







总结:本文为和鲸python 可视化探索训练营资料整理而来,加入了自己的理解(by GPT4o)
原作者:作者:大话数据分析,知乎、公众号【大话数据分析】主理人,5年数据分析经验,前蚂蚁金服数据运营,现京东经营分析师。
第三节 Seaborn数据可视化
本节你将学习Seaborn数据可视化内容,Seaborn是Python常用的绘图工具之一。它涵盖了基础知识和多种图表类型,可直观展示数据分布、关系和异常值,还提供强大的统计图表功能。掌握Seaborn绘图方法可以增强你的数据分析效能,使数据呈现更直观和专业,有助于学术研究、项目报告和日常数据分析,为决策提供有力支持。
核心知识点
1.Seaborn基础知识:
- Seaborn安装与导入
- Seaborn图表设置
2.Seaborn图表类型:
- Seaborn基础图表
- Seaborn统计图表
一、Seaborn基础知识
1.Seaborn安装与导入
什么是Seaborn?
Seaborn是一个基于Python的数据可视化库,它基于Matplotlib库进行构建,提供了更高级别的界面和更好看的默认风格。Seaborn旨在使可视化成为探索和理解数据的核心部分,其提供了面向数据集的API,可以方便地在相同变量的不同视觉表示之间切换,以便更好地理解数据集。
Seaborn和Matplotlib有什么不同?
Matplotlib和Seaborn的区别包括以下几点:
- Seaborn是基于Matplotlib的更高级别的封装,使得作图更加容易,且图形更加美观;
- Seaborn提供了更漂亮的默认样式和调色板,使统计图形更具吸引力;
- Seaborn与pandas的数据结构紧密集成,使得数据处理和可视化更加方便;
- 可针对于统计绘图,用于数据的统计描述和探索分析,补充Matplotlib作图风格。
相对于Matplotlib,Seaborn的语法更简洁,更容易上手。但其功能相比于Matplotlib可能少一些。可以把Seaborn视为Matplotlib的补充,进阶学习Python数据可视化。
Seaborn安装与升级
安装Seaborn包使用pip install+包的名称,如果要安装指定的Seaborn包,可==具体的版本号。如在命令行输入pip install seaborn==xxx 可下载指定版本,xxx为版本号,接下来重点学习如何导入seaborn包,导入seaborn包与matplotlib包方法一样,使用import方式,起个别名即可导入成功。
1.1导入Seaborn包
import seaborn #导入seaborn
print('Seaborn 版本为: ' + seaborn.__version__)
Seaborn 版本为: 0.13.2
#查看包的方法
import seaborn
print(dir(seaborn))
['FacetGrid', 'JointGrid', 'PairGrid', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', '_base', '_compat', '_core', '_docstrings', '_orig_rc_params', '_statistics', '_stats', 'algorithms', 'axes_style', 'axisgrid', 'barplot', 'blend_palette', 'boxenplot', 'boxplot', 'categorical', 'catplot', 'choose_colorbrewer_palette', 'choose_cubehelix_palette', 'choose_dark_palette', 'choose_diverging_palette', 'choose_light_palette', 'clustermap', 'cm', 'color_palette', 'colors', 'countplot', 'crayon_palette', 'crayons', 'cubehelix_palette', 'dark_palette', 'desaturate', 'despine', 'displot', 'distplot', 'distributions', 'diverging_palette', 'dogplot', 'ecdfplot', 'external', 'get_data_home', 'get_dataset_names', 'heatmap', 'histplot', 'hls_palette', 'husl_palette', 'jointplot', 'kdeplot', 'light_palette', 'lineplot', 'lmplot', 'load_dataset', 'matrix', 'miscplot', 'move_legend', 'mpl', 'mpl_palette', 'pairplot', 'palettes', 'palplot', 'plotting_context', 'pointplot', 'rcmod', 'regplot', 'regression', 'relational', 'relplot', 'reset_defaults', 'reset_orig', 'residplot', 'rugplot', 'saturate', 'scatterplot', 'set', 'set_color_codes', 'set_context', 'set_hls_values', 'set_palette', 'set_style', 'set_theme', 'stripplot', 'swarmplot', 'utils', 'violinplot', 'widgets', 'xkcd_palette', 'xkcd_rgb']
Seaborn内置了多种数据集,这些数据集涵盖了不同领域和主题,如经济学、社会学、生物学等。这些数据集经过精心设计和整理,具有代表性和实际意义,非常适合初学者进行练习。通过Seaborn的内置数据集,学习者可以轻松获取真实的经济数据进行可视化分析,从而加深对经济现象的理解和对数据可视化的掌握。
#以下命令可以查看seaborn包含的数据集种类
# import seaborn as sns
# sns.get_dataset_names()
如果要使用官方提供的数据集,可以使用sns.load_dataset('xxx')命令,xxx表示seaborn包含的数据集种类,比如要使用tips小费数据集,可以使用命令sns.load_dataset('tips')
#tips=sns.load_dataset('tips')
#tips[10:15]
由于国内网无法直接连接国外服务器,使用上面的命令无法加载出来数据,解决方法可从github上下载数据到本地, 从本地读取数据,只需加上data_home这个参数,指定数据保存的文件路径即可加载数据。
- Seaborn数据下载地址: https://github.com/mwaskom/seaborn-data
#tips = sns.load_dataset('tips',data_home=r'C:\Users\shangtianqiang\Desktop\seaborn-data')
#tips.head()
1.2创建数据集
import pandas as pd
import numpy as np
import random
# 商品品类列表
categories = ['办公家具', '厨房电器','家装饰品', '床品件套', '电脑硬件']
# 使用列表生成式随机生成分类字段的值
random_categories = [random.choice(categories) for i in range(30)]
#导入数据
df=pd.DataFrame(data={'销售日期': pd.date_range('20231101',periods=30),
'销售数': np.random.randint(low=100,high=1000,size=30),
'销售单均': np.random.randint(low=50,high=100,size=30),
'销售成本': np.random.randint(low=500,high=1000,size=30),
'商品品类': random_categories}
)
df['日期'] = df['销售日期'].dt.day # 提取日期中的日数据
df['销售额']=df['销售数']*df['销售单均']
df['利润']=df['销售额']-df['销售成本']
df.head()
| 销售日期 | 销售数 | 销售单均 | 销售成本 | 商品品类 | 日期 | 销售额 | 利润 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 579 | 97 | 568 | 电脑硬件 | 1 | 56163 | 55595 |
| 1 | 2023-11-02 | 448 | 62 | 681 | 电脑硬件 | 2 | 27776 | 27095 |
| 2 | 2023-11-03 | 789 | 68 | 697 | 厨房电器 | 3 | 53652 | 52955 |
| 3 | 2023-11-04 | 557 | 60 | 682 | 家装饰品 | 4 | 33420 | 32738 |
| 4 | 2023-11-05 | 934 | 74 | 708 | 厨房电器 | 5 | 69116 | 68408 |
1.3使用sns.lineplot命令绘制折线图。sns.lineplot()
函数签名:
seaborn.lineplot(x=None, y=None, hue=None, size=None, style=None, data=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, dashes=True, markers=True, style_order=None, ci=95, n_boot=1000, err_style=‘band’, err_palette=None, err_kws=None, legend=‘auto’, ax=None, **kwargs)
参数解释:
- x, y: 数据中的变量名,分别代表横纵坐标。
- hue: 数据中的变量名,用于区分不同的线。
- size: 数据中的变量名,用于改变线宽。
- style: 数据中的变量名,用于改变线条样式。
- data: 包含数据的DataFrame对象。如果没有提供x和y的参数,则需要提供此参数。
- palette: 用于hue参数的颜色映射。
- hue_order: hue变量的排序顺序。
- sizes: 用于改变线宽的尺寸大小。
- ci: 置信区间的大小,默认为95。
- n_boot: 计算置信区间时的bootstrap迭代次数。
- err_style: 置信区间的样式,可以是’band’(带状)或’bars’(线条)。
- err_palette: 置信区间的颜色映射。
- legend: 是否显示图例,可以是’auto’,True或False。
- ax: matplotlib的Axes对象,用于绘制图形。
- **kwargs: 控制线条、标记等属性的其他参数。
#一个最简单的seaborn折线图
import seaborn as sns
import matplotlib.pyplot as plt # 导入matplotlib包
import matplotlib.pyplot as plt #导入matplotlib包
import warnings
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
plt.figure(figsize = (9, 6)) #设置图表画布大小
# sns.lineplot(x='日期',y='销售数',data=df)
sns.lineplot(x='日期',y='销售数',data=df,linestyle= "--",linewidth=1,marker="o",markersize=5,color=sns.color_palette()[3])
# 在Seaborn中,设置图表标题可以使用plt.title()函数,这是基于Matplotlib库的函数
plt.title('双十一销售量数据趋势',fontsize=12,color='k') # 设置标题
Text(0.5, 1.0, '双十一销售量数据趋势')

1.4* 拓展说明
a. color=sns.color_palette()[3] 官方调色板的解释说明
#官方配色调色板
sns.color_palette()
import seaborn as sns
# 获取官方配色并转换为十六进制颜色值
colors = sns.color_palette().as_hex()
# 添加序号并打印颜色值
for idx, color in enumerate(colors):
print(f'第{idx + 1}种官方配色颜色值:{color}')
第1种官方配色颜色值:#1f77b4
第2种官方配色颜色值:#ff7f0e
第3种官方配色颜色值:#2ca02c
第4种官方配色颜色值:#d62728
第5种官方配色颜色值:#9467bd
第6种官方配色颜色值:#8c564b
第7种官方配色颜色值:#e377c2
第8种官方配色颜色值:#7f7f7f
第9种官方配色颜色值:#bcbd22
第10种官方配色颜色值:#17becf
b. 分类对象
在绘制涉及类别数据的图表时,学习者可以设置分类对象的属性,例如类别标签的字体、颜色、位置等,以确保类别之间的清晰区分,hue为数据中的变量名,用于区分不同分类对象的线,hue_order对hue变量的排序顺序。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.lineplot(x='日期',y='销售数',data=df,hue='商品品类',
hue_order=['电脑硬件','办公家具','家装饰品','床品件套','厨房电器'])#用于区分不同的线。
<Axes: xlabel='日期', ylabel='销售数'>

c. 使用主题
Seaborn是基于matplotlib的数据可视化库,提供多种主题样式,可方便地定制图表的外观,这些主题可以快速地改变图表的整体风格和视觉效果。Seaborn库中有五种风格主题供使用。如:darkgrid、whitegrid、dark、white、ticks,要使用darkgrid主题,可通过调用seaborn.set_style()函数来全局设置主题样式,该函数接受一个字符串参数用于指定主题样式。
注意:sns.set_style(“darkgrid”) 可能会重置字体设置,因为 Seaborn 的风格设置会覆盖 Matplotlib 的一些默认配置,解决方式是将这句话放到matplotlib设置(字体、正负号等)的前边
- sns.set_style(“darkgrid”) # 设置darkgrid主题
- sns.set_style(“whitegrid”) # 设置whitegrid主题
- sns.set_style(“dark”) # 设置dark主题
- sns.set_style(“white”) # 设置white主题
- sns.set_style(“ticks”) # 设置ticks主题
⏳跟练题目1
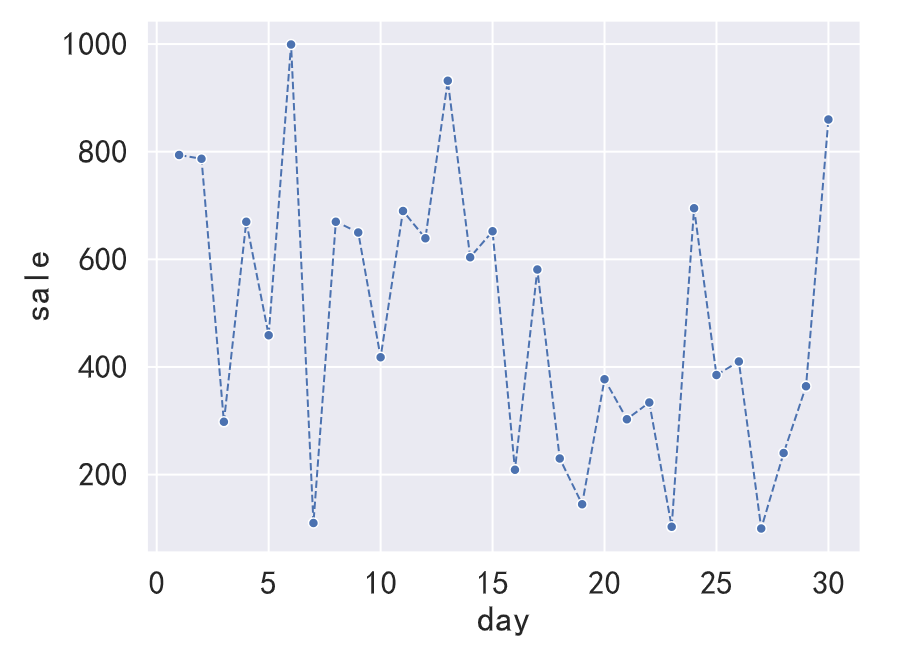
✍跟练1:假如你是一名零售分析师,现在需要制作一个折线图来跟踪电商的销售数据,以便更好地了解销售趋势和变化,Seaborn中的折线图可清晰地展示其波动情况,请你在设计折线图时增加必要的图表元素,比如轴标题、线型、点型、颜色、图表主题等。
💡 提示:生成数据表可使用下面的所例的代码,sns.lineplot()参数设置可以做折线图,做出来的图表应该与下面的图表类似。
imprt pandas as pd
df=pd.DataFrame({'date':pd.date_range('20231101',periods=30),'sale':np.random.randint(100,1000,size=30)})
df['day']=df['date'].dt.day
#一个最简单的seaborn折线图
import seaborn as sns
import matplotlib.pyplot as plt # 导入matplotlib包
import matplotlib.pyplot as plt #导入matplotlib包
import warnings
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
sns.set_style("darkgrid") # 设置darkgrid主题
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
# 数据
df=pd.DataFrame({'date':pd.date_range('20231101',periods=30),'sale':np.random.randint(100,1000,size=30)})
df['day']=df['date'].dt.day
plt.figure(figsize = (9, 6)) #设置图表画布大小
# sns.lineplot(x='日期',y='销售数',data=df)
sns.lineplot(x='day',y='sale',data=df,linestyle= "--",linewidth=1,marker="o",markersize=5)
plt.title('双十一销售量数据趋势',fontsize=12,color='k') # 设置标题
Text(0.5, 1.0, '双十一销售量数据趋势')

二、Seaborn图表类型
Seaborn含有多个图表类型,这一特点使得它成为数据分析与可视化过程中的强大工具。每一种图表类型都有其特定的用途,可以展现不同类型的数据和关系,满足经管专业学习者在多种场景下的数据分析和数据可视化需求,这对于他们的学术研究和实际工作都将大有裨益。
例如,柱状图可以用来展示不同类别之间的数值比较;折线图则适用于展示时间序列或连续变量之间的趋势关系;散点图可以用于观察两个连续变量之间的关系,并可通过颜色和大小加入第三、第四维度的信息。
除了这些基础图表类型,Seaborn还提供了一些复杂但极其有用的图表,如热力图、分面网格图等。热力图可以用于展示二维数据矩阵中的值,而分面网格图则允许学习者在一个画面中查看多个子图,从而进行更为详细和全面的数据分析。
- Seaborn官网画廊:https://seaborn.pydata.org/examples/index.html
#导入数据
df=pd.DataFrame(data={'销售日期': pd.date_range('20231101',periods=30),
'销售数': np.random.randint(low=100,high=1000,size=30),
'销售单均': np.random.randint(low=50,high=100,size=30),
'销售成本': np.random.randint(low=500,high=1000,size=30),
'商品品类': random_categories}
)
df['日期'] = df['销售日期'].dt.day # 提取日期中的日数据
df['销售额']=df['销售数']*df['销售单均']
df['利润']=df['销售额']-df['销售成本']
df.head()
| 销售日期 | 销售数 | 销售单均 | 销售成本 | 商品品类 | 日期 | 销售额 | 利润 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 650 | 75 | 815 | 电脑硬件 | 1 | 48750 | 47935 |
| 1 | 2023-11-02 | 831 | 96 | 889 | 电脑硬件 | 2 | 79776 | 78887 |
| 2 | 2023-11-03 | 351 | 61 | 676 | 厨房电器 | 3 | 21411 | 20735 |
| 3 | 2023-11-04 | 975 | 86 | 902 | 家装饰品 | 4 | 83850 | 82948 |
| 4 | 2023-11-05 | 272 | 67 | 814 | 厨房电器 | 5 | 18224 | 17410 |
1.Seaborn基础图表
1.1折线图
**sns.lineplot():**是Seaborn库中用于绘制线性图。
函数签名
sns.lineplot(x=None, y=None, hue=None, data=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, dashes=True, markers=True, style=None, style_order=None, ci=95, n_boot=10000, err_style=“band”, err_kws=None, legend=True, ax=None, **kwargs)
参数解释
- x, y: 用于绘制图形的数据集的变量名。x 是横坐标,y 是纵坐标。
- hue: 数据集的变量名,用于在不同的线上进行区分。
- data: 包含数据的 DataFrame 对象。如果没有指定 x 和 y 参数,可以从 data 参数中推断。
- palette: 用于控制色调的颜色映射或颜色列表。
- hue_order: 控制 hue 参数类别的顺序。
- sizes: 用于控制线宽的变量名或数字。
- size_order: 控制 sizes 参数类别的顺序。
- dashes: 布尔值,是否使用虚线。
- markers: 布尔值,是否在线上标记数据点。
- style: 用于在线上区分不同样式的变量名。
- style_order: 控制 style 参数类别的顺序。
- ci: 置信区间的大小,用于绘制阴影区域表示不确定性。
- err_style: 阴影区域的样式,可以是 “band” 或 “bars”。
- err_kws: 传递给阴影区域绘制函数的参数。
- legend: 布尔值,是否显示图例。
- ax: 用于绘制图形的 matplotlib 轴对象。如果没有提供,将使用当前活动的轴。
- **kwargs: 其他关键字参数,用于传递给 plt.plot() 函数。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.lineplot(x="日期",y="销售数",data=df)
<Axes: xlabel='日期', ylabel='销售数'>

1.2柱形图
**sns.barplot():**是Seaborn库中用于绘制条形图。
函数签名:
sns.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, ax=None, **kwargs)
参数解释:
- x, y: 数据中的变量名,分别表示条形图的x轴和y轴。
- hue: 数据中的变量名,用于区分不同类别的条形图,不同类别将使用不同颜色表示。
- data: 包含数据的DataFrame对象。如果没有指定x和y参数,可以从data参数中推断。
- order, hue_order: 控制类别顺序的参数,可以传入类别列表来指定顺序。
- orient: 条形图的方向,可以是"v"表示垂直方向,或者"h"表示水平方向。默认为"v"。
- color: 条形的颜色。可以传入颜色名、RGB元组或颜色列表。如果指定了palette参数,则该参数将被忽略。
- palette: 用于控制色调的颜色映射或颜色列表。
- saturation: 条形的饱和度,用于控制颜色的深浅,取值范围为0到1。
- width: 条形的宽度。
- dodge: 布尔值,表示是否将不同类别的条形分开显示。
- fliersize: 异常值的大小。
- linewidth: 条形边框的宽度。
- whis: 控制箱线图须线(whiskers)的长度,默认为1.5倍IQR(四分位距)。
- ax: 用于绘制图形的matplotlib轴对象。如果没有提供,将使用当前活动的轴。
- **kwargs: 其他关键字参数,用于传递给底层绘图函数。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.barplot(x="商品品类",y="销售数",data=df)
<Axes: xlabel='商品品类', ylabel='销售数'>

1.3计数图
sns.countplot(): 用于显示类别变量的计数。
函数签名:
seaborn.countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, ax=None, **kwargs)
参数解释:
- x, y, hue: 数据集中的变量名,分别对应x轴,y轴和颜色区分。
- data: DataFrame类型,绘制的数据集。
- order, hue_order: 对应x轴和颜色区分的类别顺序。
- orient: 绘图方向,"h"为水平方向,"v"为垂直方向。
- color: 单个颜色或颜色的列表,用于元素的颜色。
- palette: 颜色板的名字,或者是颜色列表的列表,用于hue的颜色。
- saturation: 颜色的饱和度。
- width: 条形的宽度。
- dodge: 是否分开不同hue的条形。
- fliersize: 异常值点的大小。
- linewidth: 条形边缘线的宽度。
- whis: 确定异常值点的位置,即IQR(四分位距)的倍数。
- ax: matplotlib的子图对象,绘制图形的位置。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.countplot(x='商品品类',data=df,palette='Greens_d')#计数图
<Axes: xlabel='商品品类', ylabel='count'>

1.4箱线图
**boxplot():**用于绘制箱线图。可以接受x和y参数以及data参数来指定数据。
函数签名:
seaborn.boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, ax=None, **kwargs)
参数解释:
- x, y, hue: 数据集中的变量名,分别对应x轴,y轴和颜色区分。
- data: DataFrame类型,绘制的数据集。
- order, hue_order: 对应x轴和颜色区分的类别顺序。
- orient: 绘图方向,"h"为水平方向,"v"为垂直方向。
- color: 单个颜色或颜色的列表,用于元素的颜色。
- palette: 颜色板的名字,或者是颜色列表的列表,用于hue的颜色。
- saturation: 颜色的饱和度。
- width: 条形的宽度。
- dodge: 是否分开不同hue的条形。
- fliersize: 异常值点的大小。
- linewidth: 条形边缘线的宽度。
- whis: 确定异常值点的位置,即IQR(四分位距)的倍数。
- ax: matplotlib的子图对象,绘制图形的位置。
- orient:箱线图的方向,可以是"h"(水平)或"v"(垂直)。
- saturation:颜色的饱和度,用于调整箱线图的颜色深浅。
- whis:箱线图须(whiskers)的长度,表示箱线图上下边缘延伸的范围。默认值是1.5,表示箱线图上下边缘延伸1.5倍的四分位距(IQR)。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.boxplot(x="商品品类",y="销售数",data=df)
<Axes: xlabel='商品品类', ylabel='销售数'>

import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.boxplot(x="销售数",y="商品品类",data=df,orient='h')
<Axes: xlabel='销售数', ylabel='商品品类'>

1.5热力图
**heatmap():**用于绘制热力图。可以接受data参数来指定数据,c参数用于设置颜色,cmap参数用于设置颜色映射,常见的颜色映射有"viridis"、“coolwarm”、"RdBu"等
函数签名:
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=False, fmt=‘.2g’, annot_kws=None, linewidths=0, linecolor=‘white’, cbar=True, cbar_kws=None, cbar_ax=None, square=False, ax=None, **kwargs)
参数解释:
- data: 必须参数,用于绘制热力图的数据,可以是Pandas的DataFrame或者Numpy的2D数组。
- vmin, vmax: 可选参数,分别代表颜色映射的最小值和最大值。
- cmap: 可选参数,用于定义颜色映射,可以是Matplotlib的颜色映射名称,或者是Seaborn的颜色映射名称。
- center: 可选参数,数据表的中心值。
- robust: 可选参数,如果为True,且没设定vmin和vmax,则使用稳健的统计方法(即去掉异常值后)计算vmin和vmax。
- annot: 可选参数,如果为True,则在每个单元格中写入数据值。
- fmt: 可选参数,字符串格式化代码,用于annot=True时格式化单元格中的数据。
- annot_kws: 可选参数,字典类型,用于设置单元格中注释的属性,如颜色、字体大小等。
- linewidths: 可选参数,定义每个单元格边框的宽度。
- linecolor: 可选参数,定义每个单元格边框的颜色。
- cbar: 可选参数,是否绘制颜色条。
- cbar_kws: 可选参数,字典类型,用于设置颜色条的属性。
- cbar_ax: 可选参数,matplotlib的Axes对象,用于绘制颜色条。
- square: 可选参数,如果为True,则所有单元格为正方形。
- ax: 可选参数,matplotlib的Axes对象,用于绘制热力图。如果不提供,则使用当前活跃的Axes。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
# 绘制热力图
grouped_df = df.pivot_table(index='日期', columns='商品品类', values='销售数', aggfunc='sum')
print(grouped_df)
sns.heatmap(data=grouped_df, cmap='RdBu') # 或其他合适的颜色映射
商品品类 办公家具 厨房电器 家装饰品 床品件套 电脑硬件
日期
1 NaN NaN NaN NaN 650.0
2 NaN NaN NaN NaN 831.0
3 NaN 351.0 NaN NaN NaN
4 NaN NaN 975.0 NaN NaN
5 NaN 272.0 NaN NaN NaN
6 NaN NaN NaN 158.0 NaN
7 NaN NaN NaN 224.0 NaN
8 NaN NaN NaN NaN 132.0
9 NaN 676.0 NaN NaN NaN
10 NaN 561.0 NaN NaN NaN
11 NaN NaN NaN NaN 763.0
12 NaN NaN NaN 962.0 NaN
13 NaN NaN NaN NaN 759.0
14 NaN 231.0 NaN NaN NaN
15 199.0 NaN NaN NaN NaN
16 NaN 208.0 NaN NaN NaN
17 NaN 686.0 NaN NaN NaN
18 812.0 NaN NaN NaN NaN
19 NaN NaN 722.0 NaN NaN
20 NaN 230.0 NaN NaN NaN
21 153.0 NaN NaN NaN NaN
22 NaN NaN NaN NaN 816.0
23 821.0 NaN NaN NaN NaN
24 NaN NaN NaN NaN 133.0
25 NaN NaN NaN NaN 915.0
26 241.0 NaN NaN NaN NaN
27 NaN NaN NaN 939.0 NaN
28 558.0 NaN NaN NaN NaN
29 630.0 NaN NaN NaN NaN
30 NaN 991.0 NaN NaN NaN
<Axes: xlabel='商品品类', ylabel='日期'>

⏳跟练题目2
✍跟练2:假如你是一名零售分析师,现在需要制作一个热力图来展示各个商品品类的订单数据。热力图可直观地了解哪些品类受到消费者的青睐,通过热力图颜色的变化,可以发现哪些品类销售较好,哪些品类可能需要更多的关注和推广,请根据以上需求生成一个热力图。
💡 提示:可使用下面的代码模拟生成一组各个商品品类的订单数据,小数模拟各个品类销售得相关关系。sns.heatmap()可以做热力图,做出来的图表应与下面的图表类似。
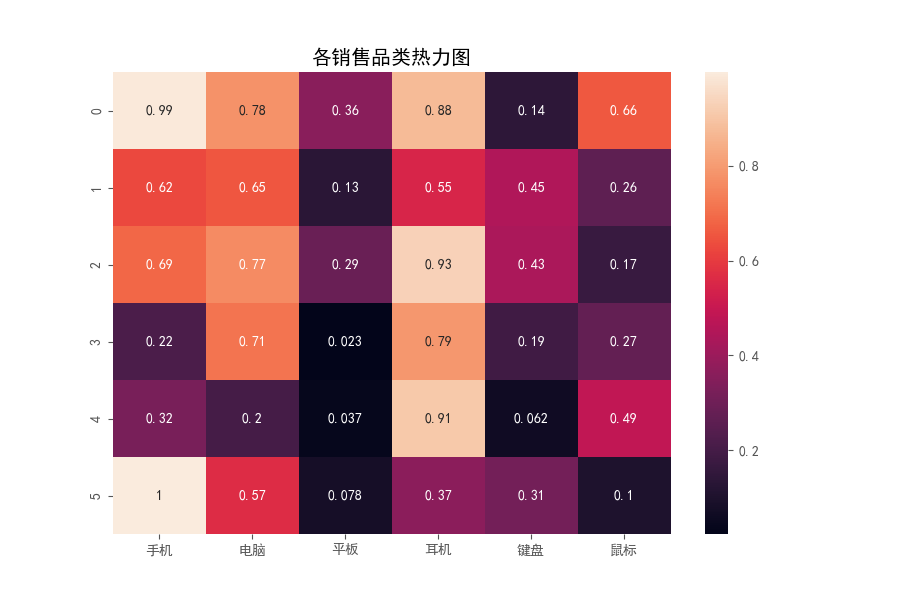
import pandas as pd
import numpy as np
#模拟个商品品类相关系数
df = pd.DataFrame(np.random.rand(6, 6),
columns=['手机','电脑','平板','耳机','键盘','鼠标'])
df
| 手机 | 电脑 | 平板 | 耳机 | 键盘 | 鼠标 | |
|---|---|---|---|---|---|---|
| 0 | 0.514056 | 0.478816 | 0.420472 | 0.983366 | 0.873318 | 0.420538 |
| 1 | 0.564656 | 0.724551 | 0.546994 | 0.077563 | 0.147118 | 0.123305 |
| 2 | 0.929929 | 0.629004 | 0.324035 | 0.844803 | 0.287265 | 0.426697 |
| 3 | 0.144596 | 0.439335 | 0.222482 | 0.972202 | 0.728970 | 0.865514 |
| 4 | 0.493837 | 0.283075 | 0.298518 | 0.315817 | 0.014783 | 0.959344 |
| 5 | 0.054093 | 0.270143 | 0.525587 | 0.234712 | 0.989975 | 0.019292 |
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
# 绘制热力图
sns.heatmap(data=df,annot=True) # 或其他合适的颜色映射
plt.title('各销售品类热力图',fontsize=12,color='k') # 设置标题
Text(0.5, 1.0, '各销售品类热力图')

1.6散点图
**sns.scatterplot():**是 Seaborn 库中用于绘制散点图的函数。
函数签名:
seaborn.scatterplot(x=None, y=None, hue=None, style=None, size=None, data=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=True, style_order=None, x_bins=False, y_bins=False, latitude=False, longitude=False, legend=‘auto’, ax=None, **kwargs)
参数解释:
- x, y: 数据中的变量名,分别表示 x 轴和 y 轴的值。
- hue: 数据中的变量名,用于根据不同的值改变点的颜色。
- style: 数据中的变量名,用于根据不同的值改变点的样式(如标记的形状)。
- size: 数据中的变量名,用于根据不同的值改变点的大小。
- data: 包含数据的 DataFrame 对象。如果提供了 x,y,hue,style 或 size 参数,则可以省略此参数。
- palette: 用于 hue 参数的颜色映射。可以是颜色列表或 Seaborn 颜色映射的名称。
- hue_order: hue 变量的类别顺序。
- hue_norm: 用于 hue 变量的归一化函数,以便在颜色映射中进行均匀分布。
- sizes: 传递给点大小的值的列表或数组。
- size_order: size 变量的类别顺序。
- size_norm: 用于 size 变量的归一化函数,以便在点大小中进行均匀分布。
- markers: 是否使用标记样式。布尔值或标记样式列表。
- style_order: style 变量的类别顺序。
- x_bins, y_bins: 是否对 x 轴和 y 轴进行分箱处理,以便对数据进行聚合。
- latitude, longitude: 如果数据是地理坐标,则设置这两个参数为 True。
- legend: 图例的显示方式,可以是 ‘auto’(自动选择最佳位置)或指定图例的位置。
- ax: 用于绘制图形的 matplotlib Axes 对象。如果没有提供,则使用当前活动的 Axes 对象。
- **kwargs: 其他关键字参数,这些参数将传递给 matplotlib 的 scatter 函数。
#导入数据
df=pd.DataFrame(data={'销售日期': pd.date_range('20231101',periods=30),
'销售数': np.random.randint(low=100,high=1000,size=30),
'销售单均': np.random.randint(low=50,high=100,size=30),
'销售成本': np.random.randint(low=500,high=1000,size=30),
'商品品类': random_categories}
)
df['日期'] = df['销售日期'].dt.day # 提取日期中的日数据
df['销售额']=df['销售数']*df['销售单均']
df['利润']=df['销售额']-df['销售成本']
df.head()
| 销售日期 | 销售数 | 销售单均 | 销售成本 | 商品品类 | 日期 | 销售额 | 利润 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 846 | 99 | 795 | 电脑硬件 | 1 | 83754 | 82959 |
| 1 | 2023-11-02 | 435 | 77 | 637 | 电脑硬件 | 2 | 33495 | 32858 |
| 2 | 2023-11-03 | 768 | 86 | 725 | 厨房电器 | 3 | 66048 | 65323 |
| 3 | 2023-11-04 | 929 | 59 | 645 | 家装饰品 | 4 | 54811 | 54166 |
| 4 | 2023-11-05 | 222 | 98 | 901 | 厨房电器 | 5 | 21756 | 20855 |
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
# 绘制散点图
sns.scatterplot(x='销售数',y='销售额',data=df)
<Axes: xlabel='销售数', ylabel='销售额'>

2.Seaborn统计图表
Seaborn的统计图表提供了多种丰富的图表类型,这些图表不仅具有高度的可视化效果,更重要的是它们被设计用于数据的探索分析。数据的探索分析是数据分析的初步阶段,它可以帮助分析者了解数据的基本特性、分布规律、变量之间的关系等,为后续的高级统计分析打下基础。
比如,Seaborn中的核密度估计图可以帮助学习者观察连续变量的分布形态,而小提琴图则在此基础上加入了箱线图的元素,同时显示数据的分布和概率密度。此外,Seaborn还提供了一系列的成对关系图,如成对散点图、成对箱线图等,这些图表可以一次性展示多个变量之间的两两关系,为学习者提供了一个快速探索多维数据的途径。
经管专业的学习者通过学习和运用Seaborn的统计图表,可以进行更为深入和系统的数据探索分析。这种分析方法不仅能够帮助他们更好地理解自己的数据,还能为后续的高级统计建模提供有价值的参考。
2.1小提琴图
**violinplot():**用于绘制小提琴图。可小提琴图可以表示数据的密度,数据的密度越大的区域越胖。“小提琴”形状表示数据的核密度估计,每个点的形状宽度表示该点的数据密度。
函数签名:
seaborn.violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, bw=‘scaled’, cut=2, scale=‘area’, scale_leaves=True, width=0.8, inner=‘box’, split=False, dodge=True, orient=None, linewidth=None, color=None, palette=None, saturation=0.75, width_ratio=0.6, ax=None, **kwargs)
参数解释:
- x, y, hue, data: 用于指定数据的参数,类似于其它 Seaborn 函数。
- order, hue_order: 用于指定类别顺序的参数。
- bw: 用于指定核密度估计的带宽,可以是 ‘scaled’(默认值,表示使用数据的自动缩放带宽)或浮点数。
- cut: 在小提琴图的哪一部分绘制箱线图。默认值为2,表示在小提琴图的内部绘制箱线图。
- scale: 用于指定小提琴图面积缩放方式的参数,可以是 ‘area’(默认值,表示所有小提琴图的面积相等)或 ‘count’(表示小提琴图的面积与数据点数量成比例)。
- scale_leaves: 布尔值,表示是否对分组的小提琴图进行面积缩放。
- width: 小提琴图的宽度。
- inner: 小提琴图内部的绘制方式,可以是 ‘box’,‘quartile’,‘point’,‘stick’,None 等。
- split: 布尔值,表示是否将小提琴图分为多个部分(当 hue 参数不为 None 时有效)。
- dodge: 布尔值,表示是否错开分组的小提琴图。
- orient: 用于指定数据方向的参数,可以是 ‘v’ 或 ‘h’,分别表示垂直和水平方向。
- linewidth, color: 用于指定小提琴图边框的线宽和颜色。
- palette: 用于指定调色板的参数。
- saturation: 用于指定颜色饱和度的参数。
- width_ratio: 小提琴图与箱线图宽度的比例。
- ax: 用于绘制图形的 matplotlib Axes 对象。如果没有提供,则使用当前活动的 Axes 对象。
- **kwargs: 其他关键字参数将传递给底层绘图函数。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
# 绘制小提琴图
sns.violinplot(x='商品品类',y='销售额',data=df)
<Axes: xlabel='商品品类', ylabel='销售额'>

import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
# 绘制小提琴图
sns.violinplot(x='销售额',y='商品品类',data=df)
<Axes: xlabel='销售额', ylabel='商品品类'>

2.2点图
**pointplot():**用于绘制热图。点图是一种统计图表,用于显示一组数据及其变异性的平均值或集中趋势。点图通常用于探索性数据分析,可以快速可视化数据集的分布或比较多个数据集。
函数签名:
seaborn.pointplot(x=None,y=None,hue=None,data=None,order=None,hue_order=None,estimator=‘mean’,ci=95,n_boot=1000,units=None,markers=‘o’,linestyles=‘-’,dodge=False,join=True,scale=1,orient=None,color=None,palette=None,errwidth=None,capsize=None,ax=None, **kwargs)
参数解释:
- x, y, hue, data: 用于数据映射的变量名和数据集。
- order, hue_order: 控制类别级别的顺序。
- estimator: 在每个分类级别上调用的统计函数,默认为mean,即计算均值。
- ci: 置信区间的大小,或者如果为None,则不绘制置信区间。
- n_boot: 用于计算置信区间的bootstrap迭代次数。
- units: 分组数据的标识变量,如果提供,则会在每个x水平的位置上为units的每个级别绘制一个点。
- markers: 点的标记样式。
- linestyles: 线的样式。
- dodge: 是否沿着分类轴移动点以避免重叠。
- join: 是否在点之间绘制线。
- scale: 点的大小缩放因子。
- orient: 控制是水平还是垂直绘制点图。
- color: 点的颜色。
- palette: 用于hue变量的颜色映射。
- errwidth: 置信区间的宽度。
- capsize: 置信区间帽的大小。
- ax: 用于绘制图形的matplotlib轴。
- **kwargs: 其他关键字参数将传递给plt.scatter或plt.plot,用于控制点的样式。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.pointplot(x='商品品类',y='销售数',data=df,linestyles='--',markers ='o',color='r')
<Axes: xlabel='商品品类', ylabel='销售数'>

2.3分簇散点图
**swarmplot():**用于绘制分簇散点图。分簇散点图与条形图相似,但是它会修改一些点以防止重叠,这有助于更好地表示值的分布。在该图中,每个数据点表示为一个点,并且这些点的排列使得它们在分类轴上不会相互重叠。
函数签名:
seaborn.swarmplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, size=5, edgecolor=“gray”, linewidth=0, ax=None, **kwargs)
参数解释:
- x, y: 数据中的变量名,对应于x轴和y轴的值。
- hue: 数据中的变量名,用于给散点上色。
- data: 包含数据的DataFrame对象,如果没有提供x,y,hue参数,则需要提供此参数。
- order, hue_order: 用于排序分类级别的顺序。
- orient: 绘图的方向,可以是"v"或"h",默认为"v",表示垂直方向。
- color: 散点的颜色。
- palette: 用于hue参数的颜色映射。
- size: 散点的大小。
- edgecolor: 散点边缘的颜色。
- linewidth: 散点边缘的线宽。
- ax: matplotlib的子图对象,如果没有提供,则使用当前活动的子图。
- **kwargs: 其他关键字参数,用于控制散点的样式。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.swarmplot(x='销售数',y='商品品类',data=df,hue='商品品类',dodge=True,orient='h',size=8)
<Axes: xlabel='销售数', ylabel='商品品类'>

2.4回归图
**lmplot():**用于绘制回归图。lmplot() 是一个在Python的数据可视化库seaborn中的函数,用于绘制线性模型图,也就是回归图。这个函数主要用于探索两个变量之间的关系,并可以拟合一个线性回归模型。
函数签名:
seaborn.lmplot(x, y, data, hue=None, col=None, row=None, palette=None, hue_order=None, col_order=None, row_order=None, aspect=1, height=5, scatter_kws=None, line_kws=None, lowess_kws=None, robust_kws=None, ci=95, n_boot=1000, fit_reg=True, scatter=True, size=None, sizes=(10, 10), color=None, legend=True, legend_out=True, x_estimator=None, x_bins=None, x_ci=‘ci’, scatter_func=<function scatterplot at 0x7f6e0d1bf4c0>, truncate_mode=‘outliers’, truncate_func=<function mad at 0x7f6e0c738550>, sharex=False, sharey=False, ax=None, **kwargs)
参数解释:
- x, y: 数据集中的变量名,用于绘制线性关系。
- data: 包含数据的pandas DataFrame对象。
- hue: 数据集中的变量名,用于区分不同类别的数据点。
- col, row: 用于在多个子图中绘制数据的变量名。
- palette: 用于hue参数的颜色映射。
- aspect: 子图的宽高比。
- height: 子图的高度。
- scatter_kws: 传递给scatterplot的关键字参数,用于控制散点的样式。
- line_kws: 传递给regplot的关键字参数,用于控制线性拟合线的样式。
- lowess_kws: 用于控制LOWESS平滑的参数。
- robust_kws: 用于控制鲁棒线性拟合的参数。
- ci: 置信区间的大小。
- n_boot: 计算置信区间时的bootstrap迭代次数。
- fit_reg: 是否拟合线性回归模型。
- scatter: 是否绘制散点图。
- size, sizes: 控制散点大小的参数。
- color: 控制散点颜色的参数。
- legend: 是否绘制图例。
- legend_out: 是否将图例放在图的外部。
- x_estimator: 用于估计x值的函数。
- x_bins: 用于分箱的x值的数量。
- x_ci: 用于计算x的置信区间的类型。
- truncate_mode: 用于处理离群点的模式。
- truncate_func: 用于确定离群点的函数。
- sharex, sharey: 是否共享x轴或y轴。
- ax: matplotlib的Axes对象,用于绘制图形。
- **kwargs: 控制其他图形属性的参数。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.lmplot(x="销售数",y="销售额",data=df)
<seaborn.axisgrid.FacetGrid at 0x2745c5e1610>
<Figure size 900x600 with 0 Axes>

⏳跟练题目3
✍跟练3:假如你是一名数据分析师,现在需要研究销量的累计和趋势,同时做销售量回归分析用来预测未来的销售趋势,Seaborn中的回归图可对销售量进行回归分析,探究销量与其他变量之间的关系,请使用代码完成回归图的创建,要求包含基本的图表元素。
💡 提示:模拟生成一组sale销量数据如下,cumsum()可计算销量的累计和,sns.lmplot()可做回归图,做出来的图表应与下面的图表类似。
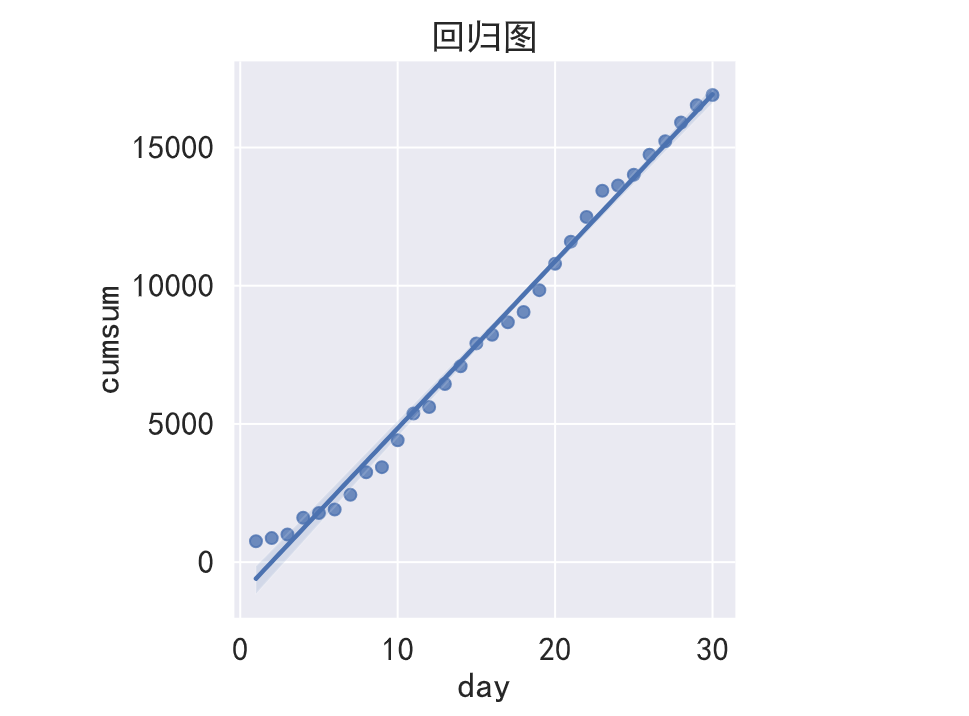
import pandas as pd
import numpy as np
df=pd.DataFrame({'date':pd.date_range('20231101',periods=30),
'sale':np.random.randint(100,1000,size=30)})
df['day']=df['date'].dt.day
df['cumsum']=df['sale'].cumsum()#可求累计和
df.head()
| date | sale | day | cumsum | |
|---|---|---|---|---|
| 0 | 2023-11-01 | 202 | 1 | 202 |
| 1 | 2023-11-02 | 671 | 2 | 873 |
| 2 | 2023-11-03 | 708 | 3 | 1581 |
| 3 | 2023-11-04 | 658 | 4 | 2239 |
| 4 | 2023-11-05 | 523 | 5 | 2762 |
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.lmplot(x="day",y="cumsum",data=df)
# 设置 x 轴,y 轴
plt.xticks(ticks=np.arange(0, 31, 10), labels=np.arange(0, 31, 10))
plt.yticks(ticks=np.arange(0, 20001, 5000), labels=np.arange(0, 20001, 5000))
([<matplotlib.axis.YTick at 0x2745c660790>,
<matplotlib.axis.YTick at 0x2745c6605e0>,
<matplotlib.axis.YTick at 0x2745c695eb0>,
<matplotlib.axis.YTick at 0x2745c6902e0>,
<matplotlib.axis.YTick at 0x2745c690880>],
[Text(0, 0, '0'),
Text(0, 5000, '5000'),
Text(0, 10000, '10000'),
Text(0, 15000, '15000'),
Text(0, 20000, '20000')])
<Figure size 900x600 with 0 Axes>

2.5联合分布图
**jointplot(():**用于绘制联合分布图。联合分布图将两个不同的图组合在一个表示中,可以展示两个变量之间的关系(二元关系)。
函数签名:
seaborn.jointplot(x, y, data=None, kind=‘scatter’, stat_func=None, color=None, height=6, ratio=5, space=.2, dropna=True, xlim=None, ylim=None, joint_kws=None, marginal_kws=None, annot_kws=None, **kwargs)
参数解释:
- x, y: 数据集中的变量名,这两个变量之间的关系将在图中展示。
- data: 包含数据的DataFrame对象,如果没有提供x和y的参数,则需要提供此参数。
- kind: 绘制类型,可以是’scatter’,‘hex’,‘kde’,‘reg’,‘resid’。这决定了在中心区域显示什么样的图。
- stat_func: 统计函数,用于计算在图上显示的统计信息。默认为None,即不进行统计计算。
- color: 图的颜色。
- height: 图的高度,默认为6。
- ratio: 中心图与侧边图的比例,越大,中心图占比越大,默认为5。
- space: 中心图与侧边图的间隔大小,默认为0.2。
- dropna: 是否删除含有NaN的数据,默认为True。
- xlim, ylim: x轴和y轴的范围,默认为None,表示使用数据的自动范围。
- joint_kws: 传递给jointplot在中心区域的额外关键字参数。
- marginal_kws: 传递给jointplot在边际区域的额外关键字参数。
- annot_kws: 传递给注释的额外关键字参数。
- **kwargs: 其他关键字参数。
#导入数据
df=pd.DataFrame(data={'销售日期': pd.date_range('20231101',periods=30),
'销售数': np.random.randint(low=100,high=1000,size=30),
'销售单均': np.random.randint(low=50,high=100,size=30),
'销售成本': np.random.randint(low=500,high=1000,size=30),
'商品品类': random_categories}
)
df['日期'] = df['销售日期'].dt.day # 提取日期中的日数据
df['销售额']=df['销售数']*df['销售单均']
df['利润']=df['销售额']-df['销售成本']
df.head()
| 销售日期 | 销售数 | 销售单均 | 销售成本 | 商品品类 | 日期 | 销售额 | 利润 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 858 | 52 | 563 | 电脑硬件 | 1 | 44616 | 44053 |
| 1 | 2023-11-02 | 385 | 86 | 544 | 电脑硬件 | 2 | 33110 | 32566 |
| 2 | 2023-11-03 | 874 | 65 | 976 | 厨房电器 | 3 | 56810 | 55834 |
| 3 | 2023-11-04 | 506 | 76 | 944 | 家装饰品 | 4 | 38456 | 37512 |
| 4 | 2023-11-05 | 667 | 57 | 750 | 厨房电器 | 5 | 38019 | 37269 |
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.jointplot(x="销售数", y="销售额",data=df)
<seaborn.axisgrid.JointGrid at 0x27457ac69d0>
<Figure size 900x600 with 0 Axes>

2.6分类散点图
**catplot():**用于绘制分类散点图。cat图(分类图的缩写)是Seaborn中的定制的一种图,它可以可视化数据集中一个或多个分类变量与连续变量之间的关系。它可用于显示分布、比较组或显示不同变量之间的关系。
函数签名:
seaborn.catplot(x=None,y=None,hue=None,data=None,row=None,col=None,order=None,hue_order=None,row_order=None,col_order=None,kind=‘point’,height=5,aspect=1,orientation=None,color=None,palette=None,legend=True,legend_out=True,sharex=True,sharey=True,margin_titles=False,facet_kws=None,**kwargs)
参数解释:
- x, y, hue: 数据中的变量名,用于绘图。x和y分别代表横纵坐标,hue用于区分不同类别的数据点。
- data: 包含数据的 DataFrame 对象。如果没有提供 x,y,hue 参数,则需要提供此参数。
- row, col: 用于创建子图的变量名,分别表示行和列。
- order, hue_order, row_order, col_order: 用于排序分类级别的顺序。
- kind: 绘制图形的类型,例如 ‘point’, ‘bar’, ‘strip’, ‘swarm’, ‘box’, ‘violin’, 或 ‘boxen’。
- height: 创建的子图的高度。
- aspect: 子图的宽度与高度的比例。
- orientation: 方向,可以是 ‘v’ 或 ‘h’,表示垂直或水平方向。这个参数在一些特定的图形类型中起作用。
- color: 图形的颜色。
- palette: 用于 hue 参数的颜色映射。
- legend: 是否显示图例。
- legend_out: 是否将图例放在图的外部。
- sharex, sharey: 是否共享 x 轴或 y 轴。
- margin_titles: 是否在子图的边缘显示标题。
- facet_kws: 传递给子图的其他关键字参数。
- **kwargs: 控制其他图形属性的参数,这些参数会传递给具体的绘图函数(如 plt.scatter,plt.bar 等)。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.catplot(data=df, x="销售数", y="商品品类",hue='商品品类')
<seaborn.axisgrid.FacetGrid at 0x2745cf147f0>
<Figure size 900x600 with 0 Axes>

2.7散点图矩阵
**pairplot():**用于绘制散点图矩阵。散点图矩阵可视化了数据集中几个变量之间的成对关系。它创建了一个坐标轴网格,这样所有数值数据点将在彼此之间创建一个图,在x轴上具有单列,y轴上具有单行。对角线图是单变量分布图,它绘制了每列数据的边际分布。
函数签名:
seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, diag_kind=‘auto’, markers=‘o’, plot_kws=None, diag_kws=None, kwargss=None, dropna=True, ax=None)
参数解释:
- data: 包含数据的DataFrame对象。
- hue: 数据中的变量名,用于区分不同类别的数据点,会给不同类别的点赋予不同的颜色。
- hue_order: 用于排序hue参数指定的分类级别的顺序。
- palette: 用于hue参数的颜色映射。
- vars: 需要在图中显示的变量的列表。
- x_vars: 作为x轴的变量的列表。
- y_vars: 作为y轴的变量的列表。
- diag_kind: 对角线上的图的类型。可以是’hist’(直方图),‘kde’(核密度估计),或’reg’(线性回归)。默认为’auto’,即根据变量的类型自动选择。
- markers: 用于散点图的标记样式。
- plot_kws: 传递给散点图的关键字参数。
- diag_kws: 传递给对角线图的关键字参数。
- kw_color: 传递给颜色关键词的参数。
- kwargss: Dictionary of keyword arguments for each level of the hue variable in the plot.
- dropna: 是否删除含有NaN的数据点,默认为True。
- ax: matplotlib的Axes对象数组,用于绘制图形,如果没有提供,则使用当前活动的子图。
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
#魔法命令,用于在笔记本内联显示matplotlib图表
# %matplotlib inline
# #确保图表以SVG格式显示
# %config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (9, 6)) #设置图表画布大小
sns.pairplot(data=df[['销售数','销售单均','销售成本','销售额','利润','商品品类']],hue='商品品类')
<seaborn.axisgrid.PairGrid at 0x2745cfa6a90>
<Figure size 900x600 with 0 Axes>

三、闯关题
STEP1: 按照要求计算下方题目结果
⛳️闯关题目:电商销售量和销售额的回归分析
假如你是一家电商公司的数据分析师,想要探究销售量与销售额之间的关系。为了做这一分析,你需要使用pandas生成一组模拟的销售量和销售额数据,然后使用seaborn制作回归图,并计算相关的回归统计量,根据上面生成的回归系数等得出一个回归方程,从而根据销售量数据预测销售额达成。
💡题目提示:
- 使用pandas生成电商销售量和销售额的模拟数据。
- 使用seaborn制作销售量与销售额的回归图。
- 计算回归系数、R方等统计量。
- 得出回归方程,并解释其含义。
- 解释回归系数在经管专业中的意义。
📚回归统计量解释
- slope (斜率): 它是回归线的斜率,也称为回归系数。
- intercept (截距): 这是回归线与y轴的交点。
- r_value (相关系数): 这是皮尔逊相关系数的值,它衡量了两个变量之间的线性关系的强度和方向。它的值范围在-1到1之间。1表示完全的正相关,-1表示完全的负相关,0表示没有线性关系。
- p_value (p值): 这是检验回归线斜率是否显著不为零的p值。如果p值小于某个显著性水平(如0.05),则我们可以拒绝原假设(斜率为零),认为销售量与销售额之间存在显著的线性关系。
- std_err (标准误差): 这是估计的斜率的标准误差。它衡量了斜率估计值的不确定性。标准误差越大,意味着斜率估计值的不确定性越大。
请使用下面的代码模拟生成销售量和销售额数据,根据销售量和销售额数据做回归分析。
#请使用下面的代码模拟生成销售量和销售额数据
import pandas as pd
# 销售量数据
sales_volume = [1854, 1871, 1996, 1754, 689, 1748, 1908, 1900, 1806, 1132,
1127, 1472, 1782, 1882, 1209, 1979, 1934, 1148, 817, 1748,
1757, 1183, 1163, 1897, 1995, 1756, 1636, 941, 1063, 1791,
1909, 1910, 1636, 1451, 1604, 1198, 612, 501, 1141, 719,
1354, 1748, 884, 1926, 1653, 1576, 1229, 1939, 746, 1335]
# 销售额数据
sales_amount = [3080, 4189, 3960, 5448, 1681, 6060., 4383, 5952, 5592, 2039,
2835, 4256, 5732, 4049, 2346, 5783, 6032, 2522, 1382, 5910,
4032, 2999, 3693, 5409, 5926, 3368, 4225, 2720, 2080, 3313,
6613, 4838, 3307, 5067, 5503, 3134, 1998, 940, 2347, 2085,
4323, 5615, 2041, 6308, 5292, 5313, 3773, 5502, 1985, 2996]
df = pd.DataFrame({'销售量': sales_volume, '销售额': sales_amount})
df.head()
| 销售量 | 销售额 | |
|---|---|---|
| 0 | 1854 | 3080.0 |
| 1 | 1871 | 4189.0 |
| 2 | 1996 | 3960.0 |
| 3 | 1754 | 5448.0 |
| 4 | 689 | 1681.0 |
以下代码可生成销售量和销售额的回归统计量
#以下代码可生成销售量和销售额的回归统计量
from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(df['销售量'], df['销售额'])
# 下面这里写入你的代码
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import stats
# 生成模拟的销售量和销售额数据
sales_volume = [1854, 1871, 1996, 1754, 689, 1748, 1908, 1900, 1806, 1132,
1127, 1472, 1782, 1882, 1209, 1979, 1934, 1148, 817, 1748,
1757, 1183, 1163, 1897, 1995, 1756, 1636, 941, 1063, 1791,
1909, 1910, 1636, 1451, 1604, 1198, 612, 501, 1141, 719,
1354, 1748, 884, 1926, 1653, 1576, 1229, 1939, 746, 1335]
sales_amount = [3080, 4189, 3960, 5448, 1681, 6060., 4383, 5952, 5592, 2039,
2835, 4256, 5732, 4049, 2346, 5783, 6032, 2522, 1382, 5910,
4032, 2999, 3693, 5409, 5926, 3368, 4225, 2720, 2080, 3313,
6613, 4838, 3307, 5067, 5503, 3134, 1998, 940, 2347, 2085,
4323, 5615, 2041, 6308, 5292, 5313, 3773, 5502, 1985, 2996]
df = pd.DataFrame({'销售量': sales_volume, '销售额': sales_amount})
# 使用seaborn制作回归图
sns.lmplot(x='销售量', y='销售额', data=df, scatter_kws={'color': 'blue'}, line_kws={'color': 'red'})
plt.title('销售量与销售额的回归图')
plt.show()
# 计算回归系数、R方等统计量,并得出回归方程
slope, intercept, r_value, p_value, std_err = stats.linregress(df['销售量'], df['销售额'])
print("回归系数 (斜率):", slope)
print("截距:", intercept)
print("R方值:", r_value**2)
print("p值:", p_value)
print("标准误差:", std_err)
print("回归方程:", f"销售额 = {slope} × 销售量 + {intercept}" )

回归系数 (斜率): 2.9910100883568944
截距: -427.7133125841078
R方值: 0.7008800732888629
p值: 3.5718222278407785e-14
标准误差: 0.28203179771586495
回归方程: 销售额 = 2.9910100883568944 × 销售量 + -427.7133125841078
q1:使用以上销售量和销售额数据做回归分析,得出回归系数(斜率),保留两位小数,并把结果赋值给a1。
a1 = round(slope, 2)
a1
2.99
#使用以上销售量和销售额数据做回归分析,得出回归系数(斜率)
# a1= #在=后填入回归系数(斜率),保留两位小数,比如2.98
q2:使用以上销售量和销售额数据做回归分析,得出R方值,保留一位小数,并把结果赋值给a2。
a2 = round(r_value**2, 1)
a2
0.7
#使用以上销售量和销售额数据做回归分析,得出R方值
# a2= #在=后填入R方值,保留一位小数,比如0.8
q3:使用以上销售量和销售额数据做回归分析,判断销售量与销售额之间是否存在显著性,选择正确的选项,并把选项赋值给a3。
- A:显著
- B:不显著
根据前面的回归分析,p 值为 3.5718222278407785e-14<0.05,因此销售量与销售额之间存在显著性关系。
#使用以上销售量和销售额数据做回归分析,判断销售量与销售额之间是否存在显著性
a3='A' #在=后根据P值判断销售量与销售额之间是否存在显著的线性关系。可选项,A:'显著'、B:'不显著'
a3
'A'


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









