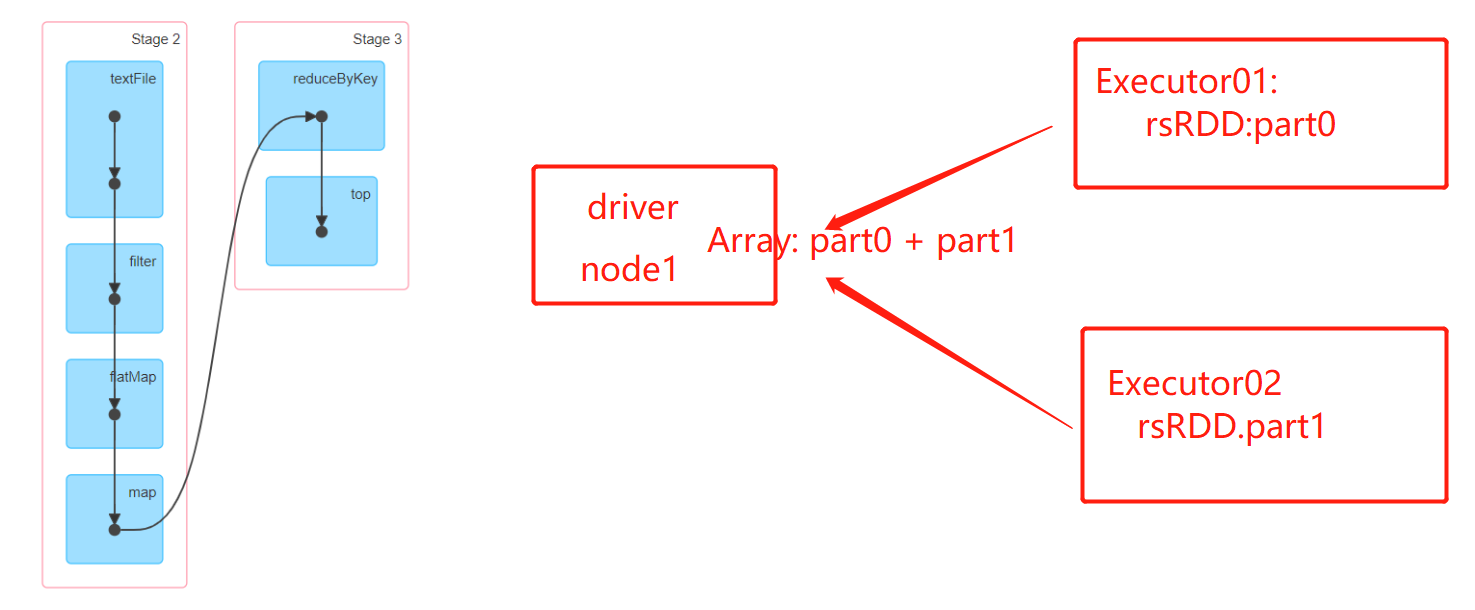
-
-
Executor:Task:物理计划
- 多个:分布式内存
- RDD的数据:分布式存储和分布式计算
-
-
二、概要
- RDD中的常用函数
- 熟练的使用各种函数:函数的功能
- 了解函数的用法
- RDD的容错机制
- 血脉
- 缓存
- 持久化
- 日志分析案例
- 搜狗日志:分词来实现统计
- RDD函数的应用
- SparkCore中的常用数据源
- HBASE:读写HBASE
- MySQL:读写MySQL
三、RDD常用函数
1、分区操作函数
-
函数:map、foreach
-
功能:取集合中每个元素来调用参数来处理
(1 to 10).toList.map(x => x*2) -
区别:map有返回值,foreach没有返回值
-
map
def map[U: ClassTag](f: T => U)
-
-
mapPartitions
- 功能:取RDD的每个分区的数据来进行处理,有返回值
-
foreachPartition
- 功能:取RDD的每个分区的数据来进行处理,没有返回值
-
应用于用法
-
用法
-
mapPartitions
def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U]) Iterator[T]:RDD的每个分区 -
foreachParition
def foreachPartition(f: Iterator[T] => Unit)) Iterator[T]:RDD的每个分区 -
与直接使用map和foreach的结果是一致的,没有区别
-
-
应用场景:如果需要对数据处理过程中构建资源的时候
- map、foreach:基于每一个元素构建一个资源
- mapPartitions、foreachPartition:基于每一个分区来构建一个资源
-
举个栗子:将结果写入MySQL
- 资源的使用不一样
rsRdd .foreach(tuple => { //todo:1-申明驱动 Class.forName("com.mysql.jdbc.Driver") //todo:2-构建连接对象:只要有一个KV,就构建一次连接 val conn = DriverManager.getConnection("") }) rsRdd .foreachPartition(part => { //todo:1-申明驱动 Class.forName("com.mysql.jdbc.Driver") //todo:2-构建连接对象:一个分区构建一次 val conn = DriverManager.getConnection("") //迭代分区的数据 part.foreach(tuple => { //直接赋值 }) })
-
-
代码实现
package bigdata.it.cn.spark.scala.function import java.sql.DriverManager import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext, TaskContext} /** * @ClassName SparkCoreSimpleMode * @Description TODO 演示分区操作函数:基于每个分区进行操作 * @Date 2020/12/12 17:58 * @Create By Frank */ object SparkCorePartitionOptFunction { def main(args: Array[String]): Unit = { /** * step1:初始化SparkContext */ val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // println(s"这是类名:${this.getClass.getSimpleName}") val sc = new SparkContext(conf) sc.setLogLevel("WARN") /** * step2:数据处理逻辑开发 */ //todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") // println(inputRdd.first()) // inputRdd.collect() //todo:2-数据处理 val rsRdd: RDD[(String, Int)] = inputRdd .filter(line => null != line && line.trim.length > 0) .flatMap(line => line.split("\\s+")) // .map(word => (word,1)) //对RDD的每个分区来调用参数函数进行处理 .mapPartitions(part => { //对每个分区中的每个元素再进行处理 part.map(word => (word,1)) }) .reduceByKey(_+_) //todo:3-保存结果 rsRdd.foreachPartition(part => { println(s"${TaskContext.getPartitionId()}") //得到每个分区,对每个分区的数据进行打印 part.foreach(println) }) rsRdd .foreach(tuple => { //todo:1-申明驱动 Class.forName("com.mysql.jdbc.Driver") //todo:2-构建连接对象:只要有一个KV,就构建一次连接 val conn = DriverManager.getConnection("") }) rsRdd .foreachPartition(part => { //todo:1-申明驱动 Class.forName("com.mysql.jdbc.Driver") //todo:2-构建连接对象:一个分区构建一次 val conn = DriverManager.getConnection("") //迭代分区的数据 part.foreach(tuple => { //直接赋值 }) }) // rsRdd.saveAsTextFile("/datas/output/wordcount/wc-"+System.currentTimeMillis()) /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
2、重分区函数
-
功能:调整RDD的分区个数,增加、减少
-
问题:每个RDD的分区默认的规则不适合实际的使用
- 读取数据源
- HDFS:block = 分区
- HBASE:region = 分区
- Kafka :分区 = 分区
- 转换得到的:子RDD的分区数 = 父RDD的分区数
- 读取数据源
-
应用场景
-
增加分区个数的场景
- Spark读HBASE:inputRdd的分区个数 = HBASE表region的个数
- 3个Region,每个Region有50万条数据
- 这个RDD有3个分区,每个分区由50万条数据
- 一个分区 = 一个Task = 1CoreCPU
- 需求:根据数据量合理的调整RDD的分区个数,来将数据分布到更多的分区中,提高并行度
- 每个Task处理5万的数据最快的
- 将RDD的分区个数调整为30个分区,每个分区的数据为5万条
- Spark读HBASE:inputRdd的分区个数 = HBASE表region的个数
-
减少分区个数的场景
-
如果读取的数据很大:读取1GB文件
inputRdd :10个分区 -
经过聚合转换:最后得到的结果RDD,也有10个分区,但可能只有3条结果数据
rsRdd:至少有7个分区的数据是空的 -
保存结果时,没有必要保留空的分区,根据数据量降低分区个数为1
-
-
-
repartition:用于调整分区的个数,一般用于调大分区个数
-
定义
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { coalesce(numPartitions, shuffle = true) } -
本质还是调用了coalesce来实现的,但是开启了shuffle
-
-
coalesce:用于调整分区的个数,一般用于降低分区个数
-
定义
- 第一个参数表示新的RDD分区个数,第二个参数表示是否经过shuffle过程
def coalesce(numPartitions: Int, shuffle: Boolean = false)
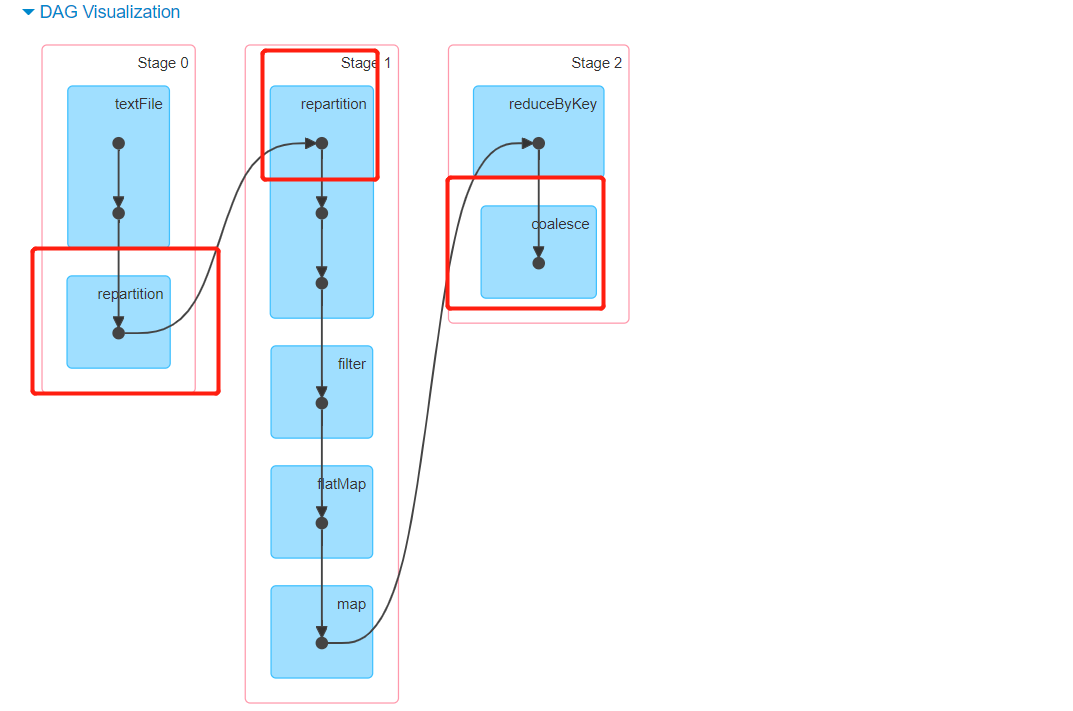
-
设计原因
- repartition:也可以降低分区个数,但是它会走shuffle,一般不用于降低分区个数
- coalesce:也可以提高分区个数,但是必须开启shuffle
-
为什么走shuffle才能提高分区个数,不走shuffle可以降低分区个数?
-
调大分区
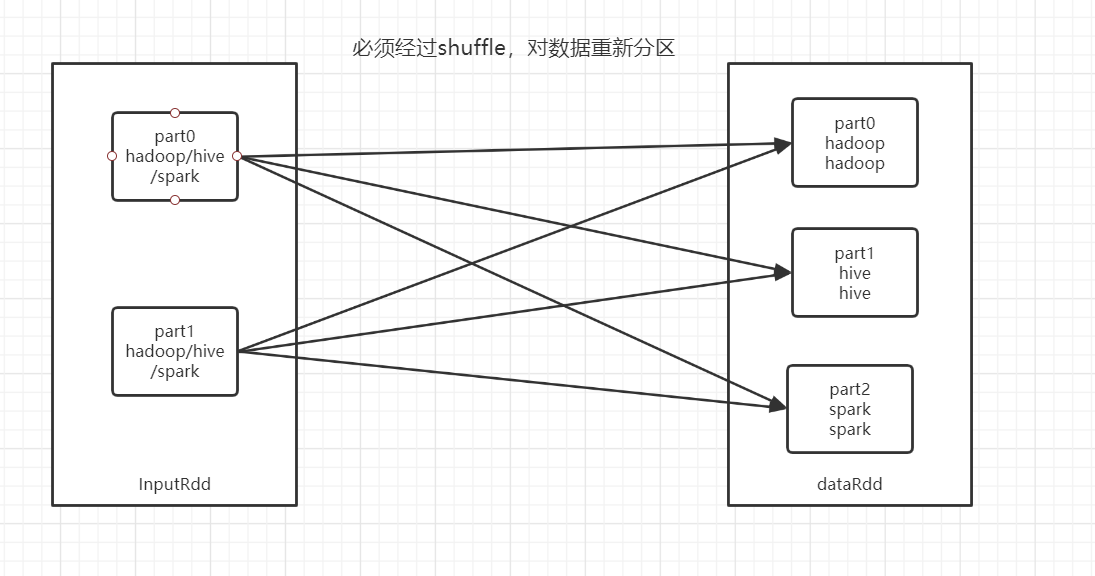
-
调小分区
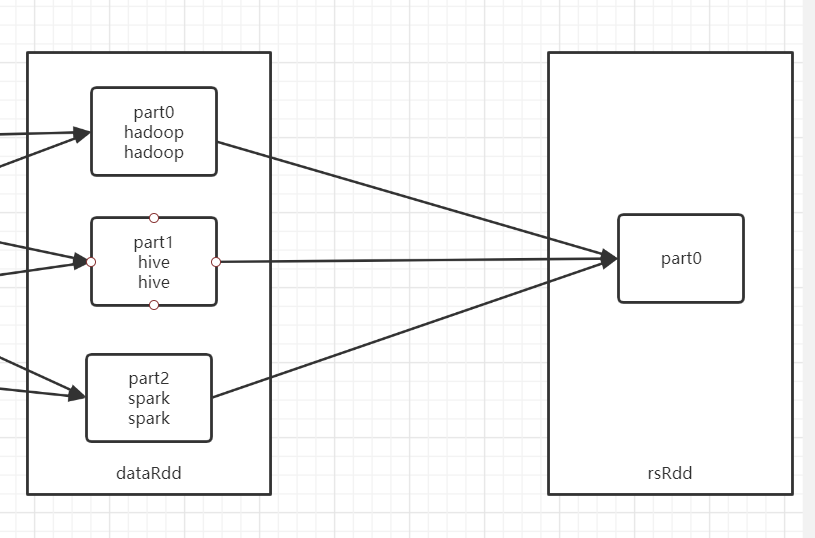
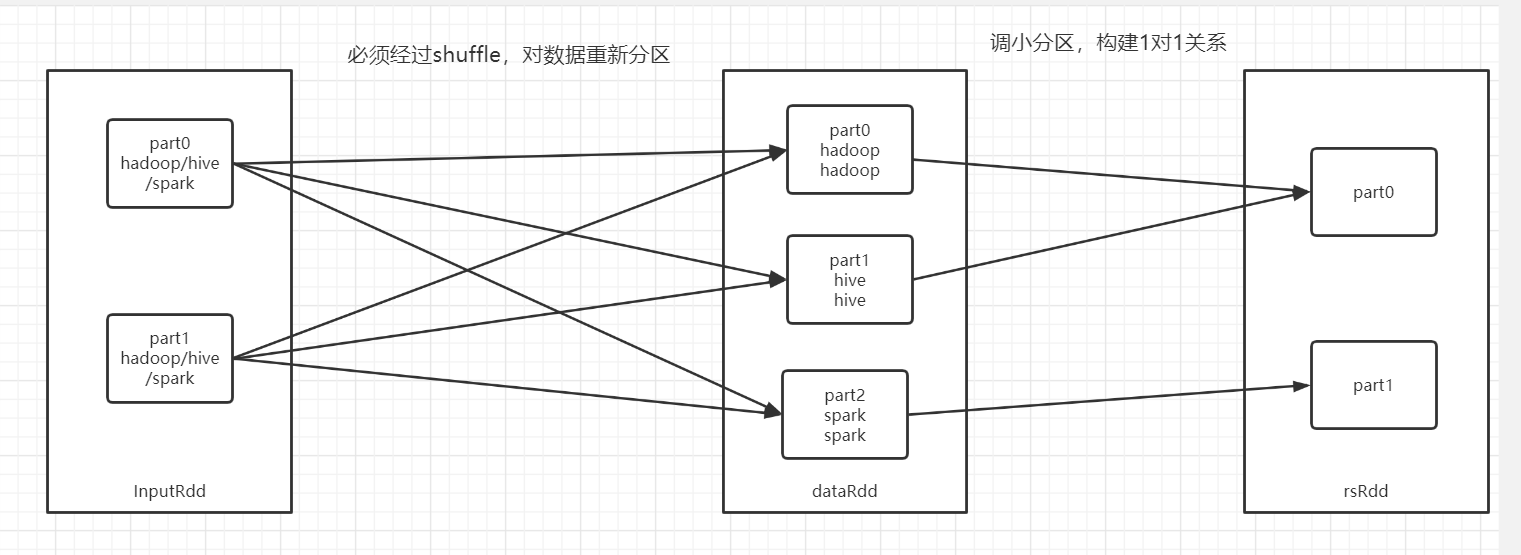
-
-
partitionBy:自定义分区
-
-
代码实现
package bigdata.it.cn.spark.scala.function import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext, TaskContext} /** * @ClassName SparkCoreSimpleMode * @Description TODO 实现调整RDD的分区个数:repartition、coalesce * @Date 2020/12/12 17:58 * @Create By Frank */ object SparkCoreRepartitionFunction { def main(args: Array[String]): Unit = { /** * step1:初始化SparkContext */ val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // println(s"这是类名:${this.getClass.getSimpleName}") val sc = new SparkContext(conf) sc.setLogLevel("WARN") /** * step2:数据处理逻辑开发 */ //todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") println(s"inputRdd part numb = ${inputRdd.partitions.length}") // println(inputRdd.first()) //todo:2-数据处理 //todo:如果每个分区的数据量过大,需要增加分区的个数,来提高并行度,提高效率 val dataRdd: RDD[String] = inputRdd.repartition(3) println(s"dataRdd part numb = ${dataRdd.partitions.length}") //对分区数比较多的RDD做并行处理 val rsRdd: RDD[(String, Int)] = dataRdd .filter(line => null != line && line.trim.length > 0) .flatMap(line => line.split("\\s+")) .map(word => (word,1)) .reduceByKey(_+_) //todo:3-保存结果 rsRdd //结果数据比较少,没必要用多个分区来运行处理,降低分区个数 .coalesce(1) .foreachPartition(part => { println(s"当前的分区编号为:${TaskContext.getPartitionId()}") part.foreach(tuple => { println(tuple._1+"\t"+tuple._2) }) }) // rsRdd.saveAsTextFile("/datas/output/wordcount/wc-"+System.currentTimeMillis()) /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
3、聚合函数
-
聚合的设计:挨个聚合,将每次聚合的结果保存在临时变量中,再用临时变量与其他元素进行聚合
-
分布式聚合中:先做每个分区的聚合【并行】,最后将所有分区的结果再进行总的聚合
-
reduce:聚合逻辑是一致的
- 实现每个分区的先聚合,分区间最后的结果再聚合
-
fold:聚合逻辑是一致的
-
注意:初始值会在分区内和分区间计算时,重复构建
part = 1 tmp = 1 item = 6 part = 1 tmp = 7 item = 7 part = 1 tmp = 14 item = 8 part = 1 tmp = 22 item = 9 part = 1 tmp = 31 item = 10 part = 0 tmp = 1 item = 1 part = 0 tmp = 2 item = 2 part = 0 tmp = 4 item = 3 part = 0 tmp = 7 item = 4 part = 0 tmp = 11 item = 5 part = 0 tmp = 1 item = 41 part = 0 tmp = 42 item = 16 58
-
aggregate:聚合函数,分区内的聚合与分区间的聚合逻辑是分开定义的
- reduce和fold有一个共同的特点:分区内的聚合逻辑与分区间的聚合逻辑是一致的
- 如果我想实现,分区内的处理逻辑与分区间的处理逻辑不一样怎么办?
- 需求:统计1到10之间最大的两个元素
- 实现:思路:将每个元素进行比较,每次保留最大的两个元素
part = 1 tmp = ListBuffer() item = 6 part = 1 tmp = ListBuffer(6) item = 7 part = 1 tmp = ListBuffer(6, 7) item = 8 part = 1 tmp = ListBuffer(7, 8) item = 9 part = 1 tmp = ListBuffer(8, 9) item = 10 part = 0 tmp = ListBuffer() item = 1 part = 0 tmp = ListBuffer(1) item = 2 part = 0 tmp = ListBuffer(1, 2) item = 3 part = 0 tmp = ListBuffer(2, 3) item = 4 part = 0 tmp = ListBuffer(3, 4) item = 5 part = 0 tmp1 = ListBuffer() item = ListBuffer(9, 10) part = 0 tmp1 = ListBuffer(9, 10) item = ListBuffer(4, 5) -
代码测试
package bigdata.it.cn.spark.scala.function import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext, TaskContext} import scala.collection.immutable import scala.collection.mutable.ListBuffer /** * @ClassName SparkCoreMode * @Description TODO Spark Core 中常用聚合函数:reduce、fold、aggregate * @Date 2020/12/17 9:32 * @Create By Frank */ object SparkCoreAggregateFunction { def main(args: Array[String]): Unit = { /** * step1:初始化一个SparkContext */ //构建配置对象 val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") //构建SparkContext的实例,如果存在,直接获取,如果不存在,就构建 val sc = SparkContext.getOrCreate(conf) //调整日志级别 sc.setLogLevel("WARN") /** * step2:实现数据的处理过程:读取、转换、保存 */ //todo:1-读取 //Scala集合 val list: immutable.Seq[Int] = (1 to 10).toList //Spark集合 val listRdd: RDD[Int] = sc.parallelize(list) //todo:2-转换 /** * todo:reduce * def reduce(f: (T, T) => T): T * 先做分区内的聚合,最后做分区间的聚合 */ //集合reduce // val list1 = list.reduce((tmp,item) => { // //打印每次临时变量和元素变量的值 // println(s"tmp = ${tmp} item = ${item}") // //实现每个元素的聚合 // tmp+item // }) // println(list1) // val listRdd1 = listRdd.reduce((tmp,item) => { // //打印每次临时变量和元素变量的值 // println(s"part = ${TaskContext.getPartitionId()} tmp = ${tmp} item = ${item} ") // //实现每个元素的聚合 // tmp+item // }) // println(listRdd1) /** * todo:fold * def fold(zeroValue: T)(op: (T, T) => T):有初始值 * 先做分区内的聚合,最后做分区间的聚合 * 注意:初始值在每次分区内计算和分区间计算时,会被重复构建 * */ // val list2 = list.fold(1)((tmp,item) => { // //打印每次临时变量和元素变量的值 // println(s"tmp = ${tmp} item = ${item}") // //实现每个元素的聚合 // tmp+item // }) // println(list2) // val listRdd2 = listRdd.fold(1)((tmp,item) => { // //打印每次临时变量和元素变量的值 // println(s"part = ${TaskContext.getPartitionId()} tmp = ${tmp} item = ${item} ") // //实现每个元素的聚合 // tmp+item // }) // println(listRdd2) /** * todo:aggregate * def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U * zeroValue: U:初始值,临时变量的默认值 * seqOp: (U, T) => U:分区内的聚合逻辑 * combOp: (U, U) => U:分区间的聚合逻辑 * 需求:取集合中最大的两个元素 */ listRdd.aggregate(new ListBuffer[Int])( //第一个函数:分区内的聚合:将每个分区中最大的两个元素取出:第一个参数就是临时变量,第二个参数是集合中的元素 (tmp,item) => { //打印 println(s"part = ${TaskContext.getPartitionId()} tmp = ${tmp} item = ${item} ") //将集合中的每个元素放入临时的变量中 tmp += item //返回最大的两个值 tmp.sorted.takeRight(2) }, //第二个函数:分区间的聚合:将所有分区的聚合的结果再次聚合:第一个参数是临时变量,第二个参数是每个分区的结果 (tmp1,tmp2) => { println(s"part = ${TaskContext.getPartitionId()} tmp1 = ${tmp1} tmp2 = ${tmp2} ") //将每个分区的结果进行合并 tmp1 ++= tmp2 //取合并以后的最大的两个元素 tmp1.sorted.takeRight(2) } ) //todo:3-保存 /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
4、二元组函数
-
特征:xxxByKey函数
- PairRddFunction
-
groupByKey:按照Key进行分组,将Value放入一个迭代器中
def groupByKey(): RDD[(K, Iterable[V])] -
reduceByKey/foldByKey:按照Key分组并对Value做聚合,分区内与分区间的聚合逻辑是一致的
def reduceByKey(func: (V, V) => V): RDD[(K, V)]- 与reduce的用法是一致的,先按Key做分组
- 尽量能用reduceByKey或者aggregateByKey实现分组聚合,就不要用groupByKey,再聚合
- 原因
- groupByKey的问题:只做分组,没有聚合,最后会产生所有数据在一个迭代器对象中,容易导致内存溢出
- 直接将所有数据分组聚合
- reduceByKey:先对每个分区做分组聚合,最后做所有分区结果的分组聚合
- groupByKey的问题:只做分组,没有聚合,最后会产生所有数据在一个迭代器对象中,容易导致内存溢出
- 原因
-
aggregateByKey:按照Key分组并对Value做聚合,分区内与分区间的聚合逻辑是可以分开定义
-
sortByKey:按照Key实现排序
-
测试代码
package bigdata.it.cn.spark.scala.function import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreSimpleMode * @Description TODO :groupByKey,reduceByKey,aggregateByKey * @Date 2020/12/12 17:58 * @Create By Frank */ object SparkCorePairRDDFunction { def main(args: Array[String]): Unit = { /** * step1:初始化SparkContext */ val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // println(s"这是类名:${this.getClass.getSimpleName}") val sc = new SparkContext(conf) sc.setLogLevel("WARN") /** * step2:数据处理逻辑开发 */ //todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") // println(inputRdd.first()) //todo:2-数据处理 val rsRdd = inputRdd .filter(line => null != line && line.trim.length > 0) .flatMap(line => line.split("\\s+")) .map(word => (word,1)) //todo:groupByKey:按照Key进行分组,将相同Key对象的所有value放入一个迭代中 // .groupByKey() // .map(tuple => { // val word = tuple._1 // //取出单词对应的所有的value进行求和 // val numb = tuple._2.sum // (word,numb) // }) //todo:reduceByKey/foldByKey:按照key分组然后对Value聚合 // .reduceByKey(_+_) //todo:aggregateByKey .aggregateByKey(0)( (tmp,item) => tmp+item, (tmp1,tmp2) => tmp1 + tmp2 ) //todo:3-保存结果 rsRdd.foreach(tuple => println(tuple._1+"\t"+tuple._2)) // rsRdd.saveAsTextFile("/datas/output/wordcount/wc-"+System.currentTimeMillis()) /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
5、关联函数
-
join/leftJoin/rightJoin
-
join函数只能用于二元组类型的函数:按照Key来实现关联Join
-
定义
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))] RDD[(K, V)].join(RDD[(K, W)]) def rightOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (Option[V], W))]
-
-
代码测试
package bigdata.it.cn.spark.scala.function import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreMode * @Description TODO Spark Core 实现两个RDD的join关联 * @Date 2020/12/17 9:32 * @Create By Frank */ object SparkCoreRddJoin { def main(args: Array[String]): Unit = { /** * step1:初始化一个SparkContext */ //构建配置对象 val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") //构建SparkContext的实例,如果存在,直接获取,如果不存在,就构建 val sc = SparkContext.getOrCreate(conf) //调整日志级别 sc.setLogLevel("WARN") /** * step2:实现数据的处理过程:读取、转换、保存 */ //todo:1-读取 val empRdd: RDD[String] = sc.textFile("datas/hive/emp.txt") val deptRdd: RDD[String] = sc.textFile("datas/hive/dept.txt") //todo:2-转换 //将数据变成二元组类型的RDD //emp表:<deptno,ename> val empJoinRdd: RDD[(String, String)] = empRdd .map(line => { val arr = line.trim.split("\t") //deptno,ename (arr(7),arr(1)) }) //dept表:<deptno,dname> val deptJoinRdd = deptRdd .map(line => { val arr = line.trim.split("\t") (arr(0),arr(1)) }) //join结果:ename detpno dname val joinRdd: RDD[(String, (String, String))] = empJoinRdd.join(deptJoinRdd) // joinRdd.foreach{ case (deptno,(ename,dname)) => println(ename+"\t"+deptno+"\t"+dname) tuple => println(tuple._2._1+tuple._1+tuple._2._2) // } //def rightOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (Option[V], W))] val rightJoinRdd: RDD[(String, (Option[String], String))] = empJoinRdd.rightOuterJoin(deptJoinRdd) rightJoinRdd.foreach{ case (deptno,(ename:Option[String],dname)) => println(ename.getOrElse(null)+"\t"+deptno+"\t"+dname) } //todo:3-保存 /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
6、函数练习
-
常用的函数练习
-
mapValues:二元组类型的函数,用于专门对Value进行处理,Key不变
- 一般用于一对一的Value获取、Value的转换
四、RDD容错机制
1、问题
-
RDD的数据是由Task运行时构建在内存中,如果我在转换时,这个RDD的数据丢失了一个分区的数据怎么办?
val inputRdd = sc.textFile val filterRdd = inputRdd.filter val flatMapRdd = filterRdd.flatMap- 如果Rdd的数据丢失:根据血脉关系,可以重新构建所有数据
-
有一个RDD在两个Job中都会被使用到,在第一个job运行时,会构建这个RDD的数据,当job1结束以后,数据也被释放,job2必须重新构建,导致资源浪费以及性能问题
rsRdd.foreach(tuple => println(tuple._1+"\t"+tuple._2)) rsRdd.first() -
解决方案:不需要每次都重新构建,可以RDD缓存在内存
- 根据你的需求,自己选择性的决定是否缓存这个数据
2、容错机制:Persist
-
功能:根据需求,开发者可以自己选择将RDD进行缓存,缓存在内存中,当下次使用该RDD的数据时,直接从缓存中获取对应的数据
-
使用
-
缓存
-
cache
def cache(): this.type = persist() -
persist
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) -
StorageLevel:缓存级别
val NONE = new StorageLevel(false, false, false, false) //将数据只缓存在磁盘中,2代表缓存两份 val DISK_ONLY = new StorageLevel(true, false, false, false) val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) //将数据只缓存在内存中,2代表缓存两份,ser代表序列化 val MEMORY_ONLY = new StorageLevel(false, true, false, true) val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) //优先将数据缓存在内存,如果内存不足,将剩余的数据缓存在磁盘中 val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) //将数据缓存在堆外内存,机器的物理内存 val OFF_HEAP = new StorageLevel(true, true, true, false, 1)-
默认级别:MEMORY_ONLY
-
常用的方案
MEMORY_AND_DISK_2 MEMORY_AND_DISK_SER_2
-
-
-
设置缓存
rdd.persist(StorageLevel) -
释放缓存
-
unpersist
rdd.unpersist()
-
-
-
注意事项:缓存用完,一定要记得释放缓存
-
测试程序
package bigdata.it.cn.spark.scala.function import org.apache.spark.rdd.RDD import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreSimpleMode * @Description TODO 实现缓存数据 * @Date 2020/12/12 17:58 * @Create By Frank */ object SparkCoreWordCountPersist { def main(args: Array[String]): Unit = { /** * step1:初始化SparkContext */ val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // println(s"这是类名:${this.getClass.getSimpleName}") val sc = new SparkContext(conf) sc.setLogLevel("WARN") /** * step2:数据处理逻辑开发 */ //todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") // println(inputRdd.first()) //todo:2-数据处理 val rsRdd: RDD[(String, Int)] = inputRdd .filter(line => null != line && line.trim.length > 0) .flatMap(line => line.split("\\s+")) .map(word => (word,1)) .reduceByKey(_+_) //由于这个RDD会被使用多次,进行缓存 // rsRdd.cache() //将数据缓存在内存中,如果内存不足,使用磁盘 rsRdd.persist(StorageLevel.MEMORY_AND_DISK_SER) //todo:3-保存结果 rsRdd.foreach(tuple => println(tuple._1+"\t"+tuple._2)) rsRdd.first() // rsRdd.saveAsTextFile("/datas/output/wordcount/wc-"+System.currentTimeMillis()) /** * step3:释放资源 */ Thread.sleep(1000000L) //释放缓存 rsRdd.unpersist() sc.stop() } }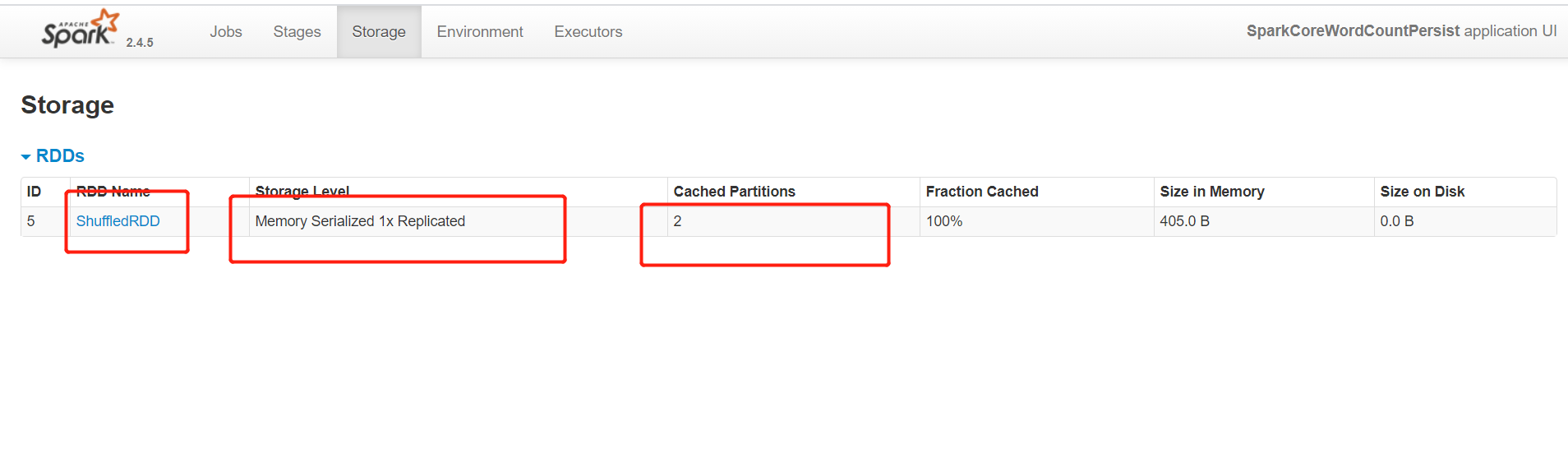

-
应用场景
- 情况1:这个RDD被使用多次
- 情况2:这个RDD是经过非常复杂的转换得到的,使用1次以上
-
问题:对RDD做了persist缓存,这个缓存的数据也在内存中,如果缓存的数据丢失了,怎么办?
- Spark会根据血脉,重新构建这个缓存
3、容错机制:Checkpoint
-
功能:将RDD数据永久性的存储在HDFS上,以后使用RDD的数据时,直接从HDFS中读取对应的数据即可
-
使用
-
step1:先设置一个checkpoint的目录,用于存储RDD的数据
- 工作中这是一个HDFS目录
//设置checkpoint的目录,用于存储rdd的数据 sc.setCheckpointDir("datas/checkpoint") -
step2:在代码中设置对RDD进行checkpoint
//todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") //todo:2-数据处理 //设置将这个RDD的数据进行存储 inputRdd.checkpoint()
-
-
代码测试
package bigdata.it.cn.spark.scala.function import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreSimpleMode * @Description TODO 使用RDD数据的永久性存储 * @Date 2020/12/12 17:58 * @Create By Frank */ object SparkCoreWordCountCheckPoint { def main(args: Array[String]): Unit = { /** * step1:初始化SparkContext */ val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // println(s"这是类名:${this.getClass.getSimpleName}") val sc = new SparkContext(conf) sc.setLogLevel("WARN") //设置checkpoint的目录,用于存储rdd的数据 sc.setCheckpointDir("datas/checkpoint") /** * step2:数据处理逻辑开发 */ //todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") //todo:2-数据处理 //设置将这个RDD的数据进行存储 inputRdd.checkpoint() //todo:3-保存结果 println( inputRdd.first()) println(inputRdd.count()) /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } } -
监控
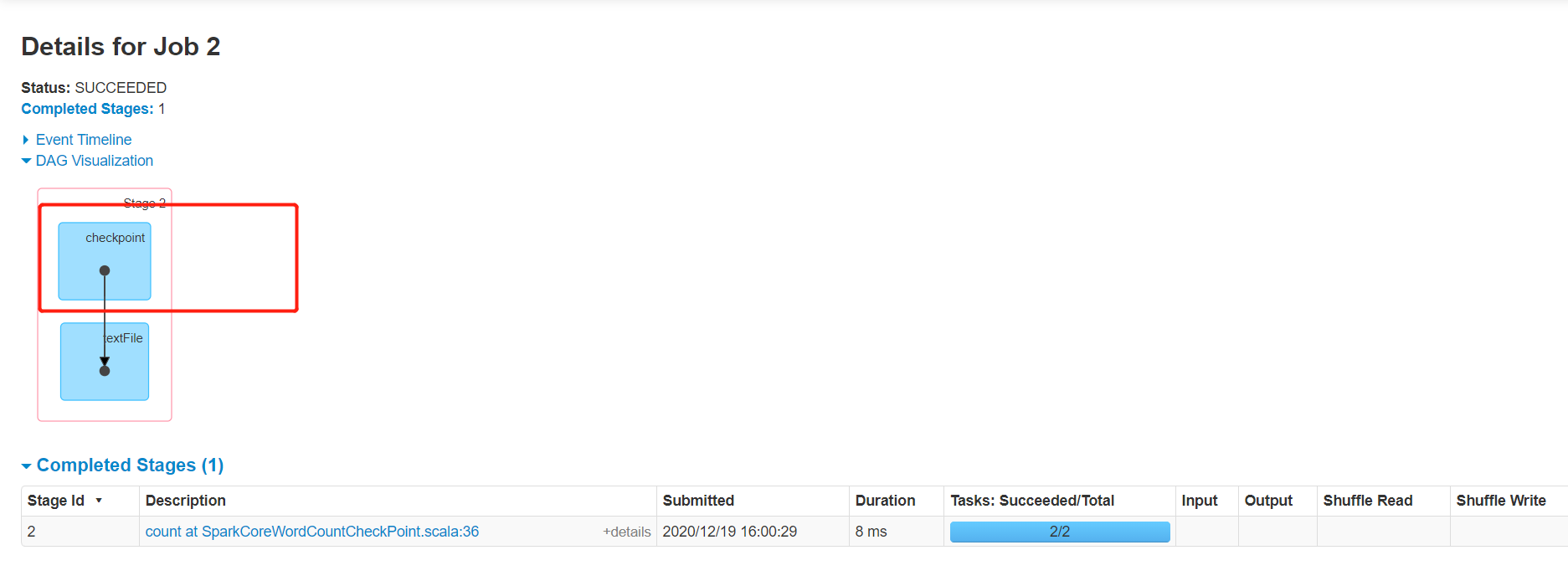
4、依赖关系
- persist与checkpoint的区别
- 存储位置
- persist:内存
- checkpoint:HDFS
- 生命周期
- persist:当程序执行结束,释放缓存
- checkpoint:这个数据,除非手动删除,不然一直存在
- 存储位置
- 血脉的存储
- persist:会记录RDD依赖关系
- checkpoint:只记录RDD的数据
五、搜狗日志分析
1、业务需求
-
数据:一天24个小时的用户搜索数据
访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL -
需求一:统计热门搜索词Top10
- 统计搜索次数出现最多的前10个关键词
- 先分词,然后对分词的结果做词频统计
-
需求二:统计用户搜索的最多点击次数、最少点击次数、平均点击次数
- step1:先按照每个用户每次搜索来分组,得到每个用户每次搜索的点击次数
- step2:最大值、最小值、平均值
-
需求三:统计每个小时的PV数
- 将小时取出,分组统计个数
2、分词设计
package bigdata.it.cn.spark.test.hanlp
import java.util
import com.hankcs.hanlp.HanLP
import com.hankcs.hanlp.seg.common.Term
import scala.collection.immutable
/**
* @ClassName HanLPTest
* @Description TODO HanLp工具类解析测试
* @Date 2020/12/19 16:21
* @Create By Frank
*/
object HanLPTest {
def main(args: Array[String]): Unit = {
//调用分词的方法
val terms1: util.List[Term] = HanLP.segment("我爱中国共产党,汶川地震原因")
//转换Scala集合
import scala.collection.JavaConverters._
val terms2: immutable.Seq[Term] = terms1.asScala.toList
//打印每个词
terms2.foreach(term => println(term.word))
}
}
3、需求实现
package bigdata.it.cn.spark.scala.sougou
import com.hankcs.hanlp.HanLP
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* @ClassName SparkCoreMode
* @Description TODO Spark Core实现搜狗数据分析
* @Date 2020/12/17 9:32
* @Create By Frank
*/
object SparkCoreSogouCase {
def main(args: Array[String]): Unit = {
/**
* step1:初始化一个SparkContext
*/
//构建配置对象
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
//构建SparkContext的实例,如果存在,直接获取,如果不存在,就构建
val sc = SparkContext.getOrCreate(conf)
//调整日志级别
sc.setLogLevel("WARN")
/**
* step2:实现数据的处理过程:读取、转换、保存
*/
//todo:1-读取
val inputRdd: RDD[String] = sc.textFile("datas/sogou/SogouQ.reduced")
//todo:2-转换
/**
* todo:ETL:解析文件中的每一行,过滤非法数据,将每一行数据封装为SogouRecord对象
*/
val etlRDD: RDD[SogouRecord] = inputRdd
//过滤长度不合法或者空的数据
.filter(line => null != line && line.trim.split("\\s+").length == 6)
//将每行分割,封装到样例类中
.mapPartitions(part =>{
//对每个分区进行处理
part.map(line => {
//先分割
val arr = line.trim.split("\\s+")
//返回:00:00:00 8561366108033201 [汶川地震原因] 3 2 www.big38.net/
SogouRecord(
arr(0),
arr(1),
arr(2).replaceAll("\\[|\\]",""),
arr(3).toInt,
arr(4).toInt,
arr(5)
)
})
})
//etl的结果需要被使用多次,进行缓存
etlRDD.persist(StorageLevel.MEMORY_AND_DISK_SER)
/**
* todo:需求一:统计热门搜索词Top10
*/
val rs1 = etlRDD
//过滤,搜索词不能为空
.filter(item => item.queryWords != null && item.queryWords.trim.length > 0)
//将每个搜索词变成二元组:(word,1),由于做分词,一个搜索词可能被分成很多个词,需要降维
.flatMap( item => {
//分词
val terms = HanLP.segment(item.queryWords)
//转为Scala集合
import scala.collection.JavaConverters._
//将每个term对象取出word构建二元组
terms.asScala.toList.map(term => (term.word,1))
})
//统计每个词出现的次数
.reduceByKey(_+_)
//排序
.sortBy(tuple => tuple._2,false)
//取前10
// .take(10)
// rs1.foreach(println)
/**
* todo:需求二:统计用户搜索的最多点击次数、最少点击次数、平均点击次数
* 思路:先求出每个用户在每次搜索中的点击次数
*/
val rs2: RDD[Int] = etlRDD
//构建每个用户的每次搜索,每点击一次,就计1,对用户和搜素词分组聚合即可
.map(item => {
//Key:用户和搜索词,value就是1
((item.userId,item.queryWords),1)
})
//分组聚合,得到每个用户在每次搜索时的点击次数
.reduceByKey(_+_)
//获取value
.map(tuple => tuple._2)
// println(s"max click num = ${rs2.max()}")
// println(s"min click num = ${rs2.min()}")
// println(s"avg click num = ${rs2.mean()}")
/**
* todo:需求三:统计每个小时的PV数,按照PV降序排序
*/
val rs3 = etlRDD
//一条数据就代表这个小时出现一次PV,将每条数据变成(hour,1)
.map(item => {
//取出这个PV的小时
val hour = item.queryTime.substring(0,2)
//表示这个小时出现一次PV
(hour,1)
})
//按照小时分组聚合
.reduceByKey(_+_)
//按照PV降序
.top(24)(Ordering.by(tuple => tuple._2))
rs3.foreach(println)
//todo:3-保存
/**
* step3:释放资源
*/
Thread.sleep(1000000L)
//释放缓存
etlRDD.unpersist()
sc.stop()
}
}
六、外部数据源
1、应用场景
- Spark读写其他数据源:HBASE、MySQL
2、HBASE
-
Spark没有实现读写HBASE的API,但是Spark投机取巧了,但是Hadoop有,Spark中读写HBASE是调用Hadoop的类来实现
- 读写文件:TextInputFormat、TextOutputFormat
- 读写HBASE:TableInputFormat、TableOutputFormat
-
HBASE Java API
-
命令:
-
插入或者更新:
put 'ns:tbname','rowkey','cf:col','value' -
读取数据
//获取单个rowkey的数据 get 'ns:tbname','rowkey' get 'ns:tbname','rowkey','cf' get 'ns:tbname','rowkey','cf:col' //用于获取批量数据 scan 'ns:tbname' + filter【Filter】
-
-
Java API
-
表
Table table = ConnectionFactory.getConnection().getTable(TableName) -
写
//构建put对象 Put put = new Put(rowkey) //给put对象赋值:列族、列名称、值 put.addColumn(cf,col,value) //执行Put table.put(put) -
读
-
get
Get get = new Get(rowkey) Result rs = table.get(get) Result get(Get get) Cell[] cells = rs.rawCells() for(Cell cell : cells){ //取出每一列的数据:rowkey,列族,列名称,timestamp,value }- 一个Result对象代表一个Rowkey的数据
- 一个Rowkey中包含很多列的数据
- 一个Cell对象代表一列的数据
- 一个Result对象中包含一个Cell数组,里面放了这个rowkey的每一列的数据
- 获取:result.rawCells
- 一个Result对象代表一个Rowkey的数据
-
scan
Scan scan = new Scan() //构建一个过滤器 Filter filter= new MultipleColumnPrefixFilter //让Scan加载过滤器 scan.setFilter(filter) //执行scan ResultScanner rsscan = table.getScanner(scan) for(Result rs:rsscan){ for(Cell cell : rs.rawCells){ //取出每一列的数据:rowkey,列族,列名称,timestamp,value } }- ResultScanner:多个Result对象的集合
-
-
-
-
写HBASE
-
启动HBASE
start-dfs.sh zookeeper-daemons.sh start start-hbase.sh hbase shell -
创建表
create 'htb_wordcount','info' -
开发
-
-
读HBASE
3、MySQL
-
写MySQL
-
登录MySQL:node1
mysql -uroot -p -
MySQL中创建表
USE db_test ; drop table if exists `tb_wordcount`; CREATE TABLE `tb_wordcount` ( `word` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL, `count` varchar(100) NOT NULL, PRIMARY KEY (`word`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ; -
代码实现
附录一:Spark Maven依赖
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client 依赖 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- MySQL Client 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<version>${mysql.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>















 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









