






(1)分享在CSS2021上看的比较相关的paper
- Cert-RNN: Towards Certifying the Robustness of Recurrent Neural Networks, 认证方向,应用在两种RNNs模型(RNN, LSTM)上。本能感觉认证可以和攻击防御结合,当然本文也是这样做的。
- Locally Private Graph Neural Networks, 基于差分隐私的图网络隐私保护计算,和我做的隐私保护计算方向契合,但是我不做差分隐私,之前想过做GNN的隐私保护计算,也是为了做而做。之前也不熟悉图网络,还要好好学一下~
现在结合攻击防御方面的论文挺多的,单纯的隐私保护计算的工作少了。
(2) NDSS2021
- POSEIDON: Privacy-Preserving Federated Neural Network Learning.
- Practical Non-Interactive Searchable Encryption with Forward and Backward Privacy.
近期准备总结一下机器学习算法和密码学结合的论文:
- 朴素贝叶斯(Naive Bayes)
最新的一篇,2022年发表在TIFS上的Fast Privacy-Preserving Text Classification Based on Secure Multiparty Computation,作者声明 We propose the first privacy- preserving Naive Bayes classifier with private feature extraction,previous works assumed the features to be publicly known. 印象中有做NB算法外包计算的,但是竟然做的那么浅,特征都不能保护,估计更多人集中做deep learning外包而“看不上”传统机器学习算法。 可惜文本分类不太懂,估计要多花时间才能看懂了。
朴素贝叶斯原理:基于贝叶斯定理和特征条件独立假设多分类方法。基于特征条件独立假设学习到输入输出到联合概率分布,然后利用贝叶斯定理求出后验概率最大的输出。(摘)
P(c|x)=P(x|c)P(\c)/P(x), 把P(x)看作常数, 假设有输入向量X=(x1,x2,…,xd), c表示类别,
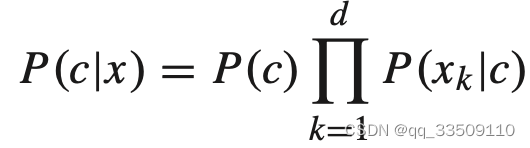
然后再取对数
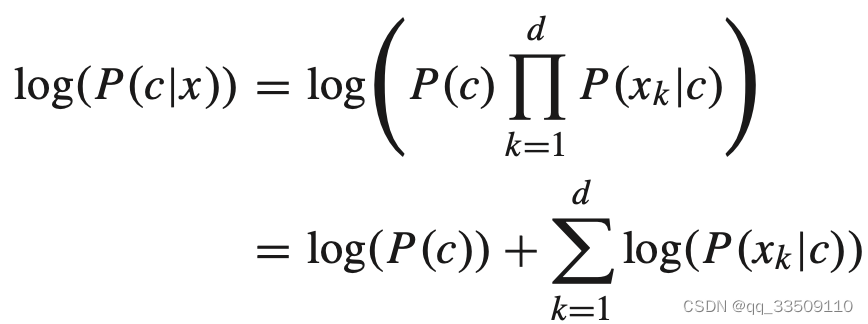
最后求最大值对应的类
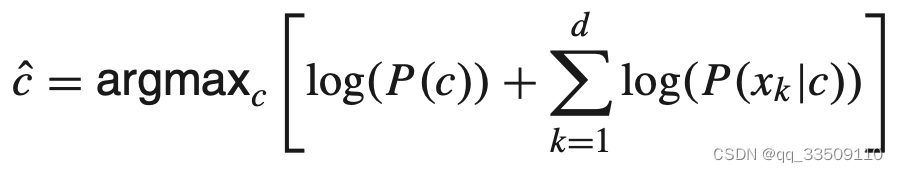
1-1. NB安全协议:
(1) 基于秘密共享的加乘运算,乘法也是Beaver三元组设计;
(2) 安全相等比较,按照二进制逐位加设计协议;
(3) 特征提取,也就是判断Bob拥有Alice的哪些“词”,用到相等判断协议;
(4) 进制转换,前面1-3都是在二进制上进行,然后现在需要转换,为了后面进行乘法运算,这部分算法相当于约定俗成,利用逻辑电路;
(5) 安全比特提取,我也没明白这个协议的作用,这部分感觉也是已有算法的引用(设计这协议的人真是天才,看不懂);
(6) 安全大小比较,利用最高有效位判断,也是比较常见的方法; - 决策树
决策树算法是基本的分类和回归算法,决策树学习通常包括三个步骤:特征选择,决策树生成和决策树修剪。
(1) ID3算法
核心是根据信息增益选择特征,选择信息增益最大的作为根节点,直到所有特征的信息增益极小或为0停止选择,相当于用极大似然法进行概率模型选择。信息增益g(D,A)=H(D)-H(D|A)。不能剪枝,存在过拟合问题。
(2) C4.5
类似于ID3,不同的是采用信息增益比选择特征。
(3) Cart算法
回归树:基于最小二乘回归生成树;
分类树:基于基尼系数生成树。
总结:选择信息增益大,信息增益比大和基尼指数最小最为特征选择准则。
2-1. 隐私保护决策树协议
比较新的是2022年发表在ACM Trans. 上的Privacy-Preserving Decision Trees Training and Prediction
基于全同态加密和多项式近似。通信复杂度和树深度和数据大小无关。 - 隐马尔可夫模型
比较新的是2022年发表在TSC的Privacy-Preserving Classification in Multiple clouds eHealthcare,基于希尔密码做的,没想到传统的代换密码也有发挥的余地,可能在HMM模型中比较适用。另外这个模型做的工作挺少的。HMM包含三个功能,这篇论文是实现的Evaluation功能。
Evaluation:


前向算法和后向算法是为了解决原算法复杂度过高的问题,把笔记留着方便以后看~
4. K-means聚类
TDSC2022上的《Privacy-Preserving and Outsourced Multi-party K-means Clustering based on Multi-key Fully Homomorphic Encryption》基于多密钥同态加密算法设计K-means聚类外包方案,本身K-means算法不复杂,可以分为四步:1) 首先随机选取k个样本点作为中心点;2) 计算每个样本和k个中心点的欧氏距离,比较大小并排序,得到k个聚类簇;3) 通过计算每个簇中样本点的均值得到新中心点;4) 更新簇的中心点直到最大迭代次数。第一次接触多密钥同态加密算法,计算原理还不明白。如果根据功能,可以用在多方安全计算和联邦学习任务中,本文也是直接引用并简单介绍。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









