







学号后三位:492 张涛磊
“原创作品转载请注明出处 + https://github.com/mengning/linuxkernel/ ”
一、程序是如何运行起来的?
(1)在内存中划出一片内存空间;
(2)将硬盘上可执行文件中的代码(机器指令)拷贝到划出的内存空间中;
(3)pc指向第一条指令,cpu取指执行。
当有OS时,以上过程肯定都是通过相应的API来实现的。
在Linux下,OS提供两个非常关键的API,一个是fork,另一个是exec。
fork : 开辟出一块内存空间
exec : 将程序代码(机器指令)拷贝到开辟的内存空间中,并让pc指向第一条指令,cpu开始执行,进程就运行起来了,运行起来的进程会与其它的进程切换着并发运行。
二、fork
1.函数原型
#include <unistd.h>
pid_t fork(void);
2.函数功能
从调用该函数的进程复制出子进程,被复制的进程则被称为父进程,复制出来的进程称为子进程。
复制后有两个结果:
1)依照父进程内存空间样子,原样复制地开辟出子进程的内存空间;
2)由于子进程的空间是原样复制的父进程空间,因此子进程内存空间中的代码以及数据和父进程完全相同。
其实,复制父进程的主要目的,就是为了复制出一块内存空间,只不过复制的附带效果是,子进程原样地拷贝了一份父进程的代码和数据,事实上复制出子进程内存空间的主要目的,其实是为了exec加载新程序的代码。
3.函数参数
无参数。
4.函数返回值
由于子进程原样地复制了父进程代码,因此父子进程都会执行fork函数,当然这个说法有些欠妥,但暂时可以这么理解。
1)父进程的fork, 成功返回子进程的PID,失败返回-1,errno被设置。
2)子进程的fork, 成功返回0,失败返回-1,errno被设置。
5.复制的原理
Linux有虚拟内存机制,所以父进程是运行在虚拟内存上的,虚拟内存是OS通过数据结构基于物理内存模拟出来的,因此底层对应的还是物理内存。
复制子进程时,会复制父进程的虚拟内存数据结构,那么就得到了子进程的虚拟内存,相应的底层会应对着一片新的物理内存空间,里面放了与父进程一模一样的代码和数据。
6.fork实验
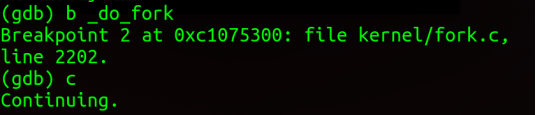
(1)在_do_fork处设置断点,然后运行
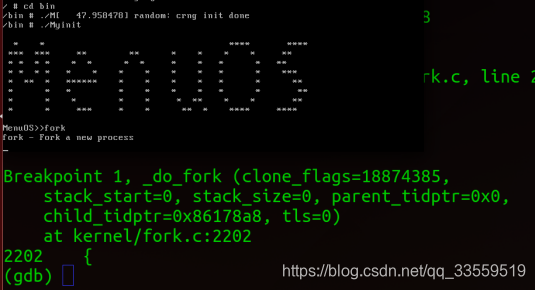
(2)运行MenuOS,执行fork
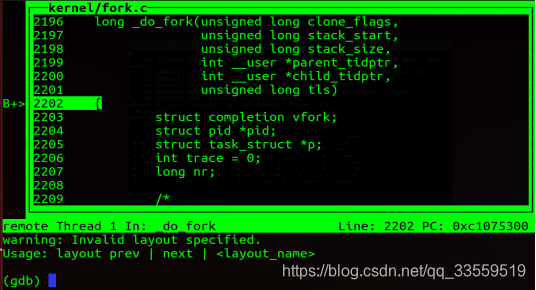
输入layout命令,显示程序代码
(3)输入bt命令,列出调用栈
可以看出,在执行了MenuOS中执行了fork后,具体执行流程是(5.0内核):
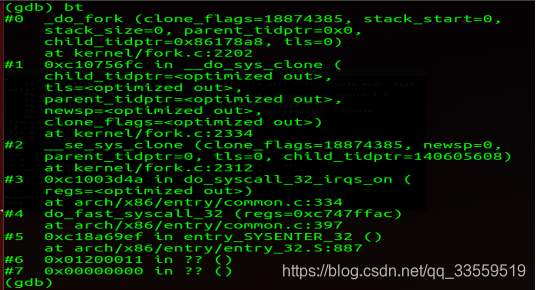
entry_SYSENTER_32 ()
--->do_fast_syscall_32 (regs=0xc747ffac)
--->do_syscall_32_irqs_on (regs=<optimized out>)
--->__se_sys_clone (clone_flags=18874385, newsp=0,parent_tidptr=0,
tls=0, child_tidptr=140605608)
--->__do_sys_clone (
child_tidptr=<optimized out>,
tls=<optimized out>,
parent_tidptr=<optimized out>,
newsp=<optimized out>,
clone_flags=<optimized out>)
--->_do_fork (clone_flags=18874385, stack_start=0,
stack_size=0, parent_tidptr=0x0,
child_tidptr=0x86178a8, tls=0)
(4)分析_do_fork
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
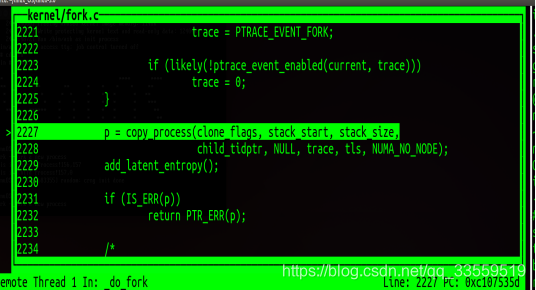
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
add_latent_entropy();
if (IS_ERR(p))
return PTR_ERR(p);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
trace_sched_process_fork(current, p);
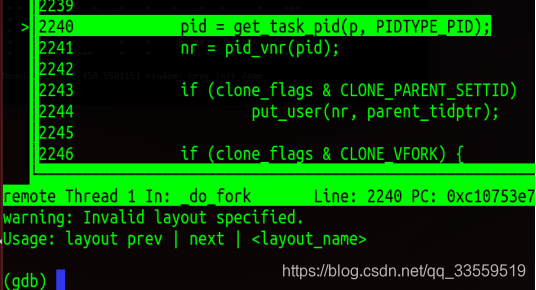
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
return nr;
}
#ifndef CONFIG_HAVE_COPY_THREAD_TLS
/* For compatibility with architectures that call do_fork directly rather than
* using the syscall entry points below. */
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
return _do_fork(clone_flags, stack_start, stack_size,
parent_tidptr, child_tidptr, 0);
}
#endif
新版本的系统中clone的TLS设置标识会通过TLS参数传递, 因此_do_fork替代了老版本的do_fork。老版本的do_fork只有在如下情况才会定义:
- 只有当系统不支持通过TLS参数通过参数传递而是使用pt_regs寄存器列表传递时
- 未定义CONFIG_HAVE_COPY_THREAD_TLS宏
函数参数说明:
| 参数 | 描述 |
|---|---|
| clone_flags | 与clone()参数flags相同, 用来控制进程复制过的一些属性信息, 描述你需要从父进程继承那些资源。该标志位的4个字节分为两部分。最低的一个字节为子进程结束时发送给父进程的信号代码,通常为SIGCHLD;剩余的三个字节则是各种clone标志的组合(本文所涉及的标志含义详见下表),也就是若干个标志之间的或运算。通过clone标志可以有选择的对父进程的资源进行复制; |
| stack_start | 与clone()参数stack_start相同, 子进程用户态堆栈的地址 |
| stack_size | 用户状态下栈的大小, 该参数通常是不必要的, 总被设置为0 |
| parent_tidptr | 与clone的ptid参数相同, 父进程在用户态下pid的地址,该参数在CLONE_PARENT_SETTID标志被设定时有意义 |
| child_tidptr | 与clone的ctid参数相同, 子进程在用户太下pid的地址,该参数在CLONE_CHILD_SETTID标志被设定时有意义 |
| tls | Thread Local Storage,clone的标识CLONE_SETTLS接受一个参数来设置线程的本地存储区 |
进入copy_process函数,复制进程描述符如果所有必须的资源都是可用的,该函数返回刚创建的task_struct描述符的地址。
如果是 vfork(设置了CLONE_VFORK和ptrace标志),就将父进程插入等待队列直到子进程调用exec函数或退出。
获得task结构体中的pid
pid = get_task_pid(p, PIDTYPE_PID);
根据pid结构体获得进程pid
nr = pid_vnr(pid);
将子进程添加到调度器的队列,使之有机会获得CPU

wake_up_new_task(p);
return nr//返回子进程pid!!!
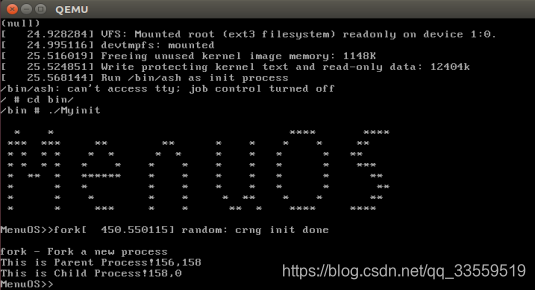
实验结果:
_do_fork总结:
主要完成了调用copy_process()复制父进程信息、获得pid、调用wake_up_new_task将子进程加入调度器队列等待获得分配CPU资源运行、通过clone_flags标志做一些辅助工作,其中cpoy_process()是创建一个进程内容的主要代码。
copy_process流程:
1.dup_task_struct()。分配一个新的进程控制块,包括新进程在kernel中的堆栈。新的进程控制块会复制父进程的进程控制块,但是因为每个进程都有一个kernel堆栈,新进程的堆栈将被设置成新分配的堆栈。
2.初始化一些新进程的统计信息,如此进程的运行时间
3.copy_semundo()复制父进程的semaphore undo_list到子进程。
4.copy_files()、copy_fs()。复制父进程文件系统相关的环境到子进程
5.copy_sighand()、copy_signal()。复制父进程信号处理相关的环境到子进程。
6.copy_mm()。复制父进程内存管理相关的环境到子进程,包括页表、地址空间和代码数据。
7.copy_thread()/copy_thread_tls。设置子进程的执行环境,如子进程运行时各CPU寄存器的值、子进程的kernel栈的起始地址。
8.sched_fork()。设置子进程调度相关的参数,即子进程的运行CPU、初始时间片长度和静态优先级等。
9.将子进程加入到全局的进程队列中
10.设置子进程的进程组ID和对话期ID等。
简单的说,copy_process()就是将父进程的运行环境复制到子进程并对某些子进程特定的环境做相应的调整。
三、execve实验
fork, vfork等复制出来的进程是父进程的一个副本, 现在想加载新的程序, 可以通过execve来加载和启动新的程序。
exec()函数族
exec函数一共有六个,其中execve为内核级系统调用,其他(execl,execle,execlp,execv,execvp)都是调用execve的库函数。
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg,...,char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
ELF文件格式以及可执行程序的表示
ELF可执行文件格式:
Linux下标准的可执行文件格式是ELF.ELF(Executable and Linking Format)是一种对象文件的格式,用于定义不同类型的对象文件(Object files)中都放了什么东西、以及都以什么样的格式去放这些东西。它自最早在 System V 系统上出现后,被 xNIX 世界所广泛接受,作为缺省的二进制文件格式来使用。
但是linux也支持其他不同的可执行程序格式, 各个可执行程序的执行方式不尽相同, 因此linux内核每种被注册的可执行程序格式都用linux_bin_fmt来存储, 其中记录了可执行程序的加载和执行函数。
同时我们需要一种方法来保存可执行程序的信息, 比如可执行文件的路径, 运行的参数和环境变量等信息,即linux_bin_prm结构。
struct linux_bin_prm结构描述一个可执行程序
inux_binprm是定义在include/linux/binfmts.h中, 用来保存要要执行的文件相关的信息, 包括可执行程序的路径, 参数和环境变量的信息。
struct linux_binprm {
char buf[BINPRM_BUF_SIZE];// 保存可执行文件的头128字节
#ifdef CONFIG_MMU
struct vm_area_struct *vma;
unsigned long vma_pages;
#else
# define MAX_ARG_PAGES 32
struct page *page[MAX_ARG_PAGES];
#endif
struct mm_struct *mm;
unsigned long p; /* current top of mem,当前内存页最高地址*/
unsigned long argmin; /* rlimit marker for copy_strings() */
unsigned int
/*
* True after the bprm_set_creds hook has been called once
* (multiple calls can be made via prepare_binprm() for
* binfmt_script/misc).
*/
called_set_creds:1,
/*
* True if most recent call to the commoncaps bprm_set_creds
* hook (due to multiple prepare_binprm() calls from the
* binfmt_script/misc handlers) resulted in elevated
* privileges.
*/
cap_elevated:1,
/*
* Set by bprm_set_creds hook to indicate a privilege-gaining
* exec has happened. Used to sanitize execution environment
* and to set AT_SECURE auxv for glibc.
*/
secureexec:1;
#ifdef __alpha__
unsigned int taso:1;
#endif
unsigned int recursion_depth; /* only for search_binary_handler() */
struct file * file;/* 要执行的文件 */
struct cred *cred; /* new credentials */
int unsafe; /* how unsafe this exec is (mask of LSM_UNSAFE_*) */
unsigned int per_clear; /* bits to clear in current->personality */
int argc, envc;/* 命令行参数和环境变量数目 */
const char * filename; /* Name of binary as seen by procps 要执行的文件的名称 */
const char * interp; /* Name of the binary really executed. Most
of the time same as filename, but could be
different for binfmt_{misc,script}要执行的文件的真实名称,通常和filename相同 */
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
struct rlimit rlim_stack; /* Saved RLIMIT_STACK used during exec. */
} __randomize_layout;
struct linux_binfmt可执行程序的结构
linux支持其他不同格式的可执行程序, 在这种方式下, linux能运行其他操作系统所编译的程序, 如MS-DOS程序, 活BSD Unix的COFF可执行格式, 因此linux内核用struct linux_binfmt来描述各种可执行程序。
linux内核对所支持的每种可执行的程序类型都有个struct linux_binfmt的数据结构,定义如下:
/*
* This structure defines the functions that are used to load the binary formats that
* linux accepts.
*/
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump; /* minimal dump size */
} __randomize_layout;
其提供了3种方法来加载和执行可执行程序
- load_binary
通过读存放在可执行文件中的信息为当前进程建立一个新的执行环境 - load_shlib
用于动态的把一个共享库捆绑到一个已经在运行的进程, 这是由uselib()系统调用激活的 - core_dump
在名为core的文件中, 存放当前进程的执行上下文. 这个文件通常是在进程接收到一个缺 省操作为”dump”的信号时被创建的, 其格式取决于被执行程序的可执行类型。
所有的linux_binfmt对象都处于一个链表中, 第一个元素的地址存放在formats变量中, 可以通过调用register_binfmt()和unregister_binfmt()函数在链表中插入和删除元素, 在系统启动期间, 为每个编译进内核的可执行格式都执行registre_fmt()函数. 当实现了一个新的可执行格式的模块正被装载时, 也执行这个函数, 当模块被卸载时, 执行unregister_binfmt()函数.
当我们执行一个可执行程序的时候, 内核会list_for_each_entry遍历所有注册的linux_binfmt对象, 对其调用load_binrary方法来尝试加载, 直到加载成功为止.
execve加载可执行程序的过程
内核中实际执行execv()或execve()系统调用的程序是do_execve(),这个函数先打开目标映像文件,并从目标文件的头部(第一个字节开始)读入若干(当前Linux内核中是128)字节(实际上就是填充ELF文件头,下面的分析可以看到),然后调用另一个函数search_binary_handler(),在此函数里面,它会搜索我们上面提到的Linux支持的可执行文件类型队列,让各种可执行程序的处理程序前来认领和处理。如果类型匹配,则调用load_binary函数指针所指向的处理函数来处理目标映像文件。在ELF文件格式中,处理函数是load_elf_binary函数,下面主要就是分析load_elf_binary函数的执行过程(说明:因为内核中实际的加载需要涉及到很多东西,这里只关注跟ELF文件的处理相关的代码):
sys_execve() > do_execve() > do_execveat_common > search_binary_handler() > load_elf_binary()
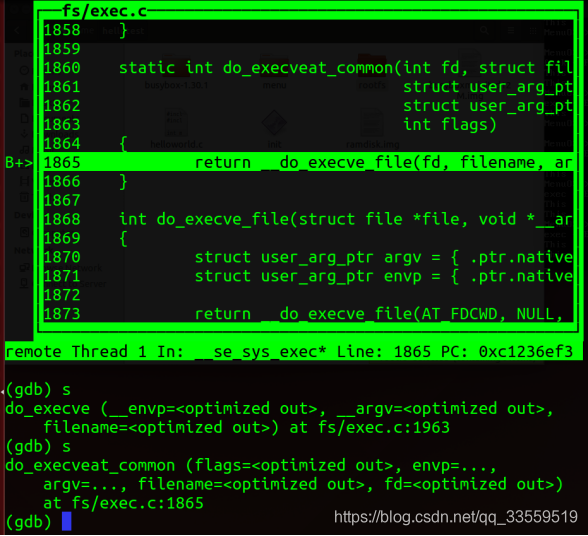
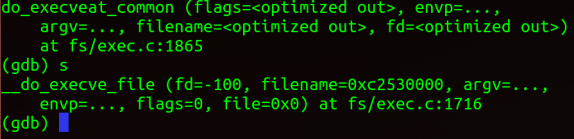
do_execveat_common中的__do_execve_file定义:
/*
* sys_execve() executes a new program.
*/
static int __do_execve_file(int fd, struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags, struct file *file)
{
char *pathbuf = NULL;
struct linux_binprm *bprm;/* 这个结构当然是非常重要的,下文,列出了这个结构体以便查询各个成员变量的意义 */
struct files_struct *displaced;
int retval;
if (IS_ERR(filename))
return PTR_ERR(filename);
/*
* We move the actual failure in case of RLIMIT_NPROC excess from
* set*uid() to execve() because too many poorly written programs
* don't check setuid() return code. Here we additionally recheck
* whether NPROC limit is still exceeded.
*/
if ((current->flags & PF_NPROC_EXCEEDED) &&
atomic_read(¤t_user()->processes) > rlimit(RLIMIT_NPROC)) {
retval = -EAGAIN;
goto out_ret;
}
/* We're below the limit (still or again), so we don't want to make
* further execve() calls fail. */
current->flags &= ~PF_NPROC_EXCEEDED;
/*1.调用unshare_files()为进程复制一份文件表;*/
retval = unshare_files(&displaced);
if (retval)
goto out_ret;
retval = -ENOMEM;
/*2、调用kzalloc()在堆上分配一份struct linux_binprm结构体;*/
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
if (!bprm)
goto out_files;
retval = prepare_bprm_creds(bprm);
if (retval)
goto out_free;
check_unsafe_exec(bprm);
current->in_execve = 1;
if (!file)
/*3、调用open_exec()查找并打开二进制文件;*/
file = do_open_execat(fd, filename, flags);
retval = PTR_ERR(file);
if (IS_ERR(file))
goto out_unmark;
/*4、调用sched_exec()找到最小负载的CPU,用来执行该二进制文件;*/
sched_exec();
/*5、根据获取的信息,填充struct linux_binprm结构体中的file、filename、interp成员;*/
bprm->file = file;
if (!filename) {
bprm->filename = "none";
} else if (fd == AT_FDCWD || filename->name[0] == '/') {
bprm->filename = filename->name;
} else {
if (filename->name[0] == '\0')
pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d", fd);
else
pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d/%s",
fd, filename->name);
if (!pathbuf) {
retval = -ENOMEM;
goto out_unmark;
}
/*
* Record that a name derived from an O_CLOEXEC fd will be
* inaccessible after exec. Relies on having exclusive access to
* current->files (due to unshare_files above).
*/
if (close_on_exec(fd, rcu_dereference_raw(current->files->fdt)))
bprm->interp_flags |= BINPRM_FLAGS_PATH_INACCESSIBLE;
bprm->filename = pathbuf;
}
bprm->interp = bprm->filename;
/*6、调用bprm_mm_init()创建进程的内存地址空间,并调用init_new_context()检查当前进程是否使用自定义的局部描述符表;如果是,那么分配和准备一个新的LDT;*/
retval = bprm_mm_init(bprm);
if (retval)
goto out_unmark;
retval = prepare_arg_pages(bprm, argv, envp);
if (retval < 0)
goto out;
/*调用prepare_binprm()检查该二进制文件的可执行权限;最后,kernel_read()读取二进制文件的头128字节(这些字节用于识别二进制文件的格式及其他信息,后续会使用到);*/
retval = prepare_binprm(bprm);
if (retval < 0)
goto out;
/*调用copy_strings_kernel()从内核空间获取二进制文件的路径名称;*/
retval = copy_strings_kernel(1, &bprm->filename, bprm);
if (retval < 0)
goto out;
bprm->exec = bprm->p;
/*调用copy_string()从用户空间拷贝环境变量*/
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out;
/*调用copy_string()从用户空间拷贝命令行参数;*/
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out;
would_dump(bprm, bprm->file);
/*
至此,二进制文件已经被打开,struct linux_binprm结构体中也记录了重要信息;
下面需要识别该二进制文件的格式并最终运行该文件
*/
retval = exec_binprm(bprm);
if (retval < 0)
goto out;
/* execve succeeded */
current->fs->in_exec = 0;
current->in_execve = 0;
membarrier_execve(current);
rseq_execve(current);
acct_update_integrals(current);
task_numa_free(current);
free_bprm(bprm);
kfree(pathbuf);
if (filename)
putname(filename);
if (displaced)
put_files_struct(displaced);
return retval;
out:
if (bprm->mm) {
acct_arg_size(bprm, 0);
mmput(bprm->mm);
}
out_unmark:
current->fs->in_exec = 0;
current->in_execve = 0;
out_free:
free_bprm(bprm);
kfree(pathbuf);
out_files:
if (displaced)
reset_files_struct(displaced);
out_ret:
if (filename)
putname(filename);
return retval;
}
exec_binprm识别并加载二进程程序
每种格式的二进制文件对应一个struct linux_binprm结构体,load_binary成员负责识别该二进制文件的格式;
内核使用链表组织这些struct linux_binfmt结构体,链表头是formats。
接着do_execveat_common()继续往下看:
调用search_binary_handler()函数对linux_binprm的formats链表进行扫描,并尝试每个load_binary函数,如果成功加载了文件的执行格式,对formats的扫描终止。
static int exec_binprm(struct linux_binprm *bprm)
{
pid_t old_pid, old_vpid;
int ret;
/* Need to fetch pid before load_binary changes it */
old_pid = current->pid;
rcu_read_lock();
old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent));
rcu_read_unlock();
ret = search_binary_handler(bprm);
if (ret >= 0) {
audit_bprm(bprm);
trace_sched_process_exec(current, old_pid, bprm);
ptrace_event(PTRACE_EVENT_EXEC, old_vpid);
proc_exec_connector(current);
}
return ret;
}
search_binary_handler识别二进程程序
这里需要说明的是,这里的fmt变量的类型是struct linux_binfmt *, 但是这一个类型与之前在do_execveat_common()中的bprm是不一样的
/*
* cycle the list of binary formats handler, until one recognizes the image
*/
int search_binary_handler(struct linux_binprm *bprm)
{
bool need_retry = IS_ENABLED(CONFIG_MODULES);
struct linux_binfmt *fmt;
int retval;
/* This allows 4 levels of binfmt rewrites before failing hard. */
if (bprm->recursion_depth > 5)
return -ELOOP;
retval = security_bprm_check(bprm);
if (retval)
return retval;
retval = -ENOENT;
retry:
read_lock(&binfmt_lock);
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth++;
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
bprm->recursion_depth--;
if (retval < 0 && !bprm->mm) {
/* we got to flush_old_exec() and failed after it */
read_unlock(&binfmt_lock);
force_sigsegv(SIGSEGV, current);
return retval;
}
if (retval != -ENOEXEC || !bprm->file) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
if (need_retry) {
if (printable(bprm->buf[0]) && printable(bprm->buf[1]) &&
printable(bprm->buf[2]) && printable(bprm->buf[3]))
return retval;
if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0)
return retval;
need_retry = false;
goto retry;
}
return retval;
}
load_binary加载可执行程序
前面提到了,linux内核支持多种可执行程序格式, 每种格式都被注册为一个linux_binfmt结构, 其中存储了对应可执行程序格式加载函数等。
四、进程的切换和系统的一般执行过程
进程切换的关键代码switch_to分析
a.进程调度与进程调度的时机分析
1、不同类型的进程有不同的调度需求
第一种分类:
(1)I/O-bound:频繁进行I/O,花费很多时间等待I/O操作的完成。
(2)CPU-bound:计算密集型,需要大量CPU时间进行计算。
第二种分类:
(1)批处理进程:不必交互、很快响应。
(2)实时进程:要求响应时间短。
(3)交互式进程(shell)。
2、调度策略:是一组规则,它们决定什么时候以怎样的方式选择一个新进程运行。
3、linux进程调度是基于分时和优先级的。
4、Linux的进程根据优先级排队。
5、Linux中进程的优先级是动态的。
6、内核中的调度算法相关代码使用了类似OOD中的策略模式。
7、进程调度的时机:
(1)中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
(2)内核线程(只有内核态没有用户态的特殊进程)可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
(3)用户态进程无法实现主动调度,只能被动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
b.进程上下文切换相关代码分析
1、进程的切换
(1)为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换;
(2)挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行;
(3)进程上下文包含了进程执行需要的所有信息
1)用户地址空间:包括程序代码,数据,用户堆栈等
2)控制信息:进程描述符,内核堆栈等
3)硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
2、schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
(1)next = pick_ next_task(rq, prev);//进程调度算法都封装这个函数内部
(2)context_switch(rq, prev, next);//进程上下文切换
(3)switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
switch_to:
31#define switch_to(prev, next, last)
32do {
33 /*
34 * Context-switching clobbers all registers, so we clobber
35 * them explicitly, via unused output variables.
36 * (EAX and EBP is not listed because EBP is saved/restored
37 * explicitly for wchan access and EAX is the return value of
38 * __switch_to())
39 */
40 unsigned long ebx, ecx, edx, esi, edi;
41
42 asm volatile("pushfl\n\t" /* save flags */ //保存当前进程的flags
43 "pushl %%ebp\n\t" /* save EBP */ //把当前进程的堆栈基址压栈
44 "movl %%esp,%[prev_sp]\n\t" /* save ESP */ //把当前的栈顶保存到prev->thread.sp
45 "movl %[next_sp],%%esp\n\t" /* restore ESP */ //把下一个进程的栈顶保存到esp中,这两句完成了内核堆栈的切换
46 "movl $1f,%[prev_ip]\n\t" /* save EIP */ //保存当前进程的EIP,可以从这恢复
47 "pushl %[next_ip]\n\t" /* restore EIP */ //把下一个进程的起点位置压到堆栈,就是next进程的栈顶。next_ip一般是$1f,对于新创建的子进程是ret_from_fork
//一般用return直接把next_ip pop出来
48 __switch_canary
49 "jmp __switch_to\n" /* regparm call */ //jmp通过寄存器传递参数,即后面的a,d。 函数__switch_to也有return把next_ip pop出来
50 "1:\t" //认为从这开始执行next进程(EIP角度),第一条指令是next_ip这个起点,但前面已经完成内核堆栈的切换,早就是next进程的内核堆栈(算prev进程,比较模糊)
51 "popl %%ebp\n\t" /* restore EBP */ //next进程曾经是prev进程,压栈过ebp
52 "popfl\n" /* restore flags */
53
54 /* output parameters */
55 : [prev_sp] "=m" (prev->thread.sp), //当前进程的,在中断内部,在内核态,sp是内核堆栈的栈顶
56 [prev_ip] "=m" (prev->thread.ip), //当前进程的EIP
57 "=a" (last),
58
59 /* clobbered output registers: */
60 "=b" (ebx), "=c" (ecx), "=d" (edx),
61 "=S" (esi), "=D" (edi)
62
63 __switch_canary_oparam
64
65 /* input parameters: */
66 : [next_sp] "m" (next->thread.sp), //下一个进程的内核堆栈的栈顶
67 [next_ip] "m" (next->thread.ip), //下一个进程的执行起点
68
69 /* regparm parameters for __switch_to(): */
70 [prev] "a" (prev), //寄存器的传递
71 [next] "d" (next)
72
73 __switch_canary_iparam
74
75 : /* reloaded segment registers */
76 "memory");
77} while (0)
Linux系统的一般执行过程
(一)Linux系统的一般执行过程分析
1、Linux系统的一般执行过程
最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
(1)正在运行的用户态进程X
(2)发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
(3)SAVE_ALL //保存现场
(4)中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
(5)标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
(6)restore_all //恢复现场
(7)iret - pop cs:eip/ss:esp/eflags from kernel stack
(8)继续运行用户态进程Y
(二)Linux系统执行过程中的几个特殊情况
1、几种特殊情况
(1)通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
(2)内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
(3)创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
(4)加载一个新的可执行程序后返回到用户态的情况,如execve;
实验结果:
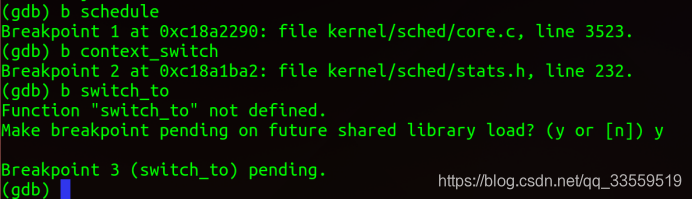
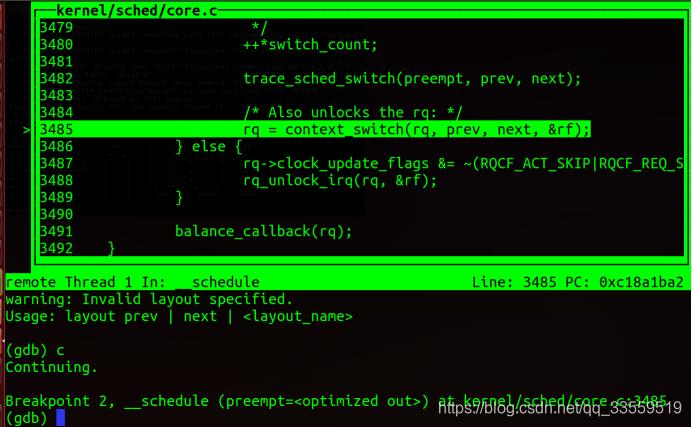
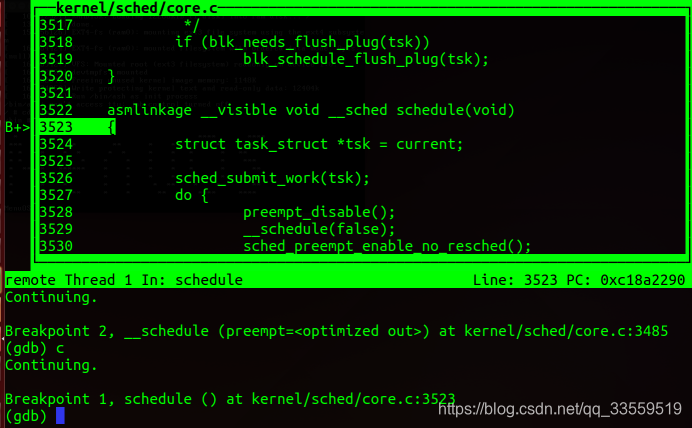
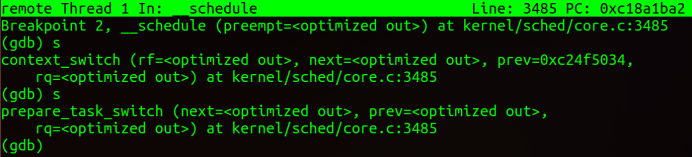
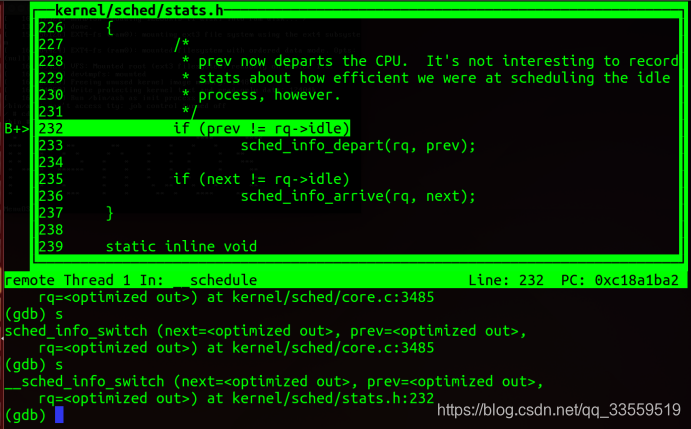
五、总结
1、Linux进程调度是基于分时和优先级的。
2、Linux中,内核线程是只有内核态没有用户态的特殊进程。
3、内核可以看作各种中断处理过程和内核线程的集合。
4、Linux系统的一般执行过程 可以抽象成正在运行的用户态进程X切换到运行用户态进程Y的过程。
5、Linux中,内核线程可以主动调度,主动调度时不需要中断上下文的切换。
6、Linux内核调用schedule()函数进行调度,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换。














 981
981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









