






煎蛋妹子图网站

最近一直在通过爬虫的练习,来巩固自己的所学习到的 python 基础,和爬虫一些框架的使用。今天的程序就是最近在学习的 selenium 库,通过利用 requests + beautifulsoup + selenium 库来进行网站的抓取。抓取的对象是煎蛋网中的妹子板块,图片的质量还是很高的,我放几张妹子图大家感受下。


正所谓妹子驱动学习,今天就给大家详细解析下我是如何一步步的完成妹子图片的抓取。
爬取结果

先看下最后的爬取结果,通过运行 demo.py 代码,程序就会把网站上的妹子图片,保存到当前工程目录下。在此程序中我创建了「jiandan」文件夹,并以当前的进度条为新的文件夹名,即「0.0」「1.0」「2.1」等等。最后把爬取到的图片,保存到相应的文件里。
程序结构
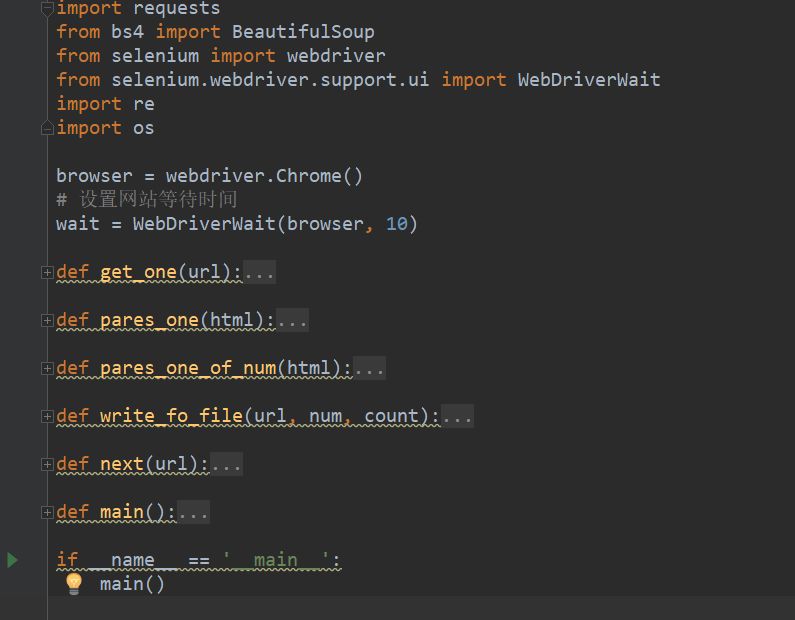
程序主要是由 6 个函数组成
get_one():是利用 webdriver 来请求对应的网站
pares_one():解析没带进度条的网站
pares_one_of_num():解析有带进度条的网站
write_to_file():把抓取到的图片保存到本地文件
next():进行翻页
main():程序执行的主函数
程序思路
如果你对爬虫比较熟悉的话,就会知道爬虫的步骤其实很简单,总结下主要有三部分:
1 目标站点分析,利用合适的请求库进行请求。
2 解析源代码,提取出相应的数据。
3 保存数据。
爬虫程序核心部分就这三个。我们顺着这个思路来看看这次的代码。
目标站点分析
首先要对目标网站进行结构分析,看看它的网页结构是如何,以及网页返回的数据是什么,是否有反爬机制,有些数据是否是通过 js 进行渲染,是否要进行翻页等等。
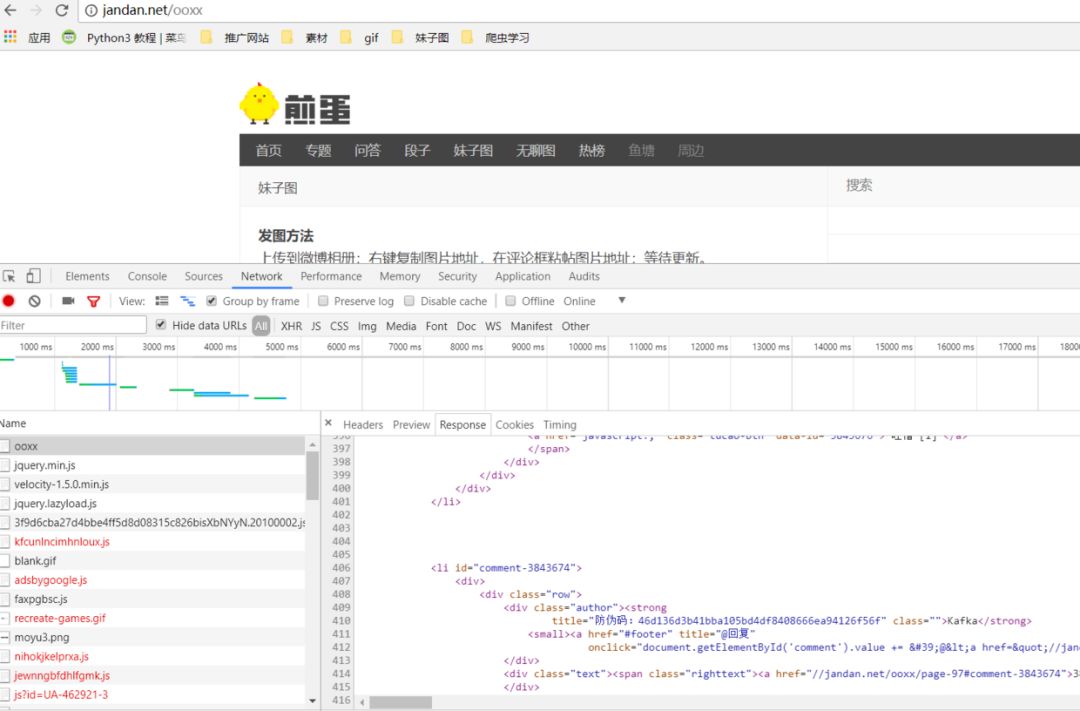
通过谷歌浏览器的开发者模式可以看到,网站的返回结果里是一堆 html 代码,但并没有我们想要的图片链接信息。如果你用常规的 requests 进行请求,返回的数据是不会有我们想要的图片信息。
所以这里我就想到,网站的图片资源应该是通过 js 加载的。对于需要 js 才能加载出来的网站,我们就可以利用 selenium 自动化测试请求库来进行加载。通过 selenium 请求库,我们就可以模拟一个真实的浏览器,请求网站,加载 js,返回我们想要的数据。这里对应的代码如下,需要你去网上下载对应的 chrome 驱动。
browser = webdriver.Chrome()
# 设置网站等待时间
wait = WebDriverWait(browser, 10)
图片信息提取
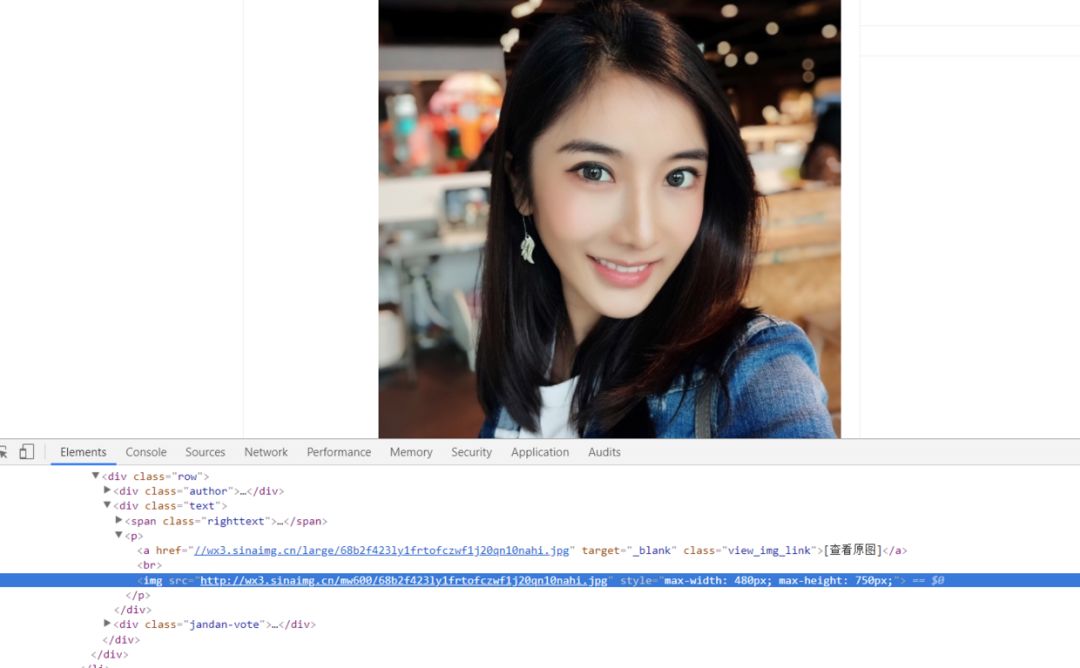
随后就可以利用 beautifulsoup 这个解析库进行解析,把想要的信息提取出来。在这里我们需要的是图片信息,所以我通过 select() 函数进行提取,代码如下:
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select('img')
返回的是一个列表,然后再利用 for 把每个图片的链接,提取出来,并下载,代码如下:
for img in imgs:
img_url = re.findall('src="(.*?)"', str(img))
if not img_url[0][-3:] == 'gif':
if not img_url[0][-3:] == 'png':
if img_url[0][-3:]:
print('正在下载:%s 第 %s 张' % (img_url[0], count))
write_fo_file(img_url[0], percent_num, count)
count += 1
这里需要注意的是,我最开始在爬取的过程中遇到有些图片不是 jpg 格式,以及有些图片是 gif 格式。所以我加了一些判断来保证,获取到的图片链接是 jpg 格式,程序才能把图片下载下来。所以这里就有优化的地方,大家可以去再查找一些资料,看看是否可以把 png 或 gif 格式的图片一起保存。
解析源代码
当前进度条
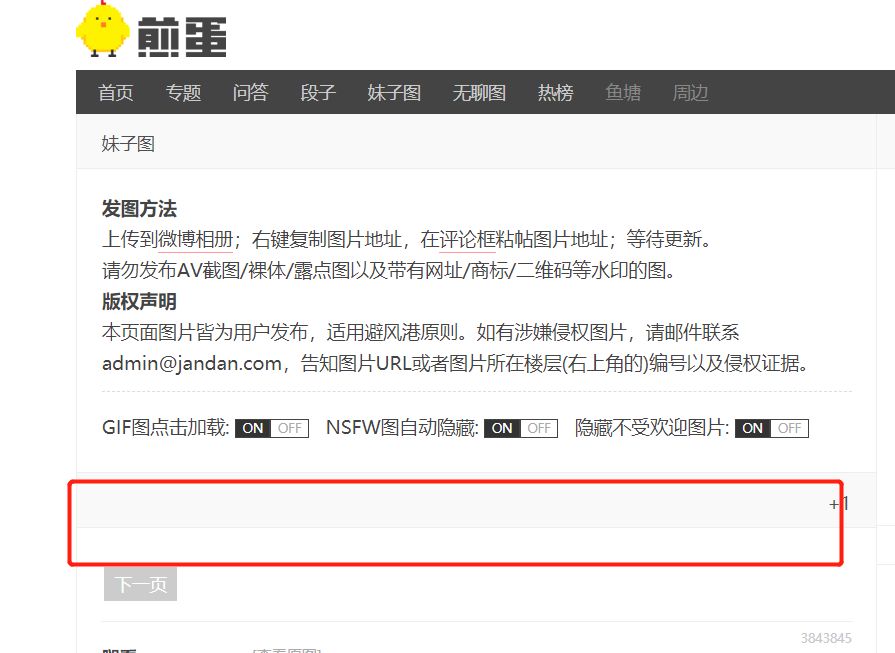
为了控制程序爬取的次数,我们就需要找到一些条件来进行判断。一般的网站是会返回总的条数,但这次的网站通过观察并没有返回总条数的信息。并且在最开始进入妹子图板块,上方是没有进度条信息。
但当点击下一页的时候,网站就有显示出当前的进度条。
我们就可以利用这个当前浏览的位置,来控制程序爬取的次数。随后通过网站的源代码分析,就很容易得到这部分的信息,对应的代码如下:
num = soup.select('#body #comments .comments .page-meter-title')[0].getText()
percent = re.findall('\d+', num)
percent_num = percent[0] + '.' + percent[1]
然后定义一个 next() 函数,来判断当前的进度条是否达到 100.0%,如果没有则继续爬取,对应的代码如下:
def next(url):
html = get_one(url)
percent_num, next_url = pares_one_of_num(html)
while percent_num != '100.0':
next(next_url)
下一页链接

进一步的观察我们可以看到,下一页的链接地址,是保存在 a 标签当中,所以我们获取到 a 标签的内容,我们就有了跳转的能力,就可以爬取下一页的内容。对应的代码如下:
url = soup.select('#body #comments .comments .cp-pagenavi a')[1]
href = re.findall('href="(.*?)"', str(url))
next_url = 'https:' + href[0]
针对最开始的页面没有当前浏览位置信息,我分别写了两个解析函数:pares_one()、pares_one_of_num()。对应的代码如下:
def pares_one(html):
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select('img')
url = soup.select('#body #comments .comments .cp-pagenavi a')[1]
href = re.findall('href="(.*?)"', str(url))
next_url = 'https:' + href[0]
count = 0
for img in imgs:
img_url = re.findall('src="(.*?)"', str(img))
if not img_url[0][-3:] == 'gif':
if not img_url[0][-3:] == 'png':
print('正在下载:%s 第 %s 张' % (img_url[0], count))
write_fo_file(img_url[0], '0.0', count)
count += 1
return next_url
def pares_one_of_num(html):
soup = BeautifulSoup(html, 'lxml')
imgs = soup.select('img')
num = soup.select('#body #comments .comments .page-meter-title')[0].getText()
percent = re.findall('\d+', num)
url = soup.select('#body #comments .comments .cp-pagenavi a')[1]
href = re.findall('href="(.*?)"', str(url))
percent_num = percent[0] + '.' + percent[1]
next_url = 'https:' + href[0]
count = 0
for img in imgs:
img_url = re.findall('src="(.*?)"', str(img))
if not img_url[0][-3:] == 'gif':
if not img_url[0][-3:] == 'png':
if img_url[0][-3:]:
print('正在下载:%s 第 %s 张' % (img_url[0], count))
write_fo_file(img_url[0], percent_num, count)
count += 1
return percent_num, next_url
保存数据
最后就是把图片保存到文件中,这部分的代码如下:
def write_fo_file(url, num, count):
dirName = u'{}/{}'.format('jiandan', num)
if not os.path.exists(dirName):
os.makedirs(dirName)
filename = '%s/%s/%s.jpg' % (os.path.abspath('.'), dirName, count)
print(filename)
with open(filename, 'wb+') as jpg:
jpg.write(requests.get(url).content)
优化改进

源代码我已上传到 Github 上,需要的同学可以点击「阅读原文」,如果觉得程序还不错的话,可以给我项目点个 star。
本次的程序还有一些不足的地方,比如利用 selenium 库在解析的时候非常的慢,这部分是可以优化的。还有程序在爬取到 80.6% 的时候,程序报错了,并没能把图片全部爬取完。这就说明还有一些情况,我没有考虑到。有待以后进一步优化。
这波教程不点个赞,点个广告说不过去吧?这个网站有很多福利,我只能说大家注意身体。
推荐阅读:
每天分析 python 干货
















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









