






一、检验神经网络
训练神经网络时,一般会把70%的数据作为训练集,30%的数据作为测试集,有了测试集才能对误差进行评价,然后对参数进行优化。除了误差外,精确度也可以衡量模型的优劣,R2 Score一般用于衡量预测值是连续数字的精确度,F1 Score 一般用于测量不均衡数据的精度。
模型在训练集上的误差和测试集上的误差会有一些差别,训练误差小并不代表着测试误差小。

当训练误差太小时,测试误差可能很大,这种现象叫过拟合,也就是模型太过于依赖训练集,泛化性太差。在机器学习中,有不少方法可以解决过拟合,比如 l1, l2 正规化, dropout 方法。
神经网络中有很多参数,为了确定合适的参数,使其能更好地解决问题,可以使用交叉验证方法。交叉验证方法就是不断地调整参数的值,根据误差来选择合适的参数。也就是说,以某一参数的值作为横轴,误差作为纵轴,选择误差符合要求的值作为最终参数的值。
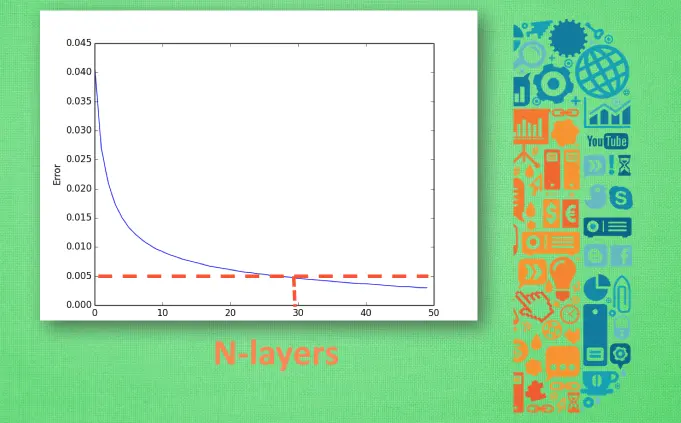
参考链接:https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/3-01-Evaluate-NN/
二、特征标准化
输入数据中,有的数据的值可能非常大,当其对应的参数发生变化时,对输出的影响会非常大。同理,那些值很小的数据的参数发生变化时,对输出几乎没有什么影响。
特征标准化就能解决这个问题,特征标准化可以将数据的值映射到一定的范围内。通常用于 特征标准化的途径有两种, 一种叫做 min max normalization, 他会将所有特征数据按比例缩放到0-1的这个取值区间. 有时也可以是-1到1的区间. 还有一种叫做 standard deviation normalization, 他会将所有特征数据缩放成 平均值为0, 方差为1。

参考链接:https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/3-02-normalization/
三、选择好特征
1. 避免无意义的信息(不具备区分能力的信息,如果参数的每个取值对应的所有可能输出的比值大致相同,那么该参数可能就是无意义的信息)
2. 避免重复性的信息
3. 避免复杂的信息(在重复的信息中选择简单的那一个)
参考链接:https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/3-03-choose-feature/
四、激励函数
激励函数可以用来将线性模型转为非线性模型,比如relu、sigmoid、tanh。激励函数可以自己进行定义,但是要确保的是这些激励函数必须是可以微分的, 因为在 backpropagation 误差反向传递的时候, 只有这些可微分的激励函数才能把误差传递回去。
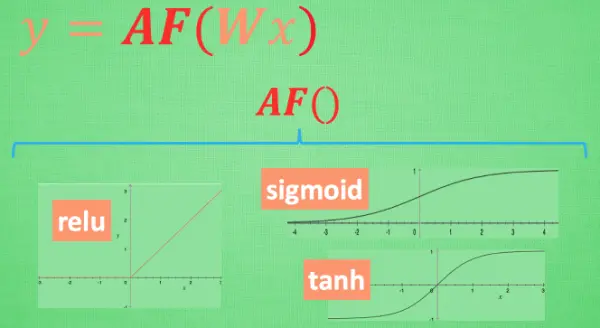
在少量层结构中, 可以尝试很多种不同的激励函数. 在卷积神经网络 Convolutional neural networks 的卷积层中, 推荐的激励函数是 relu. 在循环神经网络中 recurrent neural networks, 推荐的是 tanh 或者是 relu
五、过拟合
过拟合过分拟合了训练数据 这使得模型的复杂度提高,泛化能力较差。其解决方法如下:
1. 增加数据量, 大部分过拟合产生的原因是因为数据量太少了. 如果我们有成千上万的数据, 红 线也会慢慢被拉直, 变得没那么扭曲 .

2. 运用正规化. L1, l2 regularization等等, 这些方法适用于大多数的机器学习,包括神经网络。(图中的L3是三次方,L4是四次方)

3. dropout,专门用在神经网络的正规化的方法。 在训练的时候, 随机忽略掉一些神经元和神经联结 , 是这个神经网络变得”不完整”. 用一个不完整的神经网络训练一次。到第二次再随机忽略另一些, 变成另一个不完整的神经网络。
参考链接:https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/3-05-overfitting/
六、加速神经网络训练
1. Stochastic Gradient Descent (SGD) 随机梯度下降
2. Momentum

3. AdaGrad

4. RMSProp

5. Adam

参考链接:https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/3-06-speed-up-learning/
https://blog.csdn.net/u010089444/article/details/76725843
七、处理不均衡数据
不均衡的数据是指:某一类数据占据主导地位的数据,比如在一组数据中有90%是梨,而只有10%是苹果。这会导致模型总是预测梨,这样也会有90%的正确率。对于这种情况有如下解决方法:
1. 获取更多的数据,让其达到均衡
2. 更换评判方式,比如,不使用准确率和误差,而使用F1 Score
3. 重组数据,方式一: 复制或者合成少数部分的样本, 使之和多数部分差不多数量.。方式二: 砍掉一些多数部分, 使两者数量差不多。
4. 使用其他机器学习方法,神经网络对不均衡数据束手无策,可以使用决策树
5. 修改算法,如果使用sigmoid激励函数,那么可以修改其预测门槛,让其只有在特别自信的时候才预测为少的一方。

参考链接:https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/3-07-imbalanced-data/
八、批标准化
激励函数的输入在合适的区间非常重要,可以使用标准化将数据映射到激励函数的有效区间以获得良好的激励效果。

批标准化(Batch Normalization)就是用来对数据进行标准化的一种方法,在数据进行前向传递的时候,对每一层进行标准化处理。

BN算法公式如下:

公式中包含了一个反标准化工序,将 标准化后的数据再扩展和平移,让神经网络自己去学着使用和修改这个扩展参数 gamma和 平移参数 β,去增加或削弱标准化操作。
九、L1/L2正规化
正规化是为了让误差不仅仅取决于拟合数据拟合的好坏, 而且取决于参数的值的大小。这样就不容易出现某个参数偏大的情况,能够在一定程度上避免过拟合。
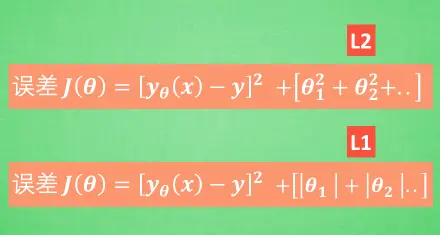
L1方法有可能只保留了一些对结果共享较大的参数,所以很多人也用 l1 正规化来挑选对结果贡献最大的重要特征。但是 l1 的结并不是稳定的。L2 针对于变动, 白点的移动不会太大, 而 L1的白点则可能跳到许多不同的地方 , 因为这些地方的总误差都是差不多的。
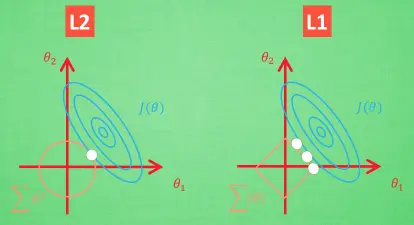
为了控制这种正规化的强度, 会加上一个参数 lambda, 并且通过 交叉验证 来选择比较好的 lambda. 这时, 为了统一化这类型的正规化方法, 还会使用 p 来代表对参数的正规化程度。这就是这一系列正规化方法的最终的表达形式。
















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









