







本文是在原本数据结构与算法闯关的基础上总结得来,加入了自己的理解和部分习题讲解
邀请码: JL57F5
目录
栈和队列
1.什么是栈 ?
栈也是一种数据呈线性排列的数据结构,不过在这种结构中,我们只能访问最新添加的数据。栈就像是一摞书,拿到新书时我们会把它放在书堆的最上面,取书时也只能从最上面的新书开始取。

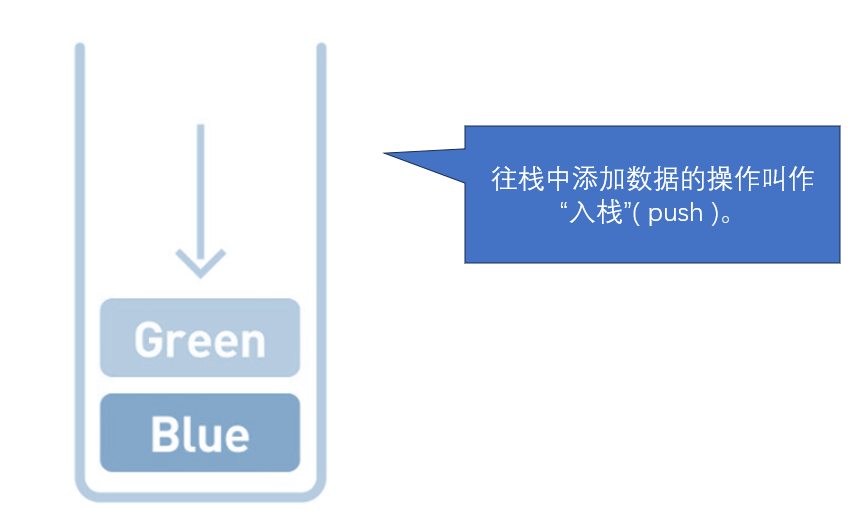
栈的入栈、出栈操作
往栈中添加数据的操作叫作"入栈"(push)。
从栈中取出数据的操作叫作"出栈"( pop )
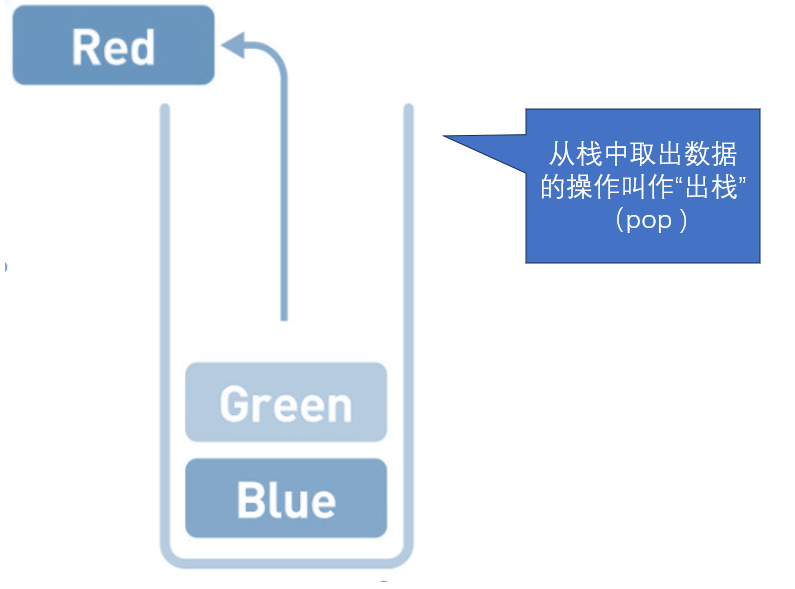
像栈这种最后添加的数据最先被取出,即“后进先出”的结构,我们称为Last In First Out,简称LIFO。与链表和数组一样,栈的数据也是线性排列,但在栈中,添加和删除数据的操作只能在一端进行,访问数据也只能访问到顶端的数据。想要访问中间的数据时,就必须通过出栈操作将目标数据移到栈顶才行。大家要注意这一点
栈只能在一端操作这一点看起来似乎十分不便,但在只需要访问最新数据时,使用它就比较方便了。
案例:用python语言实现栈的示例代码
class Stack:
def __init__(self):
self.stack = []
def push(self, item):
self.stack.append(item)
def pop(self):
if not self.is_empty():
return self.stack.pop()
else:
raise Exception("Stack is empty")
def top(self):
if not self.is_empty():
return self.stack[-1]
else:
raise Exception("Stack is empty")
def is_empty(self):
return len(self.stack) == 0
stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.pop()) # 输出:3
print(stack.top()) # 输出:2
print(stack.is_empty()) # 输出:False
output:
3
2
False
2.什么是队列 ?
与前面提到的数据结构相同,队列中的数据也呈线性排列。虽然与栈有些相似,但队列中添加和删除数据的操作分别是在两端进行的。就和“队列”这个名字一样,把它想象成排成一队的人更容易理解。在队列中,处理总是从第一名开始往后进行,而新来的人只能排在队尾。

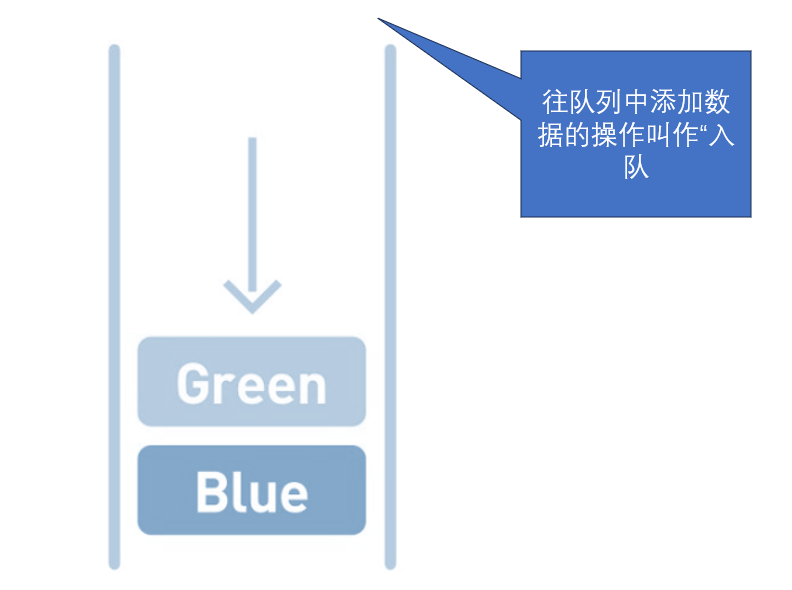
队列的入队和出队
往队列中添加数据的操作叫作"入队"
从队列中删除数据的操作叫作"出队"
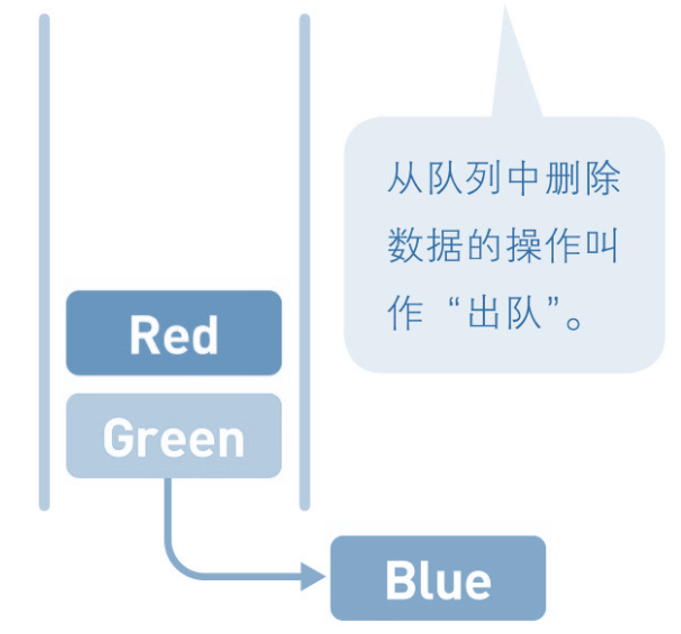
像队列这种最先进去的数据最先被取来,即“先进先出”的结构,我们称为First In First Out,简称FIFO
与栈类似,队列中可以操作数据的位置也有一定的限制。在栈中,数据的添加和删除都在同一端进行,而在队列中则分别是在两端进行的。队列也不能直接访问位于中间的数据,必须通过出队操作将目标数据变成首位后才能访问。“先来的数据先处理”是一种很常见的思路,所以队列的应用范围非常广泛.
案例:用python语言实现队列的示例代码
# 用python语言实现队列的示例代码
class Queue:
def __init__(self):
self.queue = []
def enqueue(self, item):
self.queue.append(item)
def dequeue(self):
if not self.is_empty():
return self.queue.pop(0)
else:
raise Exception("Queue is empty")
def front(self):
if not self.is_empty():
return self.queue[0]
else:
raise Exception("Queue is empty")
def is_empty(self):
return len(self.queue) == 0
queue = Queue()
queue.enqueue(1)
queue.enqueue(2)
queue.enqueue(3)
print(queue.dequeue()) # 输出:1
print(queue.front()) # 输出:2
print(queue.is_empty()) # 输出:False
output:
1
2
False
3.案例讲解 : 使用Python实现栈来管理定时任务
定时任务在公司业务中经常会出现,其应用涉及到定时各种自动化操作,如备份操作、数据清理、报告生成等
定时任务的一个重要用途是实现自动化操作。自动化操作可以提高开发、测试和运维等人员的效率,减少人为错误及其所带来的负面影响。 我们可以通过定时任务来自动执行系统备份、日志清理、文件同步和数据导出等操作
再比如 , 在机器学习任务中,训练时间可能非常长,而且计算量也非常大,可以通过定时任务来自动执行分布式训练操作,以节省时间和费用。另外,在大规模数据分析中,我们可以使用定时任务来分批导入数据、计算指标等,以提高数据分析的处理效率和准确性
import time
class Task:
def __init__(self, name, timeout, interval=None):
self.name = name # 任务名称
self.timeout = timeout # 任务执行时间
self.interval = interval # 任务执行周期(可选)
def __str__(self):
return f'Task(name={self.name}, timeout={self.timeout}, interval={self.interval})'
class TaskStack:
def __init__(self):
self.stack = [] # 初始化一个空栈
def add_task(self, task):
self.stack.append(task) # 将新任务添加到栈中
self.stack.sort(key=lambda t: t.timeout) # 按执行时间排序,保持栈顶的任务是最早执行的任务
def remove_task(self, task):
self.stack.remove(task) # 从栈中删除指定任务
def run(self):
current_time = time.time() # 获取当前时间
while self.stack and self.stack[0].timeout <= current_time:
# 如果栈非空,且栈顶任务的执行时间早于等于当前时间,就执行该任务
task = self.stack.pop(0) # 弹出栈顶任务
print(f'Running {task.name} at {task.timeout}')
if task.interval:
task.timeout += task.interval # 如果任务有执行周期,就计算下次执行的时间
self.add_task(task) # 将任务重新添加到栈中,以便下次执行
def __str__(self):
return '\n'.join(str(task) for task in self.stack)
您提供的 Python 代码定义了两个类:Task 和 TaskStack。这些类共同实现了一个基于时间的任务执行系统,类似于一个定时任务调度器。我将逐一解释这些类及其方法的功能。
Task 类
Task 类用于创建任务对象。每个任务具有以下属性:
name:任务的名称。timeout:任务应该执行的时间。interval:任务的执行周期。如果提供了这个值,任务将会周期性地执行。
__str__ 方法是 Task 类的字符串表示形式,它定义了当打印 Task 对象时的输出格式。
TaskStack 类
TaskStack 类实现了一个任务栈,用于管理和执行 Task 对象。它具有以下方法:
-
__init__方法:
初始化一个空的任务栈。 -
add_task方法:- 功能:向栈中添加一个任务,并根据任务的执行时间
timeout对栈中的任务进行排序,确保栈顶的任务是最早执行的任务。 - 参数:
task- 要添加的 Task 对象。
- 功能:向栈中添加一个任务,并根据任务的执行时间
-
remove_task方法:- 功能:从栈中移除一个任务。
- 参数:
task- 要移除的 Task 对象。
-
run方法:- 功能:执行任务。它会不断检查栈顶的任务是否到了执行时间(
timeout),如果是,则执行该任务。对于有执行周期(interval)的任务,计算下次执行时间并重新添加到栈中,以便下次执行。
- 功能:执行任务。它会不断检查栈顶的任务是否到了执行时间(
-
__str__方法:
提供 TaskStack 对象的字符串表示形式,显示栈中所有任务的详情。
当调用 task_stack.run() 时,代码会执行到期的任务。对于周期性任务(例如 task2),它会在执行后计算下一次执行的时间并再次加入栈中等待执行。
这个系统适用于管理和执行基于时间的任务,特别是在需要周期性执行的场景中。
task1 = Task("Task 1", time.time() + 5)
task2 = Task("Task 2", time.time() + 10, 2)
stack = TaskStack()
stack.add_task(task1)
stack.add_task(task2)
print(stack) # 打印任务栈中的任务信息
stack.run() # 执行任务
print(stack) # 打印任务栈中的任务信息
Task(name=Task 1, timeout=1704110116.3876796, interval=None)
Task(name=Task 2, timeout=1704110121.387707, interval=2)
Task(name=Task 1, timeout=1704110116.3876796, interval=None)
Task(name=Task 2, timeout=1704110121.387707, interval=2)
代码详解:上述代码实例化了两个任务 task1 和 task2,并将它们添加到 TaskStack 实例 stack 中。然后,代码打印了任务栈中的任务信息,执行了任务,并再次打印了任务栈中的任务信息。我将逐步解释这段代码的执行流程。
-
创建任务
task1和task2:task1被设置为在当前时间之后 5 秒执行。task2被设置为在当前时间之后 10 秒执行,并且每 2 秒执行一次(周期性任务)。
-
将任务添加到
TaskStack:task1和task2被添加到任务栈stack中。- 根据任务的
timeout属性,任务栈会自动排序,以确保最早执行的任务位于栈顶。
-
第一次打印任务栈中的任务信息:
- 这将展示
stack中当前排列的任务。由于task1的timeout更早,它将排在task2之前。
- 这将展示
-
执行
stack.run():- 这个调用会检查并执行到期的任务。具体行为取决于代码执行时的当前时间。
- 如果在
task1的timeout之后调用run,task1将被执行并从栈中移除。 - 如果当前时间还没到
task2的timeout,它不会被执行。如果已经到达或超过task2的timeout,task2将被执行,并因为它是周期性任务,它将被重新添加到栈中,其timeout更新为下一个周期的时间。
-
第二次打印任务栈中的任务信息:
- 这将展示
stack.run()执行后任务栈的当前状态。 - 根据
stack.run()调用时的具体时间和任务的执行情况,可能会看到task1被移除,task2的timeout被更新。
- 这将展示
请注意,实际的执行情况取决于您调用 stack.run() 时的确切时间。如果这段代码是立即执行的(即在创建任务后不久),那么很可能 task1 将会被执行而 task2 则还未到执行时间。如果有一段延迟后再调用 stack.run(),则两个任务都可能执行,且 task2 将会根据其周期性计划被重新安排。
提问: 也就是说如果我在创建以上任务的5秒内执行代码,那么我的任务都不会执行,这时候任务列表不会有变化
是的,您的理解解是正确的。如果您在创建任务之后的 5 秒内执行这段代码,那么由于 task1 和 task2 的执行时间 timeout 都尚未到达,这段时间内调用 stack.run() 将不会执行任何任务。
在这种情况下,任务列表(任务栈)将保持不变,因为:
task1的执行时间设置在创建后 5 秒,所以在这 5 秒内它不会被执行。task2的执行时间设置在创建后 10 秒,所以在这 5 秒内它同样不会被执行。
因此,当您在创建任务后的 5 秒内执行这段代码时,第一次和第二次打印任务栈中的任务信息将会显示相同的内容,即包含未执行的 task1 和 task2。
其他:Python 中的 append(), remove(), 和 pop() 函数介绍。这些函数都是 Python 列表对象的内置方法,用于操作列表中的元素。
-
append() 函数
- 用途:
append()用于在列表的末尾添加一个元素。 - 语法:
list.append(element) - 参数:
element:这是您想要添加到列表末尾的元素。
- 返回值:这个方法没有返回值,但会修改原列表。
示例:
fruits = ['apple', 'banana', 'cherry'] fruits.append('orange') # 现在 fruits = ['apple', 'banana', 'cherry', 'orange'] - 用途:
-
remove() 函数
- 用途:
remove()用于删除列表中的第一个匹配项(即找到的第一个指定值)。 - 语法:
list.remove(element) - 参数:
element:要从列表中删除的元素。
- 返回值:这个方法没有返回值,但会修改原列表。
示例:
numbers = [1, 2, 3, 2, 4] numbers.remove(2) # 现在 numbers = [1, 3, 2, 4] - 用途:
-
pop() 函数
- 用途:
pop()用于删除列表中的一个元素(默认是最后一个),并返回该元素的值。 - 语法:
list.pop([index]) - 参数:
index(可选):要删除的元素的索引。默认值是 -1,表示删除最后一个元素。
- 返回值:这个方法返回被删除的元素的值。
示例:
colors = ['red', 'green', 'blue'] removed_color = colors.pop() # 现在 colors = ['red', 'green'] # removed_color = 'blue'如果指定索引:
colors = ['red', 'green', 'blue'] removed_color = colors.pop(1) # 现在 colors = ['red', 'blue'] # removed_color = 'green' - 用途:
这些方法是处理列表时常用的,它们可以让您更有效地管理列表中的数据。
可以看到,任务栈中的任务信息首先按照执行时间排序,然后依次执行任务并更新下次执行的时间。
上述代码中我们定义了 Task 类和 TaskStack 类。Task 类用于存储定时任务的相关信息,包括任务名称、执行时间和执行周期。TaskStack 类用于管理定时任务的栈,支持添加任务、删除任务和运行任务等操作。在运行任务时,我们首先获取当前时间,然后不断循环,直到栈为空或者栈顶任务的执行时间晚于当前时间为止。如果栈非空,我们就依次弹出栈中的任务,并执行任务。如果任务有执行周期,我们就计算下次执行的时间,并把任务重新添加到栈顶中。
4.案例讲解 : 如何用“栈”来处理浏览器的历史记录?
实现思路可以概括为:
当用户访问新网页时,将该网页地址压入历史记录栈中;当用户点击返回按钮时,弹出历史记录栈顶元素,将其压入后退记录栈中,并返回历史记录栈的新栈顶元素;
当用户点击前进按钮时,弹出后退记录栈顶元素,将其压入历史记录栈中,并返回后退记录栈的新栈顶元素。
这种基于栈的实现方式可以有效地管理网页历史记录,方便用户在访问网页时进行前进和后退操作.
class Browser:
def __init__(self):
self.history_stack = [] # 历史记录栈
self.forward_stack = [] # 后退记录栈
def visit(self, url):
# 将新的访问记录添加到历史记录栈中
self.history_stack.append(url)
def back(self):
if len(self.history_stack) > 1:
# 弹出当前页面并加入后退记录栈
current_page = self.history_stack.pop()
self.forward_stack.append(current_page)
# 因为要回退到,所以返回上一个历史记录
return self.history_stack[-1]
else:
# 如果历史记录栈只剩一个元素,那么就不能再返回了
return None
def forward(self):
if len(self.forward_stack) > 0:
# 弹出当前页面并加入历史记录栈
current_page = self.forward_stack.pop()
self.history_stack.append(current_page)
# 返回前进的页面
return current_page
else:
# 如果后退记录栈为空,那么就不能再前进了
return None
def print_history(self):
print('History:', self.history_stack)
print('Forward:', self.forward_stack)
首先,在__init__方法中,我们创建了两个空的列表:history_stack和forward_stack,用于存储浏览器的历史记录和后退记录。
visit方法接收一个URL作为参数,并将该URL添加到历史记录栈history_stack中。
back方法用于回退到上一个历史记录页面。如果历史记录栈history_stack中的记录多于一个,我们从栈顶弹出当前页面,并将其添加到后退记录栈forward_stack中。然后返回历史记录栈history_stack中的上一个页面作为要回退到的页面。如果历史记录栈只有一个元素,即当前页面是最早访问的页面,我们无法再回退,此时返回None。
forward方法用于前进到下一个页面。如果后退记录栈forward_stack中有记录,我们从栈顶弹出当前页面,并将其添加到历史记录栈history_stack中。然后从后退记录栈中取出下一个页面作为要前进到的页面,并返回该页面。如果后退记录栈为空,则无法再前进,此时返回None。
print_history方法用于打印当前浏览器的历史记录和后退记录栈。
browser = Browser()
browser.visit("https://www.google.com")
browser.visit("https://www.yahoo.com")
browser.visit("https://www.bing.com")
print("初始状态:")
browser.print_history()
print("回退:")
print(browser.back())
print("回退:")
print(browser.back())
print("前进:")
print(browser.forward())
print("访问新页面:")
browser.visit("https://www.wikipedia.org")
print("最新状态:")
browser.print_history()
初始状态:
History: ['https://www.google.com', 'https://www.yahoo.com', 'https://www.bing.com']
Forward: []
回退:
https://www.yahoo.com
回退:
https://www.google.com
前进:
https://www.yahoo.com
访问新页面:
最新状态:
History: ['https://www.google.com', 'https://www.yahoo.com', 'https://www.wikipedia.org']
Forward: ['https://www.bing.com']
这段示例代码模拟了在浏览器中访问多个网页、回退和前进的过程。我们可以通过visit方法访问网页,通过back方法回退到上一个页面,通过forward方法前进到下一个页面,通过print_history方法打印当前浏览器的历史记录和后退记录栈的状态。
提问:back方法的current_page是当前页面,函数返回操作执行后即将显示的页面。而forward方法的current_page就是执行操作后即将显示的页面,返回的也是这个页面?
是的,您的理解是正确的。让我们更明确地解释一下 back 和 forward 方法的行为:
-
back方法:current_page是在执行后退操作时的当前页面,即历史记录栈(history_stack)的顶部元素。- 当执行后退操作时,
current_page被移出历史记录栈并推入前进栈(forward_stack)。 - 方法返回的是操作执行后即将显示的页面,也就是现在历史记录栈的新顶部元素。
-
forward方法:current_page是在执行前进操作时的页面,即前进栈(forward_stack)的顶部元素。- 当执行前进操作时,
current_page被移出前进栈并重新推回历史记录栈。 - 方法返回的是操作执行后即将显示的页面,也就是
current_page,此时它已经被重新放回历史记录栈的顶部。
这种设计模拟了大多数浏览器的后退和前进按钮的行为。在使用后退按钮时,当前页面移入前进栈,同时历史记录栈的上一个页面变成了当前页面。相反,在使用前进按钮时,前进栈的顶部页面移回历史记录栈,并成为当前页面。
5.闯关题(*注意学习第九题案例:通过“队列”实现数据的缓存)
STEP1:根据要求完成题目
Q1. (单选)栈和队列都是什么类型的数据结构?
A. 动态数据结构
B. 静态数据结构
C. 线性数据结构
D. 非线性数据结构
Q2. (单选)下列哪项不是栈的特点?
A. 先进后出
B. 后进先出
C. 支持插入和删除操作
D. 只能在栈底进行插入和删除操作
Q3. (单选)如何在 Python 中实现一个栈?
A. 利用列表的 append() 和 pop() 方法
B. 利用列表的 extend() 和 remove() 方法
C. 利用元组的 append() 和 pop() 方法
D. 利用元组的 extend() 和 remove() 方法
Q4. (单选)下列哪种情况适合采用队列数据结构?
A. 消费者和生产者之间的异步消息传递
B. 系统中的前进后出操作
C. 一般类型的后进先出操作
D. 需要快速随机访问存储元素的列表
Q5.(判断对错) 栈也是一种数据呈树形的一种数据结构 (T/F)
Q6.(判断对错)栈这种最后添加的数据最先被取出,即“后进先出”的结构 (T/F)
Q7.(判断对错)列表可以直接用来实现栈的功能,只需要在列表的末尾添加元素,用 pop() 方法从列表末尾删除元素即可。这样,列表就变成了一个简单的 LIFO 数据结构 (T/F)
Q8.(判断对错)队列这种最先进去的数据最先被取来,即“先进先出”的结构 (T/F)
# 如何通过“队列”实现数据的缓存,以下是实现代码:
import queue
import time
import random
import threading
# 创建一个队列,用于数据缓存
cache_queue = queue.Queue()
# 生产者线程:向队列中不断添加数据
def producer():
while True:
# 生成随机数据
data = random.randint(1, 1000)
# 将数据放入队列
cache_queue.put(data)
print("Produced data:", data)
time.sleep(1) # 模拟产生数据的时间间隔
# 消费者线程:从队列中不断取出数据进行处理
def consumer():
while True:
# 从队列中取出数据
data = cache_queue.get()
print("Consumed data:", data)
# 数据处理逻辑示例:打印数据和模拟处理时间
print("Processing data...")
time.sleep(2) # 模拟处理数据的时间间隔
print("Data processing finished")
cache_queue.task_done() # 标记队列中的任务已完成
# 主线程:启动生产者和消费者线程
if __name__ == '__main__':
producer_thread = threading.Thread(target=producer)
# q9题目 : 通过threading模块生成变量名consumer_thread的对象
# 启动线程
producer_thread.start()
consumer_thread.start()
在每次处理完一个数据后,我们调用了cache_queue.task_done()方法来标记任务的完成。这样做的目的是保证在队列中所有的数据被处理完之前,主线程会一直阻塞,确保所有任务的完成。
需要注意的是,当队列中没有任务时,消费者线程将会自动阻塞等待新的任务到来。当生产者线程不断产生数据时,消费者线程会一直从队列中取出数据进行处理。
这样就实现了一个数据缓存系统,并通过队列和多线程实现了数据的生产和消费过程
如何通过“队列”实现数据的缓存,上面是实现代码
观察上面的代码,完成下面的单选题(注意查看前后代码)
Q9.代码第46行为空,现在需要实现 通过threading模块生成变量名为consumer_thread的对象,下面哪个选项为正确代码,选择正确选项并把结果赋值给a9
A : consumer_thread = threading.Thread(target=consumer)
B : consumer_thread = threading.Thread(target=consumer())
C : consumer_thread = threading.Thread(queue=consumer())
D : consumer_thread = threading.Thread(queue=consumer)
E : consumer_thread = threading.Thread(queue == consumer)
进一步完善的代码(加入了消费者线程,并且相比题目代码添加了结束线程模块)
# 创建一个队列
cache_queue = queue.Queue()
# 共享变量,控制线程的运行状态
running = True
# 生产者线程:向队列中不断添加数据
def producer():
while running:
data = random.randint(1,1000)
cache_queue.put(data)
print("Produced data:",data)
time.sleep(1)
# 消费者线程:从队列中不断取出数据进行处理
def consumer():
while running:
data = cache_queue.get()
print("Consumed data:",data)
print("Processing data...")
time.sleep(2)
print("Data processing finished")
cache_queue.task_done()
# 主线程:启动生产者和消费者线程,并在一定时间后停止它们
if __name__ == '__main__':
producer_thread = threading.Thread(target = producer)
consumer_thread = threading.Thread(target = consumer)
producer_thread.start()
consumer_thread.start()
# 进行一段时间后停止线程
time.sleep(10) # 这里设置了10秒,可以根据需要调整
running = False
producer_thread.join()
consumer_thread.join()
print("Threads successfully stopped")
Produced data: 432
Consumed data: 432
Processing data…
Produced data: 712
Produced data: 521
Produced data: 317
Produced data: 913
Data processing finished
Consumed data: 712
Processing data…
Produced data: 790
Produced data: 295
Produced data: 285
Produced data: 199
Data processing finished
Consumed data: 521
Processing data…
Produced data: 852
Produced data: 859
Produced data: 484
Data processing finishedProduced data:
Consumed data: 317
Processing data…
511
Produced data: 81
Produced data: 392
Produced data: 841
Data processing finished
Consumed data: 913
Processing data…
Produced data: 411
Produced data: 241
Produced data: 214
Produced data: 340
Data processing finished
Threads successfully stopped
在这段代码中,我们创建了一个消费者线程 consumer_thread,它运行 consumer 函数。这个函数负责从队列 cache_queue 中获取数据,执行一些处理逻辑(这里是简单地打印消息和等待一段时间),然后标记队列中的任务为已完成。这样,生产者线程和消费者线程将并行运行,模拟了一个生产者-消费者问题的经典解决方案。
提问:还有一个问题是虽然使用了join()函数,但是当调用到join函数的时候,只会把当前的存在的线程对象运行结束对吗?由于消费者需要的时间更多,理论上是不会把队列中所有数据都执行完
是的,您的理解是正确的。join() 函数用于等待线程结束,但它只关注线程对象的完成,而不保证处理队列中的所有项目。
在您的生产者-消费者示例中,producer_thread.join() 和 consumer_thread.join() 调用确实等待相应的线程完成它们的执行。然而,这些调用并不保证消费者线程已经处理了队列中的所有项目。特别是在以下情况下:
- 如果生产者线程的生产速度快于消费者的处理速度,队列可能在消费者线程结束时仍然包含未处理的项目。
- 当设置
running = False后,生产者和消费者线程将完成当前的迭代并退出循环。如果此时队列中还有项目,它们将不会被处理。
为了确保队列中的所有项目都被处理,你可以在设置 running = False 后,使用 queue.join()。这个方法会阻塞,直到队列中的所有项目都被处理(即对每个 put() 调用都有一个对应的 task_done() 调用)。这样可以确保在线程结束之前,队列中的所有项目都被处理。
修改后的代码中加入了 cache_queue.join():
# ... [之前的代码]
if __name__ == '__main__':
# ... [启动线程的代码]
# 运行一段时间后停止线程
time.sleep(10)
running = False
# 等待队列中的所有项目都被处理
cache_queue.join()
# 等待线程完成
producer_thread.join()
consumer_thread.join()
print("Threads and queue processing completed")
这样修改后,程序将确保所有队列中的数据都被处理完毕后,再结束线程。
#填入你的答案后运行
a1 = ‘C’ # 如 a1= ‘A’
a2 = ‘D’ # 如 a2= ‘A’
a3 = ‘A’ # 如 a3= ‘A’
a4 = ‘A’ # 如 a4= ‘A’
a5 = ‘F’ # 如 a5= ‘F’,请注意大小写
a6 = ‘T’ # 如 a5= ‘T’,请注意大小写
a7 = ‘T’ # 如 a5= ‘F’,请注意大小写
a8 = ‘T’ # 如 a5= ‘T’,请注意大小写
a9 = ‘A’ # 如 a9= ‘B’
STEP2:将结果保存为 csv 文件
csv 需要有两列,列名:id、answer。其中,id 列为题号,如 q1、q2;answer 列为 STEP1 中各题你计算出来的结果。💡 这一步的代码你不用做任何修改,直接运行即可。
```python
# 生成 csv 作业答案文件
def save_csv(a1, a2, a3, a4, a5,a6,a7,a8,a9):
import pandas as pd
df = pd.DataFrame({"id": ["q1", "q2", "q3", "q4","q5","q6","q7","q8","q9"], "answer": [a1, a2, a3,a4,a5,a6,a7,a8,a9]})
df.to_csv("answer_ago_1_2.csv", index=None)
save_csv(a1, a2, a3,a4,a5,a6,a7,a8,a9) # 运行这个cell,生成答案文件;该文件在左侧文件树project工作区下,你可以自行右击下载或者读取查看














 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









