







目录
- 511. 游戏玩法分析 I
- 方法一:(row_number 窗函数 添加rn列 + 子查询)
- 方法二:min + group by
- 方法三:dense_rank() 窗函数 + 子查询
- 512. 游戏玩法分析 II
- 方法一:in + 子查询
- 方法二 : row_number() 窗函数 + 子查询
- 534. 游戏玩法分析 III
- 方法一:sum() + 窗口函数
- 对窗函数的理解(转自[这里](https://www.ssfiction.com/sqljc/1051655.html))
- 方法二:自联表 + group by(容易把自己搞晕)
- 550. 游戏玩法分析 IV
- 方法一:内联表
- 方法二:子查询 + 左外连接 + AVG()灵活运用
- 569.员工薪水中位数
- 方法一:子查询 + row_number() + 窗函数 确定每个公司内的工资排名,count() + 窗函数 确定每个公司的人数
- 方法二:不使用内置函数解决问题(待补充)
- 571.给定数字的频率查询中位数
- 方法一:以 sum() over (order by) 来获取累加和,升序(s1)和降序(s2), 条件:s1 >= total/2 and s2 >= total/2
- 570.至少有5名直接下属的经理
- 方法一: in + 子查询
- 571.给定数字的频率查询中位数
- 580.统计各专业学生人数
- 方法一:外连接 + count(expression)
- 597.好友申请I
- 方法一:distinct 可作用到到多个元素(select distinct requester_id,accepter_id from ......)
- 602.好友申请II :谁有最多的好友
- 方法一:union all 的使用
- 603.连续空余座位(关联题目180)
- 方法一:自联表 (tb_a join tb_b where 条件)
- 1068.产品销售分析 I
- 方法一:natural join
- 方法二:内连接
- 方法三:左外连接
- 1069.产品销售分析 II
- 方法一:简单题 : natural join + group by
- 1069.产品销售分析 III
- 方法一:年有可能重复,用 rank() 或 dense_rank()构成的窗函数作排名
- 1075.项目员工 I
- 方法一:select 使用聚合函数的项 ... group by (另一种方式是 group by + having + 聚合函数的条件)
- 1076.项目员工 II (知识点关联题目1082)
- 方法一:group by + having 聚合函数 + all
- 方法二:窗函数计算每个工程的员工人数排名
- 1077.项目员工 III
- 方法一:窗函数的使用
- 1082.销售分析 I (其他关联题目1076,1077)
- 只有order by 的情况,可以看出前边解法的partition by 并没有发挥作用, order by sum(price) 之后数据只剩一条
- 使用group by 就对了,group by 没让数据减少
- 方法一:窗函数的灵活运用,group by + 只有order by sum(price)
- 方法二:all + 子查询
- 1083.销售分析 II
- 方法一:group by 分组+ sum 与 if构成的条件语句筛选
- 方法二:group by 分组+ sum 与 case语句 构成的条件语句筛选
- 方法三:case语句的另外一种写法
- 1084.销售分析 III
- 方法一:直接GROUP BY然后HAVING筛选日期条件(不需要排除或者子查询)
- 1112.每位学生的最高成绩
- 方法一:窗函数:order by 后可跟多个元素(order by grade desc,course_id)
511. 游戏玩法分析 I

题目:

建表:
create table Activity (
player_id int,
device_id int,
event_date date,
games_played int
);
insert into Activity values
(1, 2, '2016-03-01', 5),
(1, 2, '2016-05-02', 6),
(2, 3, '2017-06-25', 1),
(3, 1, '2016-03-02', 0),
(3, 4, '2018-07-03', 5);
方法一:(row_number 窗函数 添加rn列 + 子查询)
思路:row_number 窗函数 添加rn列 + 子查询
最早的登录时间,就是rn=1时的时间
中间过程:
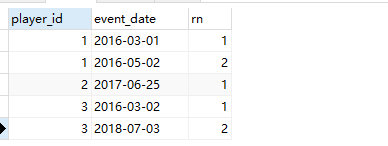
# 中间过程
select player_id,event_date,
row_number() over (partition by player_id order by event_date) as rn
from Activity;
输出:
最终代码:
```sql
select player_id , event_date as first_login
from(
select player_id,event_date,
row_number() over (partition by player_id order by event_date) as rn
from Activity
) temp
where rn=1;
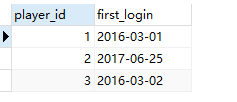
方法二:min + group by
思路:用id分组,min() 找最小日期
select player_id ,min(event_date) as first_login
from Activity
group by player_id;
结果:

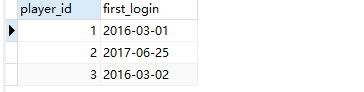
方法三:dense_rank() 窗函数 + 子查询
中间过程:
select player_id , event_date,
dense_rank() over (partition by player_id order by event_date) as rn
from Activity;

最终代码:
select player_id , event_date as first_login
from(
select player_id , event_date,
dense_rank() over (partition by player_id order by event_date) as rn
from Activity
) temp
where rn = 1;
512. 游戏玩法分析 II
题目描述:


方法一:in + 子查询
解题误区:
中间过程:
select player_id , min(event_date),device_id
from Activity
group by player_id;
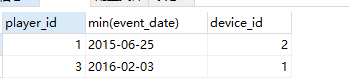
最终代码:
select player_id , device_id
from(
select player_id , min(event_date),device_id
from Activity
group by player_id
) temp;
错误原因:
这里的思路是对的,但是子查询的写法有一个误区。我们假设有这样两条数据player_id,device_id,event_date:1,1,2015;1,2,2014。您是想通过这个子查询select player_id,device_id,min(event_date) from Activity group by player_id 拿到1,2,2,2014,但是这个写法是错误的,因为当你以player_id分组后,由于没有对device_id进行操作,sql会默认取同组Id的第一条数据,因此最终实际返回的是:1,1,2014。所以这道题可以先查找到 player_id,min(event_date) (1,2014),然后外层嵌套in,来获取到(1,2014)对应的那条数据(1,2,2014)。 您可以看一下测试用例,它刚好同组的最小登陆时间的设备id在前面,所以可以通过,但是提交时的数据分布不是这样的。
新的测试用例建表
delete from Activity;
insert into Activity (player_id,device_id,event_date,games_played)
values
(1, 2, '2016-03-01', 5),
(1, 2, '2016-05-02', 6),
(1, 3, '2015-06-25', 1),
(3, 1, '2016-03-02', 0),
(3, 4, '2016-02-03', 5);
正确解法
select a.player_id,a.device_id from Activity as a
where (a.player_id,a.event_date) in (
select player_id,min(event_date) from Activity group by player_id
);
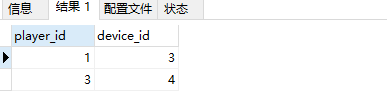
方法二 : row_number() 窗函数 + 子查询
中间过程:
select player_id,device_id,
row_number() over (partition by player_id order by event_date) as rn
from Activity;
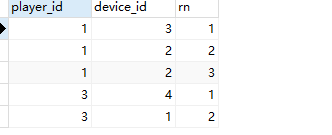
最终结果:
select player_id, device_id
from (
select player_id,device_id,
row_number() over (partition by player_id order by event_date) as rn
from Activity
) temp
where rn=1;
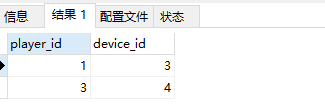
534. 游戏玩法分析 III
题目:


方法一:sum() + 窗口函数
对窗函数的理解(转自这里)
开窗函数语句解析:
函数分为两部分,一部分是函数名称,开窗函数的数量比较少,总共才11个开窗函数+聚合函数(所有的聚合函数都可以用作开窗函数)。根据函数的性质,有的需要写参数,有的不需要写参数。
另一部分为over语句,over()是必须要写的,里面的参数都是非必须参数,可以根据需求有选择地使用:
第一个参数是partition by + 字段,含义是根据此字段将数据集分为多份
第二个参数是order by + 字段,每个窗口的数据依据此字段进行升序或降序排列

开窗函数与分组聚合函数比较相似,都是通过指定字段将数据分成多份,区别在于:
sql 标准允许将所有聚合函数用作开窗函数,用over 关键字区分开窗函数和聚合函数。
聚合函数每组只返回一个值,开窗函数每组可返回多个值。
在这11个开窗函数中,实际工作中用的最多的当属row_number()、rank()、dense_rank()这三个排序函数了。
select
player_id,
event_date,
sum(games_played) over(partition by player_id order by event_date) games_played_so_far
from Activity;
方法二:自联表 + group by(容易把自己搞晕)

select
a.player_id,b.event_date,sum(a.games_played) as games_played_so_far
from activity a,activity b
where a.player_id = b.player_id
and a.event_date <=b.event_date
group by a.player_id,b.event_date;
550. 游戏玩法分析 IV
题目:


方法一:内联表
因为是计算概率,我先计算了分子,又计算了分母,结果不好合起来了。
select count(*)
from Activity a ,Activity b
where a.player_id = b.player_id
and a.event_date + 1 = b.event_date;
select count(distinct(player_id))
from Activity;
所以在保证分子分母都能查到的情况下(内联表,且没有使用 group by)进行查询
select ROUND((count(distinct(a.player_id))/(select count(distinct player_id )from Activity)),2) as fraction
from Activity a,Activity b
where a.player_id = b.player_id
and a.event_date + 1 = b.event_date
and (a.player_id,a.event_date) in (select player_id, min(event_date) from Activity group by player_id);
方法二:子查询 + 左外连接 + AVG()灵活运用
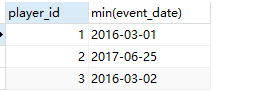
子查询:找每个玩家的id和第一次登录的时间
select player_id , min(event_date)
from Activity
group by player_id;
左关联,筛选次日存在的记录
select *
from (
select player_id , min(event_date) as login
from Activity
group by player_id
) a
left join Activity b on a.player_id = b.player_id and a.login + 1 = b.event_date;

最终结果 (is not null判断后,有eventdate值的返回1,null的返回0,avg相当于求和后(即符合条件的id个数)除以总id数即所求比例)
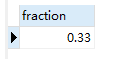
select round(avg(b.event_date is not null),2) as fraction
from (
select player_id ,min(event_date) first_login
from Activity
group by player_id
) a
left join Activity b
on a.player_id = b.player_id
and a.first_login + 1 = b.event_date;
569.员工薪水中位数
关于求众数的题目,请看这里
题目:


建表:
create table Employee
(
id int UNSIGNED auto_increment not null,
company varchar(6),
salary int,
PRIMARY key (id)
);
insert into Employee (id,company,salary)
values
(1,"A",2341),
(2,"A",341),
(3,"A",15),
(4,"A",15314),
(5,"A",451),
(6,"A",513),
(7,"B",15),
(8,"B",13),
(9,"B",1154),
(10,"B",1345),
(11,"B",1221),
(12,"B",234),
(13,"C",2345),
(14,"C",2645),
(15,"C",2645),
(16,"C",2652),
(17,"C",65);
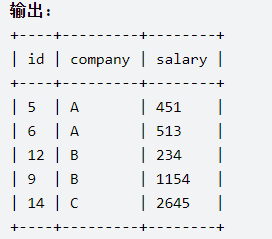
方法一:子查询 + row_number() + 窗函数 确定每个公司内的工资排名,count() + 窗函数 确定每个公司的人数
select id,Company,salary from
(
select id,
row_number() over (partition by Company order by salary asc) company_rank,
count(id) over (partition by Company) company_count,
Company,
salary
from Employee
) temp
where temp.company_rank in (floor((company_count+1)/2),floor((company_count+2)/2));
方法二:不使用内置函数解决问题(待补充)
在这里插入代码片
571.给定数字的频率查询中位数
题目:


方法一:以 sum() over (order by) 来获取累加和,升序(s1)和降序(s2), 条件:s1 >= total/2 and s2 >= total/2
解析
子查询1:
select num,
# sum(frequency), 不能直接上sum()聚合函数,否则只会输出一条数据 ,考虑再写一个子查询查找
sum(frequency) over (order by num asc) s1,
sum(frequency) over (order by num desc) s2
from Numbers;
子查询2:
select sum(frequency) total from Numbers;
最终代码:
select round(avg(num),1) median
from
(
select num,
sum(frequency) over (order by num) s1,
sum(frequency) over (order by num desc) s2
from Numbers
) t1,
(select sum(frequency) total from Numbers) t2
where s1 >= total/2 and s2 >= total/2;
570.至少有5名直接下属的经理
题目:


方法一: in + 子查询
中间过程:
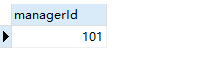
select managerId from employee group by managerId having count(managerId) >=5;
最终代码:
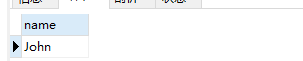
select `name` from employee
where id in (select managerId from employee group by managerId having count(managerId) >=5);
571.给定数字的频率查询中位数
题目:


580.统计各专业学生人数
| 题目:


| 错误情况:
# {"headers": ["dept_name", "student_number"], "values": [["Engineering", 2], ["Science", 1], ["Law", 1]]}
select d.dept_name,count(*) as student_number
from Department d
left join Student s
on
d.dept_id = s.dept_id
group by dept_name
order by student_number desc;

方法一:外连接 + count(expression)
# {"headers": ["dept_name", "student_number"], "values": [["Engineering", 2], ["Science", 1], ["Law", 0]]}
select d.dept_name,count(student_id) as student_number
from Department d
left join Student s
on
d.dept_id = s.dept_id
group by dept_name
order by student_number desc;
597.好友申请I
题目:



方法一:distinct 可作用到到多个元素(select distinct requester_id,accepter_id from …)
中间过程:

最终代码:
select
round(ifnull(
(select count(*) from (select distinct requester_id,accepter_id from RequestAccepted) as a)
/
(select count(*) from (select distinct sender_id,send_to_id from FriendRequest) as b),0),2) as accept_rate;
602.好友申请II :谁有最多的好友
题目:


方法一:union all 的使用
| 中间过程:union 和 union all点击这里查看知识点
UNION用的比较多union all是直接连接,取到得是所有值,记录可能有重复 union 是取唯一值,记录没有重复
| 使用union的情况:
# {"headers": ["ids"], "values": [[1], [2], [3], [4]]}
select requester_id as ids from RequestAccepted
union
select accepter_id from RequestAccepted;
| 使用union all 的情况:
# {"headers": ["ids"], "values": [[1], [1], [2], [3], [2], [3], [3], [4]]}
select requester_id as ids from RequestAccepted
union all
select accepter_id from RequestAccepted;
| 子查询:
# {"headers": ["ids", "num"], "values": [[3, 3], [1, 2], [2, 2], [4, 1]]}
select ids ,count(ids) num from(
select requester_id as ids from RequestAccepted
union all
select accepter_id from RequestAccepted
)temp
group by ids
order by num desc;
| 最终代码:注意需要用order by 先以数量由大到小排序,再去max,不然id和max的结果不匹配
select ids as id , max(num) num from (
select ids ,count(ids) num from(
select requester_id as ids from RequestAccepted
union all
select accepter_id from RequestAccepted
)temp
group by ids
order by num desc # 这里需要用order by 先以数量由大到小排序,再去max,不然id和max的结果不匹配
)temp2;
603.连续空余座位(关联题目180)
| 题目



方法一:自联表 (tb_a join tb_b where 条件)
select distinct c1.seat_id from
Cinema c1 join Cinema c2
where abs(c1.seat_id - c2.seat_id) = 1
and (c1.free = 1 and c2.free =1)
order by seat_id;
1068.产品销售分析 I
题目:


方法一:natural join
select product_name,`year`,price
from Sales natural join Product;
方法二:内连接
select product_name,`year`,price
from Sales natural join Product;
方法三:左外连接
select product_name,`year`,price
from Sales s left join Product p
on s.product_id = p.product_id;
1069.产品销售分析 II
题目:

方法一:简单题 : natural join + group by
select s.product_id,
sum(quantity) as total_quantity
from Sales as s natural join Product as p
group by s.product_id;
1069.产品销售分析 III
题目:

中间过程:
select Product_id,
dense_rank() over (partition by Product_id order by year) rn,
year,
quantity,
price
from Sales;
方法一:年有可能重复,用 rank() 或 dense_rank()构成的窗函数作排名
select Product_id,
`year` as first_year,
quantity,
price
from(
select
Product_id,
dense_rank() over (partition by Product_id order by year) rn,
`year`,
quantity,
price
from Sales
) temp
where rn = 1;
1075.项目员工 I
题目:



方法一:select 使用聚合函数的项 … group by (另一种方式是 group by + having + 聚合函数的条件)
select project_id,round(avg(experience_years),2) average_years
from Employee e, Project p
where e.employee_id = p.employee_id
group by project_id;
1076.项目员工 II (知识点关联题目1082)
题目:

方法一:group by + having 聚合函数 + all
select project_id
from Project
group by project_id
having count(employee_id) >= all(select count(employee_id) from Project group by project_id);
方法二:窗函数计算每个工程的员工人数排名
中间过程:
select project_id,
rank() over (order by count(employee_id) desc) rn
from Project
group by project_id;
最终结果:
select project_id
from(
select project_id,
rank() over (order by count(employee_id) desc) rn
from Project
group by project_id
)temp
where rn = 1;
1077.项目员工 III
题目:

方法一:窗函数的使用
中间过程
select project_id,employee_id,
dense_rank() over (partition by project_id order by experience_years desc) rn
from Project p natural join Employee e where p.employee_id = e.employee_id;
结果:
select project_id,employee_id
from(
select project_id,employee_id,
dense_rank() over (partition by project_id order by experience_years desc) rn
from Project p natural join Employee e where p.employee_id = e.employee_id
) temp
where rn = 1;
1082.销售分析 I (其他关联题目1076,1077)
题目:

中间过程:本题使用 group by 和 partition by的区别(优先级)
错误解法1:还是要子查询+窗函数 ,直接查rn不能在where里做条件
Unknown column ‘rn’ in ‘where clause’
select seller_id,
dense_rank() over (partition by seller_id order by sum(price)) rn
from Sales
where rn = 1;
错误解法二:partition by + order by 聚合函数 这样写结果少了
# {"headers": ["seller_id", "rn"], "values": [[1, 1]]}
select seller_id,
dense_rank() over (partition by seller_id order by sum(price) desc) rn
from Sales;
只有order by 的情况,可以看出前边解法的partition by 并没有发挥作用, order by sum(price) 之后数据只剩一条
# {"headers": ["seller_id", "rn"], "values": [[1, 1]]}
select seller_id,
dense_rank() over (order by sum(price) desc) rn
from Sales;
使用group by 就对了,group by 没让数据减少
# {"headers": ["seller_id", "rn"], "values": [[1, 1], [3, 1], [2, 2]]}
select seller_id,
dense_rank() over (order by sum(price) desc) rn
from Sales
group by seller_id;

方法一:窗函数的灵活运用,group by + 只有order by sum(price)
select seller_id
from(
select seller_id,
dense_rank() over (order by sum(price) desc) rn
from Sales
group by seller_id
)temp
where rn = 1;
方法二:all + 子查询
select seller_id
from Sales
group by seller_id
having sum(price) >= all(select sum(price) from Sales group by seller_id);
1083.销售分析 II
题目:


方法一:group by 分组+ sum 与 if构成的条件语句筛选
select buyer_id
from sales a inner join product b
on a.product_id = b.product_id
group by buyer_id
having sum(if(b.product_name = 'S8',1,0))>0
and sum(if(b.product_name = 'iPhone',1,0))=0;
方法二:group by 分组+ sum 与 case语句 构成的条件语句筛选
select buyer_id
from sales a inner join product b
on a.product_id = b.product_id
group by buyer_id
having sum(case b.product_name when 'S8' then 1 else 0 end)>0
and sum(case b.product_name when 'iPhone' then 1 else 0 end)=0;
方法三:case语句的另外一种写法
select buyer_id
from sales a inner join product b
on a.product_id = b.product_id
group by buyer_id
having sum(case when b.product_name='S8' then 1 else 0 end)>0 and sum(case when b.product_name ='iPhone' then 1 else 0 end)=0;
1084.销售分析 III
题目:


方法一:直接GROUP BY然后HAVING筛选日期条件(不需要排除或者子查询)
select s.product_id,product_name
from Sales s ,Product p
where s.product_id = p.product_id
group by s.product_id
having min(sale_date) >= '2019-01-01' and max(sale_date) <= '2019-03-31';
1112.每位学生的最高成绩
题目:


方法一:窗函数:order by 后可跟多个元素(order by grade desc,course_id)
解法:
select student_id,course_id,grade
from (
select *,
row_number() over (partition by student_id order by grade desc,course_id) as rn
from Enrollments
) temp
where rn = 1;














 3777
3777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









